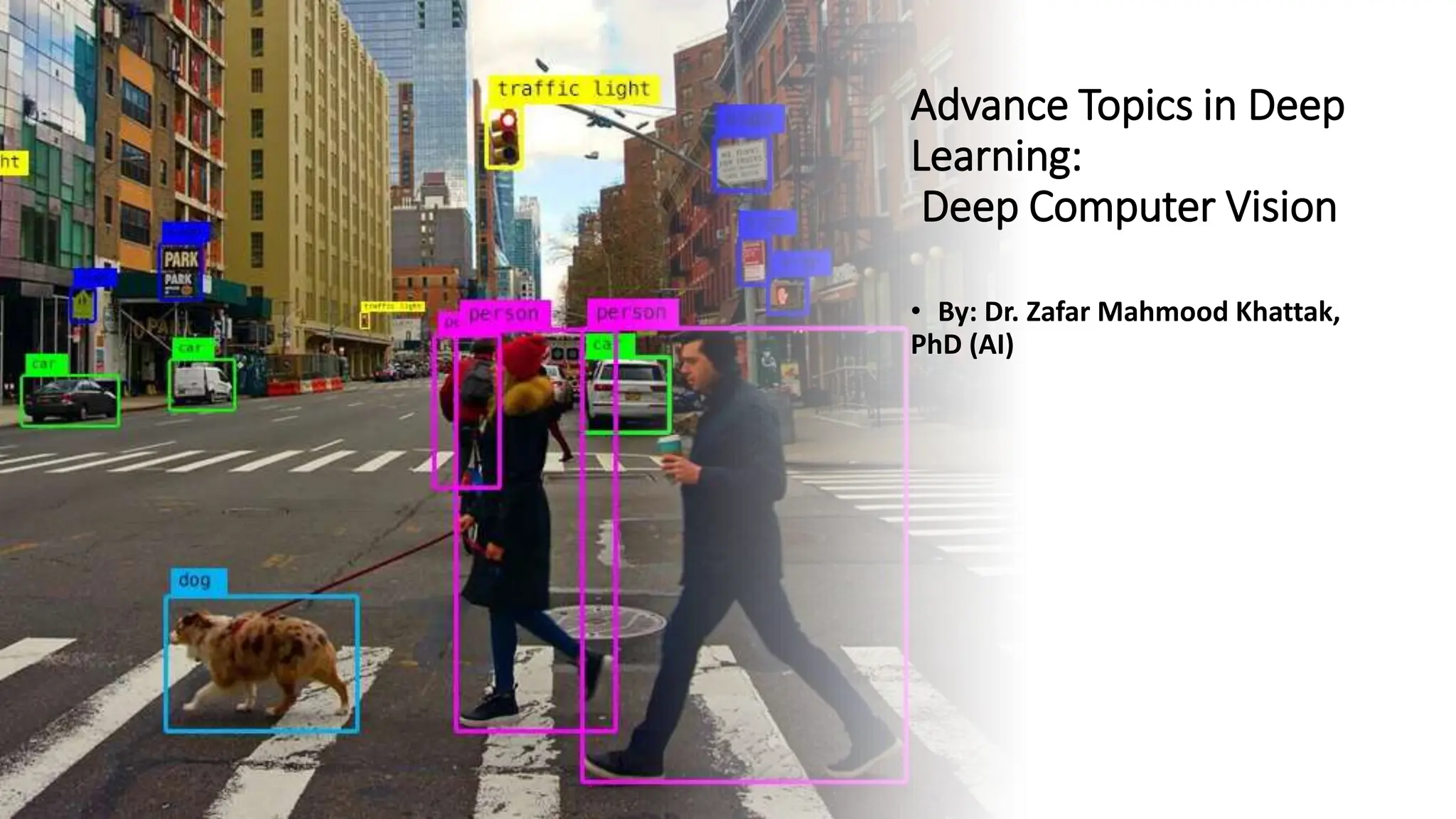
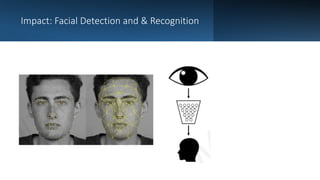
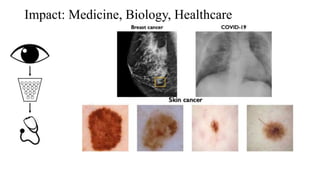
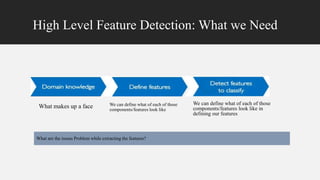
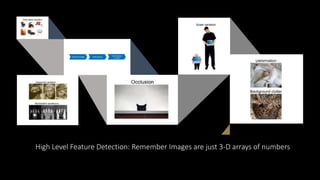
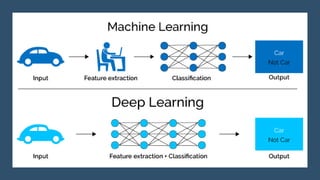
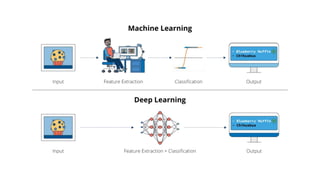
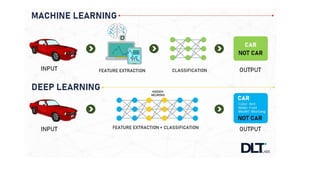
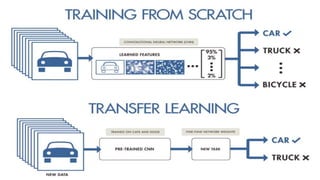
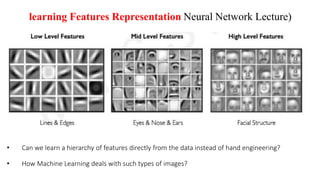
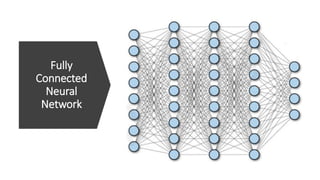
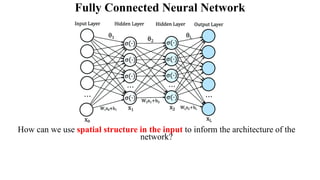
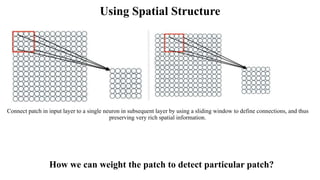
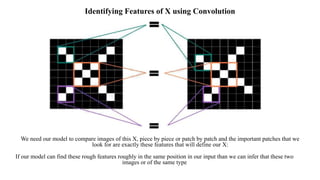
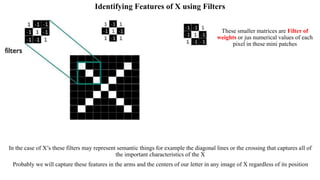
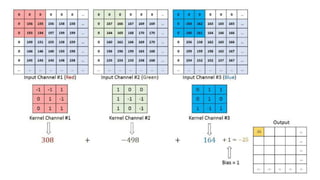
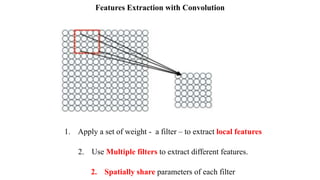
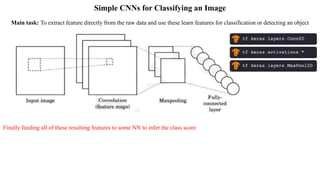
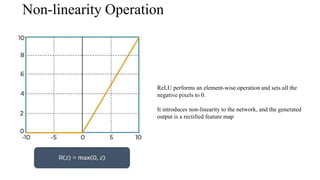
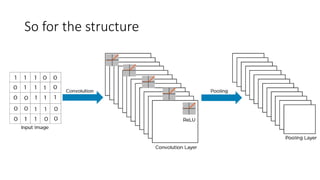
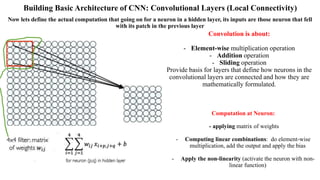
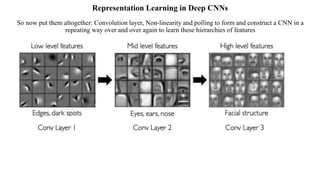
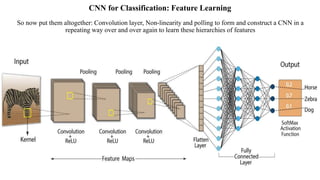
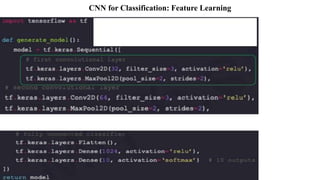
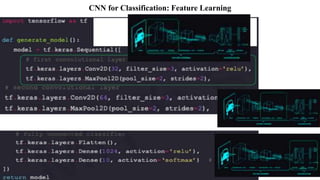
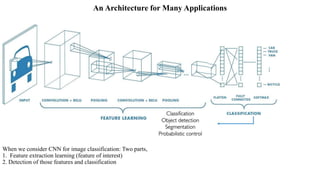
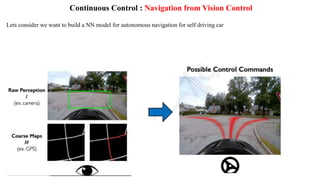
Deep computer vision uses deep learning and machine learning techniques to build powerful vision systems that can analyze raw visual inputs and understand what objects are present and where they are located. Convolutional neural networks (CNNs) are well-suited for computer vision tasks as they can learn visual features and hierarchies directly from data through operations like convolution, non-linearity, and pooling. CNNs apply filters to extract features, introduce non-linearity, and use pooling to reduce dimensionality while preserving spatial data. This repeating structure allows CNNs to learn increasingly complex features to perform tasks like image classification, object detection, semantic segmentation, and continuous control from raw pixels.























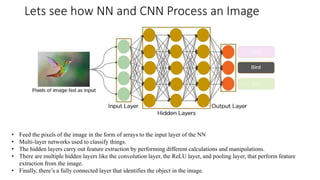
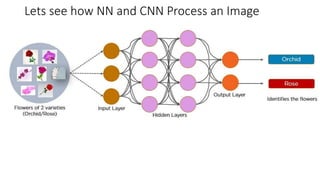
![Lets see how NN and CNN Process an Image
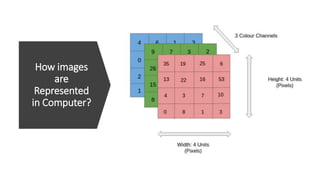
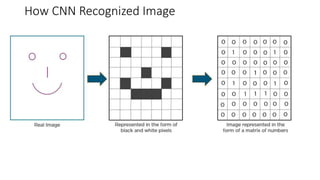
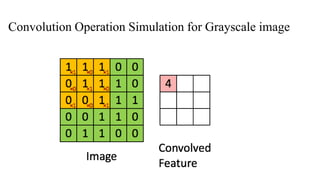
In CNN, every image is represented in the form of an array of pixel values.
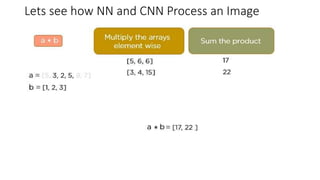
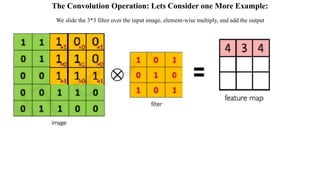
Let’s understand the convolution operation using two matrices, a and b, of 1 dimension.
a = [5,3,2,5,9,7]
b = [1,2,3]](https://image.slidesharecdn.com/deepcomputervision-1-240112140737-0d43f328/85/Deep-Computer-Vision-1-pptx-41-320.jpg)
![Lets see how NN and CNN Process an Image
a = [5,3,2,5,9,7]
b = [1,2,3]](https://image.slidesharecdn.com/deepcomputervision-1-240112140737-0d43f328/85/Deep-Computer-Vision-1-pptx-42-320.jpg)

















































![TOR Code of cunduct & misuse of computing[1].pptx](https://cdn.slidesharecdn.com/ss_thumbnails/torcodeofcunductmisuseofcomputing1-240707093743-28a2c05d-thumbnail.jpg?width=640&height=640&fit=bounds)

























