ตัวอย่างข้อมูล Big Data
•ข้อมูลเครือข่ายสังคม
• ข้อมูลการบริการทางเว็บ
• ข้อมูลธุรกรรมทางธนาคาร
• ข้อมูลการสื่อสารจากโทรศัพท์เคลื่อนที่
• ข้อมูลภาพถ่ายดาวเทียม
• ข้อมูลสภาพอากาศ
9.
ทำไมต้องสนใจ Big Data
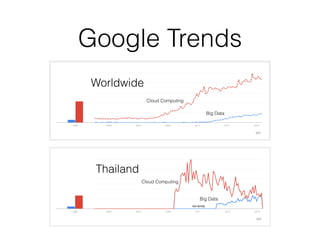
•ปัจจุบันเรามีข้อมูลที่หลายหลายรูปแบบ ปริมาณเยอะมาก
ถ้าเราเก็บไว้โดยที่ไม่ทำอะไรก็ไม่เกิดประโยชน์ แต่ถ้านำ
เอาเทคนิคความรู้ในด้าน Big Data เข้ามาช่วย นำข้อมูลที่
มีปริมาณเยอะมาประมวลผล วิเคราะห์ และนำข้อมูลเหล่า
นั้นไปใช้ให้เกิดประโยชน์






























































![Qcl 15-v4 [challenge-no 4 pareto graph]_[imnu]_[shubham gupta]](https://cdn.slidesharecdn.com/ss_thumbnails/qcl-15-v4challengeno4paretographimnushubhamgupta-150418023606-conversion-gate01-thumbnail.jpg?width=640&height=640&fit=bounds)

















