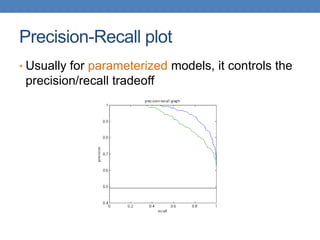
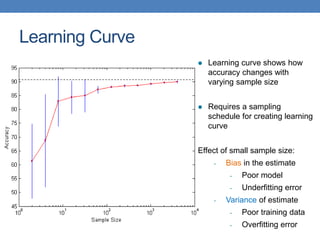
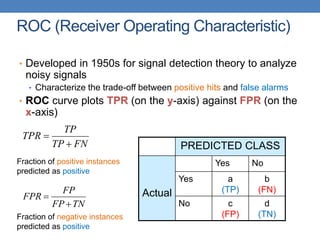
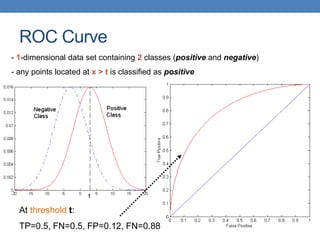
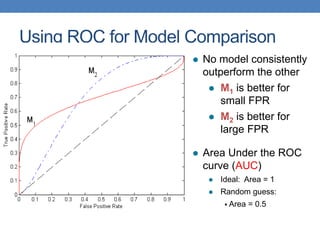
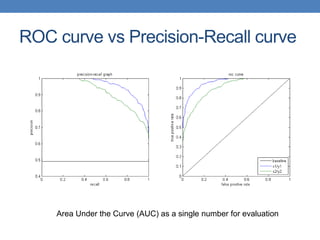
The document discusses various methods for evaluating machine learning models and comparing their performance. It covers metrics like accuracy, precision, recall, cost matrices, and ROC curves. Key methods discussed include holdout validation, k-fold cross validation, and the bootstrap method for obtaining reliable performance estimates. It also addresses issues like class imbalance and overfitting. ROC curves and the area under the ROC curve are presented as ways to visually and quantitatively compare models.




![Cost vs Accuracy
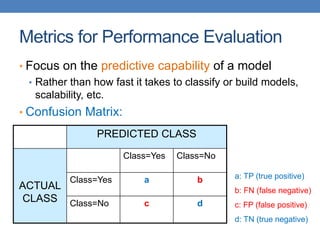
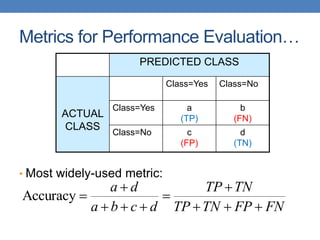
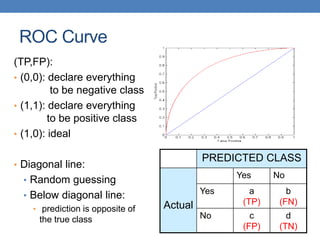
Count PREDICTED CLASS
ACTUAL
CLASS
Class=Yes Class=No
Class=Yes a b
Class=No c d
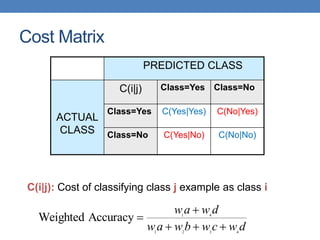
Cost PREDICTED CLASS
ACTUAL
CLASS
Class=Yes Class=No
Class=Yes p q
Class=No q p
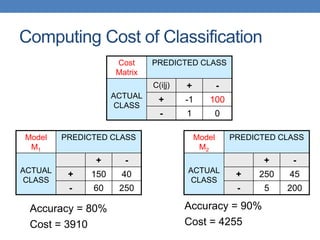
N = a + b + c + d
Accuracy = (a + d)/N
Cost = p (a + d) + q (b + c)
= p (a + d) + q (N – a – d)
= q N – (q – p)(a + d)
= N [q – (q-p) Accuracy]
Accuracy is proportional to cost if
1. C(Yes|No)=C(No|Yes) = q
2. C(Yes|Yes)=C(No|No) = p](https://image.slidesharecdn.com/datamining-lect11-221228144836-90062658/85/datamining-lect11-pptx-8-320.jpg)

































![PERFORMANCE_PREDICTION__PARAMETERS[1].pptx](https://cdn.slidesharecdn.com/ss_thumbnails/performancepredictionparameters1-240130171305-9f984922-thumbnail.jpg?width=640&height=640&fit=bounds)


































