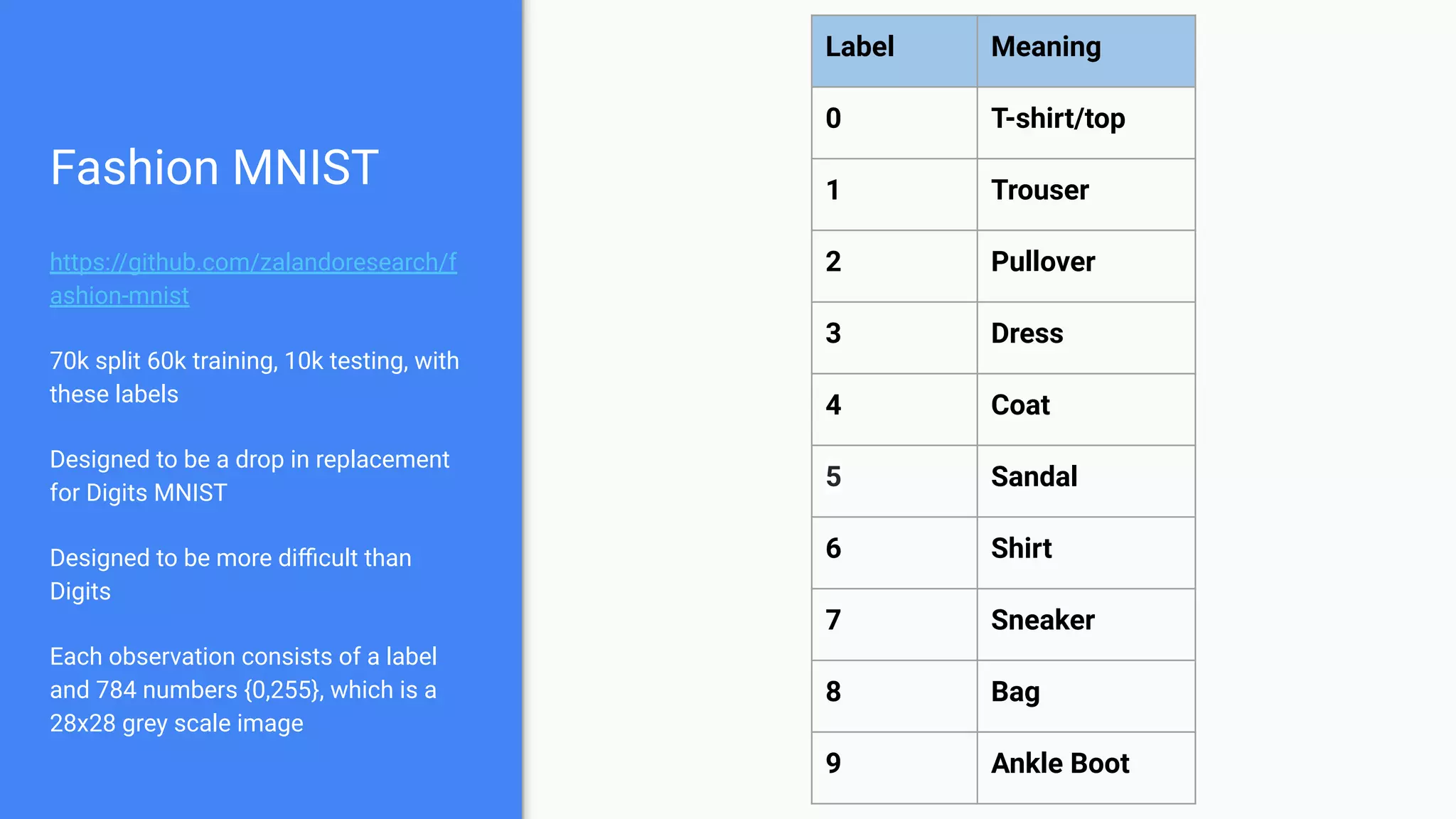
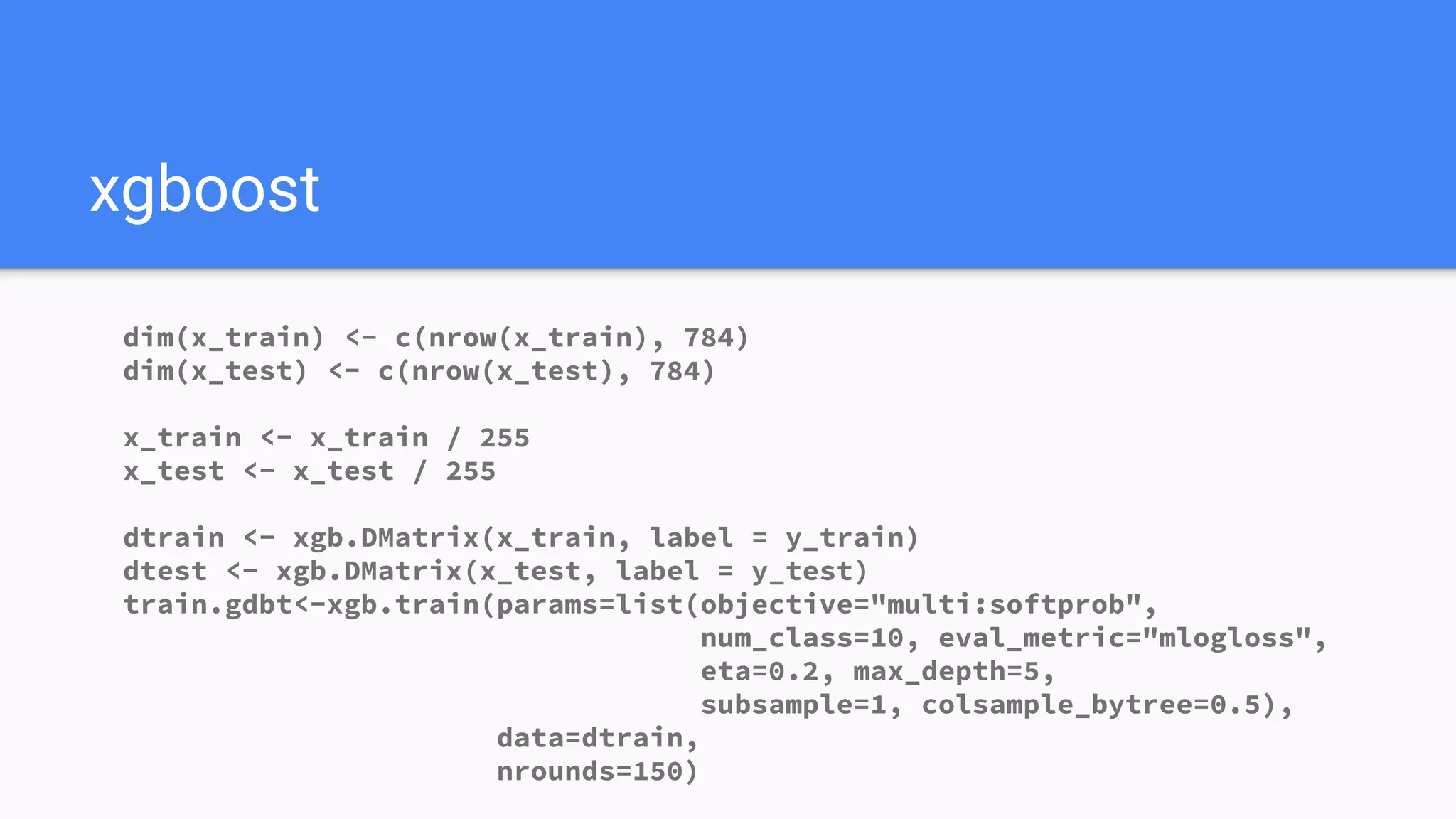
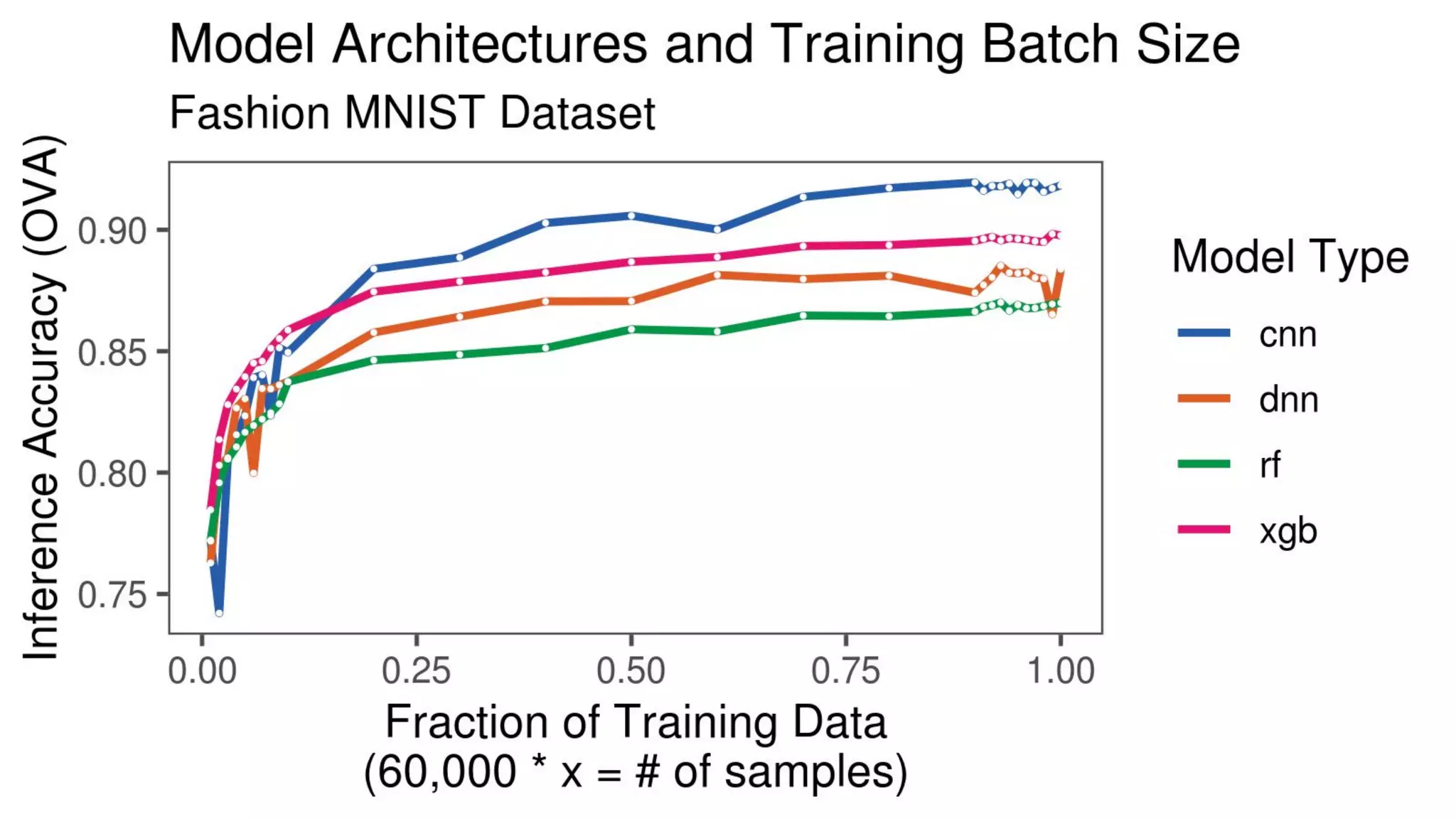
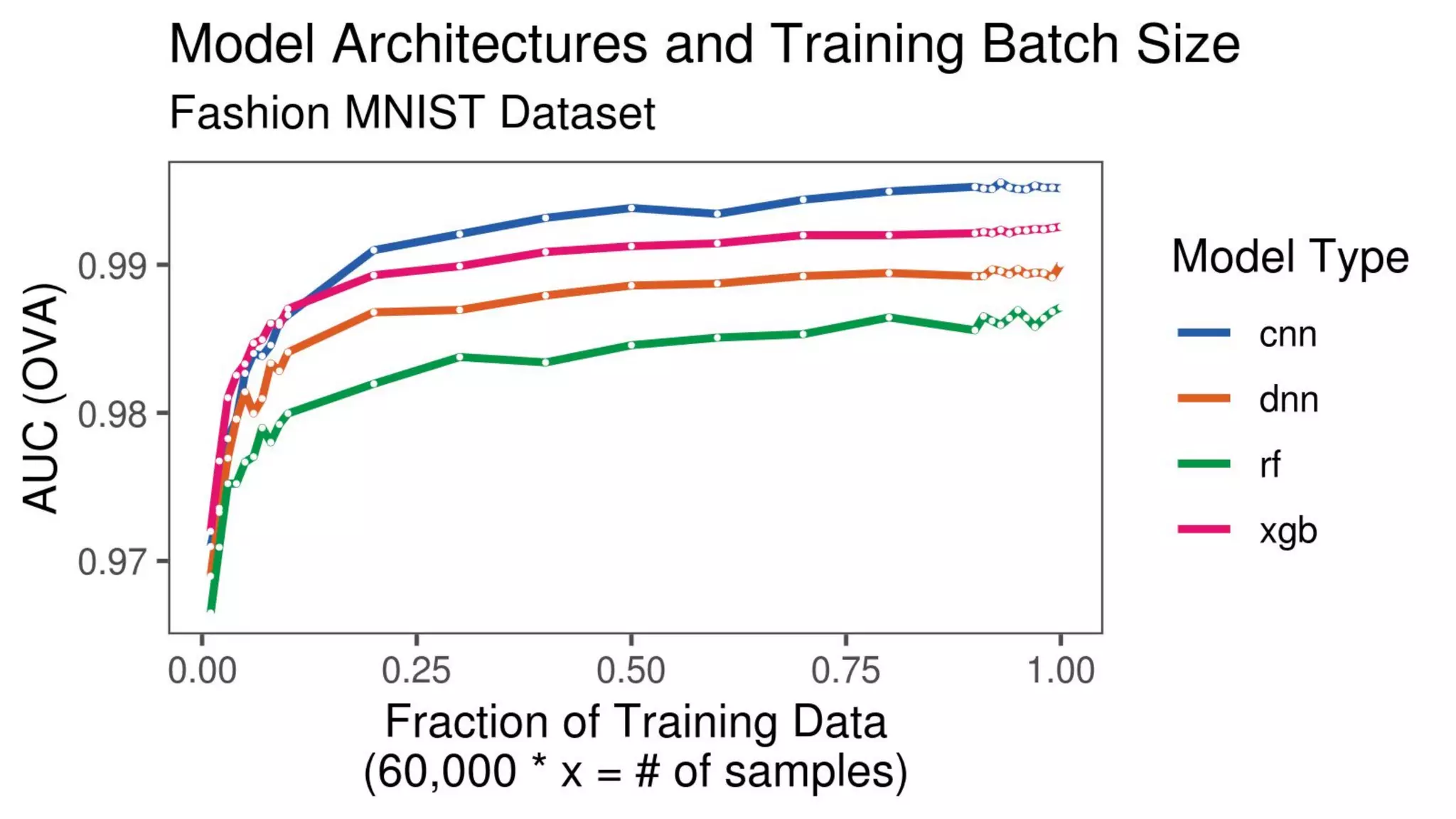
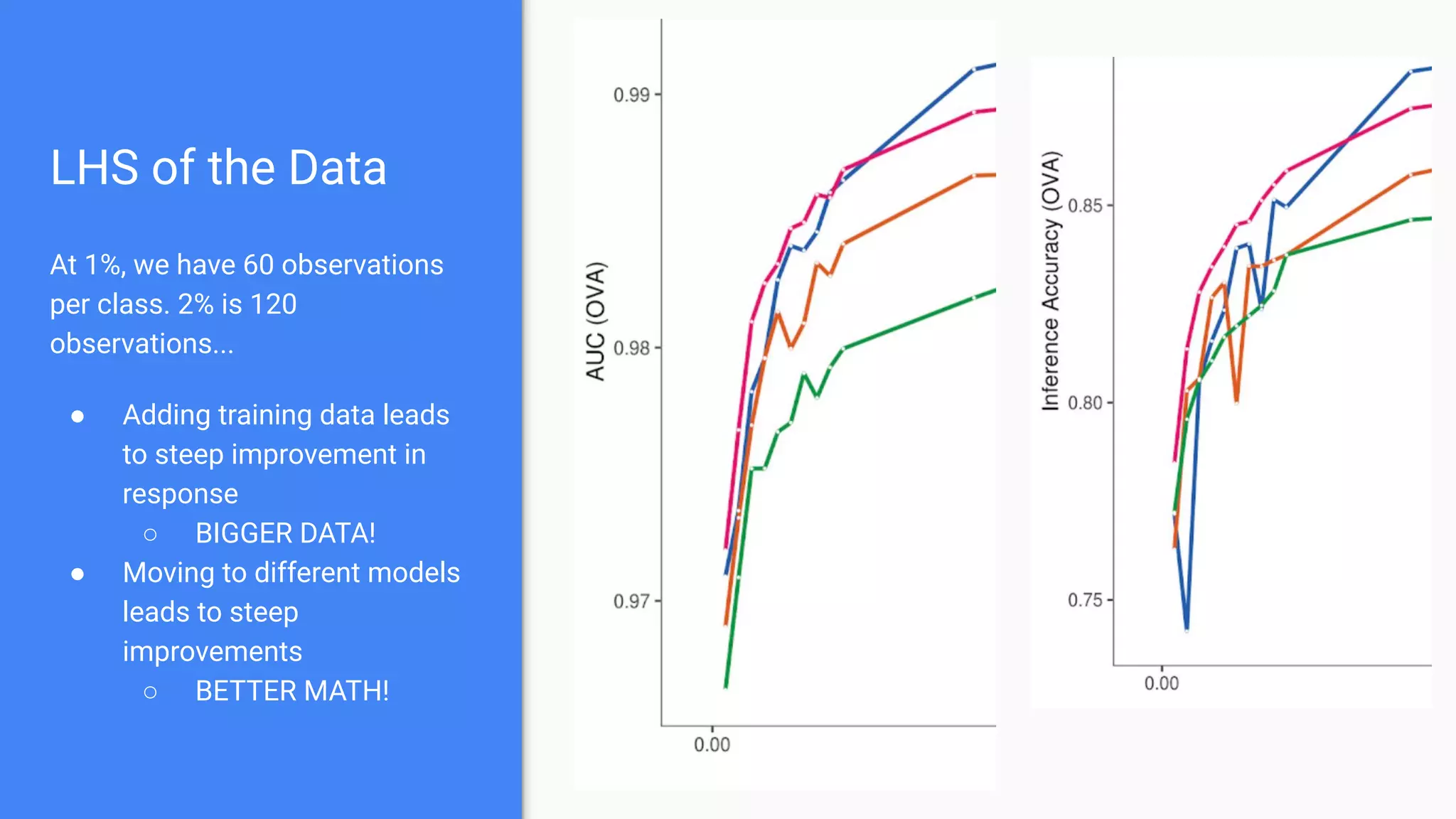
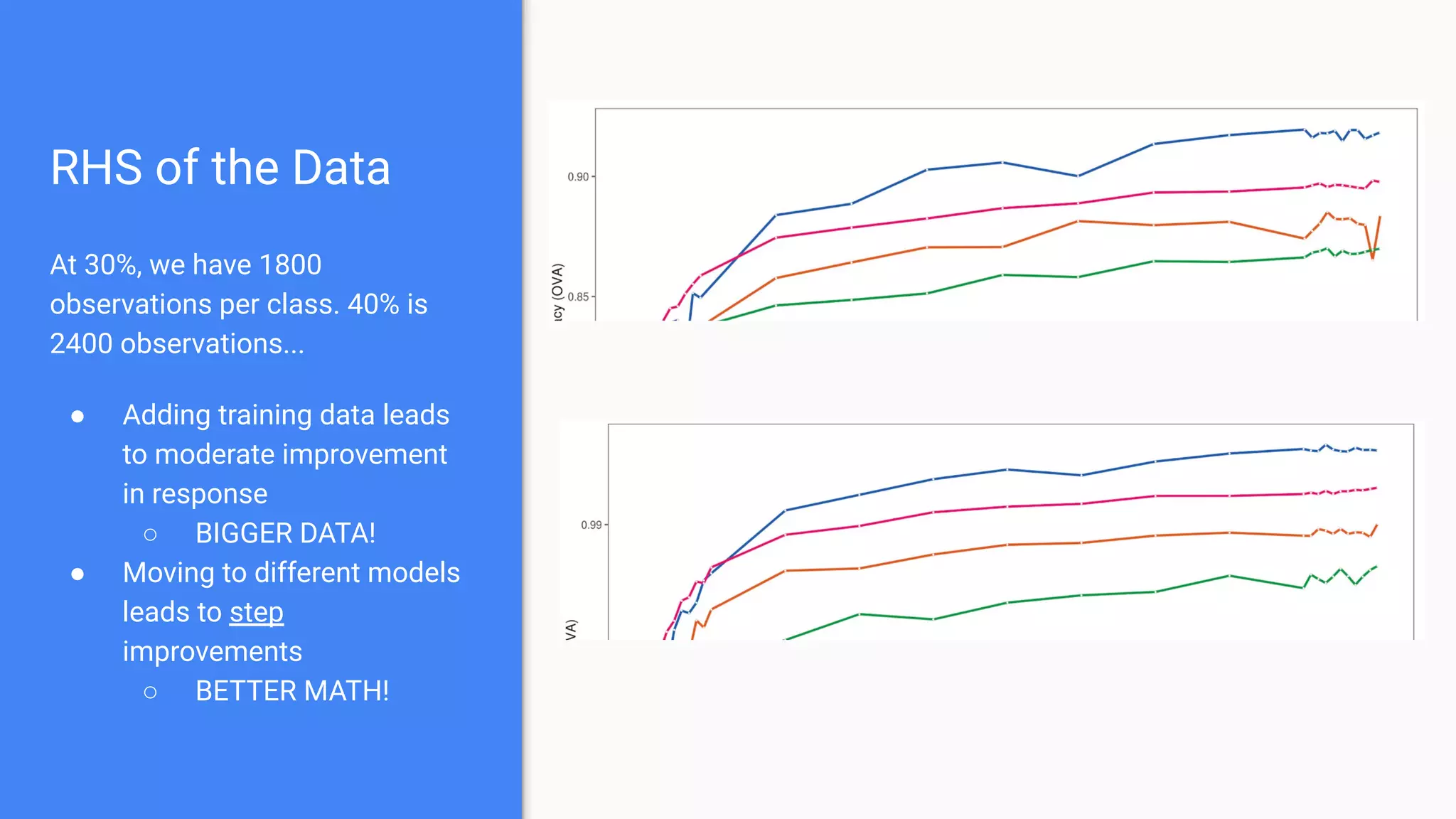
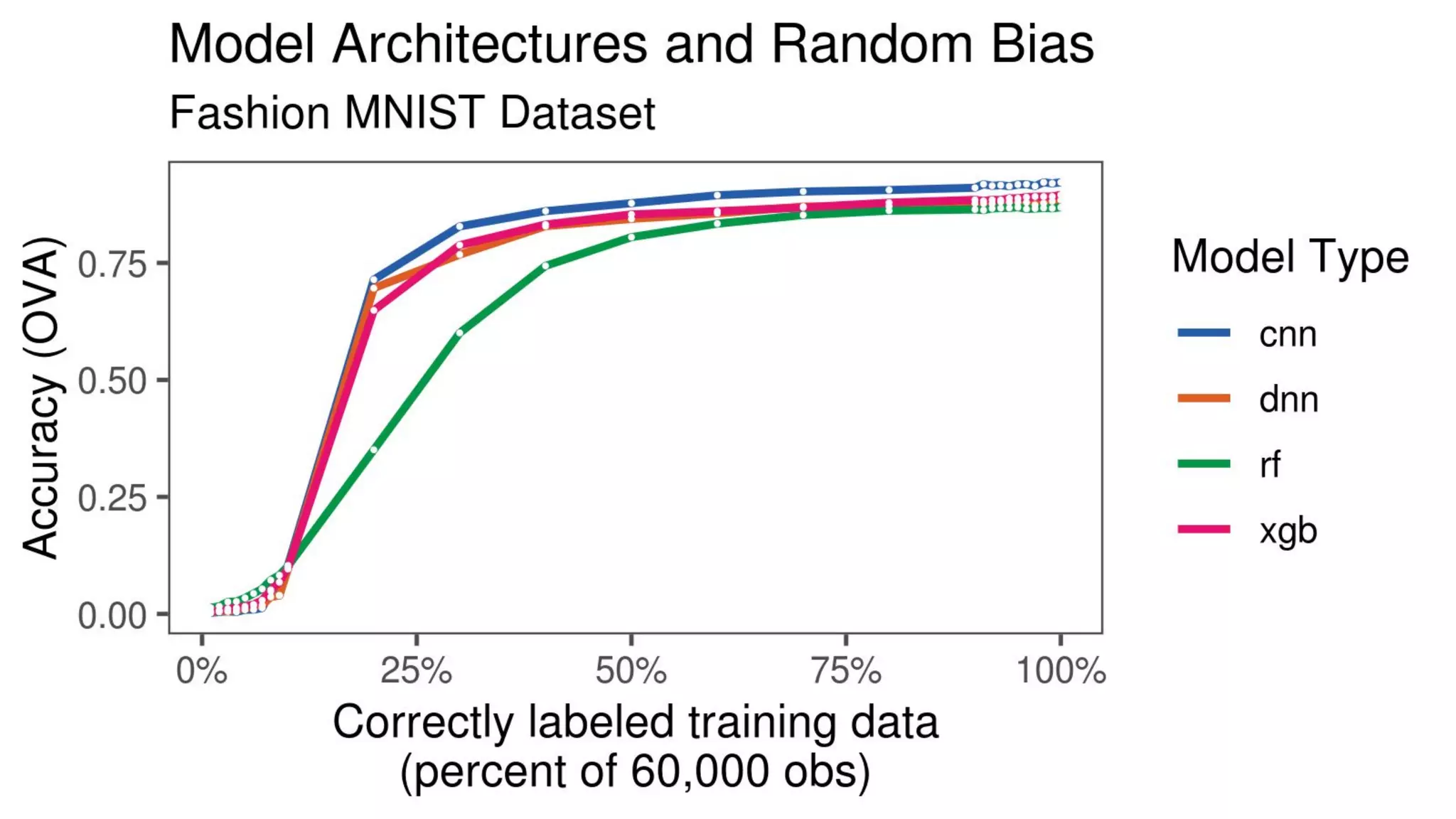
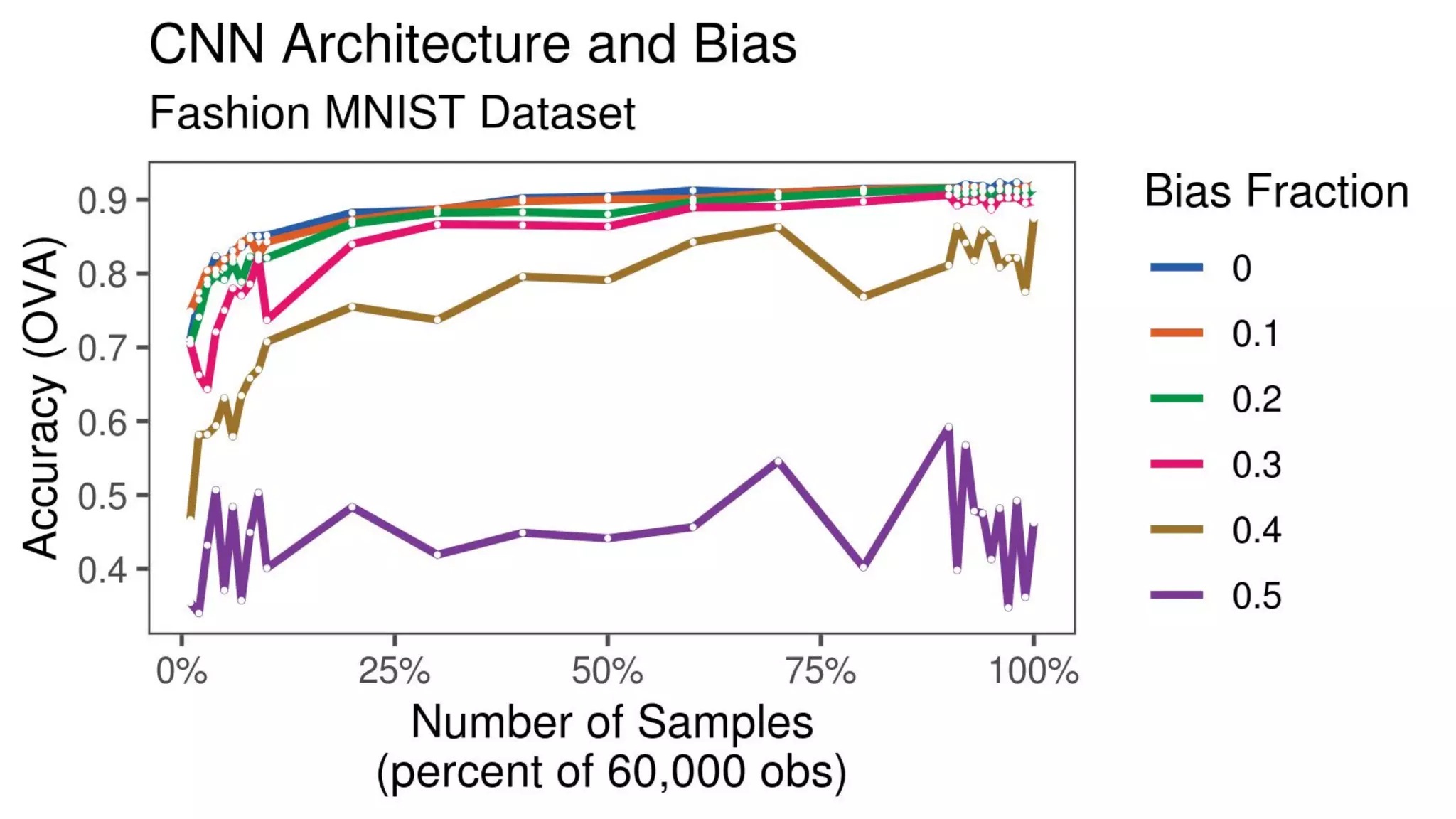
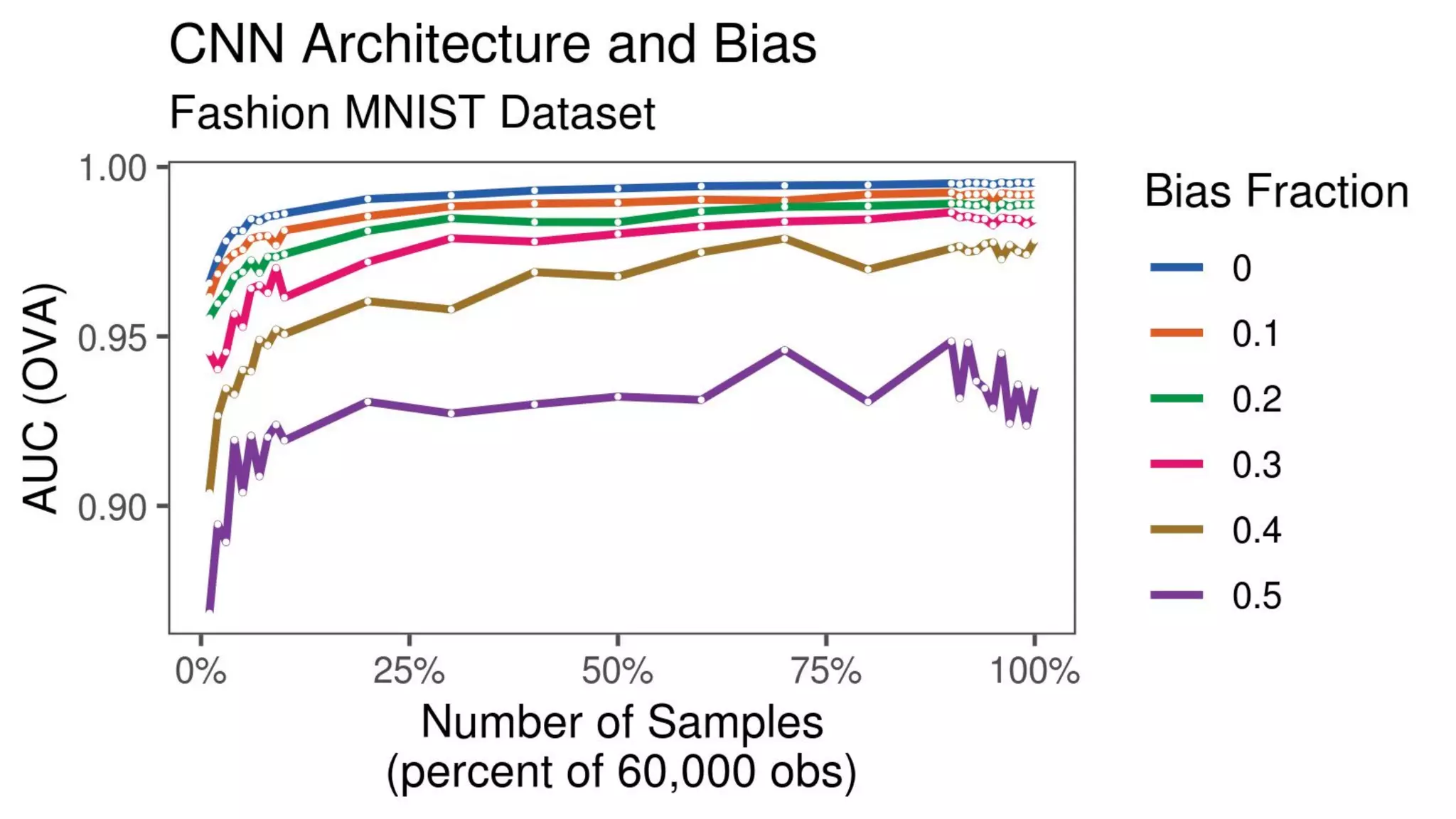
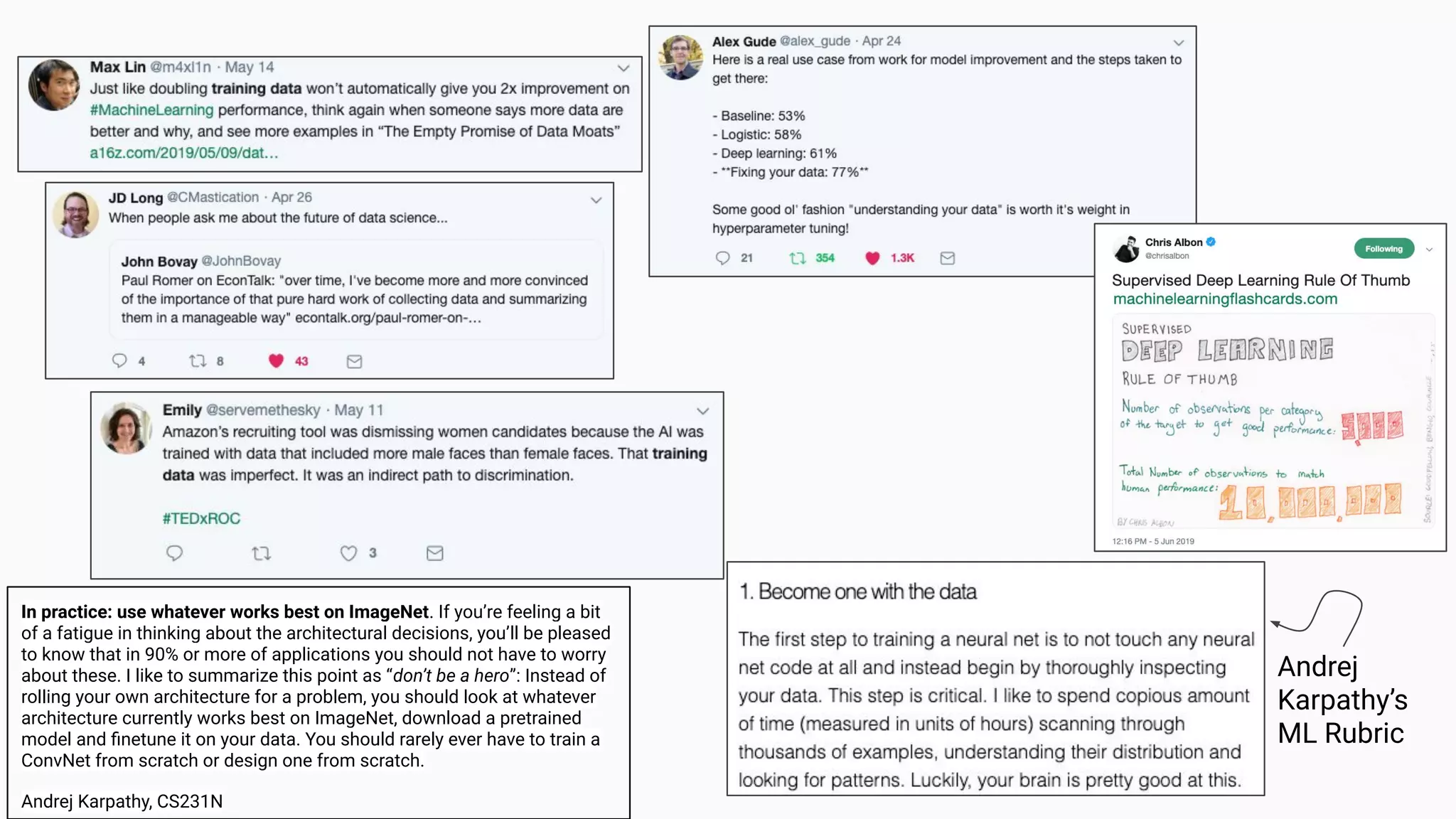
The document discusses the impact of using larger datasets versus different machine learning algorithms, concluding that bigger data significantly improves model performance, often more than switching models. It details experiments conducted on the Fashion MNIST dataset, illustrating how the amount of training data and the choice of model affect accuracy and AUC. The document also emphasizes the importance of data quality and encourages leveraging proven architectures rather than developing new ones from scratch.








![And it looks like
> str(mnist)
List of 2
$ train:List of 2
..$ x: int [1:60000, 1:28, 1:28] 0 0 0 0 0 0 0 0 0 0 ...
..$ y: int [1:60000(1d)] 9 0 0 3 0 2 7 2 5 5 ...
$ test :List of 2
..$ x: int [1:10000, 1:28, 1:28] 0 0 0 0 0 0 0 0 0 0 ...
..$ y: int [1:10000(1d)] 9 2 1 1 6 1 4 6 5 7 ...](https://image.slidesharecdn.com/biggerdatabettermath-200126140329/75/Bigger-Data-v-Better-Math-10-2048.jpg)







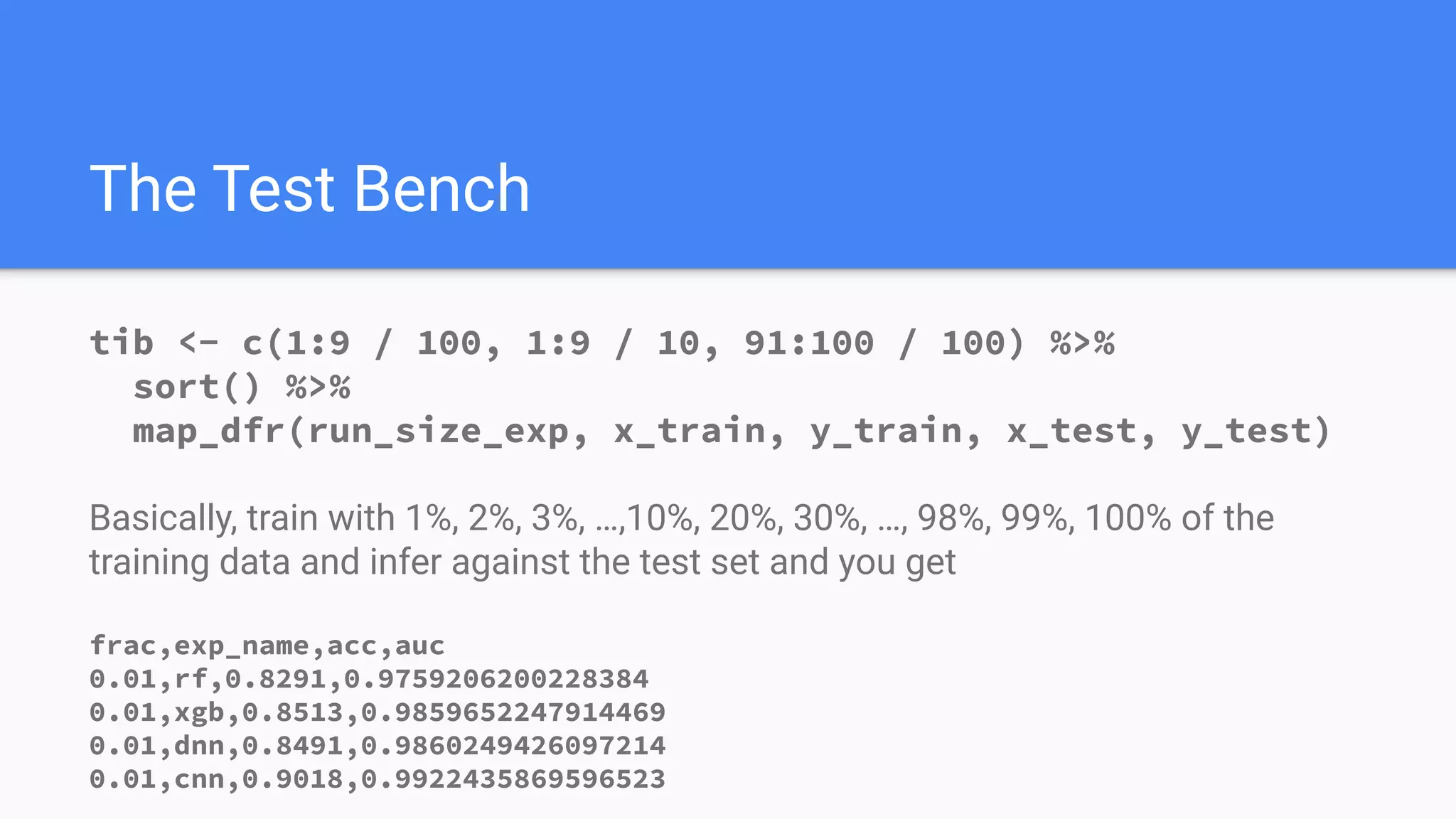
![run_size_exp
samples <- sample(nrow(x_train), floor(nrow(x_train) * frac), replace=FALSE) - 1
x_t <- x_train[samples,,]
y_t <- y_train[samples]
data <- list(x_train = x_t,
y_train = y_t,
x_test = x_test,
y_test = y_test)
math <- c(rf_exp, xgb_exp, dnn_exp, cnn_exp)
preds <- math %>%
map(exec, !!!data) FIGHT!](https://image.slidesharecdn.com/biggerdatabettermath-200126140329/75/Bigger-Data-v-Better-Math-20-2048.jpg)












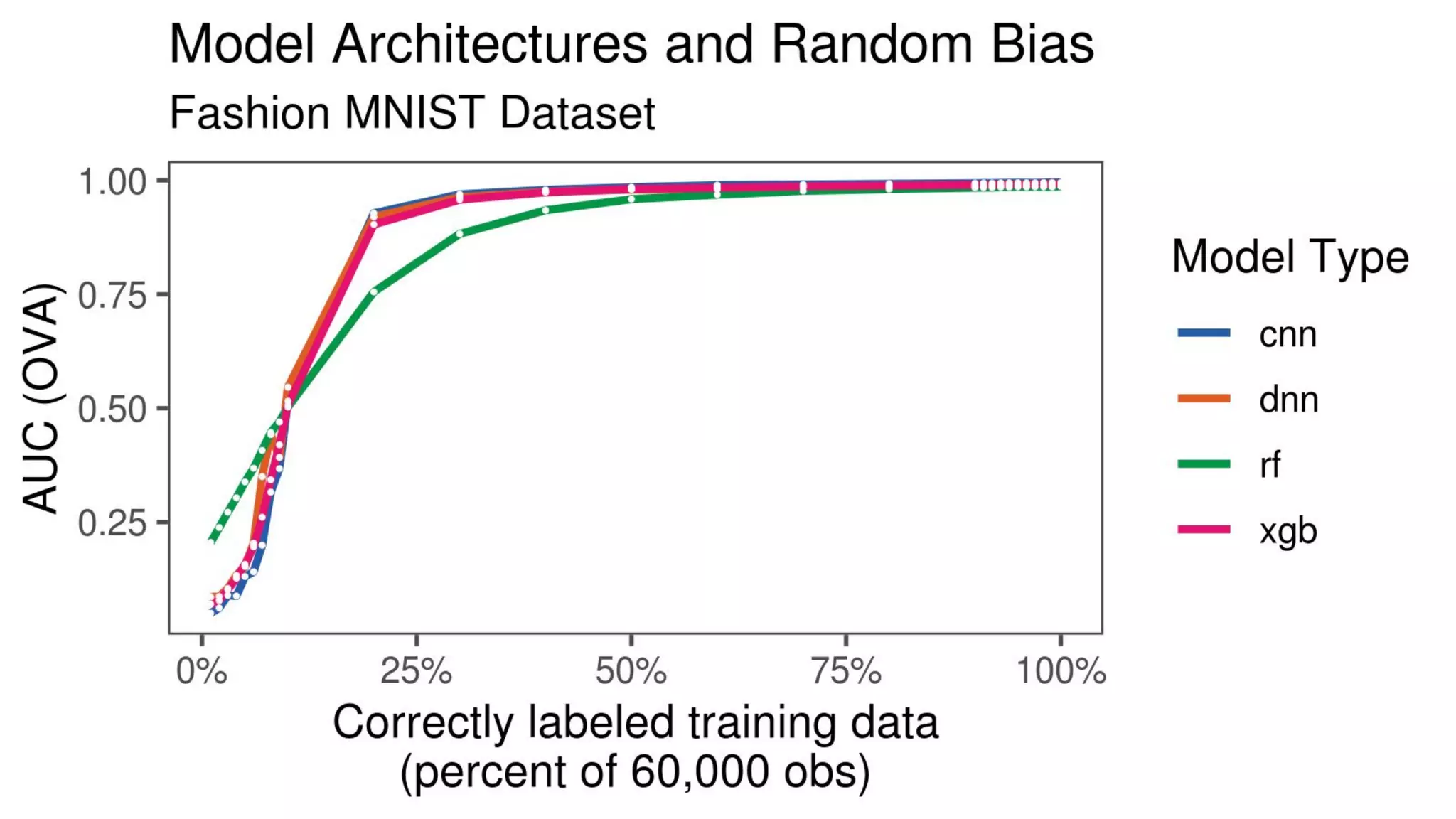




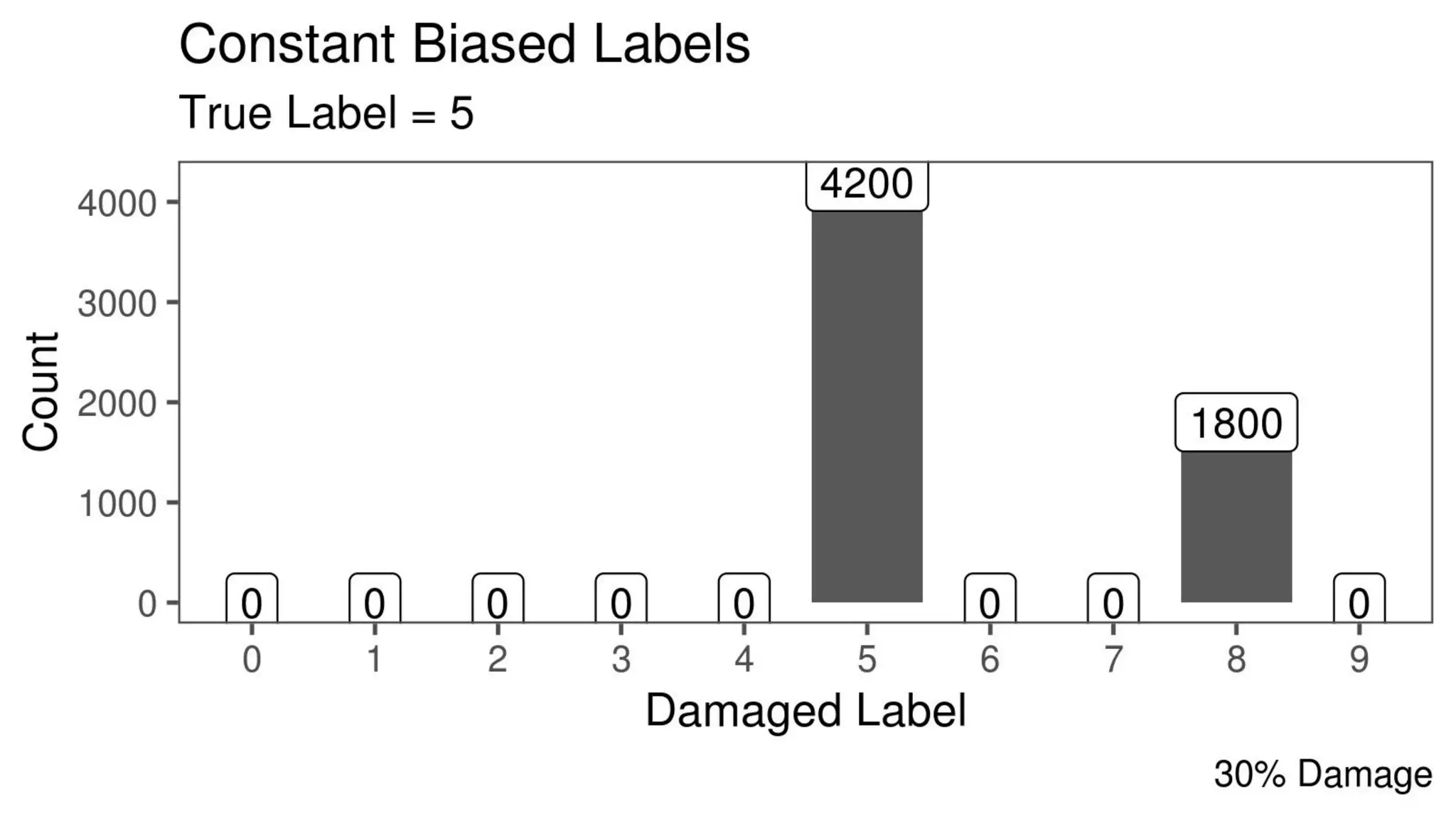
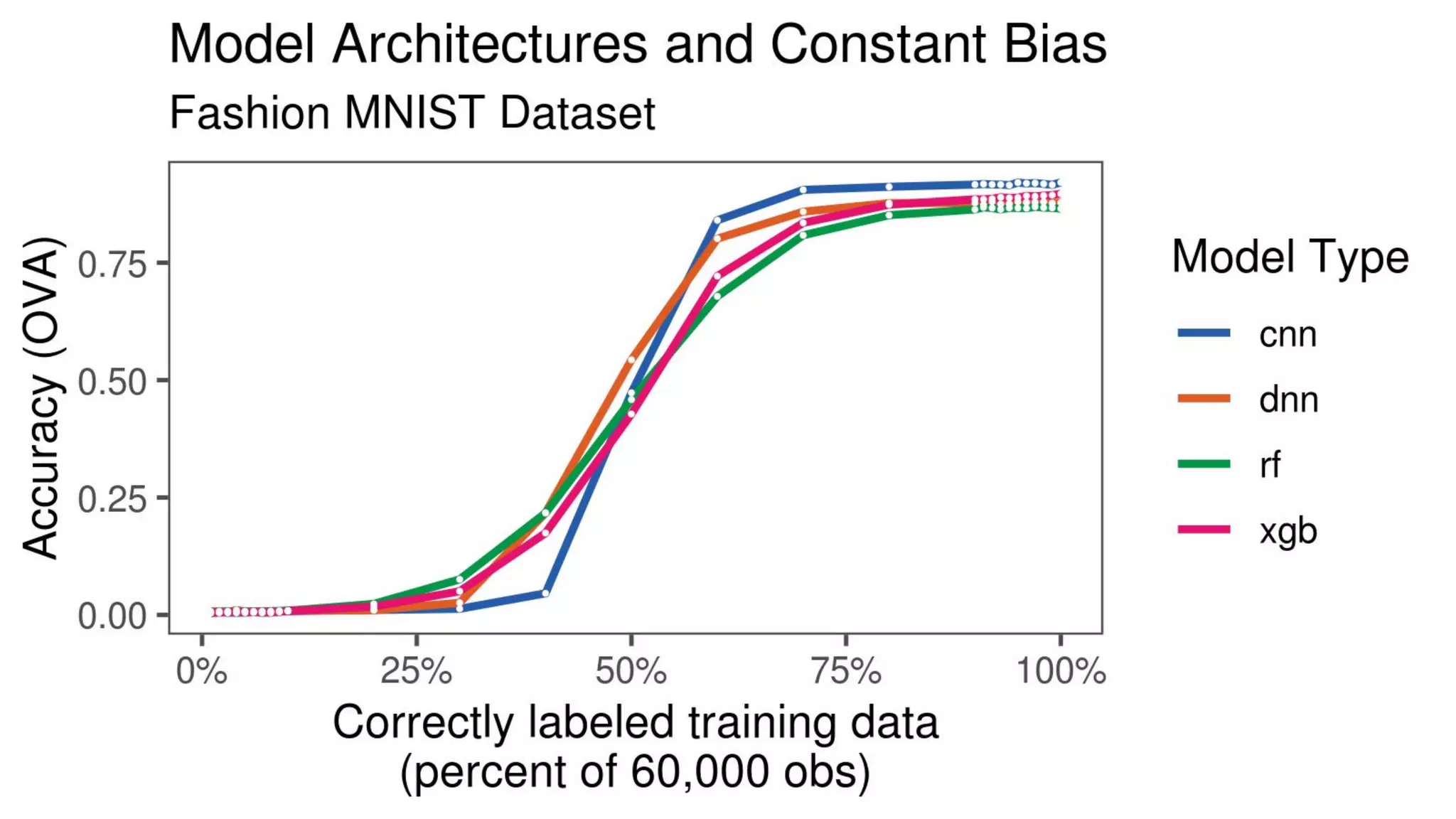
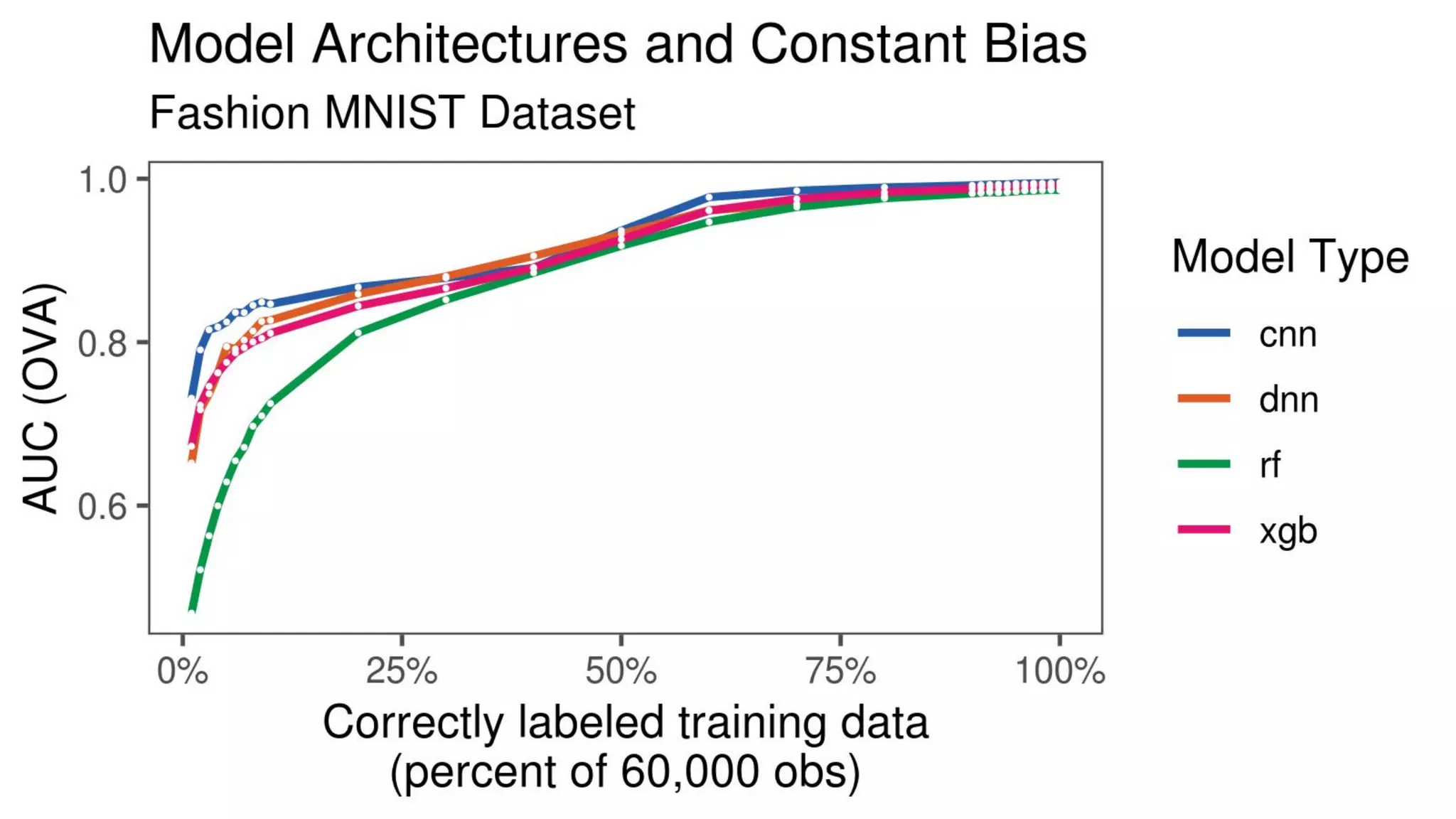
































![[243] turning data into value](https://cdn.slidesharecdn.com/ss_thumbnails/234turningdataintovalue-150915052705-lva1-app6891-thumbnail.jpg?width=640&height=640&fit=bounds)





![[DSC Europe 25] Jovan Bogicevic - Legacy to AI-Driven Defense: Transforming D...](https://cdn.slidesharecdn.com/ss_thumbnails/rsarluadt563hntyfc8q-3-251211083849-3e7bc4c0-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DSC Europe 25] Marko Krstic - Understanding the AI Threat Landscape - Risks,...](https://cdn.slidesharecdn.com/ss_thumbnails/tiyim1ins5jvbrvzpzla-2-251209104645-c69d3553-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DSC Europe 25] Dusan Pavlov - There Is No Spoon: Inferring Vision from Neura...](https://cdn.slidesharecdn.com/ss_thumbnails/wg0v1umoqjm4nnbd3p0v-there-is-no-spoon-251205085715-6d81d6c5-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Vladimir Jelic - The AI-Driven Security Shift From Reactive D...](https://cdn.slidesharecdn.com/ss_thumbnails/6g5gj25mtjwayniqem1t-6-251209104645-7a5a5fc6-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DSC Europe 25] Milan Sekuloski - Data, Defence, and Development: Cybersecuri...](https://cdn.slidesharecdn.com/ss_thumbnails/dfrkwwx4qly6atqpbl4z-4-251209104645-c3d4b0ca-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DSC Europe 25] Dragana Ilic - AI for Big Data in Astronomy.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/8palya86qaatvjhva1ms-2-dragana-ilic-ai-ilic-251208151906-652b819c-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Milan Zdravkovic - The road less traveled in District Heating...](https://cdn.slidesharecdn.com/ss_thumbnails/nfaboniqwsz4ucyctnmy-2-milan-zdravkovic-dsc2025-the-road-less-traveled-in-district-heating-operation-251208151905-f56388a5-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Dobrica Cosic - Savings by the Second: How Dynamic Pricing an...](https://cdn.slidesharecdn.com/ss_thumbnails/znp09f3smtqz3w2sq6wn-1-dobrica-cosic-savings-by-the-second-how-dynamic-pricing-and-smart-data-are-bu-251208151905-26e6f41e-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Goran Obradovic - The Rise of Sovereign AI: Building the Regi...](https://cdn.slidesharecdn.com/ss_thumbnails/7nw2xxixrxqdxvrb5wca-6-251205085714-ab09a2ac-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Marija Vlajkovic & Andrea Radonjanin - Integration of AI tool...](https://cdn.slidesharecdn.com/ss_thumbnails/qf1jrglttoc3bm8s3aop-final-integration-of-ai-tools-251208151905-394f3a6a-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DSC Europe 25] Bogdan Daniel Maruneac - AI - It starts with you.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/odov3snhrcqs9hx5ny2n-4-251205085715-f1daacfe-thumbnail.jpg?width=640&height=640&fit=bounds)
