Downloaded 15 times

![Motivations and Task Overview
2
• Grammatical correction is important by itself
• Also as a part of Machine Translation or Speech Recognition
Correction of textual content written by English Learners.
I am new in android programming.
[to, at, for, …]
⇒ Rank candidate prepositions by their likelihood of being
correct in order to potentially replace the original.](https://image.slidesharecdn.com/cikm2014romanprokofyev-141103101713-conversion-gate01/75/CIKM14-Fixing-grammatical-errors-by-preposition-ranking-2-2048.jpg)


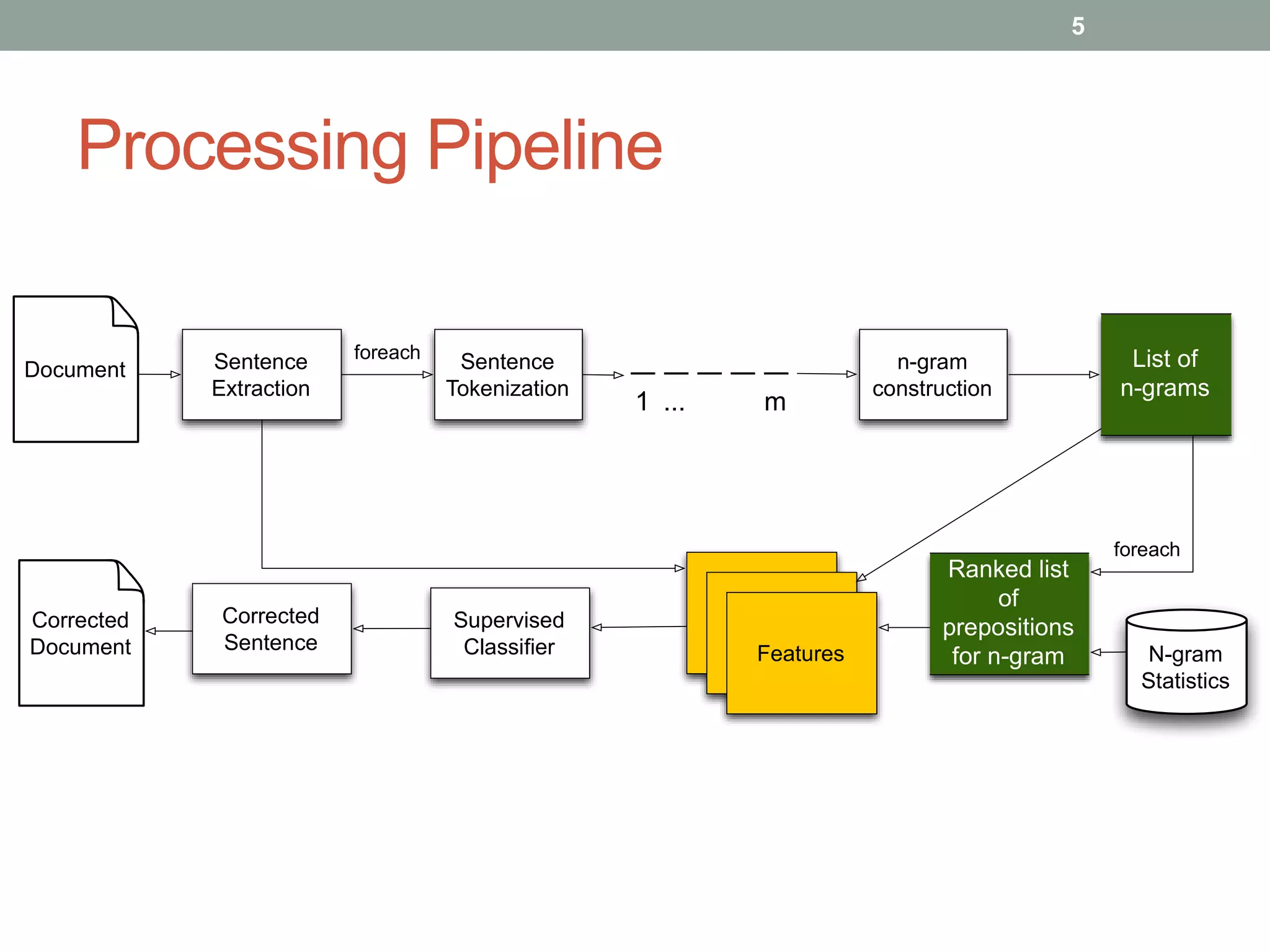


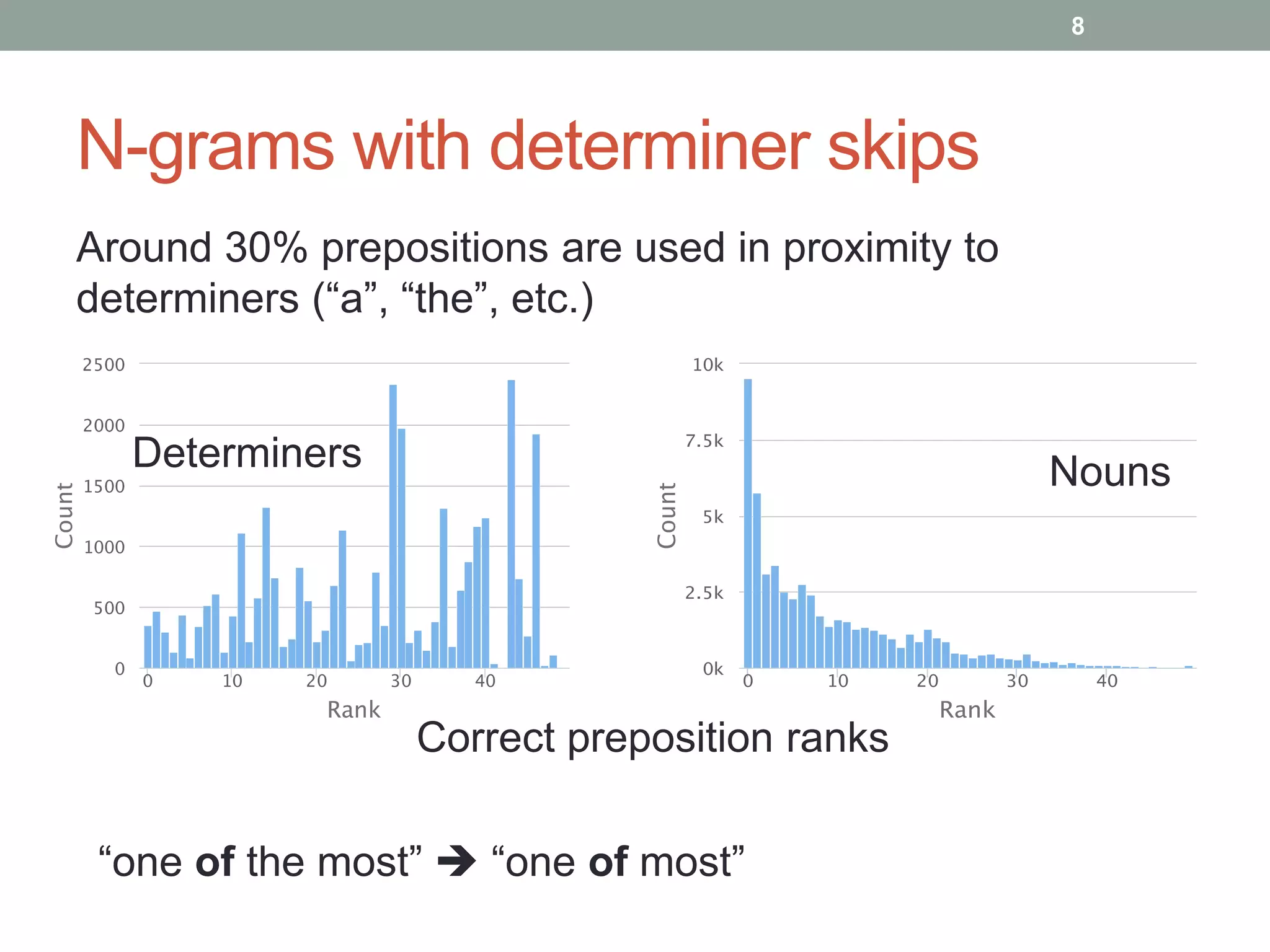

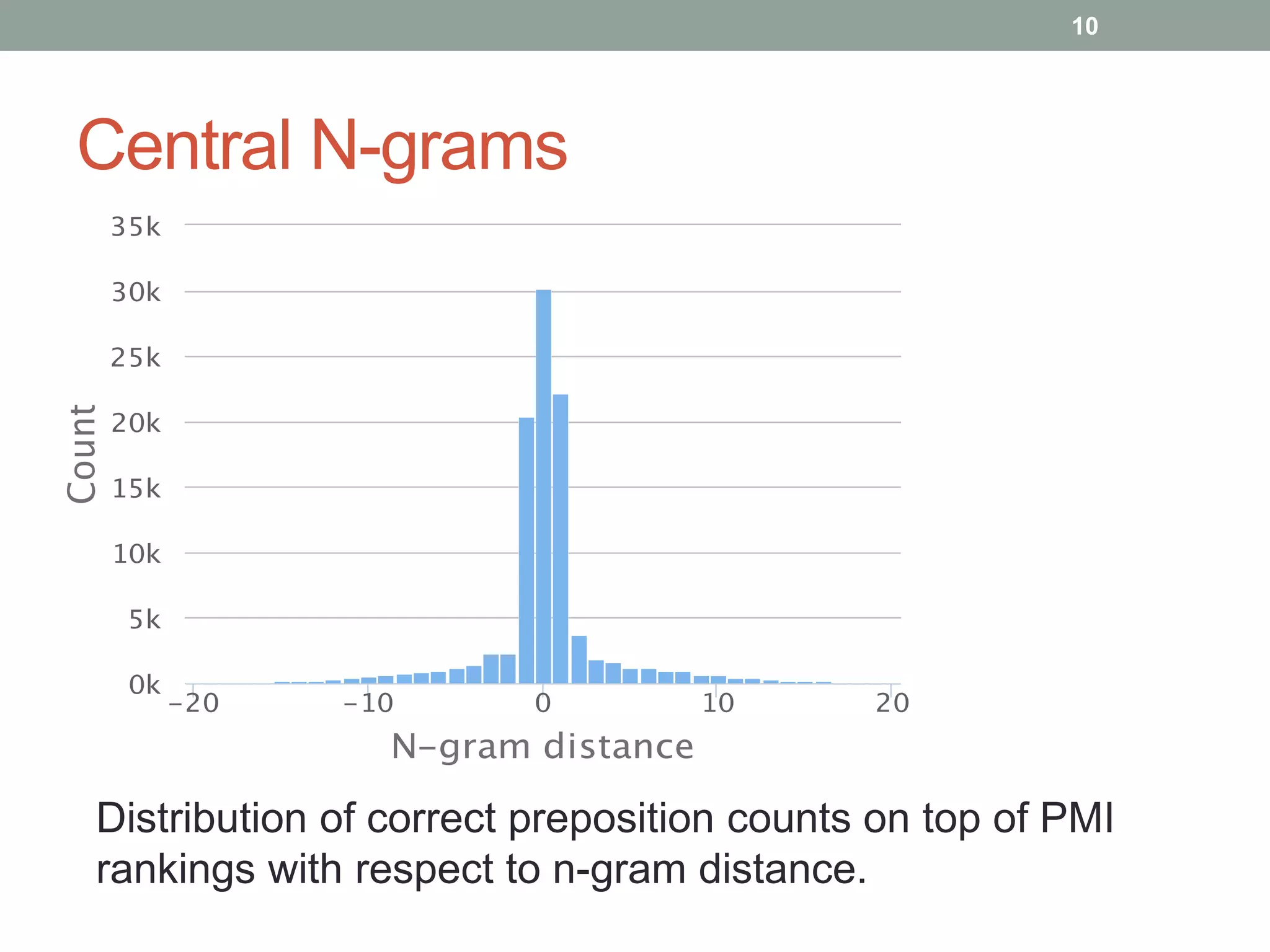





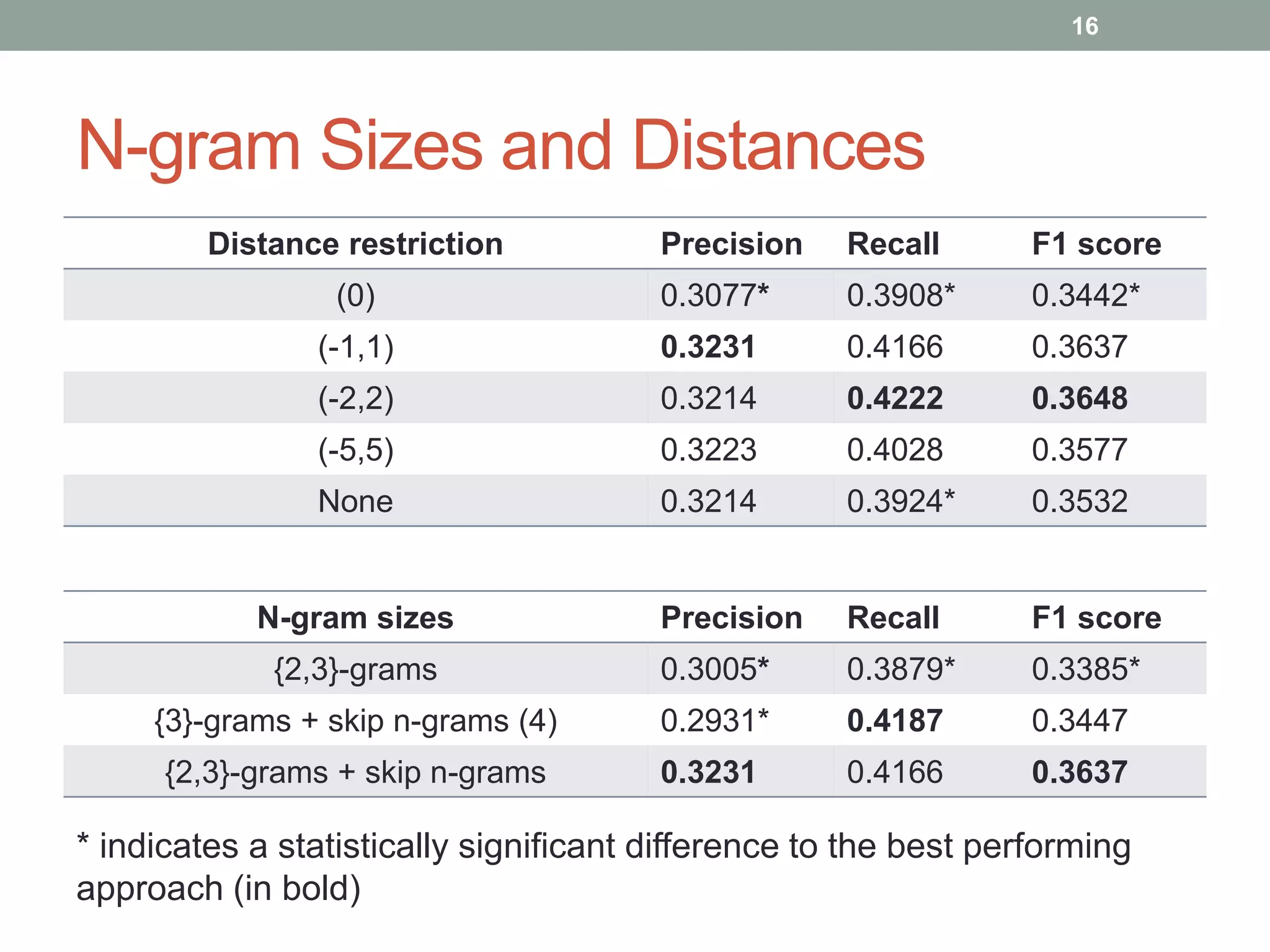
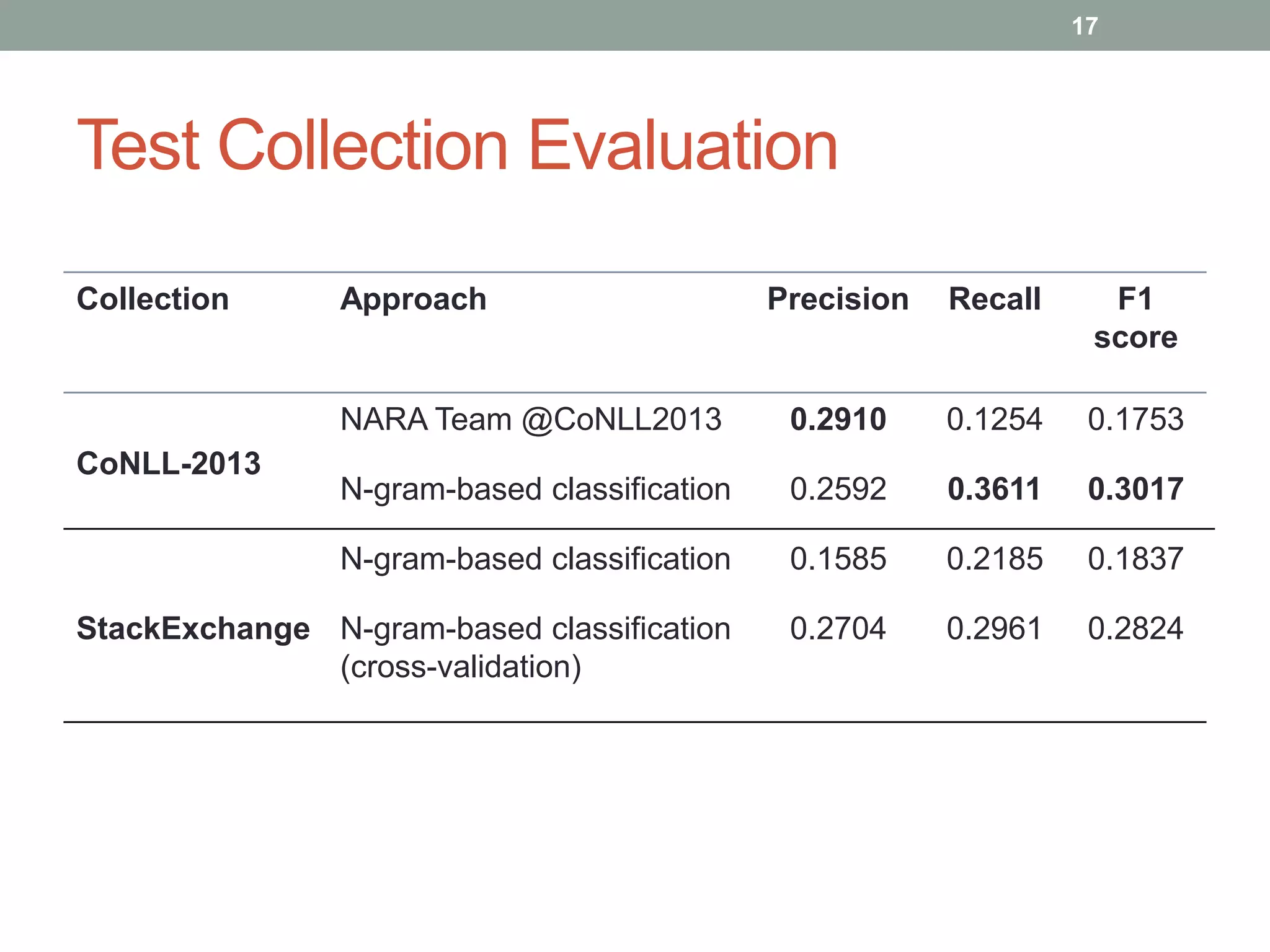





The document discusses a method for grammatical correction through ranking prepositions based on their likelihood of correctness, emphasizing its relevance in machine translation and speech recognition. It outlines the approach's processing pipeline, using n-grams and statistical measures like pointwise mutual information (PMI) to improve preposition selection. The proposed two-class classification algorithm outperforms existing methods, particularly when incorporating skip n-grams.























































































