Download as PDF, PPTX
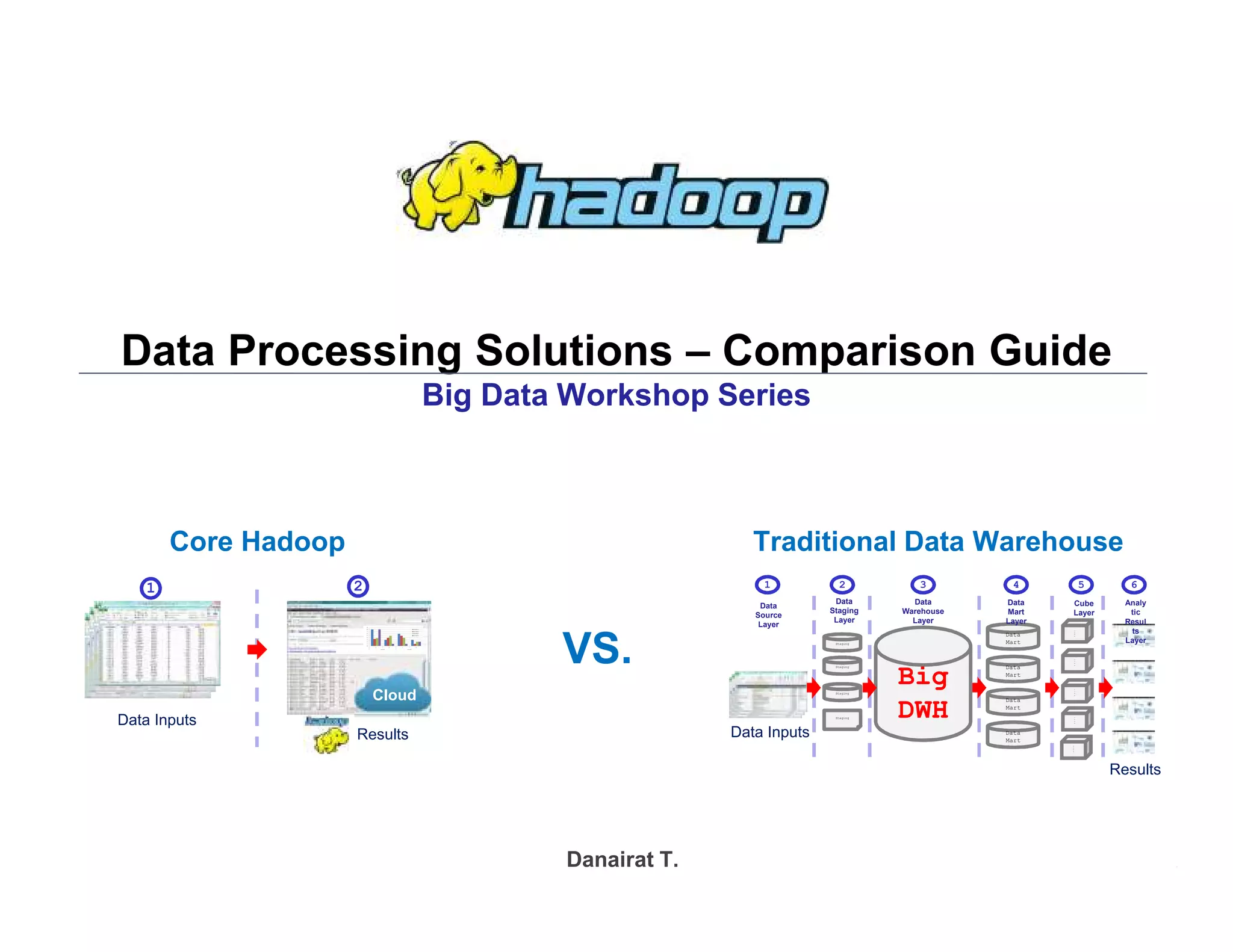
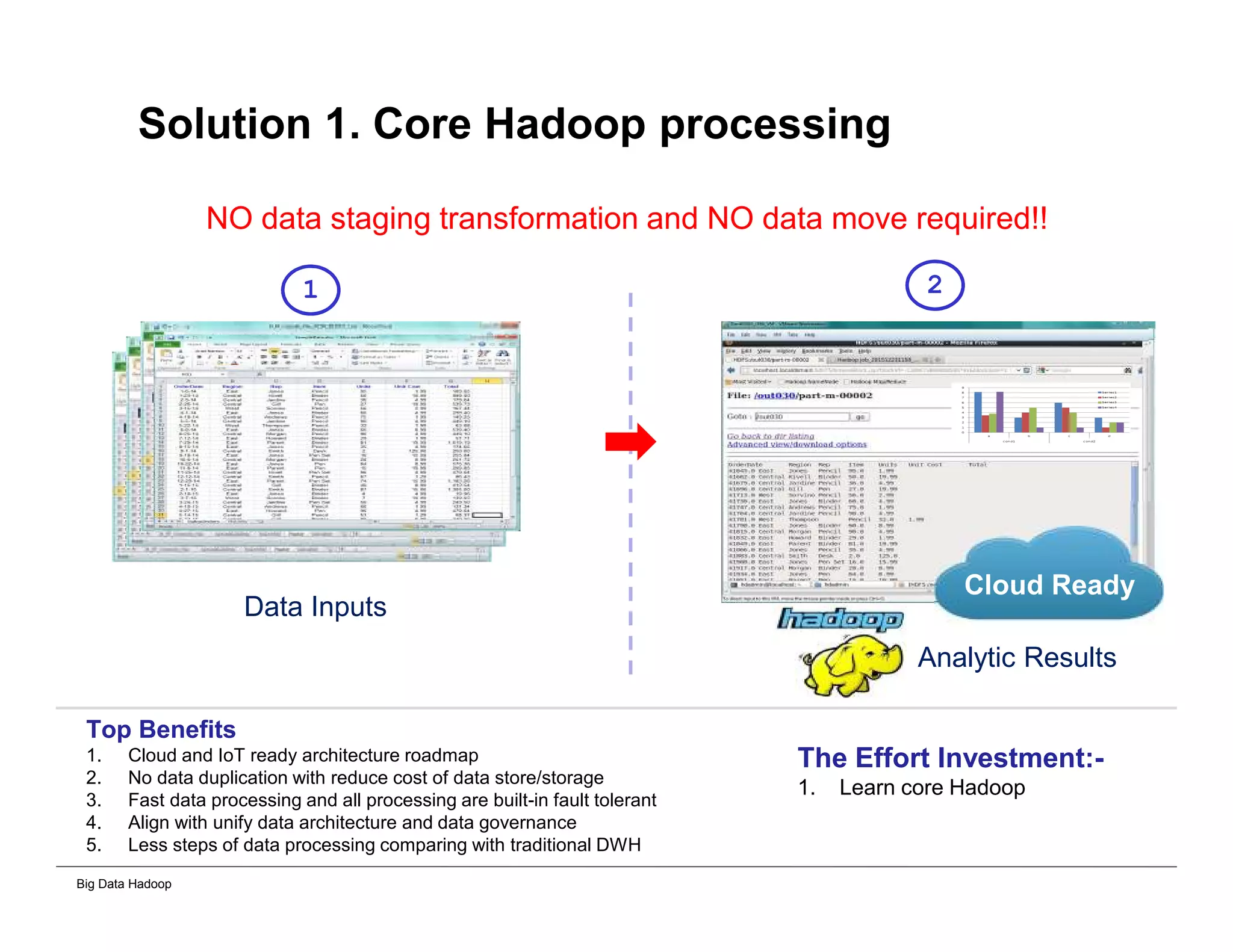
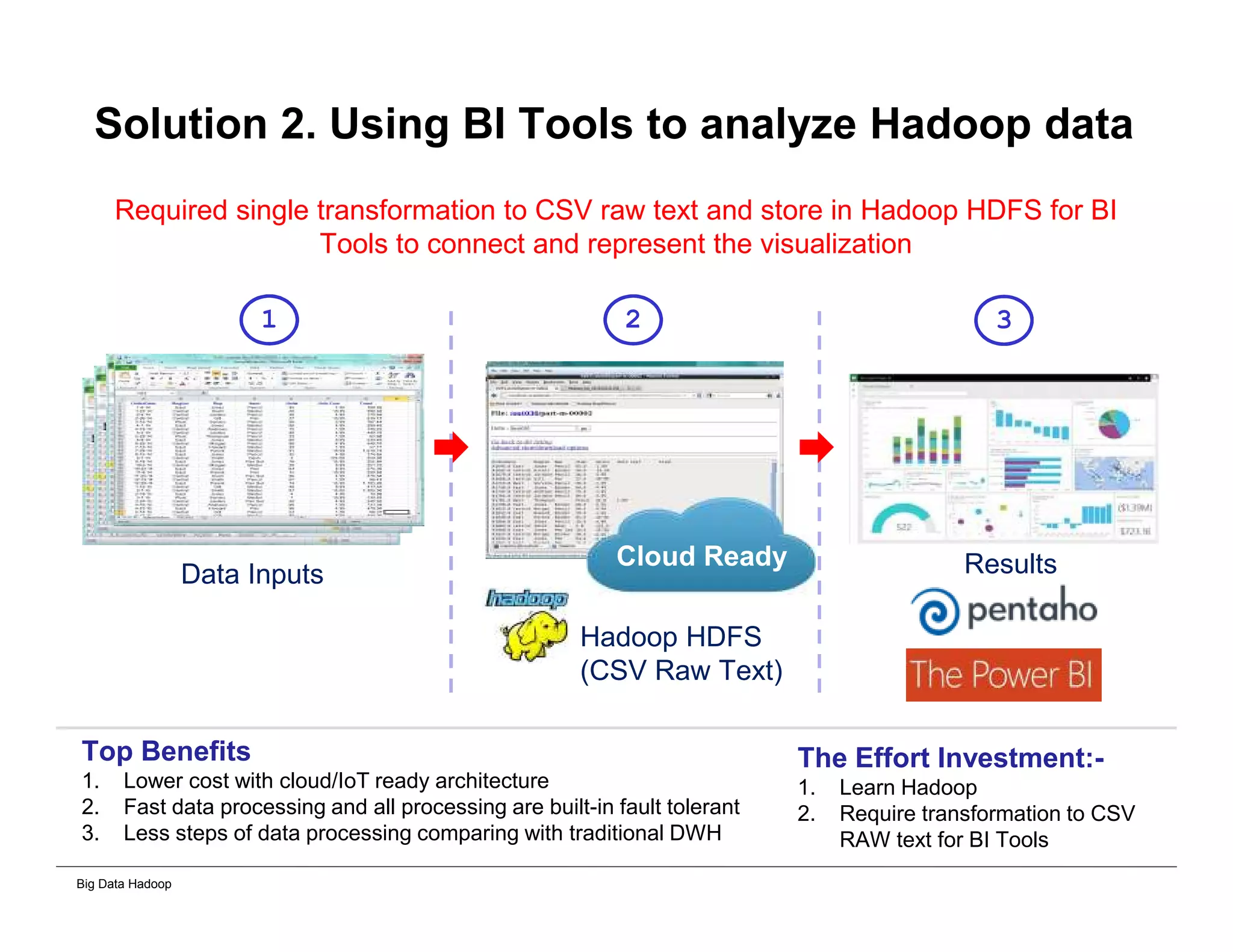
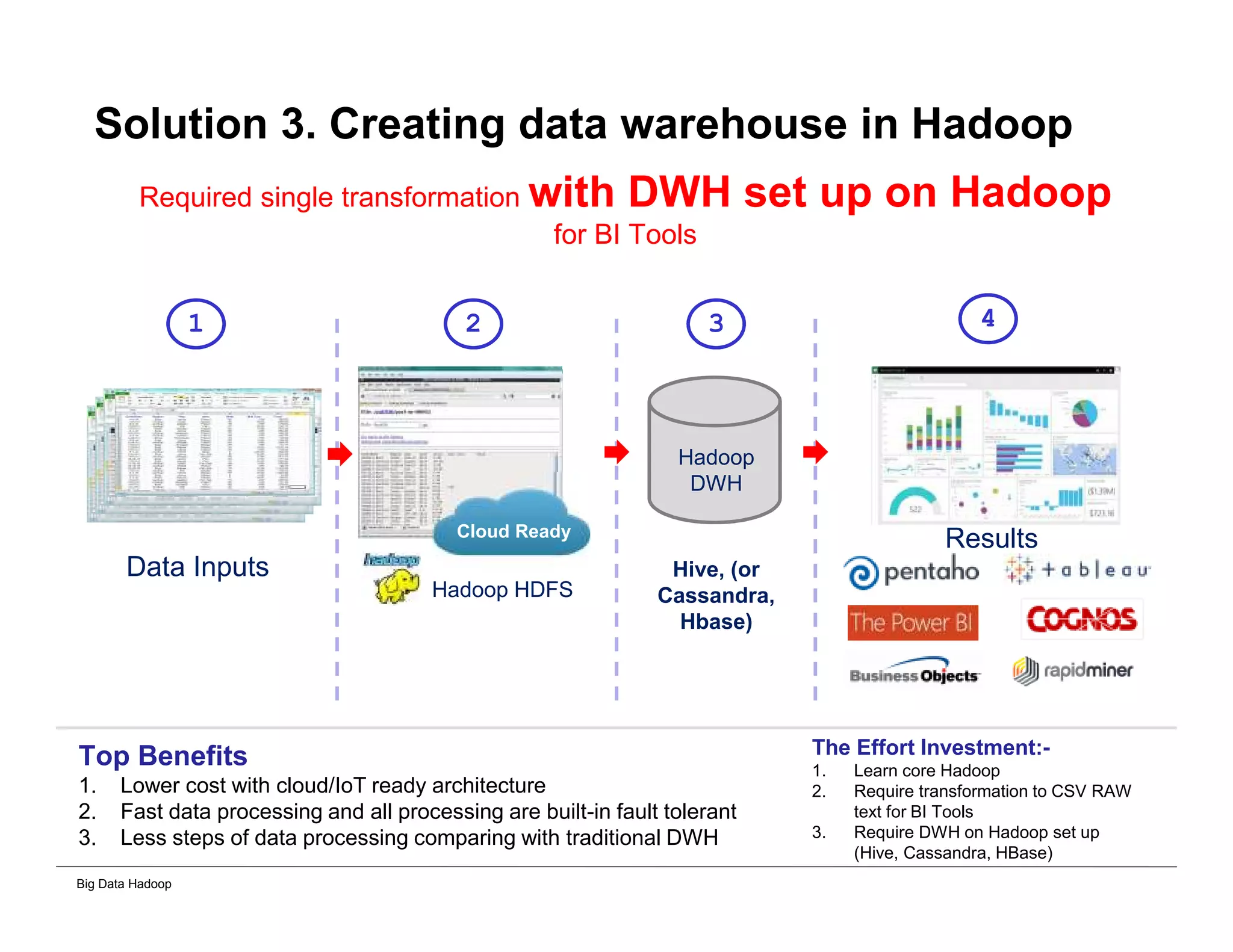
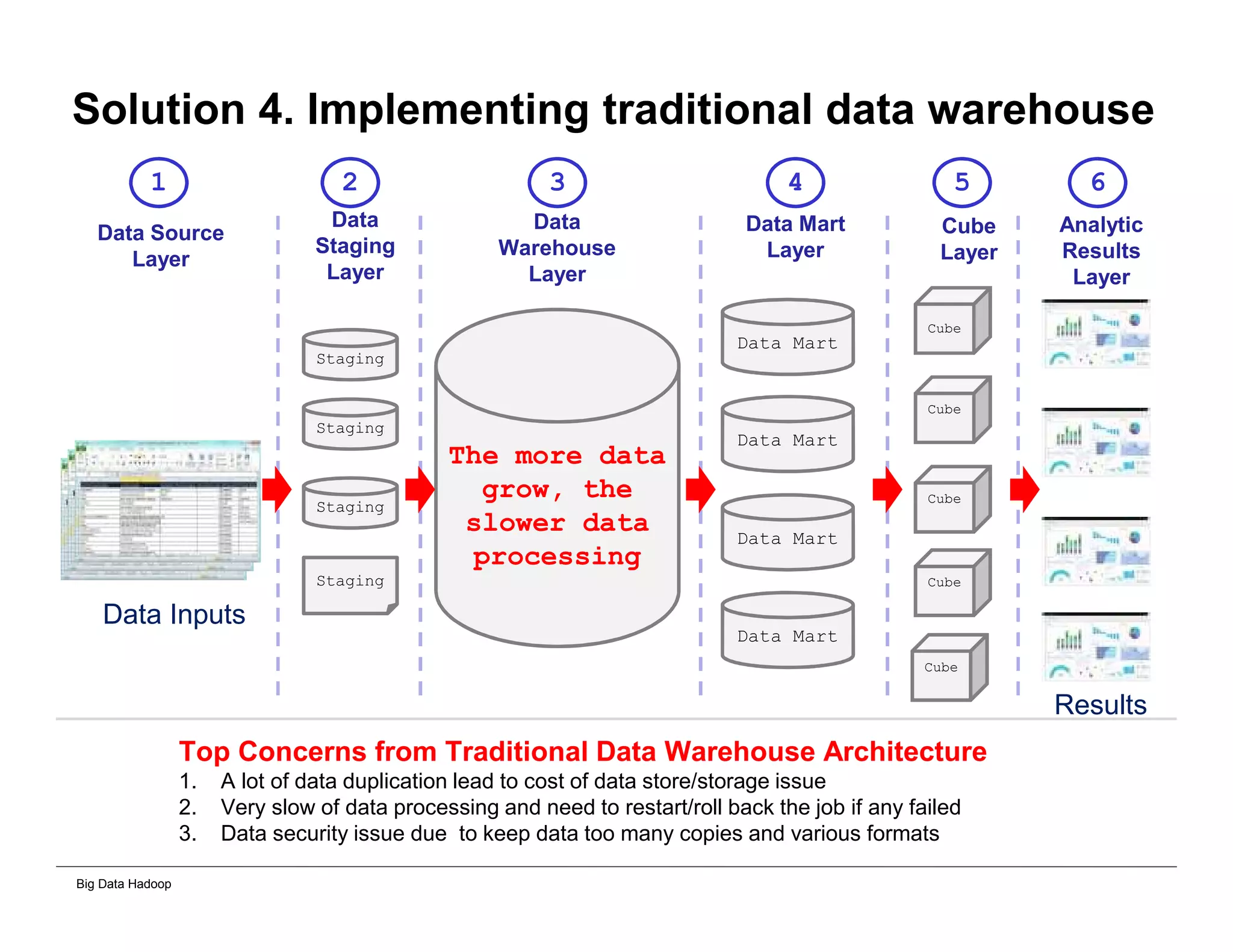
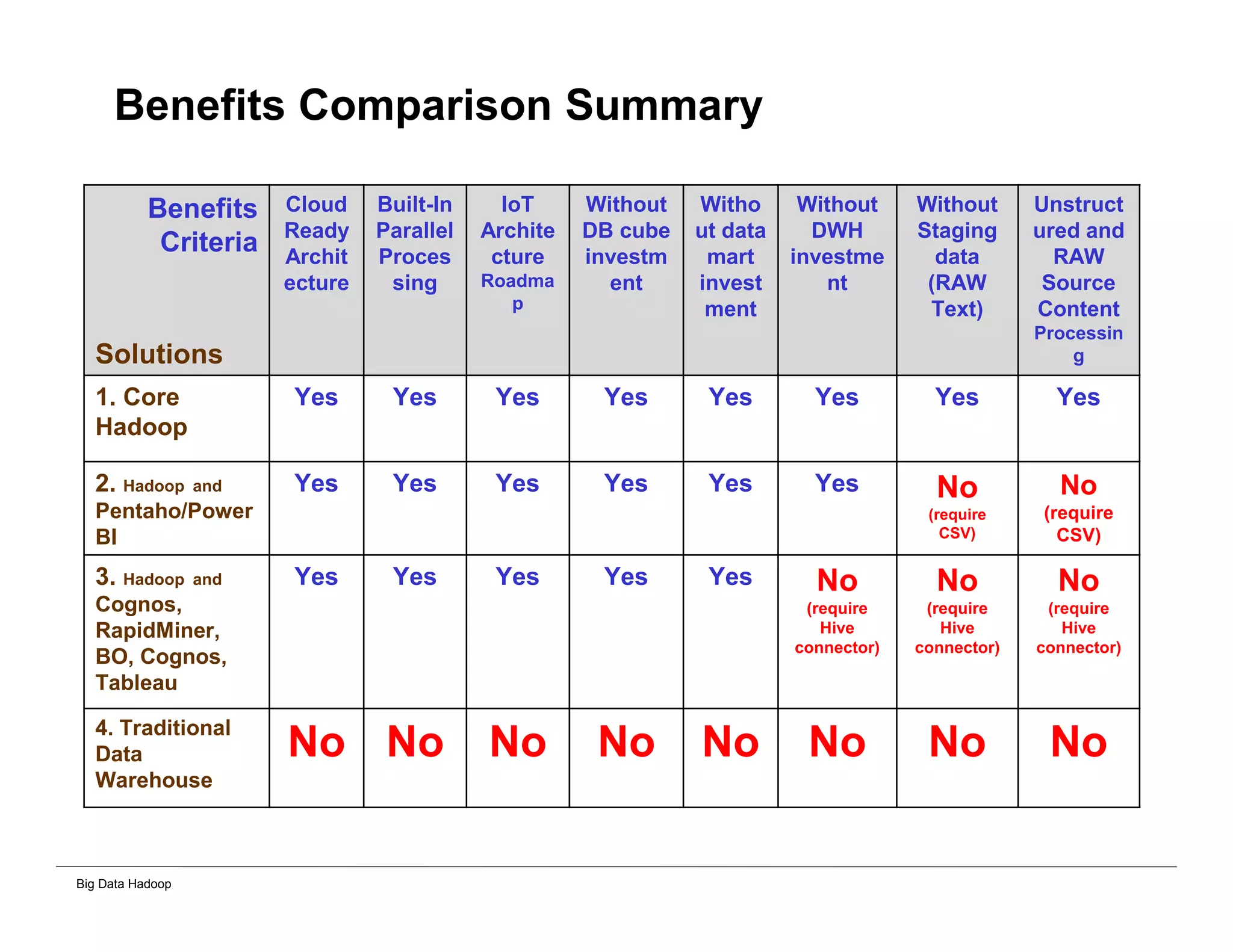

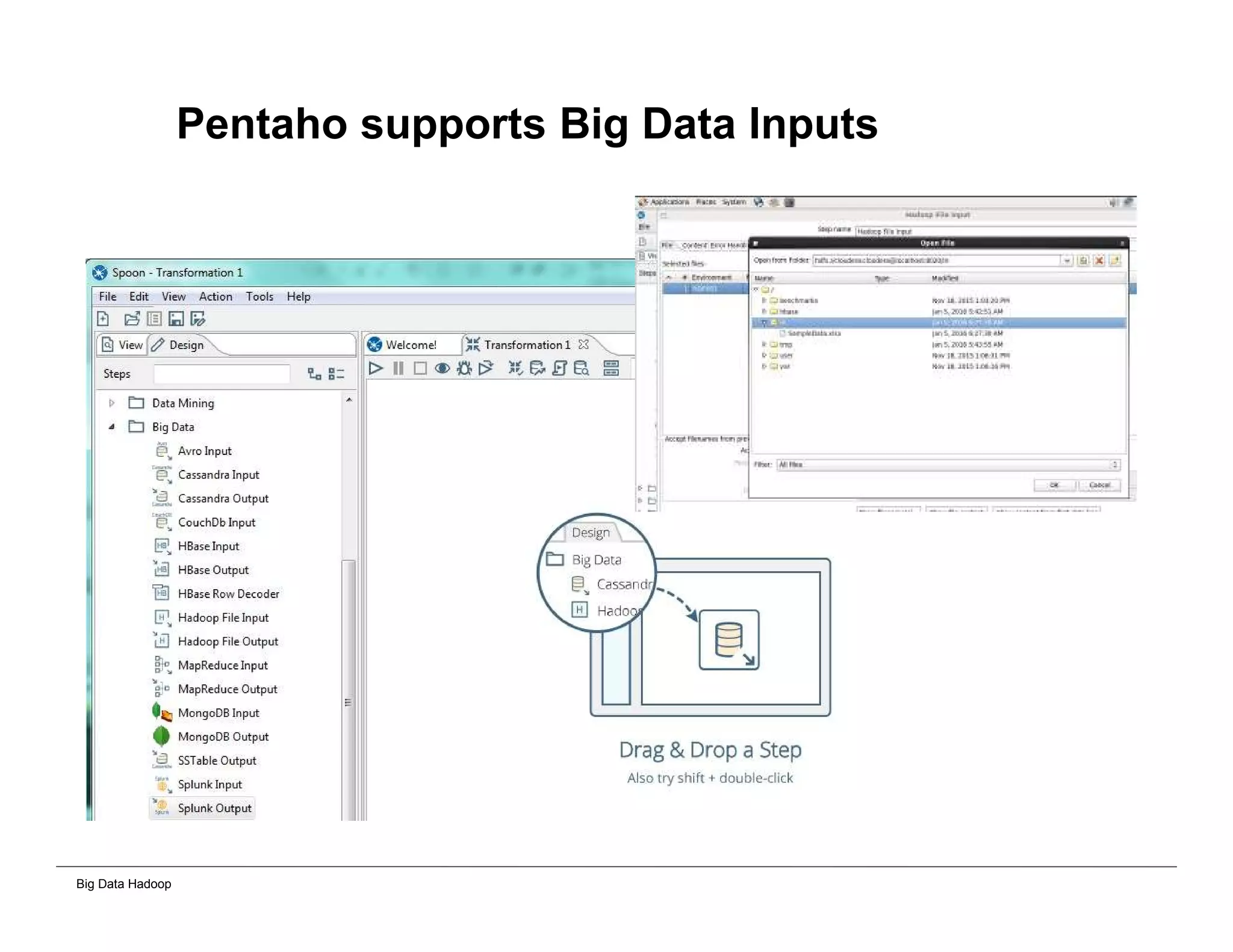
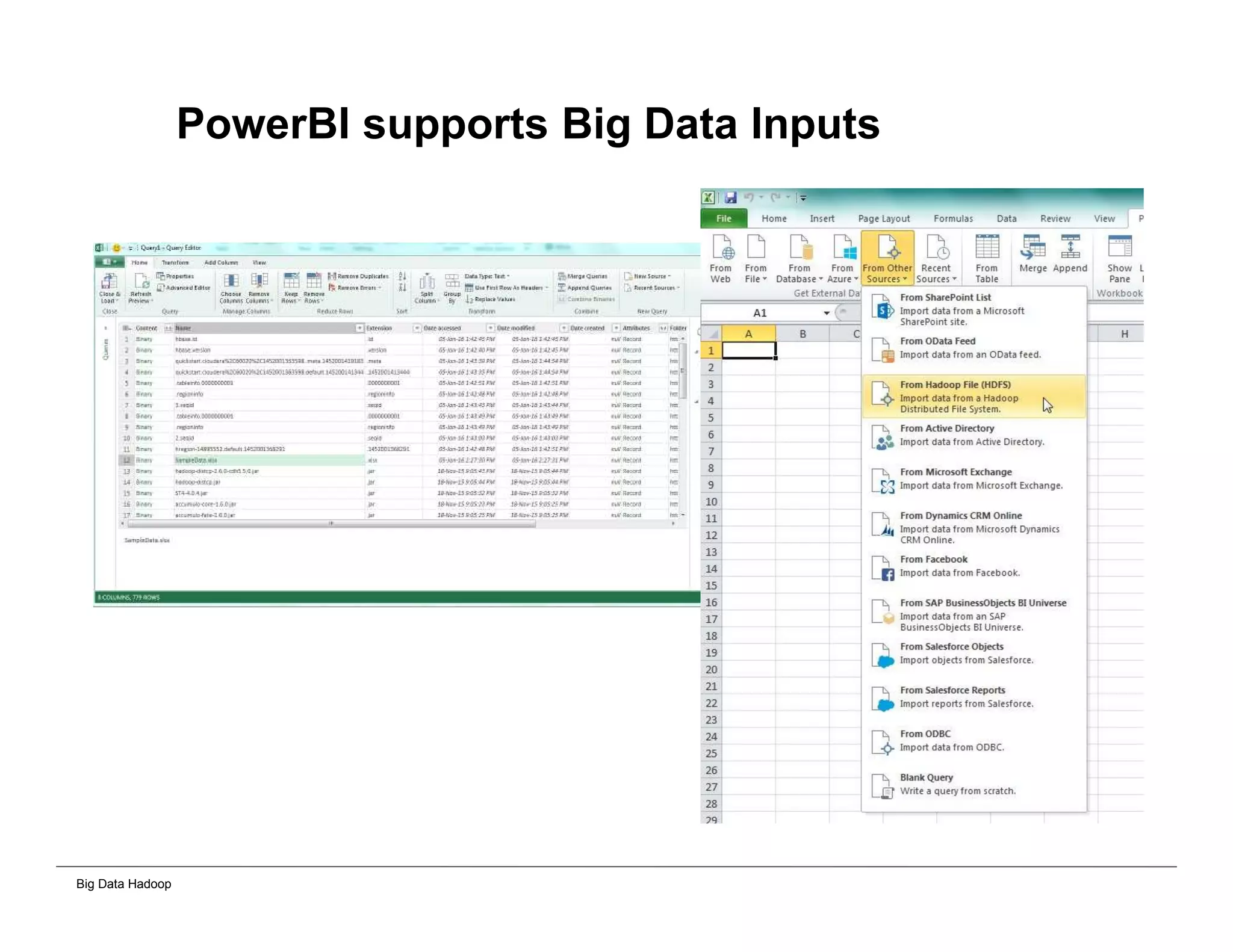
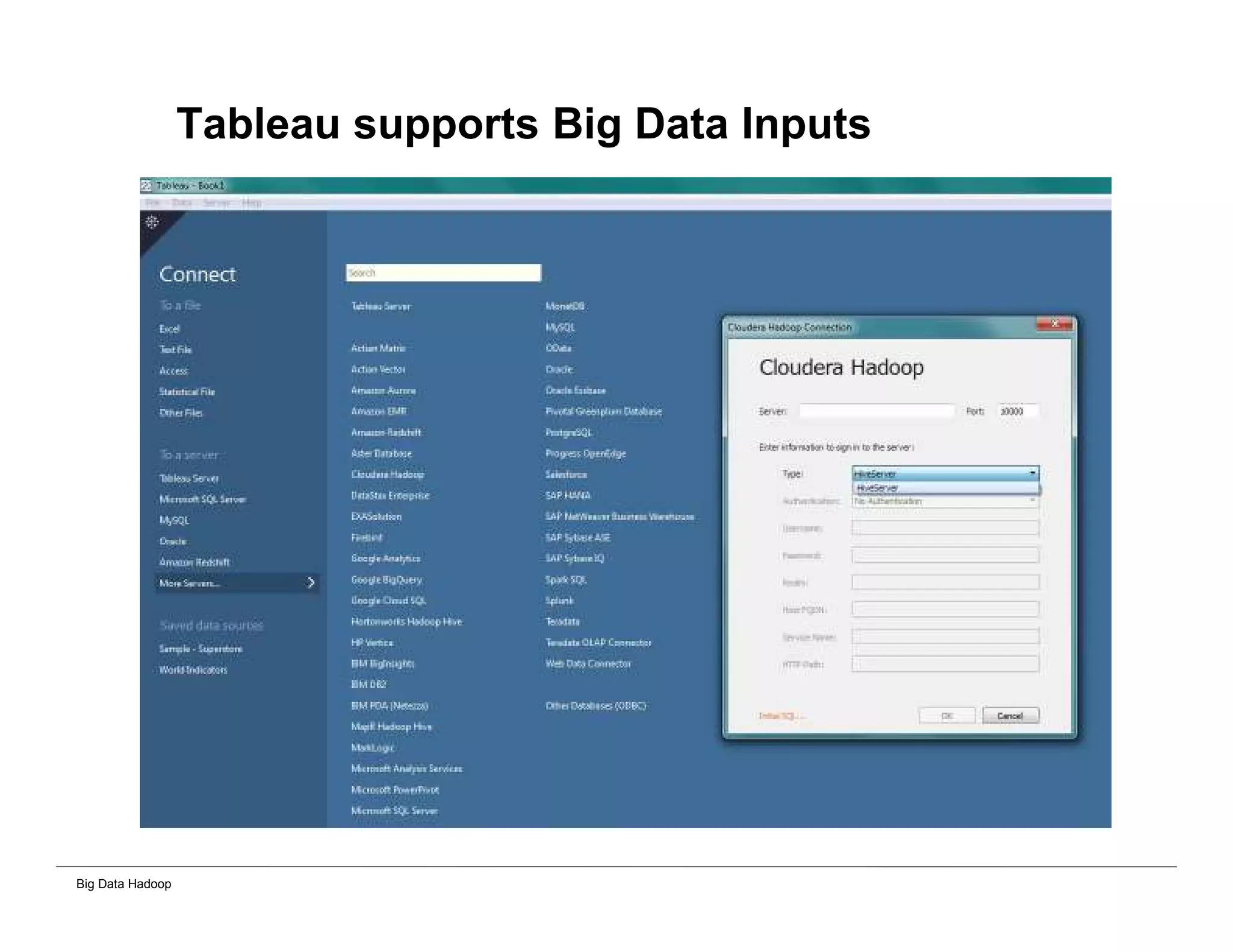
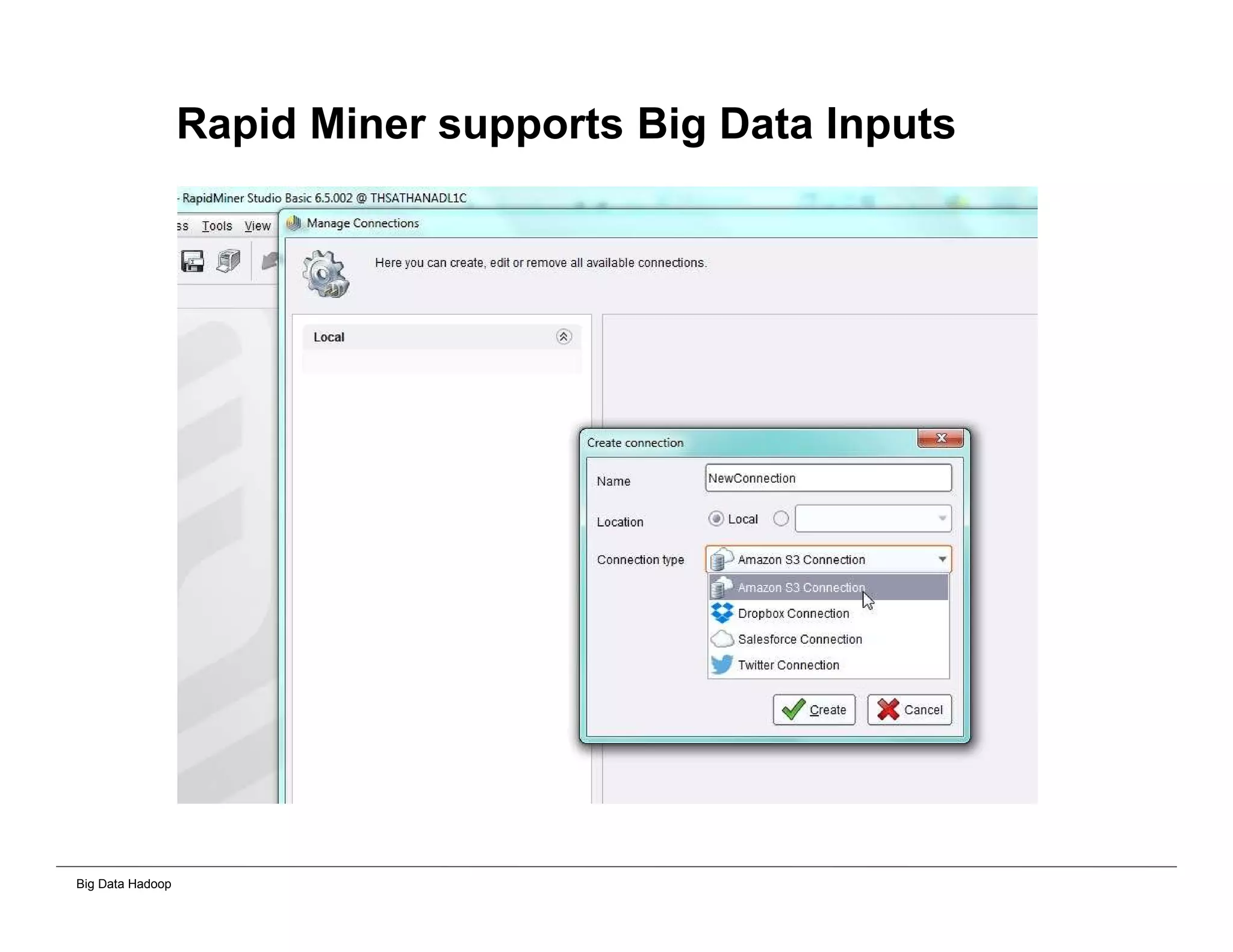

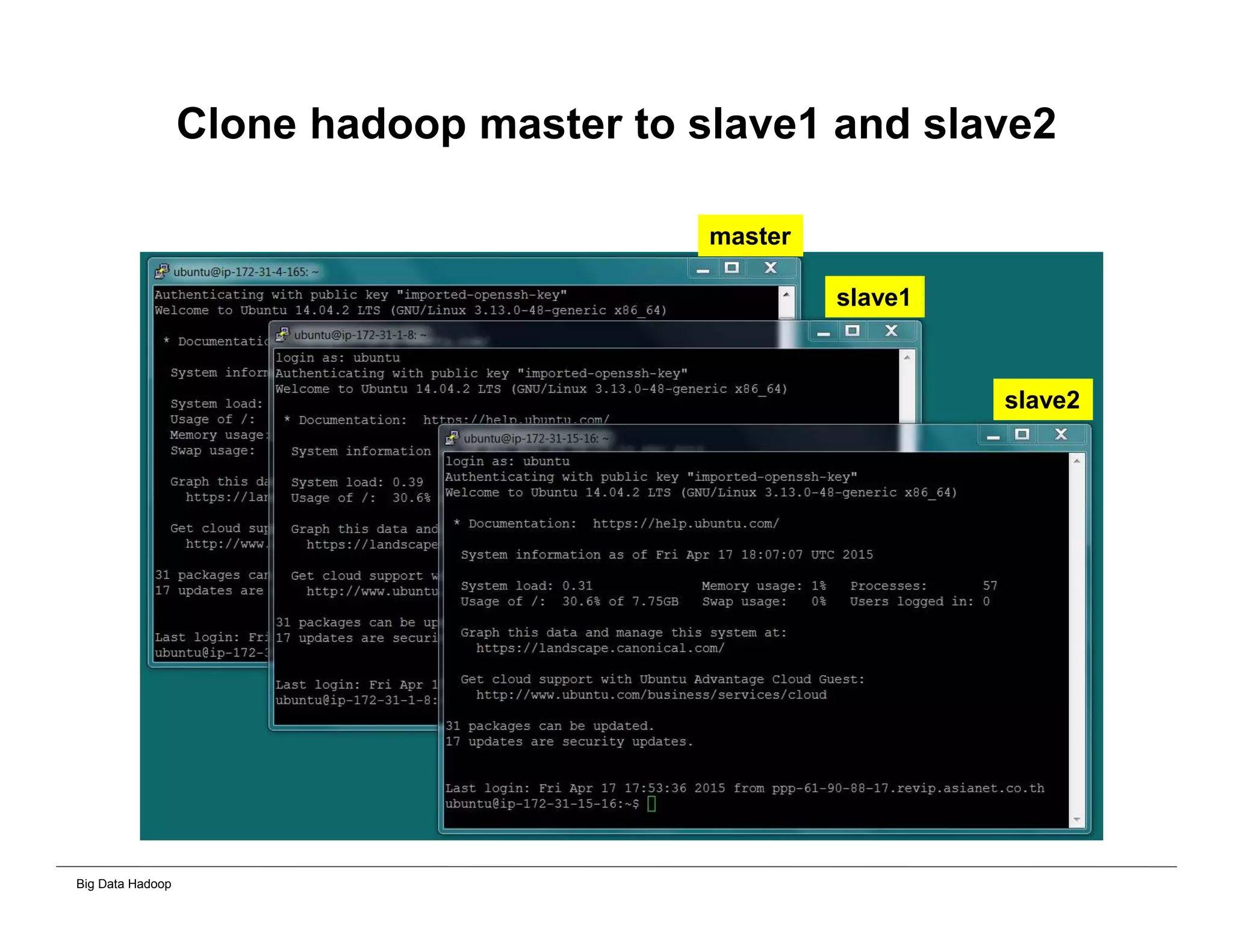
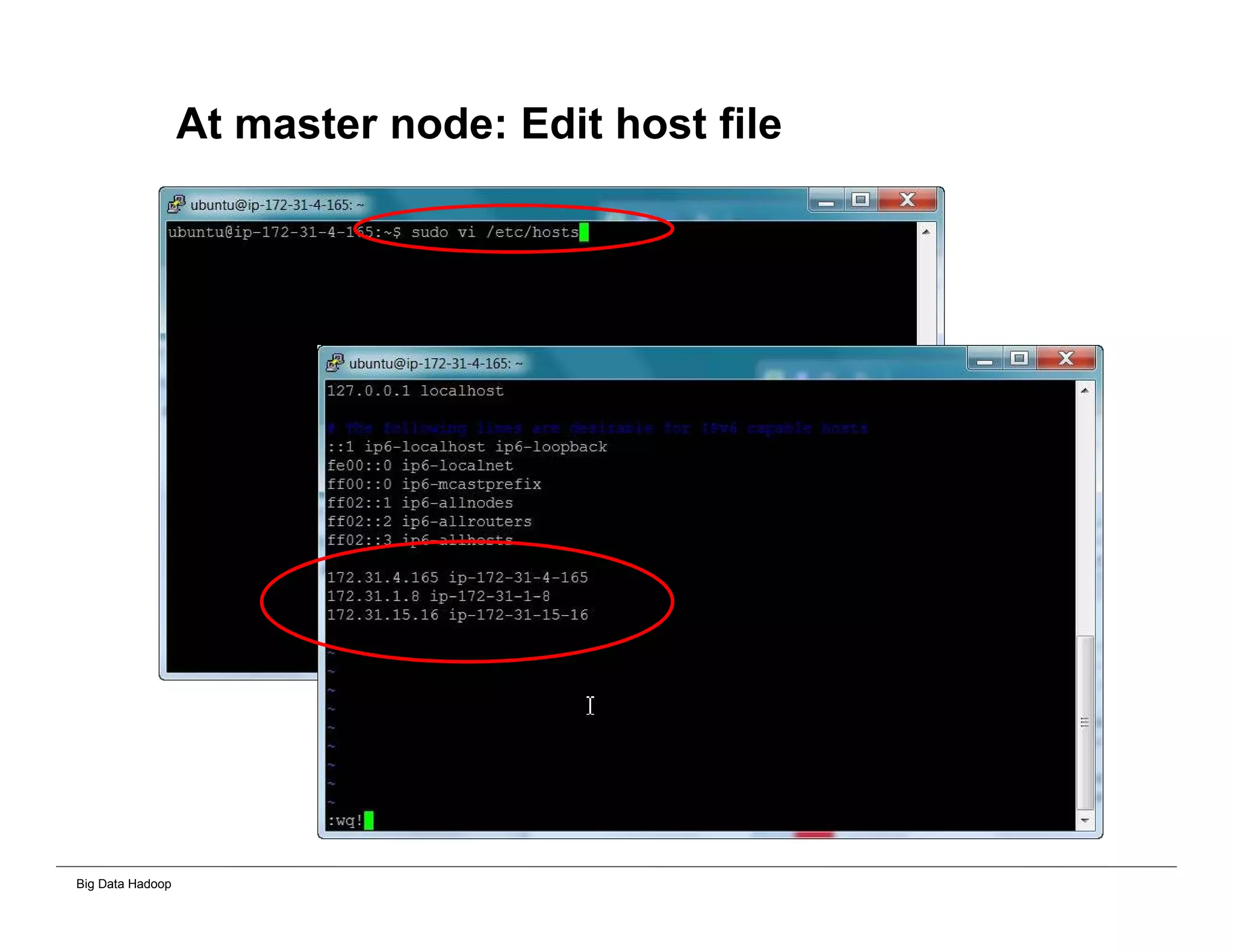


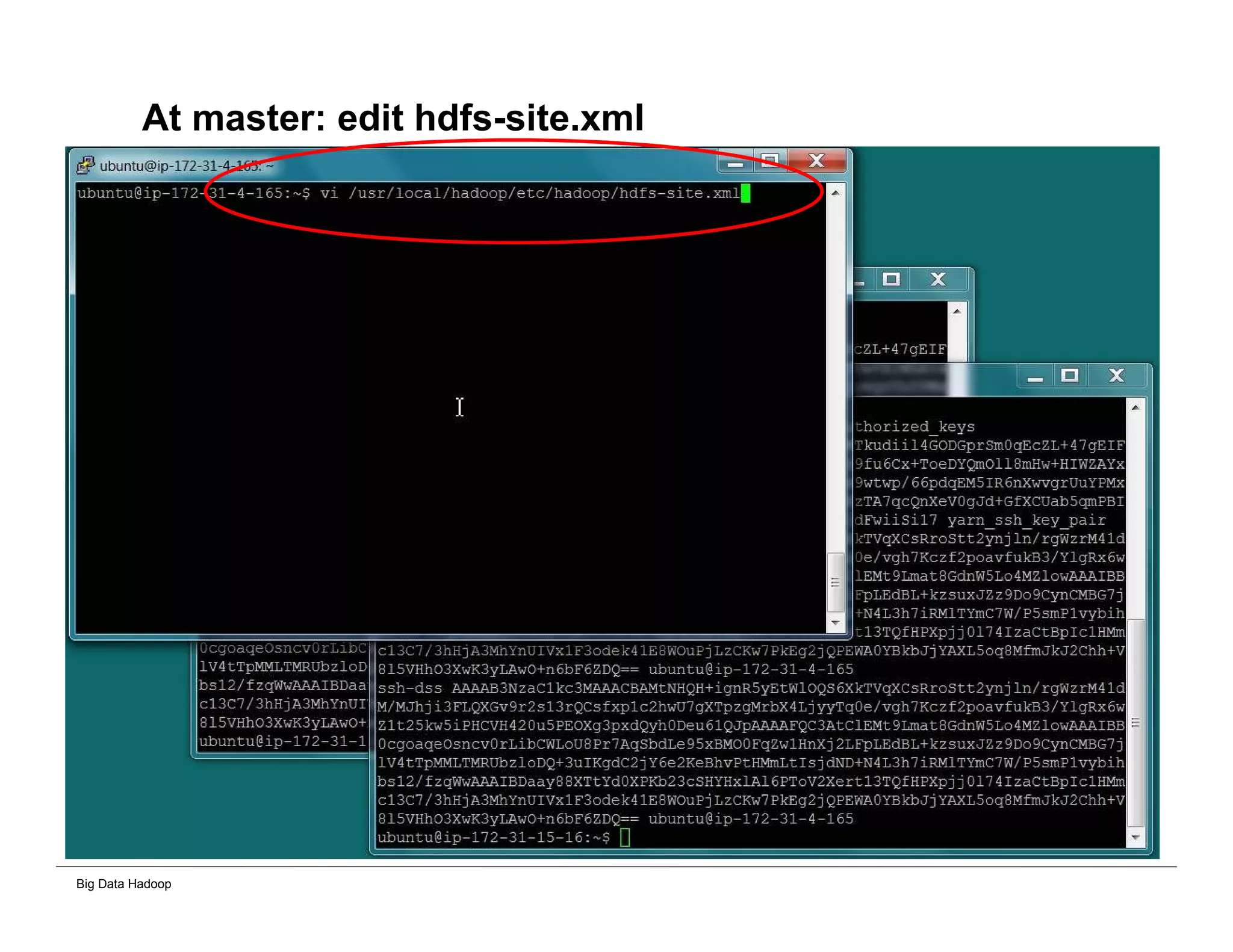
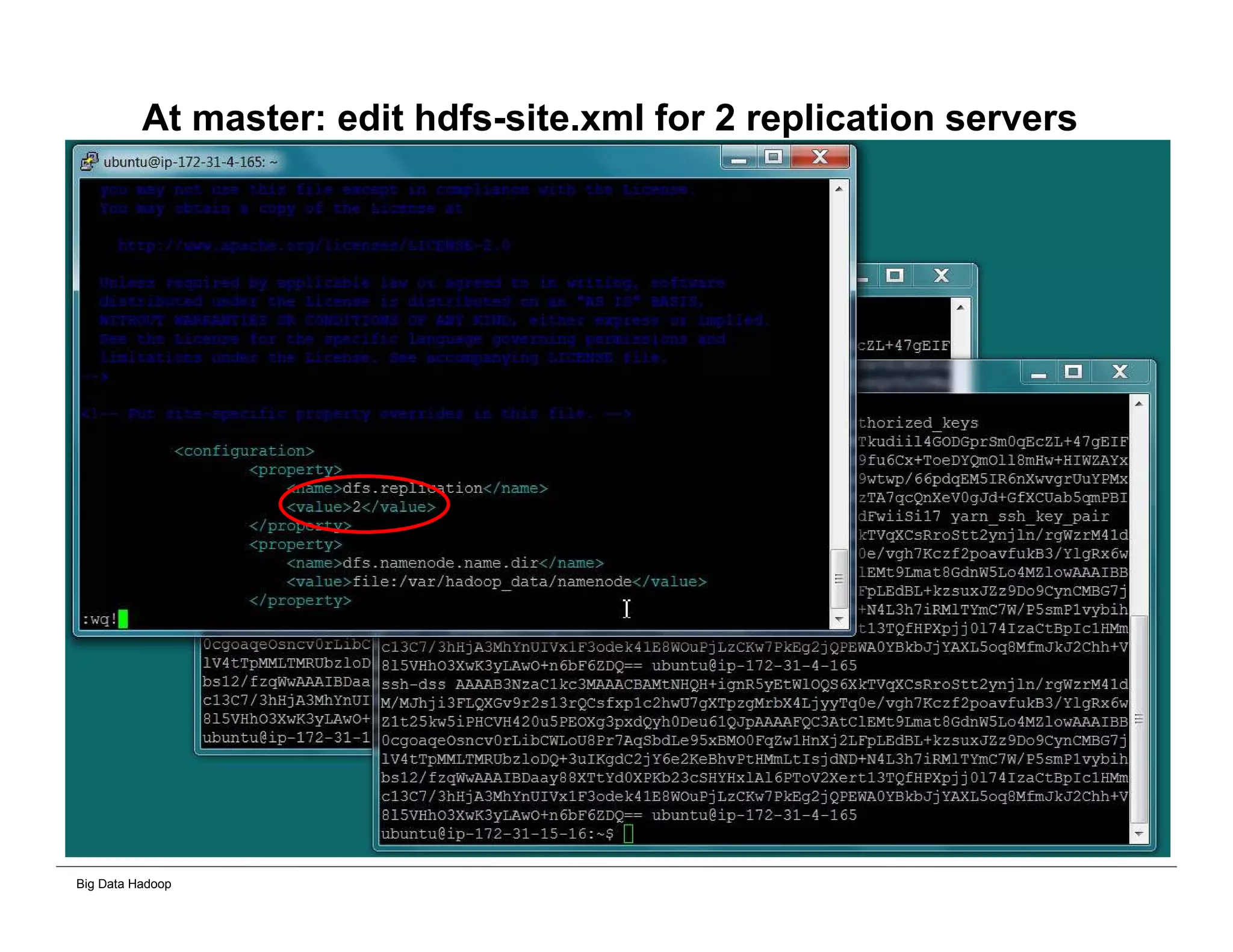
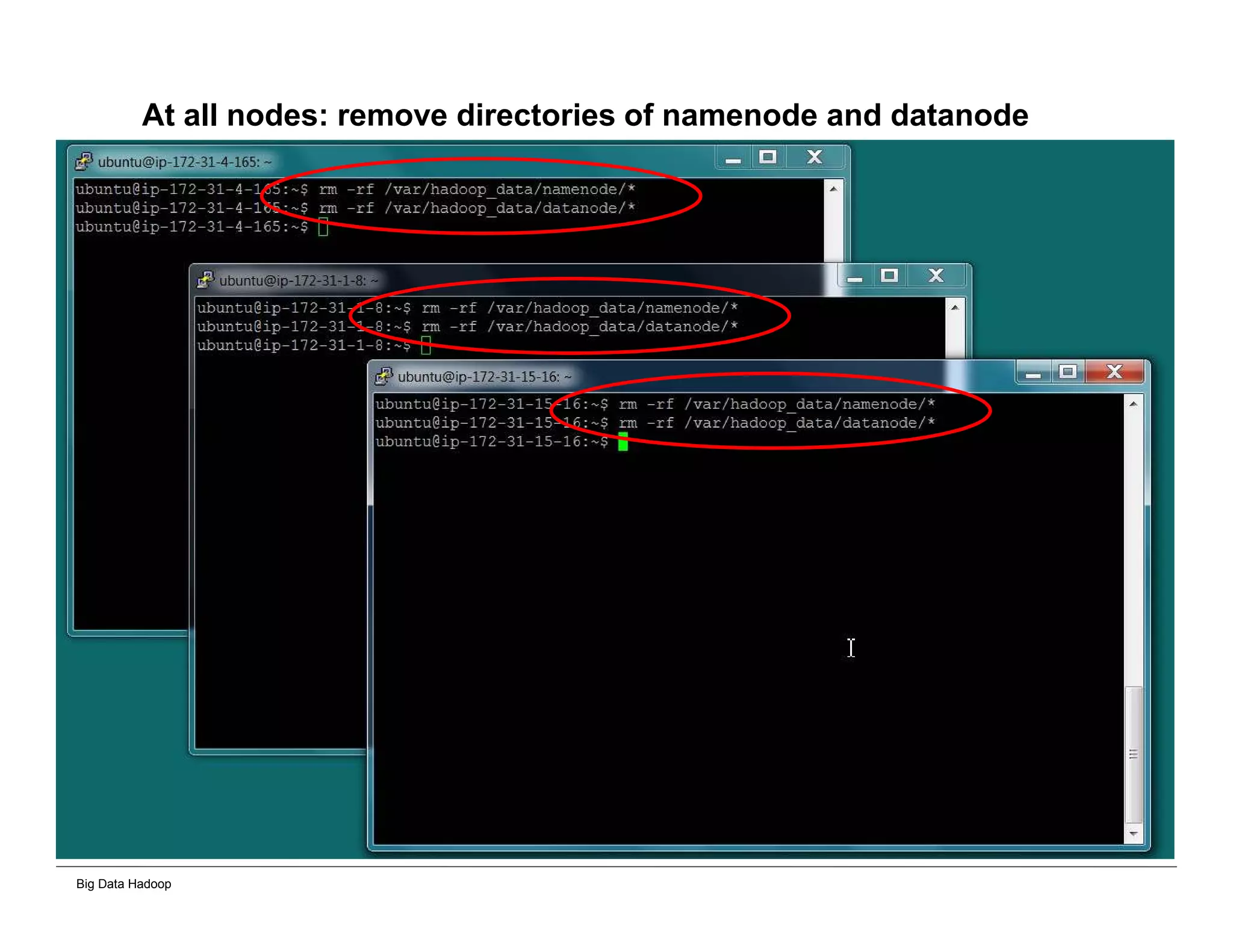
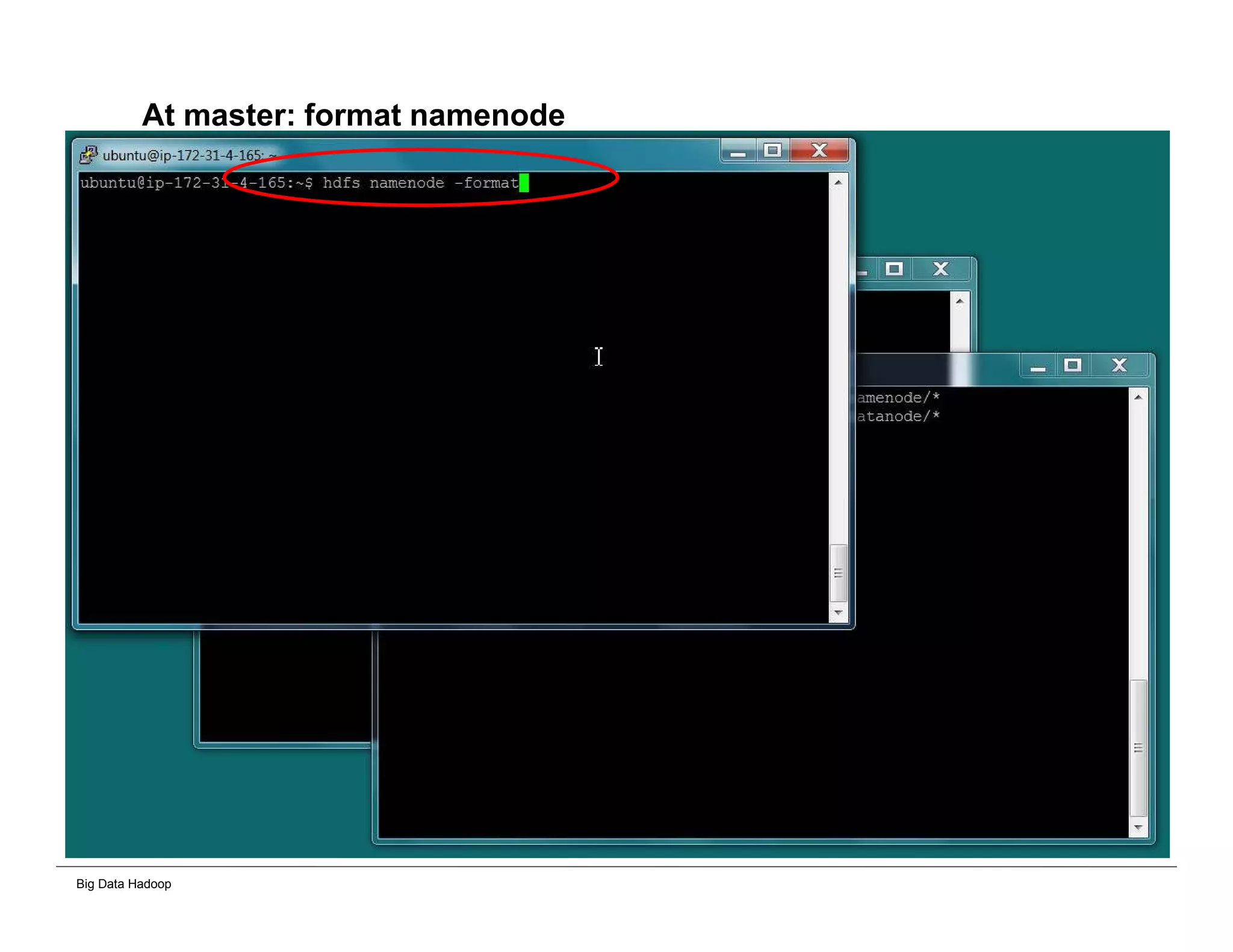
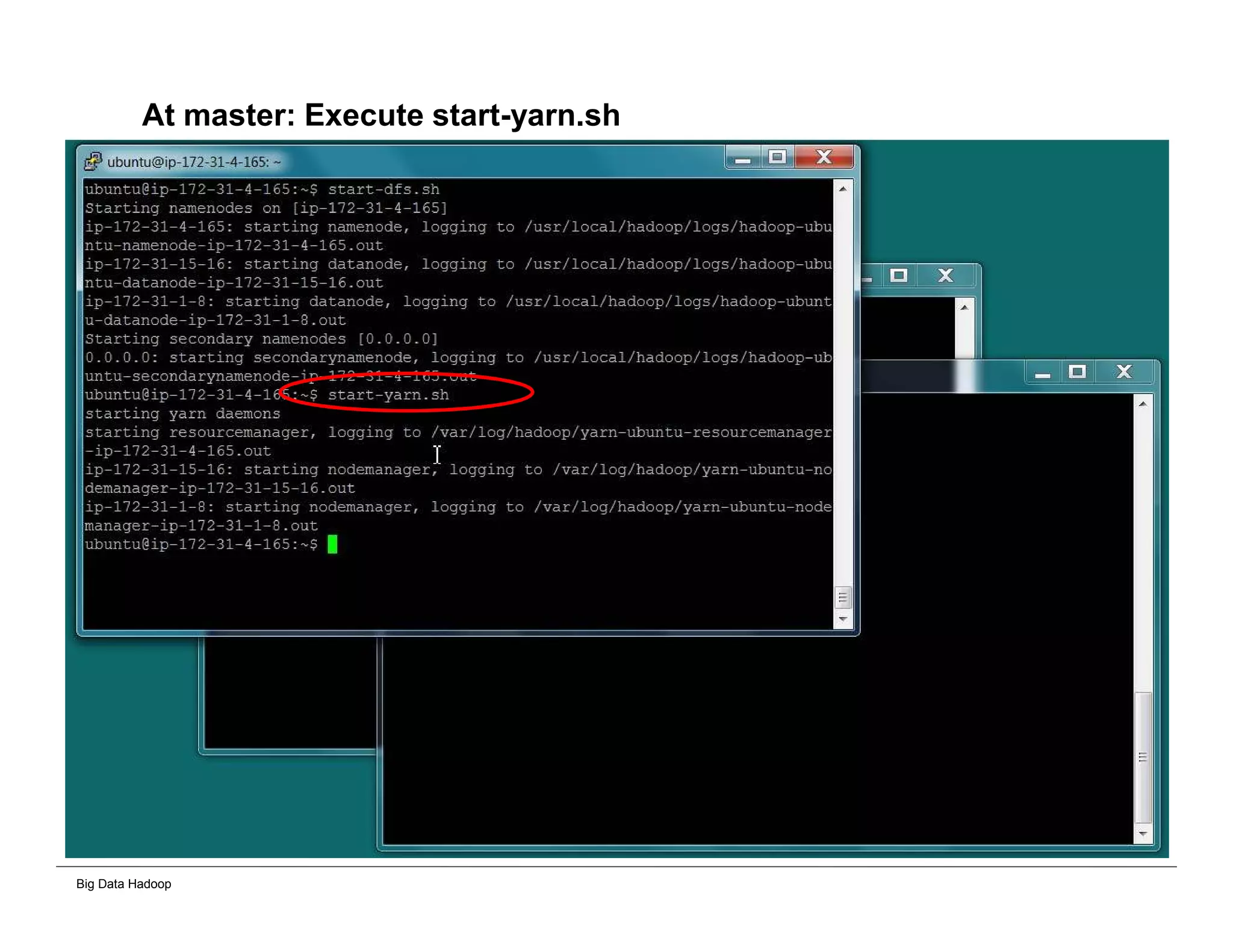
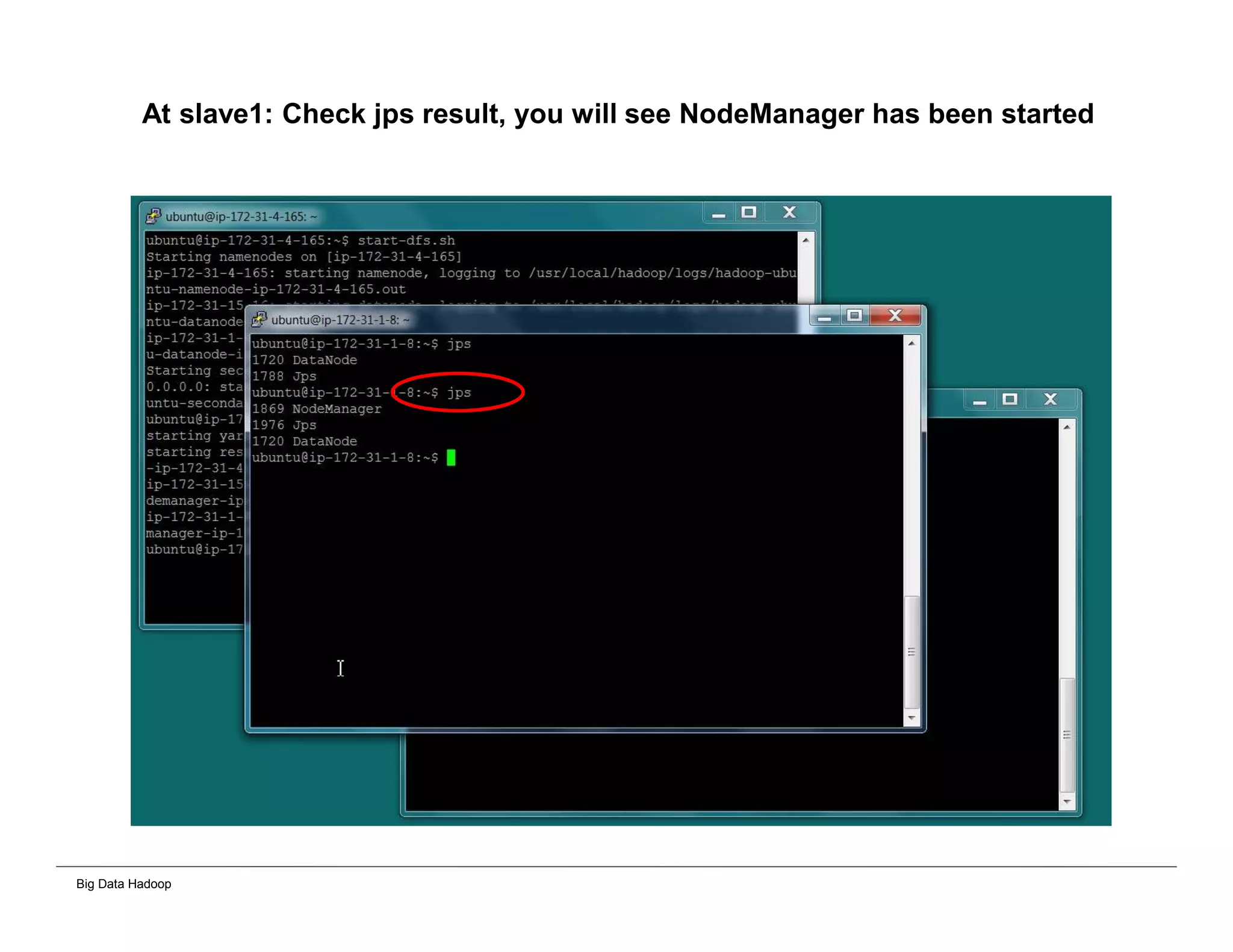
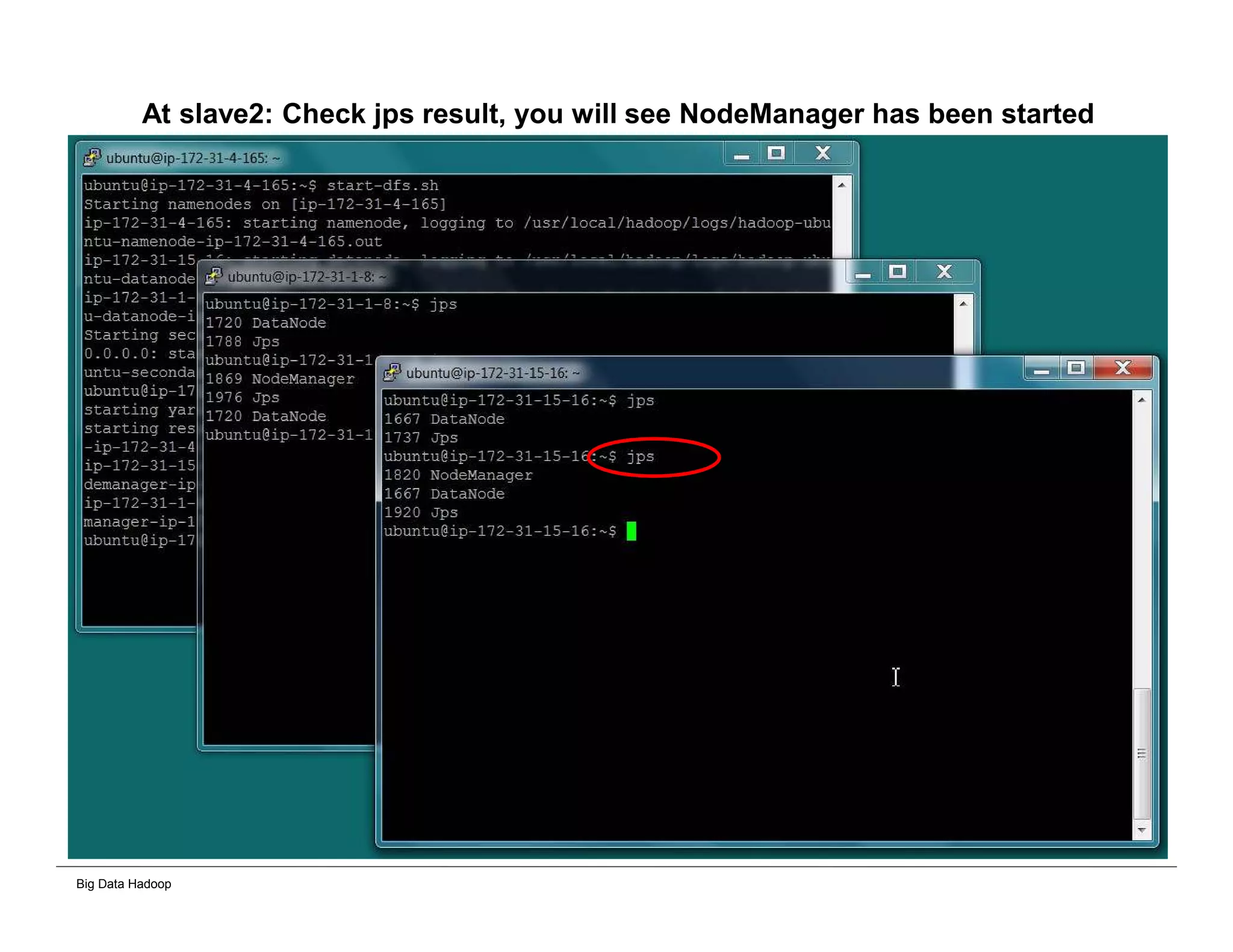

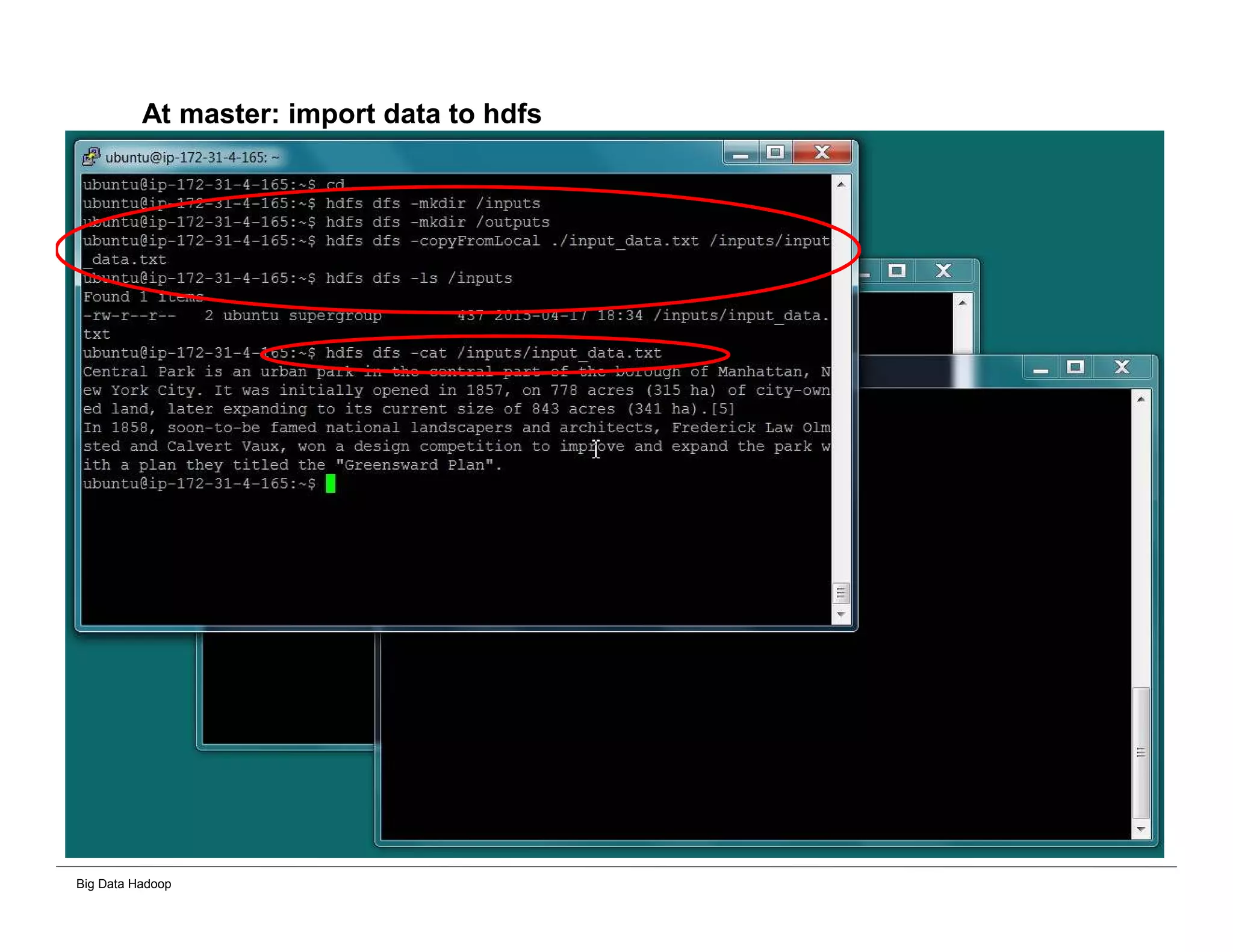
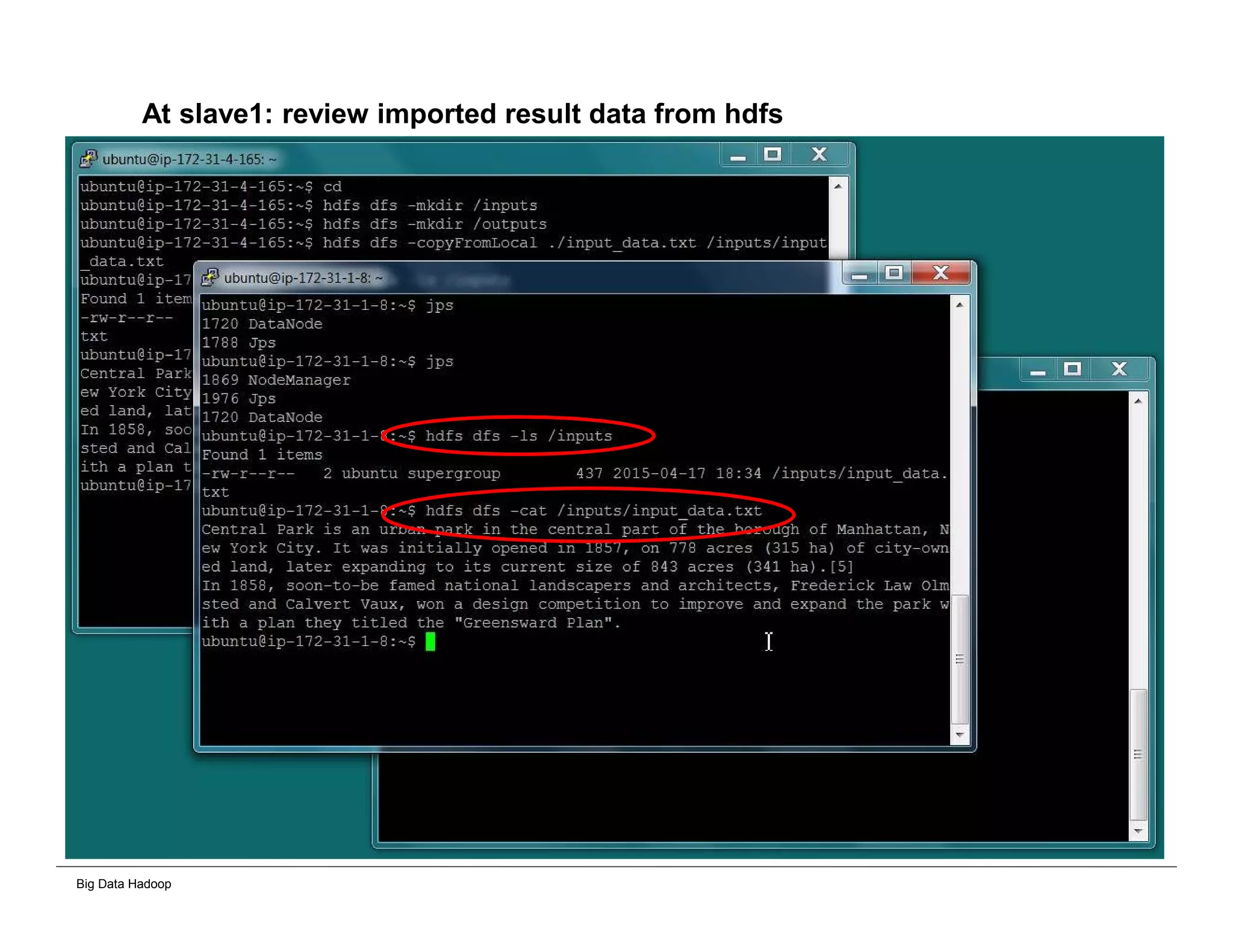
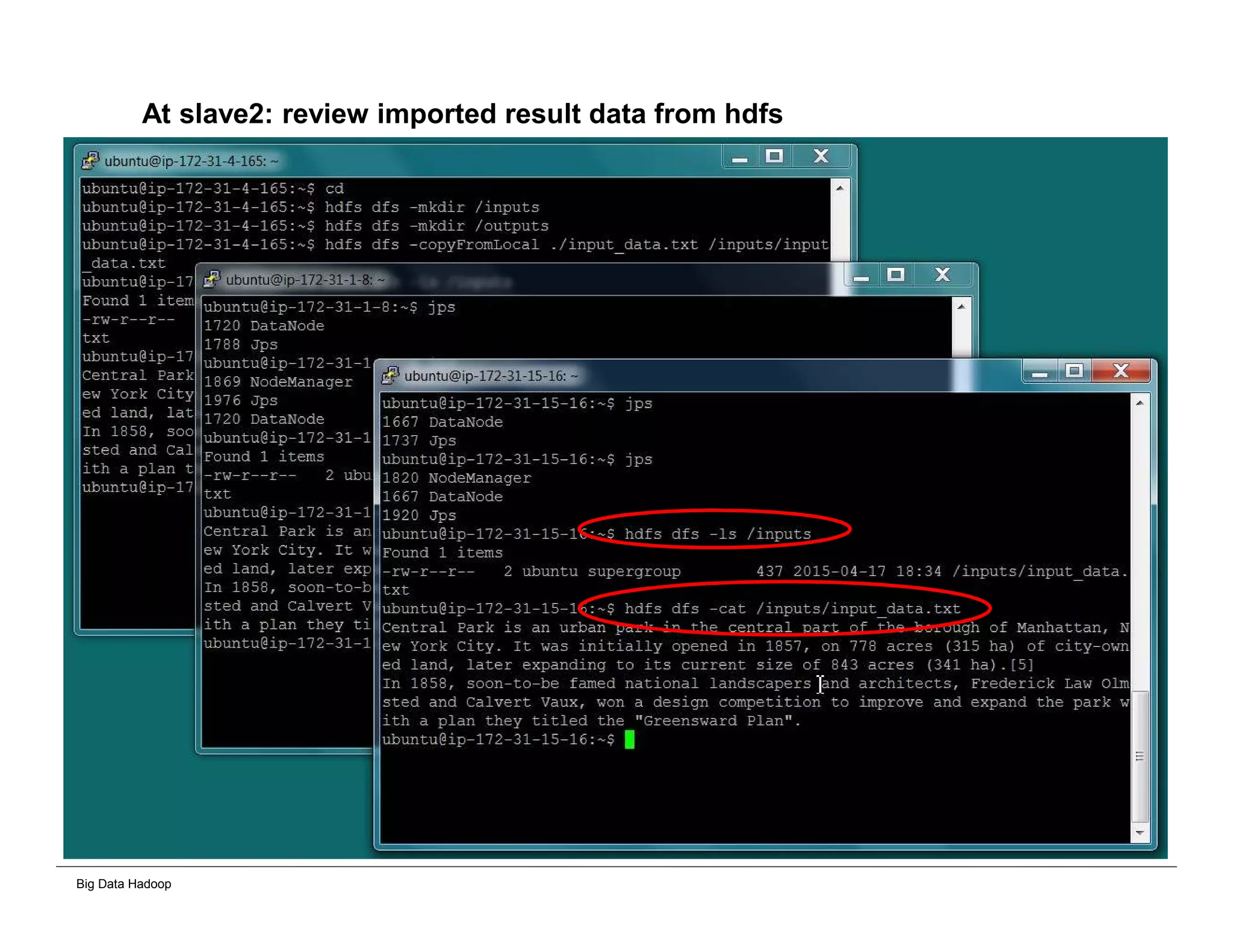

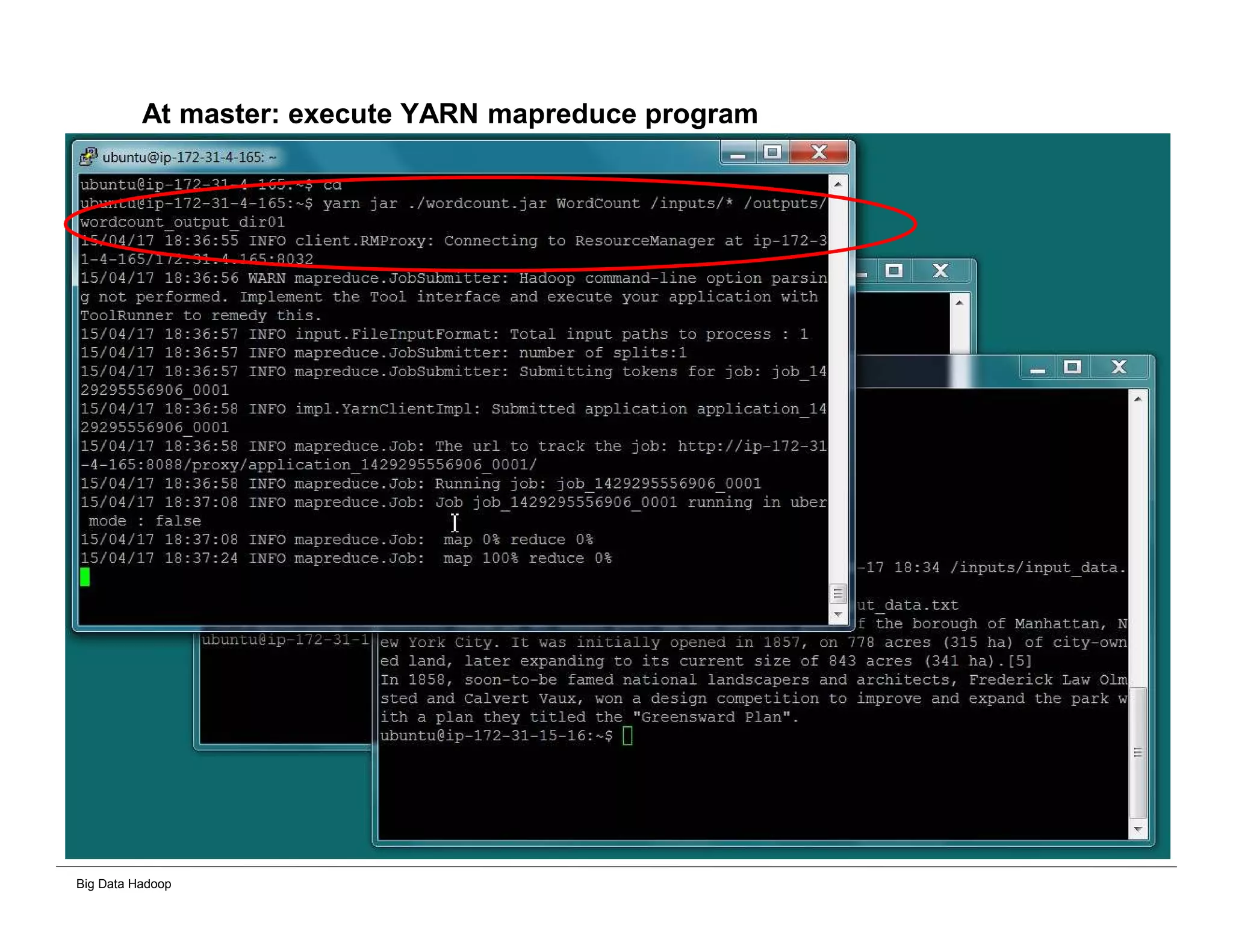
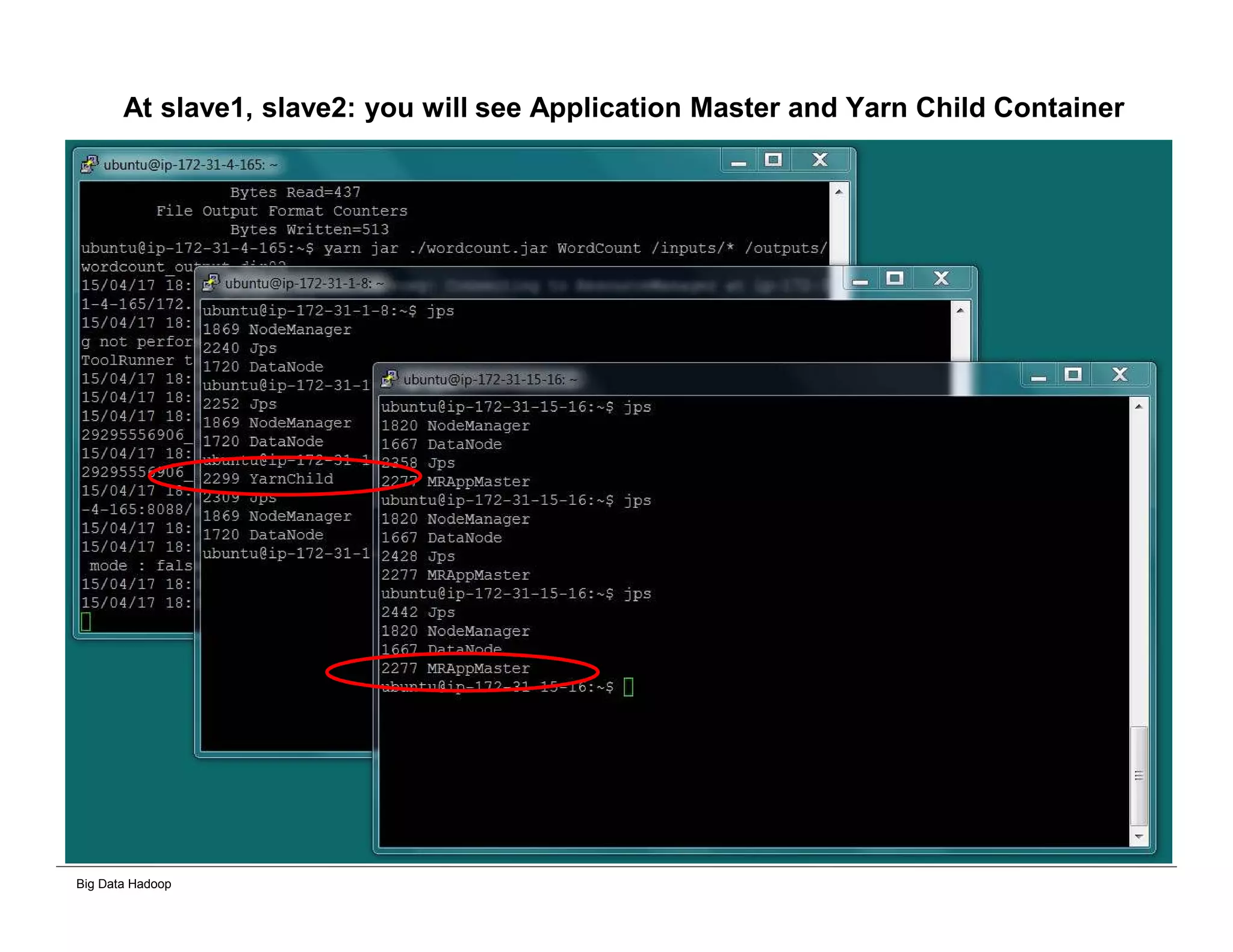
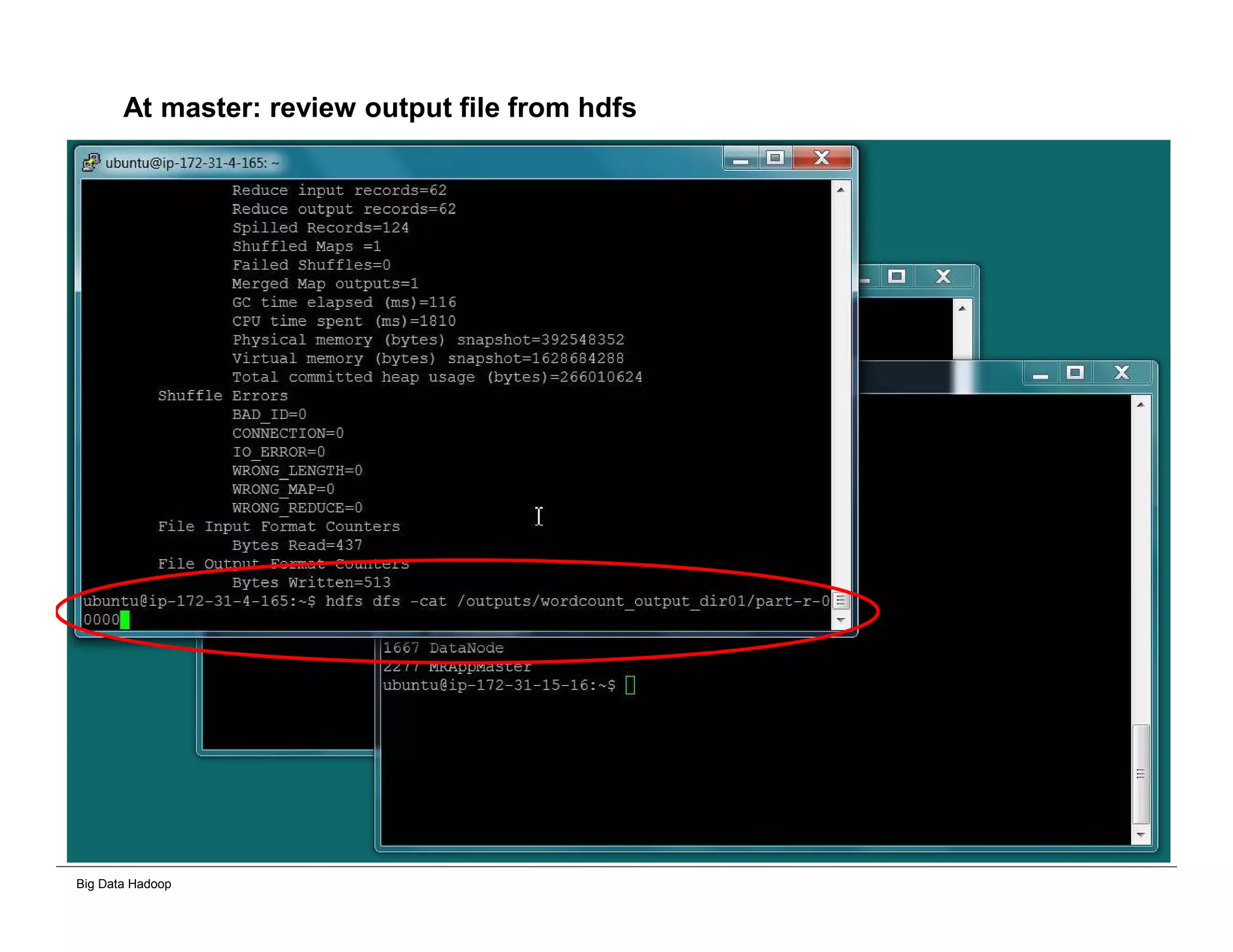
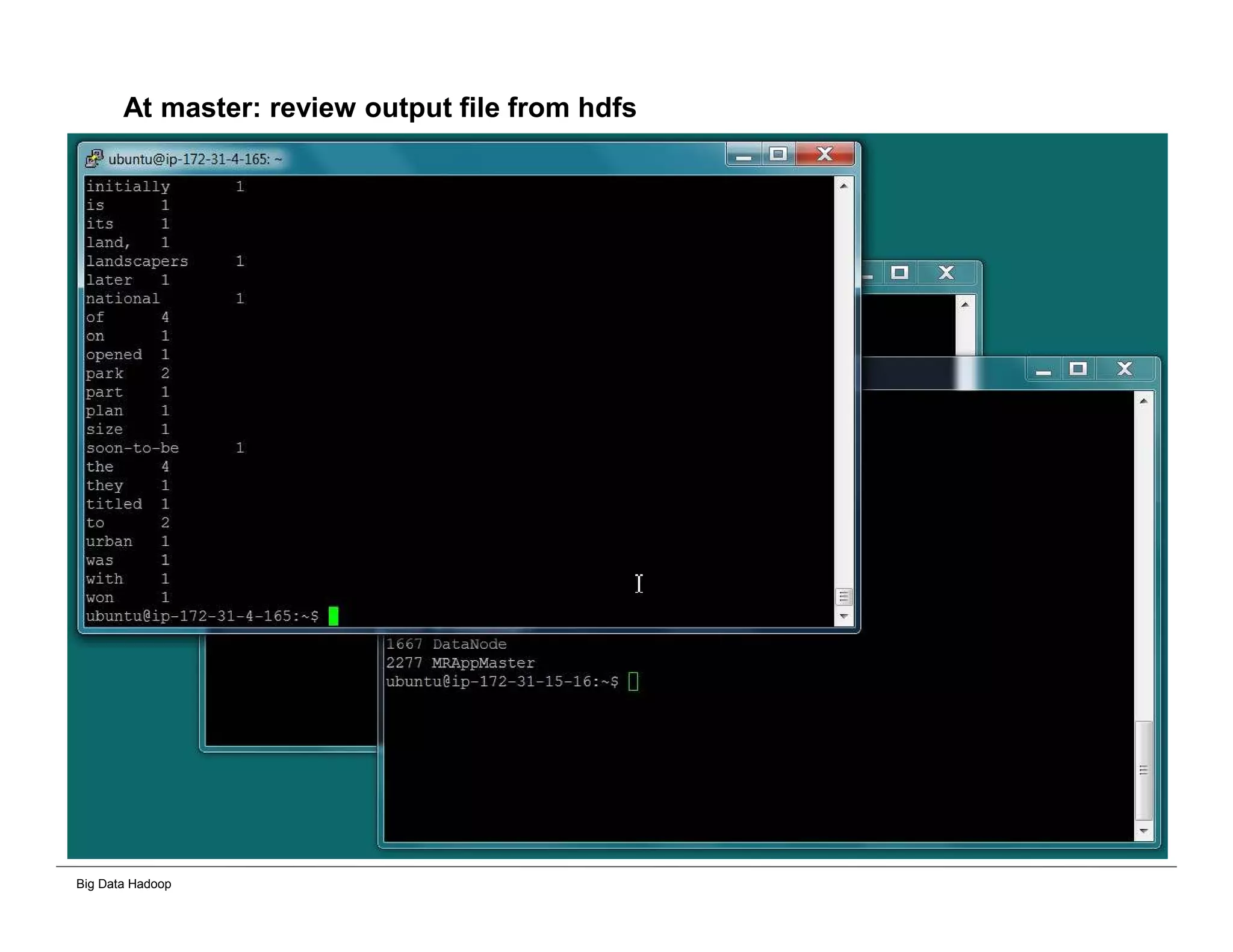
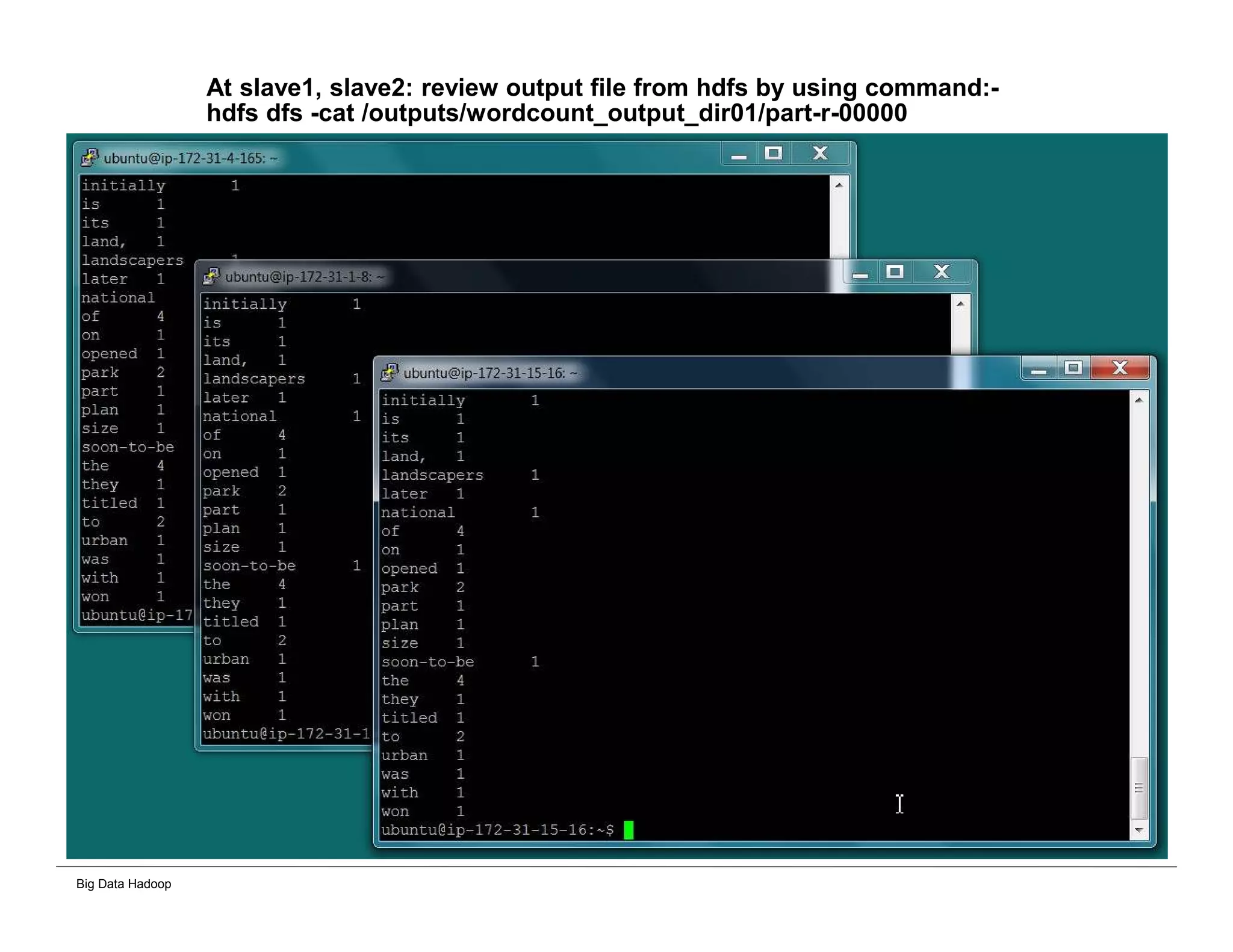
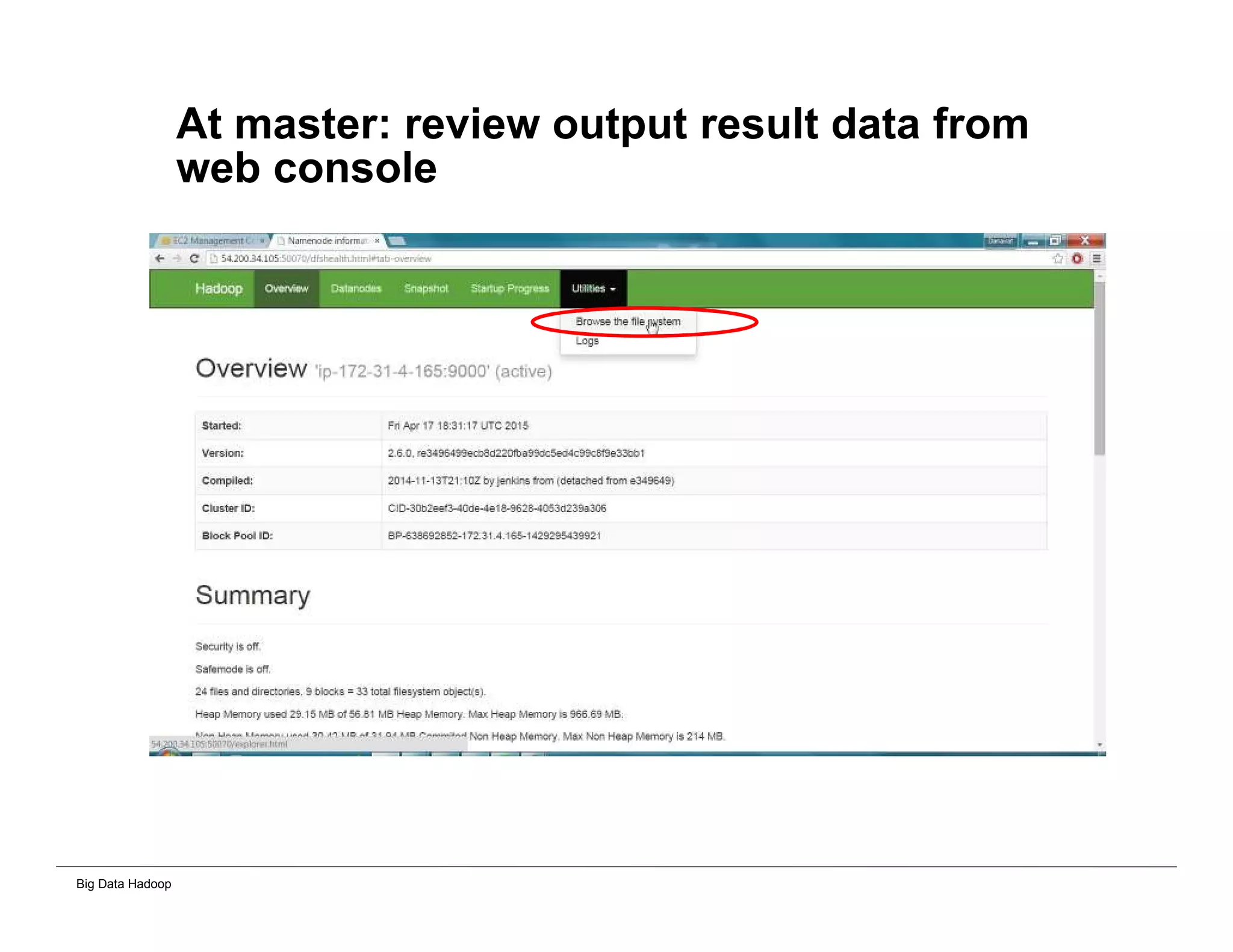
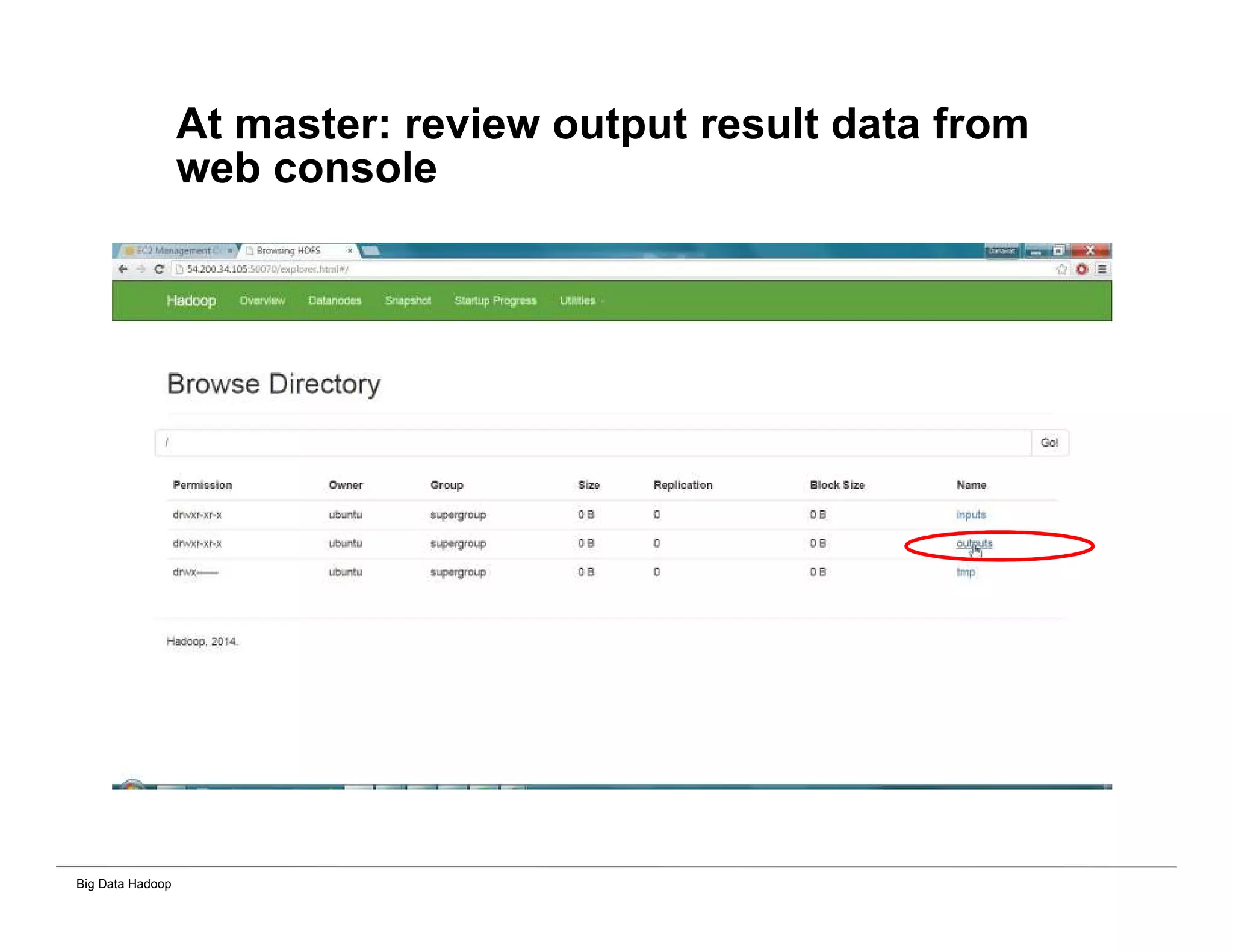
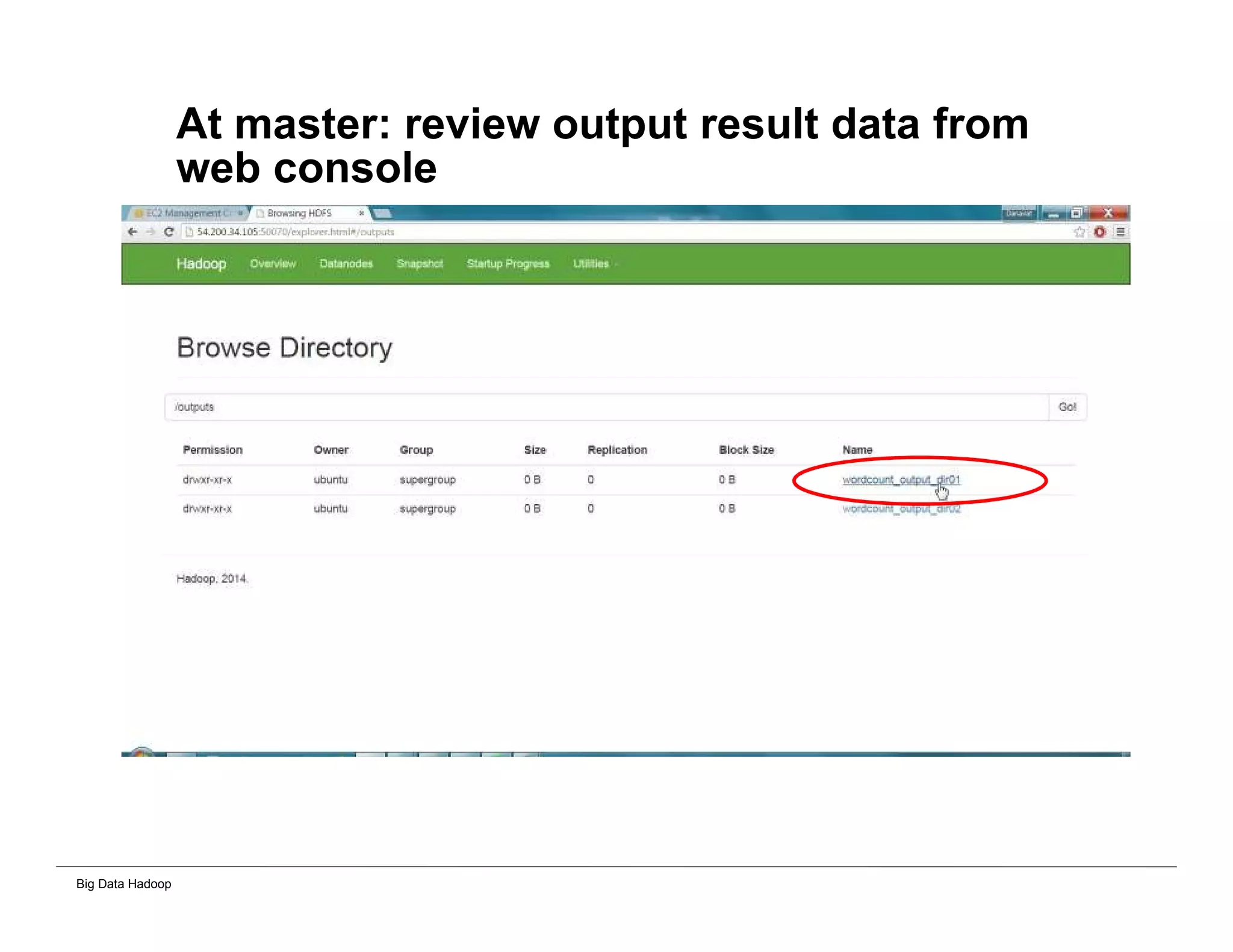
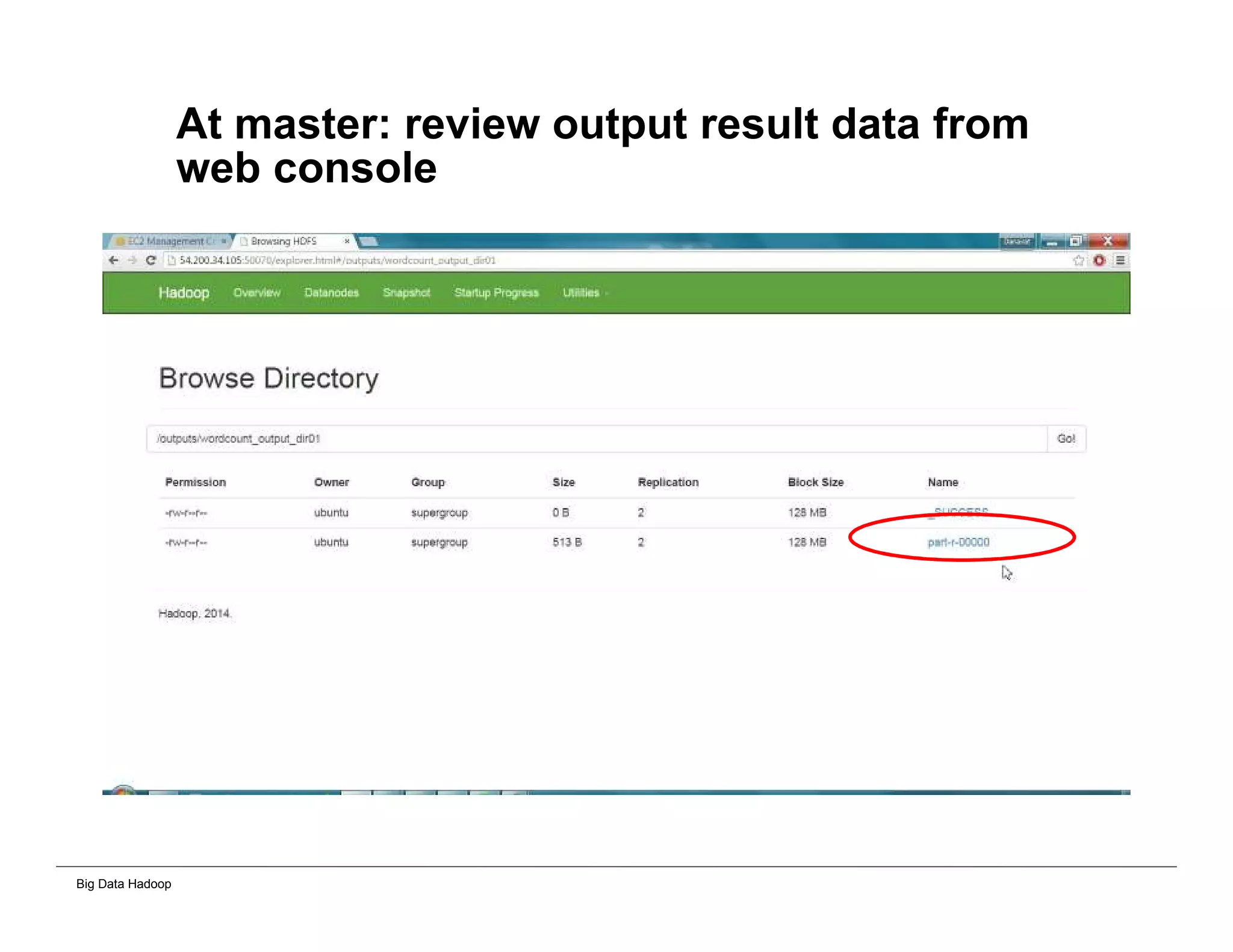





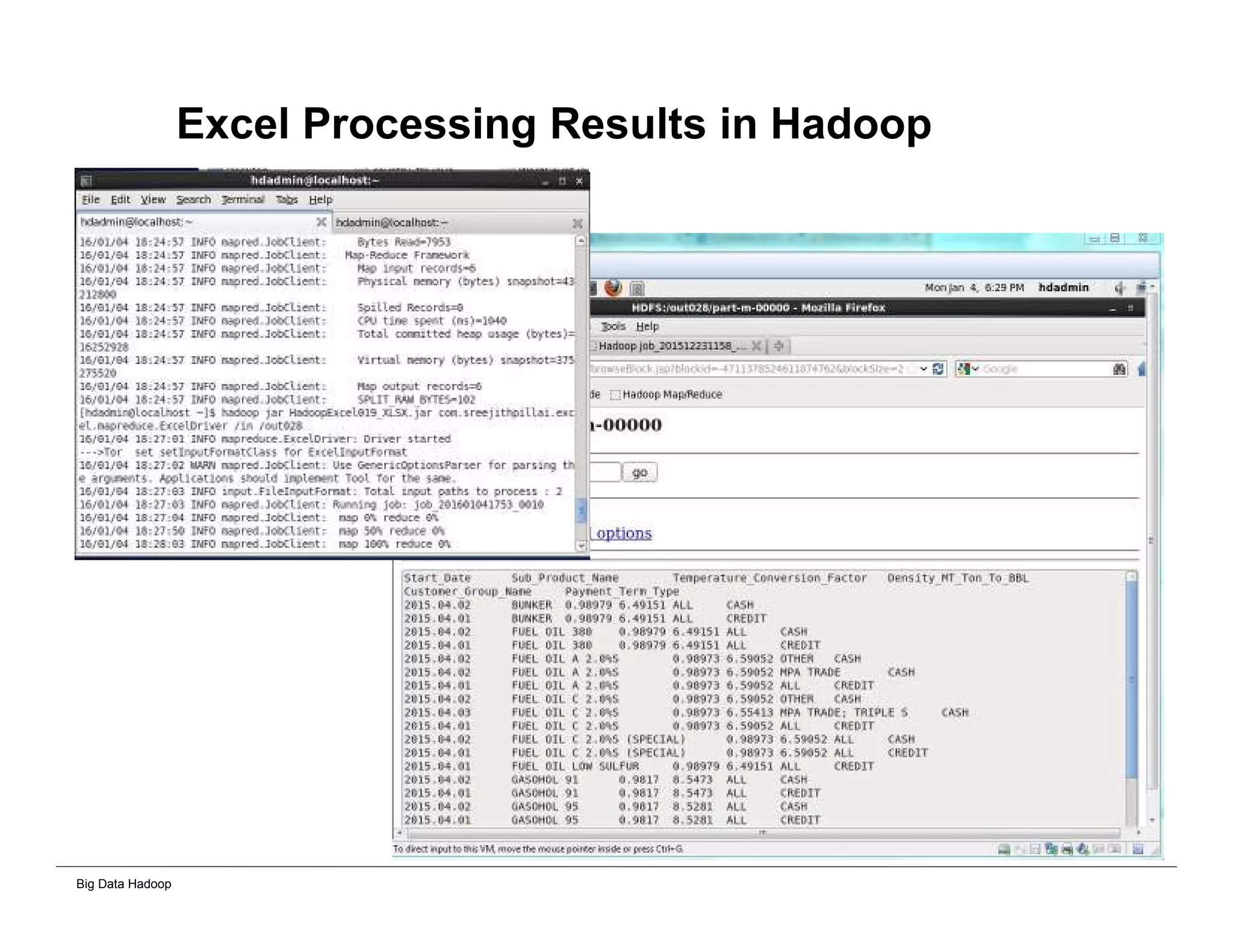



This document provides an overview of 4 solutions for processing big data using Hadoop and compares them. Solution 1 involves using core Hadoop processing without data staging or movement. Solution 2 uses BI tools to analyze Hadoop data after a single CSV transformation. Solution 3 creates a data warehouse in Hadoop after a single transformation. Solution 4 implements a traditional data warehouse. The solutions are then compared based on benefits like cloud readiness, parallel processing, and investment required. The document also includes steps for installing a Hadoop cluster and running sample MapReduce jobs and Excel processing.




























































































![Vibe Coding vs. Spec-Driven Development [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/vibecodingvsspecdrivendevelopment-251209105622-43f455e7-thumbnail.jpg?width=640&height=640&fit=bounds)











