Downloaded 2,020 times















![Dissimilarities between Data Objects?
Similarity
− Numerical measure of how alike two data
objects are.
− Is higher when objects are more alike.
− Often falls in the range [0,1]
Dissimilarity
− Numerical measure of how different are two data
objects
− Lower when objects are more alike
− Minimum dissimilarity is often 0
− Upper limit varies
Proximity refers to a similarity or dissimilarity](https://image.slidesharecdn.com/datapreprocessing-101029095653-phpapp01/75/Data-preprocessing-20-2048.jpg)

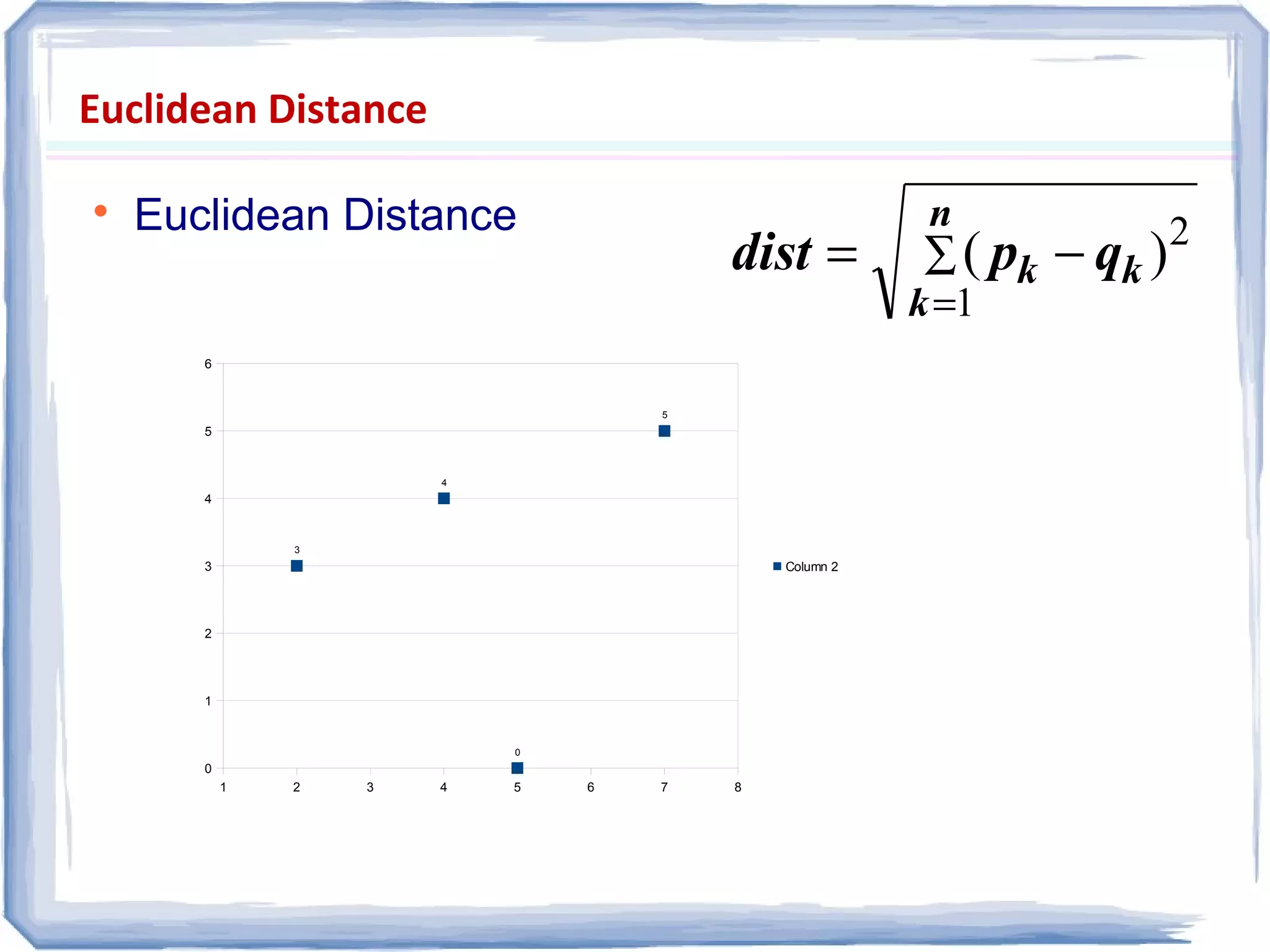

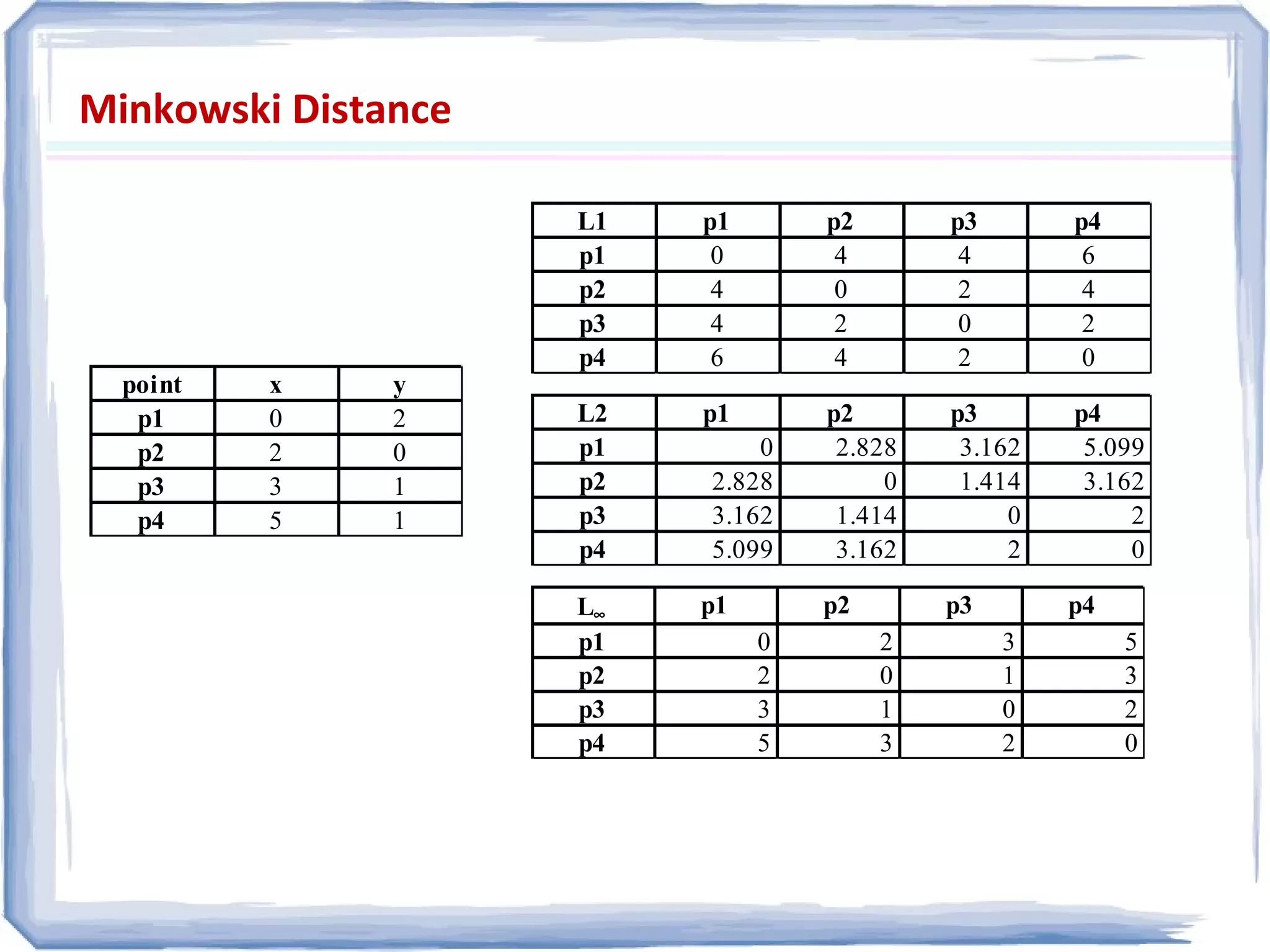






The document presents an overview of data preprocessing, emphasizing its importance for ensuring quality in data mining. It outlines key tasks such as data cleaning, integration, transformation, and reduction, along with methodologies like normalization and aggregation. The document also highlights various data quality dimensions and techniques for managing missing or inconsistent data.

























































































