Downloaded 45 times












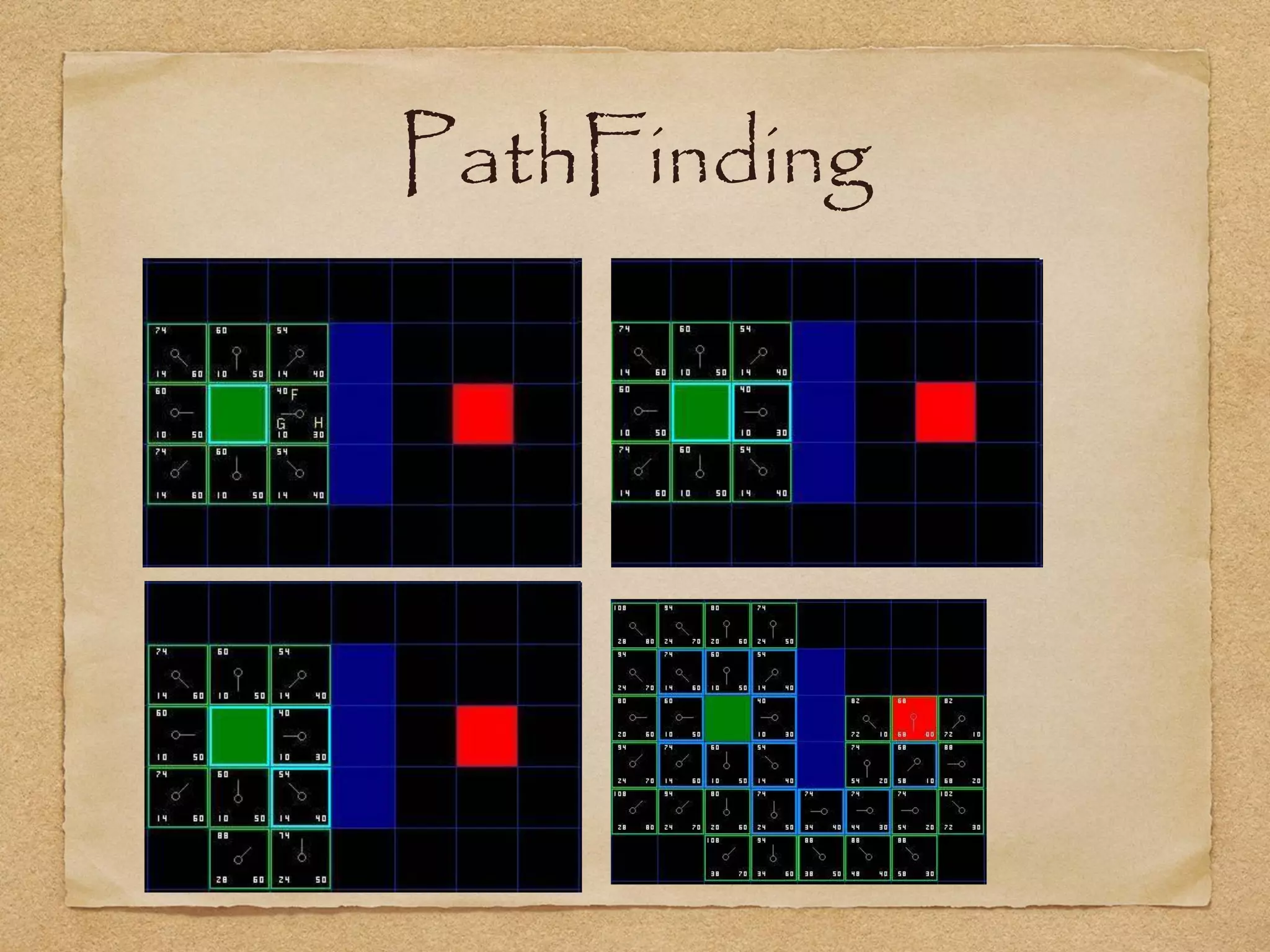
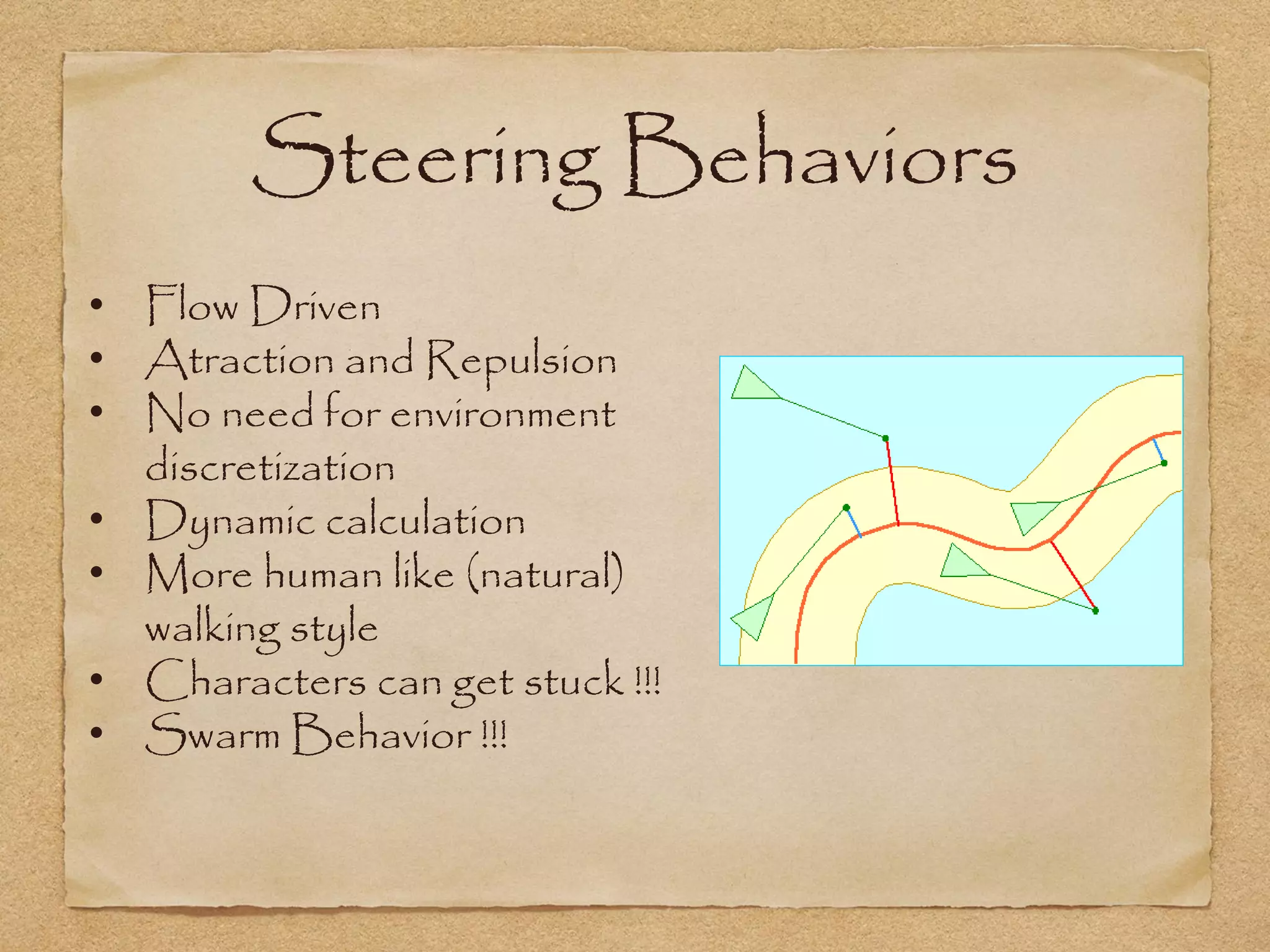
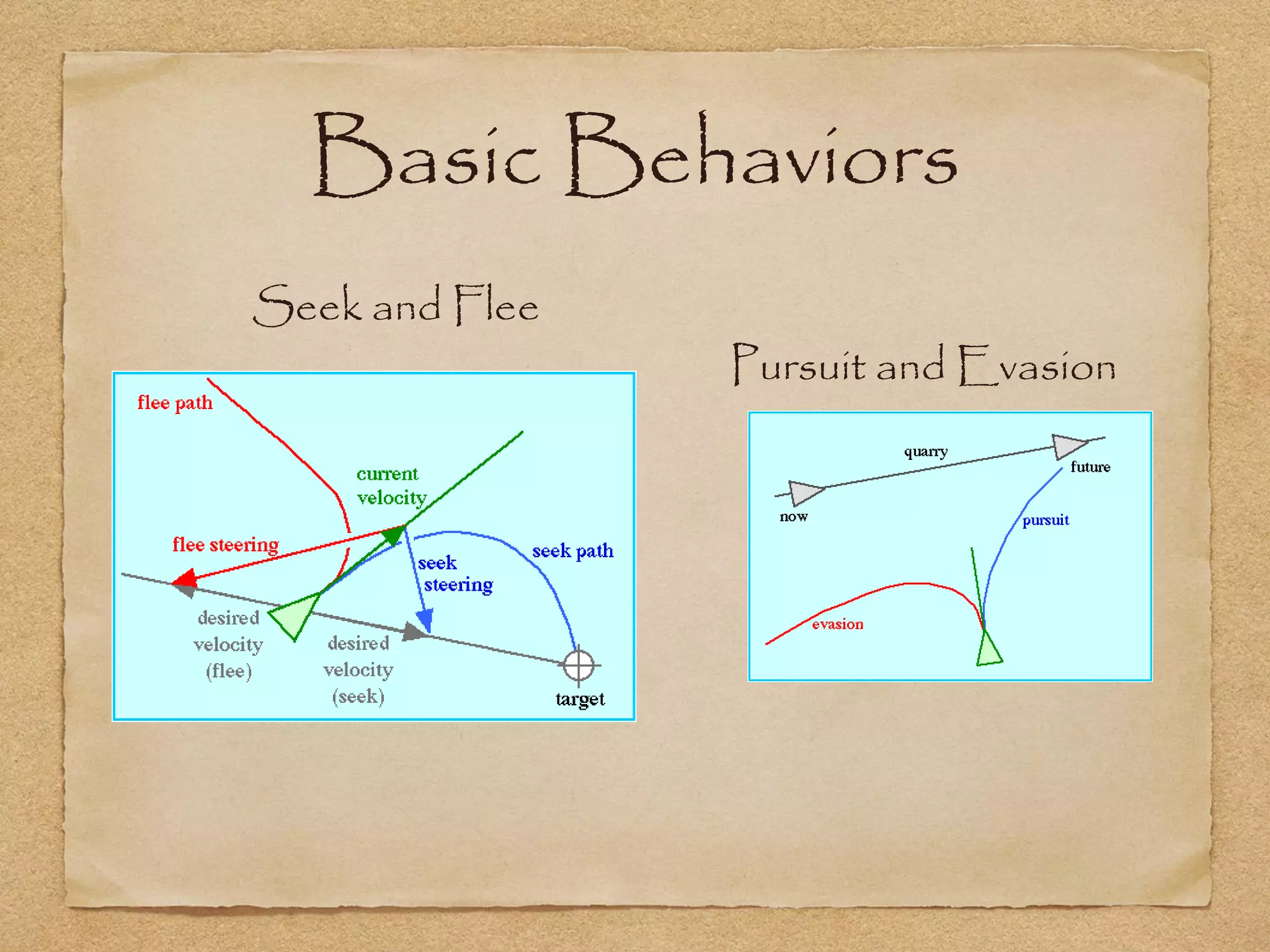
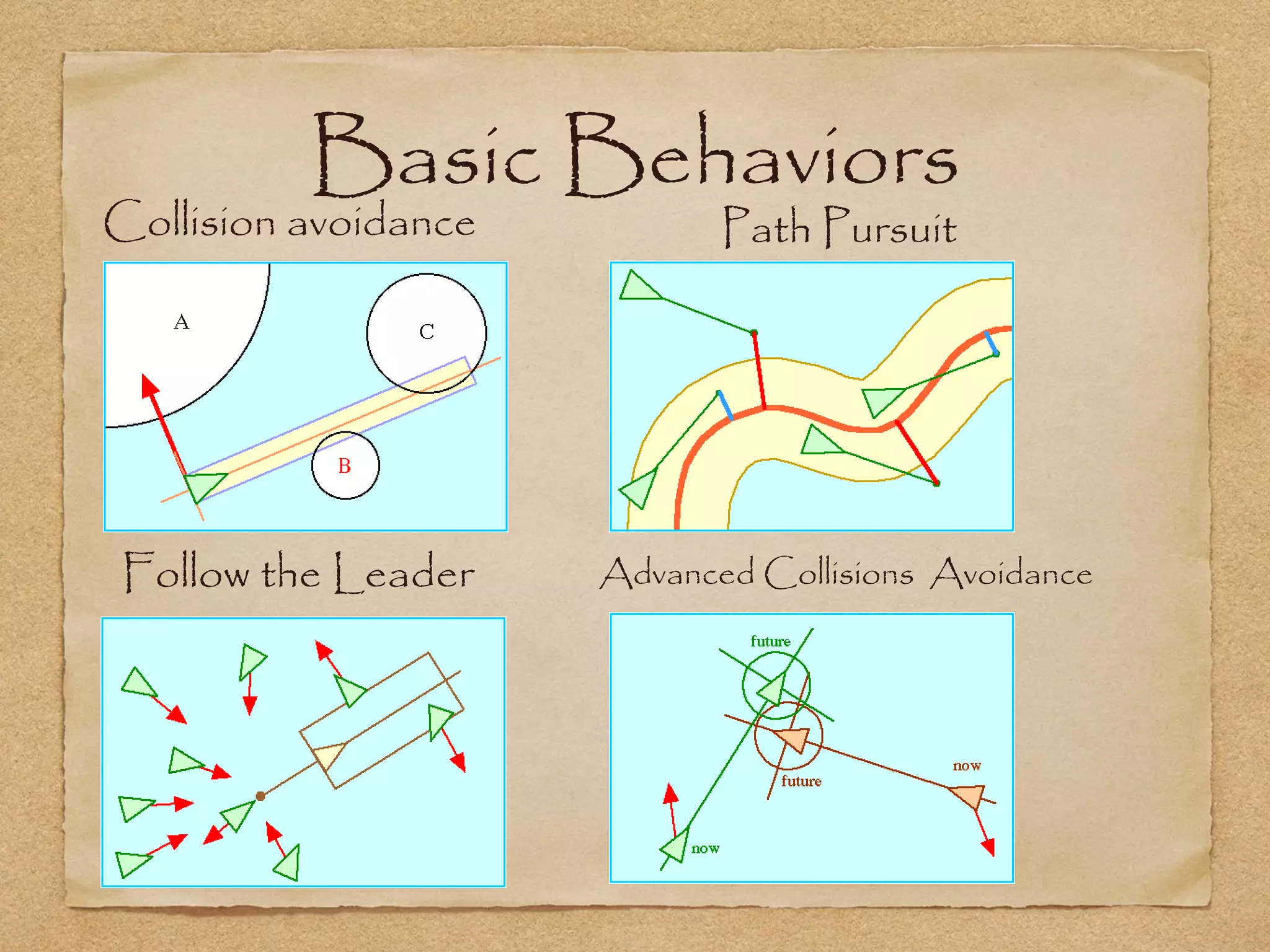




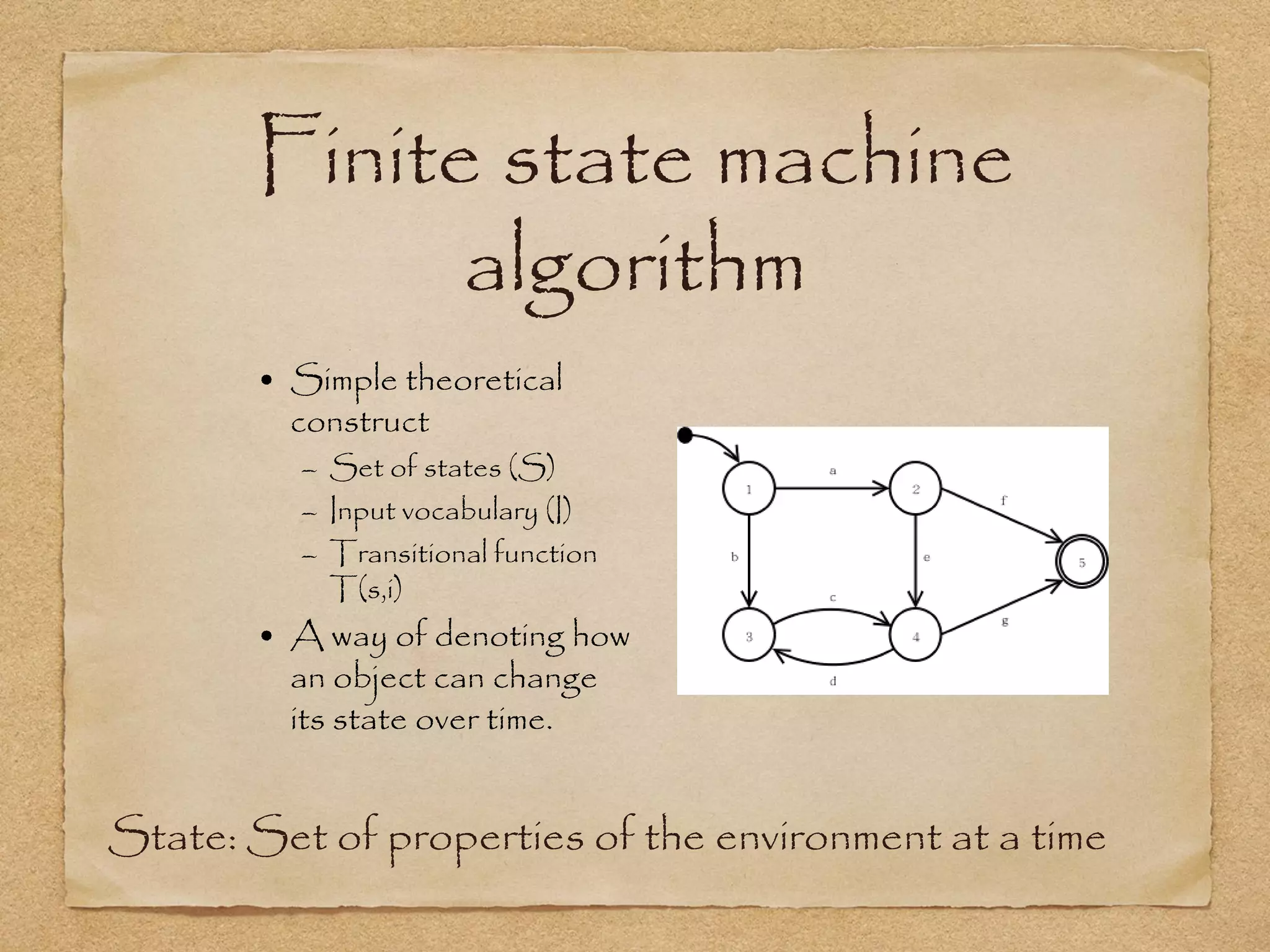
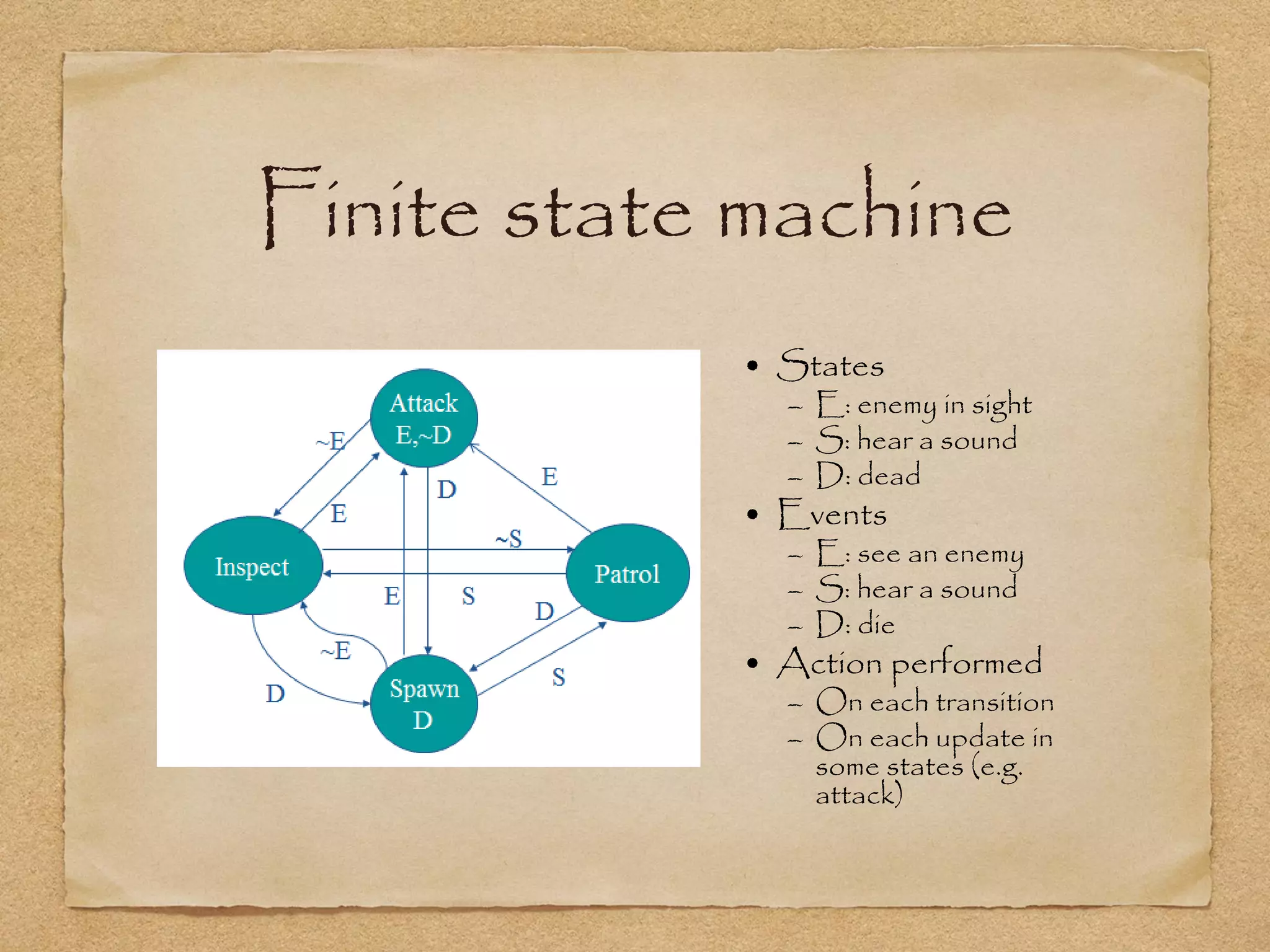



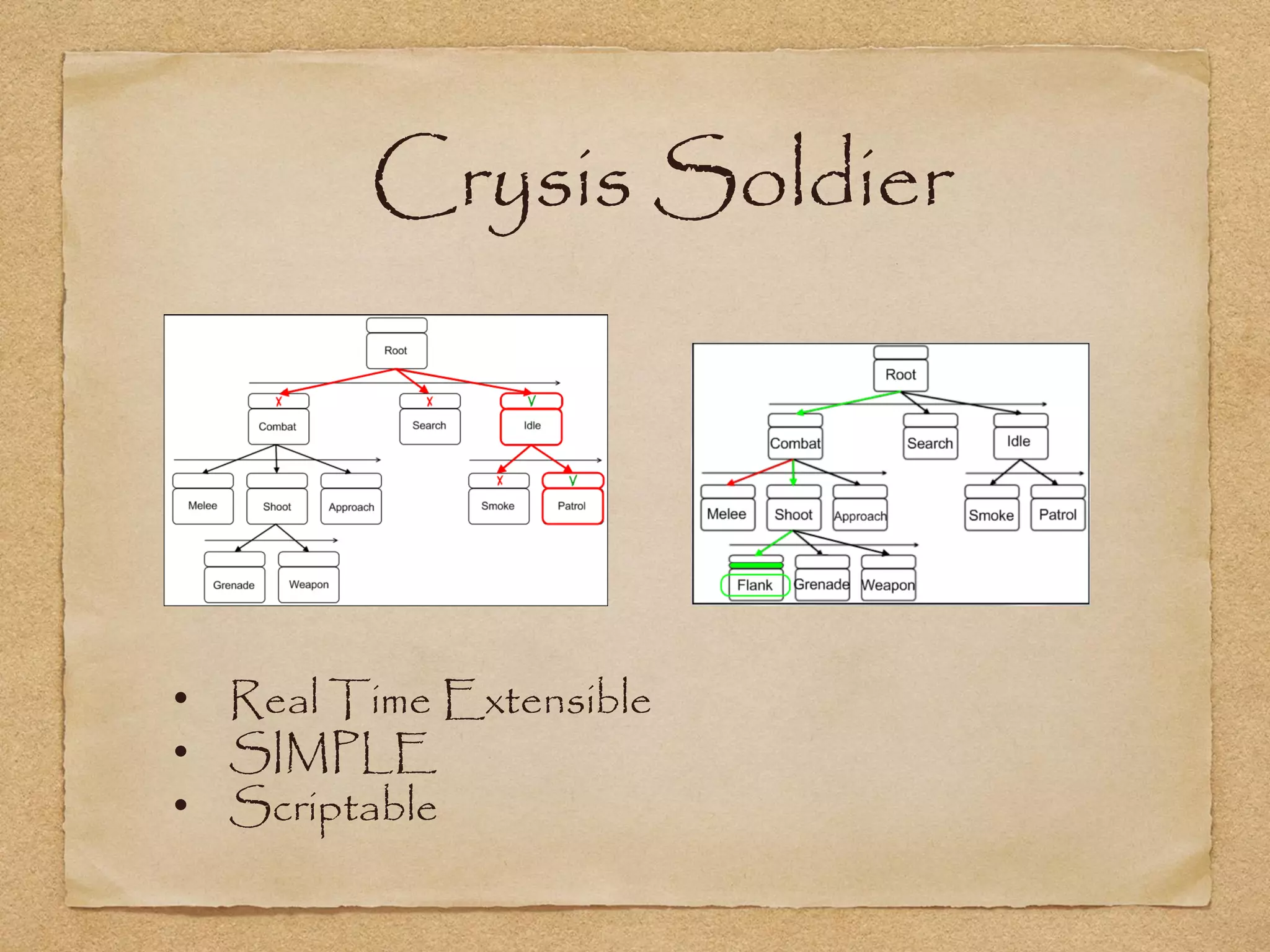
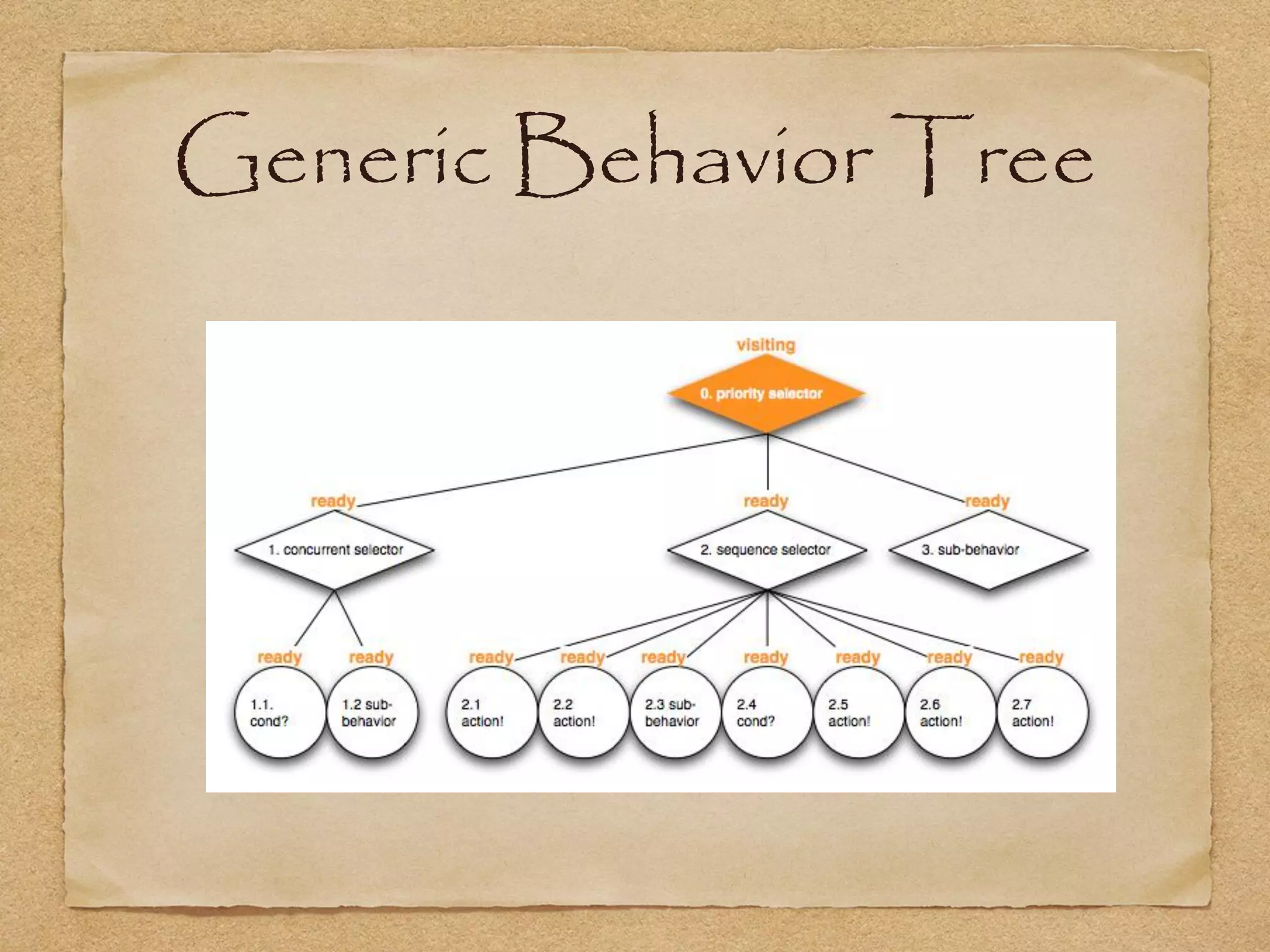
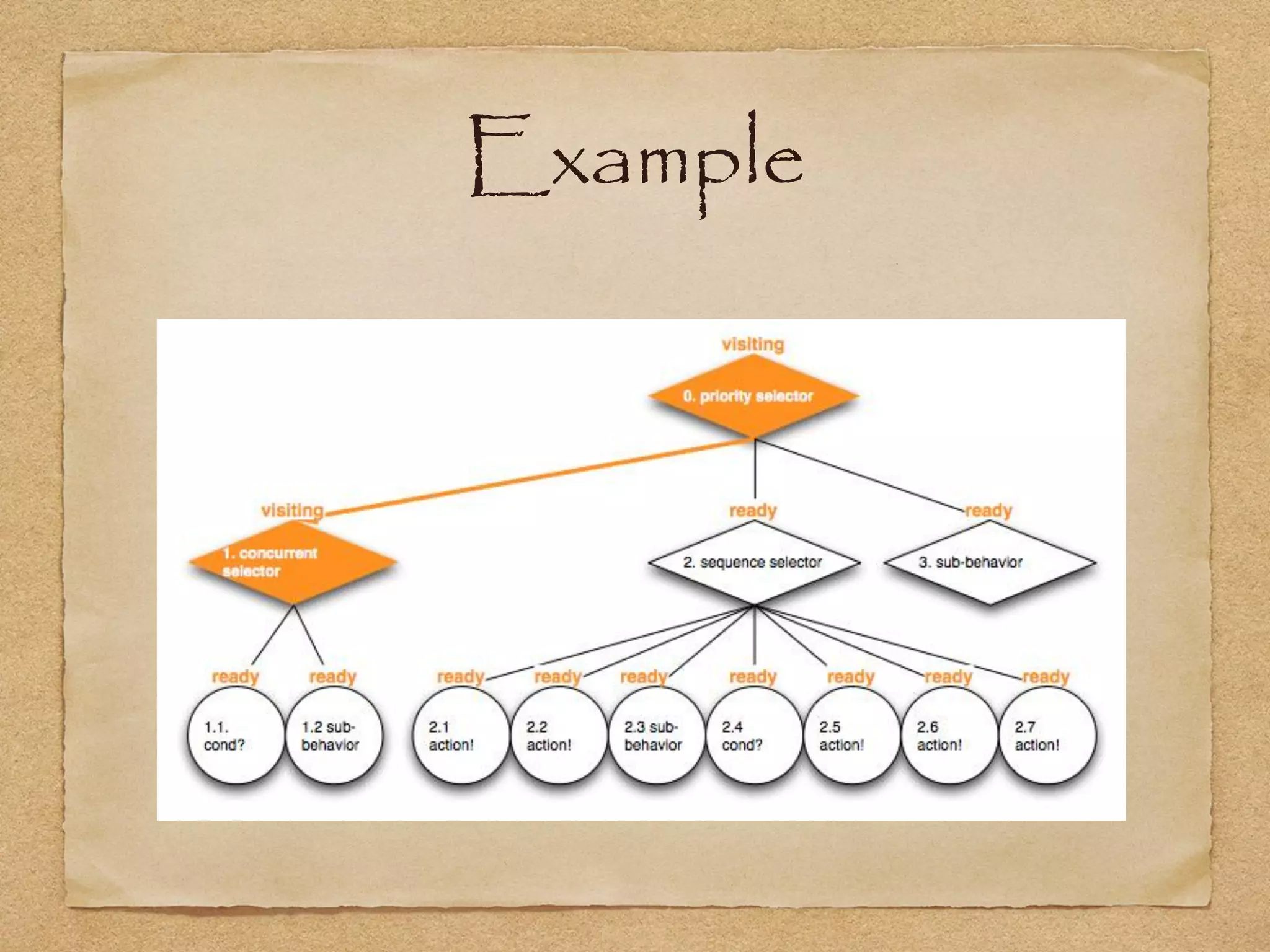
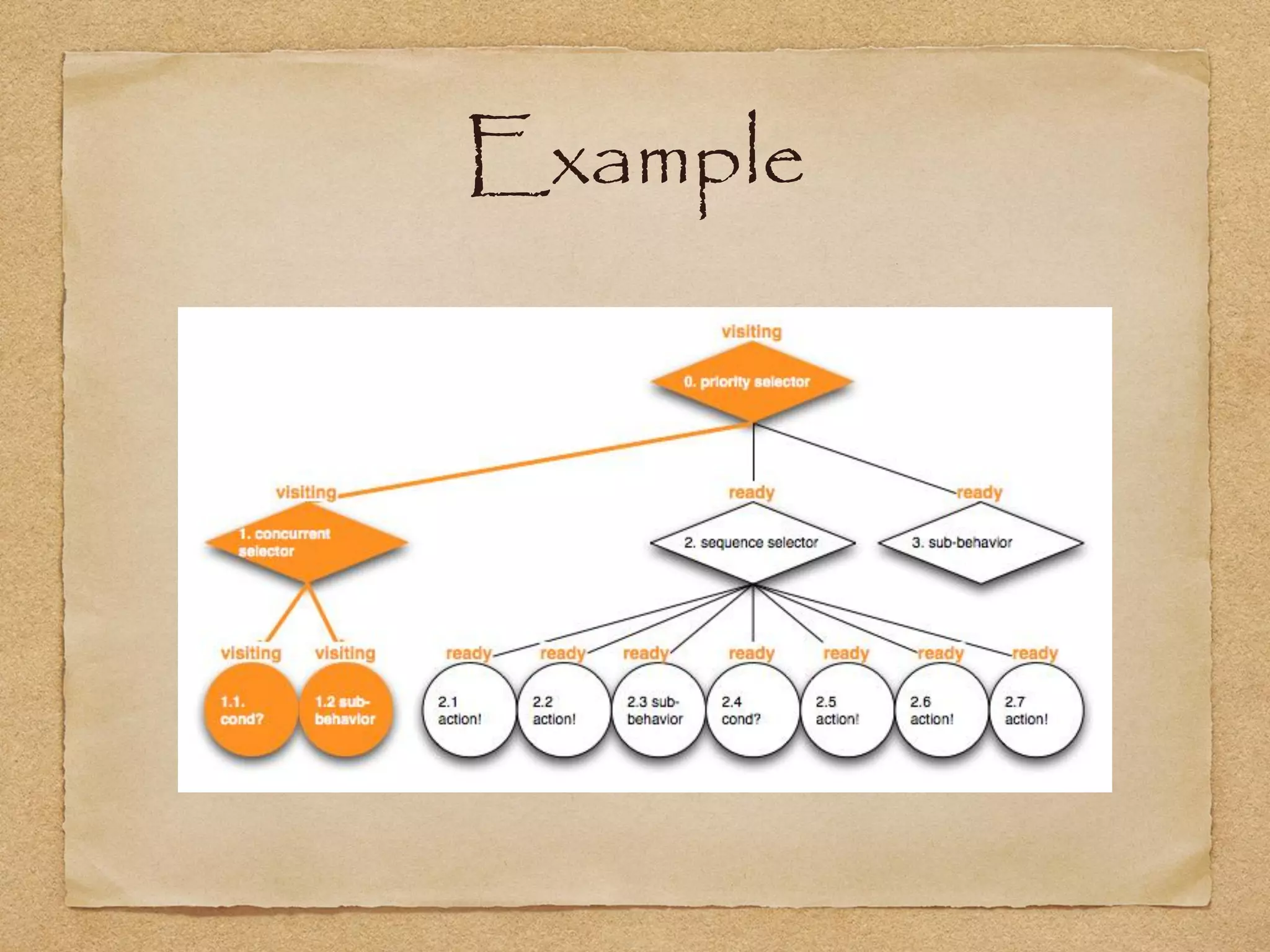
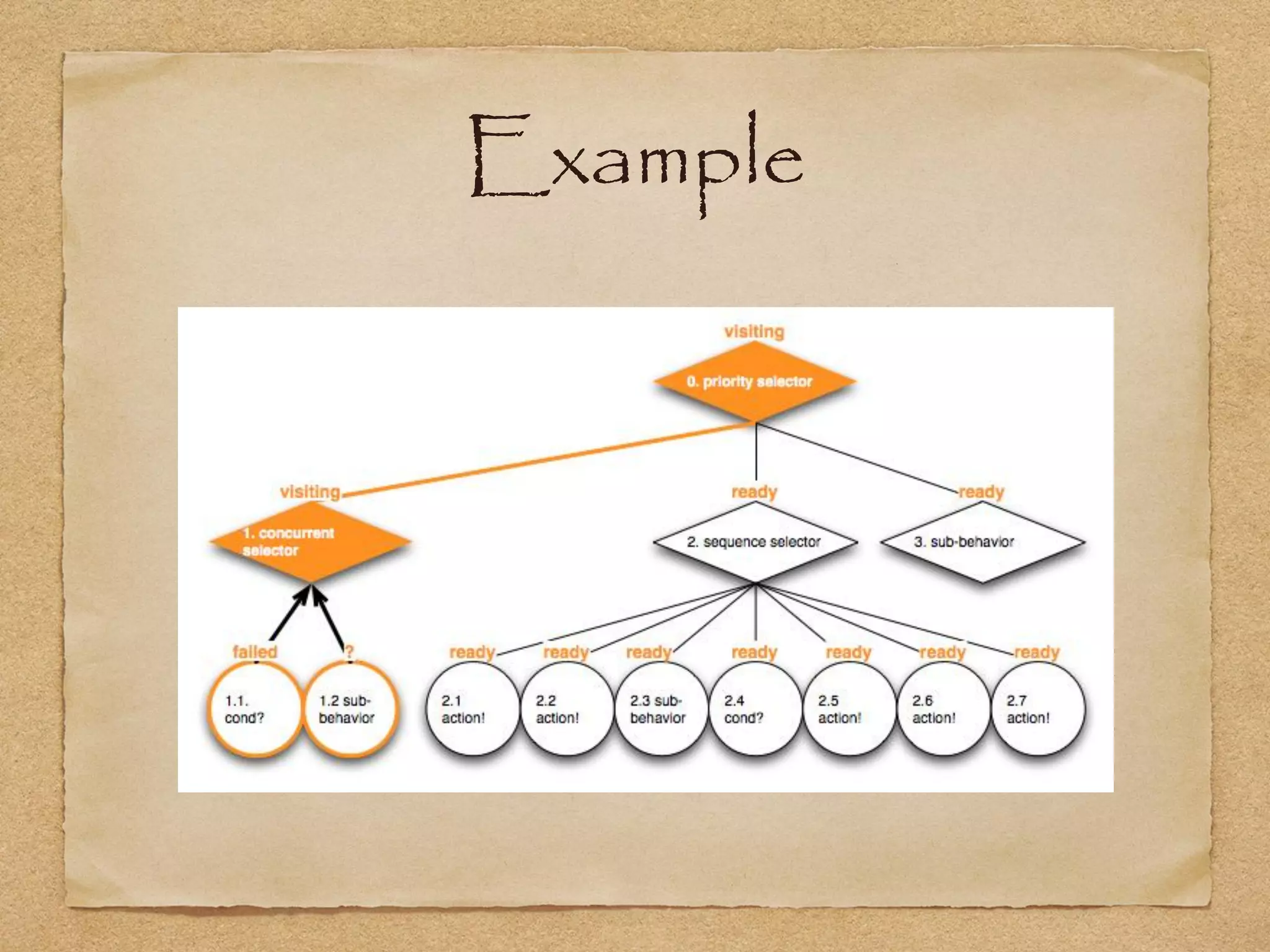
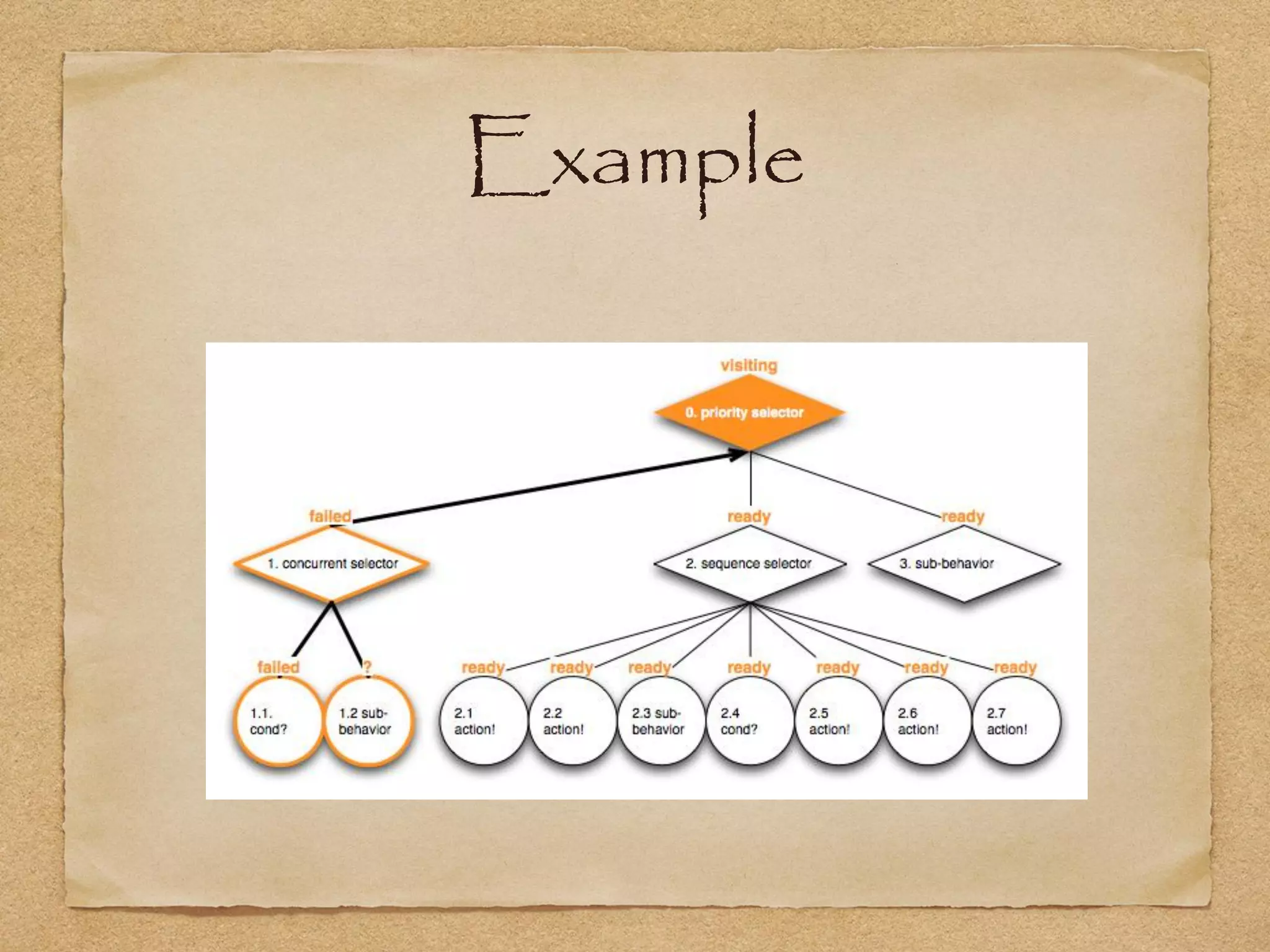
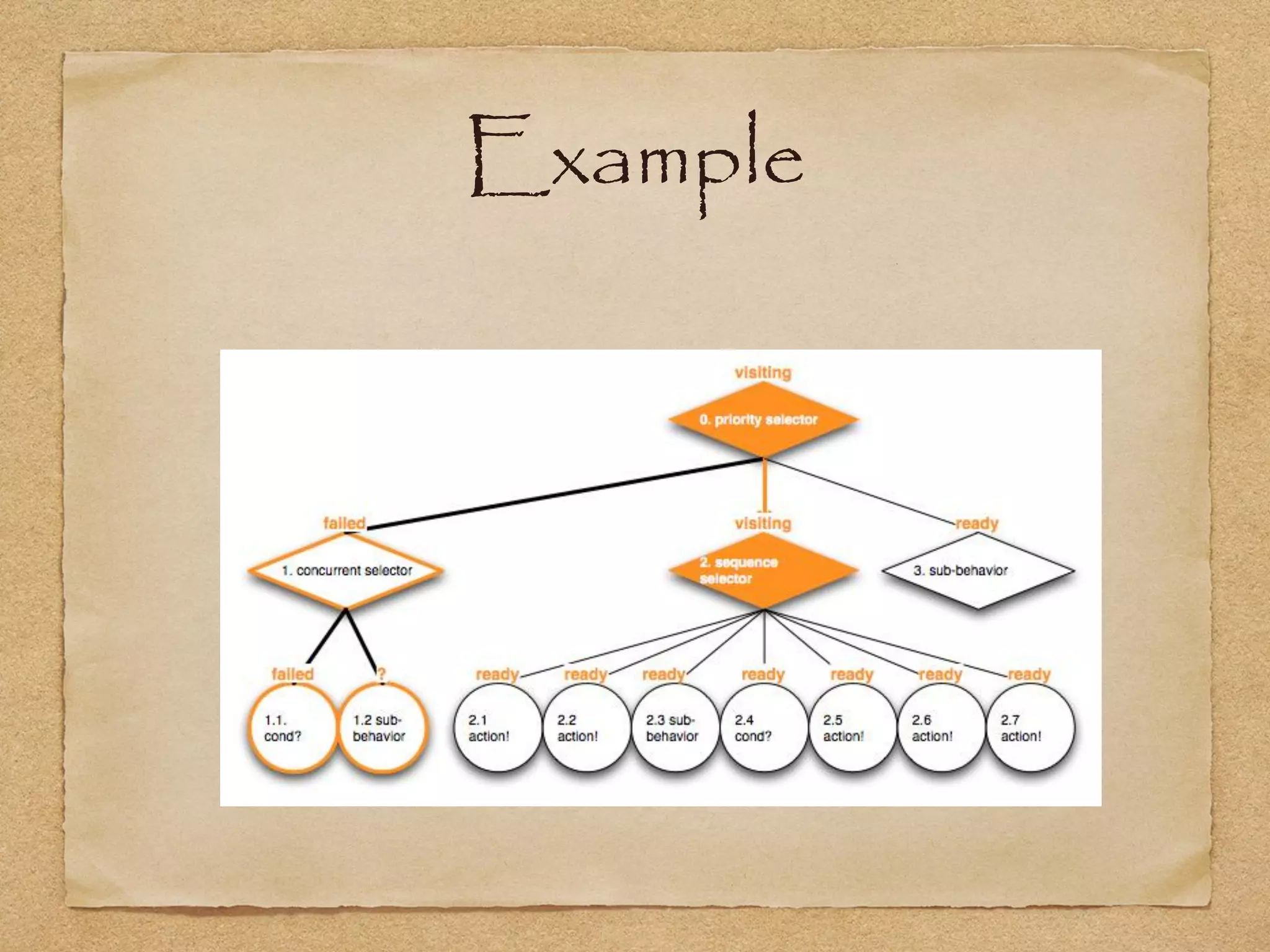
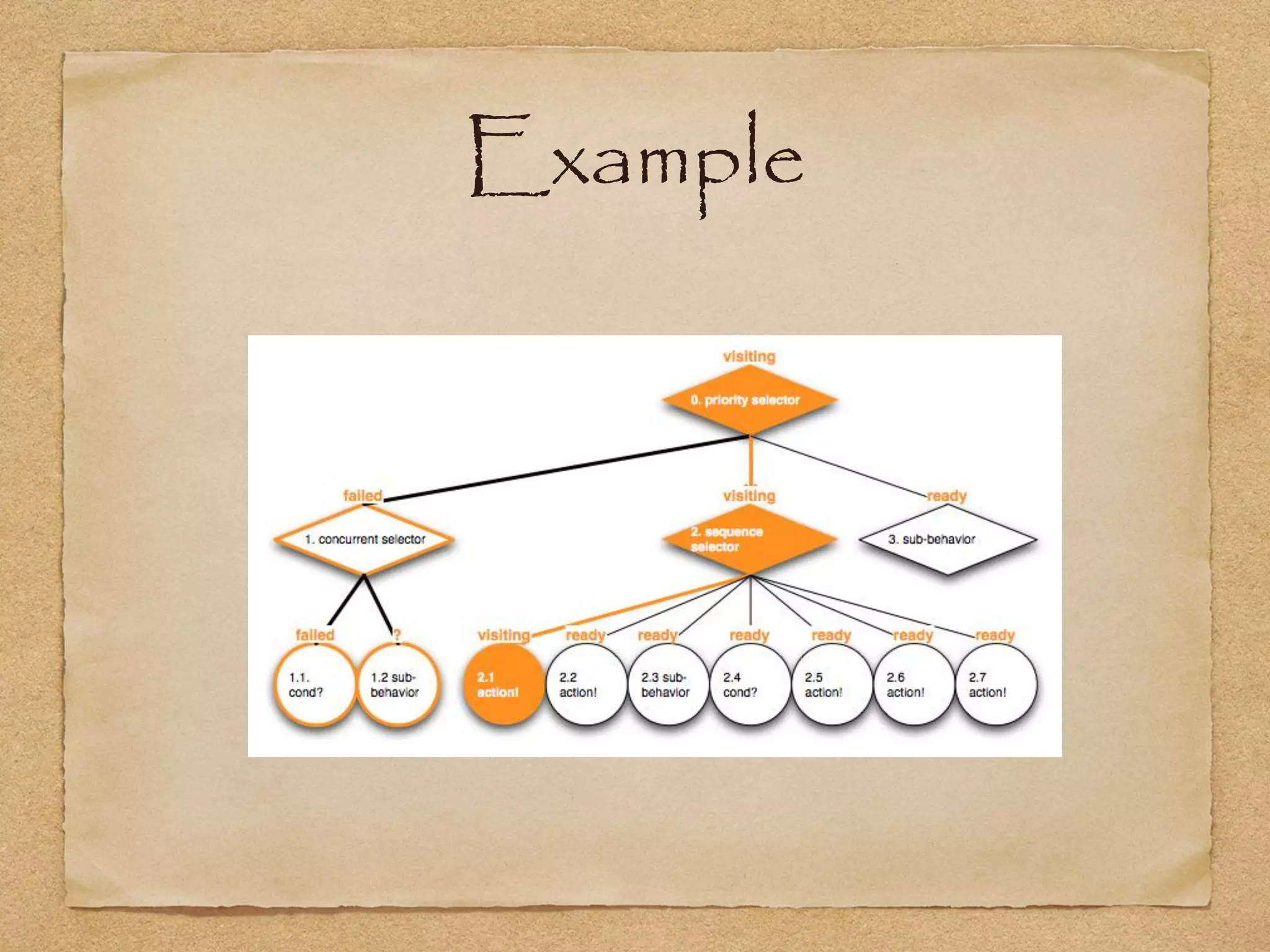
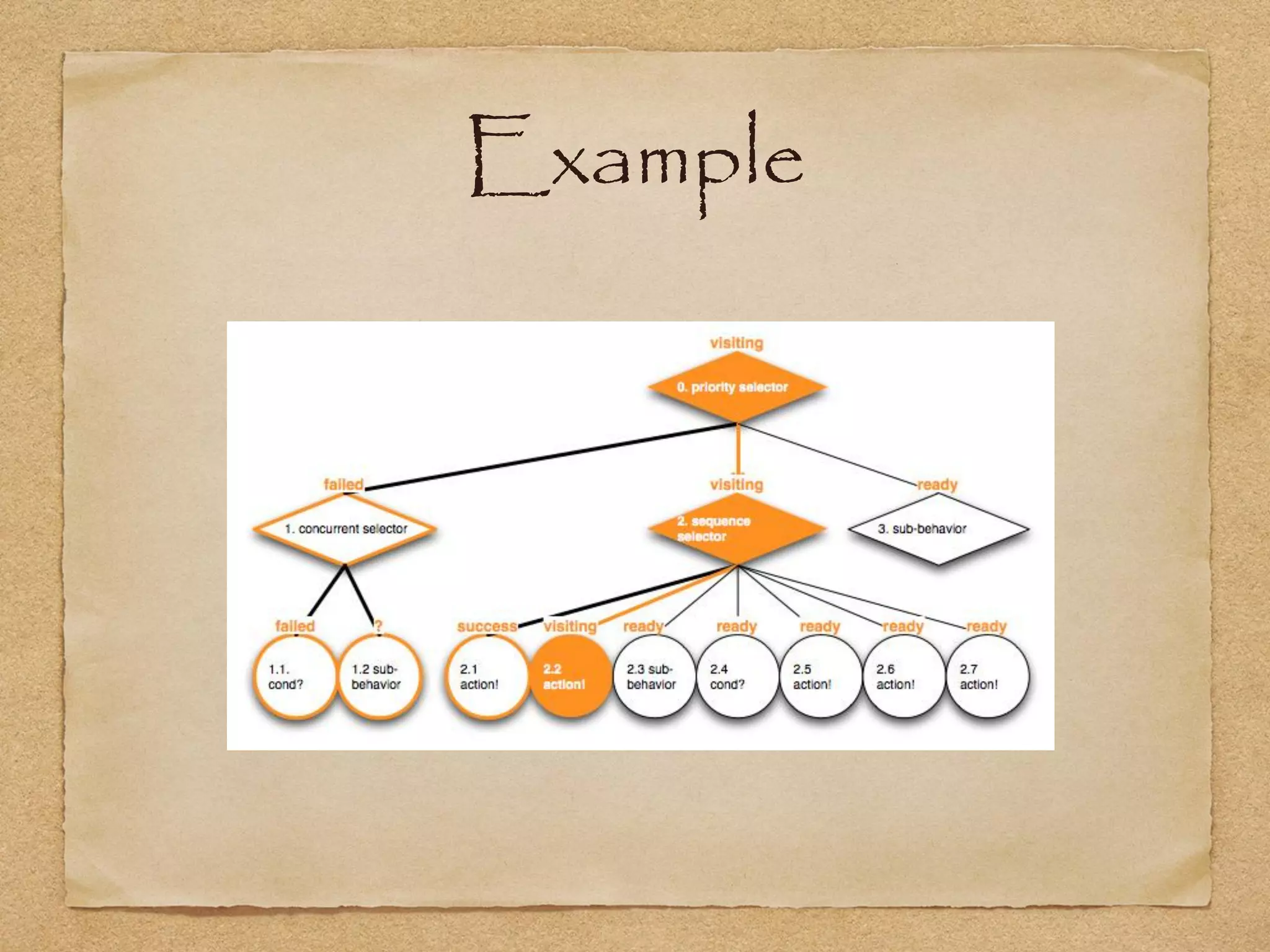
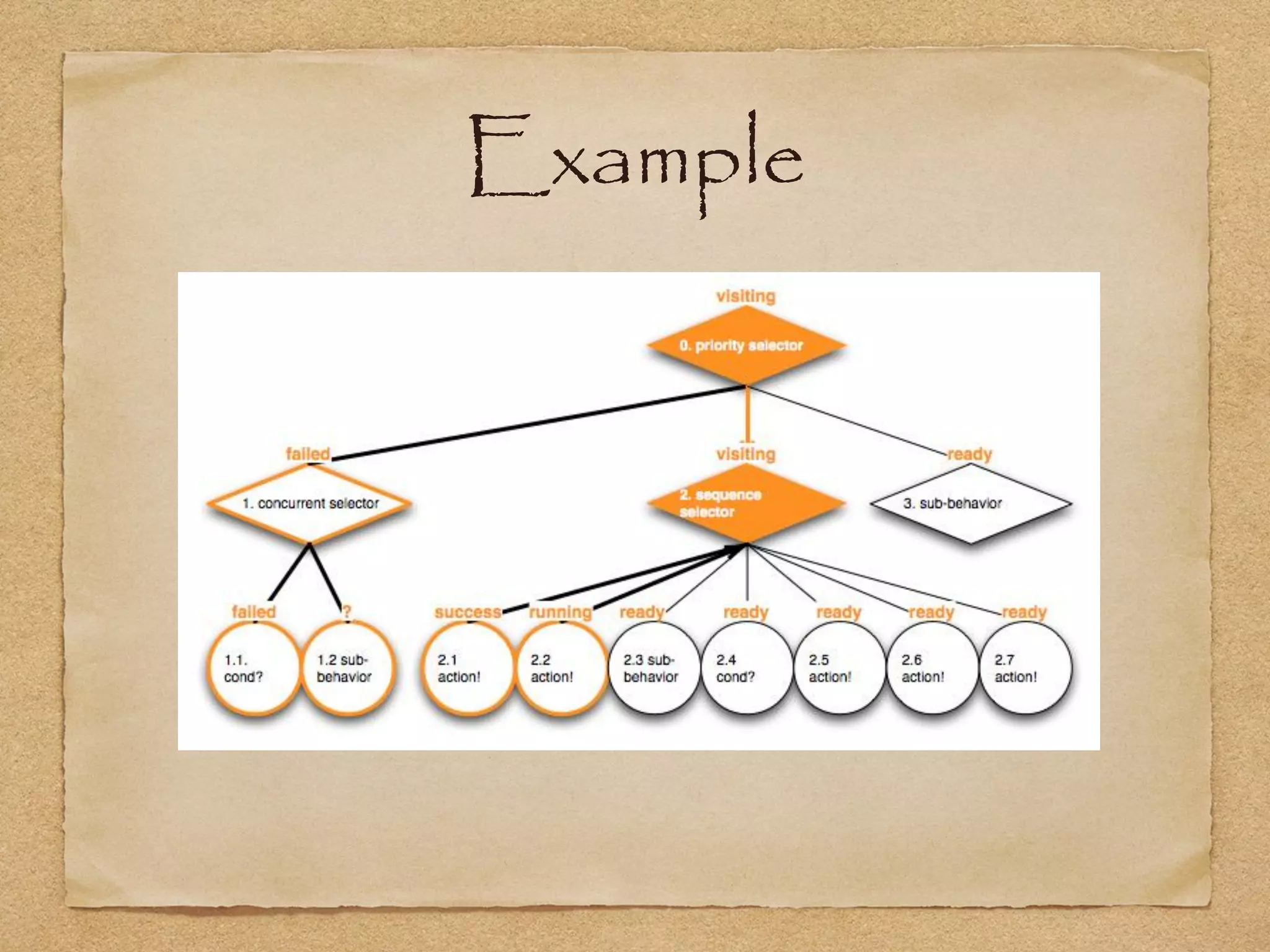
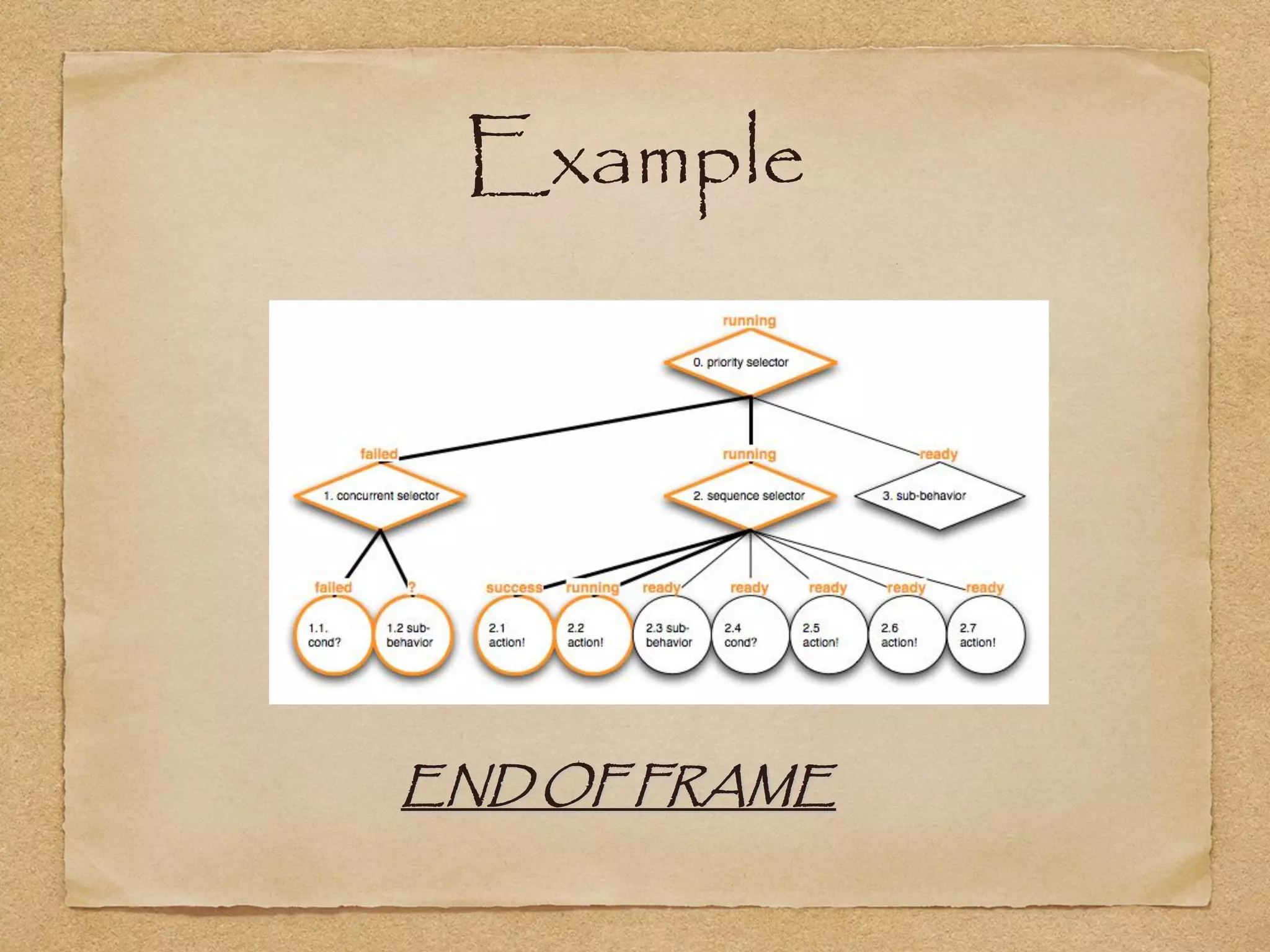


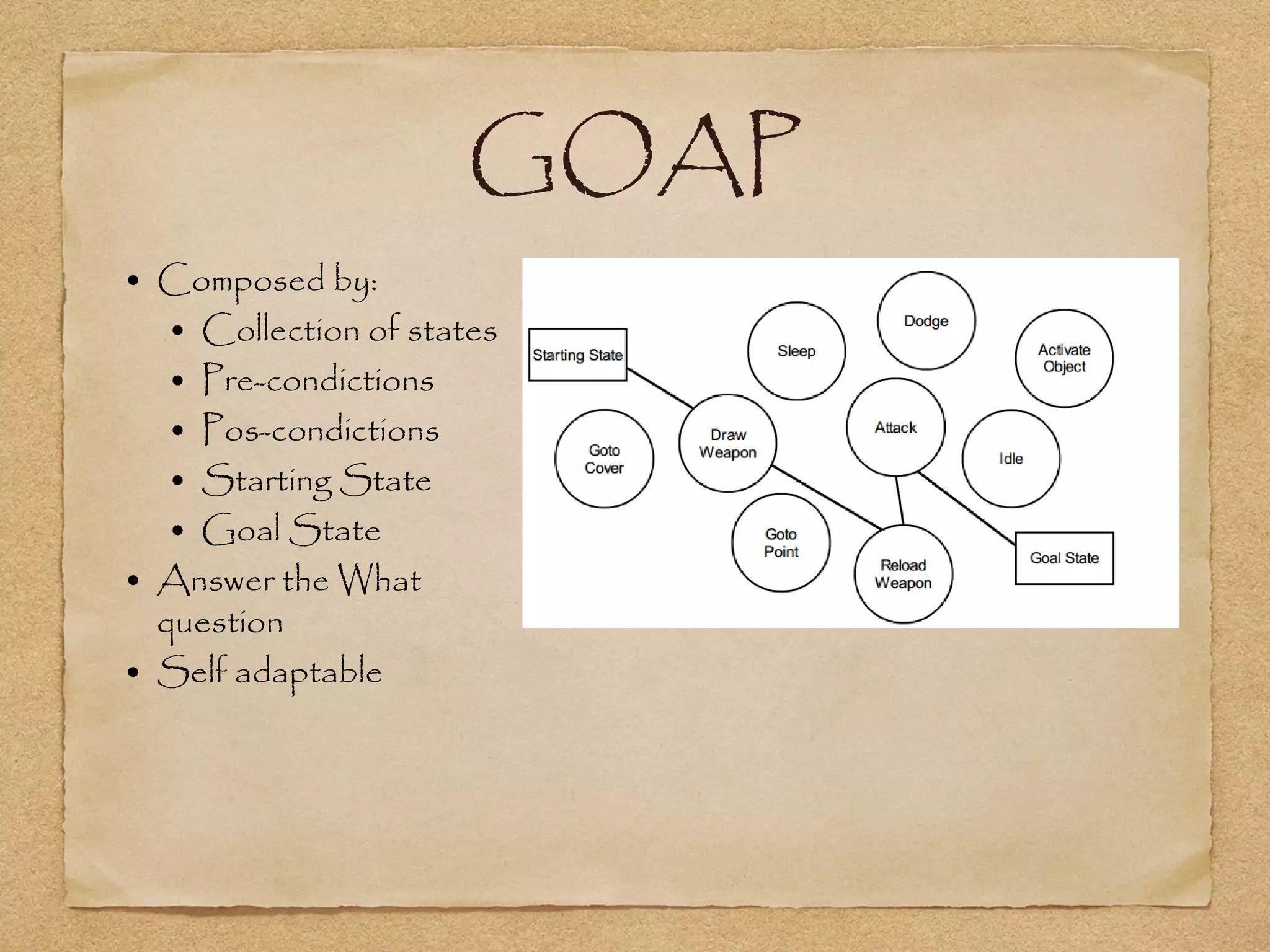

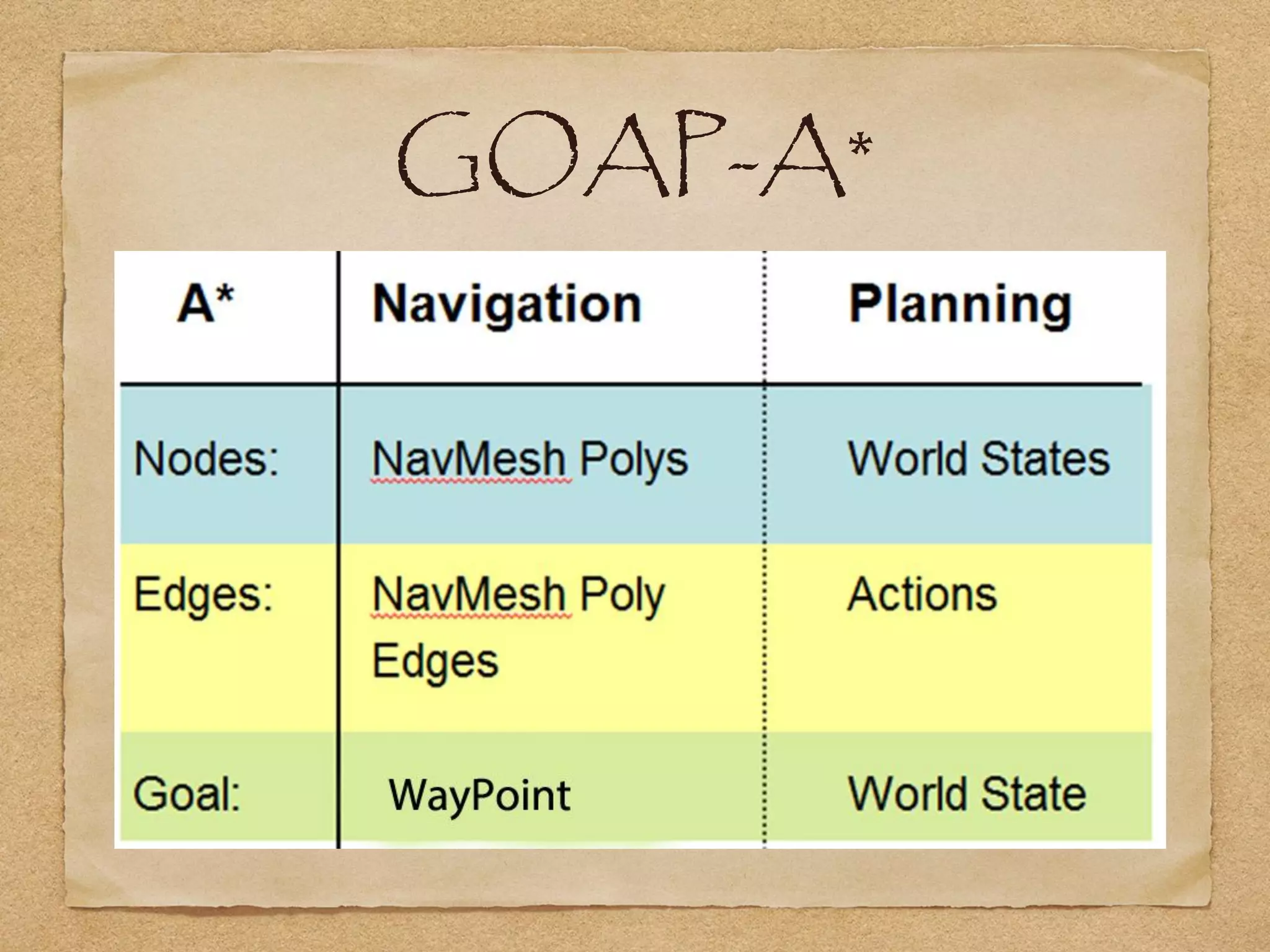

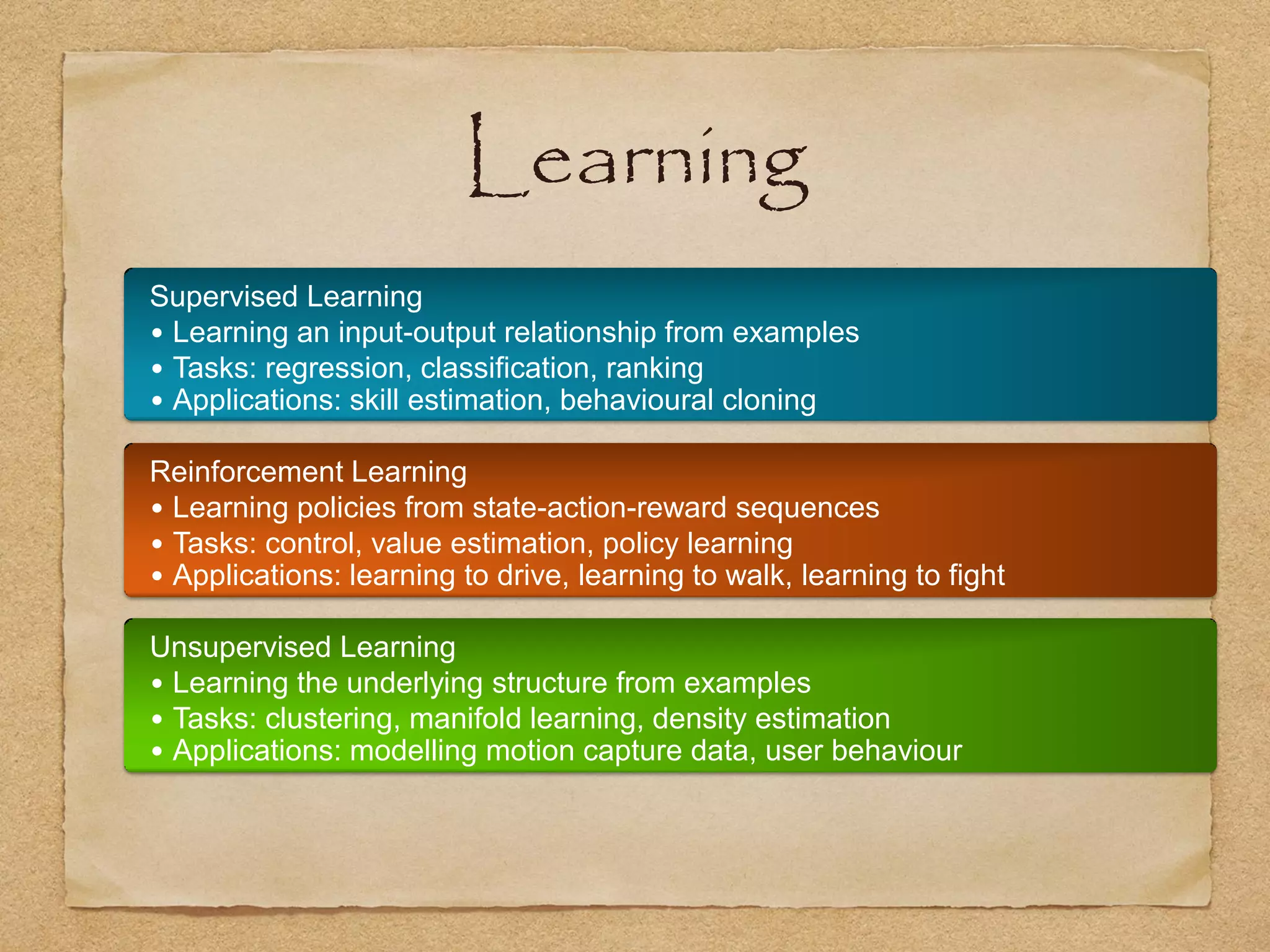
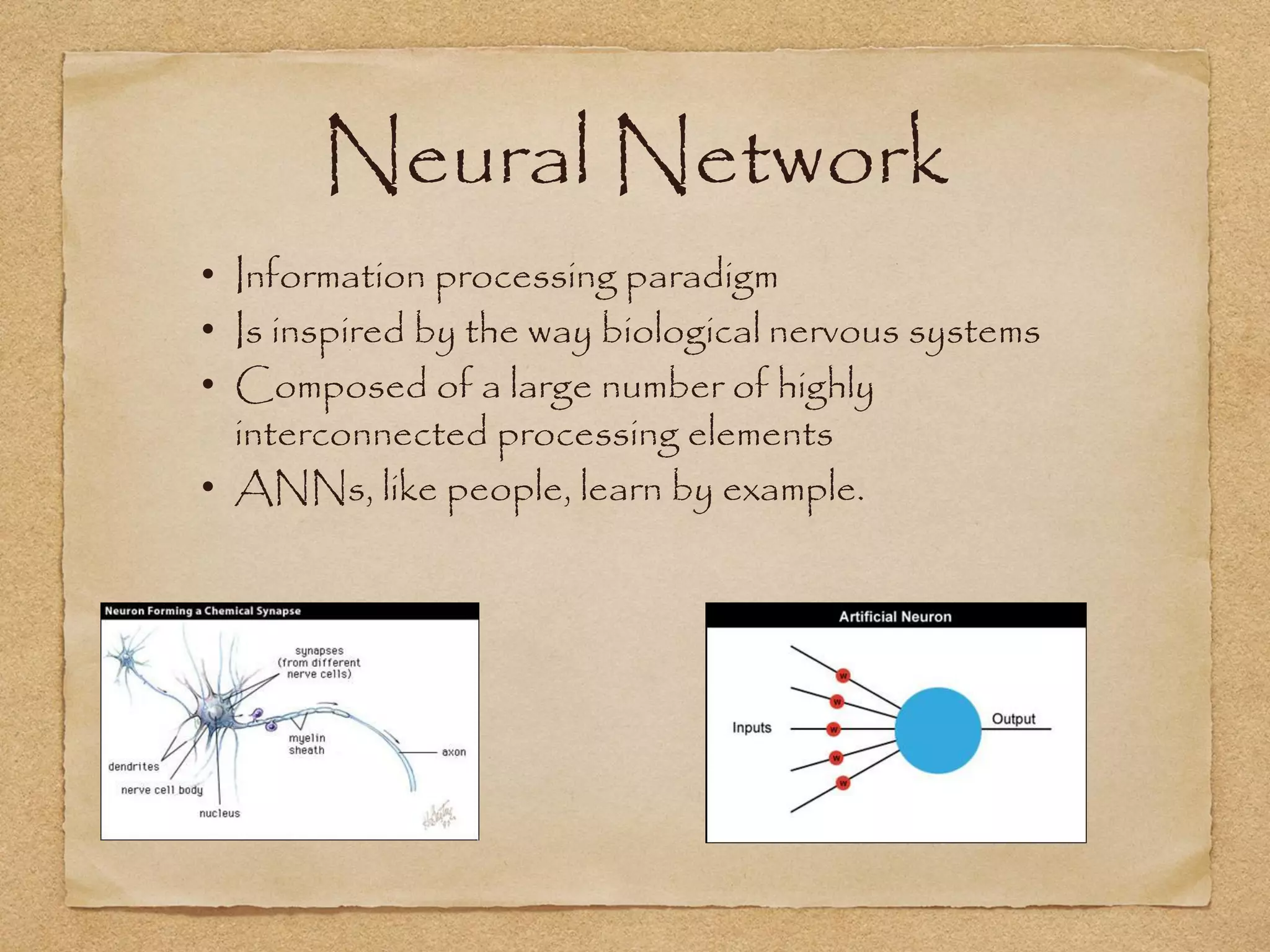
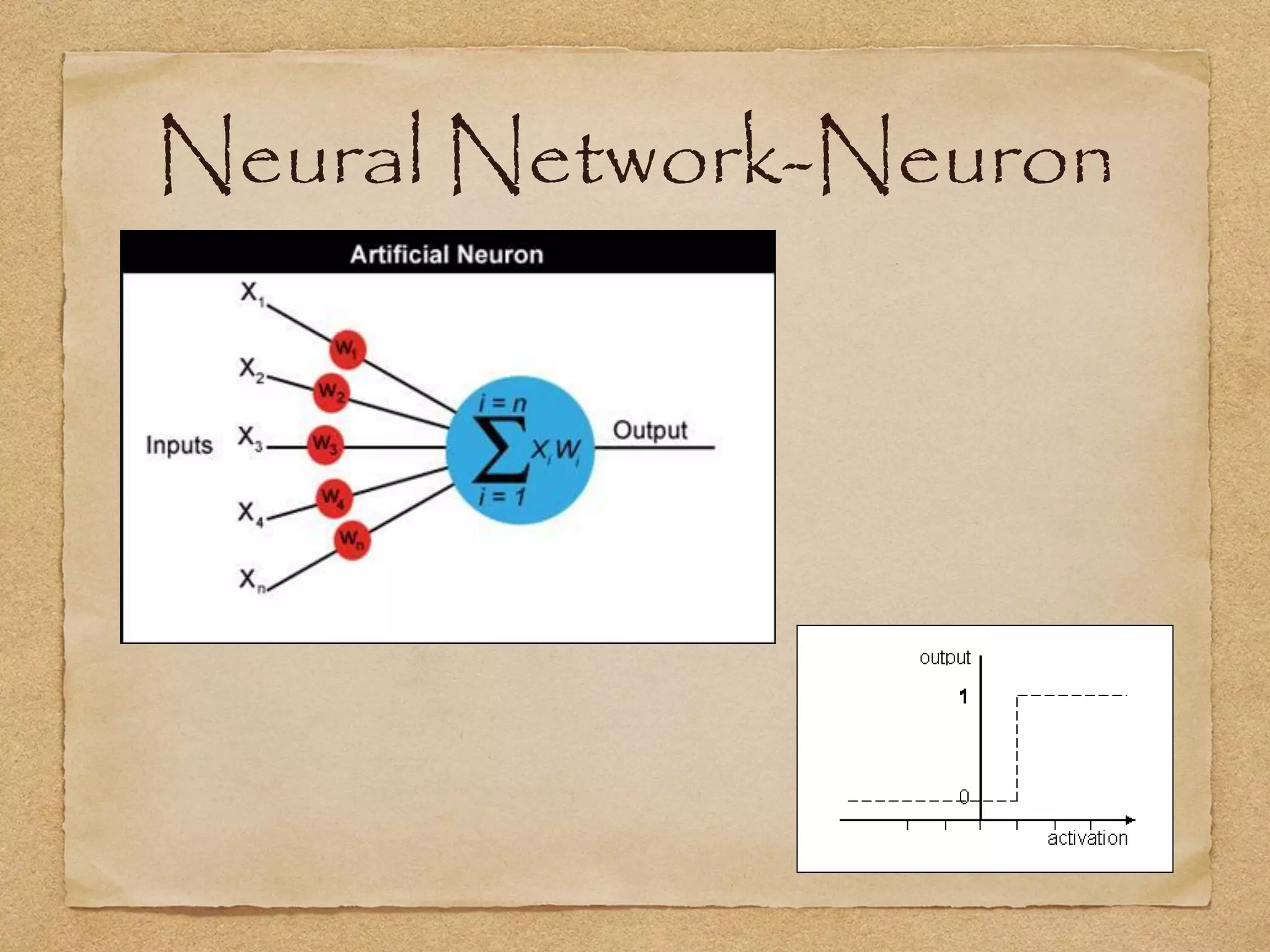
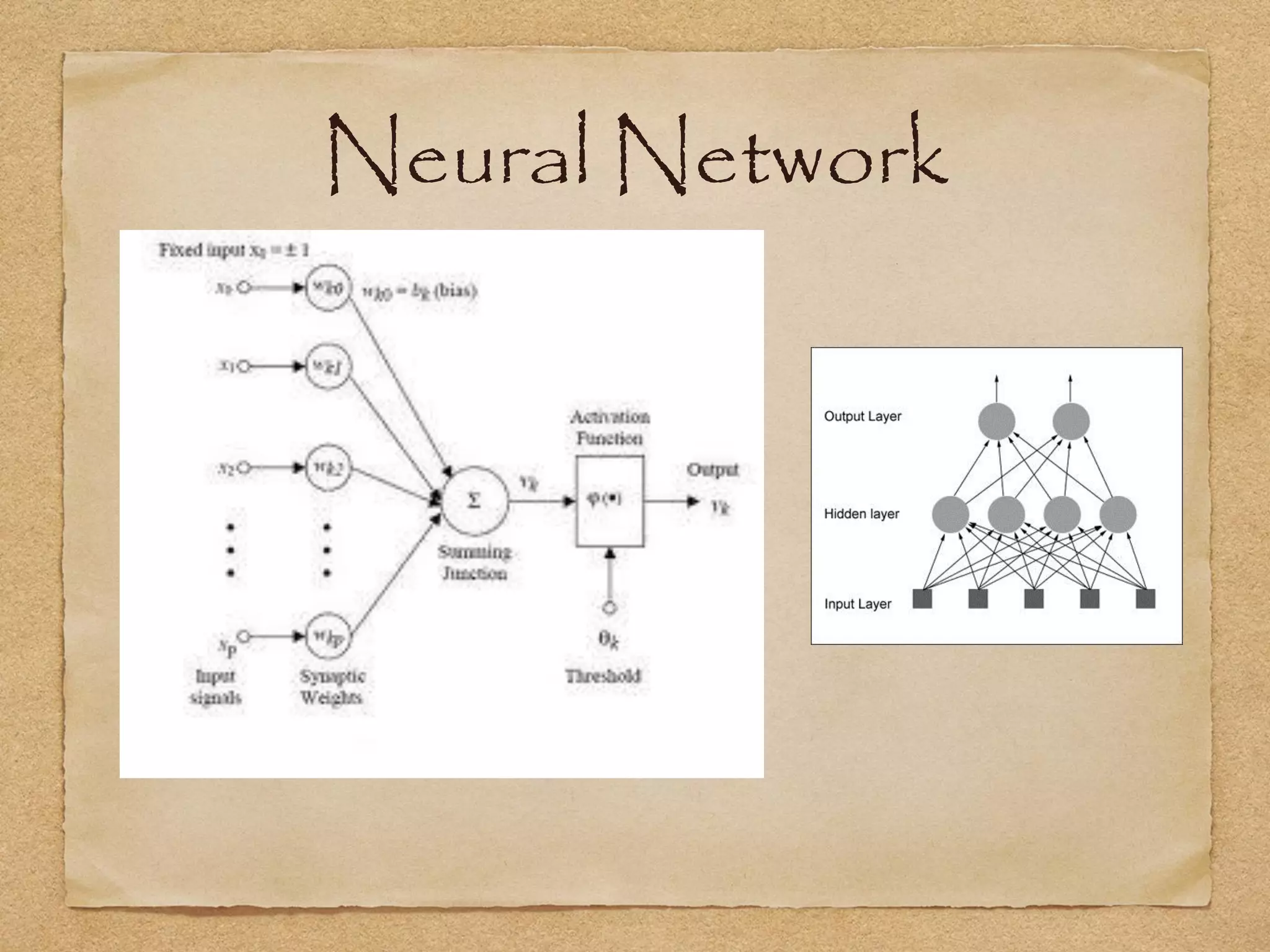


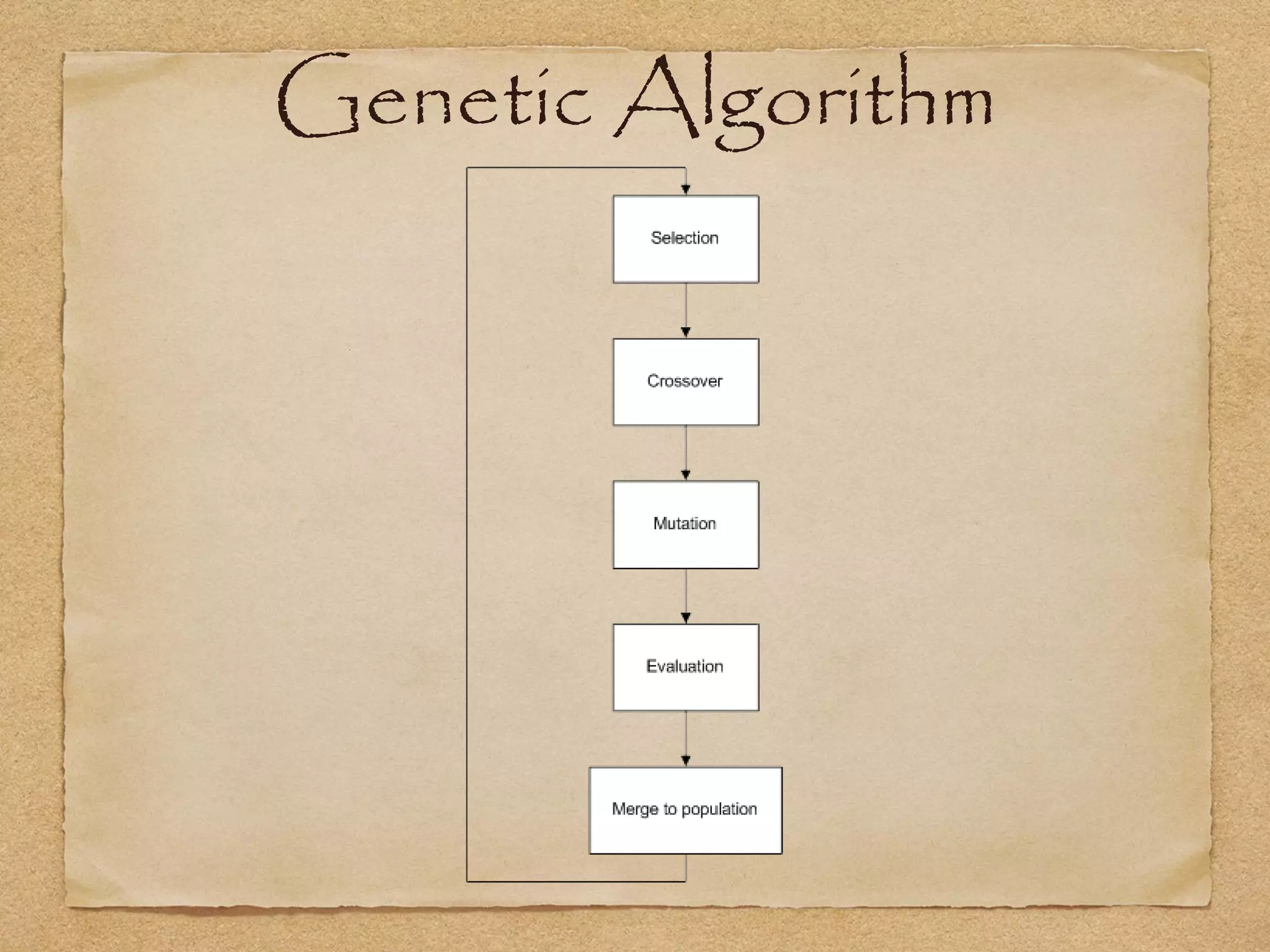



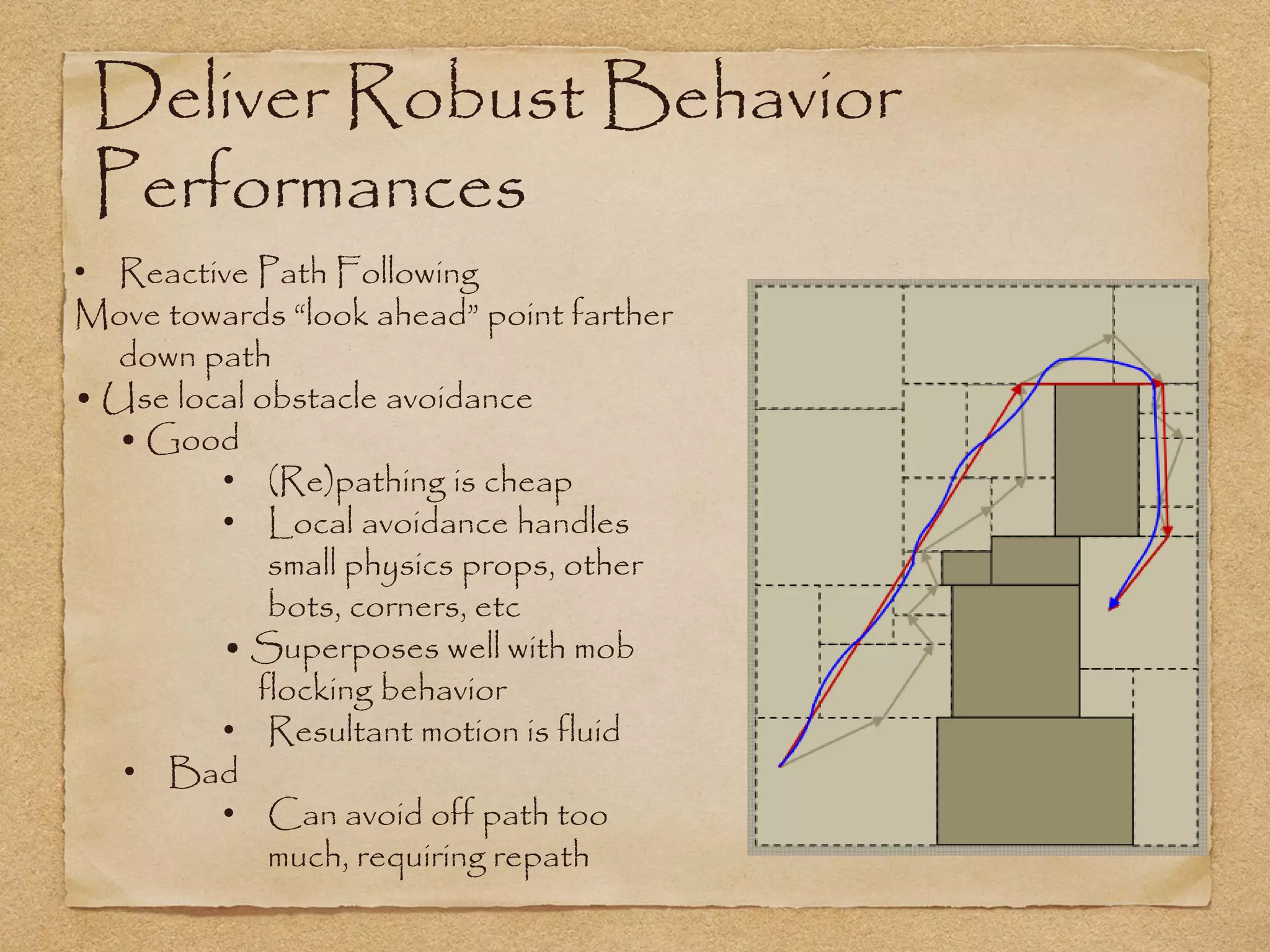
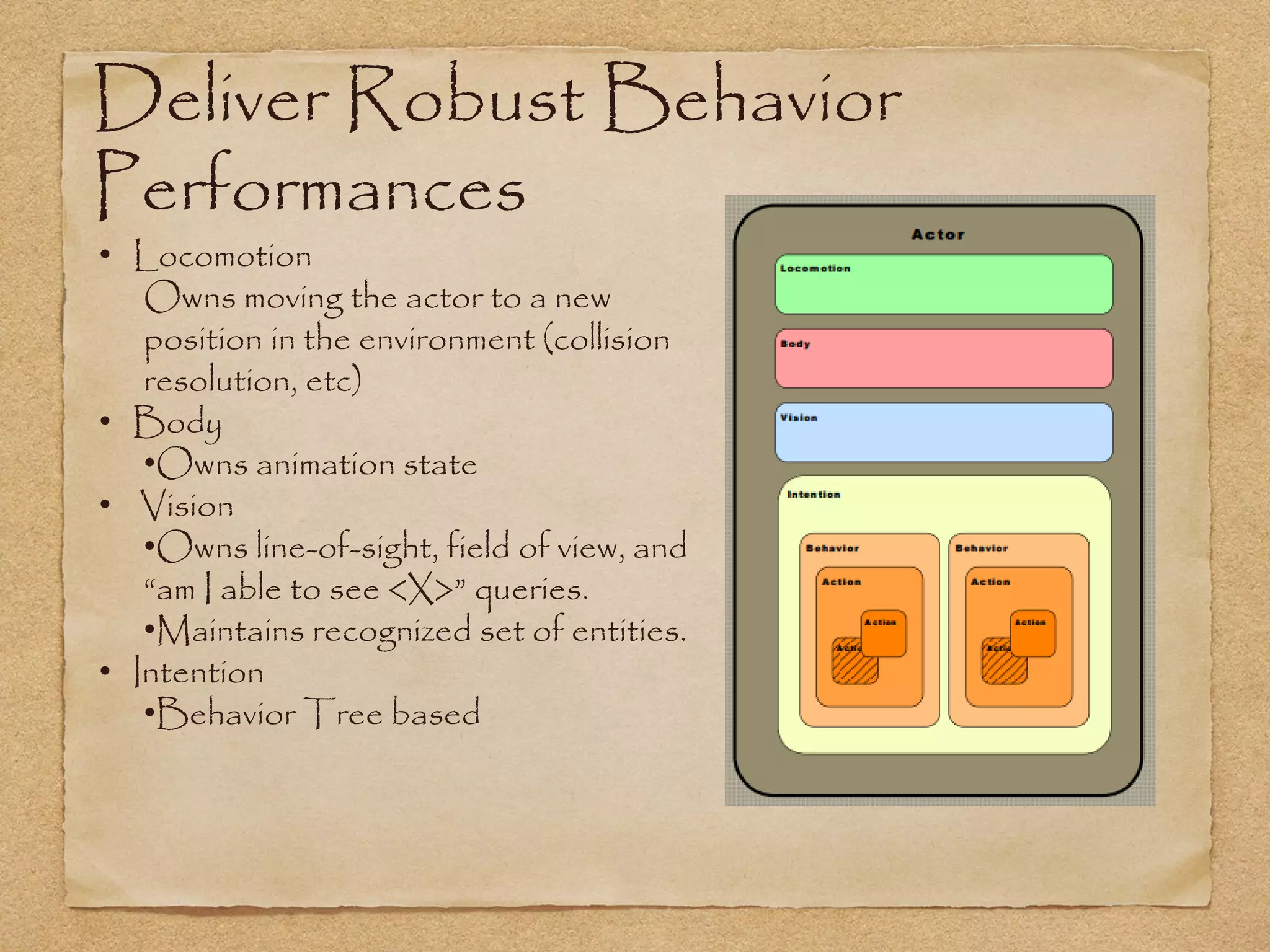


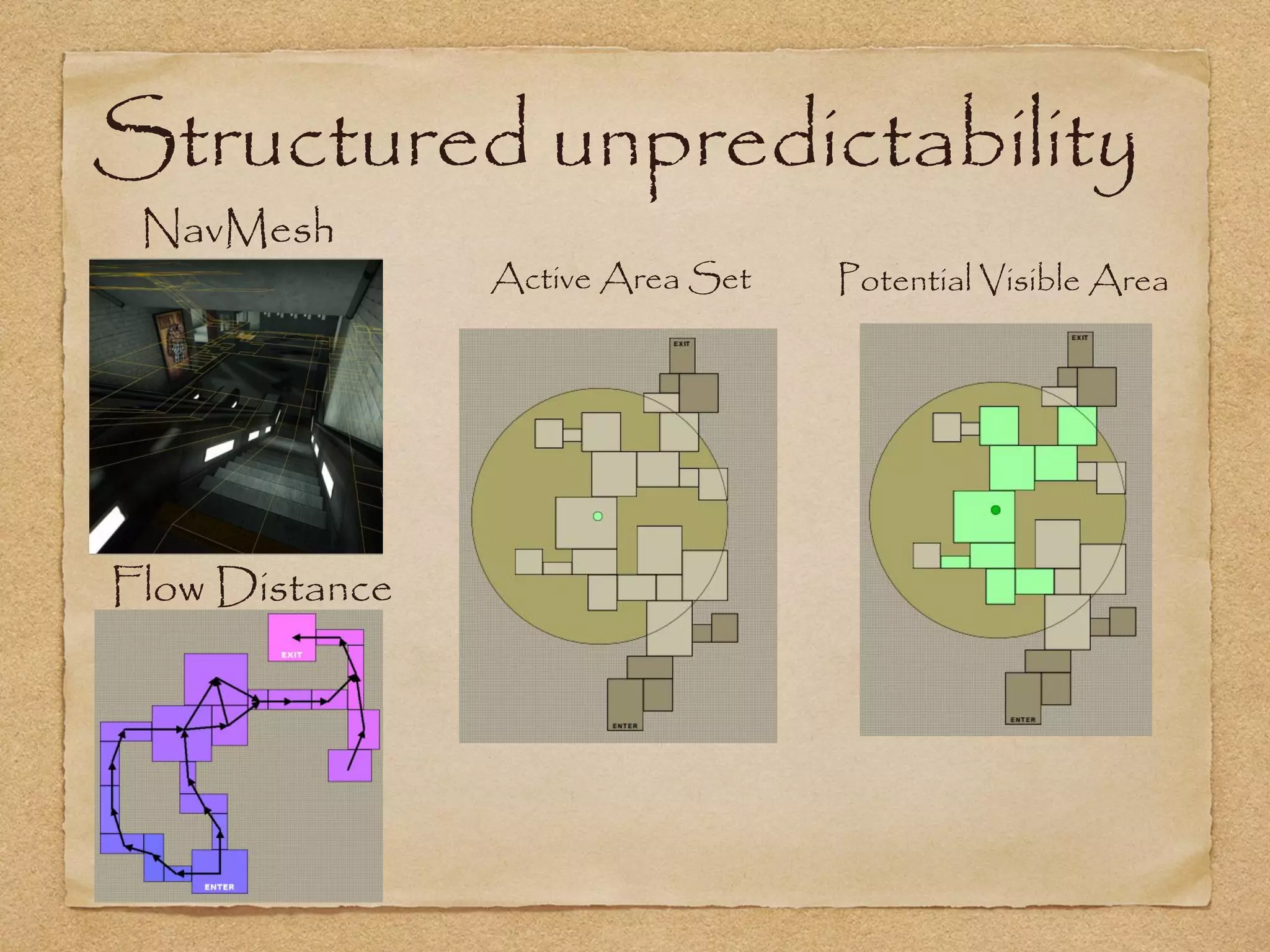

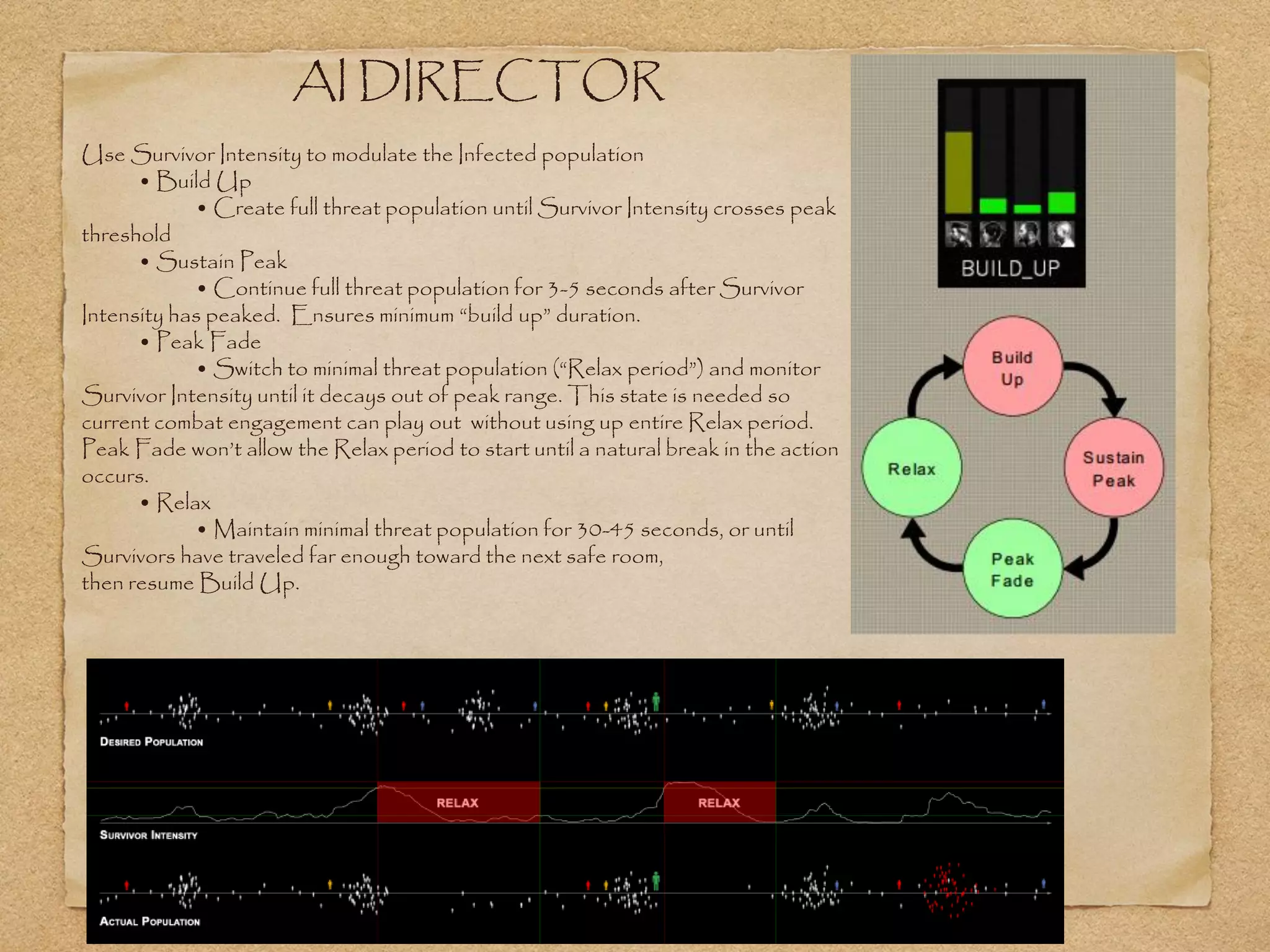




This document provides an overview of artificial intelligence concepts for games. It discusses navigation techniques like waypoints, navmeshes and pathfinding using A* and steering behaviors. It also covers perceptions, finite state machines, behavior trees, planning using GOAP and learning approaches like neural networks and genetic algorithms. Specific examples are given for how AI was implemented in the game Left 4 Dead to deliver robust behaviors, provide competent human proxies and generate dramatic pacing through an adaptive director algorithm.



























