Downloaded 18 times









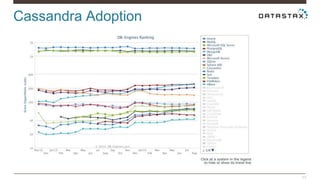
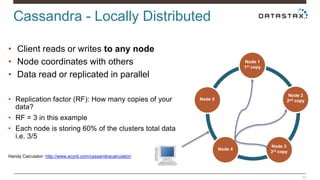
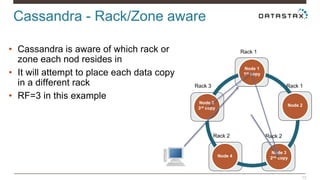
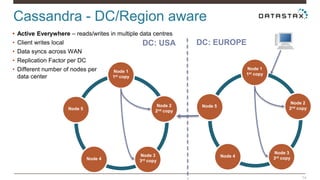
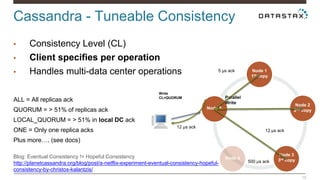
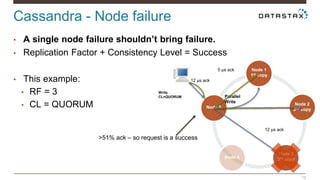
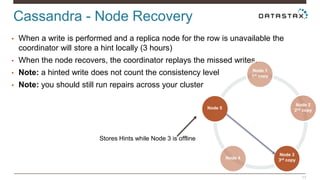
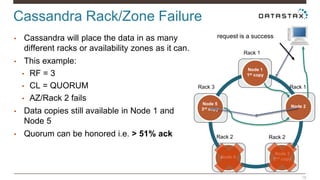



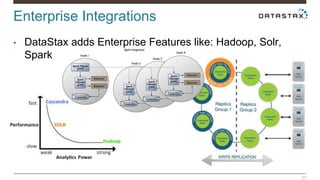
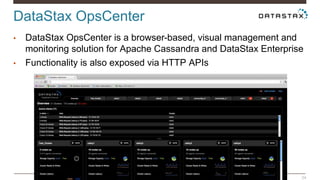








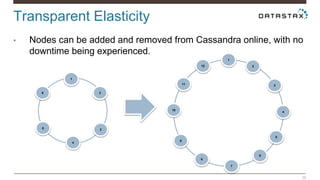
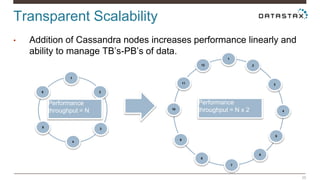

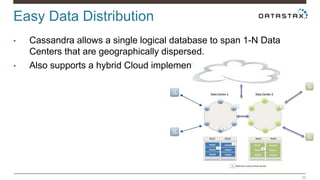

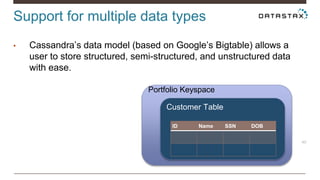







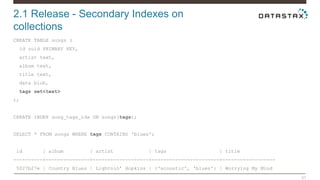

Christian Johannsen presents on evaluating Apache Cassandra as a cloud database. Cassandra is optimized for cloud infrastructure with features like transparent elasticity, scalability, high availability, easy data distribution and redundancy. It supports multiple data types, is easy to manage, low cost, supports multiple infrastructures and has security features. A demo of DataStax OpsCenter and Apache Spark on Cassandra is shown.































![Webinar: Network Automation [Tips & Tricks]](https://cdn.slidesharecdn.com/ss_thumbnails/webinar-nw-automation-august-2016-160901213303-thumbnail.jpg?width=640&height=640&fit=bounds)





















































