Downloaded 310 times




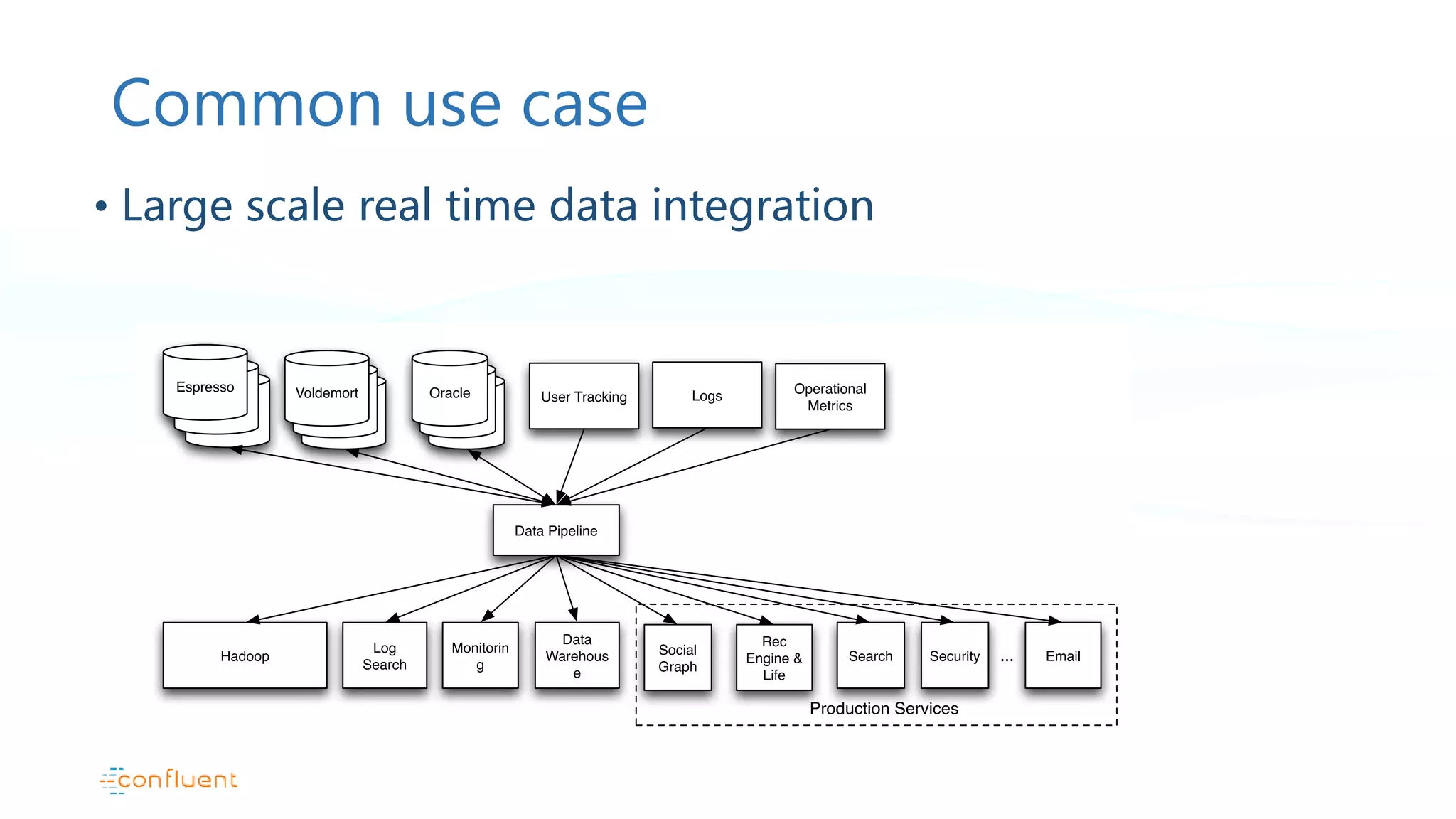



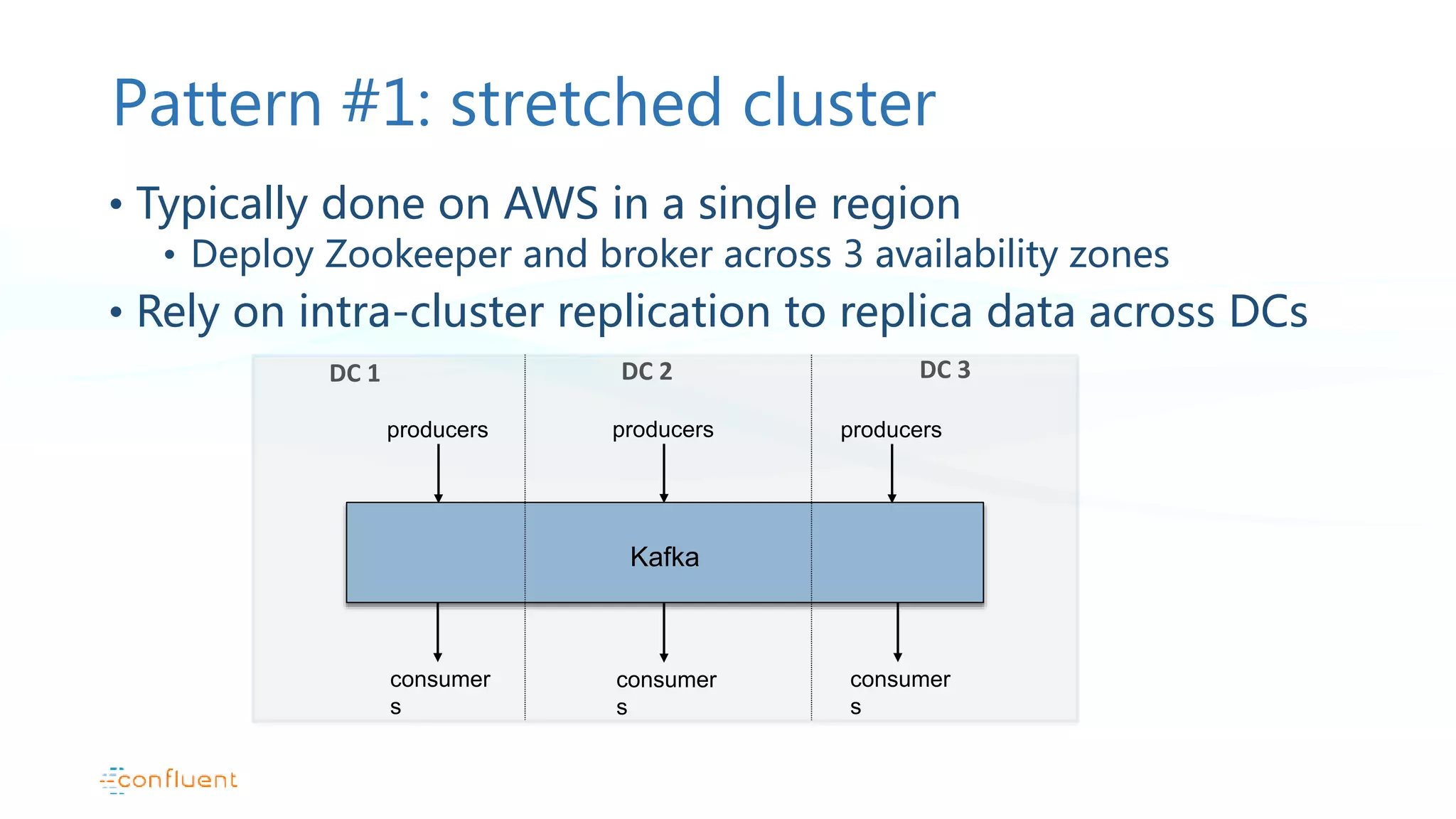
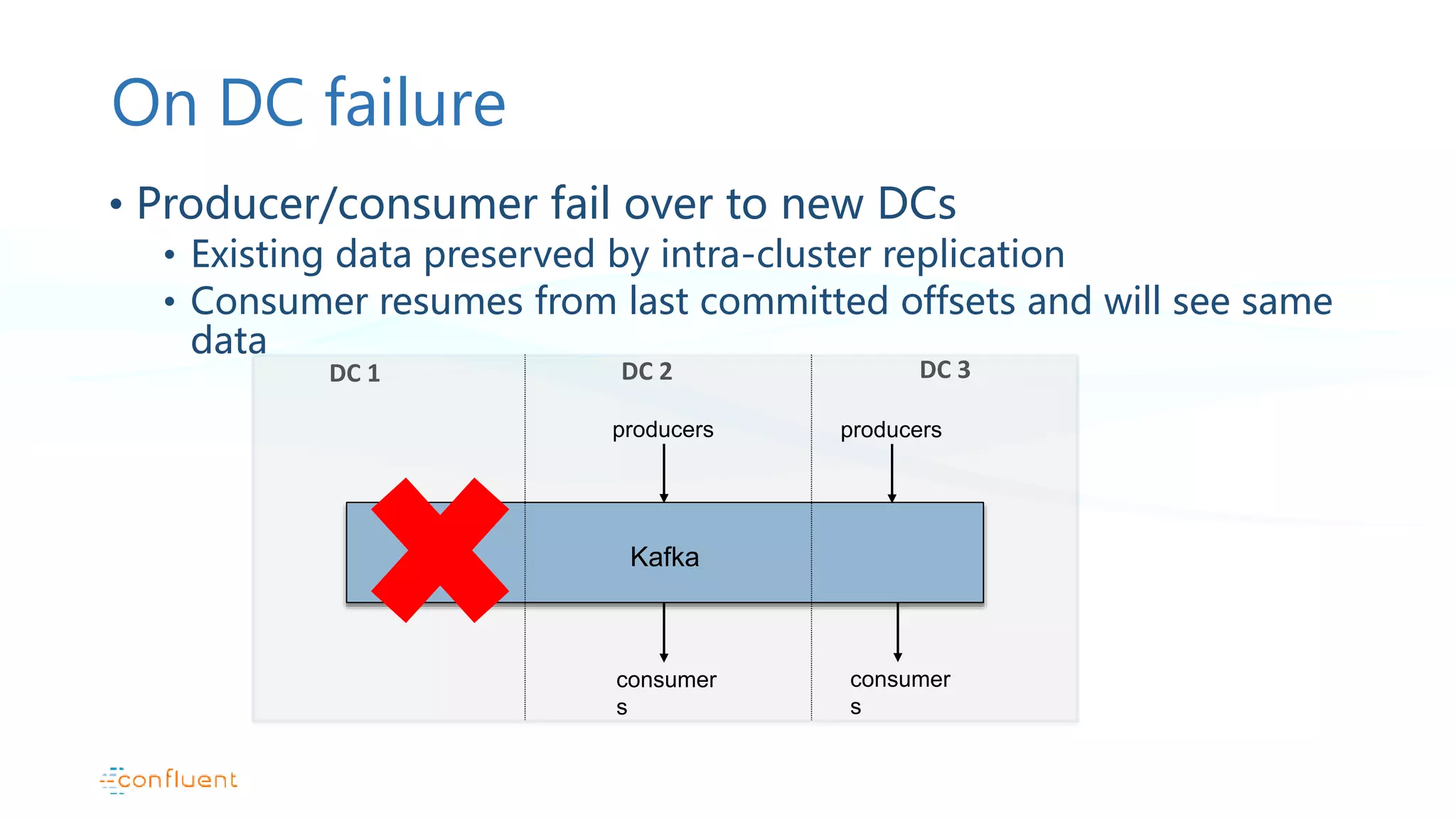
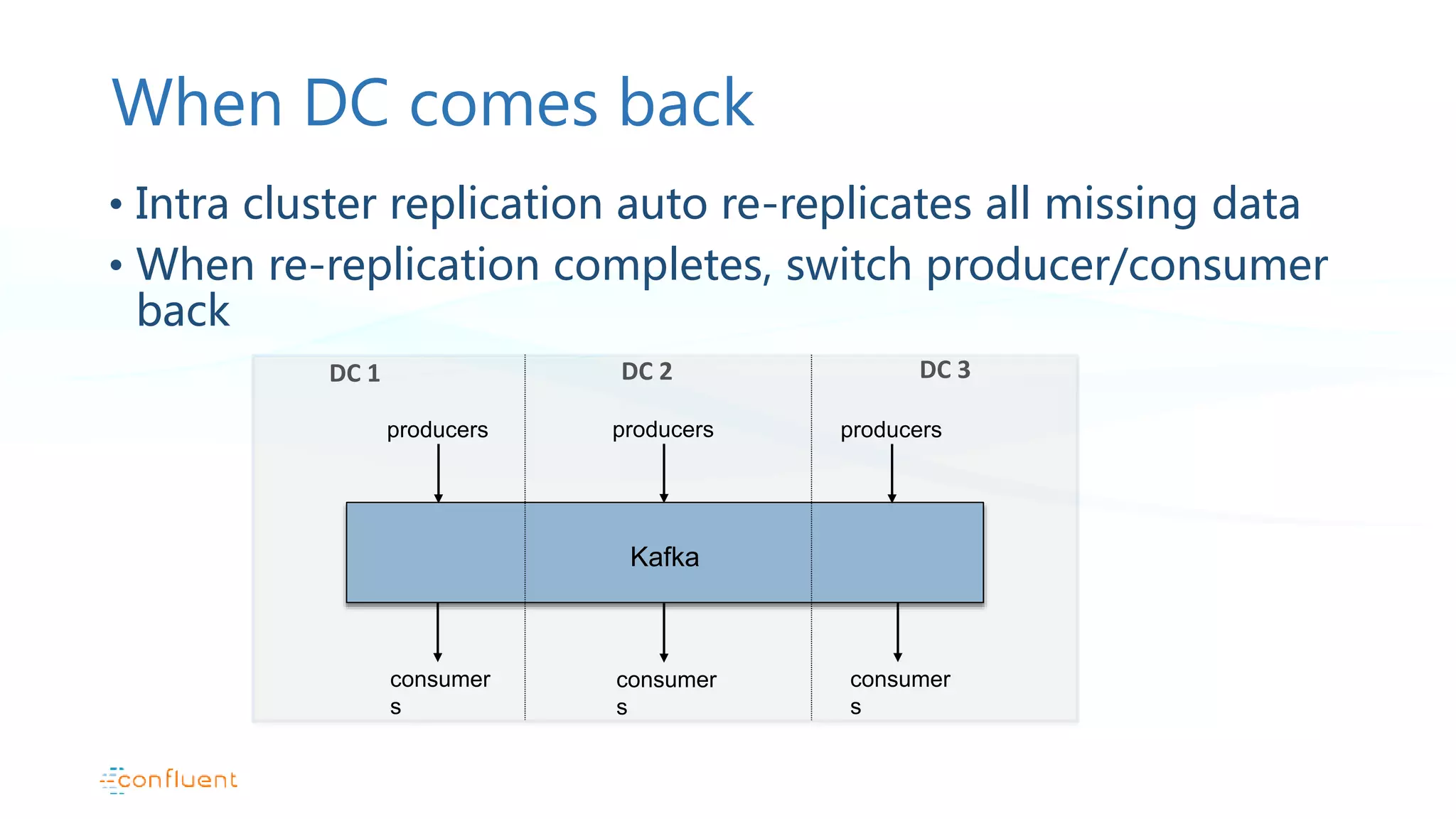

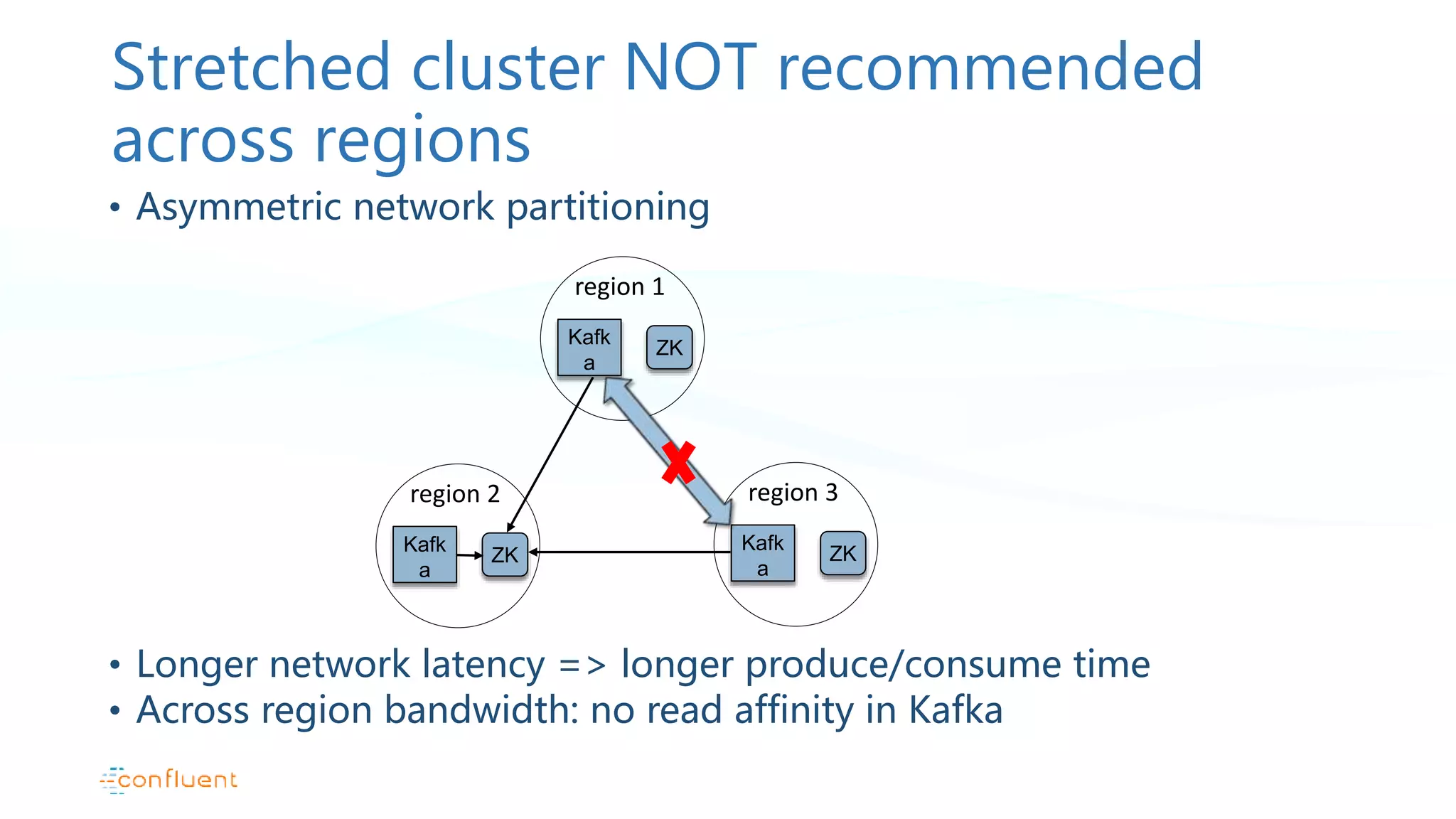
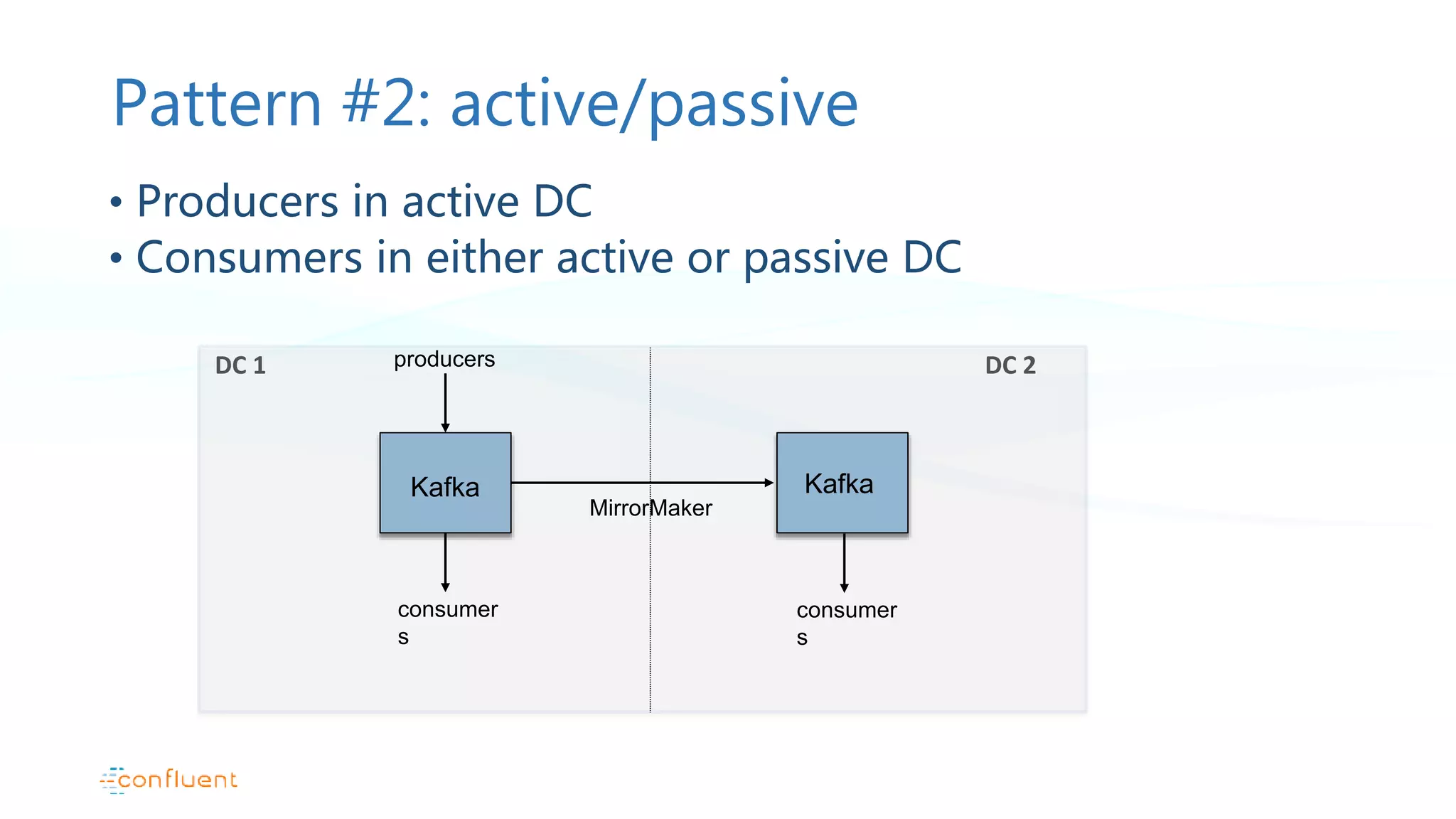

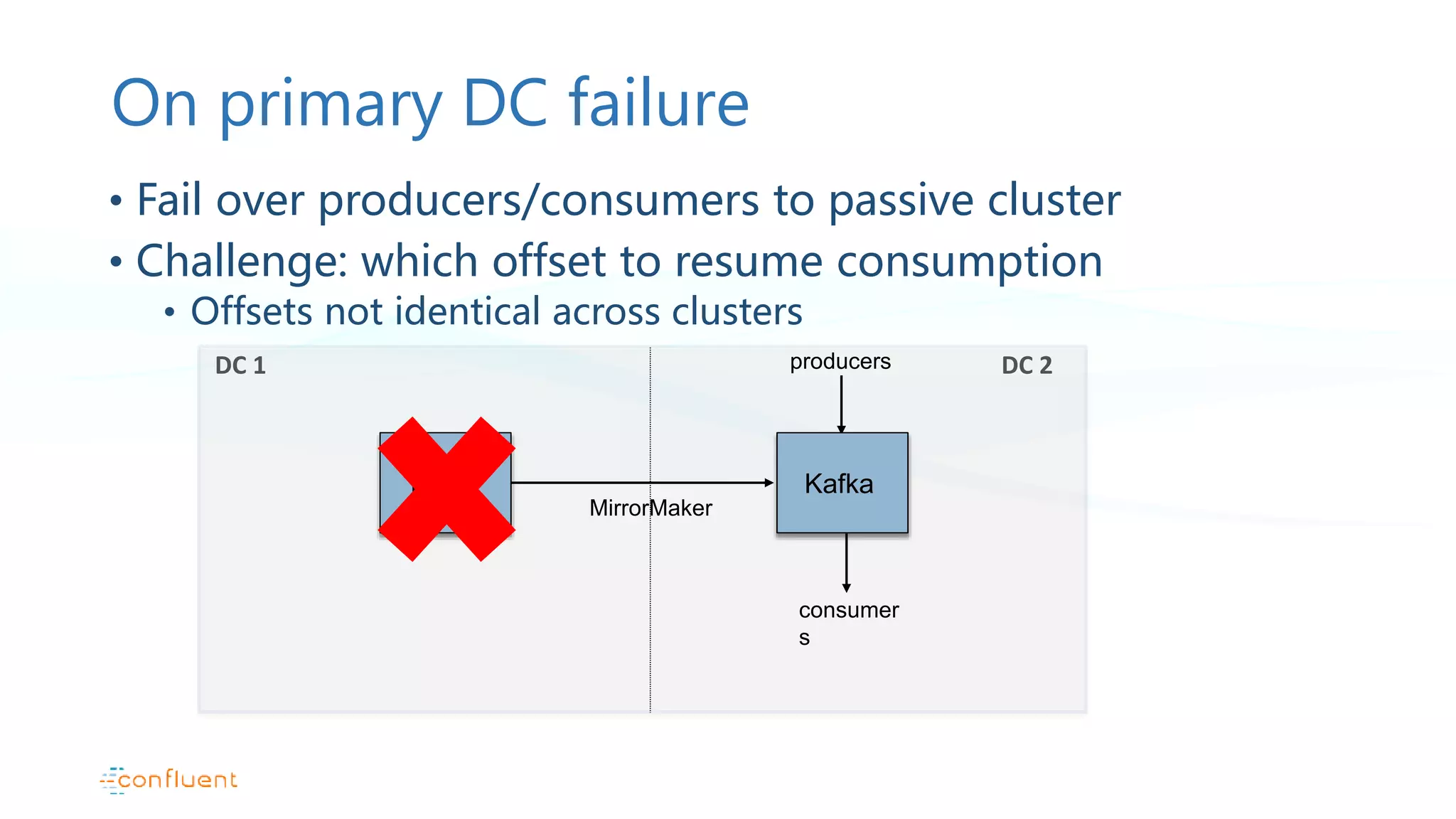

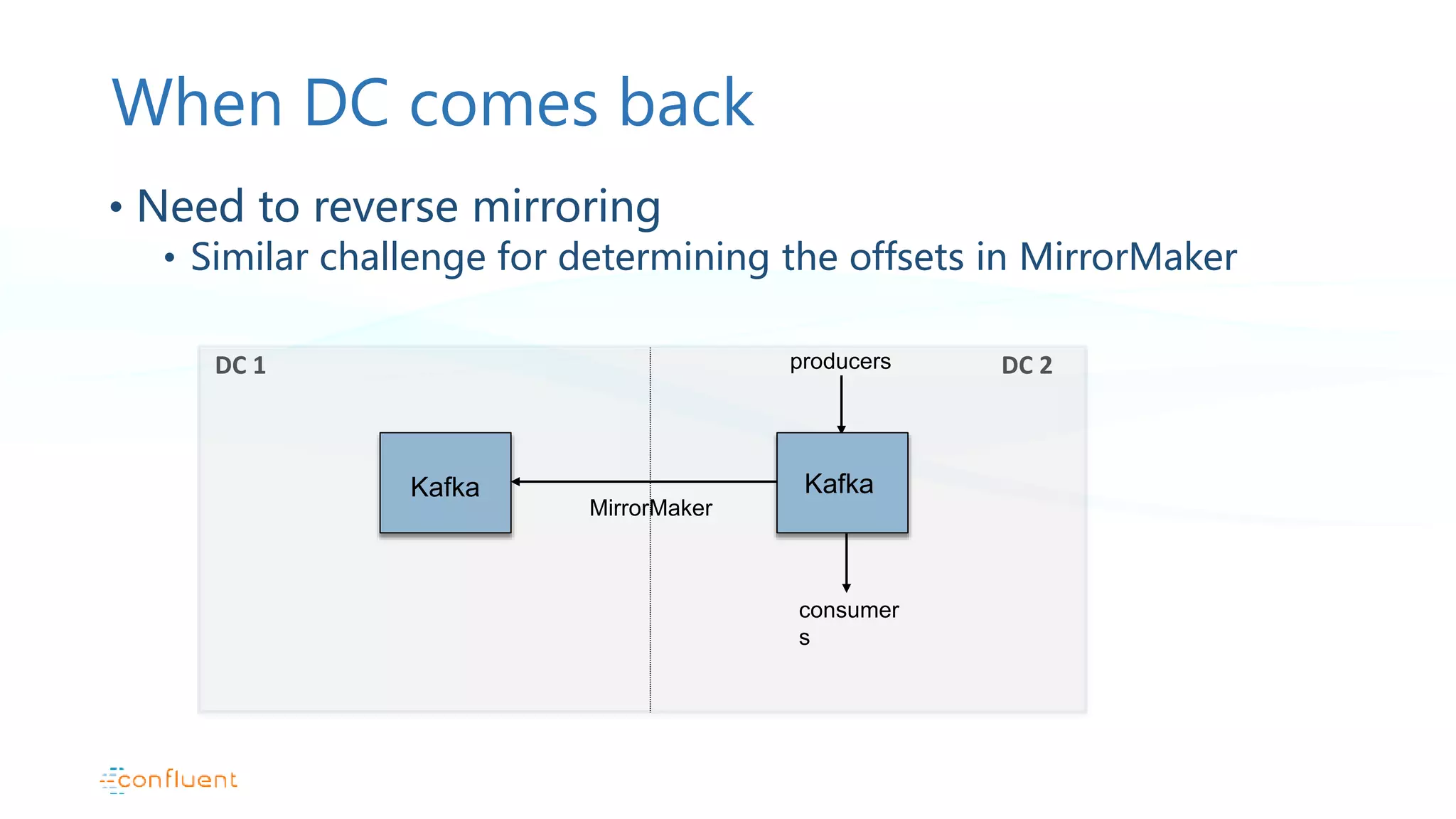

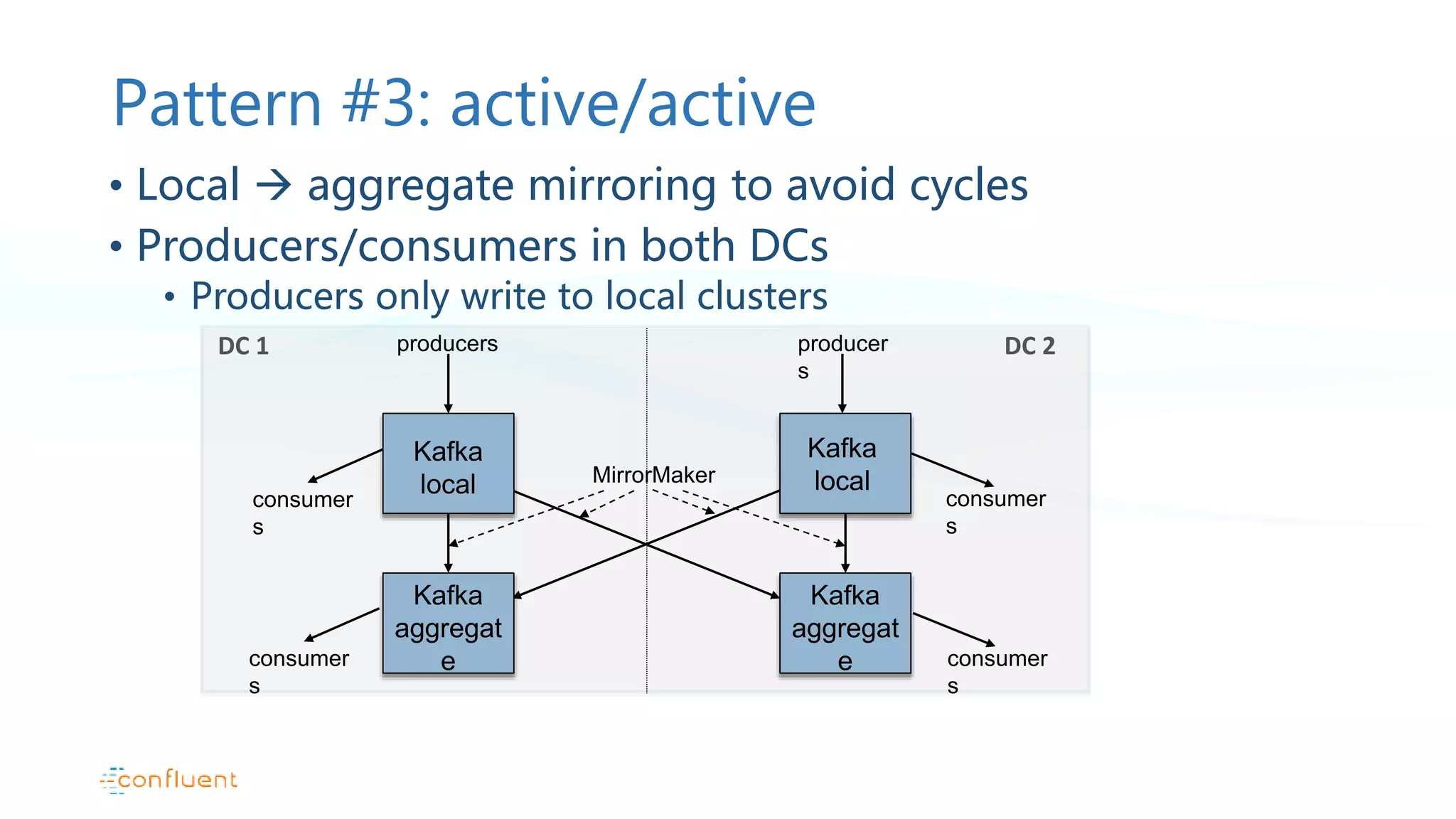
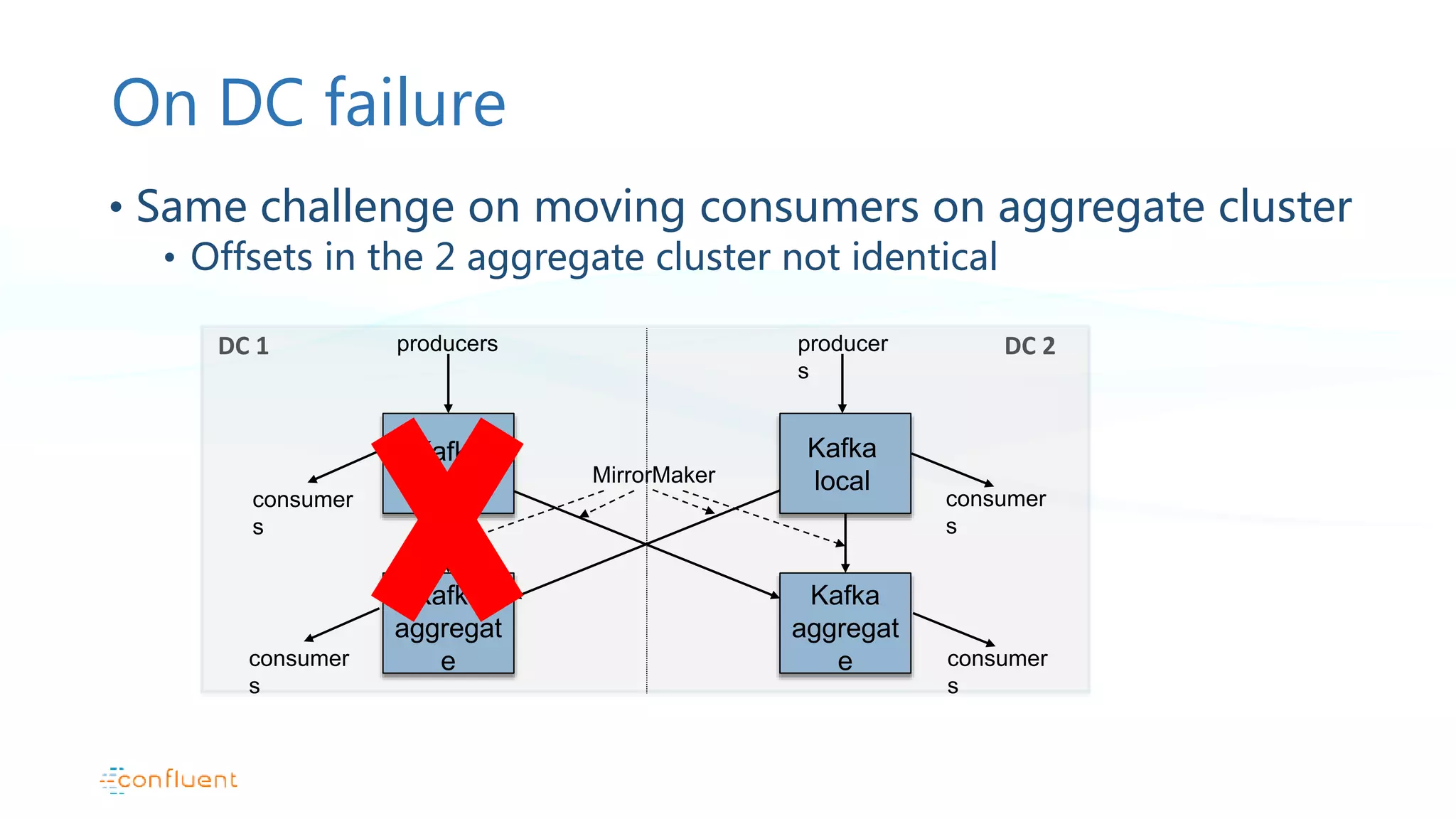
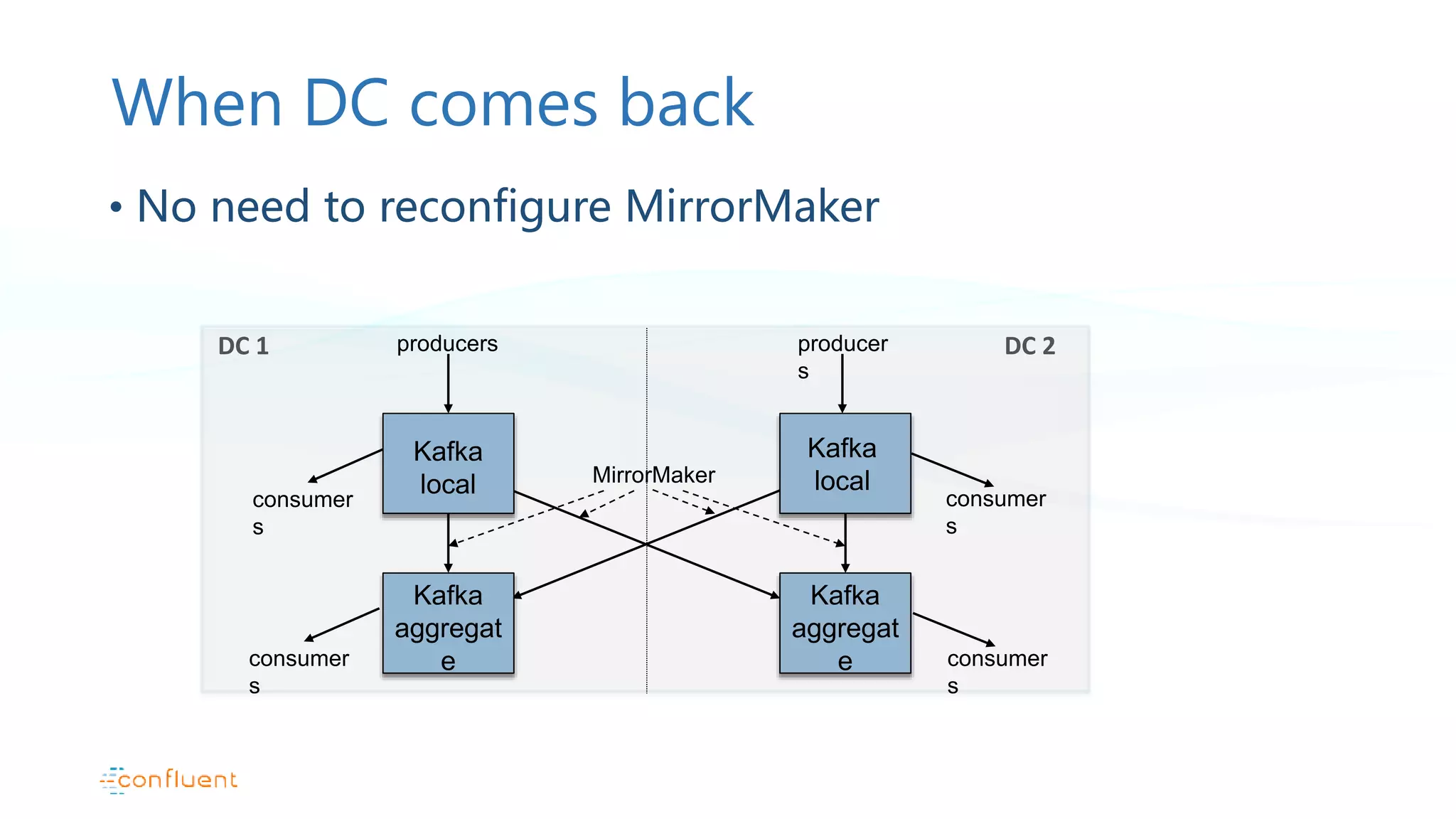
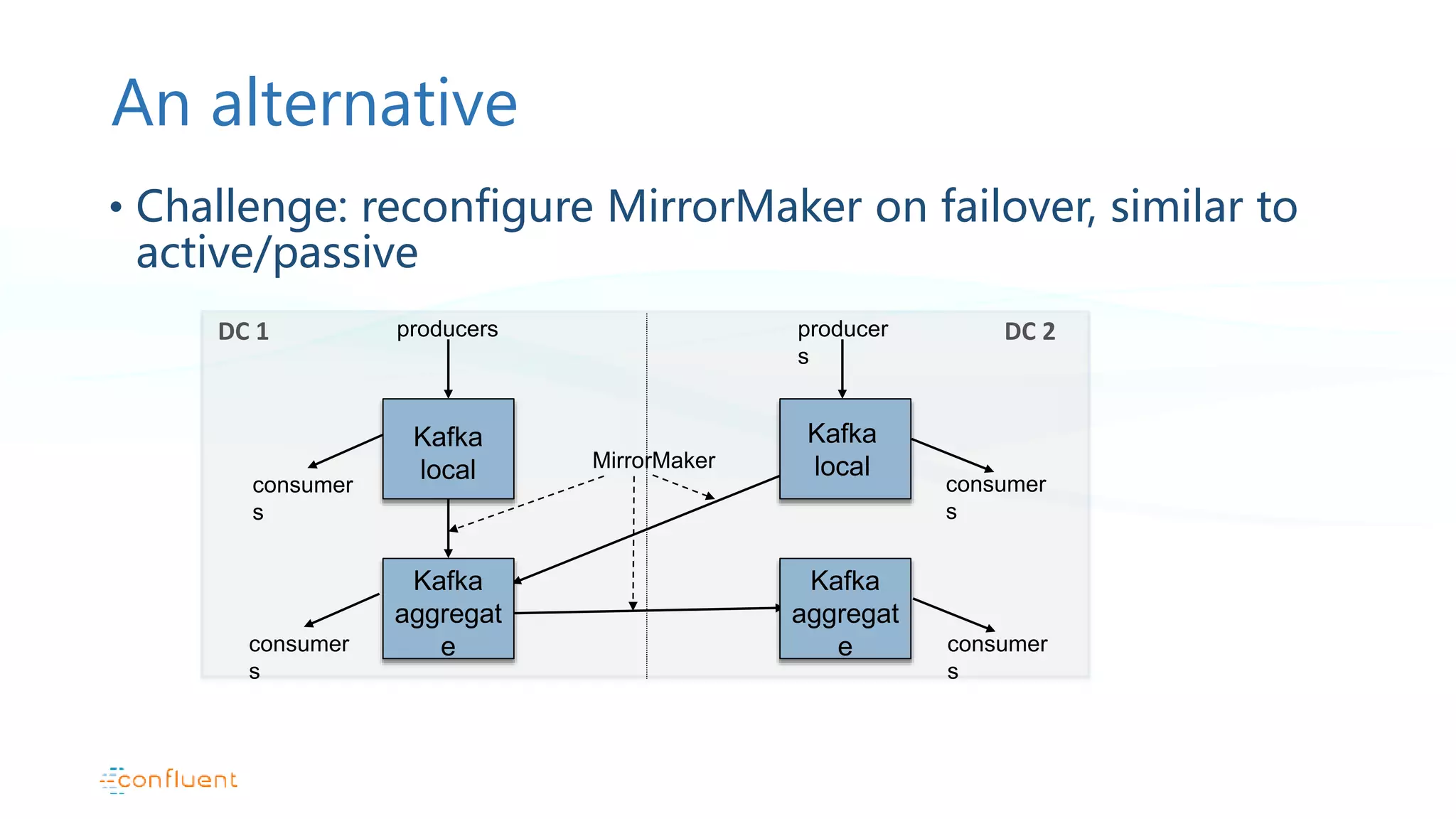



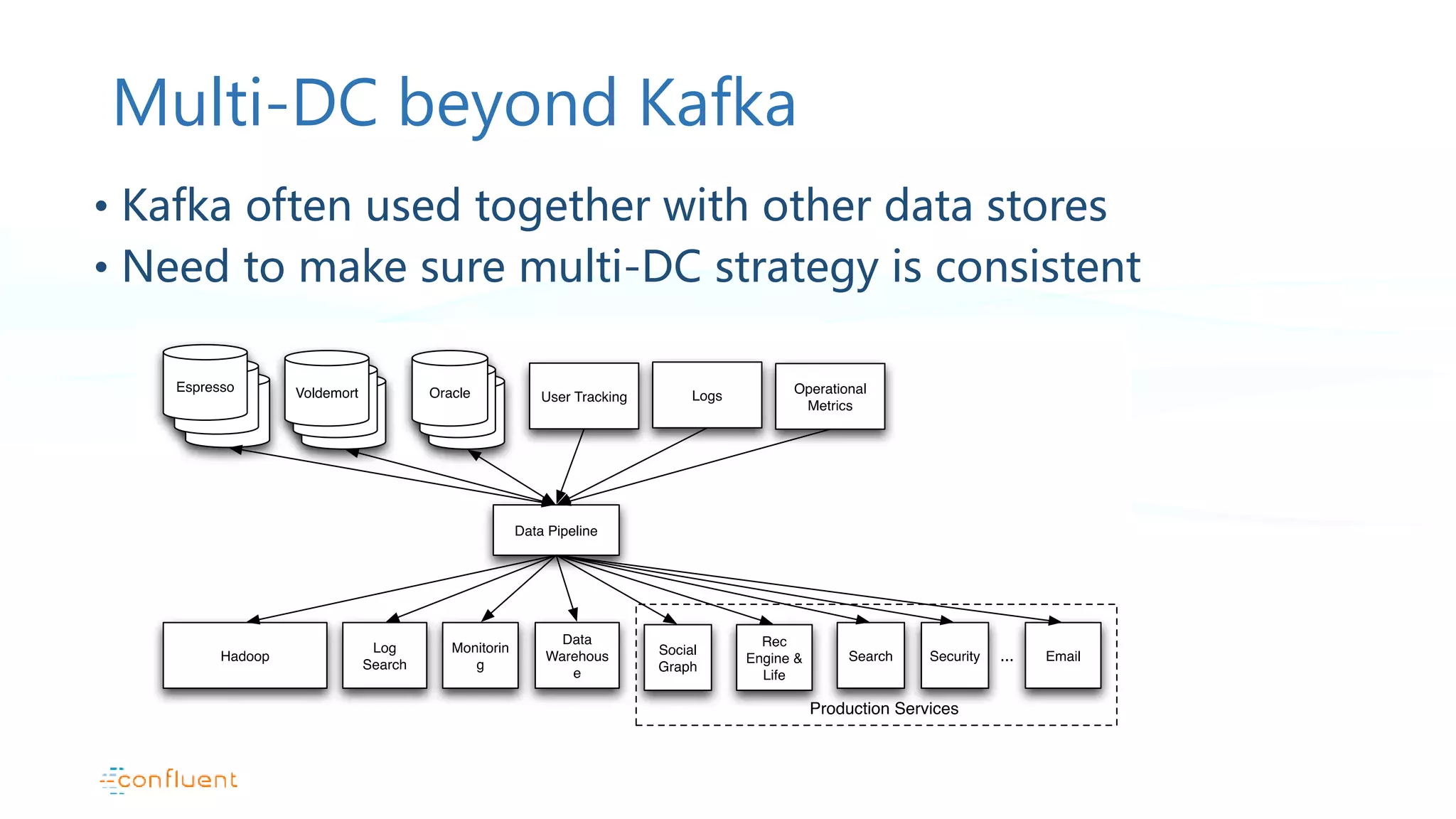

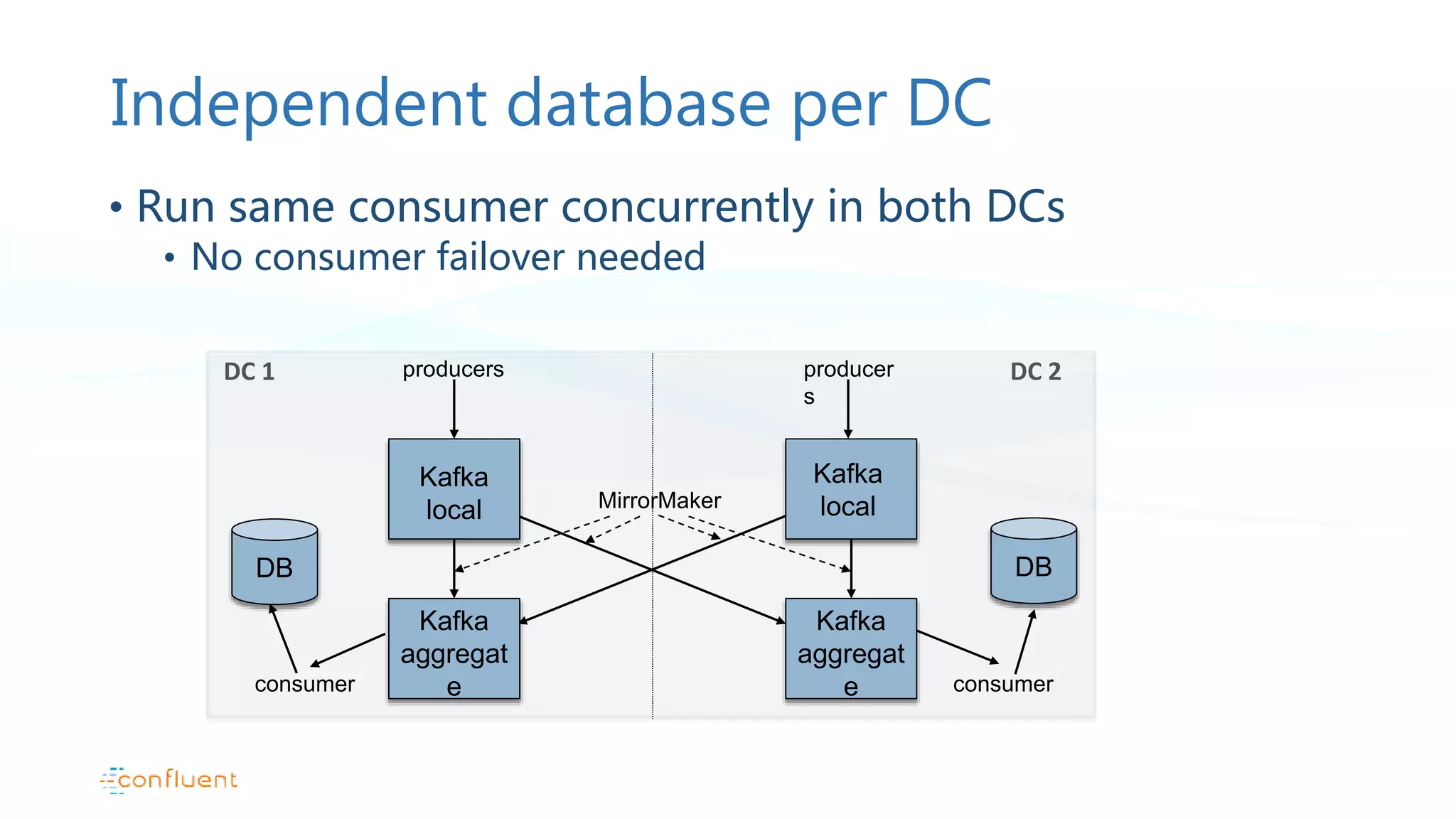
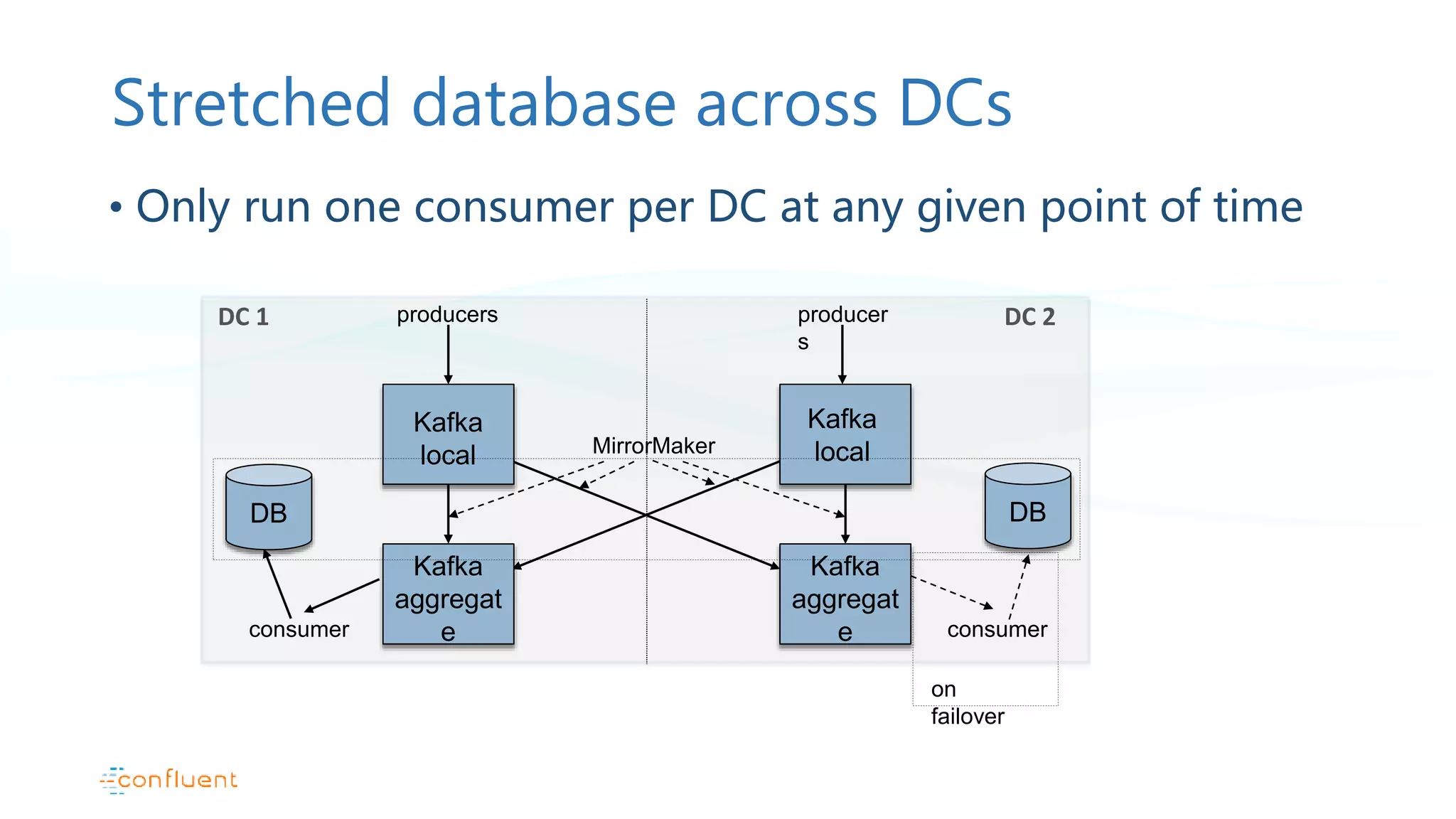




This document discusses common patterns for running Apache Kafka across multiple data centers. It describes stretched clusters, active/passive, and active/active cluster configurations. For each pattern, it covers how to handle failures and recover consumer offsets when switching data centers. It also discusses considerations for using Kafka with other data stores in a multi-DC environment and future work like timestamp-based offset seeking.























































































