Download free for 30 days
Sign in
Upload
Language (EN)
Support
Business
Mobile
Social Media
Marketing
Technology
Art & Photos
Career
Design
Education
Presentations & Public Speaking
Government & Nonprofit
Healthcare
Internet
Law
Leadership & Management
Automotive
Engineering
Software
Recruiting & HR
Retail
Sales
Services
Science
Small Business & Entrepreneurship
Food
Environment
Economy & Finance
Data & Analytics
Investor Relations
Sports
Spiritual
News & Politics
Travel
Self Improvement
Real Estate
Entertainment & Humor
Health & Medicine
Devices & Hardware
Lifestyle
Change Language
Language
English
Español
Português
Français
Deutsche
Cancel
Save
Submit search
EN
Uploaded by
KAYATO SAITO
12 views
AIプロダクト時代のPdMに必要なコンテキストエンジニアリング_2025年9月26日
-
Business
◦
Read more
0
Save
Share
Embed
Embed presentation
Download
Download to read offline
1
/ 28
2
/ 28
3
/ 28
4
/ 28
5
/ 28
6
/ 28
7
/ 28
8
/ 28
9
/ 28
10
/ 28
11
/ 28
12
/ 28
13
/ 28
14
/ 28
15
/ 28
16
/ 28
17
/ 28
18
/ 28
19
/ 28
20
/ 28
21
/ 28
22
/ 28
23
/ 28
24
/ 28
25
/ 28
26
/ 28
27
/ 28
28
/ 28
More Related Content
PPTX
2025_04_27 ptompt engineering for beginer
by
Yuki Kikuchi
PPTX
local launch small language model of AI.
by
Takao Tetsuro
PDF
『生成AIによるソフトウェア開発』(鷲崎弘宜, 鵜林尚靖, 中川尊雄, 増田航太, 徳本晋, 近藤将成, 石川冬樹, 竹之内啓太, 小川秀人, スマートエ...
by
Hironori Washizaki
PPTX
FIWARE Orion Context Broker コンテキスト情報管理 (Orion 1.15.0対応)
by
fisuda
PDF
XP祭り関西2011 森崎 修司「プラクティスが有効にはたらく前提は明らかになっていますか?」
by
Shuji Morisaki
PDF
What is web3.pdf
by
KAYATO SAITO
PDF
5分でわかるSSI(Self-Sovereign Identity / 自己主権型アイデンティティ)の必要性
by
KAYATO SAITO
PDF
PID:the Protocol for Programmable Identity.pdf
by
KAYATO SAITO
2025_04_27 ptompt engineering for beginer
by
Yuki Kikuchi
local launch small language model of AI.
by
Takao Tetsuro
『生成AIによるソフトウェア開発』(鷲崎弘宜, 鵜林尚靖, 中川尊雄, 増田航太, 徳本晋, 近藤将成, 石川冬樹, 竹之内啓太, 小川秀人, スマートエ...
by
Hironori Washizaki
FIWARE Orion Context Broker コンテキスト情報管理 (Orion 1.15.0対応)
by
fisuda
XP祭り関西2011 森崎 修司「プラクティスが有効にはたらく前提は明らかになっていますか?」
by
Shuji Morisaki
What is web3.pdf
by
KAYATO SAITO
5分でわかるSSI(Self-Sovereign Identity / 自己主権型アイデンティティ)の必要性
by
KAYATO SAITO
PID:the Protocol for Programmable Identity.pdf
by
KAYATO SAITO
More from KAYATO SAITO
PDF
NFT(Non-Fungible Token)入門資料.pdf
by
KAYATO SAITO
PDF
SSI DIDs VCs 入門資料
by
KAYATO SAITO
PDF
Web3 Events Feedback Solana Japan meetup 202208
by
KAYATO SAITO
PDF
LNURL-auth_Diamond HandsMeetup LT.pdf
by
KAYATO SAITO
PDF
Solana Japan Meetup 20220618 Solana Hacker House Tokyo Review
by
KAYATO SAITO
PDF
0からはじめるWeb3入門(WEB1.0 / WEB2.0 / BLOCKCHAIN / Bitcoin / Smart contract / DeFi ...
by
KAYATO SAITO
PDF
暗号資産ウォレット入門(METAMASKの入門~詐欺対策など).pdf
by
KAYATO SAITO
PDF
Solana Japan Meeting 2021 November
by
KAYATO SAITO
PDF
ブロックチェーン×WEB3×NFT入門資料.pdf
by
KAYATO SAITO
NFT(Non-Fungible Token)入門資料.pdf
by
KAYATO SAITO
SSI DIDs VCs 入門資料
by
KAYATO SAITO
Web3 Events Feedback Solana Japan meetup 202208
by
KAYATO SAITO
LNURL-auth_Diamond HandsMeetup LT.pdf
by
KAYATO SAITO
Solana Japan Meetup 20220618 Solana Hacker House Tokyo Review
by
KAYATO SAITO
0からはじめるWeb3入門(WEB1.0 / WEB2.0 / BLOCKCHAIN / Bitcoin / Smart contract / DeFi ...
by
KAYATO SAITO
暗号資産ウォレット入門(METAMASKの入門~詐欺対策など).pdf
by
KAYATO SAITO
Solana Japan Meeting 2021 November
by
KAYATO SAITO
ブロックチェーン×WEB3×NFT入門資料.pdf
by
KAYATO SAITO
Recently uploaded
PDF
「漫画村-Cloudflare事件」徹底解説 -Cloudflare trial-
by
Masaaki Nabeshima
PDF
事業ページ掲載用_セールスハブ営業資料.pdf1111111111111111
by
株式会社Saleshub
PDF
slideshare_ナハトエース会社説明資料_2025/12/11_SlideShare.pdf
by
syotakawagoe
PDF
【HP】202512_Low Code COMPANY DECK data.pdf
by
mii88yu
PDF
【会社紹介資料】 株式会社カンゲンエージェント [ 11 月 30 日作成資料公開 ].pdf
by
recruit21
PDF
動画『【続報】新税率は35%超!M&Aの税金が大幅増税|3.5億円から対象に』で投影した資料
by
STRコンサルティング
PDF
1ページでわかるTAPP_20251211________________
by
rikatokui
PDF
多摩市経営塾/基礎から学ぶデジタルマーケティングで中小企業講演「生成AIを使ったテキパキ仕事術」
by
竹内 幸次
PDF
【東京濾器株式会社】新卒採用パンフレット/Recruit pamphlet.pdf
by
memory0135
「漫画村-Cloudflare事件」徹底解説 -Cloudflare trial-
by
Masaaki Nabeshima
事業ページ掲載用_セールスハブ営業資料.pdf1111111111111111
by
株式会社Saleshub
slideshare_ナハトエース会社説明資料_2025/12/11_SlideShare.pdf
by
syotakawagoe
【HP】202512_Low Code COMPANY DECK data.pdf
by
mii88yu
【会社紹介資料】 株式会社カンゲンエージェント [ 11 月 30 日作成資料公開 ].pdf
by
recruit21
動画『【続報】新税率は35%超!M&Aの税金が大幅増税|3.5億円から対象に』で投影した資料
by
STRコンサルティング
1ページでわかるTAPP_20251211________________
by
rikatokui
多摩市経営塾/基礎から学ぶデジタルマーケティングで中小企業講演「生成AIを使ったテキパキ仕事術」
by
竹内 幸次
【東京濾器株式会社】新卒採用パンフレット/Recruit pamphlet.pdf
by
memory0135
AIプロダクト時代のPdMに必要なコンテキストエンジニアリング_2025年9月26日
1.
AIプロダクト時代のPdMに必要な コンテキストエンジニアリング @_kayato
2.
本日のテーマ 2 これからのプロダクトマネージャーにおいて 必要なコンテキストエンジニアリングスキル
3.
コンテキストエンジニアリングとは 3 コンテキストエンジニアリングとは、 エージェントの軌跡の各ステップにおいて、 コンテキストウィンドウを適切な情報で 埋める技術と科学です。 https://blog.langchain.com/context-engineering-for-agents/ Karpathy氏の発言
4.
Shopi f y
CEO tobi 氏のツイート 4 https://x.com/tobi/status/1935533422589399127 “ 「プロンプトエンジニアリング」よりも「コンテキストエンジニアリング」という言葉が 本当に好きです。 それは核心的なスキルをより良く表しています:LLMがそのタスクを妥 当に解決できるように、すべてのコンテキストを提供する技術です。 ”
5.
Eureka Labs Andrej
Karpathy氏の発言 5 https://x.com/karpathy/status/1937902205765607626 産業レベルのLLMアプリケーションでは、コンテキストエンジニアリングは、次のステッ プにちょうど適切な情報をコンテキストウィンドウに詰め込む、繊細な芸術と科学です。
6.
最古の学術用例(2006年) 6 注:LLMリサーチベースなのでもっと古いものあるかもしれません…
7.
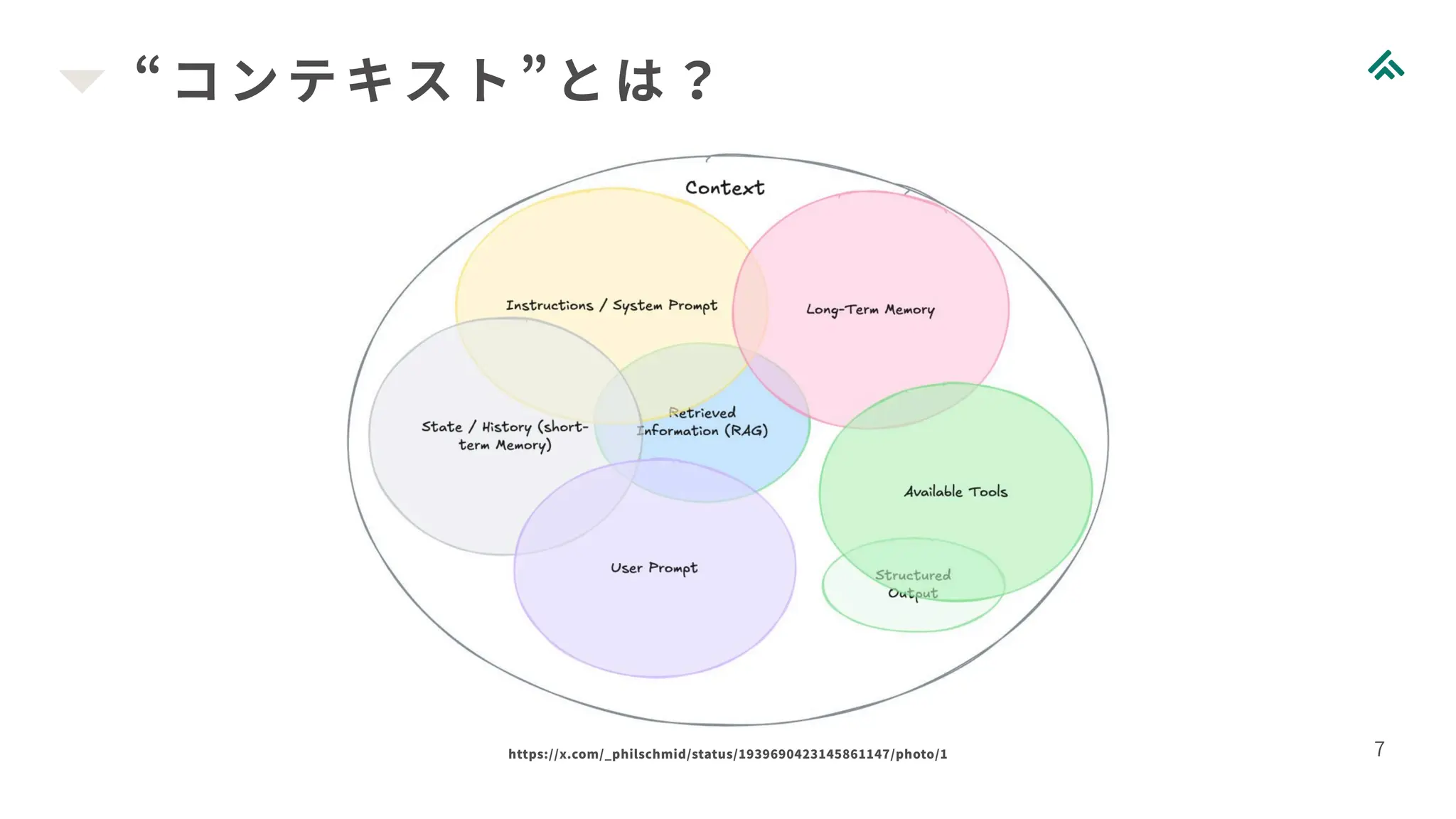
“コンテキスト”とは? 7 https://x.com/_philschmid/status/1939690423145861147/photo/1
8.
なぜ“コンテキスト”が重要なのか 8 「Garbage in, garbage
out (GIGO)」 「ゴミのようなデータを入力すれば、 ゴミのような結果しか出力されない」 情報処理システムや機械学習モデルにおいて、 入力されるデータの質が最終的な出力の質を決定する
9.
長期利用になるほどコンテキストは増える 9 https://docs.claude.com/en/docs/build-with-claude/context-windows
10.
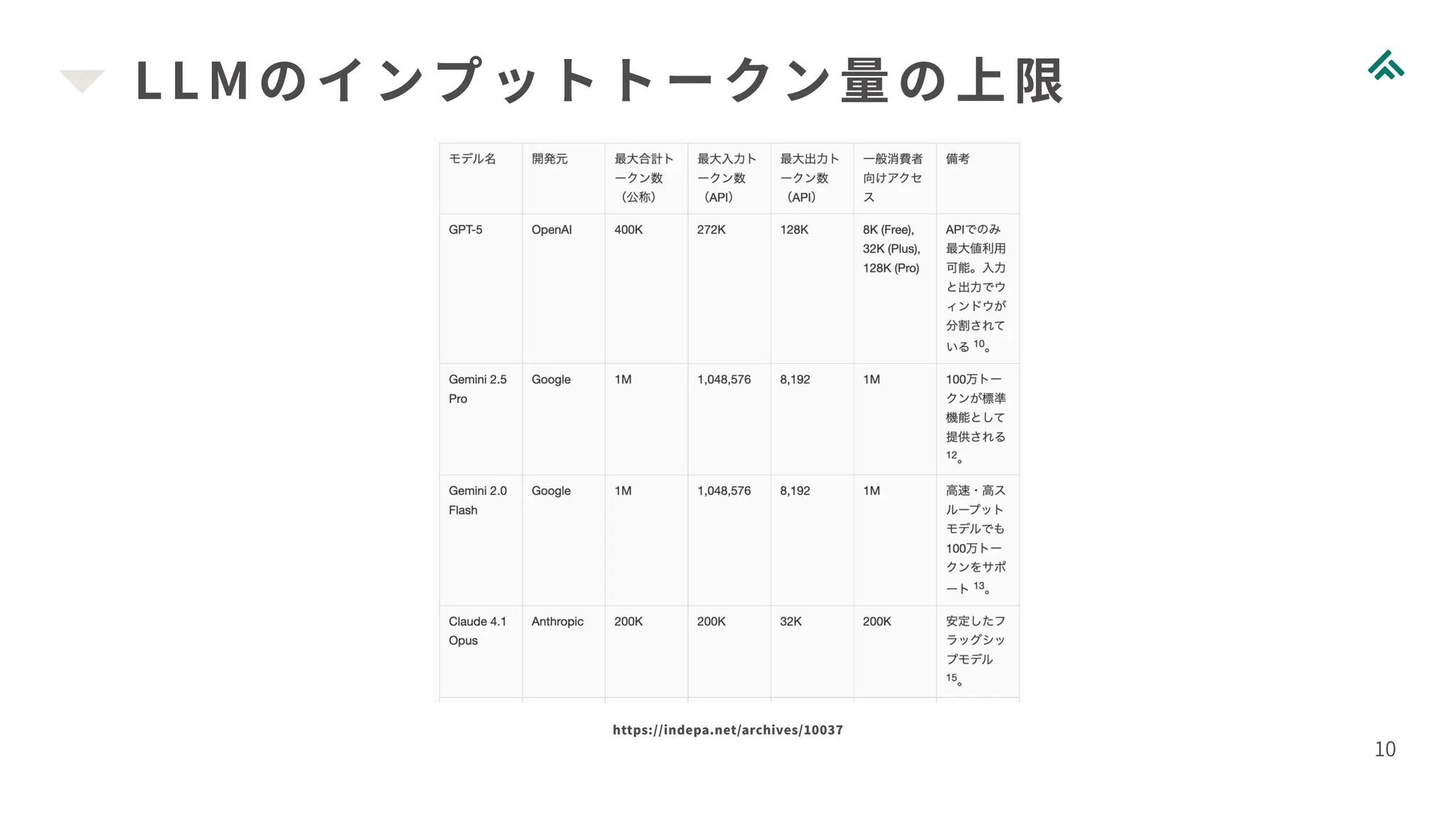
LLMのインプットトークン量の上限 10 https://indepa.net/archives/10037
11.
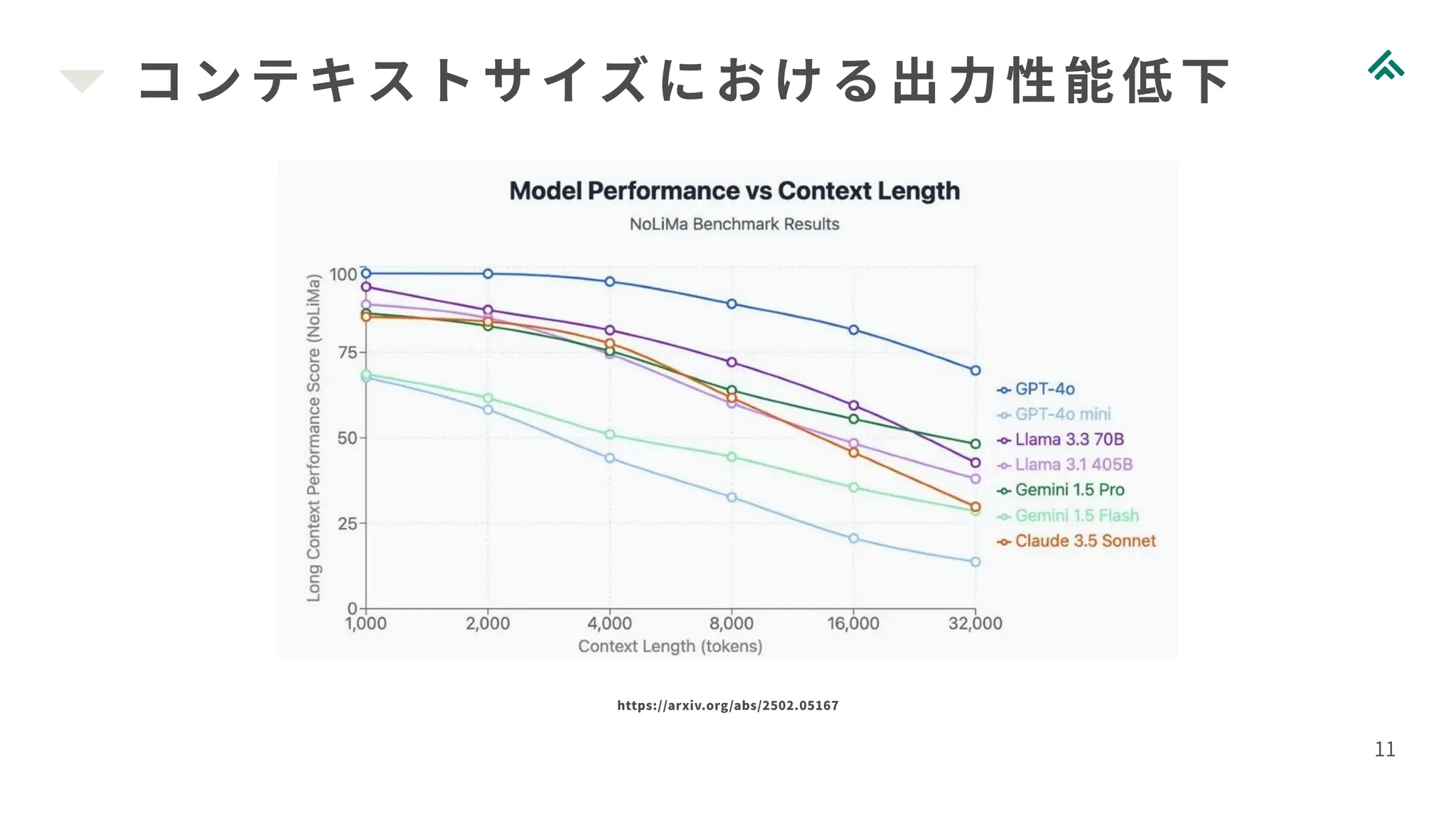
コンテキストサイズにおける出力性能低下 11 https://arxiv.org/abs/2502.05167
12.
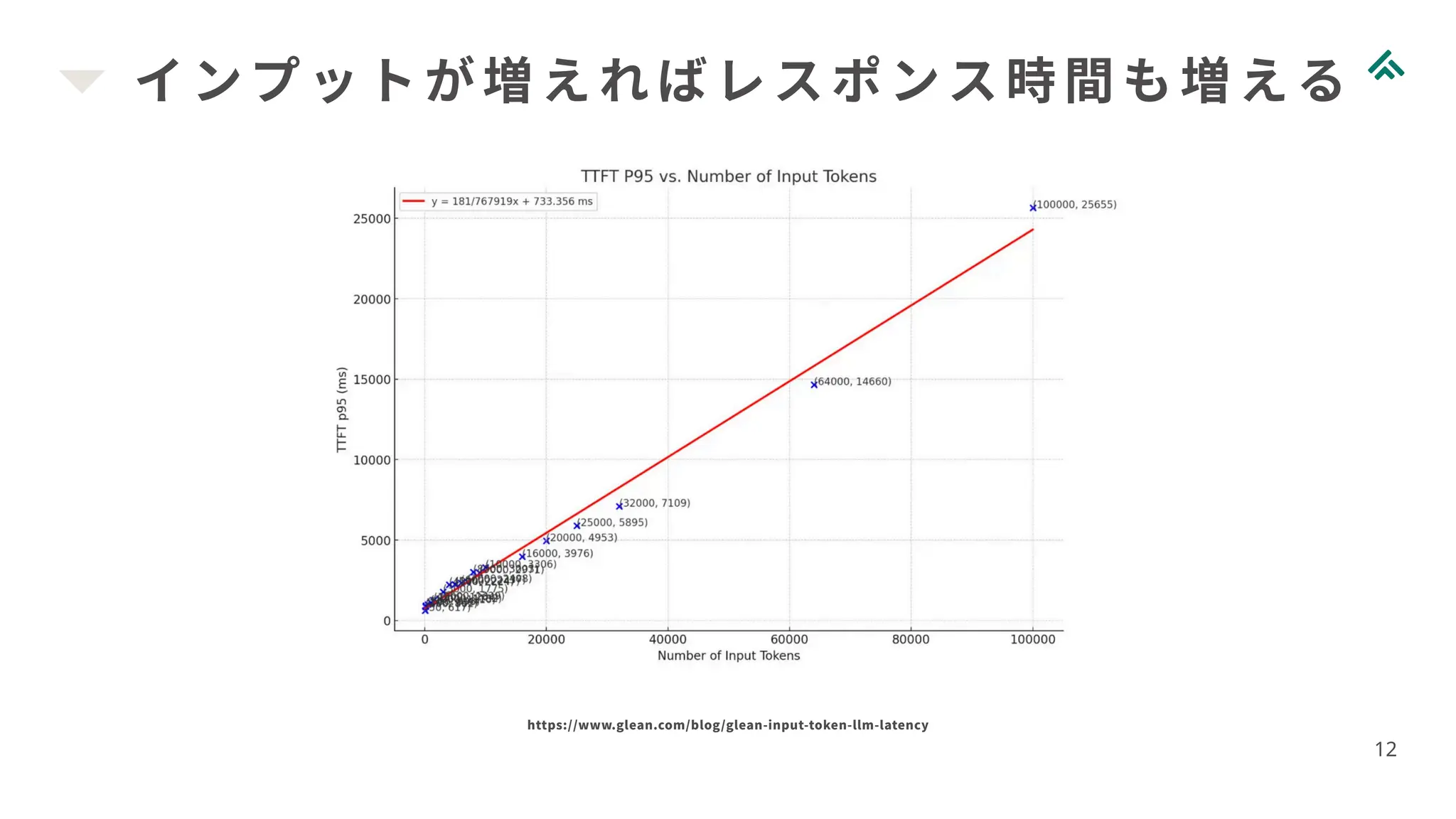
インプットが増えればレスポンス時間も増える 12 https://www.glean.com/blog/glean-input-token-llm-latency
13.
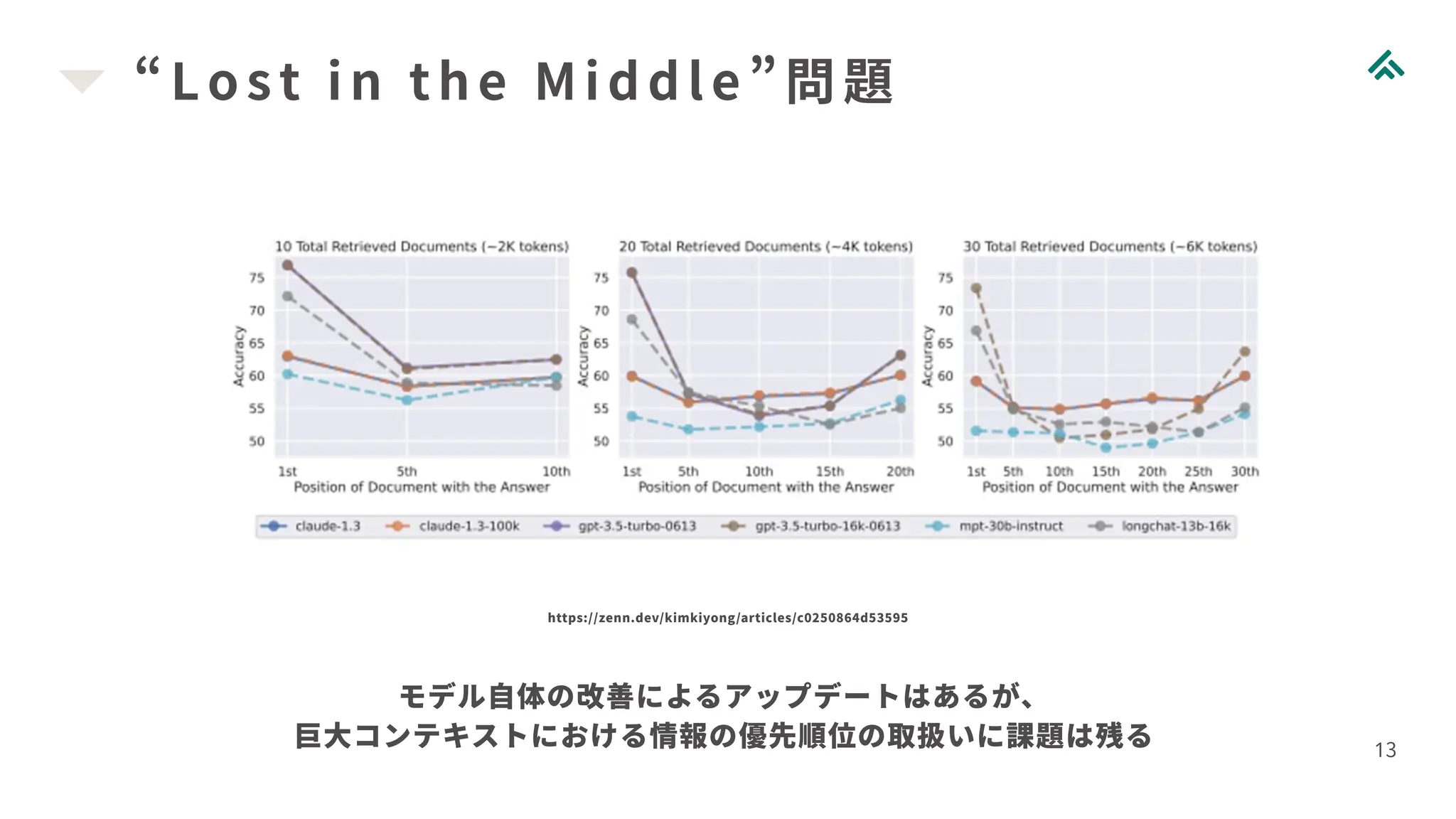
“Lost i n
the Mi ddl e”問題 13 https://zenn.dev/kimkiyong/articles/c0250864d53595 モデル自体の改善によるアップデートはあるが、 巨大コンテキストにおける情報の優先順位の取扱いに課題は残る
14.
コンテキスト管理における実運用上の課題 14 ■ Context Poisoning(コンテキストの汚染) ハルシネーションやその他のエラーがコンテキスト内に入り込み、繰り返し参照されること ■
Context Distraction (コンテキストの逸脱) コンテキストが長くなりすぎて、モデルがコンテキストに過度に集中し、トレーニング中に学習した 内容を無視してしまうこと ■ Context Confusion(コンテキストの混乱) コンテキスト内の余分なコンテンツがモデルによって使用され、品質の低い応答が生成されること ■ Context Clash(コンテキストの衝突) コンテキスト内の他の情報と矛盾する新しい情報やツールがコンテキスト内に蓄積されること https://www.dbreunig.com/2025/06/22/how-contexts-fail-and-how-to-fix-them.html
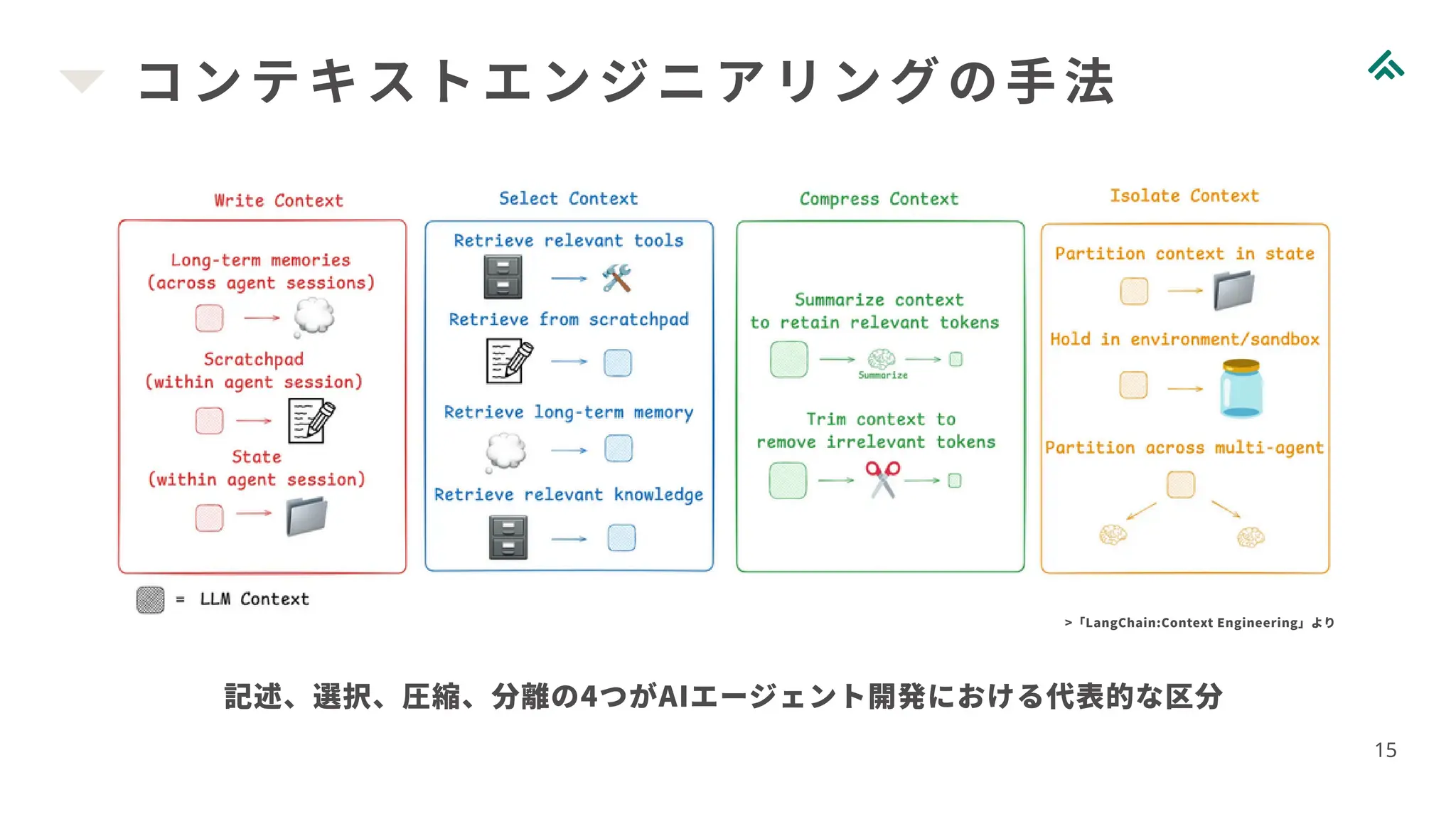
15.
コンテキストエンジニアリングの手法 15 記述、選択、圧縮、分離の4つがAIエージェント開発における代表的な区分 >「LangChain:Context Engineering」より
16.
手法①:Wri te(記述) 16 >「LangChain:Context Engineering」より コンテキストウィンドウの外部にコンテキストを保存し、コンテキストウィンドウの上限 が超えても再度コンテキストを引っ張り出せるようにしておく
17.
手法②:Sel ect(選択) 17 タスクに対して適切なコンテキストを「選択」し、 LLMに受け渡す >「LangChain:Context Engineering」より
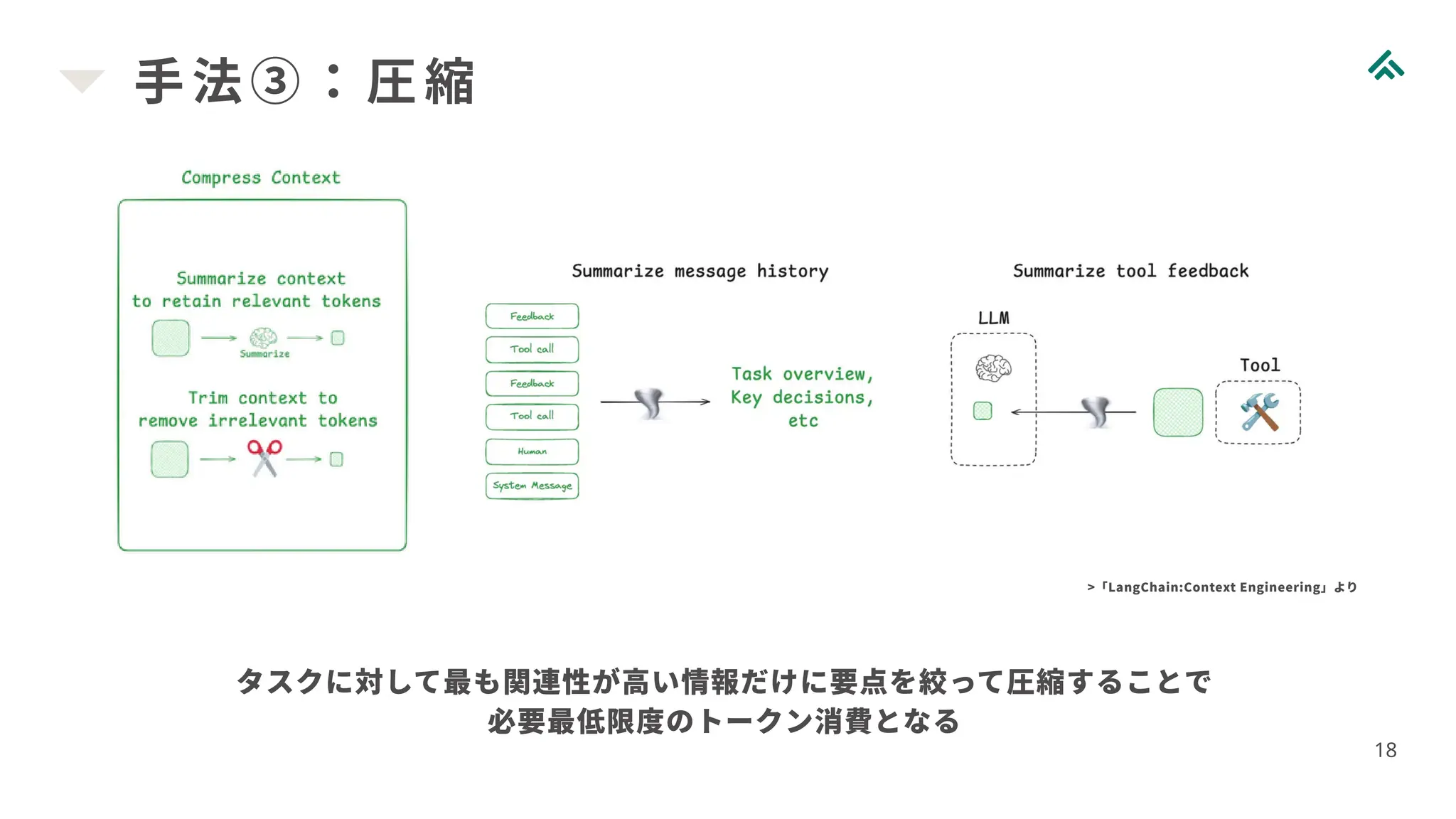
18.
手法③:圧縮 18 >「LangChain:Context Engineering」より タスクに対して最も関連性が高い情報だけに要点を絞って圧縮することで 必要最低限度のトークン消費となる
19.
手法④:分離 19 >「LangChain:Context Engineering」より タスクのスコープ自体を狭めることで活用するコンテキストのスコープも限定化される
20.
AI 時代においても不変なPdMマインド 20 ユーザー課題を理解し、 価値あるプロダクトを設計する
21.
これからのPdMにもとめられること 21 ① AI 時代のUX設計 ②
コンテキストの外部調達 ③ トークン料と提供価値の最適化
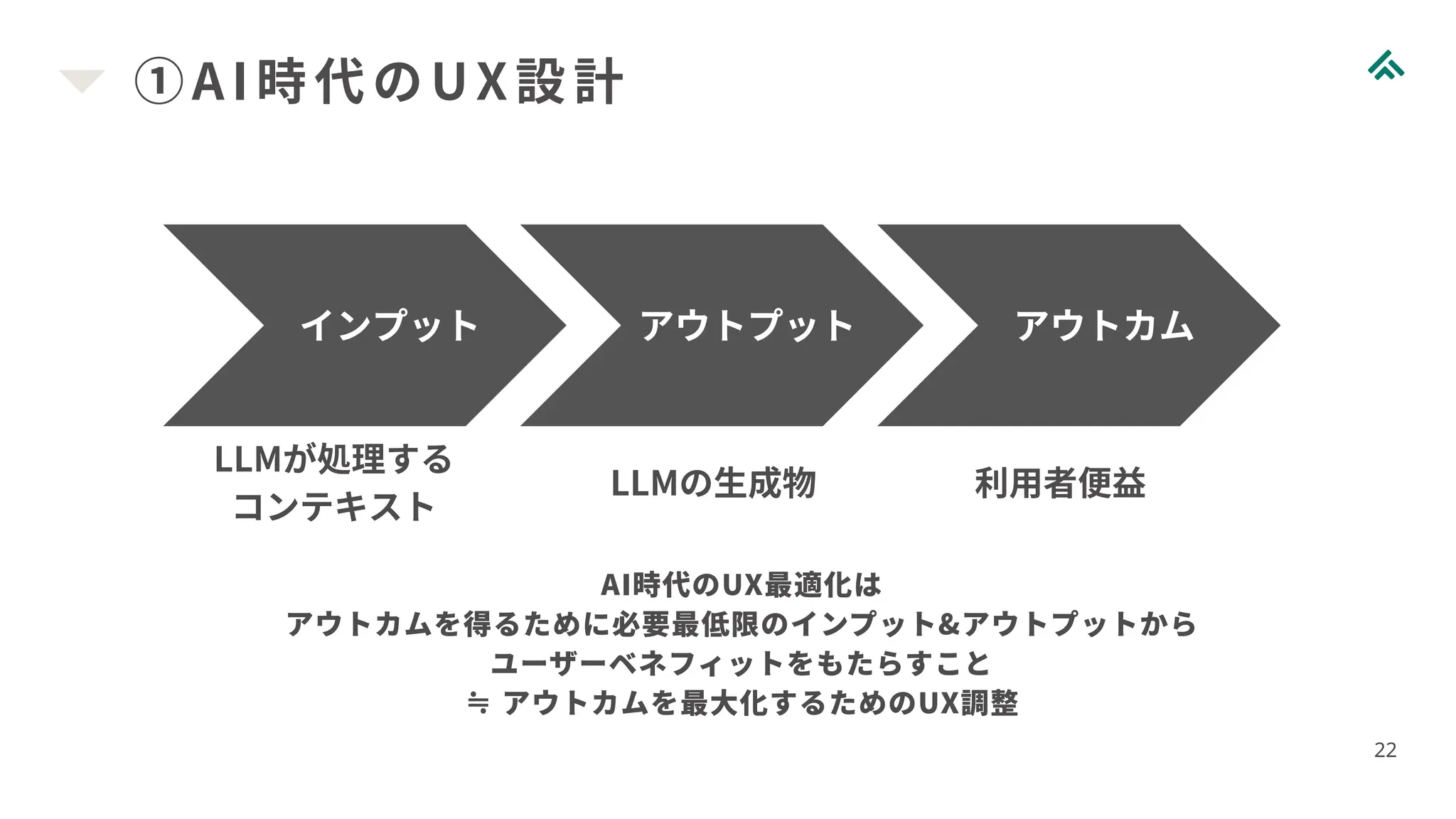
22.
①AI 時代のUX設計 22 インプット アウトプット
アウトカム LLMが処理する コンテキスト LLMの生成物 利用者便益 AI時代のUX最適化は アウトカムを得るために必要最低限のインプット&アウトプットから ユーザーベネフィットをもたらすこと ≒ アウトカムを最大化するためのUX調整
23.
Bad Case1:インプット過多 23 ユーザーインプット(コンテキスト)が多ければ、 それだけアウトプットへのハードルは上がる 必要最低限度のインプット設計&インプットの自動化でのUX改善が必要
24.
Bad Case2:アウトプット過多 24 提示するアウトプットが多いほどユーザーの認知負荷は高まる アウトカムにつながるアウトプットに絞り込みを行うプロセスでUXを改善する ユーザーストーリーに対して最適なアウトプットを定義することが重要 Human-in-the-Loop(HITL)で中間プロセスで関与するアプローチもある
25.
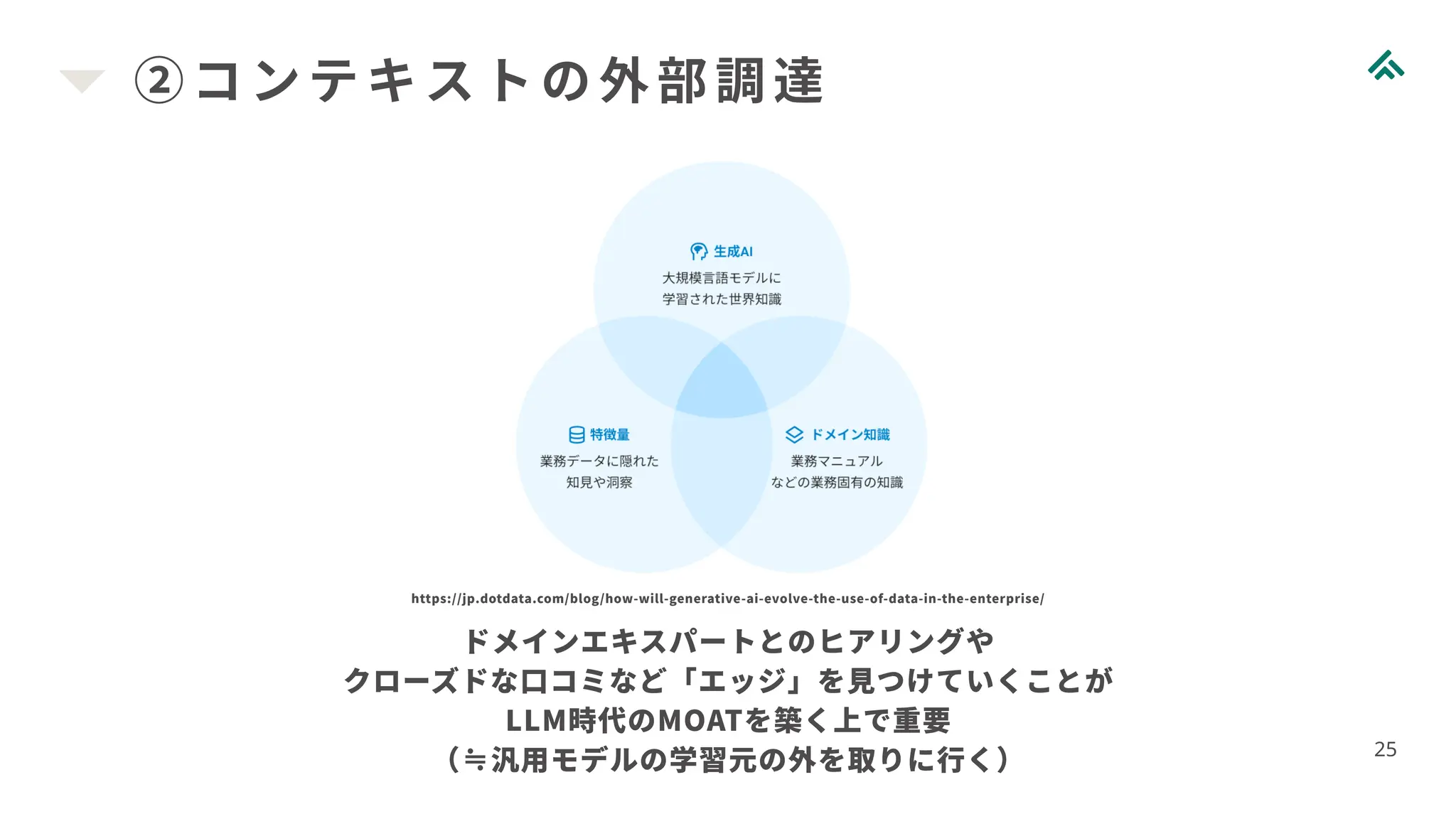
②コンテキストの外部調達 25 ドメインエキスパートとのヒアリングや クローズドな口コミなど「エッジ」を見つけていくことが LLM時代のMOATを築く上で重要 (≒汎用モデルの学習元の外を取りに行く) https://jp.dotdata.com/blog/how-will-generative-ai-evolve-the-use-of-data-in-the-enterprise/
26.
③トークン料と提供価値の最適化 26 提供コスト=システム+ トークン従量課金 LLMモデルを活用したアプリケーションレイヤーでサービス提供を行う場合、 コンテキスト調整から最適な粒度でのアウトプット調整を行わないと アプリケーションレイヤーの競争環境において提供価格で負けてしまう
27.
コスト最適化のためのTi ps 27 データの前処理は低コストモデルを活用 出力トークン上限数をあらかじめ絞る サマライズや必要パートだけ抜粋することでトークン数を 圧縮していく ワークフローの中に段階的にHI TLを挿入する UXとのトレードオフ 中間工程のアウトプットをキャッシュ化しておくことで、 最終アウトプットが期待値通りでなかったときに再処理の コストを減らす・・・など
28.
これからのPdMにもとめられること(再掲) 28 ① AI 時代のUX設計 ②
コンテキストの外部調達 ③ トークン料と提供価値の最適化
Download









































![【会社紹介資料】 株式会社カンゲンエージェント [ 11 月 30 日作成資料公開 ].pdf](https://cdn.slidesharecdn.com/ss_thumbnails/11-251211095054-61b5c9e6-thumbnail.jpg?width=640&height=640&fit=bounds)



