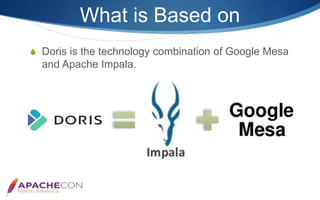
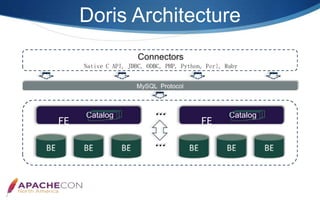
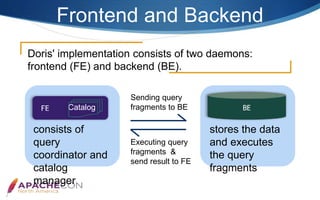
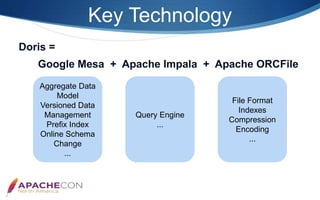
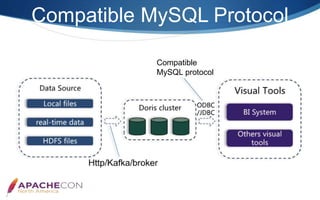
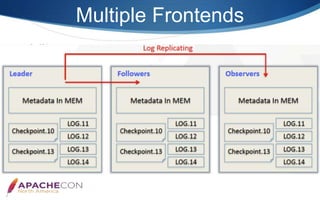
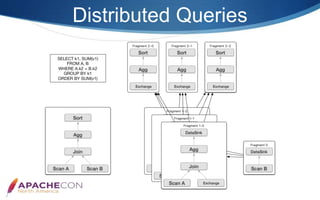
Apache Doris is an MPP-based interactive SQL data warehousing system designed for reporting and analysis, which integrates technologies from Google Mesa and Apache Impala. The system features high concurrency, a MySQL-compatible protocol, and supports advanced operations like online schema changes and materialized views. It is used in major applications like JD.com and is characterized by a simple architecture consisting of frontend and backend components.