Download as PDF, PPTX












![Parallelism in the Write-Ahead Log
Client Connections C1 C2 C3
ϟ ϟ ϟ
W3
W2
W1
WAL Writers
tx01 tx03 tx04
tx02
tx06
tx11
tx05
tx08
tx12
tx07
tx09
tx10
Sequencer W1[0] W1[1] W3[0]
W2[0] …](https://image.slidesharecdn.com/questexactlyoncecommitconf-240704152526-ea886719/75/Como-hemos-implementado-semantica-de-Exactly-Once-en-nuestra-base-de-datos-de-alto-rendimiento-16-2048.jpg)
![Out-of-order Merge
W3
W2
W1
tx01 tx03 tx04
tx02
tx06
tx11
tx05
tx08
tx12
tx07
tx09
tx10
W1[0] W1[1] W3[0]
W2[0] …
tx01
ts price symbol qty
ts01 178.08 AAPL 1000
ts02 148.66 GOOGL 400
ts03 424.86 MSFT 5000
ts10 178.09 AMZN 100
ts11 505.08 META 2500
ts12 394.14 GS 2000
… … … …
tx02
ts price symbol qty
ts04 192.42 JPM 5000
ts05 288.78 V 300
ts06 156.40 JNJ 6500
ts07 181.62 AMD 7800
ts08 37.33 BAC 1500
ts09 60.83 KO 4000
… … … …](https://image.slidesharecdn.com/questexactlyoncecommitconf-240704152526-ea886719/75/Como-hemos-implementado-semantica-de-Exactly-Once-en-nuestra-base-de-datos-de-alto-rendimiento-17-2048.jpg)











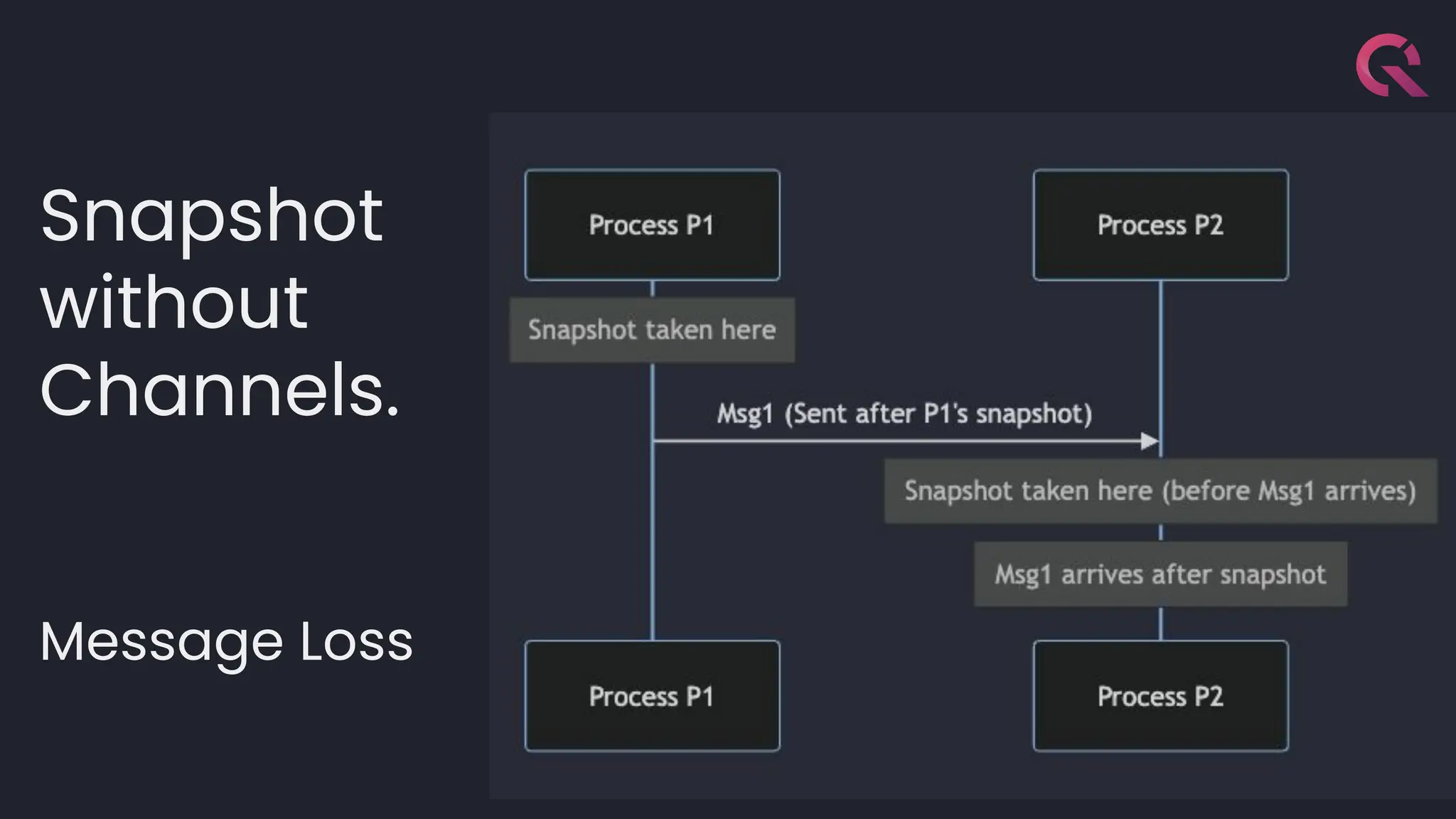
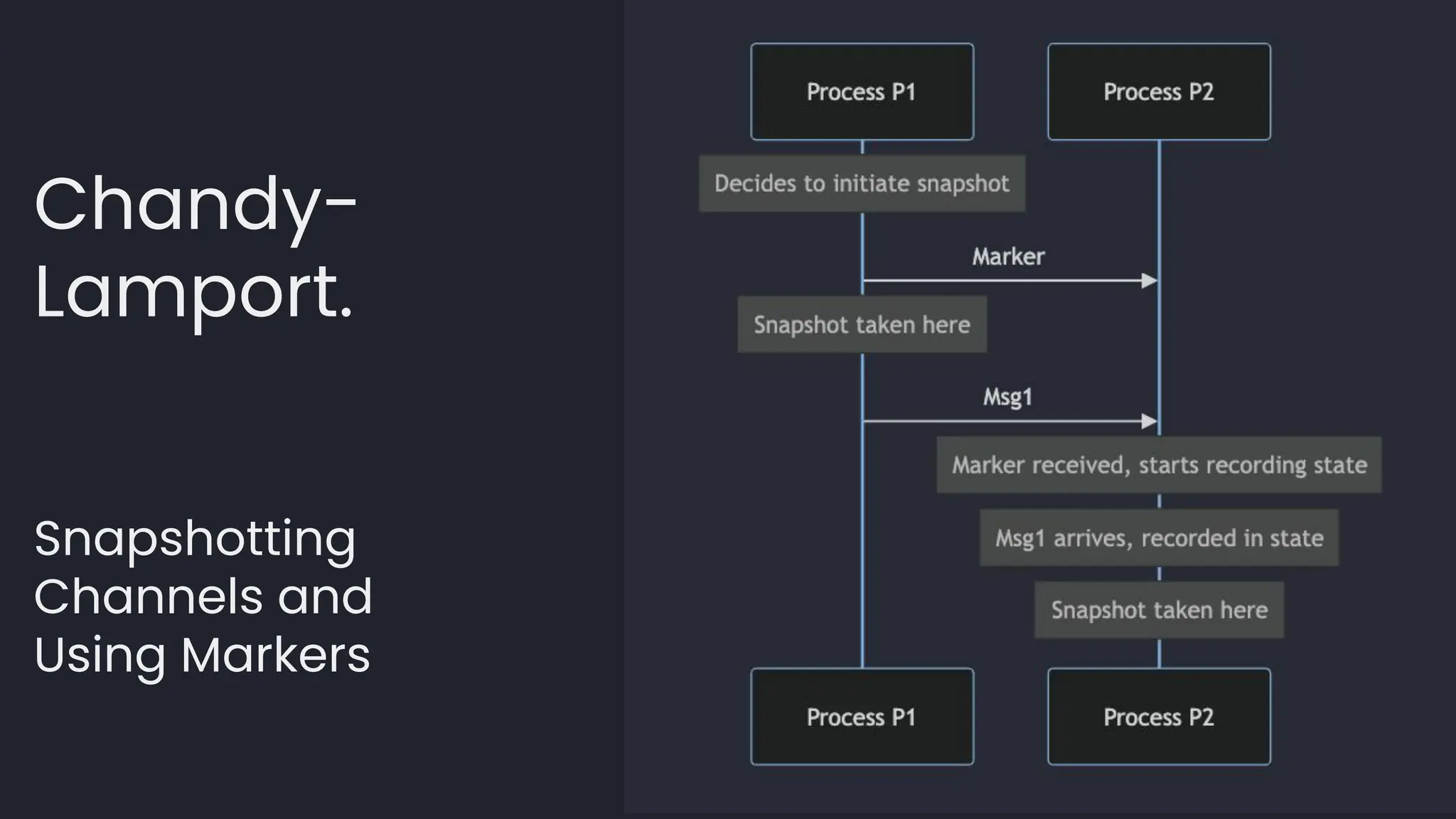
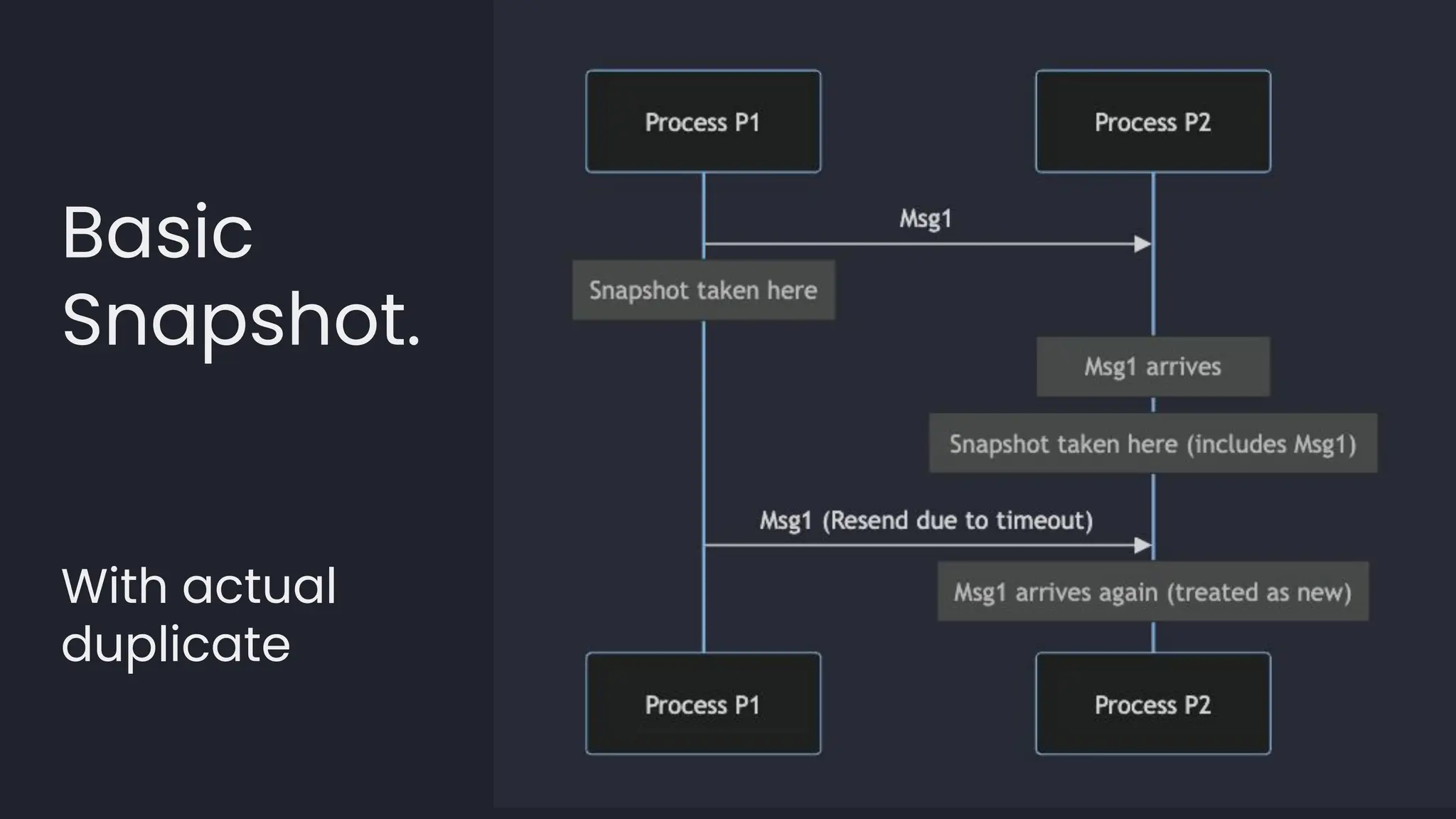
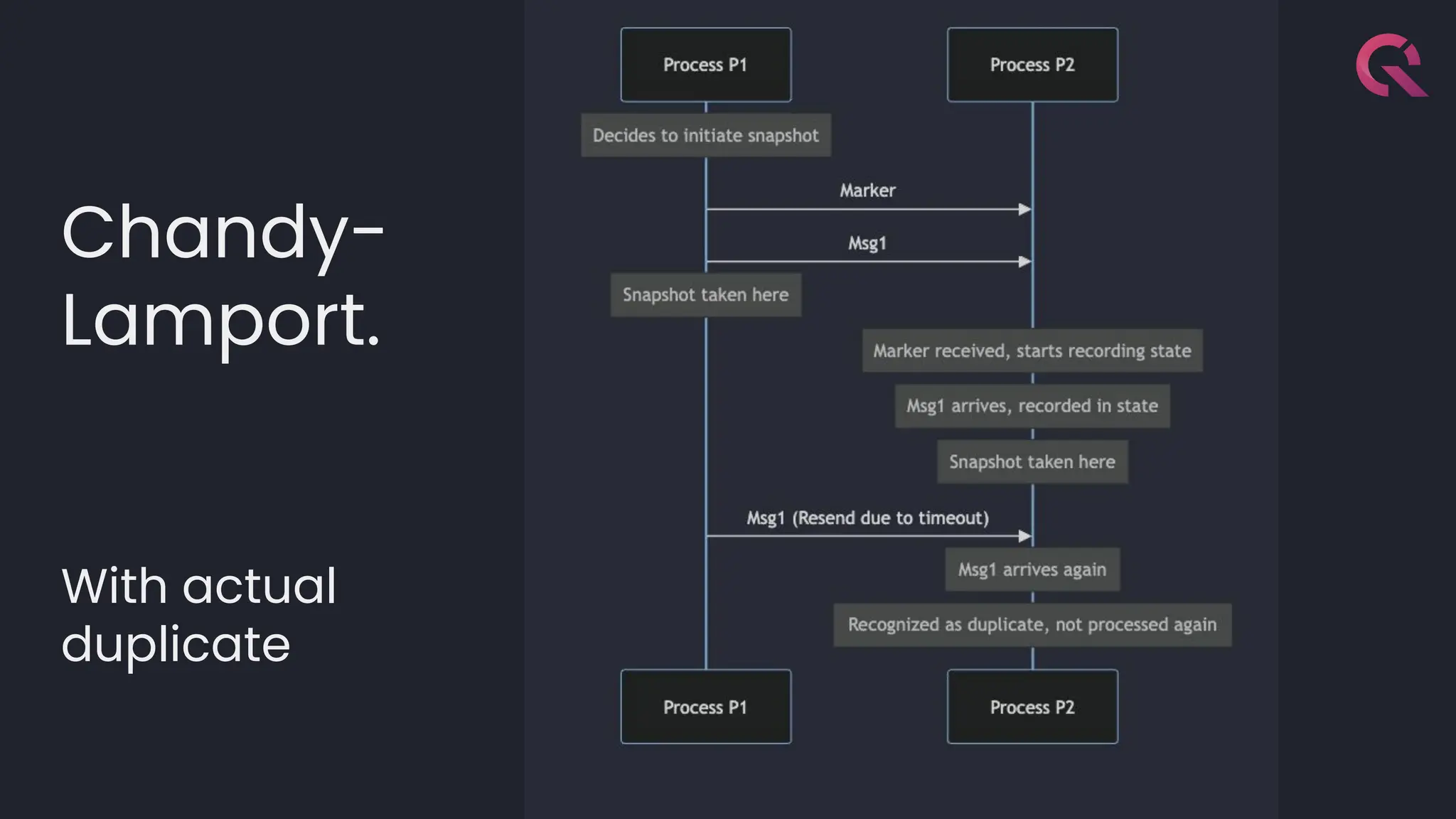
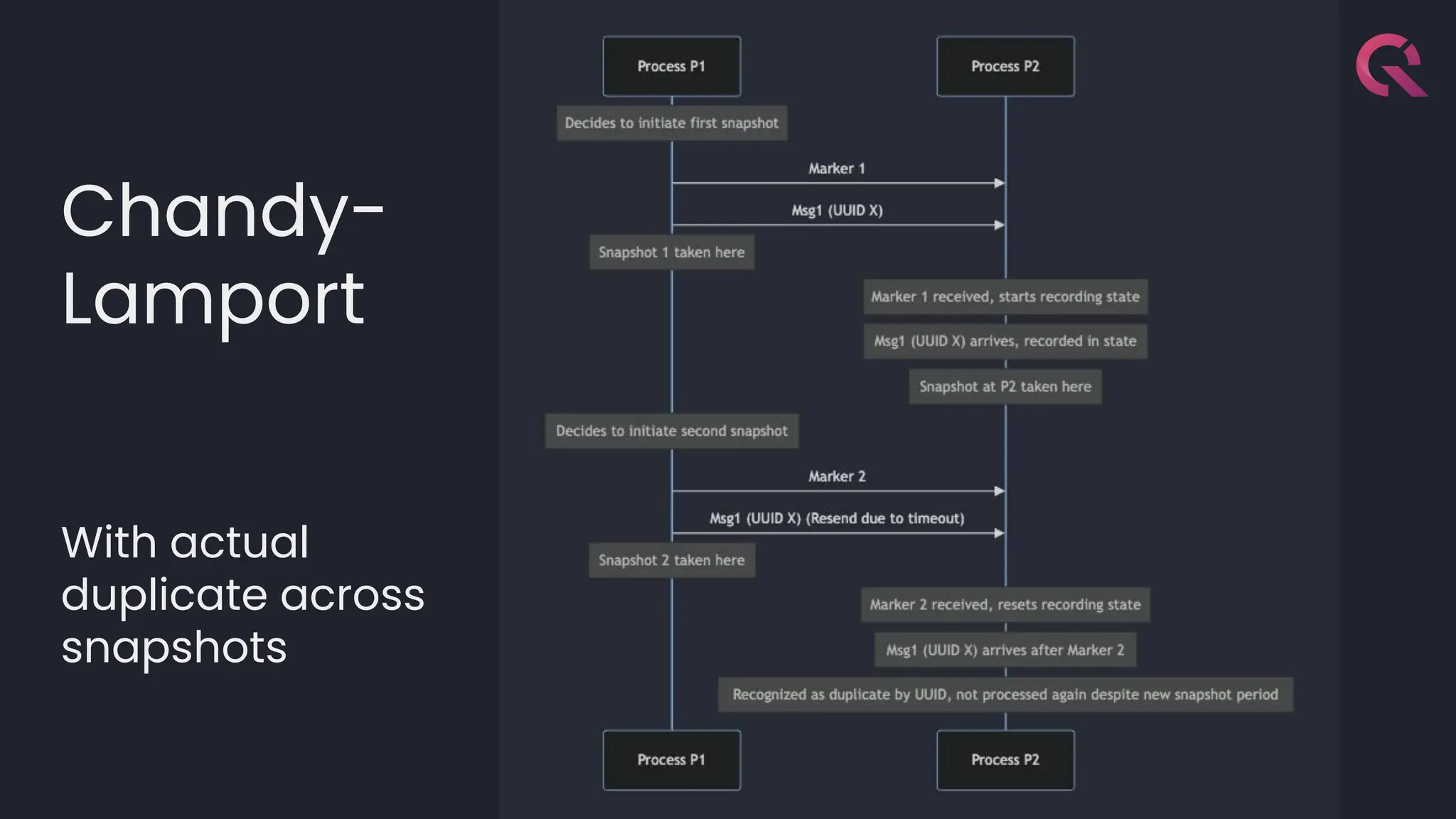

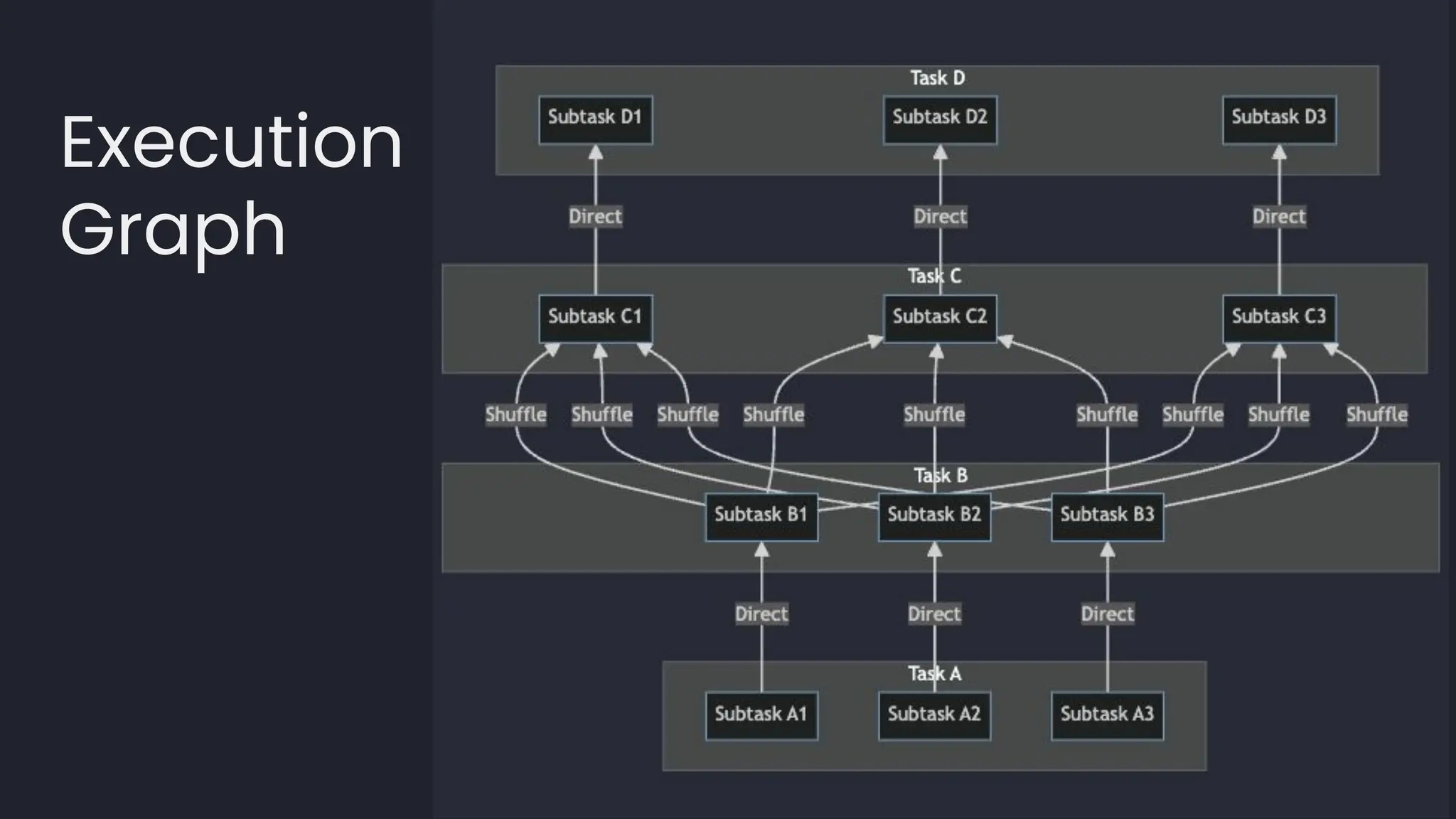
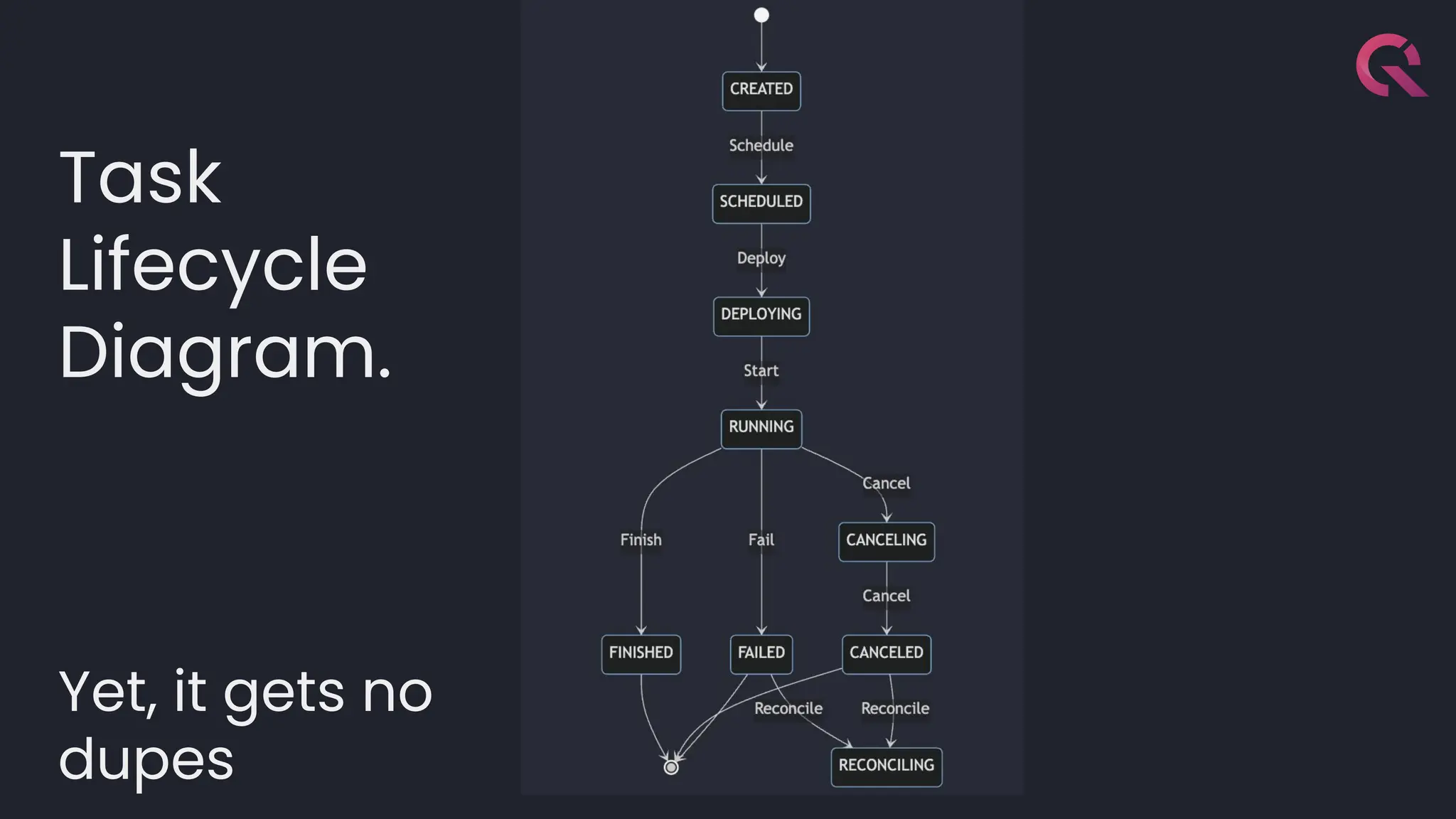


![template<typename LambdaDiff>
inline int64_t conventional_branching_search(const index_t *array, int64_t
count, int64_t value_index, LambdaDiff compare) {
int64_t low = 0;
int64_t high = count - 1;
while (low <= high) {
int64_t mid = (low + high) / 2;
auto diff = compare(value_index, array[mid].i);
if (diff == 0) {
return mid; // Found the element
} else if (diff < 0) {
high = mid - 1; // Search in the left half
} else {
low = mid + 1; // Search in the right half
}
}
return -1; // Element not found
}
Binary search by timestamp (not actual implementation)](https://image.slidesharecdn.com/questexactlyoncecommitconf-240704152526-ea886719/75/Como-hemos-implementado-semantica-de-Exactly-Once-en-nuestra-base-de-datos-de-alto-rendimiento-52-2048.jpg)

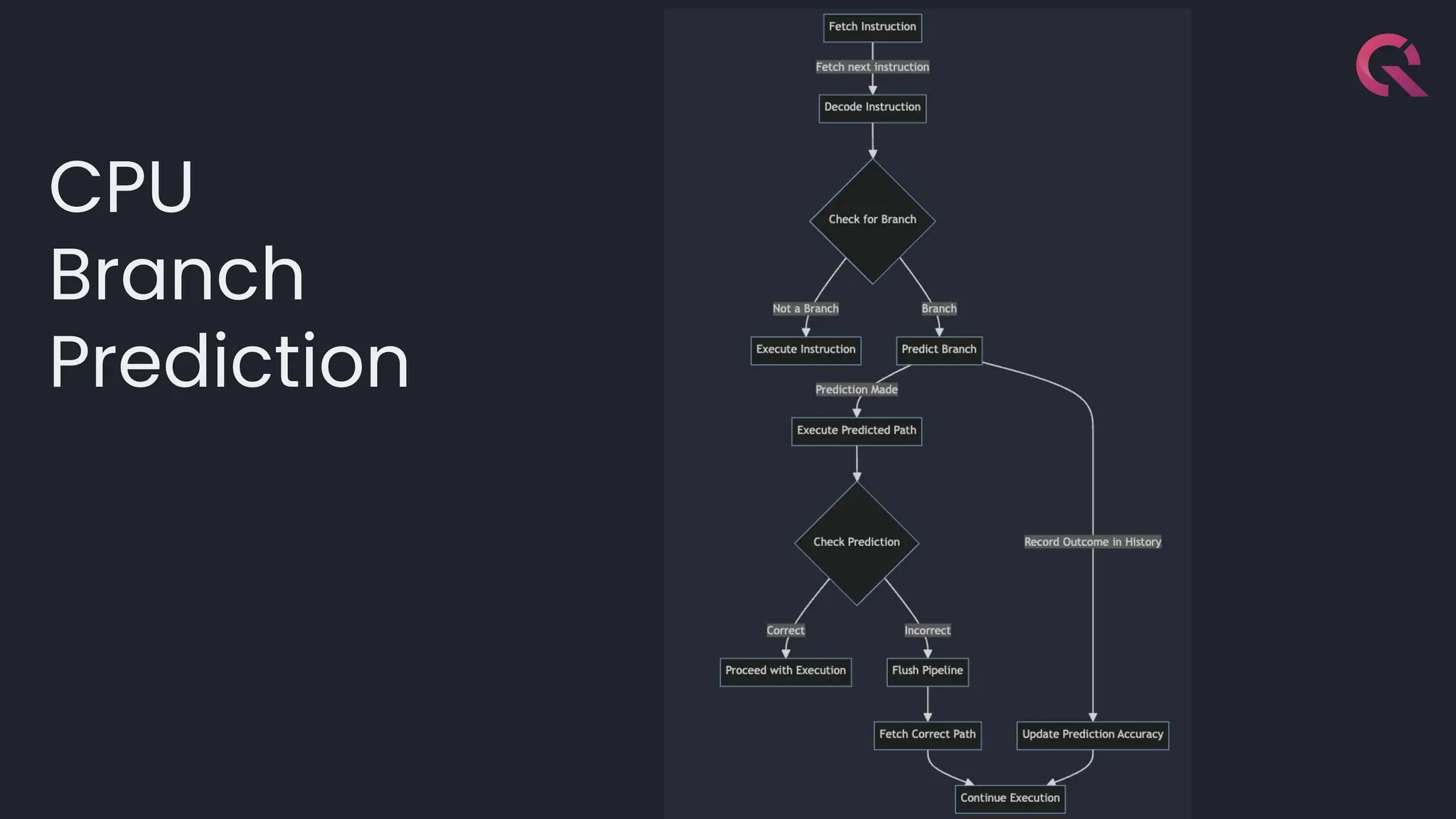
![template<typename LambdaDiff>
inline int64_t branch_free_search(const index_t *array, int64_t count, int64_t
value_index, LambdaDiff compare) {
const index_t *base = array;
int64_t n = count;
while (n > 1) {
int64_t half = n / 2;
MM_PREFETCH_T0(base + half / 2);
MM_PREFETCH_T0(base + half + half / 2);
auto diff = compare(value_index, base[half].i);
base = (diff > 0) ? base + half : base;
n -= half;
}
if (compare(value_index, base[0].i) == 0) {
return base - array;
}
if (base - array + 1 < count && compare(value_index, base[1].i) == 0) {
return base - array + 1;
}
return -1;
}
“Branch-free” Binary search by timestamp](https://image.slidesharecdn.com/questexactlyoncecommitconf-240704152526-ea886719/75/Como-hemos-implementado-semantica-de-Exactly-Once-en-nuestra-base-de-datos-de-alto-rendimiento-56-2048.jpg)






This document details how QuestDB implements 'exactly once' semantics in its high-performance database, addressing challenges associated with streaming data ingestion. It covers the architecture of QuestDB, including its optimized storage and deduplication processes, alongside technical details relevant for developers and potential users. The presentation also emphasizes the database's performance capabilities and open-source nature, alongside various use cases and examples related to data ingestion and processing.
















































![[DSC Europe 25] Ivan Peric - Intelligence Swarm Logic and Techno-Functional M...](https://cdn.slidesharecdn.com/ss_thumbnails/7my7c97fsduiccadgavw-2-251212103249-5a03f7c6-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Behzad Hosseini - AI Agents in the Wild: Deploying Models tha...](https://cdn.slidesharecdn.com/ss_thumbnails/3qtejajvsjqrzwfept2c-10-251212103250-7f2b1068-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DSC Europe 25] Miodrag Pesovic & Vladislav Radonjic - Federated Data Archite...](https://cdn.slidesharecdn.com/ss_thumbnails/gsbe3y5it5uhndi4e08e-1-251212103249-f1008e0c-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DSC Europe 25] Debmalya Biswas - Agentification: the art of transforming man...](https://cdn.slidesharecdn.com/ss_thumbnails/r5azlggvtqiaiiusrqdr-4-251212103249-5a12c89b-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Nikolay Burlutskiy - Best Practices for Building Enterprise M...](https://cdn.slidesharecdn.com/ss_thumbnails/uirvaiuvq8y1w8hzd9tx-7-251212103249-2619edb4-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Imai Jen-La Plante - The New Generation: AI and the Future of...](https://cdn.slidesharecdn.com/ss_thumbnails/kxi8t2l5rggivgcenyba-1-jenlaplante-dsc-251208152532-d1e076c2-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Marija Vlajkovic & Andrea Radonjanin - Integration of AI tool...](https://cdn.slidesharecdn.com/ss_thumbnails/qf1jrglttoc3bm8s3aop-final-integration-of-ai-tools-251208151905-394f3a6a-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DSC Europe 25] Hans Kleinsman - The Compliance Gearbox: How Tax Tech Mediate...](https://cdn.slidesharecdn.com/ss_thumbnails/dxdytie1toel0hr90bjs-2-251212103250-174fdbe7-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Milan Zdravkovic - The road less traveled in District Heating...](https://cdn.slidesharecdn.com/ss_thumbnails/nfaboniqwsz4ucyctnmy-2-milan-zdravkovic-dsc2025-the-road-less-traveled-in-district-heating-operation-251208151905-f56388a5-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DSC Europe 25] Milan Sekuloski - Data, Defence, and Development: Cybersecuri...](https://cdn.slidesharecdn.com/ss_thumbnails/dfrkwwx4qly6atqpbl4z-4-251209104645-c3d4b0ca-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Aleksandra Dragicevic - AI-Boosted Research in Healthcare: Fr...](https://cdn.slidesharecdn.com/ss_thumbnails/iqwngszurf2r7pi1lnnj-4-aleksandra-dragicevic-ad-dsc-europe-conference-20-251208151905-37c3238a-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DSC Europe 25] Sara Polak - The Archaeology of Innovation: AI as the Next Cr...](https://cdn.slidesharecdn.com/ss_thumbnails/7ecbscdnt8mlcuqbd2ln-2-sara-polak-ai-creative-industries-251208152533-aa1fcf54-thumbnail.jpg?width=640&height=640&fit=bounds)
