This document provides an overview of Bayesian inference:
- Bayesian inference uses Bayes' theorem to update probabilities of hypotheses as new evidence becomes available. It is widely used in science, engineering, medicine and other fields.
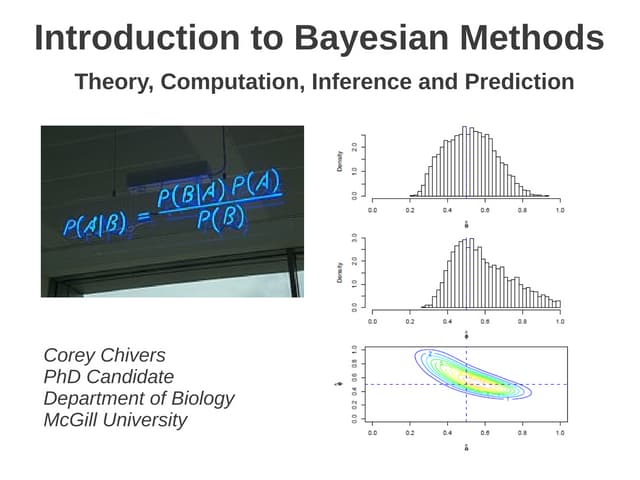
- Bayes' theorem calculates the posterior probability (probability after seeing evidence) based on the prior probability (initial probability) and the likelihood function (probability of evidence under the hypothesis).
- Common applications of Bayesian inference include artificial intelligence, expert systems, bioinformatics, and more. Advantages include incorporating prior information to improve predictions, while disadvantages include potential issues if prior information is incorrect.