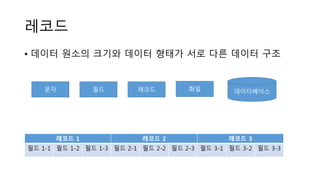
레코드
• 데이터 원소의크기와 데이터 형태가 서로 다른 데이터 구조
레코드 1 레코드 2 레코드 3
필드 1-1 필드 1-2 필드 1-3 필드 2-1 필드 2-2 필드 2-3 필드 3-1 필드 3-2 필드 3-3
레코드필드문자 화일 데이터베이스
3.
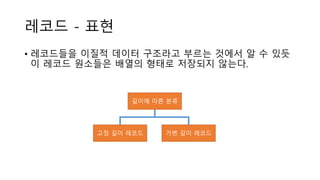
레코드 - 표현
•레코드들을 이질적 데이터 구조라고 부르는 것에서 알 수 있듯
이 레코드 원소들은 배열의 형태로 저장되지 않는다.
고정 길이 레코드 가변 길이 레코드
길이에 따른 분류
4.
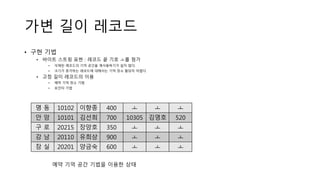
고정 길이 레코드
structDeposit {
char branch_name[20];
int account_number;
char customer_name[20];
float balance;
};
모든 자료형을 계산해보면
Deposit 레코드는 46byte를 사용한다.
5.
고정 길이 레코드
명동 10102 이향종 400
안 암 10101 김선희 700
안 암 10305 김영호 520
구 로 20215 장양호 350
강 남 20110 유희상 900
잠 실 20201 양금숙 600
20byte 20byte 20byte 20byte
customer_
name
branch_
name
account_
number
balance
위치
0
1
2
3
4
5
중간의 레코드가 삭제되면 삭제된 기억 공간을 이용하기 위한 문제 발생
명 동 10102 이향종 400
삭제된 레코드
안 암 10305 김영호 520
구 로 20215 장양호 350
강 남 20110 유희상 900
잠 실 20201 양금숙 600
20byte 20byte 20byte 20byte
customer_
name
branch_
name
account_
number
balance
위치
0
1
2
3
4
5
6.
고정 길이 레코드
2
명동 10102 이향종 400
5
안 암 10305 김영호 520
구 로 20215 장양호 350
잠 실 20201 양금숙 600
포인터
0
1
2
3
4
5
6
헤더
삭제된 기억 공간의 포인터를 저장하는 레코드를 추가
7.
고정 길이 레코드
-고정 길이 레코드에 대한 삽입과 삭제는 삭제된 레코드의 기억 장소가
레코드의 삽입에 필요한 기억 장소와 일치하므로 구현하기가 간단하다.
- 그러나 파일 내에 가변 길이의 레코드를 허용하면 이 방법은 부적합
- 삽입될 레코드는 삭제된 레코드가 차지하던 기억 장소의 양이 부족하거나
남게 되는 경우가 있기 때문
8.
가변 길이 레코드
•한 파일 내에 여러 유형의 레코드 저장
• 한 파일 내에 가변 필드를 허용하는 레코드 저장
• 반복적 필드를 허용하는 레코드 저장
struct deposit_list {
char branch_name[20];
struct{
int account_number;
char customer_name[20];
float balance;
} *account_info;
};
레코드의 크기를 제한하지 않기 위해서 사용
9.
가변 길이 레코드
•구현 기법
• 바이트 스트링 표현 : 레코드 끝 기호 ㅗ를 첨가
• 삭제된 레코드의 기억 공간을 재사용하기가 쉽지 않다.
• 크기가 증가하는 레코드에 대해서는 기억 장소 할당이 어렵다.
• 고정 길이 레코드의 이용
• 예약 기억 장소 기법
• 포인터 기법
명 동 10102 이향종 400 ㅗ
안 암 10101 김선희 700 10305
구 로 20215 장양호 305 ㅗ
강 남 20110 유희상 900 ㅗ
잠 실 20201 양금숙 600 ㅗ
김영호 520 ㅗ
바이트 스트링 표현
10.
가변 길이 레코드
•구현 기법
• 바이트 스트링 표현 : 레코드 끝 기호 ㅗ를 첨가
• 삭제된 레코드의 기억 공간을 재사용하기가 쉽지 않다.
• 크기가 증가하는 레코드에 대해서는 기억 장소 할당이 어렵다.
• 고정 길이 레코드의 이용
• 예약 기억 장소 기법
• 포인터 기법
예약 기억 공간 기법을 이용한 상태
명 동 10102 이향종 400 ㅗ ㅗ ㅗ
안 암 10101 김선희 700 10305 김영호 520
구 로 20215 장양호 350 ㅗ ㅗ ㅗ
강 남 20110 유희상 900 ㅗ ㅗ ㅗ
잠 실 20201 양금숙 600 ㅗ ㅗ ㅗ
11.
가변 길이 레코드
•구현 기법
• 바이트 스트링 표현 : 레코드 끝 기호 ㅗ를 첨가
• 삭제된 레코드의 기억 공간을 재사용하기가 쉽지 않다.
• 크기가 증가하는 레코드에 대해서는 기억 장소 할당이 어렵다.
• 고정 길이 레코드의 이용
• 예약 기억 장소 기법
• 포인터 기법
포인터 기법을 이용한 상태
명 동 10102 이향종 400
2 안 암 10101 김선희 700
안 암 10305 김영호 520
구 로 10215 장양호 350
강 남 20110 유희상 900
잠 실 20201 양금숙 600
같은 지점에 대한 레코드를 연결하는데 포인터 사용
레코드 - C언어
struct jusorok {
int number;
char name[20];
char addr[100];
char tel[13];
};
struct jusorok person[100];
- 배열
struct jusorok {
int number;
char name[20];
char addr[100];
char tel[13];
} person[100];
…
number name addr tel
person[0] person[100]
14.
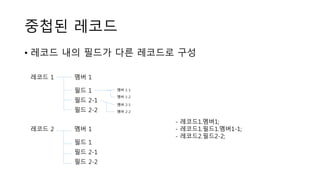
중첩된 레코드
• 레코드내의 필드가 다른 레코드로 구성
레코드 1
레코드 2
멤버 1
필드 1
필드 2-1
필드 2-2
멤버 1
필드 1
필드 2-1
필드 2-2
멤버 1-1
멤버 1-2
멤버 2-1
멤버 2-2
- 레코드1.멤버1;
- 레코드1.필드1.멤버1-1;
- 레코드2.필드2-2;
15.
리스트
• 선형 리스트(linearlist)
• 각 데이터가 배열과 같이 연속되는 기억 장소에 순차적으로 저장되는 리스트
월 요 일
화 요 일
수 요 일
목 요 일
금 요 일
토 요 일
0
1
3
4
5
6
16.
선형 리스트
• 저장,탐색, 삭제, 삽입, 변경 등을 수행 가능
• 일반적인 표현 방법 : 배열
• 각각의 항목들에 대해 index를 사용하여 접근 (포인터 x)
• 리스트 구조에서 요구되는 연산
• 리스트의 길이를 구하는 연산
• 리스트를 왼쪽에서 오른쪽 또는 그 반대로 읽는 연산
• i번째 항목에 새로운 값을 기억시키는 연산
• i번째 위치에 새로운 항목 a를 삽입시키는 연산
• i번째 위치에 항목 a를 삭제시키는 연산
전체 리스트의 순서를
유지하는 작업요구
17.
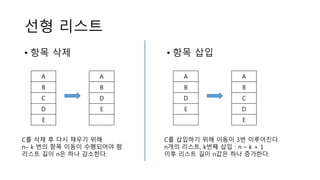
선형 리스트
• 항목삭제
A
B
C
D
E
A
B
D
E
C를 삭제 후 다시 채우기 위해
n– k 번의 항목 이동이 수행되어야 함
리스트 길이 n은 하나 감소한다.
• 항목 삽입
A
B
D
E
A
B
C
D
E
C를 삽입하기 위해 이동이 3번 이루어진다.
n개의 리스트, k번째 삽입 : n – k + 1
이후 리스트 길이 n값은 하나 증가한다.
18.
선형 리스트
• 선형리스트의장점은 가장 간단한 데이터 구조라는 것과 기억 장소의 효
율을 나타내는 메모리 밀도가 1로서 다른 어떤 데이터 구조보다 뛰어나다
고 할 수 있다.
• 메모리 밀도 : 일정 크기의 기억 장소에 얼마나 많은 데이터가 저장될 수 있는가 하는 조밀성을
계산하는 식
• 위와 같은 장점에도 불구, 데이터 항목을 추가할 경우 연속되는 기억 장소가 없으
면 처리가 불가능하며, 선형 구조를 유지하면서 데이터 항목을 추가, 삭제해야 하
므로 빈번한 삽입, 삭제가 발생될 경우 데이터 이동으로 인한 처리 속도의 저하라
는 단점을 갖게 된다.
19.
단순 연결 리스트
•연속된 항목들이 기억 장소 내에서는 어디에 저장되어 있어도 무방
• 링크 : 다음 항목의 주소나 위치에 대한 정보를 갖는 포인터
• 노드 : 리스트의 한 항목
Data1 P1 Data2 P2 Datan Pn…
데이터 링크
노드
20.
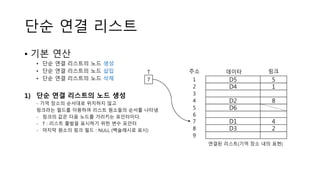
단순 연결 리스트
•기본 연산
• 단순 연결 리스트의 노드 생성
• 단순 연결 리스트의 노드 삽입
• 단순 연결 리스트의 노드 삭제
1) 단순 연결 리스트의 노드 생성
- 기억 장소의 순서대로 위치하지 않고
링크라는 필드를 이용하여 리스트 원소들의 순서를 나타냄
- 링크의 값은 다음 노드를 가리키는 포인터이다.
- T : 리스트 출발을 표시하기 위한 변수 포인터
- 마지막 원소의 링크 필드 : NULL (백슬래시로 표시)
D5
D4
D2
D6
D1
D3
5
1
8
4
2
데이타 링크주소
1
2
3
4
5
6
7
8
9
7
T
연결된 리스트(기억 장소 내의 표현)
21.
단순 연결 리스트
•생성 알고리즘
• 가용 기억 공간 중에서 리스트에 연결할 수 있게 노드를 하나 얻어내는 GetNode() 함수
• 현재 포인터 X가 가리키는 노드가 삭제 등의 조작으로 인해 더 이상 필요 없게 되었을 때 그
노드를 가용 기억 공간(storage pool)에 반납하는 RET(X) 함수
struct datanode {
char data[3];
struct datanode *link;
};
ex) 연결 리스트에 대한 노드의 데이터 형태가 datanode라고 할 때, 그 구조체는 다음과 같이 정의
데이터 필드
변수 f가 위 데이터 형태의 한 노드를 가리키는 포인터일 경우의 정의
struct datanode *f;
f→data[0], f →data[1], f →data[2], f →link
f에 의해 지칭된 노드의 각 필드는 다음과 같은 형식으로 참조될 수 있음
f.data
f
f.data[0]
f.data[1]
f.data[2]
f.link
22.
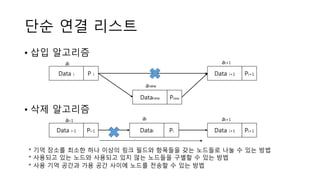
단순 연결 리스트
•삽입 알고리즘
Data i P i
Datanew Pnew
Data i+1 Pi+1
ai ai+1
anew
• 삭제 알고리즘
Data i-1 Pi-1 Datai Pi Data i+1 Pi+1
ai-1 ai+1ai
* 기억 장소를 최소한 하나 이상의 링크 필드와 항목들을 갖는 노드들로 나눌 수 있는 방법
* 사용되고 있는 노드와 사용되고 있지 않는 노드들을 구별할 수 있는 방법
* 사용 기억 공간과 가용 공간 사이에 노드를 전송할 수 있는 방법
23.
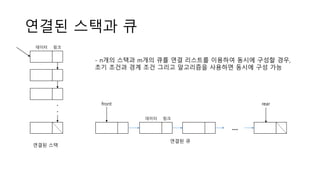
연결된 스택과 큐
데이터링크
.
.
연결된 스택
데이터 링크
front rear
연결된 큐
…
- n개의 스택과 m개의 큐를 연결 리스트를 이용하여 동시에 구성할 경우,
초기 조건과 경계 조건 그리고 알고리즘을 사용하면 동시에 구성 가능
24.
기억 공간 관리
•가용 기억 공간
• 현재 사용되고 있지 않는 모든 노드들을 포함
• 비 순차적 사상에 따라 연결된 기억 장소를 할당할 때 해결해야 될 문제
• 어떻게 노드를 구성해야 하는가
• 어떤 노드가 가용 기억 공간으로 반납되어야 하는가
• 초기 가용 노드의 생성
• 가용 노드의 획득
• 삭제 노드의 반환
25.
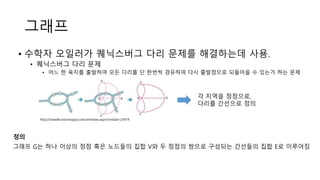
그래프
• 수학자 오일러가퀘닉스버그 다리 문제를 해결하는데 사용.
• 퀘닉스버그 다리 문제
• 어느 한 육지를 출발하여 모든 다리를 단 한번씩 경유하여 다시 출발점으로 되돌아올 수 있는가 하는 문제
각 지역을 정점으로,
다리를 간선으로 정의
그래프 G는 하나 이상의 정점 혹은 노드들의 집합 V와 두 정점의 쌍으로 구성되는 간선들의 집합 E로 이루어짐
정의
http://newdle.noonnoppi.com/xmlView.aspx?xmldid=25474
26.
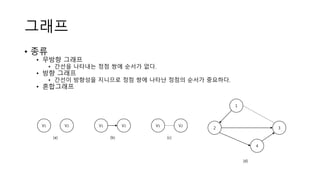
그래프
• 종류
• 무방향그래프
• 간선을 나타내는 정점 쌍에 순서가 없다.
• 방향 그래프
• 간선이 방향성을 지니므로 정점 쌍에 나타난 정점의 순서가 중요하다.
• 혼합그래프
V1 V2
(a)
V1 V2
(b)
V1 V2
(c)
1
2
(d)
3
4


![고정 길이 레코드
struct Deposit {
char branch_name[20];
int account_number;
char customer_name[20];
float balance;
};
모든 자료형을 계산해보면
Deposit 레코드는 46byte를 사용한다.](https://image.slidesharecdn.com/1-150717131431-lva1-app6892/85/amugona-study-1-4-320.jpg)



![가변 길이 레코드
• 한 파일 내에 여러 유형의 레코드 저장
• 한 파일 내에 가변 필드를 허용하는 레코드 저장
• 반복적 필드를 허용하는 레코드 저장
struct deposit_list {
char branch_name[20];
struct{
int account_number;
char customer_name[20];
float balance;
} *account_info;
};
레코드의 크기를 제한하지 않기 위해서 사용](https://image.slidesharecdn.com/1-150717131431-lva1-app6892/85/amugona-study-1-8-320.jpg)


![레코드 - C 언어
Jusorok person, employee;
struct jusorok {
int number;
char name[20];
char addr[100];
char tel[13];
} person, employee;
- 선언
employee.number = 1;
employee.name = “Moon_G”;
employee.addr = “Busan”;
employee.tel = “123-4567”;
person = employee; //치환가능
- 참조](https://image.slidesharecdn.com/1-150717131431-lva1-app6892/85/amugona-study-1-12-320.jpg)
![레코드 - C 언어
struct jusorok {
int number;
char name[20];
char addr[100];
char tel[13];
};
struct jusorok person[100];
- 배열
struct jusorok {
int number;
char name[20];
char addr[100];
char tel[13];
} person[100];
…
number name addr tel
person[0] person[100]](https://image.slidesharecdn.com/1-150717131431-lva1-app6892/85/amugona-study-1-13-320.jpg)




![단순 연결 리스트
• 생성 알고리즘
• 가용 기억 공간 중에서 리스트에 연결할 수 있게 노드를 하나 얻어내는 GetNode() 함수
• 현재 포인터 X가 가리키는 노드가 삭제 등의 조작으로 인해 더 이상 필요 없게 되었을 때 그
노드를 가용 기억 공간(storage pool)에 반납하는 RET(X) 함수
struct datanode {
char data[3];
struct datanode *link;
};
ex) 연결 리스트에 대한 노드의 데이터 형태가 datanode라고 할 때, 그 구조체는 다음과 같이 정의
데이터 필드
변수 f가 위 데이터 형태의 한 노드를 가리키는 포인터일 경우의 정의
struct datanode *f;
f→data[0], f →data[1], f →data[2], f →link
f에 의해 지칭된 노드의 각 필드는 다음과 같은 형식으로 참조될 수 있음
f.data
f
f.data[0]
f.data[1]
f.data[2]
f.link](https://image.slidesharecdn.com/1-150717131431-lva1-app6892/85/amugona-study-1-21-320.jpg)






















![[우리가 데이터를 쓰는 법] 어느 스타트업의 그럴싸한 데이터 삽질 스토리 - 헬로마켓 한상협 이사](https://cdn.slidesharecdn.com/ss_thumbnails/9-160415075729-thumbnail.jpg?width=640&height=640&fit=bounds)

![[우리가 데이터를 쓰는 법] 우리가 고객을 이해하는 법 - 에그번 에듀케이션 문관균 대표](https://cdn.slidesharecdn.com/ss_thumbnails/8-160415091829-thumbnail.jpg?width=640&height=640&fit=bounds)
![[아이투맥스] 2015.07_세일즈포스 crm 이노베이션 세미나 최신자료 salesforce crm innovation](https://cdn.slidesharecdn.com/ss_thumbnails/2015-150710052554-lva1-app6891-thumbnail.jpg?width=640&height=640&fit=bounds)
![[Mezzomedia] 메조미디어 디지털마케팅 컨퍼런스 2015](https://cdn.slidesharecdn.com/ss_thumbnails/mezzomedia-digitalmarketingtrend-2015-bydintelligence-141128012331-conversion-gate02-thumbnail.jpg?width=640&height=640&fit=bounds)










![[SOPT] 데이터 구조 및 알고리즘 스터디 - #01 : 개요, 점근적 복잡도, 배열, 연결리스트](https://cdn.slidesharecdn.com/ss_thumbnails/1-150824001021-lva1-app6892-thumbnail.jpg?width=640&height=640&fit=bounds)
















