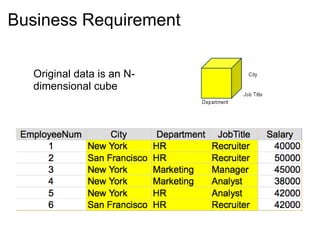
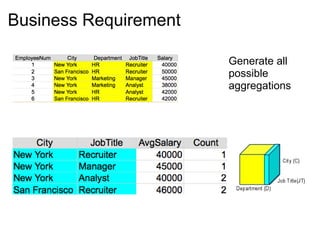
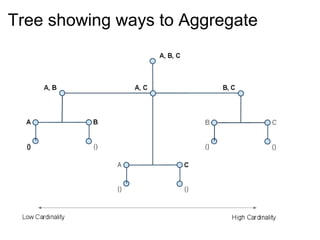
Cascalog is an internal DSL for Clojure that allows defining MapReduce workflows for Hadoop. It provides helper functions, a way to define custom functions analogous to UDFs, and functions to programmatically generate all possible data aggregations from an input based on business requirements. The workflows can be unit tested and executed on Hadoop. Cascalog abstracts away lower-level MapReduce details and allows defining the entire workflow within a single language.










![Helper Functions
(def DIMS ["?dept" "?country" "?city" "?jobtitle" "?manager" "?function"])
;All sub-lists generated by removing one member.
(defn sublists
([s] (sublists [] s))
([left right]
(let [left2 (conj (vec left) (first right)) right2 (rest right)]
(cons (concat left right2) (if (seq right2) (sublists left2 right2) [])))))
;Create key with only the requested dims. Other dims are replaced with *.
(defn key-for-dims
([dims key-str] (str-join "," (key-for-dims dims (.split key-str ",") 0)))
([dims key-split idx] (if (>= idx (count key-split)) []
(cons (if (some #{(nth DIMS idx)} dims) (nth key-split idx) "*")
(key-for-dims dims key-split (+ idx 1))))))
• Pure functions
• Immutable data types
• Recursion](https://image.slidesharecdn.com/cascaloginternaldslpreso-101104124654-phpapp01/85/Cascalog-internal-dsl_preso-13-320.jpg)
![;Computes an average from a set of other averages
(def grpavg (<- [!avg !cnt :> !newavg !newcnt]
(* !avg !cnt :> !s) (sum !s :> !total)
(sum !cnt :> !newcnt)
(div !total !newcnt :> !newavg)))
Cascalog's Analog to the UDF
• Same syntax
• No interface to implement
• Same source file (unless you want to share it)](https://image.slidesharecdn.com/cascaloginternaldslpreso-101104124654-phpapp01/85/Cascalog-internal-dsl_preso-14-320.jpg)
![;Computes an average from a set of other averages
(def grpavg (<- [!avg !cnt :> !newavg !newcnt]
(* !avg !cnt :> !s) (sum !s :> !total)
(sum !cnt :> !newcnt)
(div !total !newcnt :> !newavg)))
Cascalog's Analog to the UDF
• Same syntax
• No interface to implement
• Same source file (unless you want to share it)](https://image.slidesharecdn.com/cascaloginternaldslpreso-101104124654-phpapp01/85/Cascalog-internal-dsl_preso-15-320.jpg)
![Cascalog's Analog to the UDF
• Same syntax
• No interface to implement
• Same source file (unless you want to share it)
;Computes an average from a set of other averages
(def grpavg (<- [!avg !cnt :> !newavg !newcnt]
(* !avg !cnt :> !s) (sum !s :> !total)
(sum !cnt :> !newcnt)
(div !total !newcnt :> !newavg)))](https://image.slidesharecdn.com/cascaloginternaldslpreso-101104124654-phpapp01/85/Cascalog-internal-dsl_preso-16-320.jpg)
![Core Process
;Creates a query, where parent is the source, and the dims list is used
;to construct the output key. The other metrics are rolled up.
(defn make-qry [dims parent]
(<- [?key ?avg ?cnt]
(parent ?pkey ?pavg ?pcnt)
(key-for-dims dims ?pkey :> ?key)
(grpavg ?pavg ?pcnt :> ?avg ?cnt)))
;Given an initial src and a full list of dimensions; return a map of each
;subset of dims to a query that implements a rollup along that set of dims.
(defn generate-query-tree [src dims]
(let [query (if (= dims DIMS) (basic-qry src) (make-qry dims src))
gqt-with-src (partial generate-query-tree query)]
(if (empty? dims)
{dims query}
(assoc (apply merge (map gqt-with-src (sublists dims))) dims query))))](https://image.slidesharecdn.com/cascaloginternaldslpreso-101104124654-phpapp01/85/Cascalog-internal-dsl_preso-17-320.jpg)
![Unit Testing Cascalog
(deftest test-make-qry
(with-tmp-sources [src [["a,b,c,d,e1,f1" 200 50000]
["a,b,c,d,e1,f2" 100 20000]
["a,b,c,d,e3,f3" 300 40000]]]
(test?- [["a,b,c,d,e1,*" 300 40000]
["a,b,c,d,e3,*" 300 40000]]
(make-qry (choose DIMS [0 1 2 3 4]) src))
(test?- [["a,*,*,*,*,*" 600 40000]]
(make-qry (choose DIMS [0]) src))))
• sample input in green
• expected result in orange](https://image.slidesharecdn.com/cascaloginternaldslpreso-101104124654-phpapp01/85/Cascalog-internal-dsl_preso-18-320.jpg)
![Executing the Queries
For completeness, here is the code that executes all the queries.
(defn -main [input-dir output-dir]
(let [source (get-data (hfs-hadoop-seqfile input-dir))
queries (vals (generate-query-tree source DIMS))]
(?- (hfs-textline-replace output-dir) queries)))](https://image.slidesharecdn.com/cascaloginternaldslpreso-101104124654-phpapp01/85/Cascalog-internal-dsl_preso-19-320.jpg)












































































































