
















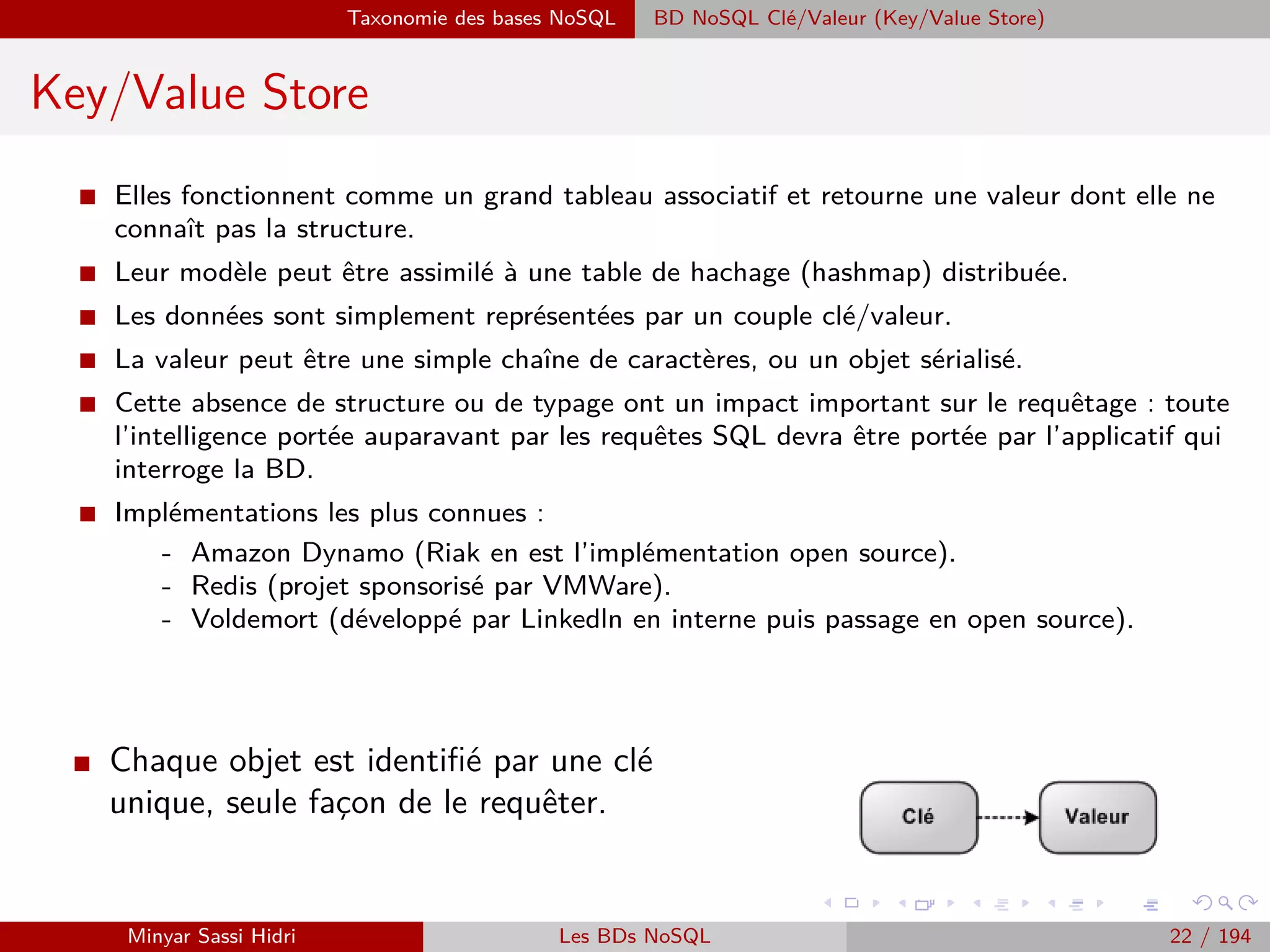


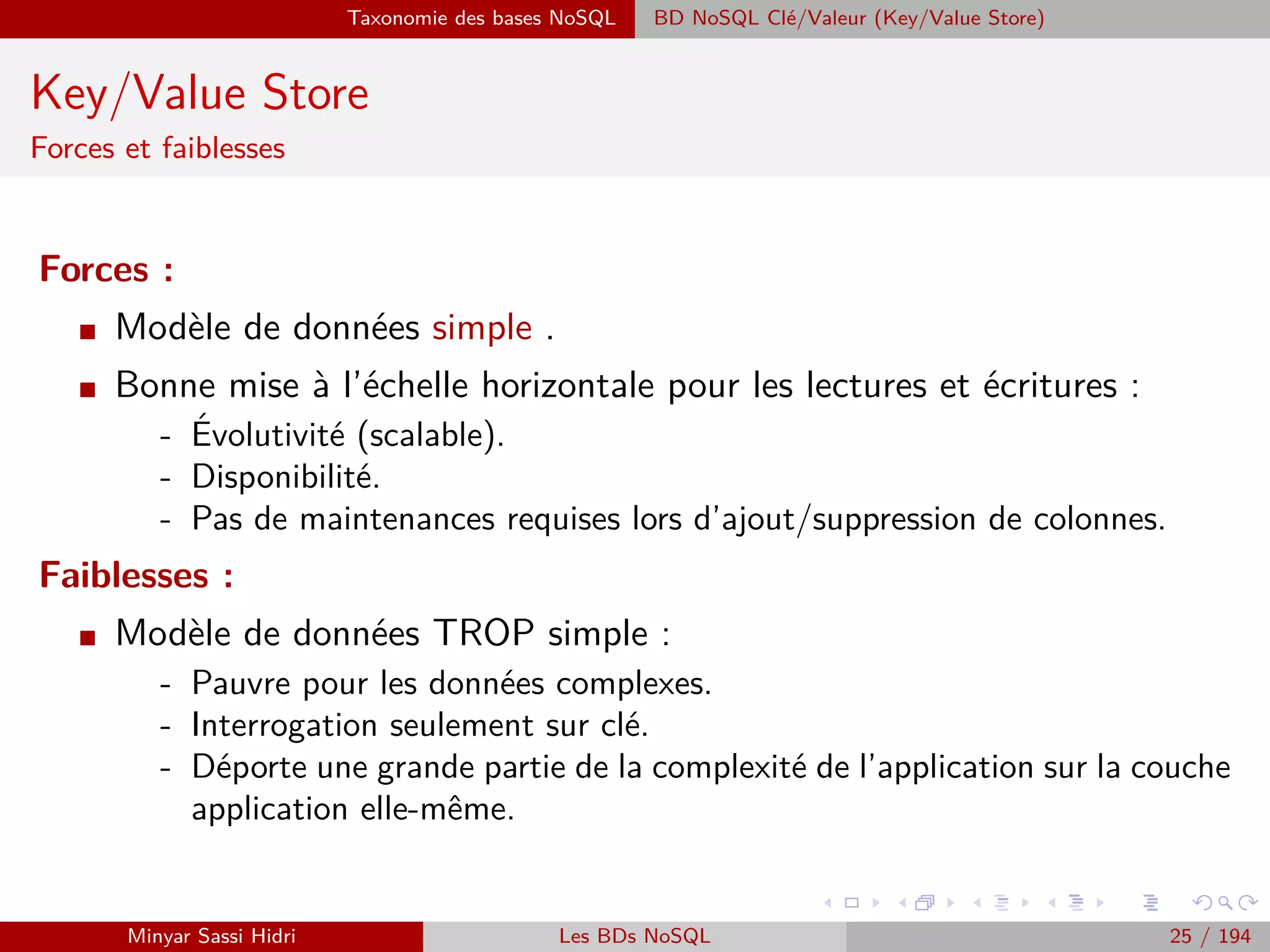


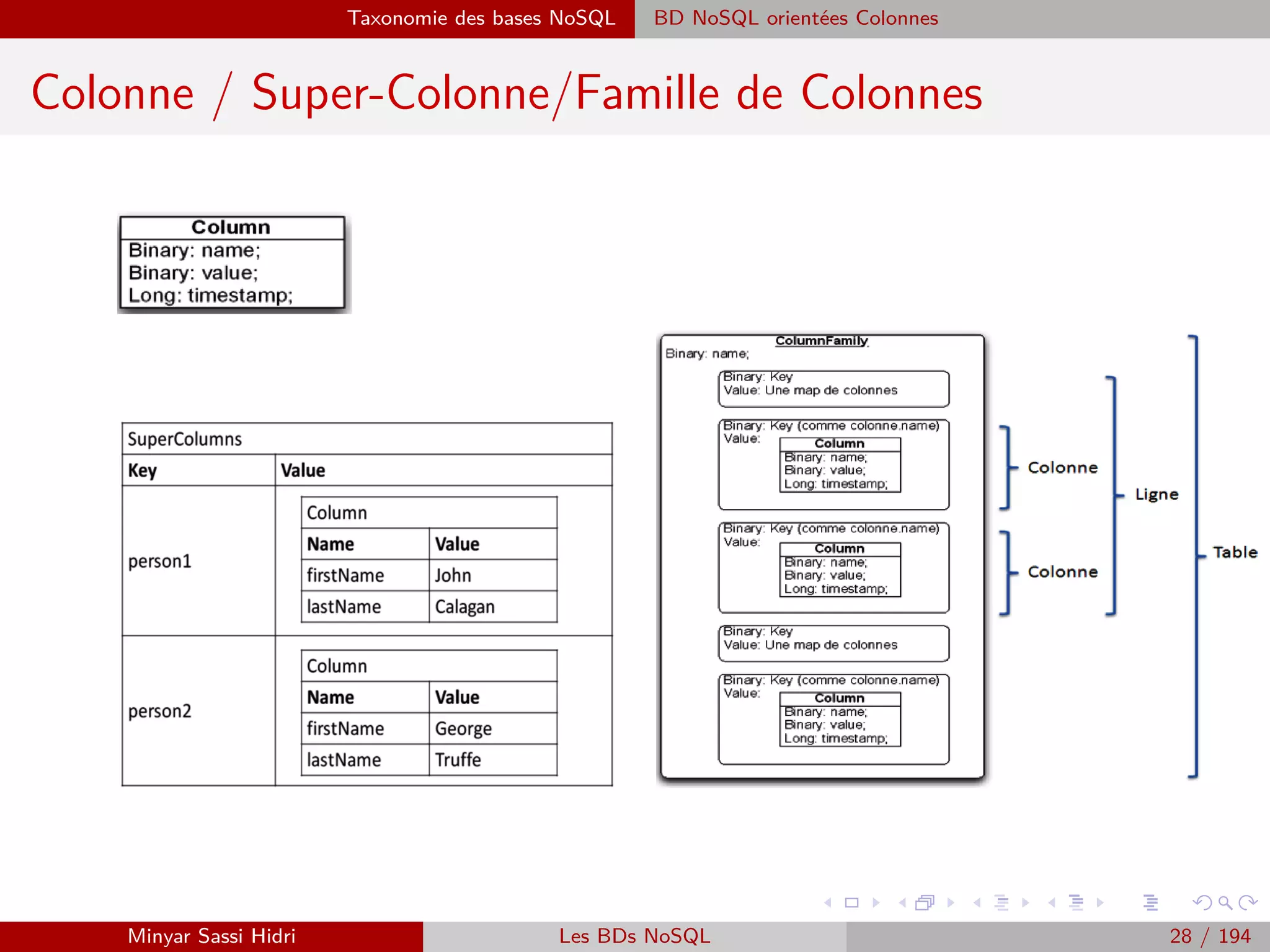
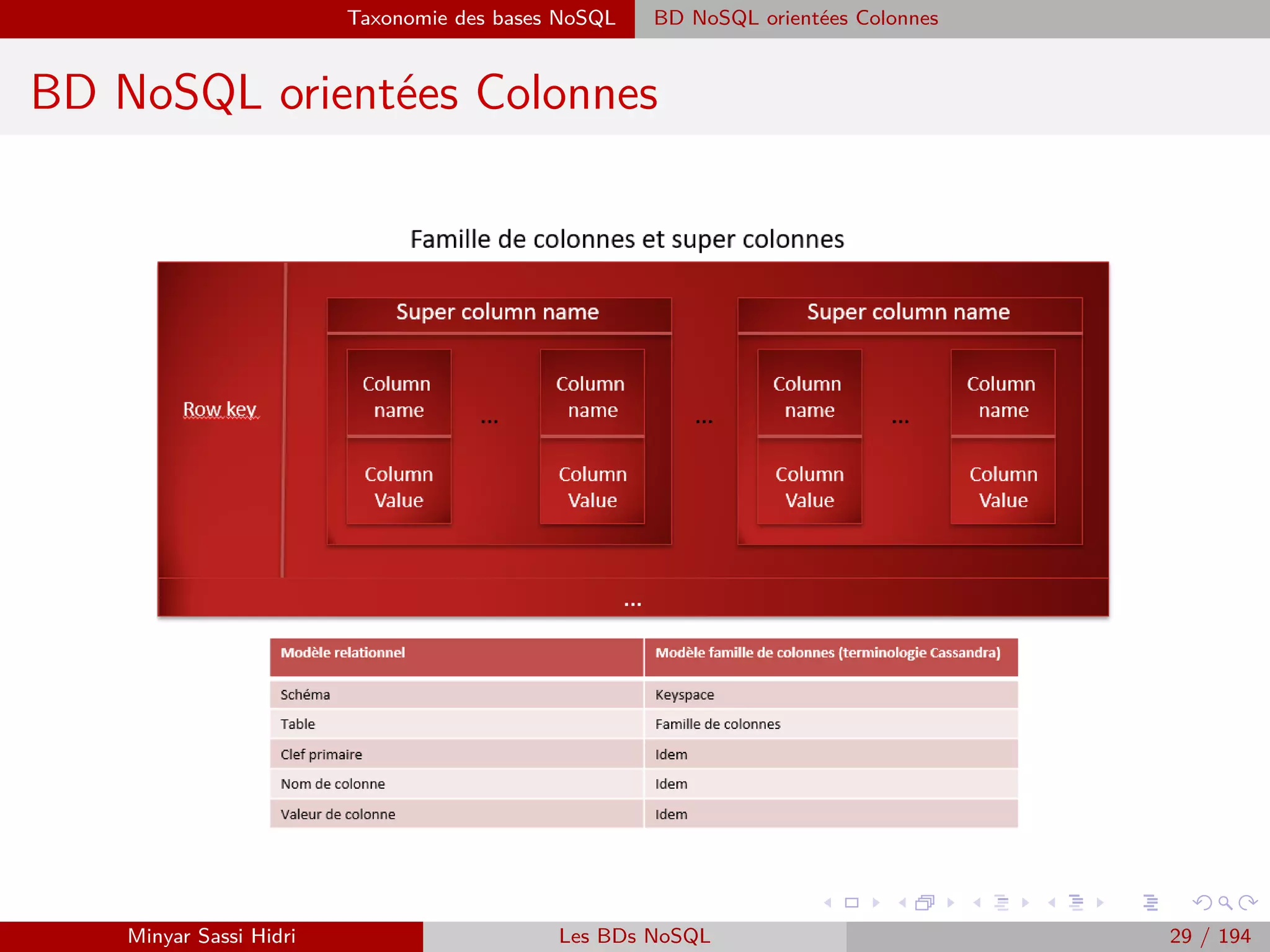



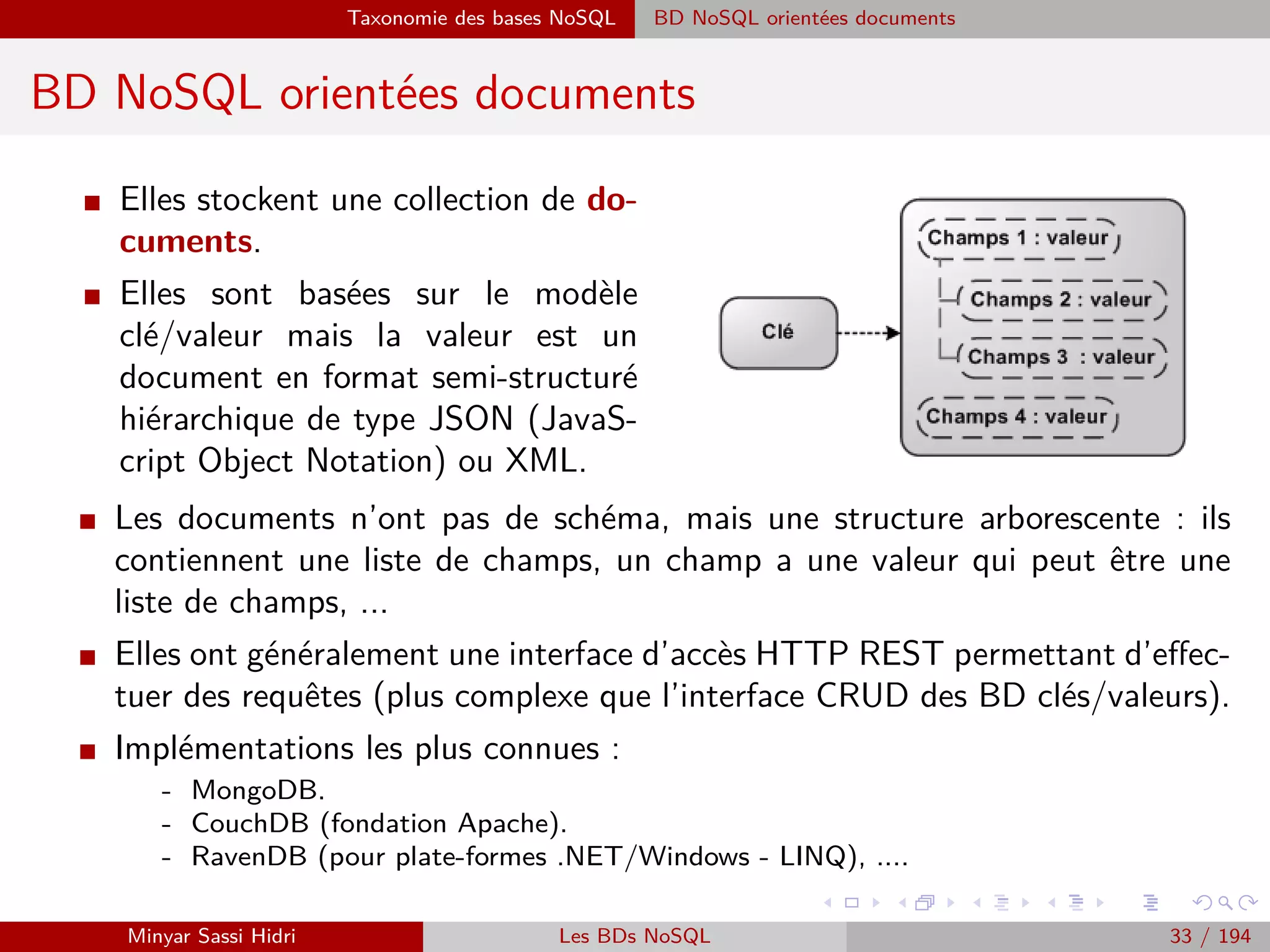
















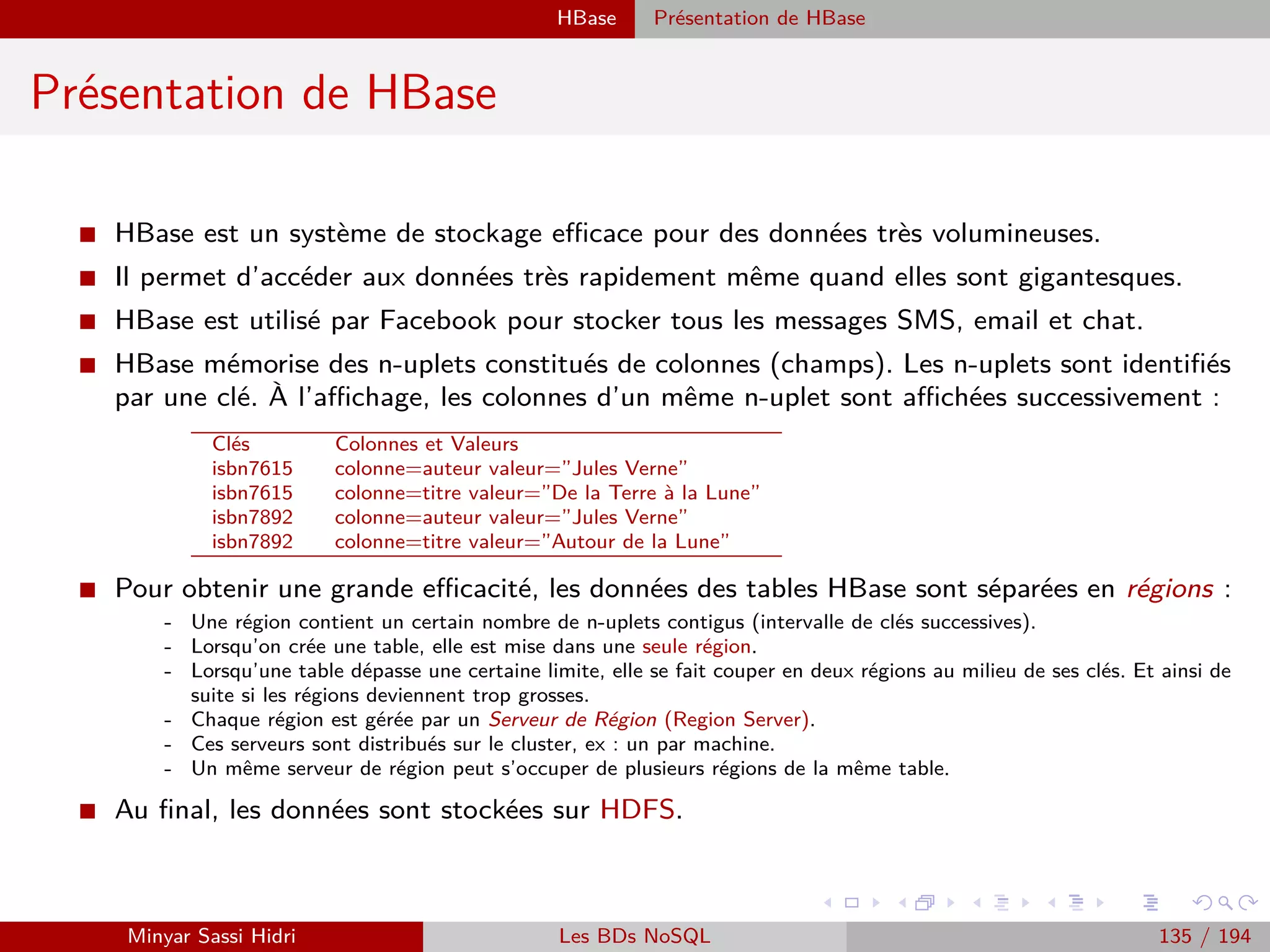
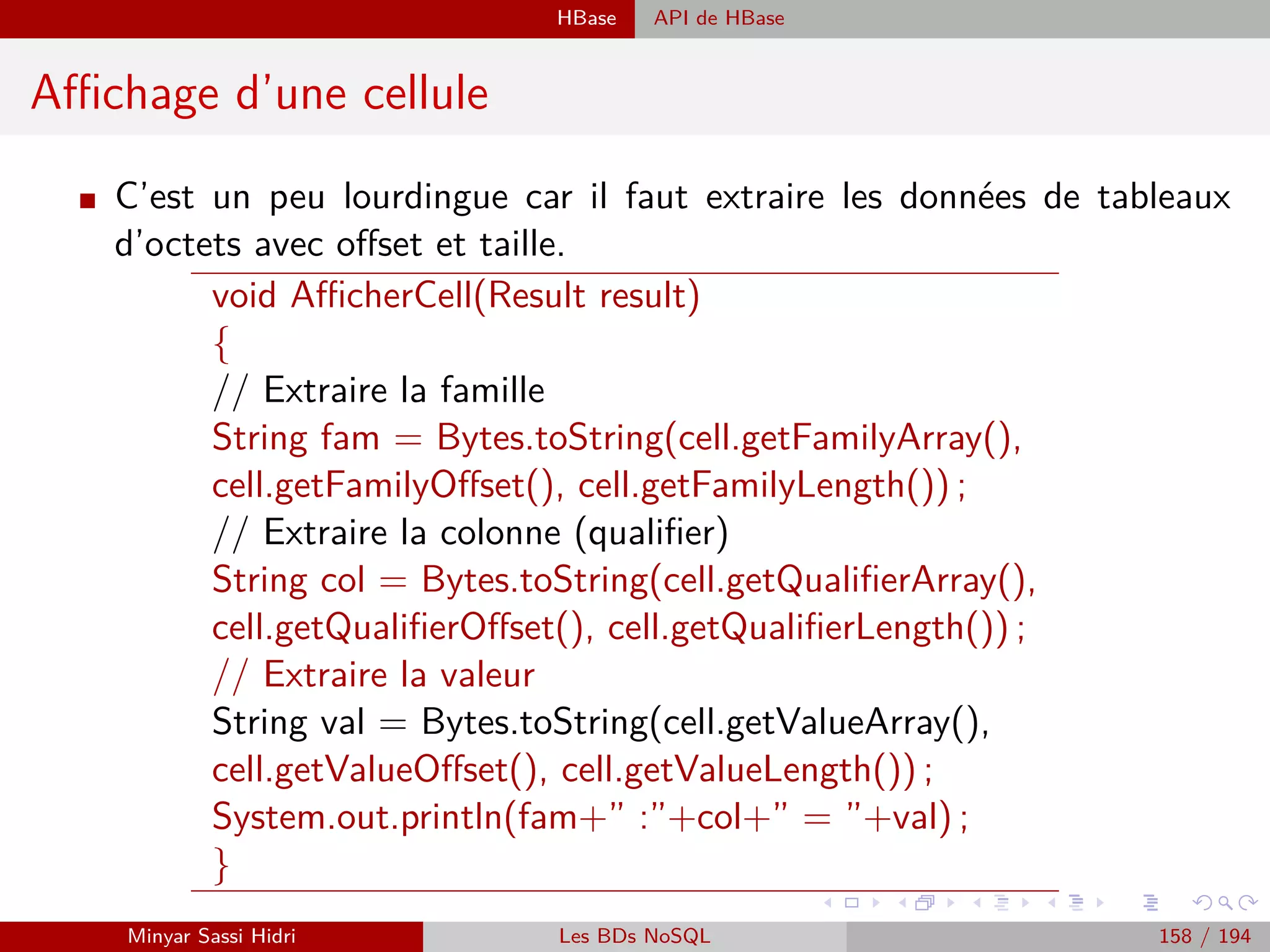
![Hadoop Problématiques du calcul distribué
Problématiques du calcul distribué (2)
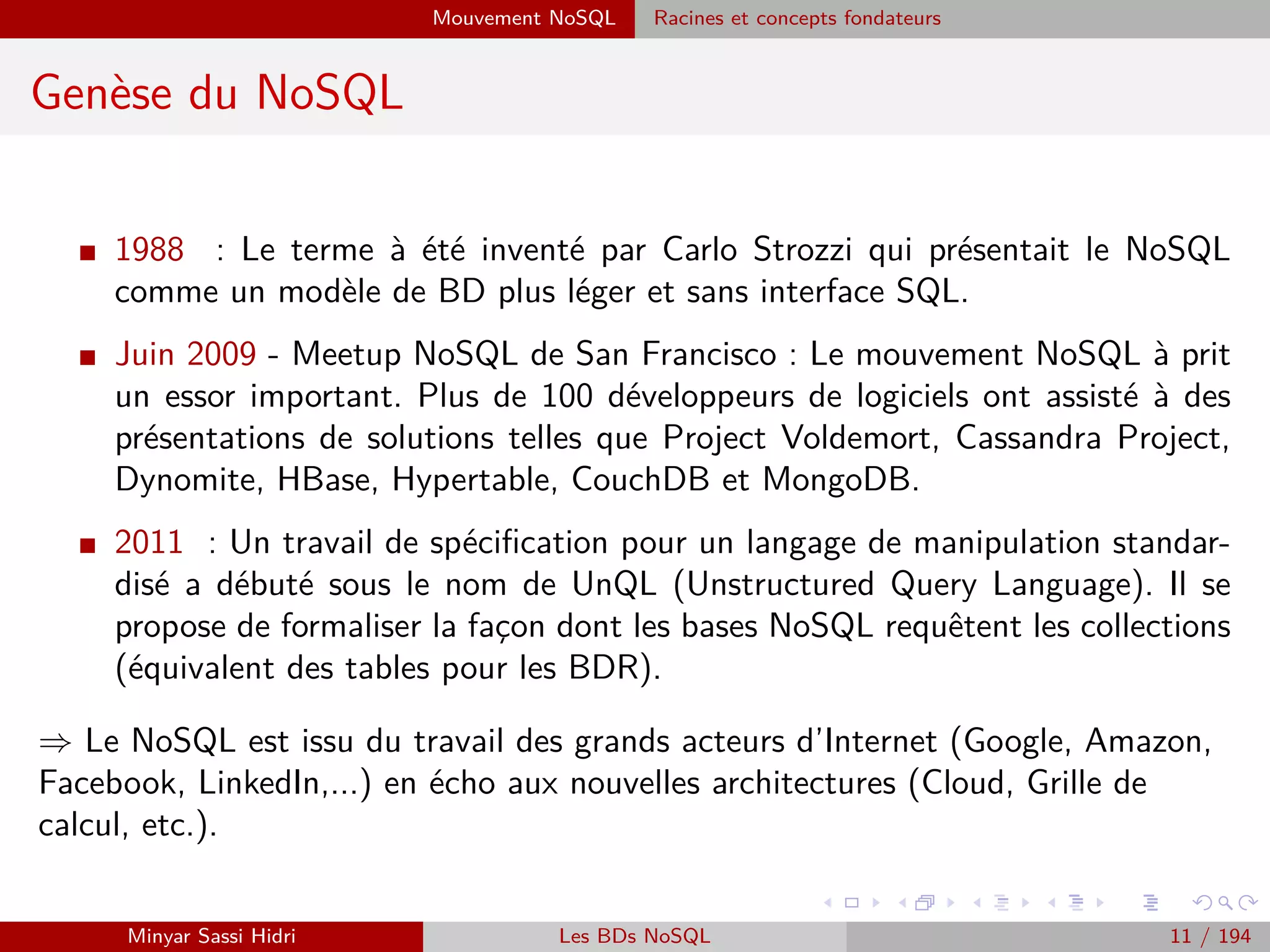
I Ces problématiques sont complexes et ont donné lieu à des années de
recherche et d’expérimentation.
I On distingue historiquement deux approches/cas d’usage :
[1] Effectuer des calculs intensifs localement (recherche scientifique) - on
souhaite avoir un cluster de machines local pour accélérer le traitement.
⇒ Solution qui était jusqu’ici coûteuse et complexe à mettre en œuvre.
[2] Exploiter la démocratisation de l’informatique moderne et la bonne
volonté des utilisateurs du réseau pour créer un cluster distribué via
Internet à moindre coût.
⇒ Solution qui suppose qu’on trouve des volontaires susceptibles de
partager leur puissance de calcul.
Minyar Sassi Hidri Technologies pour le Big Data 57 / 227](https://image.slidesharecdn.com/bigdata1-160410201905/75/Technologies-pour-le-Big-Data-58-2048.jpg)
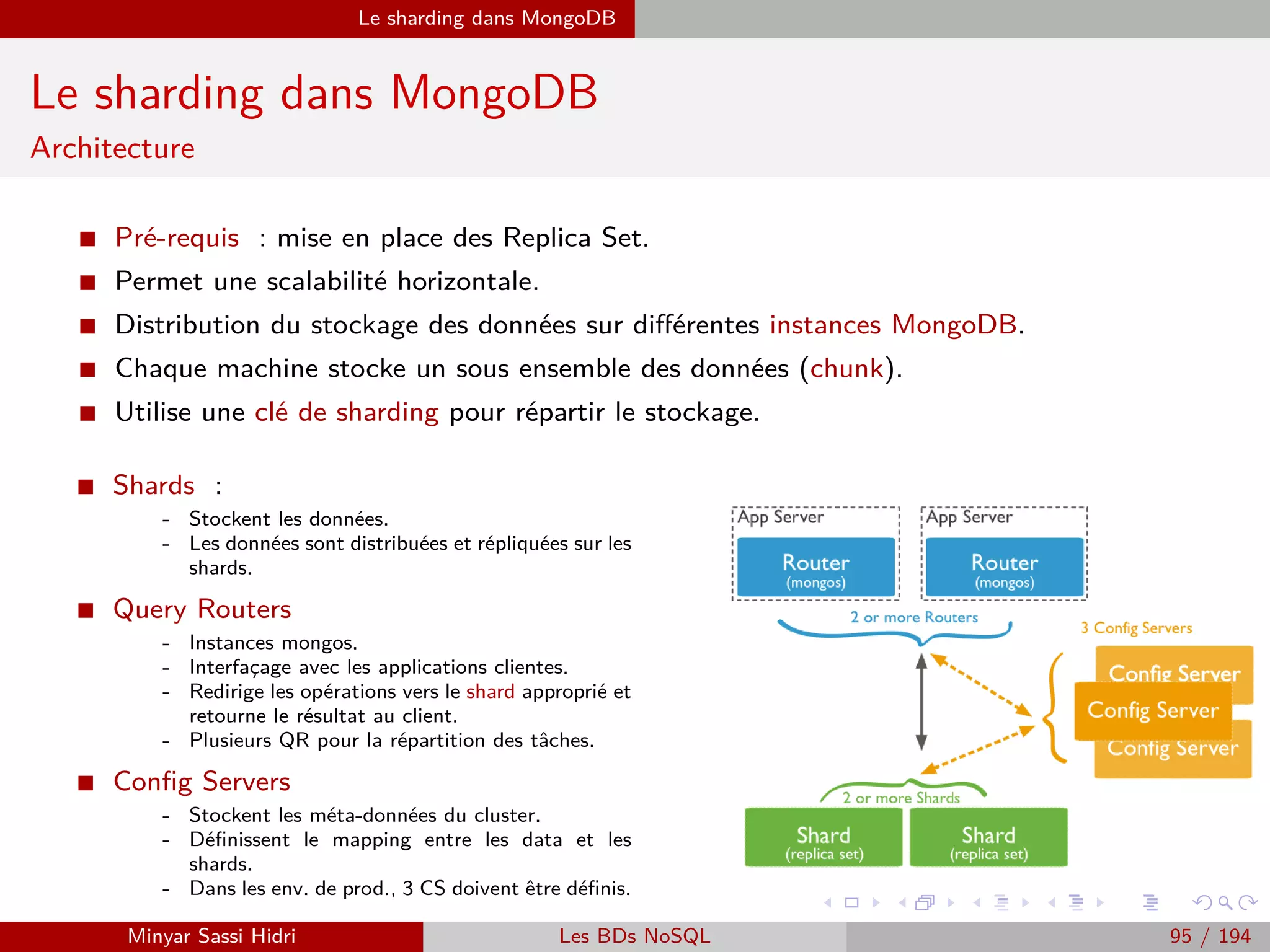
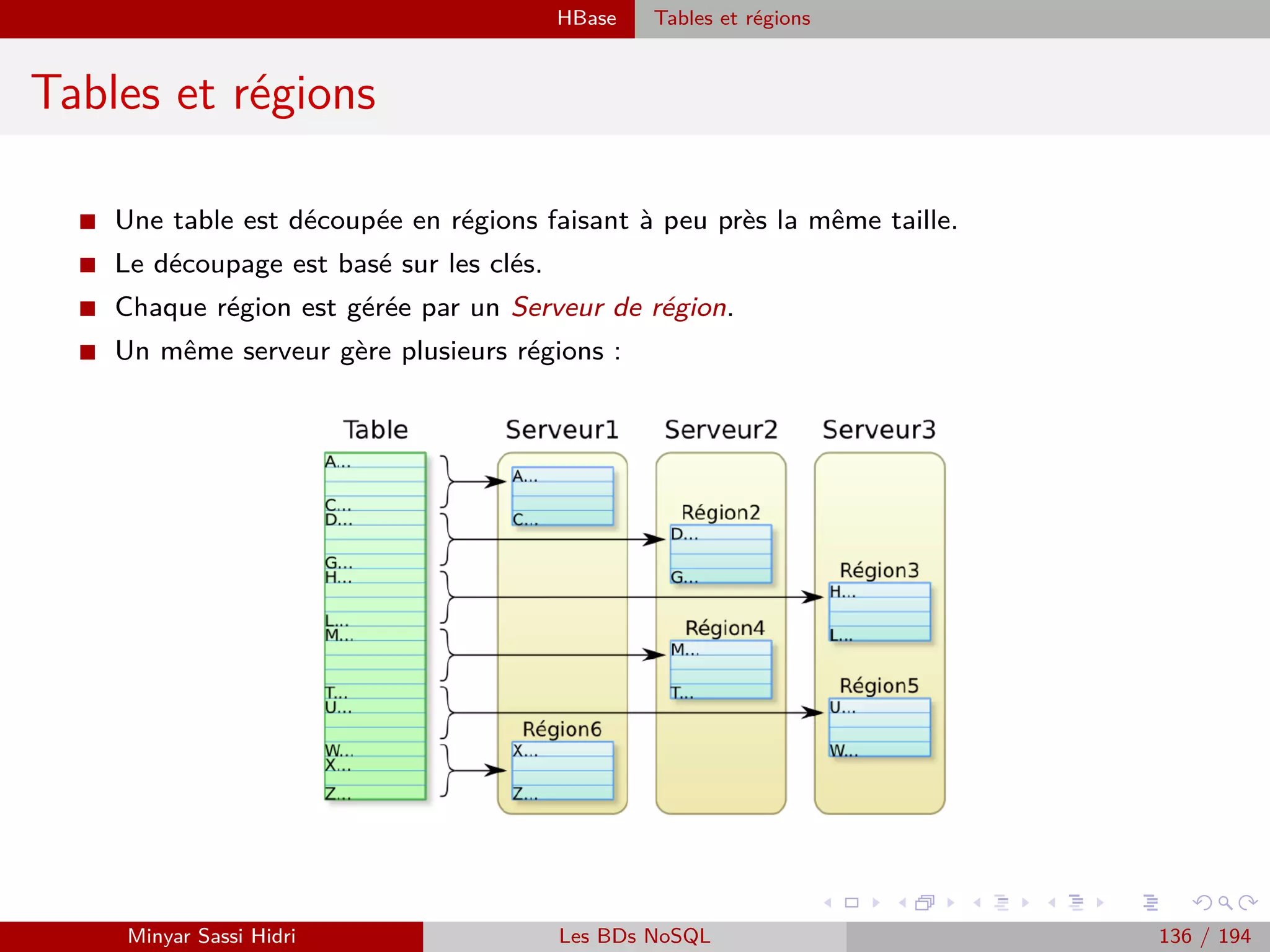
![Hadoop Problématiques du calcul distribué
Problématiques du calcul distribué (3)
I De nombreuses universités et entreprises ont des besoins d’exécution
locale de tâches parallélisables sur des données massives.
I Les solutions qui étaient disponibles jusqu’ici :
[1] Des super calculateurs classiques comme Blue Gene : très oné-
reux, souvent trop puissants par rapport aux besoins requis, réservés
aux grands groupes industriels.
[2] Des solutions développées en interne : investissement initial très
conséquent, nécessite des compétences et une rigueur coûteuses.
[3] Architecture Beowulf : un début de réponse, mais complexe à mettre
en œuvre pour beaucoup d’entreprises ou petites universités, et nécessi-
tant aussi un investissement initial assez conséquent.
Minyar Sassi Hidri Technologies pour le Big Data 58 / 227](https://image.slidesharecdn.com/bigdata1-160410201905/75/Technologies-pour-le-Big-Data-59-2048.jpg)









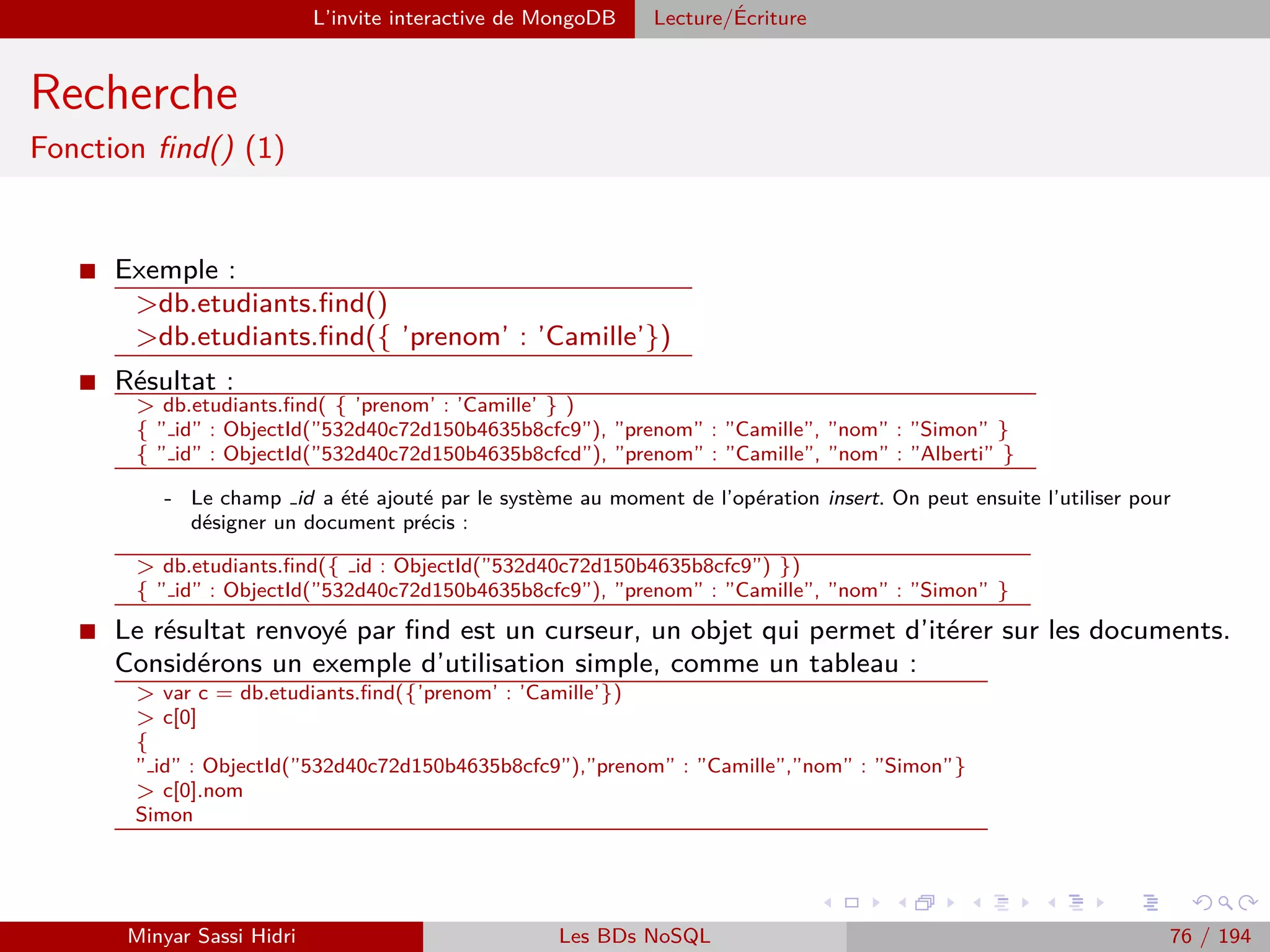

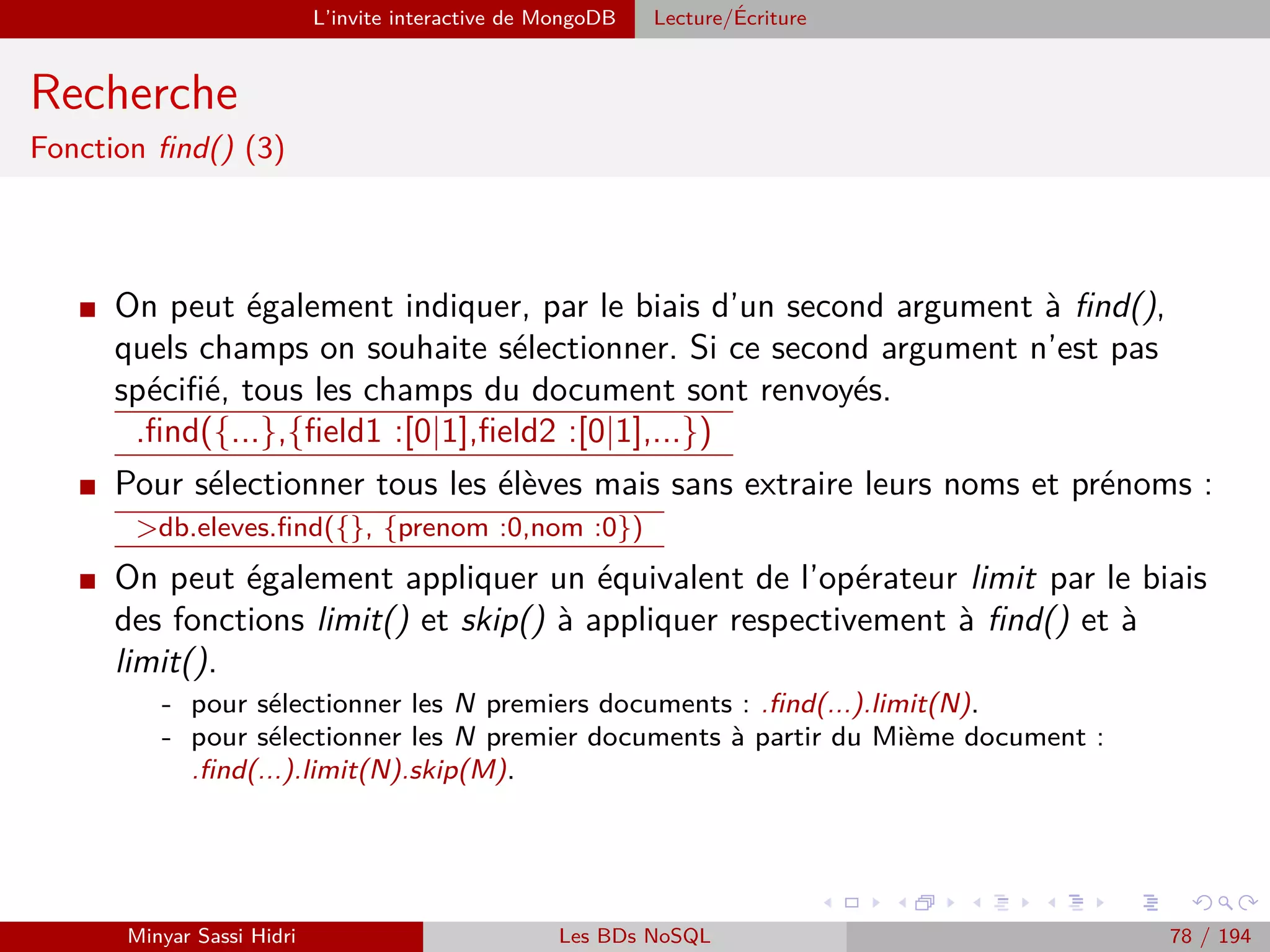
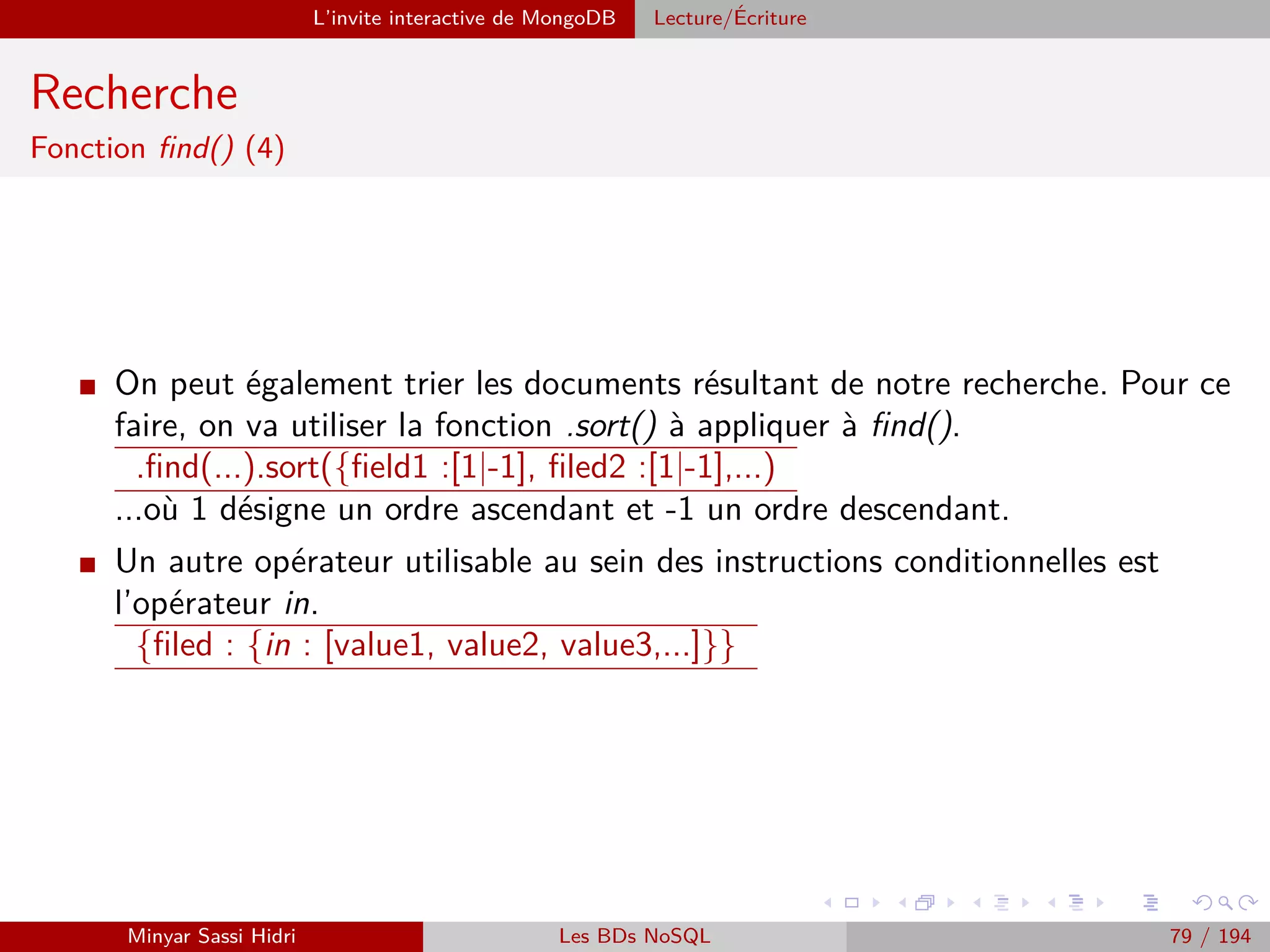
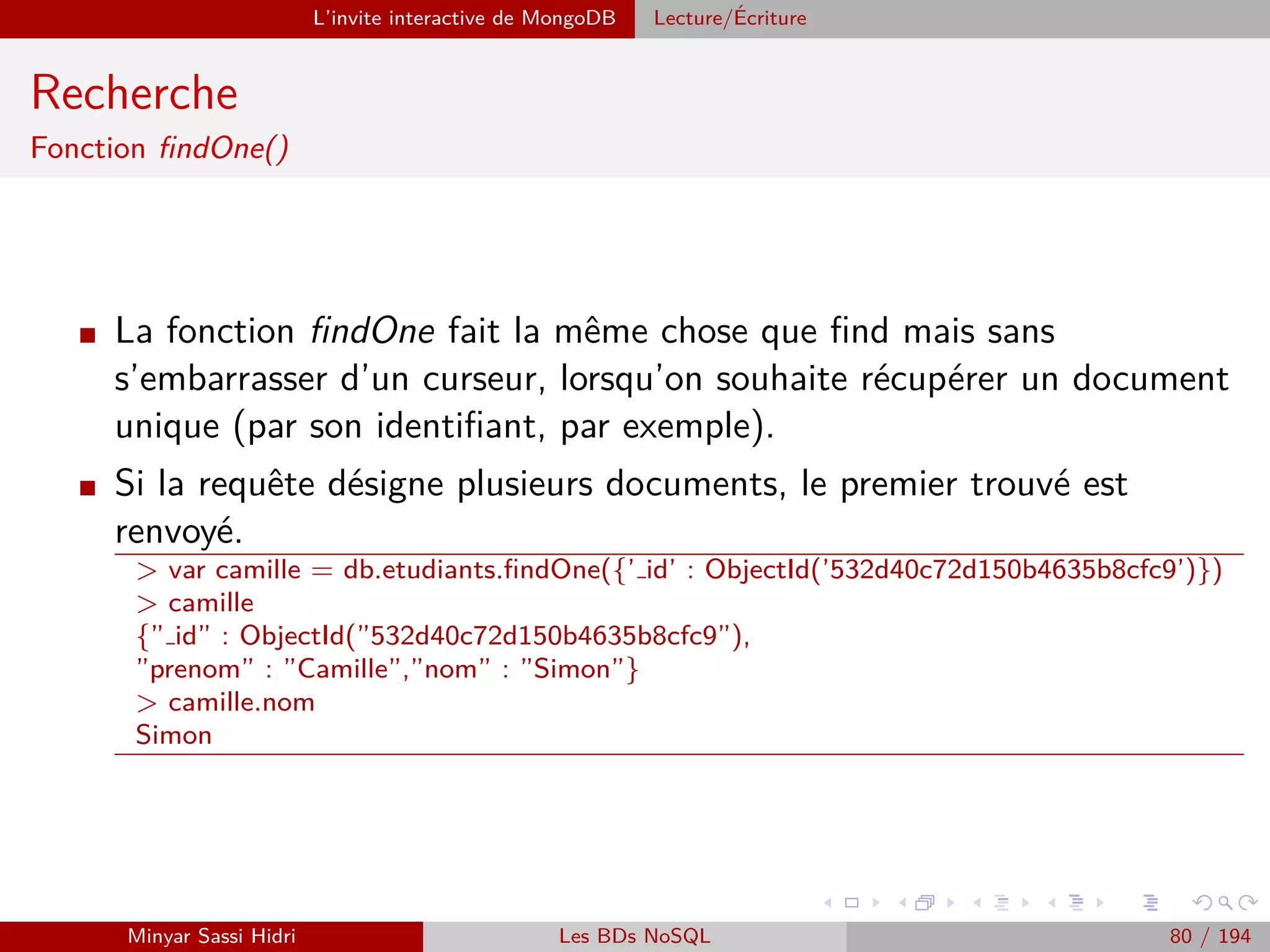
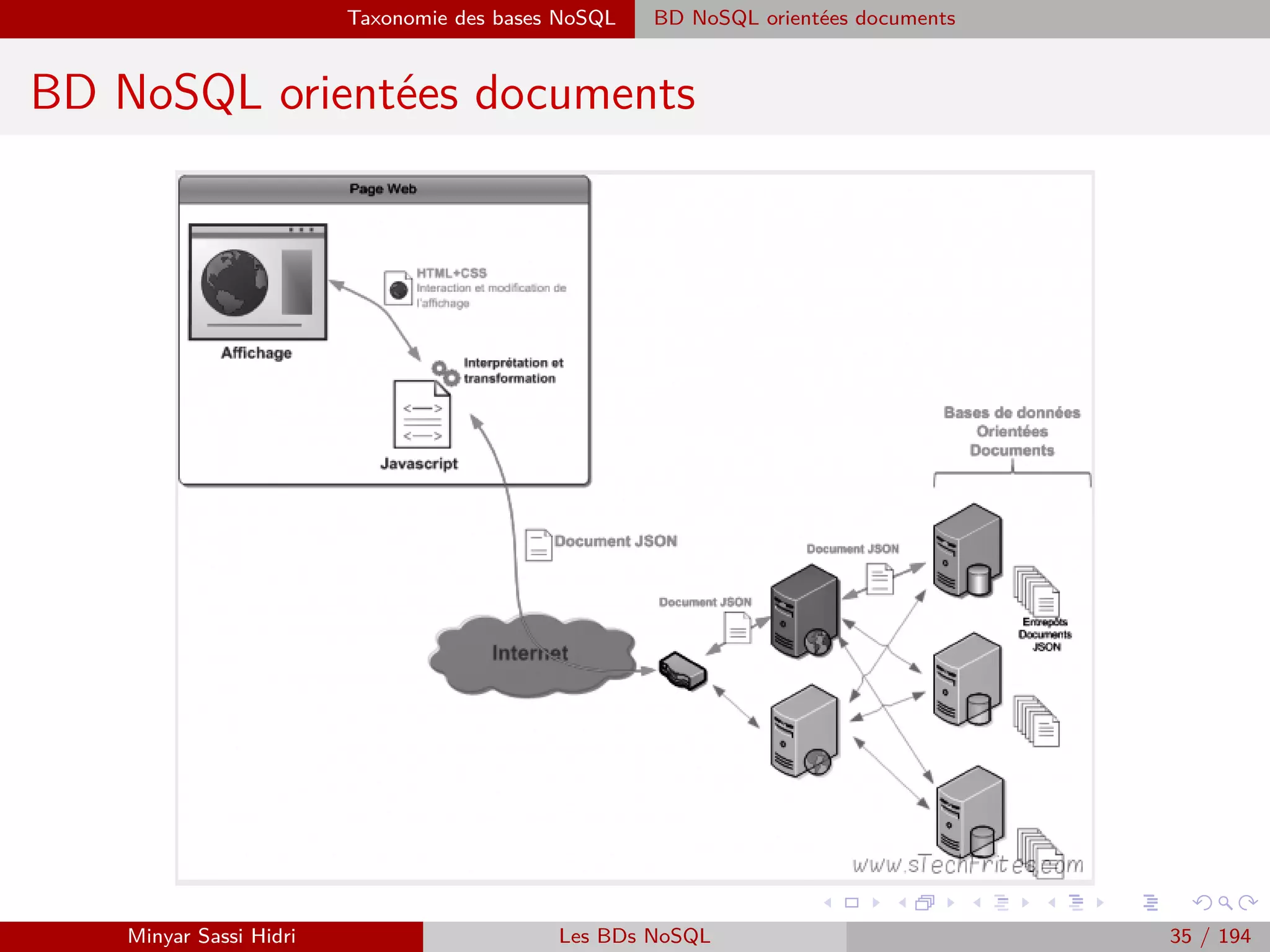
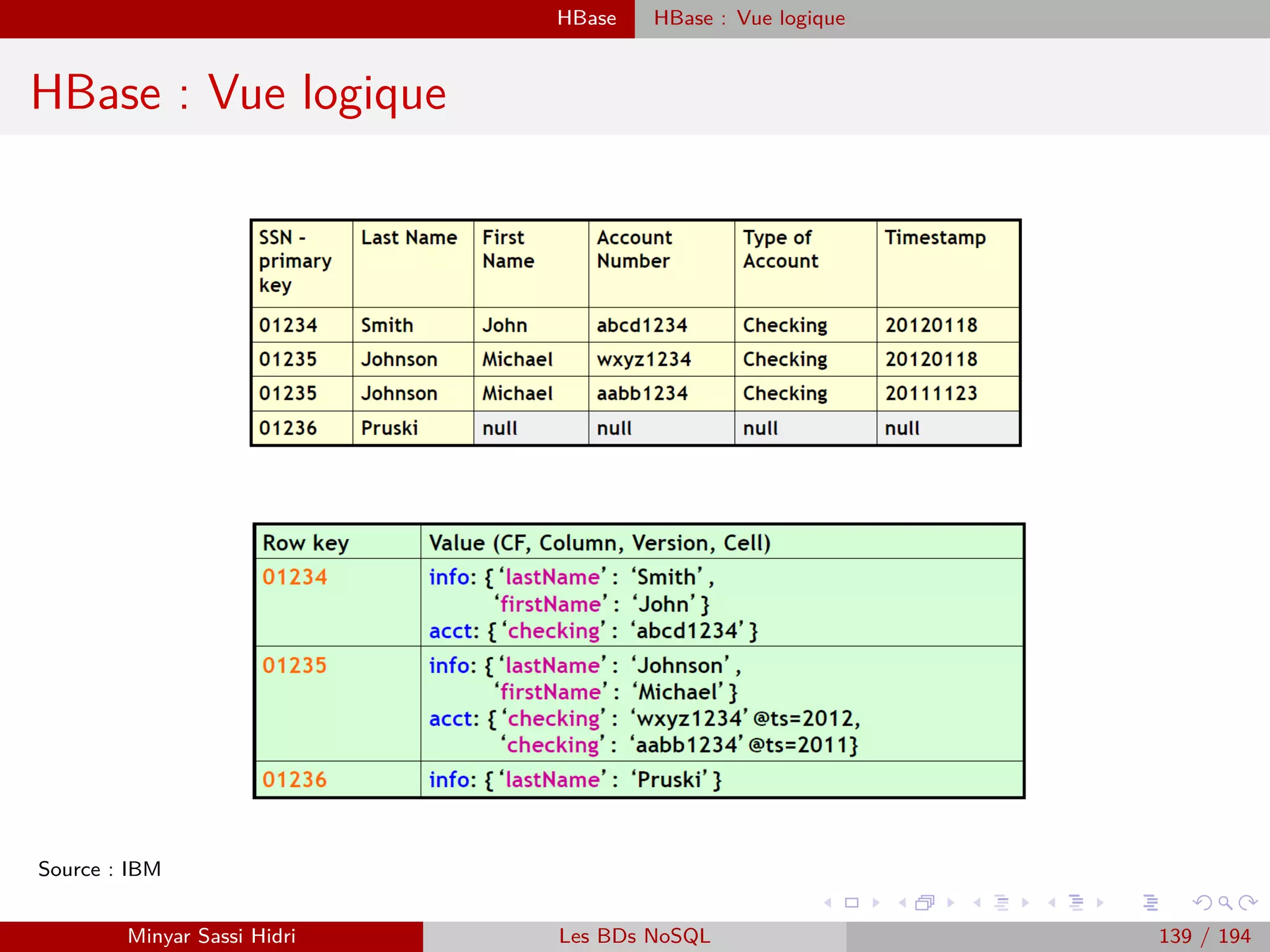
![MapReduce Présentation
Présentation (2)
MapReduce définit deux opérations distinctes à effectuer sur les données
d’entrée :
[1.] Map :
- Transforme les données d’entrée en une série de couples (key, value).
- Regroupe les données en les associant à des clés, choisies de telle sorte que les couples
(key, value) aient un sens par rapport au problème à résoudre.
Note : Cette opération doit être parallèlisable. On doit pouvoir découper les données
d’entrée en plusieurs fragments, et faire exécuter l’opération Map à chaque machine
du cluster sur un fragment distinct.
[2.] Reduce :
- Applique un traitement à toutes les valeurs de chacune des clés distinctes produite
par l’opération Map.
- Au terme de l’opération Reduce, on aura un résultat pour chacune des clés distinctes.
Ici, on attribuera à chacune des machines du cluster une des clés uniques produites
par Map, en lui donnant la liste des valeurs associées à la clé. Chacune des machines
effectuera alors l’opération Reduce pour cette clé.
Minyar Sassi Hidri Technologies pour le Big Data 84 / 227](https://image.slidesharecdn.com/bigdata1-160410201905/75/Technologies-pour-le-Big-Data-85-2048.jpg)



![MapReduce Exemples
Exemple 1 : Comptage du nombre de mots
Entre la phase Map et la phase Reduce
I Avant d’être envoyé au reducer, le fi-
chier est automatiquement trié par clé :
c’est ce que l’on appelle la phase de
shuffle & sort.
I Le fichier en entrée du reducer est le
suivant :
am,[1,1]
bour,[1,1]
colégram,[1]
et,[1,1,1,1]
gram,[1,1]
pic,[1,1]
ratatam,[1]
stram,[1,1]
Minyar Sassi Hidri Technologies pour le Big Data 89 / 227](https://image.slidesharecdn.com/bigdata1-160410201905/75/Technologies-pour-le-Big-Data-90-2048.jpg)


















![MapReduce du point de vue du développeur Java
Programmation Hadoop - Classe Driver
Exemple : Occurrences de mots (1)
I Le prototype de notre fonction main() :
public static void main(String[] args) throws Exception
On se sert de args pour récupérer les arguments de la ligne de commande. Plusieurs
fonctions Hadoop appelées au sein du main sont susceptibles de déclencher des exceptions
- on l’indique donc lors de la déclaration.
I Avant toute chose, on créé dans notre main un nouvel objet Configuration Hadoop :
// Créé un objet de configuration Hadoop.
Configuration conf=new Configuration() ;
Le package à importer est : org.apache.hadoop.conf.Configuration
I Avant toute chose, on créé dans notre main un nouvel objet Configuration Hadoop :
I On créé ensuite un nouvel objet Hadoop Job :
Job job=Job.getInstance(conf, ”Compteur de mots v1.0”) ;
Le package à importer est le suivant : org.apache.hadoop.mapreduce.Job
Minyar Sassi Hidri Technologies pour le Big Data 120 / 227](https://image.slidesharecdn.com/bigdata1-160410201905/75/Technologies-pour-le-Big-Data-121-2048.jpg)

![MapReduce du point de vue du développeur Java
Programmation Hadoop - Classe Driver
Exemple : Occurrences de mots (3)
I Ensuite, on doit indiquer où se situent nos données d’entrée et de sortie dans HDFS. On
utilise pour ce faire les classes Hadoop FileInputFormat et FileOutputFormat.
I Ces classes sont implémentées suivant un design pattern Singleton - il n’est pas nécessaire
de les instancier dans le cas qui nous intéresse (dans des cas plus complexe, on étendra
parfois la classe en question dans une nouvelle classe qui nous est propre).
On procède de la manière suivante :
FileInputFormat.addInputPath(job, new Path(ourArgs[0])) ;
FileOutputFormat.setOutputPath(job, new Path(ourArgs[1])) ;
Les packages à utiliser :
- org.apache.hadoop.mapreduce.lib.input.FileInputFormat
- org.apache.hadoop.mapreduce.lib.input.FileOutputFormat
- org.apache.hadoop.fs.Path
Minyar Sassi Hidri Technologies pour le Big Data 122 / 227](https://image.slidesharecdn.com/bigdata1-160410201905/75/Technologies-pour-le-Big-Data-123-2048.jpg)

![MapReduce du point de vue du développeur Java
Programmation Hadoop - Classe Driver
Exemple : Occurrences de mots (5)
// Notre classe Driver (contient le main du programme Hadoop).
public class WCount
{
// Le main du programme.
public static void main(String[] args) throws Exception
{
// Créé un object de configuration Hadoop.
Configuration conf=new Configuration() ;
// Permet à Hadoop de lire ses arguments génériques, récupère les arguments restants dans ourArgs.
String[] ourArgs=new GenericOptionsParser(conf,args).getRemainingArgs() ;
// Obtient un nouvel objet Job : une tâche Hadoop. On
// fourni la configuration Hadoop ainsi qu’une description textuelle de la tâche.
Job job=Job.getInstance(conf, ”Compteur de mots v1.0”) ;
// Défini les classes driver, map et reduce.
job.setJarByClass(WCount.class) ; job.setMapperClass(WCountMap.class) ;
job.setReducerClass(WCountReduce.class) ;
// Défini types clefs/valeurs de notre programme Hadoop.
job.setOutputKeyClass(Text.class) ;
job.setOutputValueClass(IntWritable.class) ;
// Définit les fichiers d’entrée du programme et le répertoire des résultats.
// On se sert du premier et du deuxième argument restants pour permettre à
// l’utilisateur de les spécifier lors de l’exécution.
FileInputFormat.addInputPath(job, new Path(ourArgs[0])) ;
FileOutputFormat.setOutputPath(job, new Path(ourArgs[1])) ;
// On lance la tâche Hadoop. Si elle s’est effectuée correctement, on renvoie 0. Sinon, on renvoie -1.
if(job.waitForCompletion(true))
System.exit(0) ; System.exit(-1) ;
} }
Minyar Sassi Hidri Technologies pour le Big Data 124 / 227](https://image.slidesharecdn.com/bigdata1-160410201905/75/Technologies-pour-le-Big-Data-125-2048.jpg)







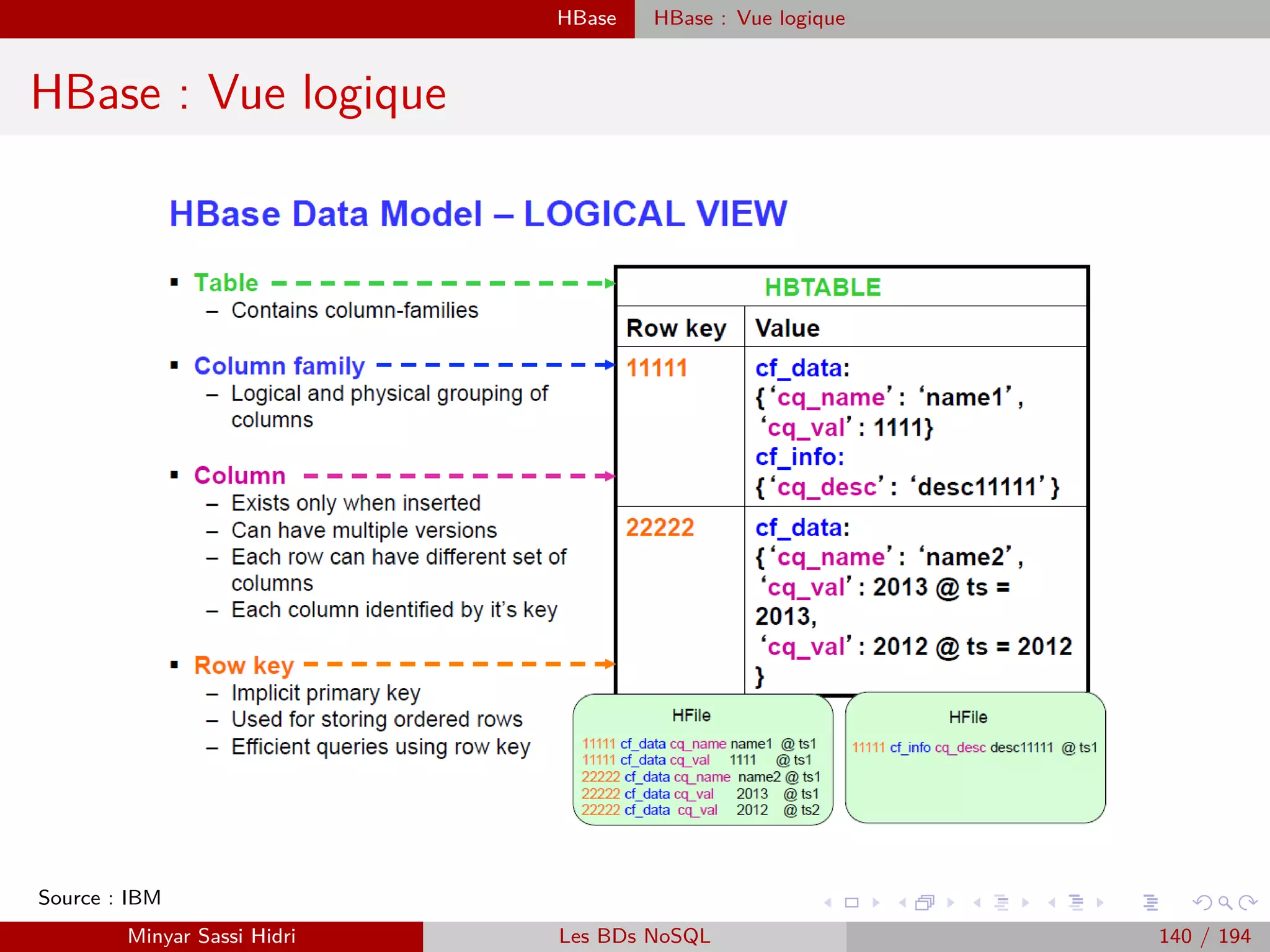
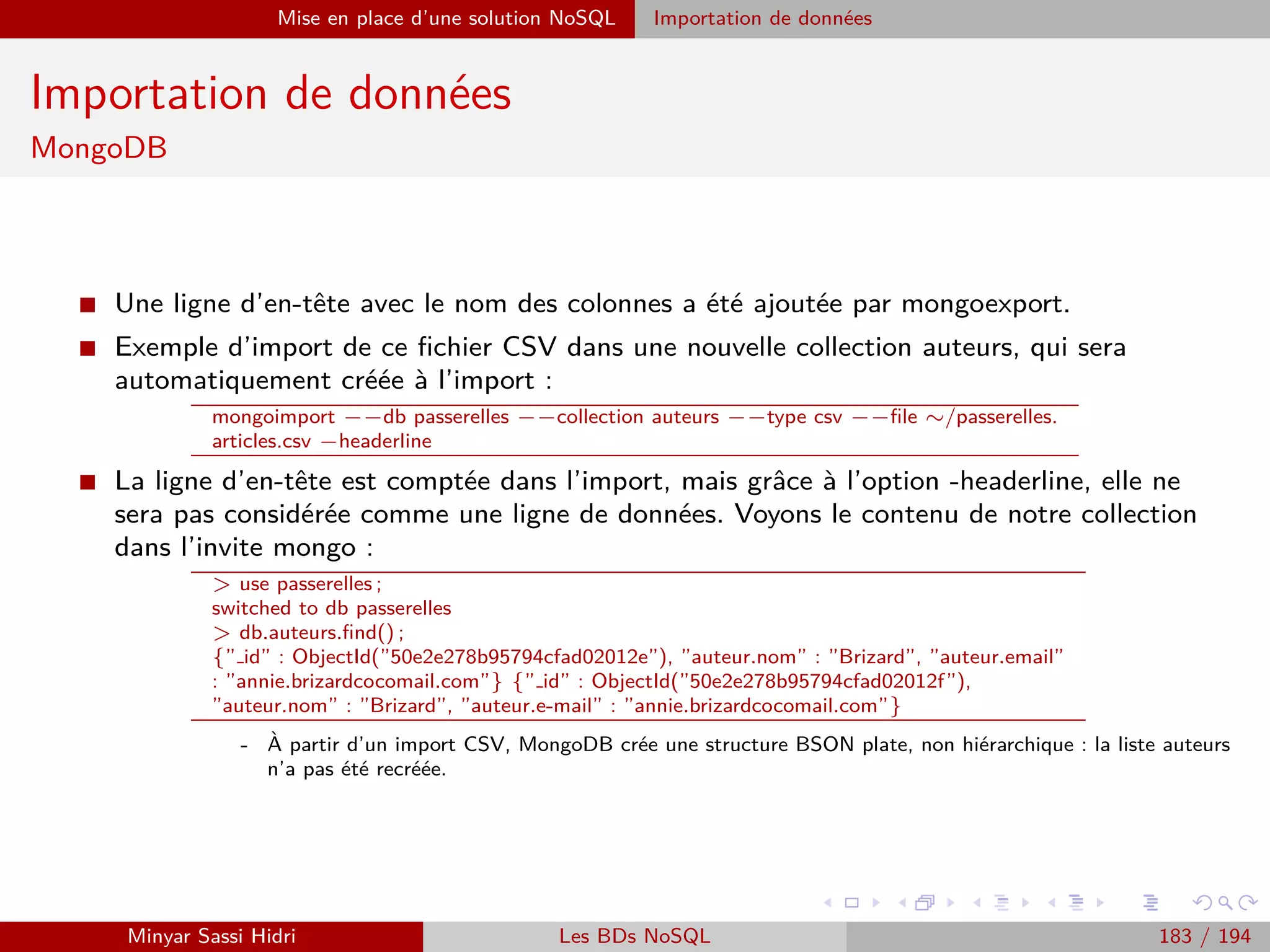
![Création d’un projet Java Wordcount sous Eclipse
Exécution du Jar sous Hadoop avec la distribution Cloudera
Notre entrée
[clouderaquickstart ∼]$hadoop fs -cat /home/cloudera/wordcount.txt
Hello Hadoop Goodbye Hadoop
Affichage du contenu du système de fichiers :
[cloudera@quickstart ∼]$ hadoop fs -ls
Found 3 items
drwx—— - cloudera cloudera 0 2015-03-24 09 :41 .Trash
drwx—— - cloudera cloudera 0 2015-03-24 19 :01 .staging
drwxr-xr-x - cloudera cloudera 0 2015-03-24 19 :01 oozie-oozi
Copie du fichier dans HDFS
[clouderaquickstart ∼]$ hadoop fs -mkdir Data Input
[clouderaquickstart ∼]$ hadoop fs -put /home/cloudera/wordcount.txt Data Input/
[clouderaquickstart ∼]$ hadoop fs -ls Data Input
Found 1 items
-rw-r–r– 1 cloudera cloudera 30 2015-03-24 20 :23 input/wordcount.txt
[clouderaquickstart ∼]$ hadoop fs -cat input/wordcount.txt
Hello Hadoop, Goodbye Hadoop.
[clouderaquickstart ∼]$
Exécution
[clouderaquickstart ∼]$ hadoop jar /home/cloudera/WCount.jar WCount Data Input/wordcount.txt Output
Affichage du contenu du répertoire Output
[clouderaquickstart ∼]$ hadoop fs -ls output
Affichage du résultat
[clouderaquickstart ∼]$ hadoop fs -cat Output/part-00000
Goodbye 1 Hadoop 2 Hello 1
Minyar Sassi Hidri Technologies pour le Big Data 141 / 227](https://image.slidesharecdn.com/bigdata1-160410201905/75/Technologies-pour-le-Big-Data-142-2048.jpg)




![Hadoop Streaming
Streaming - Map
I Lorsqu’on développe un programme Map Hadoop dans un autre langage pour
son utilisation avec l’outil streaming, les données d’entree doivent être lues
sur l’entree standard (stdin) et les données de sorties doivent être envoyées
sur la sortie standard (stdout).
I En entrée du script ou programme Map, on aura une série de lignes : nos
données d’entrée (par exemple dans le cas du compteur d’occurrences de
mots, des lignes de notre texte).
I En sortie du script ou programme Map, on doit écrire sur stdout notre série
de couples (key, value) au format : Key[TABULATION]Value.
...avec une ligne distincte pour chaque (key,value).
Minyar Sassi Hidri Technologies pour le Big Data 147 / 227](https://image.slidesharecdn.com/bigdata1-160410201905/75/Technologies-pour-le-Big-Data-148-2048.jpg)
![Hadoop Streaming
Streaming - Reduce
I Lorsqu’on développe un programme Reduce Hadoop dans un autre langage
pour son utilisation avec l’outil streaming, les données d’entree et de sortie
doivent être la aussi lues/ecrites sur stdin et stdout (respectivement).
I En entrée du script ou programme Reduce, on aura une série de lignes : des
couples (key,value) au format : Key[TABULATION]Value.
I Les couples seront triés par clé distincte, et la clé répétée à chaque fois. Par
ailleurs, on est susceptible d’avoir des clés différentes au sein d’une seule et
même exécution du programme reduce.
I En sortie du script ou programme Reduce, on doit écrire des couples (key,value),
toujours au format Key[TABULATION]Value.
Remarque : d’ordinaire, on écrira évidemment un seul couple (key,value) par
clé distincte.
Minyar Sassi Hidri Technologies pour le Big Data 148 / 227](https://image.slidesharecdn.com/bigdata1-160410201905/75/Technologies-pour-le-Big-Data-149-2048.jpg)
![Hadoop Streaming
Exécution du Jar sous Hadoop Streaming avec la
distribution Cloudera
Notre entrée
[clouderaquickstart ∼]$ cat /home/cloudera/wordcount.txt
Hello Hadoop Goodbye Hadoop
Affichage du contenu du système de fichiers :
[cloudera@quickstart ∼]$ hadoop fs -ls
Copie du fichier dans HDFS
[clouderaquickstart ∼]$ hadoop fs -mkdir Data Input
[clouderaquickstart ∼]$ hadoop fs -put /home/cloudera/wordcount.txt Data Input/
[clouderaquickstart ∼]$ hadoop fs -ls Data Input
Création de deux fichiers mapper.py et reducer.py :
http ://www.michael-noll.com/tutorials/writing-an-hadoop-mapreduce-program-in-python/
Attribution des rôles :
[clouderaquickstart ∼]$chmod +x /home/cloudera/mapper.py
[clouderaquickstart ∼]$chmod +x /home/cloudera/reducer.py
Exécution
[clouderaquickstart ∼]$ hadoop jar
/usr/lib/hadoop-0.20-mapreduce/contrib/streaming/hadoop-streaming-2.5.0-mr1-cdh5.3.0.jar -file
/home/cloudera/mapper.py -mapper /home/cloudera/mapper.py -file /home/cloudera/reducer.py -reducer
/home/cloudera/reducer.py -input Data Input -output Output
Affichage du résultat
[clouderaquickstart ∼]$ hadoop fs -cat Output/part-00000
Goodbye 1 Hadoop 2 Hello 1
Minyar Sassi Hidri Technologies pour le Big Data 149 / 227](https://image.slidesharecdn.com/bigdata1-160410201905/75/Technologies-pour-le-Big-Data-150-2048.jpg)

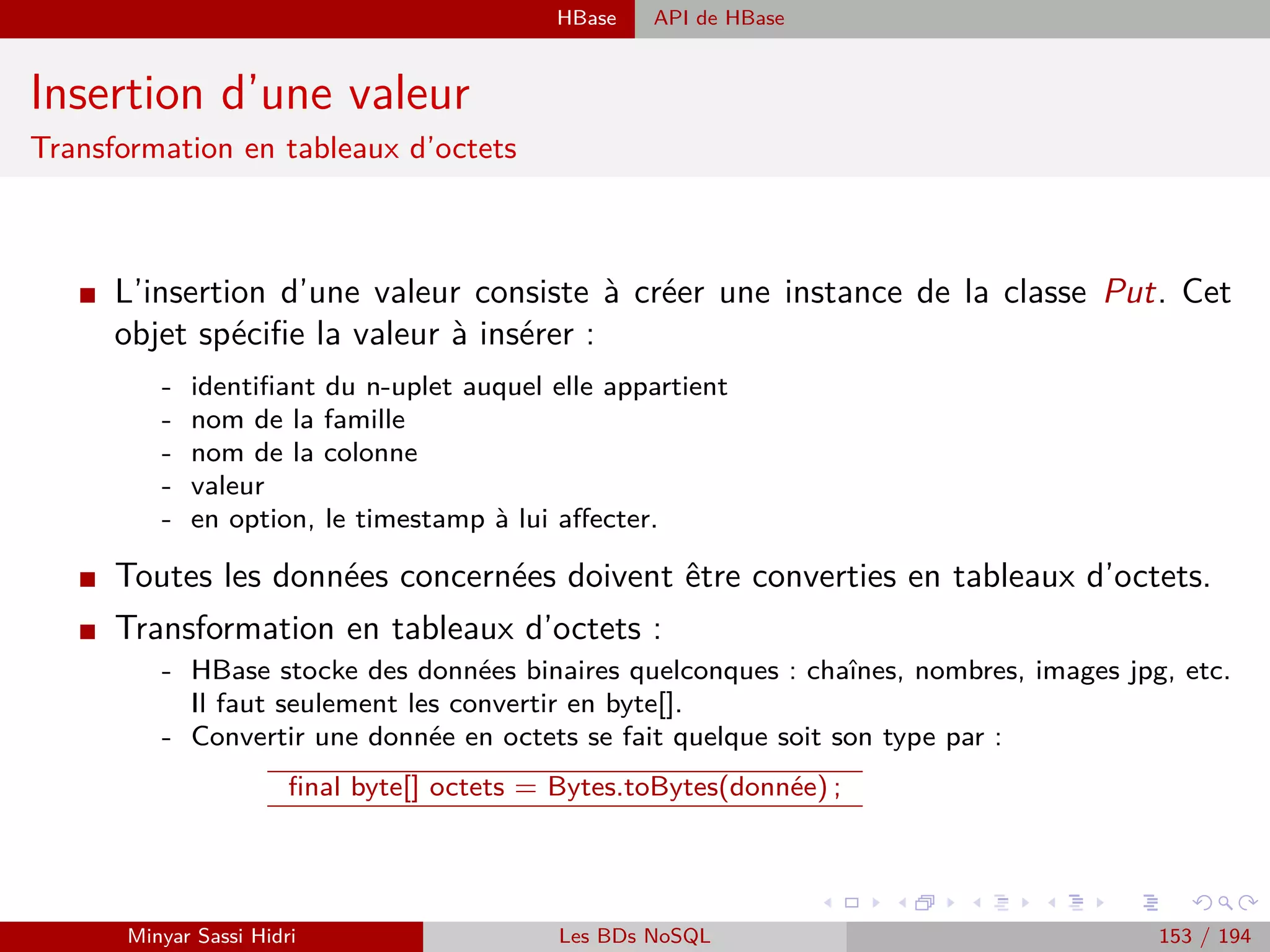
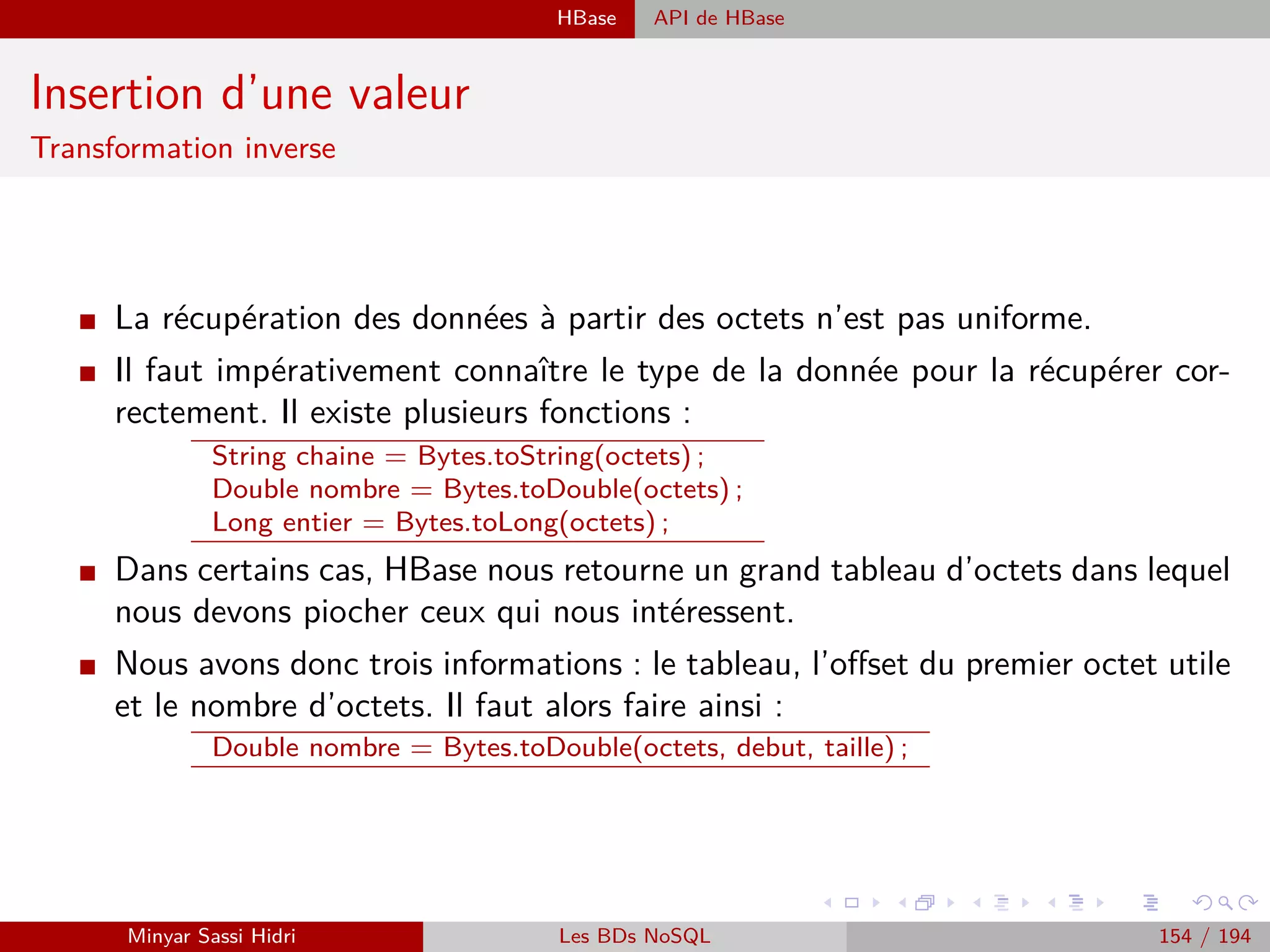
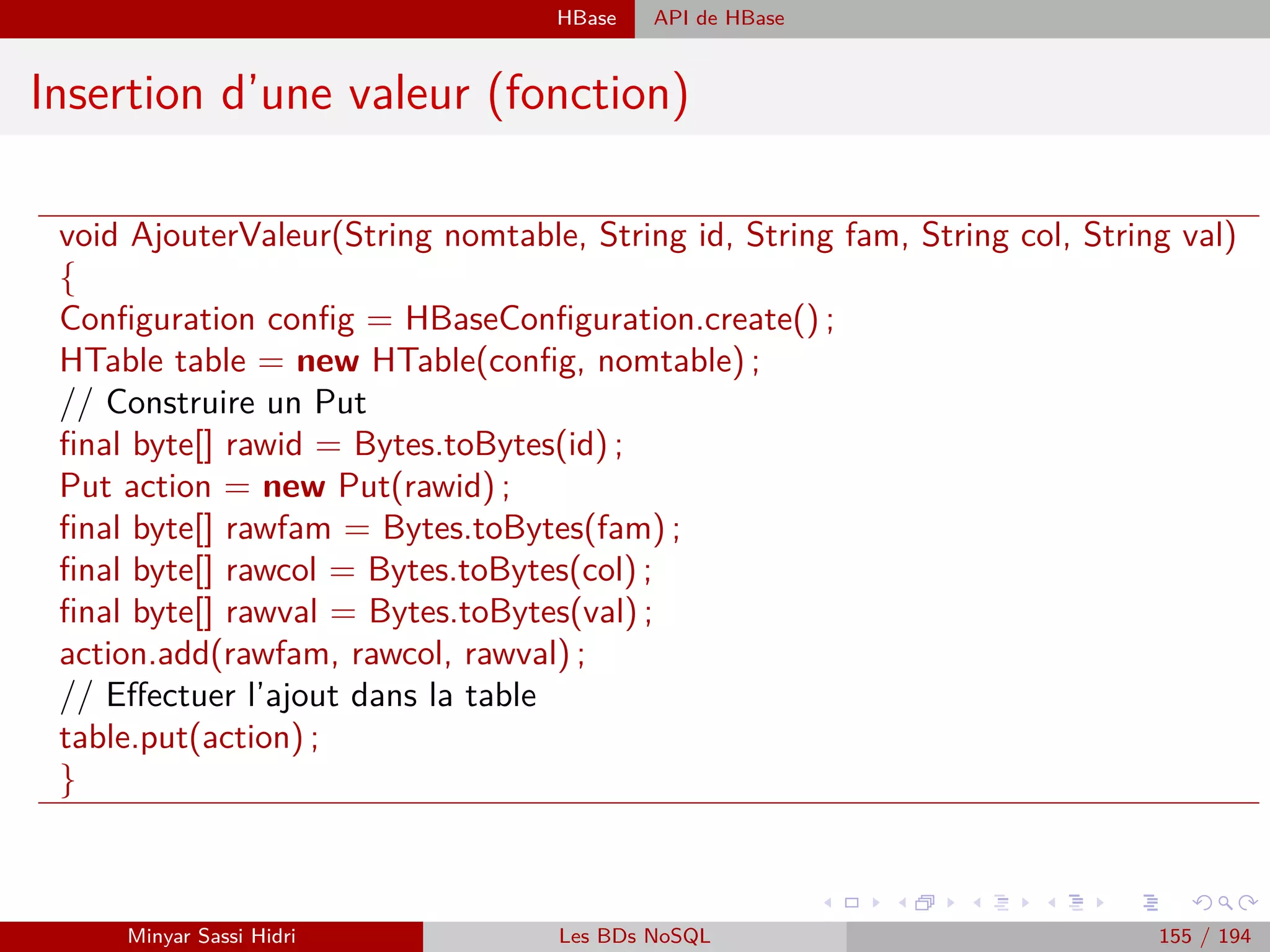

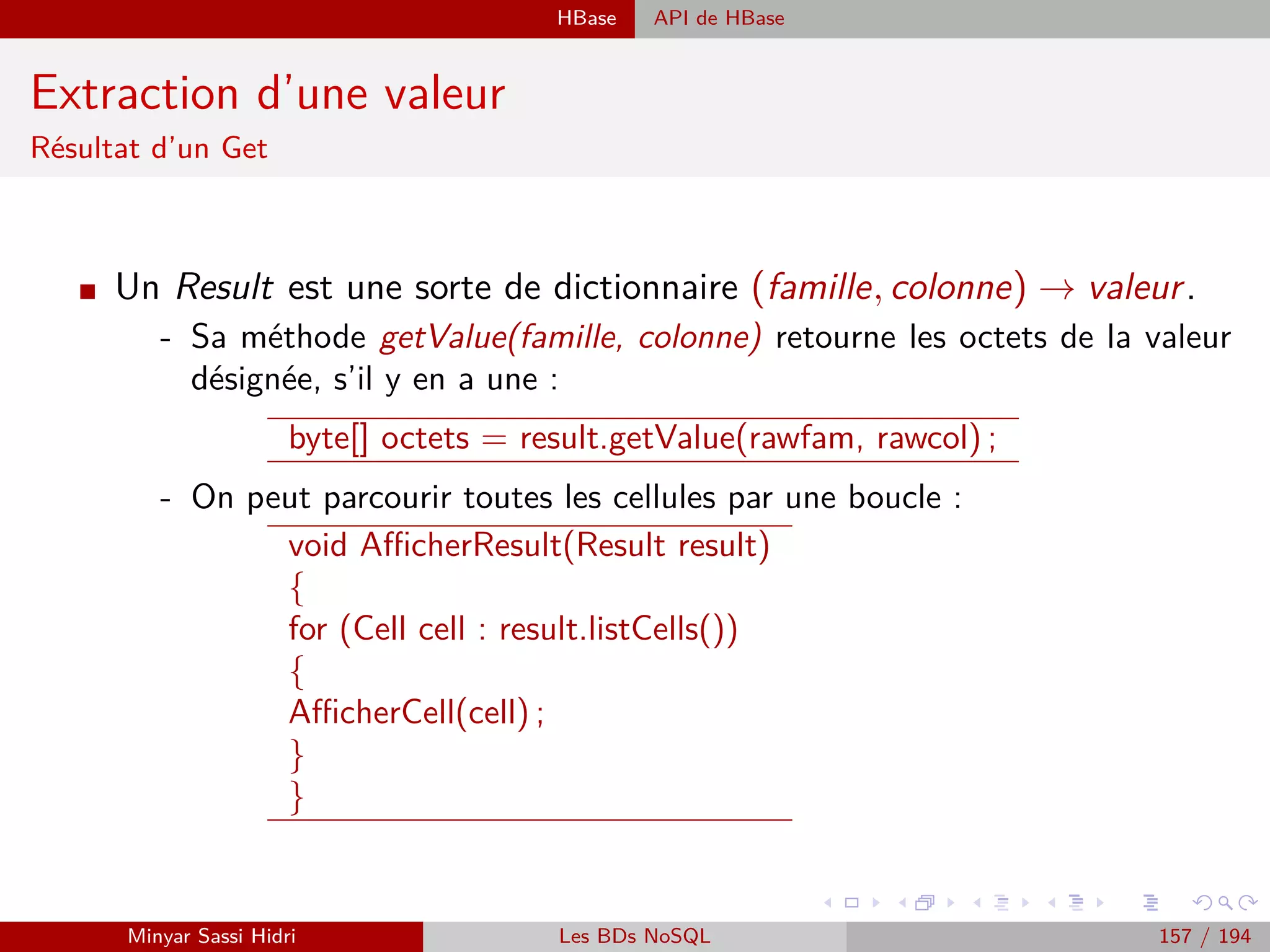

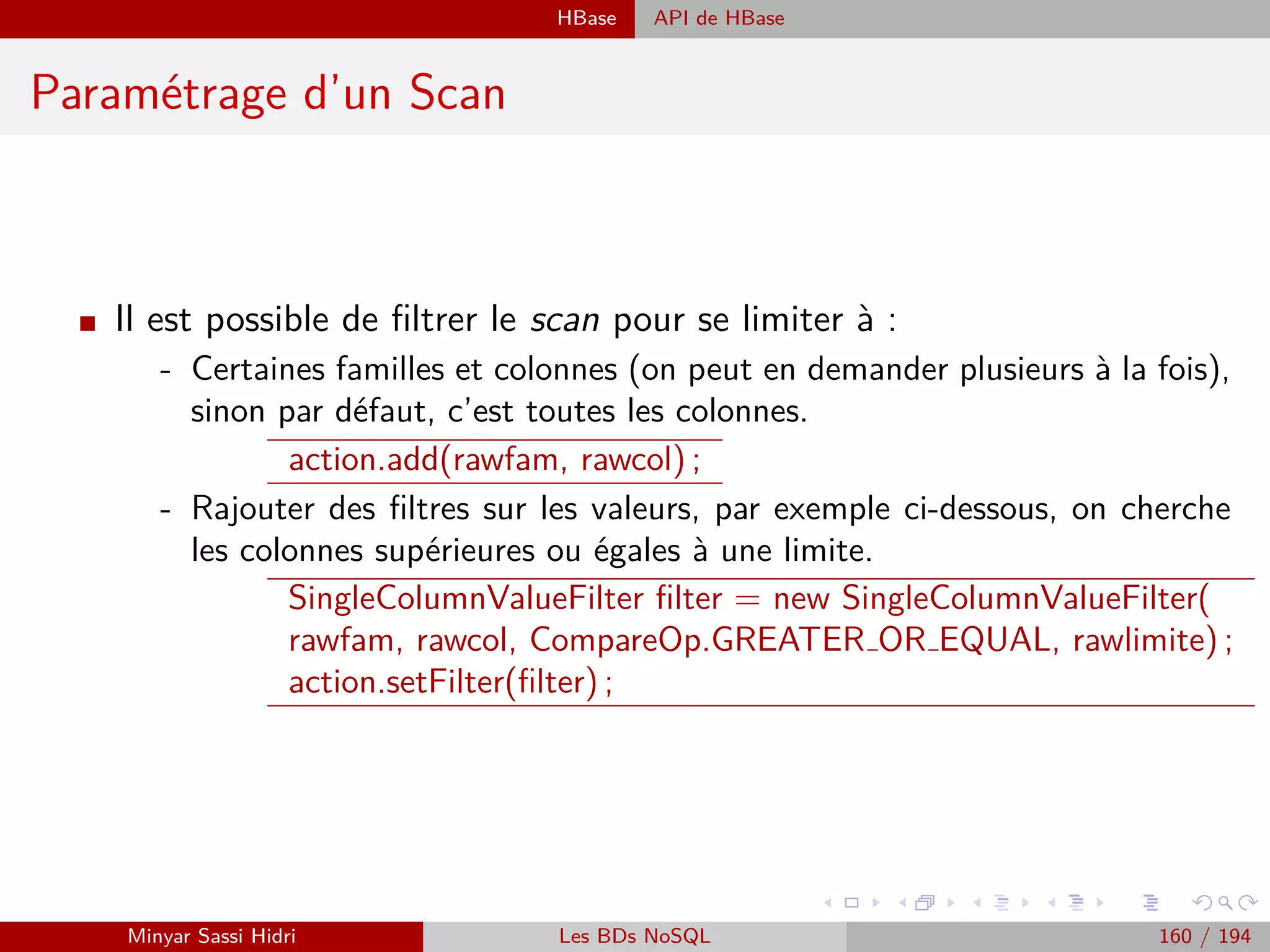


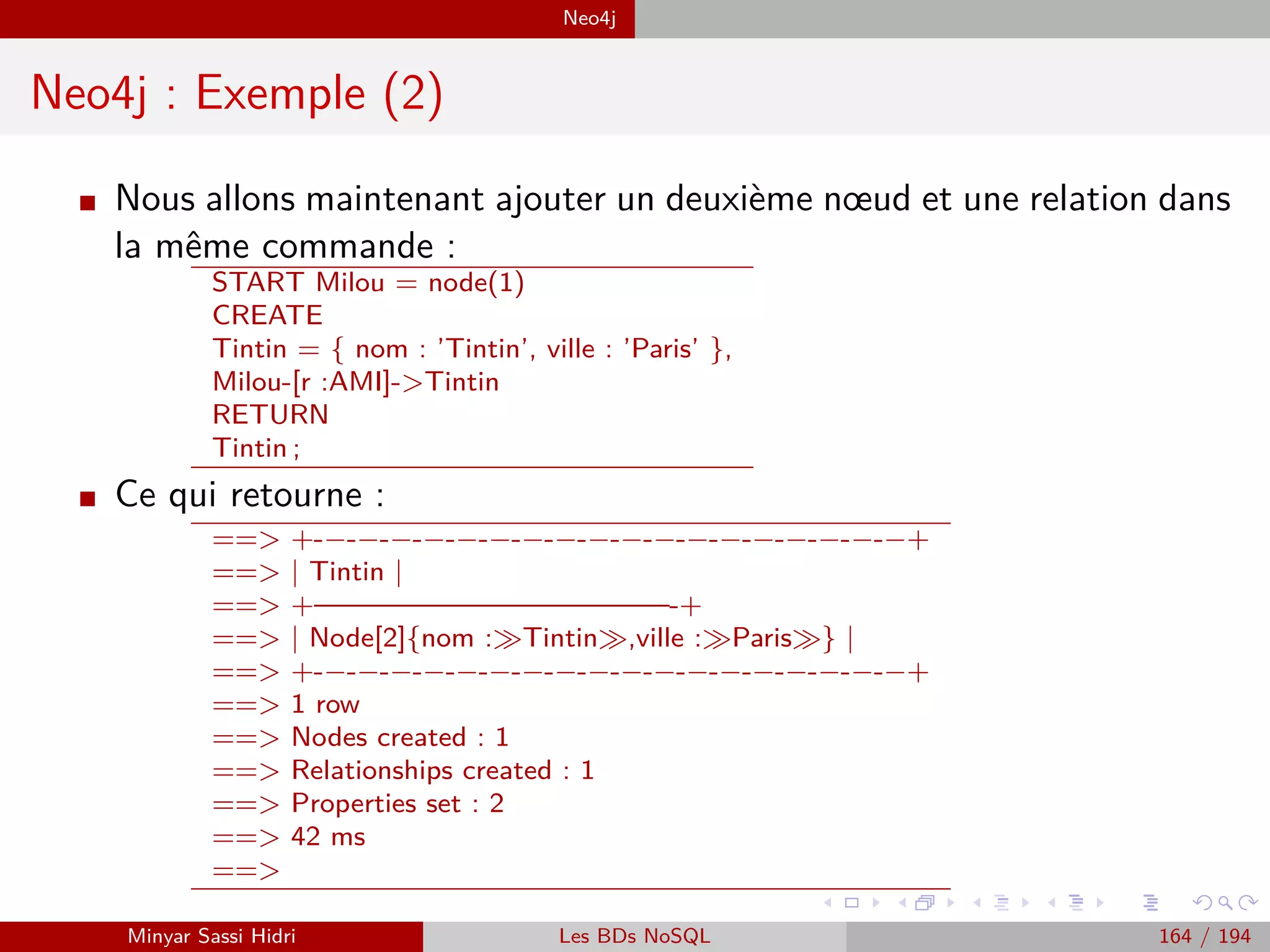








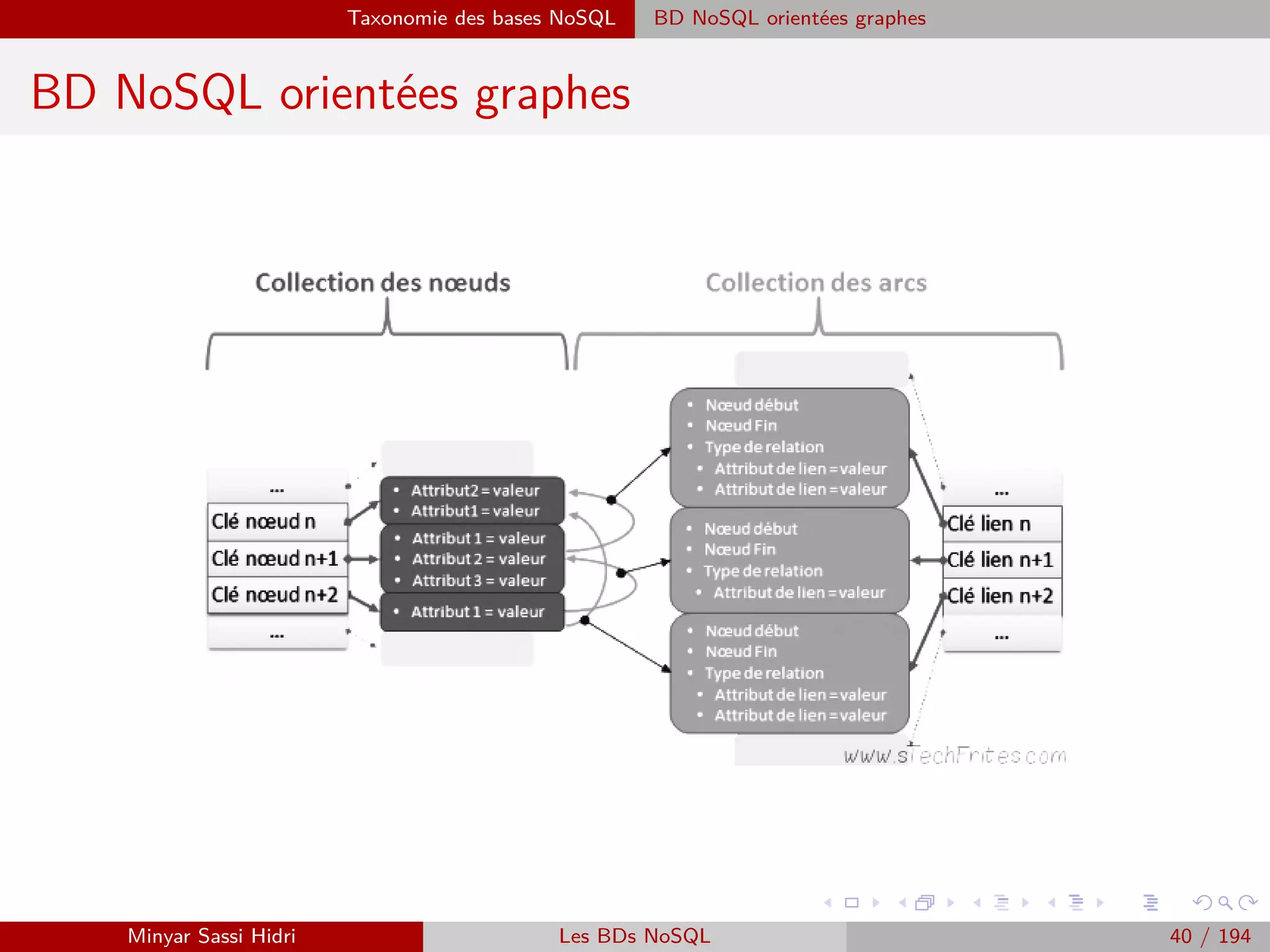
![Requêtage des données Hadoop : Pig, Hive, Spark et SparkQL Apache Pig
Types
I Pig supporte les types de données usuels suivants :
- int : un entier sur 32 bits.
- long : un entier sur 64 bits.
- float : un flottant sur 32 bits.
- double : un flottant sur 64 bits.
- chararray : une chaîne de caractères UTF-8.
- bytearray : une chaîne binaire.
- boolean : un booléen (true/false).
I Pig supporte également les trois types complexes suivants :
- tuple : une série de données. Par exemple : (12, John, 5.3)
- bag : un ensemble de tuples. Par exemple : {(12, John, 5.3), (8), (3.5, TRUE, Bob,
42)}
- map : une série de couples (clef ;valeur). Par exemple : [qui#22, le#3] (ici avec
deux couples clef ;valeur). Au sein d’un type map, chaque clef doit être unique.
Minyar Sassi Hidri Technologies pour le Big Data 175 / 227](https://image.slidesharecdn.com/bigdata1-160410201905/75/Technologies-pour-le-Big-Data-176-2048.jpg)
![Requêtage des données Hadoop : Pig, Hive, Spark et SparkQL Apache Pig
Types
I Un tuple peut tout à fait contenir d’autres tuples, ou encore des bags,
ou autres types simples et complexes.
I Par exemple :
({(1, 2), (3, John)}, 3, [qui#23])
- Un bag contenant lui-même deux tuples.
- Un entier de valeur 3.
- Un map contenant un seul couple (clef ;valeur).
Minyar Sassi Hidri Technologies pour le Big Data 176 / 227](https://image.slidesharecdn.com/bigdata1-160410201905/75/Technologies-pour-le-Big-Data-177-2048.jpg)
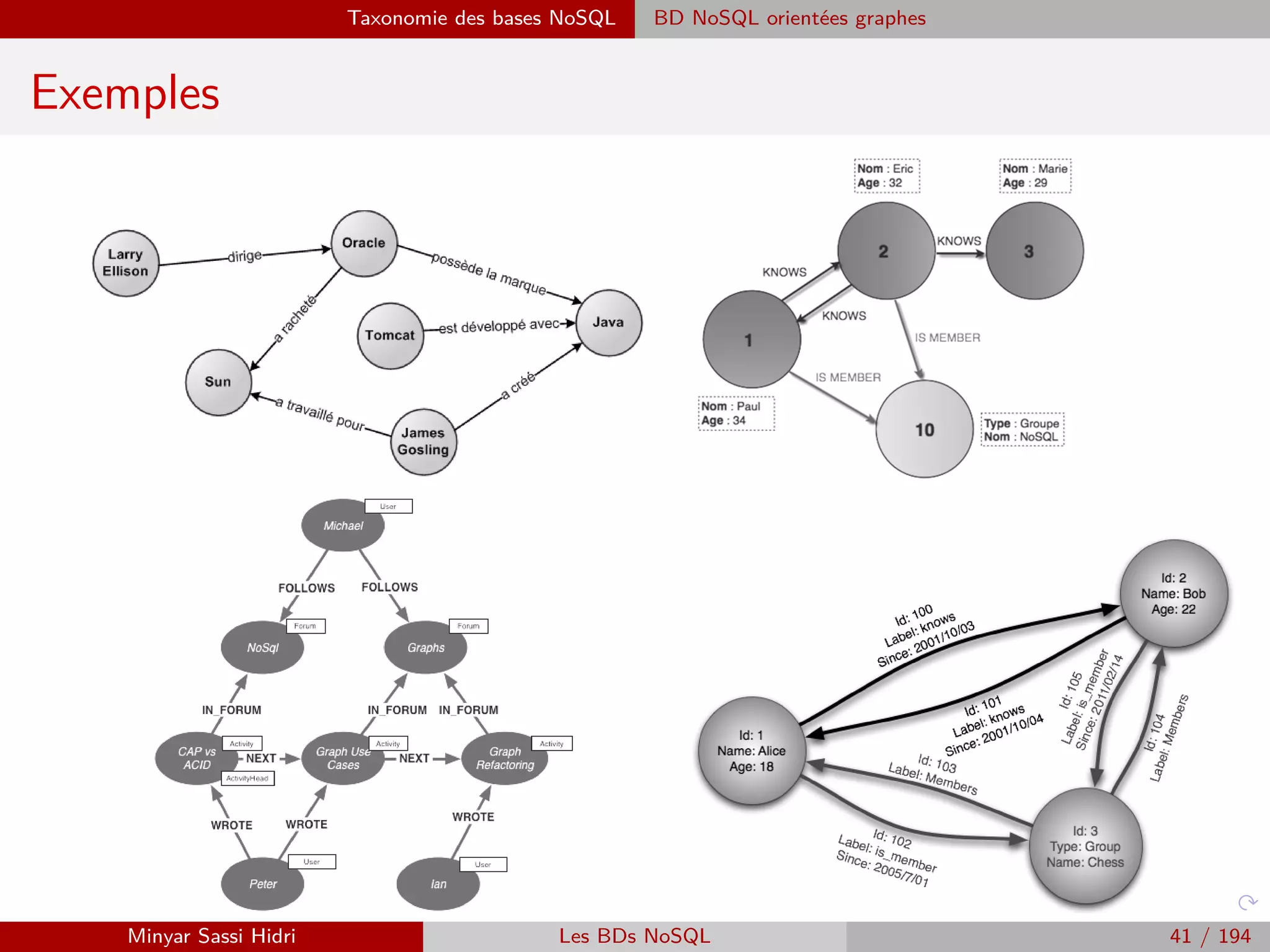
![Requêtage des données Hadoop : Pig, Hive, Spark et SparkQL Apache Pig
Chargement de données
I Les données d’entrée d’un programme pig seront typiquement chargées au
sein d’un bag.
I Pour charger des données depuis le système de fichier (HDFS en mode
MapReduce ou système de fichiers local en mode local), on utilise la
commande LOAD.
I Synopsis :
LOAD ’source’ [USING fonction] [AS schemas]
- où source est le nom du/des fichier(s) ou répertoire(s).
- fonction le nom d’une fonction d’importation.
- schemas un descriptif du format des données importées.
I Le paramètre source peut être :
- Un fichier unique, par exemple data.txt.
- Un répertoire (chargera tous les fichiers du répertoire), par exemple Data Input.
- Une expression complexe au même format que celles comprises par Hadoop/HDFS,
par exemple : Data Input/input-1-*.
Minyar Sassi Hidri Technologies pour le Big Data 177 / 227](https://image.slidesharecdn.com/bigdata1-160410201905/75/Technologies-pour-le-Big-Data-178-2048.jpg)

![Requêtage des données Hadoop : Pig, Hive, Spark et SparkQL Apache Pig
Chargement de données
I La fonction de chargement PigStorage permet ainsi facilement de charger un fichier
textuel avec des délimiteurs.
I Comme indiqué précédemment, le paramètre fonction est optionnel. Si on n’indique pas
de fonction, alors la fonction utilisée est PigStorage, avec un séparateur correspondant à
une tabulation.
I Ainsi, imaginons que notre fichier d’entrée etudiants.txt ait le format suivant :
ADAM[TAB]Guillaume[TAB]15
BERCHANE[TAB]Rachid[TAB]18
BOULLAIRE[TAB]Alexandre[TAB]16
BOYER[TAB]Raphael[TAB]17
CHAMPOUSSIN[TAB]Luca[TAB]14
CODA[TAB]Stephen[TAB]15
I Si on exécute :
A = LOAD ’etudiants.txt’ ;
...alors A contiendra le bag de tuples suivant :
(ADAM,Guillaume,15)
(BERCHANE,Rachid,18)
(BOULLAIRE,Alexandre,16)
(BOYER,Raphael,17)
(CHAMPOUSSIN,Luca,14)
(CODA,Stephen,15)
(avec trois champs texte, texte et entier par tuple)
Minyar Sassi Hidri Technologies pour le Big Data 180 / 227](https://image.slidesharecdn.com/bigdata1-160410201905/75/Technologies-pour-le-Big-Data-181-2048.jpg)




![Requêtage des données Hadoop : Pig, Hive, Spark et SparkQL Apache Pig
Sauvegarde de données : STORE
I La seconde est la commande STORE, qui sauve véritablement des
données au sein du système de fichier (HDFS ou local selon le mode).
I Syntaxe :
STORE alias INTO ’repertoire’ [USING fonction] ;
alias représente le container à sauvegarder (par exemple A).
I Comme les données sont issues d’une tâche MapReduce, elles seront
stockées sous la forme de plusieurs fichiers part-r-*.
I En conséquence, repertoire indique le répertoire dans lequel on
souhaite que la série de fichiers résultants de la tâche/du stockage
soient écrits.
Minyar Sassi Hidri Technologies pour le Big Data 189 / 227](https://image.slidesharecdn.com/bigdata1-160410201905/75/Technologies-pour-le-Big-Data-190-2048.jpg)


![Requêtage des données Hadoop : Pig, Hive, Spark et SparkQL Apache Pig
Autres commandes
I Le shell interactif de Pig offre quelques commandes pratiques pour le
développeur.
I L’une de ces commandes est cat : comme la commande cat Unix, elle
affiche le contenu d’un fichier.
I En revanche, dans le cadre de Pig, elle est étendue au fonctionnement
Hadoop ; si on fait cat [REPERTOIRE] la commande affichera
automatiquement le contenu concaténé de tous les fichiers du répertoire.
I Autres commandes uniquement disponibles en mode interactif :
- help : affiche une aide.
- sh [COMMANDE] : exécute une commande shell.
- exec [FICHIER.PIG] : exécute le script pig indique.
- history : affiche un historique de toutes les commandes utilisées.
- ls, mkdir, rm, etc. : équivalentes à Unix.
- ...
Minyar Sassi Hidri Technologies pour le Big Data 193 / 227](https://image.slidesharecdn.com/bigdata1-160410201905/75/Technologies-pour-le-Big-Data-194-2048.jpg)


![Requêtage des données Hadoop : Pig, Hive, Spark et SparkQL Apache Pig
L’opérateur ORDER
I L’opérateur ORDER permet de trier les éléments selon une condition.
C’est l’équivalent du ORDER BY de SQL.
I Syntaxe :
DEST = ORDER SOURCE BY FIELD [ASC|DESC] ;
I On pourra ainsi faire par exemple :
B = ORDER A BY note DESC ;
Ou encore :
B = ORDER A BY note DESC, nom ASC ;
Minyar Sassi Hidri Technologies pour le Big Data 196 / 227](https://image.slidesharecdn.com/bigdata1-160410201905/75/Technologies-pour-le-Big-Data-197-2048.jpg)
































Le document présente une analyse détaillée du big data, y compris sa définition, ses enjeux, ses sources et ses applications. Il aborde également les défis technologiques et stratégiques associés à la gestion de grandes quantités de données grâce à des outils comme Hadoop et MapReduce. En soulignant l'importance de l'intégration et de l'analyse des données, le texte met en lumière les opportunités offertes par le big data pour améliorer la prise de décision et la compétitivité des entreprises.




























































