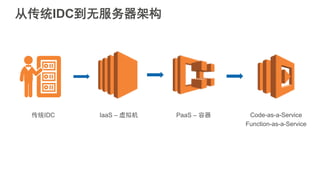
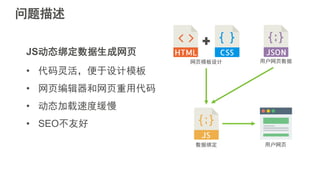
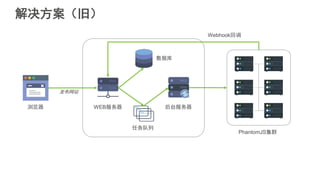
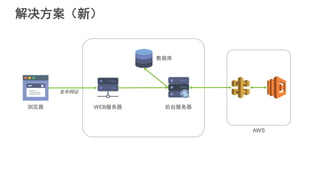
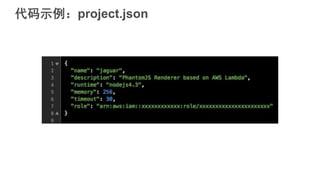
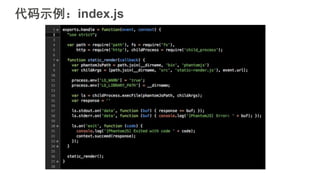
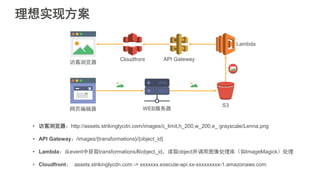
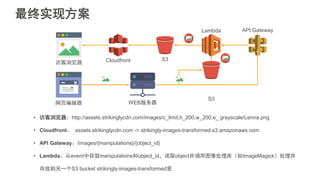
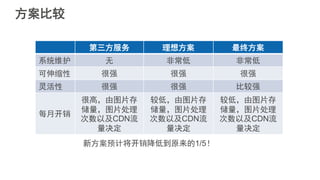
#5 互联网应用的构建平台经历了从传统IDC,到基于虚拟机技术的IaaS平台,到基于容器技术的PaaS平台三个阶段。大家可以看到,这个演化的过程一直在朝着降低运维成本,提升开发者生产力的方向前进。Strikingly在早期发展阶段使用的Heroku是典型的PaaS服务提供商。PaaS平台可以使我们关注在应用本身,不必关心服务器的配置和应用的部署等下层平台细节,从而提高开发迭代速度。当时我们在没有任何其他运维自动化工具的情况下依然可以每天部署多达十几次,这样快速迭代的能力在创业初期显得尤为重要。
但是,有了PaaS还不够。我们依然需要调节计算资源的数量来适应系统的负载变化。如果计算资源可以随着系统负载变化快速自动伸缩,不需要技术人员干预,那就更好了。无服务器计算的概念正是源于这样的需求。字面上理解,任何不需要服务器的架构都可以算是无服务器的架构,而事实上,我认为完全不需要管理计算资源,才是无服务器架构的极致体现。Lambda就提供了这样一种服务,我们称之为Code as a service或者Function as a service。