Download as PDF, PPTX








![The variational lower bound
We will learn an approximate of pΘ(z|x) : qΦ(z|x) by
maximizing a lower bound of the log-likelihood of the data
We can write :
logpΘ(x) = DKL(qΦ(z|x)||pΘ(z|x)) + L(Θ, φ, x) where:
L(Θ, Φ, x) = EqΦ(z|x)[logpΘ(x, z) − logqφ
(z|x)]
L(Θ, Φ, x)is called the variational lower bound, and the goal is
to maximize it w.r.t to all the parameters (Θ, Φ)
Diederik P Kingma, Max Welling Auto-encoding variational Bayes](https://image.slidesharecdn.com/auto-encoding-variational-bayes-151028133748-lva1-app6892/85/Auto-encoding-variational-bayes-8-320.jpg)
![Estimating the lower bound gradients
We need to compute
∂L(Θ,Φ,x)
∂Θ , ∂L(Θ,Φ,x)
∂φ to apply gradient
descent
For that, we use the reparametrisation trick : we sample
from a noise variable p( ) and apply a determenistic function
to it so that we obtain correct samples from qφ(z|x), meaning:
if ∼ p( ) we nd g so that if z = g(x, φ, ) then z ∼ qφ(z|x)
g can be the inverse CDF of qΦ(z|x) if is uniform
With the reparametrisation trick we can rewrite L:
L(Θ, Φ, x) = E ∼p( )[logpΘ(x, g(x, φ, )) − logqφ
(g(x, φ, )|x)]
We then estimate the gradients with Monte Carlo
Diederik P Kingma, Max Welling Auto-encoding variational Bayes](https://image.slidesharecdn.com/auto-encoding-variational-bayes-151028133748-lva1-app6892/85/Auto-encoding-variational-bayes-9-320.jpg)
![A connection with auto-encoders
Note that L can also be written in this form:
L(Θ, φ, x) = −DKL(qΦ(z|x)||pΘ(z)) + EqΦ(z|x)[logpΘ(x|z)]
We can interpret the rst term as a regularizer : it forces
qΦ(z|x) to not be too divergent from the prior pΘ(z)
We can interpret the (-second term) as the reconstruction
error
Diederik P Kingma, Max Welling Auto-encoding variational Bayes](https://image.slidesharecdn.com/auto-encoding-variational-bayes-151028133748-lva1-app6892/85/Auto-encoding-variational-bayes-10-320.jpg)


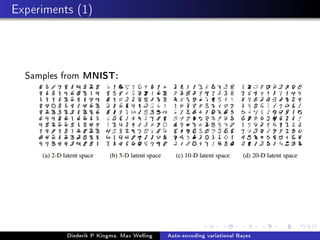

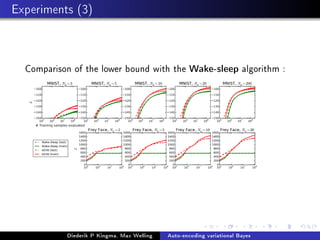


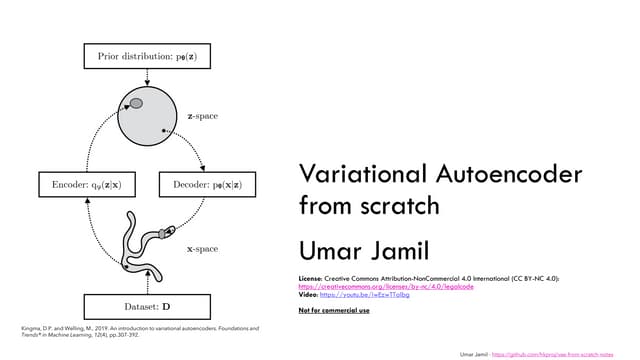
This document presents the method of auto-encoding variational Bayes for training generative models. The method approximates the intractable posterior distribution p(z|x) with a variational distribution q(z|x). It maximizes a variational lower bound on the likelihood by minimizing the KL divergence between the variational and true posteriors. This is done using the reparameterization trick to backpropagate through stochastic nodes. The method can be seen as training a variational autoencoder to generate data and learn a latent representation. Experiments show it generates realistic samples and outperforms other methods on held-out likelihood.


















































































![Polymer [ बहुलक ] Chemistry Notes PDF - Irfanullah Mehar - JJ Sir Chemistry.pdf](https://cdn.slidesharecdn.com/ss_thumbnails/polymerchemistrynotespdf-irfanullahmehar-jjsirchemistry-260210172118-3f9b37f7-thumbnail.jpg?width=640&height=640&fit=bounds)



