Download to read offline



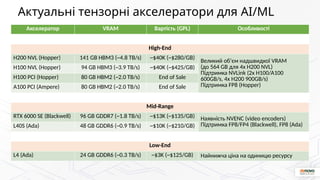





As an infrastructure provider, we often see that potential clients are somewhat disoriented when it comes to choosing the right accelerators. The technology evolves rapidly, and questions like “What’s out there?”, “How do these cards differ?”, and “Which ones are better?” are completely valid. But the selection criteria are far from simple. In this talk, we’ll explain key concepts such as compute-bound vs memory-bound models, arithmetic intensity, and model quantization—factors that are crucial when choosing the right hardware for your workload.

































