Download to read offline









![Which is fastest?
var ints = new int[InnerLoop];
var random = new Random();
for (var inner = 0; inner < InnerLoop; ++inner)
{
ints[inner] = random.Next();
}
// -----------------------------------------------var ints = new int[InnerLoop];
var random = new Random();
Parallel.For(
0,
InnerLoop,
i => ints[i] = random.Next()
);](https://image.slidesharecdn.com/concurrencyscalability-131105040918-phpapp01/85/Concurrency-scalability-9-320.jpg)
![SHARED STATE Race condition
var ints = new int[InnerLoop];
var random = new Random();
for (var inner = 0; inner < InnerLoop; ++inner)
{
ints[inner] = random.Next();
}
// -----------------------------------------------var ints = new int[InnerLoop];
var random = new Random();
Parallel.For(
0,
InnerLoop,
i => ints[i] = random.Next()
);](https://image.slidesharecdn.com/concurrencyscalability-131105040918-phpapp01/85/Concurrency-scalability-10-320.jpg)
![SHARED STATE Poor performance
var ints = new int[InnerLoop];
var random = new Random();
for (var inner = 0; inner < InnerLoop; ++inner)
{
ints[inner] = random.Next();
}
// -----------------------------------------------var ints = new int[InnerLoop];
var random = new Random();
Parallel.For(
0,
InnerLoop,
i => ints[i] = random.Next()
);](https://image.slidesharecdn.com/concurrencyscalability-131105040918-phpapp01/85/Concurrency-scalability-11-320.jpg)








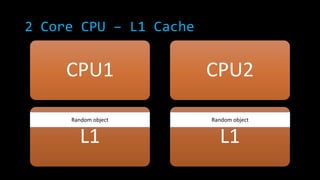
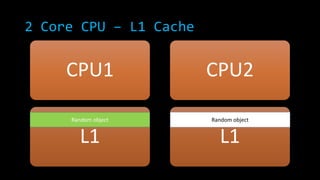
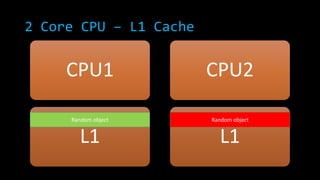
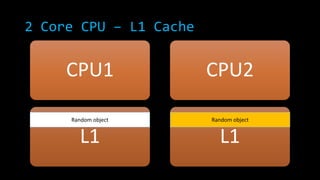
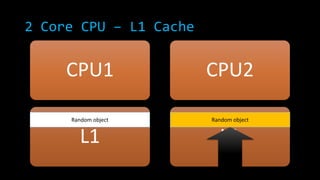
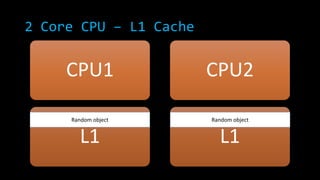
![2 Core CPU – L1 Cache
CPU1
L1
CPU2
new Random ()
new int[InnerLoop]
L1](https://image.slidesharecdn.com/concurrencyscalability-131105040918-phpapp01/85/Concurrency-scalability-23-320.jpg)
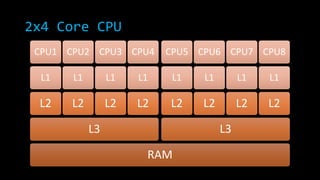
![4 Core CPU – L1 Cache
CPU1
L1
CPU2
L1
CPU3
new Random ()
new int[InnerLoop]
L1
CPU4
L1](https://image.slidesharecdn.com/concurrencyscalability-131105040918-phpapp01/85/Concurrency-scalability-30-320.jpg)
![Solution 1 – Locks
var ints = new int[InnerLoop];
var random = new Random();
Parallel.For(
0,
InnerLoop,
i => {lock (ints) {ints[i] = random.Next();}}
);](https://image.slidesharecdn.com/concurrencyscalability-131105040918-phpapp01/85/Concurrency-scalability-32-320.jpg)
![Solution 2 – No sharing
var ints = new int[InnerLoop];
Parallel.For(
0,
InnerLoop,
() => new Random(),
(i, pls, random) =>
{ints[i] = random.Next(); return random;},
random => {}
);](https://image.slidesharecdn.com/concurrencyscalability-131105040918-phpapp01/85/Concurrency-scalability-33-320.jpg)
![Parallel.For adds overhead
Level2
Level1
Level2
Level0
Level2
Level1
Level2
ints[0]
ints[1]
ints[2]
ints[3]
ints[4]
ints[5]
ints[6]
ints[7]](https://image.slidesharecdn.com/concurrencyscalability-131105040918-phpapp01/85/Concurrency-scalability-34-320.jpg)
![Solution 3 – Less overhead
var ints = new int[InnerLoop];
Parallel.For(
0,
InnerLoop / Modulus,
() => new Random(),
(i, pls, random) =>
{
var begin
= i * Modulus
;
var end
= begin + Modulus
;
for (var iter = begin; iter < end; ++iter)
{
ints[iter] = random.Next();
}
return random;
},
random => {}
);](https://image.slidesharecdn.com/concurrencyscalability-131105040918-phpapp01/85/Concurrency-scalability-35-320.jpg)
![var ints = new int[InnerLoop];
var random = new Random();
for (var inner = 0; inner < InnerLoop; ++inner)
{
ints[inner] = random.Next();
}](https://image.slidesharecdn.com/concurrencyscalability-131105040918-phpapp01/85/Concurrency-scalability-36-320.jpg)
![Solution 4 – Independent runs
var tasks = Enumerable.Range (0, 8).Select (
i => Task.Factory.StartNew (
() =>
{
var ints = new int[InnerLoop];
var random = new Random ();
while (counter.CountDown ())
{
for (var inner = 0; inner < InnerLoop; ++inner)
{
ints[inner] = random.Next();
}
}
},
TaskCreationOptions.LongRunning))
.ToArray ();
Task.WaitAll (tasks);](https://image.slidesharecdn.com/concurrencyscalability-131105040918-phpapp01/85/Concurrency-scalability-37-320.jpg)









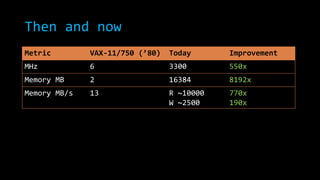
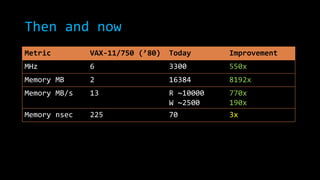
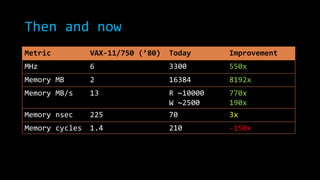
The document discusses concurrency in .NET focusing on scalability, responsiveness, and consistency in performance. It outlines various techniques such as using 'parallel.for', locks, and managing shared state to mitigate race conditions and enhance efficiency. Additionally, it compares modern processing capabilities to older hardware, emphasizing the importance of proper class design and measurement in performance optimization.










![[嵌入式系統] MCS-51 實驗 - 使用 IAR (2)](https://cdn.slidesharecdn.com/ss_thumbnails/mcs51iarpart2-150613071717-lva1-app6891-thumbnail.jpg?width=640&height=640&fit=bounds)





![[嵌入式系統] MCS-51 實驗 - 使用 IAR (3)](https://cdn.slidesharecdn.com/ss_thumbnails/mcs51iarpart3-150613071723-lva1-app6892-thumbnail.jpg?width=640&height=640&fit=bounds)

























































