Downloaded 31 times










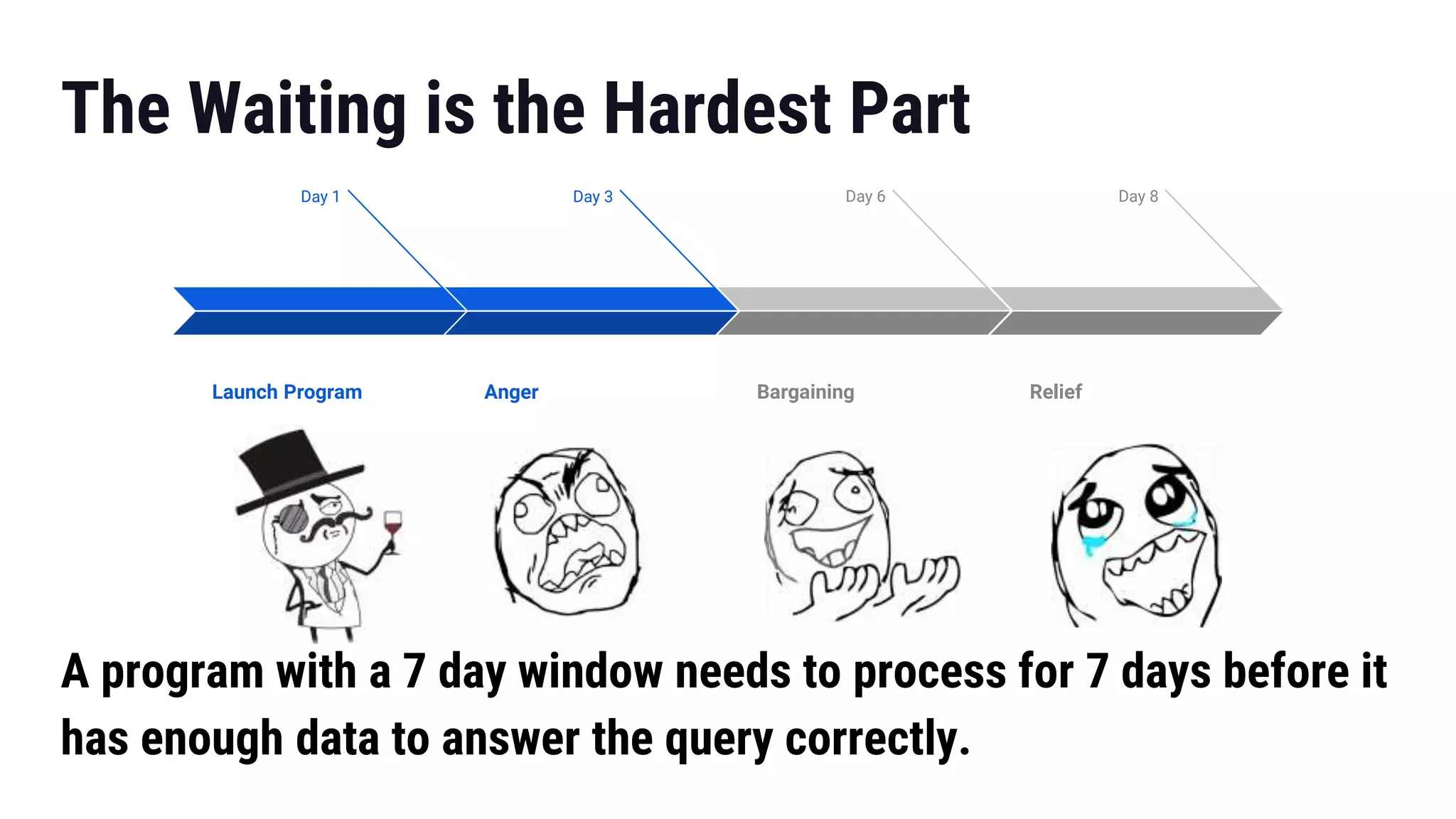






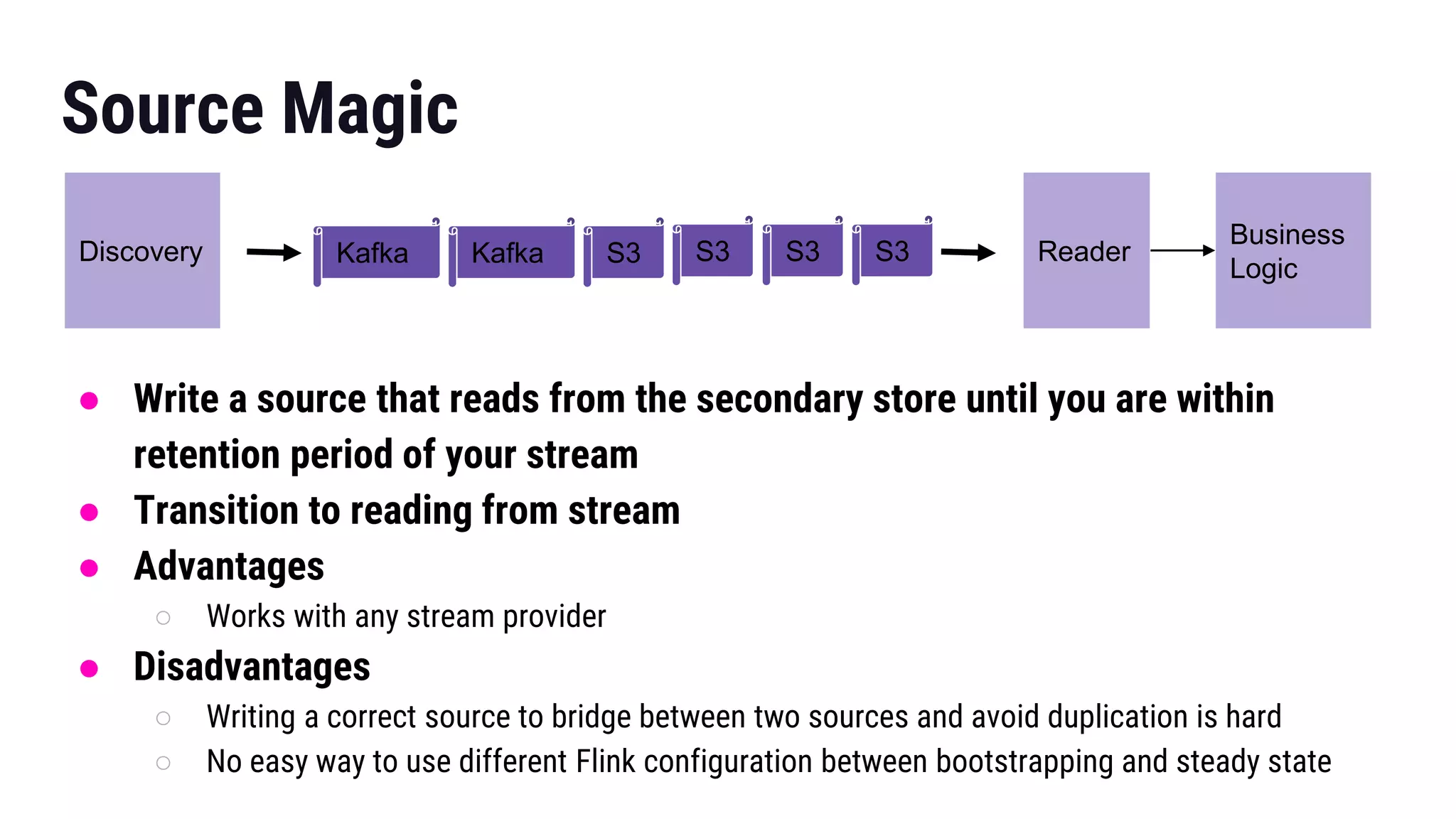


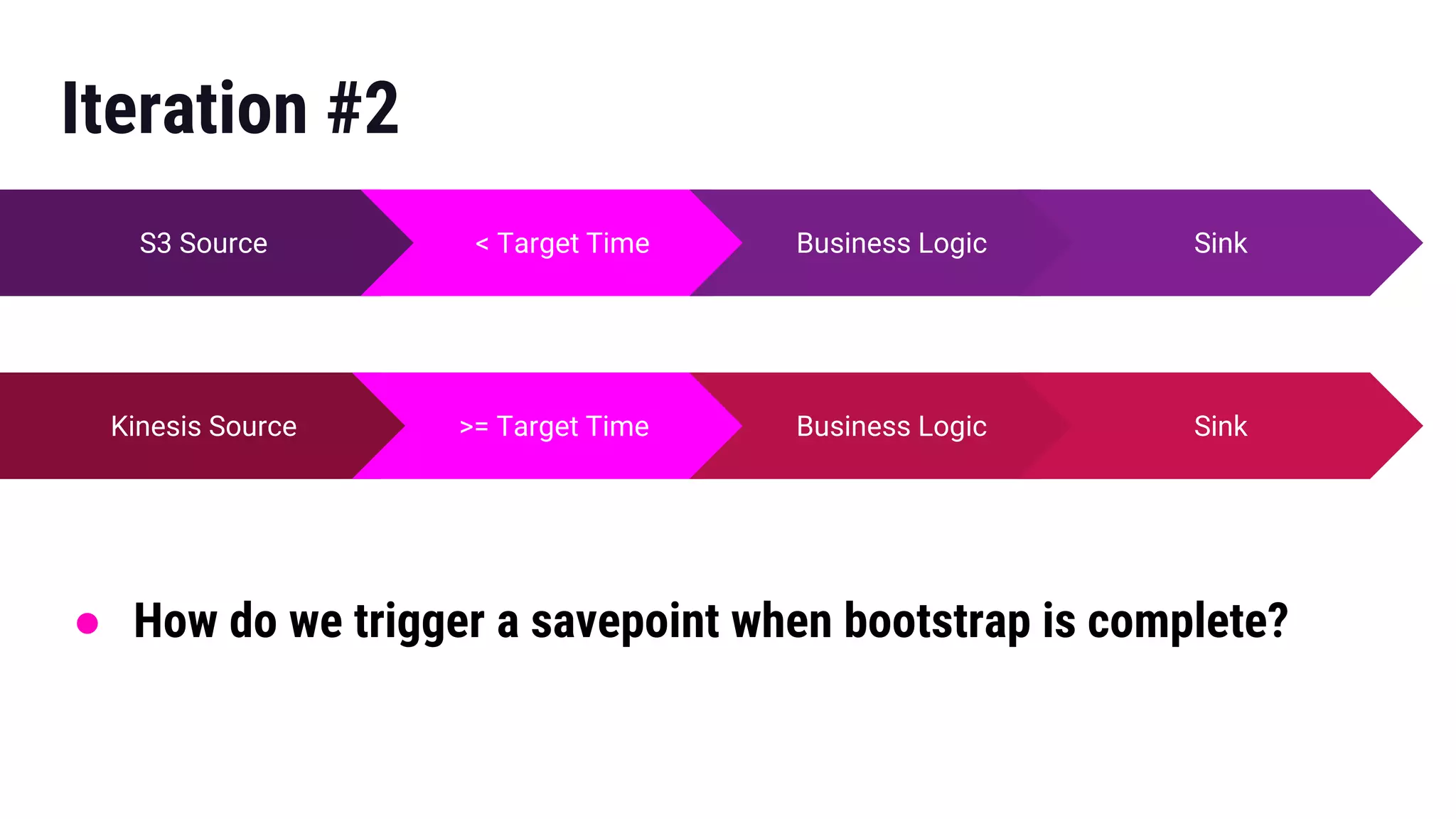




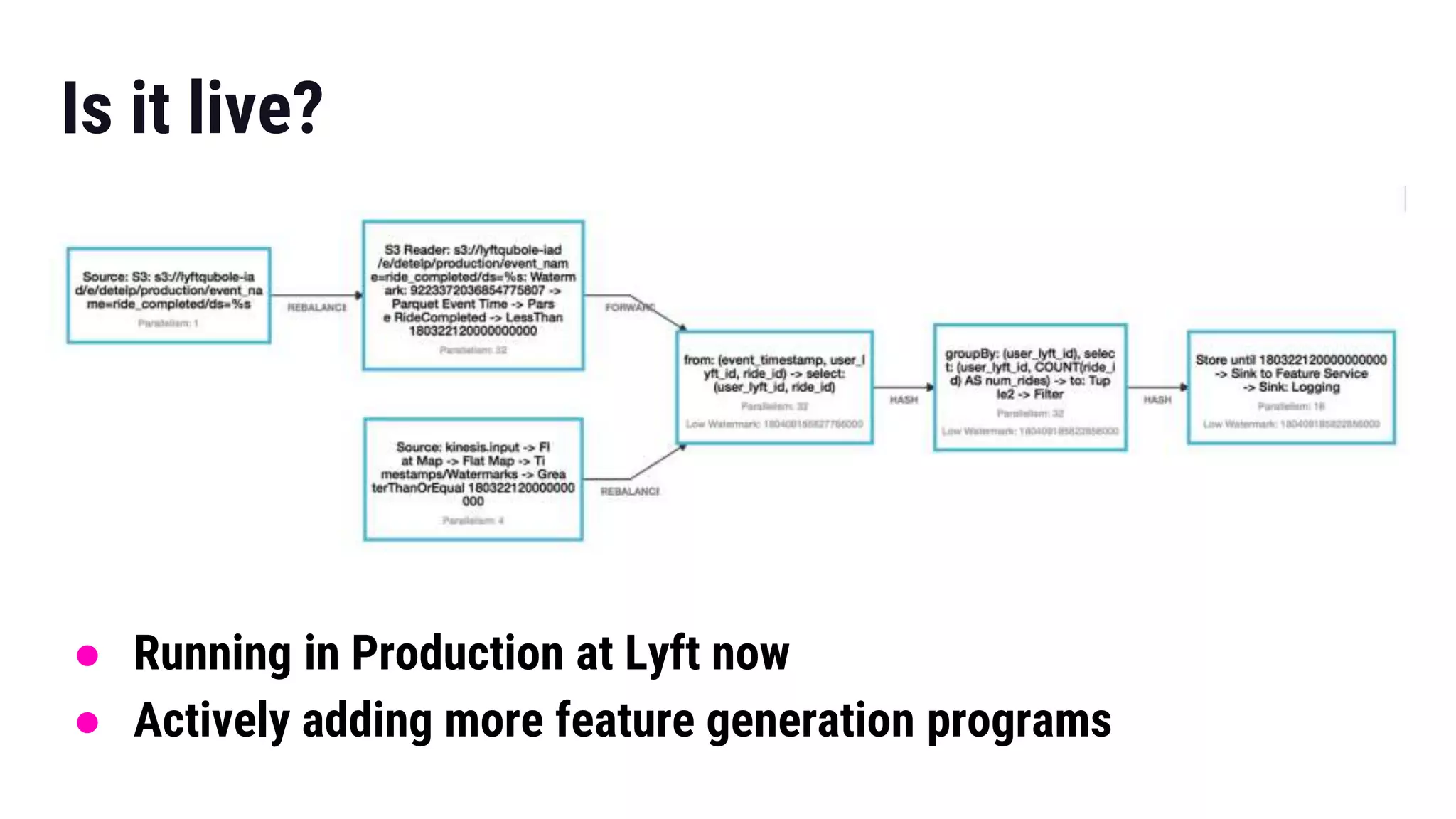




The document presents insights from Gregory Fee's talk at the DataWorks Summit 2018 on using Apache Flink for bootstrapping state in machine learning feature generation. It emphasizes the need for consistent feature generation through a combination of batch and stream processing while detailing technical approaches for efficient state management and live data integration. Key discussions include challenges and solutions around processing historic data, managing system performance, and the specifics of using Flink in production at Lyft.






















































































