




















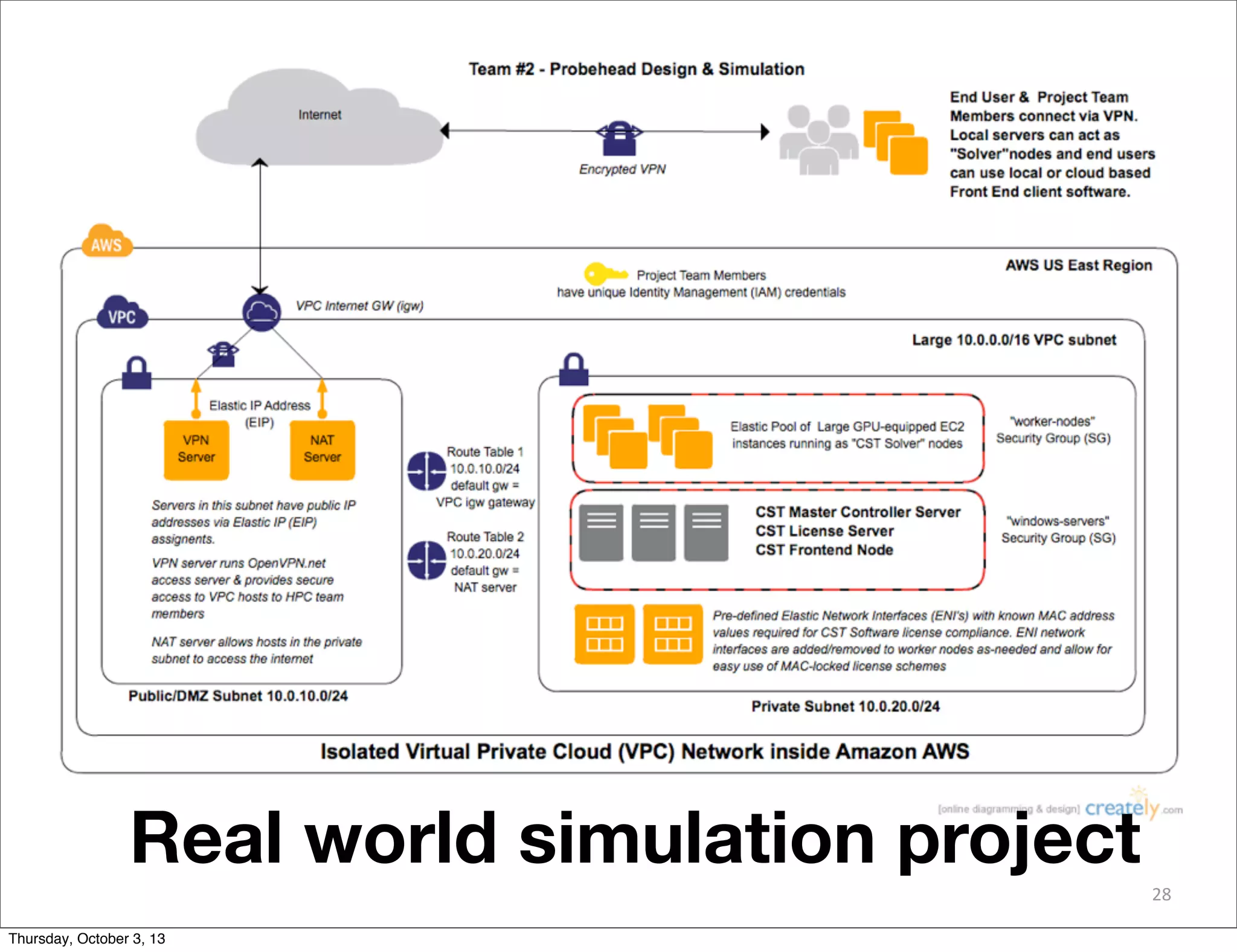
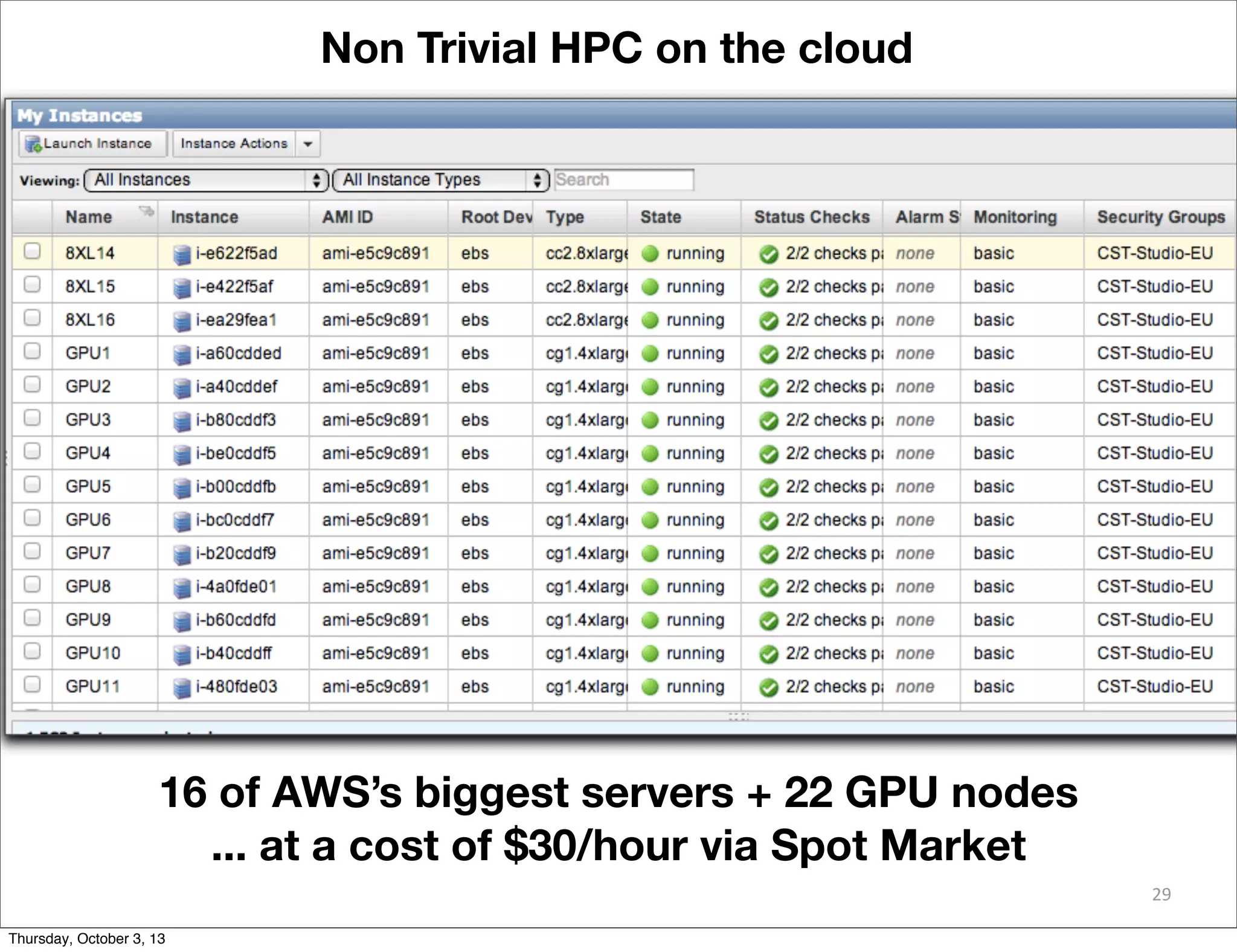




















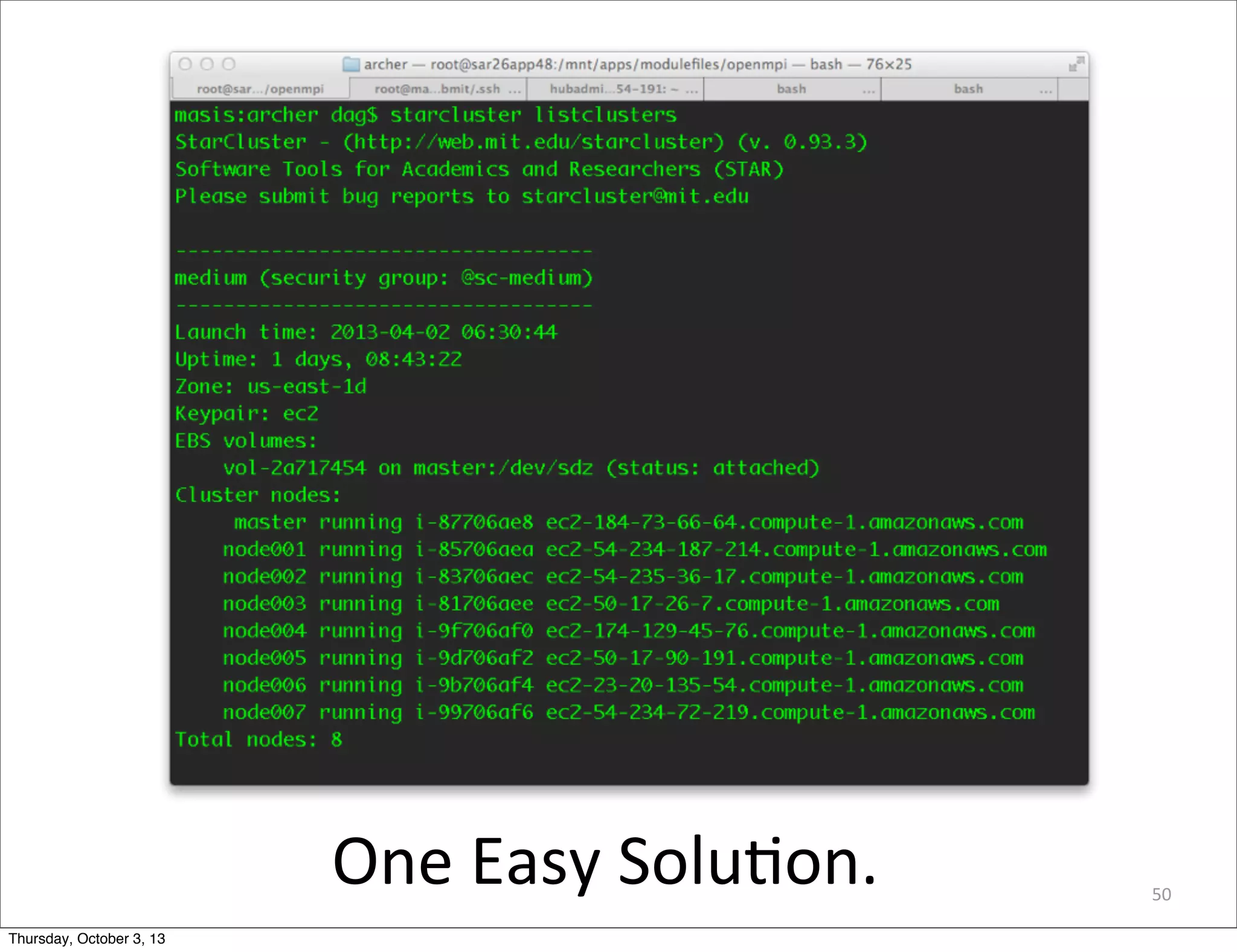
























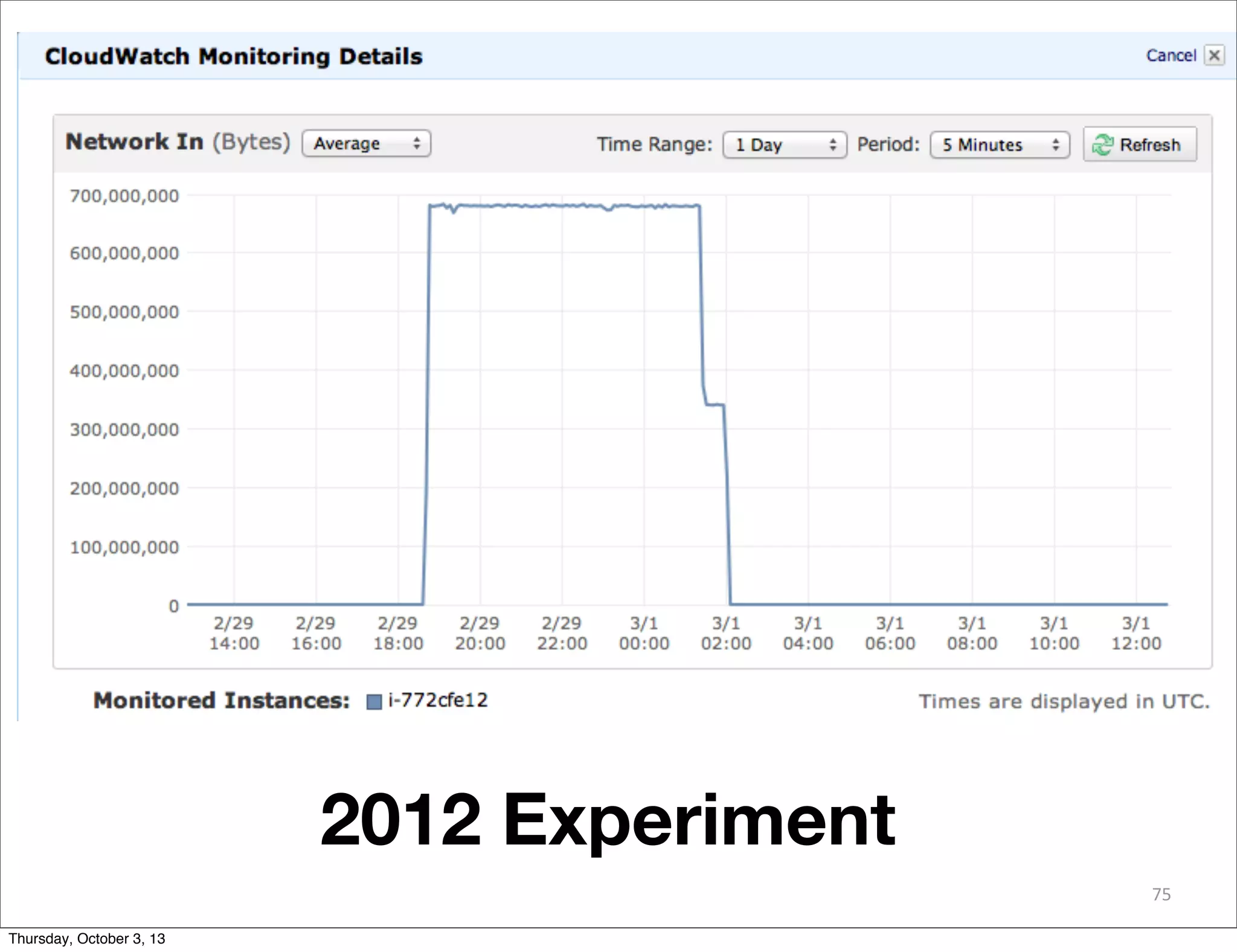









The document discusses the challenges and drivers for cloud adoption in bioinformatics and scientific research, emphasizing the need for flexible Infrastructure as a Service (IaaS) solutions to keep up with rapid advancements in scientific instrumentation and data generation. It critiques the limitations of existing cloud offerings and identifies three design patterns necessary for effective cloud integration: legacy systems, 'cloudy' adaptations, and big data analytics. Practical advice is provided for research-oriented IT organizations to develop strategies ensuring they leverage cloud capabilities effectively while avoiding common pitfalls.





































































![Vibe Coding vs. Spec-Driven Development [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/vibecodingvsspecdrivendevelopment-251209105622-43f455e7-thumbnail.jpg?width=640&height=640&fit=bounds)









