The Evolution ofAI
Communication
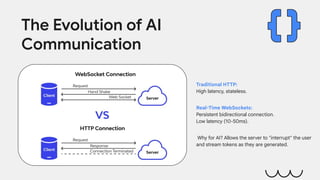
Traditional HTTP:
High latency, stateless.
Real-Time WebSockets:
Persistent bidirectional connection.
Low latency (10-50ms).
Why for AI? Allows the server to "interrupt" the user
and stream tokens as they are generated.
3.
Key Features
🗣 Voice-First:Natural speech with real-time transcription.
📸 Visual Input: Camera analysis for landmarks (e.g., Sigiriya).
🔍 Live Data: Real-time weather and Google Search integration.
🌦 Tool Calling: Auto-fetching weather for cities like Colombo or Kandy.
Project
Sri Lanka Tourist Guide Agent.
What We Are
Building Today?
4.
The Engine (Gemini& ADK)
Gemini Model Ecosystem
1. Gemini Pro: Complex reasoning, coding, deep analysis.
2. Gemini Flash: Speed-optimized, high throughput. Perfect for real-time agents.
3. Gemini Nano: On-device, privacy-first (Edge).
4. Our Choice: gemini-2.5-flash-native-audio
5.
Protocol Showdown:
WebSockets vs.WebRTC
WebSocket (Our Choice):
● Architecture: Client ↔ Server (TCP).
○ Latency: Low (10-50ms).
○ Why for AI? Excellent for streaming audio chunks
and tokens. It simplifies state management and is
natively supported by most AI backends.
○ The "Why": We need a reliable pipe to the server
(where the Brain is), not a peer-to-peer pipe to
another user.
WebRTC (The Alternative):
● Architecture: Peer-to-Peer (UDP) + Signaling Server.
○ Latency: Ultra-low (<10ms).
○ Complexity: High. Requires ICE/STUN/TURN
servers for NAT traversal and firewall penetration.
○ Use Case: Human-to-Human video conferencing
(Zoom/Meet) where sub-millisecond sync matters
more than server processing.
6.
The Engine (Gemini& ADK)
The Secret Sauce: Native Audio
● Half-Cascade (Old Way):
○ Input → Speech-to-Text → LLM → Text-to-Speech → Audio.
○ 🔴 High Latency (~2s), loss of emotion/tone.
● Native Audio (New Way):
○ Audio Input → Gemini Model → Audio Output.
○ 🟢 Low Latency (~500ms).
○ 🟢 Preserves prosody, emotion, and allows natural interruptions.
7.
The Engine (Gemini& ADK)
Google ADK (Agent Development Kit)
● What is it?
A Python framework to orchestrate real-time AI agents.
● Key Responsibilities:
○ Manages WebSocket connections.
○ Handles "Tool Calling" (routing logic to code).
○ Manages Session State and History.
8.
Architecture & Flow
High-LevelSystem Architecture
● Frontend (Client): Captures Audio (PCM 16kHz).
● FastAPI Server: Upgrades HTTP to WebSocket.
● LiveRequestQueue: Buffers audio/text for the model.
● ADK Runner: Manages the bi-directional stream with Gemini API.
9.
Architecture & Flow
The"Tool Calling" Loop
● Concept: The Model decides when to run code.
● Example Flow:
○ User: "What's the weather in Galle?"
○ Model: "I need get_current_weather(city='Galle')."
○ System: Executes Python function, returns {temp: 28, condition: 'Sunny'}.
○ Model: "It is 28°C and sunny in Galle."
def get_current_weather(city: str)-> dict:
"""Get current weather for a city using OpenWeather API.
Args: city: City name (e.g. "Colombo")
"""
# ... External API Call ...
return {"temp": 28, "unit": "C", "condition": "Cloudy"}
Hands-On
Implementation
(CodeLab)
Defining Custom Tools
14.
Advanced & Production
HandlingInterruptions
● The Challenge: User speaks while the agent is still talking.
● The Solution:
○ Model detects voice input via interrupted event.
○ Client immediately stops audio playback (clears buffer).
○ Agent halts generation and processes the new input.
● Benefit: Makes the conversation feel like a real human interaction, not a walkie-talkie
exchange.
15.
Advanced & Production
Observabilitywith LangFuse
● Why monitor? Black box decisions, token costs, and latency bottlenecks.
● What we track:
○ Full execution traces (User input → Tool Call → Response).
○ Token usage and cost per conversation.
○ Latency (P50, P99).
16.
Advanced & Production
DeploymentConsiderations
● Telephony: Can integrate with Twilio/SIP for phone-based agents (8kHz audio requires
resampling).
● Cost Control:
○ Use Flash over Pro (3-4x cheaper).
○ Cache frequent tool results (e.g., weather doesn't change every second).
○ Implement token budgets.
17.
The "Enterprise Architect"View
Scaling for Production
● State Management:
○ Move from InMemorySessionService to a persistent database (PostgreSQL) to save
conversation history across server restarts.
● Caching Layer:
○ Use Redis to cache frequent tool results (e.g., weather data doesn't change every
second) to save latency and API costs.
● Load Balancing:
○ Deploy multiple FastAPI/ADK containers behind a Load Balancer.
○ Critical: Ensure "Sticky Sessions" are enabled if you aren't using a shared session
store (though shared storage is best).
18.
Interactive Workshop Challenges
NowIt's Your Turn (Challenges)
● Level 1: The Currency Converter
○ Task: Add a new tool get_exchange_rate(from_currency, to_currency).
○ Goal: Ask the agent "How much is 100 USD in Sri Lankan Rupees?" and get a real
answer.
● Level 2: Rate Limiting
○ Goal: Restrict users to 5 requests per minute and return a graceful "Please wait"
message.










![# Initialize Agent with Tools
agent = Agent(
name="sri_lanka_tourist_guide",
model="gemini-2.5-flash-native-audio-preview-12-2025",
tools=[google_search, get_current_weather],
instruction="You are an enthusiastic Sri Lankan tourist
guide..."
)
# Initialize Runner
runner = Runner(app_name="sri-lanka-guide", agent=agent, ...)
Hands-On
Implementation
(CodeLab)
Phase 1 - Initialization](https://image.slidesharecdn.com/buildingvoiceagentswithadk-260114194726-867ec185/85/Building-Voice-Agents-with-Google-Agent-Development-Kit-11-320.jpg)
![@app.websocket("/ws/{user_id}/{session_id}")
async def websocket_endpoint(websocket, user_id, session_id):
await websocket.accept()
# Configuration for Bidirectional Streaming
run_config = RunConfig(
streaming_mode=StreamingMode.BIDI,
response_modalities=["AUDIO"],
proactivity=types.ProactivityConfig(proactive_audio=True)
)
Hands-On
Implementation
(CodeLab)
Phase 2 - The WebSocket
Endpoint](https://image.slidesharecdn.com/buildingvoiceagentswithadk-260114194726-867ec185/85/Building-Voice-Agents-with-Google-Agent-Development-Kit-12-320.jpg)






























![[WSO2Con EU 2017] Building Next Generation Banking Middleware at ING: The Rol...](https://cdn.slidesharecdn.com/ss_thumbnails/ingmodelbank-final-171107154840-thumbnail.jpg?width=640&height=640&fit=bounds)






























