目錄
• Class 11指標
• Class 12 讀檔與寫檔
• Class 13 結構
• Class 14 前處理器的應用
• Class 15 random
• Class 16 記憶體控管
• Class 17 如何寫個一好的程式碼
• Class 18 料結構概念說明
• Class 19 演算法概念說明
• Class 20 總結
關於指標的說明(一)
•據國際 ISO9899:2011文件中,6.2.5 Types第20點底下:
• A pointer type may be derived from a function type or an object type,
called the referenced type. A pointer type describes an object whose
value provides a reference to an entity of the referenced type. A
pointer type derived from the referenced type T is sometimes called
"pointer to T ". The construction of a pointer type from a referenced
type is called "pointer type derivation". A pointer type is a complete
object type.
• 部份的重點翻譯:
• 指標型別:可以從"function"或"物件"的型別產生
• 指標型別:描述一個對象,指標值提供了"引用型別"的實體引用
FILE型別
•據國際 ISO9899:2011文件中,7.21.1 Introduction第2點前段:
• The types declared are size_t (described in 7.19);
FILE
• which is an object type capable of recording all the information
needed to control a stream, including its file position indicator, a
pointer to its associated buffer (if any), an error indicator that records
whether a read/write error has occurred, and an end-of-file indicator
that records whether the end of the file has been reached
• 即FILE類型:是能夠記錄控制流的所有信息的對像類型,包括其文件位
置指示符,指向其相關聯的緩衝器(如果有的話)的指標
講解 "fopen(...)"函數(一)
•據國際 ISO9899:2011文件中,7.21.5.3The fopen function:
•Synopsis
• #include <stdio.h> 引入標頭檔
• FILE*fopen(constchar*restrictfilename,constchar*restrictmode);使用方式
•Description
• The fopen function opens the file whose name is the string pointed to
by filename,and associates a stream with it.
• The argument mode points to a string. If the string is one of the
following, the file is open in the indicated mode. Otherwise, the
behavior is undefined
EOF的概念
•全名:End Of File
•據國際ISO9899:2011文件中,7.21.1 Introduction 第三點:
•EOF
• which expands to an integer constant expression, with type int and a
negative value, that is returned by several functions to indicate end-
of-file, that is, no more input from a stream;
• 它擴展為整數常量表達式,其類型為int和負值,由幾個函數返回以指示
文件結尾,即不再有來自流的輸入
• 就Visual Studio中C程式EOF被定義為 -1
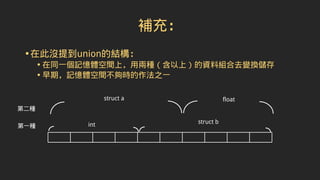
結構解說(三)
•據國際 ISO9899:2011文件中,6.5.2.3 Structureand union
members:
• The first operand of the . operator shall have an atomic, qualified, or
unqualified structure or union type, and the second operand shall
name a member of that type.
• 即:在.運算子前面的第一個需合格,.運算子後面的變數將命名該類型的
成員
※此處的.是指成員運算子
rand function(一)
•據國際 ISO9899:2011文件中,7.22.2.1The rand function:
• Synopsis:
• #include <stdlib.h> 引入標頭檔
• int rand(void); 使用方式
• Description:
• The rand function computes a sequence of pseudo-random integers in the
range 0 to RAND_MAX.
• The rand function is not required to avoid data races with other calls to pseudo-
random sequence generation functions. The implementation shall behave as if
no library function calls the rand function.
• 描述 即:
• 其大小範圍位於 0 to RAND_MAX
• 不需要rand函數來避免與其他調用偽隨機序列生成函數的數據競爭。 實現應該像
沒有庫函數調用rand函數一樣。
67.
rand function(二)
•續上頁7.22.2.1 Therand function::
• Returns
• The rand function returns a pseudo-random
• integer.Environmental limits
• The value of the RAND_MAX macro shall be at least 32767.
• 回傳:
• 偽隨機整數(因為該亂數是由亂數表取出的,所以算是偽亂數,接近亂數而非亂數)
• 範圍:
• RAND_MAX巨集定義亂數最大值的底限要在32767以上
srand function
•據國際 ISO9899:2011文件中,7.22.2.2The srand function:
• Synopsis
• #include <stdlib.h> 引入標頭檔
• void srand(unsigned int seed); 使用方式
• Description
• The srand function uses the argument as a seed for a new sequence of pseudo-
random numbers to be returned by subsequent calls to rand. If srand is then
called with the same seed value, the sequence of pseudo-random numbers shall
be repeated. If rand is called before any calls to srand have been made, the
same sequence shall be generated as when srand is first called with a seed
value of 1.
• srand function是用來設定亂數的"種子",當設定srand(種子)時會決定亂數表的資
料;當設定用的"種子"相同時,產生的亂數表資料也會相同
70.
time function(一)
•據國際 ISO9899:2011文件中,7.27.2.4The time function:
• Synopsis
• #include <time.h> 引入標頭檔
• time_t time(time_t *timer); 使用方式
• Description
• The time function determines the current calendar time. The encoding of the
value is unspecified.
• Returns
• The time function returns the implementation’s best approximation to the
current calendar time. The value (time_t)(-1) is returned if the calendar time is
not available. If timer is not a null pointer, the return value is also assigned to
the object it points to.
malloc 函數(一)
•據國際 ISO9899:2011文件中,7.22.3.4The malloc function:
• Synopsis
• #include <stdlib.h> 引入標頭檔
• void *malloc(size_t size); 呼叫函數
• Description
• The malloc function allocates space for an object whose size is specified by size
and whose value is indeterminate.
• Returns
• The malloc function returns either a null pointer or a pointer to the allocated
space.
free 函數(一)
•據國際 ISO9899:2011文件中,7.22.3.3The free function:
• Synopsis
• #include <stdlib.h> 引入標頭檔
• void free(void *ptr); 呼叫函數
• Description
• The free function causes the space pointed to by ptr to be deallocated, that is,
made available for further allocation. If ptr is a null pointer, no action occurs.
Otherwise, if the argument does not match a pointer earlier returned by a
memory management function, or if the space has been deallocated by a call to
free or realloc, the behavior is undefined.
• Returns
• The free function returns no value.










































![結構
#include<stdio.h>
int main(void){
struct my_test {
int a[10] ;
char b[8] ;
int c ;
int d ;
}M,N ;
M.c = 10;
N.c = 20;](https://image.slidesharecdn.com/exc1-170823073149/85/C-Ex-46-320.jpg)


![結構另一種寫法
#include<stdio.h>
int main(void){
struct my_test {
int a[10] ;
char b[8] ;
int c ;
int d ;
} ;
my_test my_T;
my_T M,N;
M.c = 10;
N.c = 20;](https://image.slidesharecdn.com/exc1-170823073149/85/C-Ex-49-320.jpg)

















































![針對於二維陣列
•對於二維陣列來說,因為結構略微複雜,也可以寫的明確表以達
出二維陣列的內容:
• int array[3][3] = {{1,2,3},{4,5,6},{7,8,9}};
• int array[3][3] = {
{1, 2, 3} ,
{4, 5, 6} ,
{7 ,8, 9}
};](https://image.slidesharecdn.com/exc1-170823073149/85/C-Ex-102-320.jpg)







![結構(struct)
•多種型態組成:
int、char、float、double、struct
*int、*char、*float、*double、*struct
Array[]......
struct](https://image.slidesharecdn.com/exc1-170823073149/85/C-Ex-110-320.jpg)