Download as PDF, PPTX








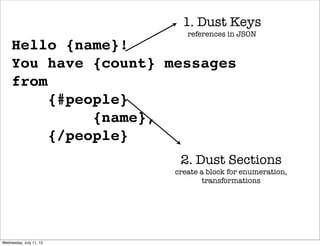
![1. Dust for markup 2. JSON for data
_t = “Hello {name}! json = {
You have {count} new "name": ”James",
messages from "count": 2,
{#people} “people” : [{ “name” : “Jim”,
{name}, “distance” : “2”
{/people} },{ “name”: ”Eran”
”; “distance” : “1”}
]
}
!dust.render(_t, json, function(error, data) {!
$(“mydiv”).html(data);!
}! 3. JAVASCRIPT for render
Hello James! You have 2 new
messages from Jim, Eran! 4. HTML
Wednesday, July 11, 12](https://image.slidesharecdn.com/curiouscaseofdust-130213220508-phpapp01/85/Curious-case-of-Dust-8-320.jpg)







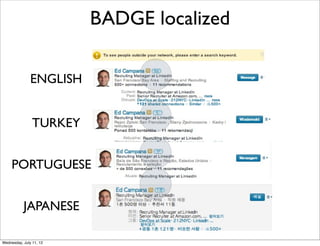







![{
"name": ”James",
"count": 2,
“people” : [{ “name” : “Jim”,
badge.tl “distance” : “2”
},{ “name”: ”Eran”
“distance” : “1”}
{#people}
]
<li>
{>”tl/shared/badge_{distance}”/} }
</li>
{/people}
badge_1.tl logic = dynamic
{@i18n text=“first degree”/}
partials
badge_2.tl
{@i18n text=“second degree”/}
localized text =
@i18n
Wednesday, July 11, 12](https://image.slidesharecdn.com/curiouscaseofdust-130213220508-phpapp01/85/Curious-case-of-Dust-25-320.jpg)





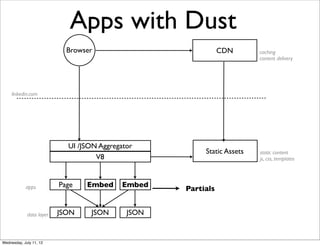
























The document discusses the Dust templating engine and how it provides separation of presentation and logic without sacrificing ease of use. It explains that Dust uses keys in templates to reference data in JSON, sections to enumerate blocks, and helpers/partials to add logic. Helpers can be written once and support the DRY principle. Partials allow passing parameters and accessing the parent scope. The document provides examples of using helpers, partials, and JavaScript controls to dynamically render badges based on a user's connection distance and add localization.















































