Downloaded 39 times






![CAP Theorem Fallout
4/6/2016 T-MobileConfidential10
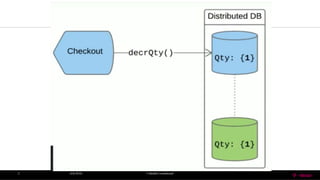
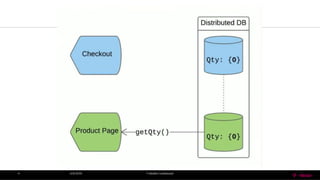
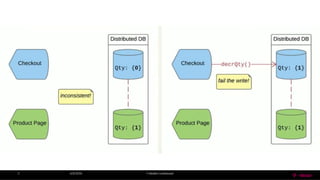
• Since partition-tolerance is essential / inevitable in today’s cloud computing systems,
CAP theorem implies that a system has to choose between consistency and
availability.
• Cassandra (AP System, Sacrifice Consistency)
• Eventual (Weak) consistency , Availability and Partition –Tolerance.
• Traditional RDBMSs (CA System, Partitions can’t happen [single node])
• Strong consistency over availability under a partition.](https://image.slidesharecdn.com/9686baa2-7e4d-473d-94f2-023a45f16118-161020002321/85/CAP-Theorem-10-320.jpg)
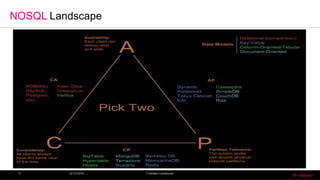






The CAP Theorem states that it is impossible for a distributed computer system to simultaneously provide consistency, availability, and partition tolerance. A system must choose between two of these three properties. Consistency means all nodes see the same data at the same time. Availability means every request receives a response without fail. Partition tolerance means the system continues operating despite network failures. Most distributed databases, like Cassandra, choose availability and partition tolerance over consistency and implement eventual consistency.























































