Download to read offline






![9/35
Introduction
Traditional techniques
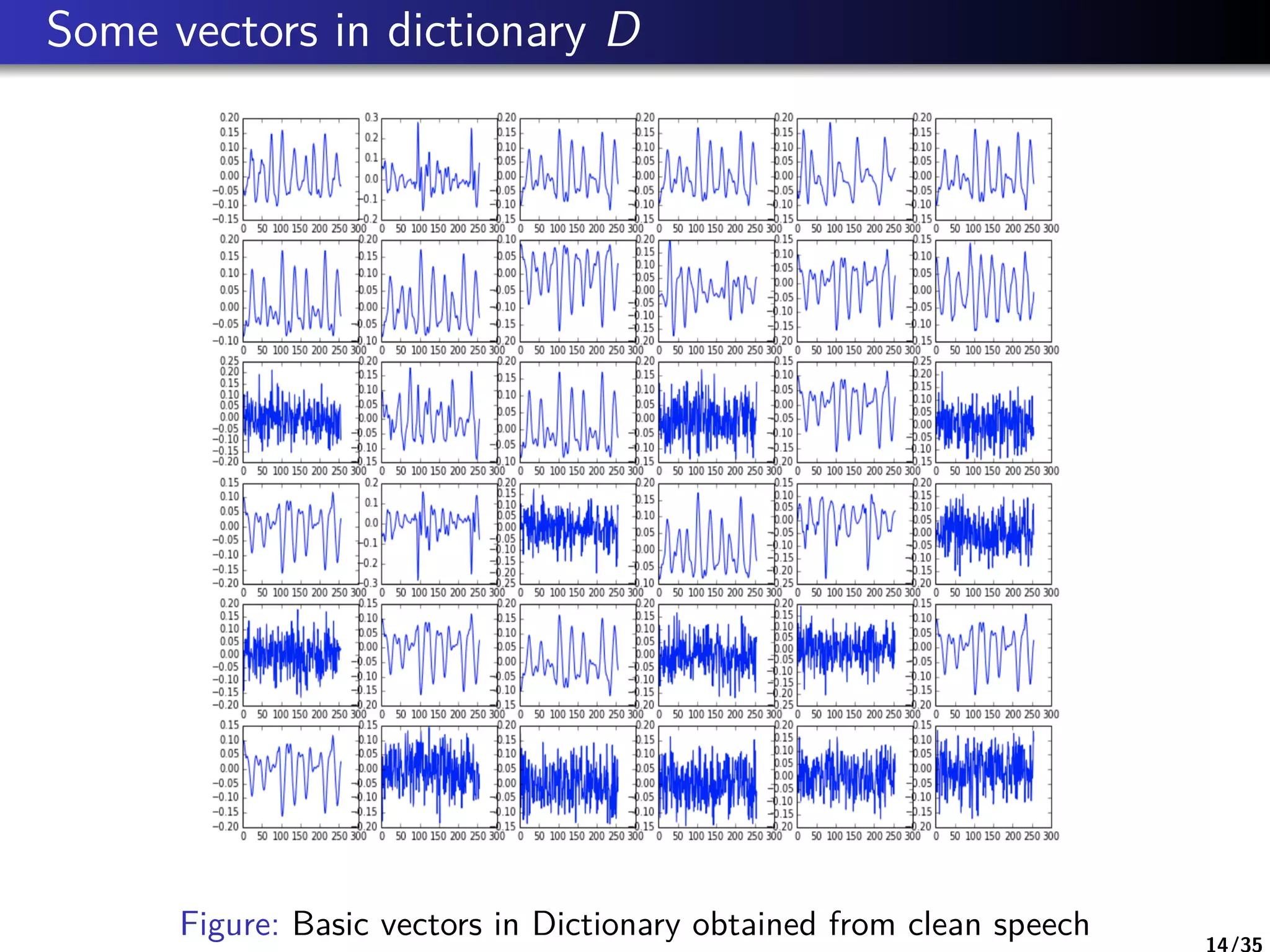
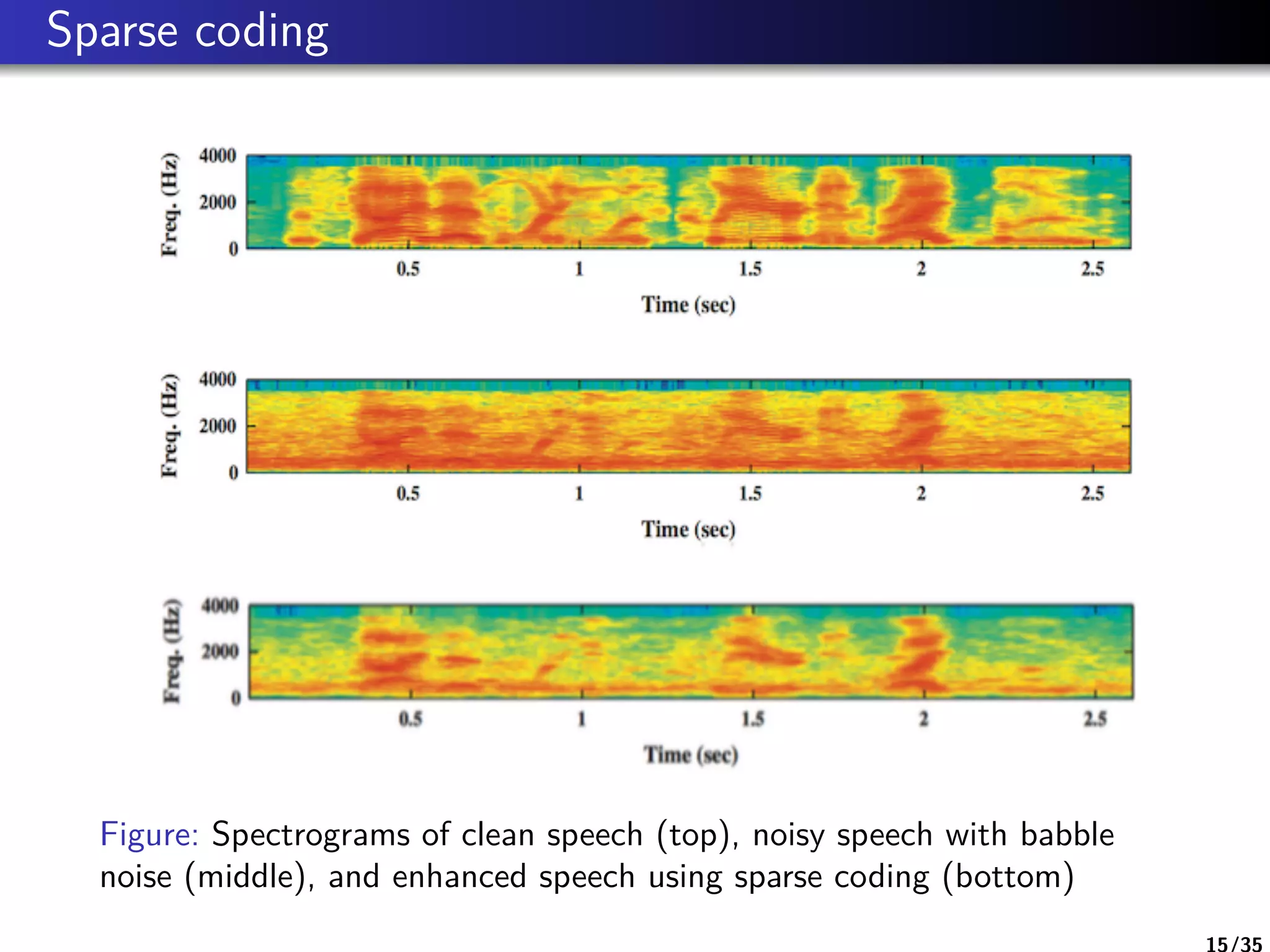
Sparse Coding
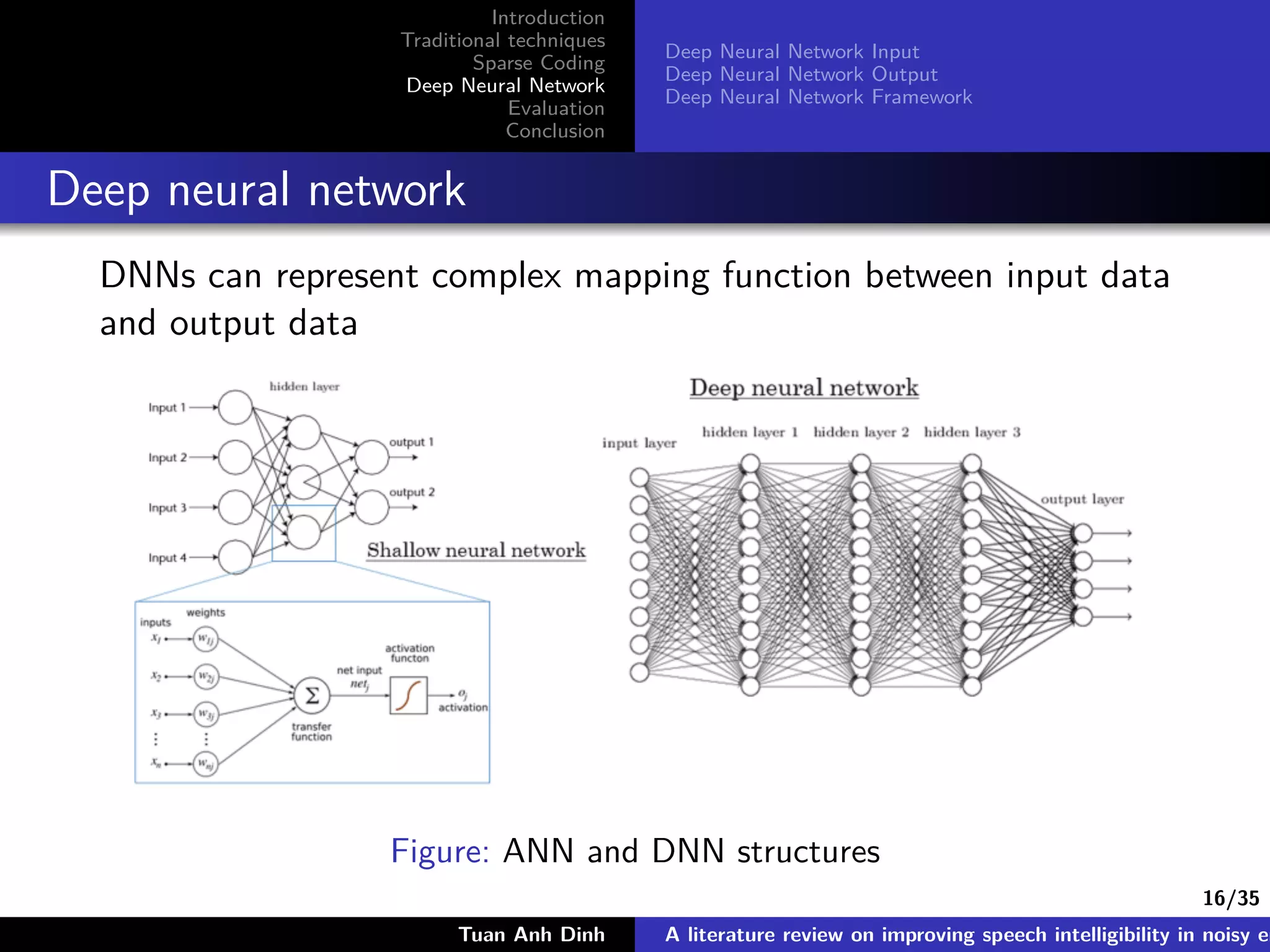
Deep Neural Network
Evaluation
Conclusion
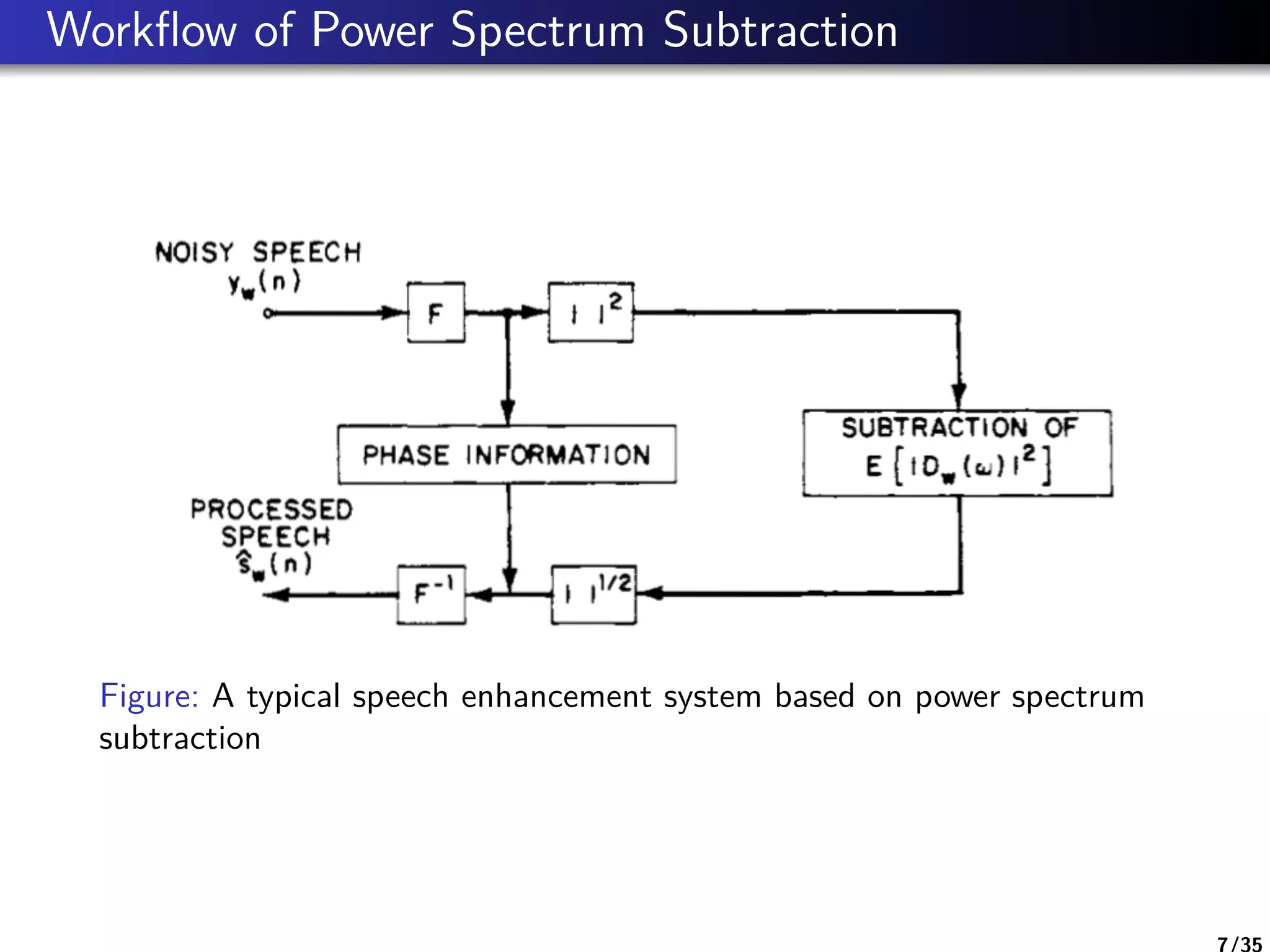
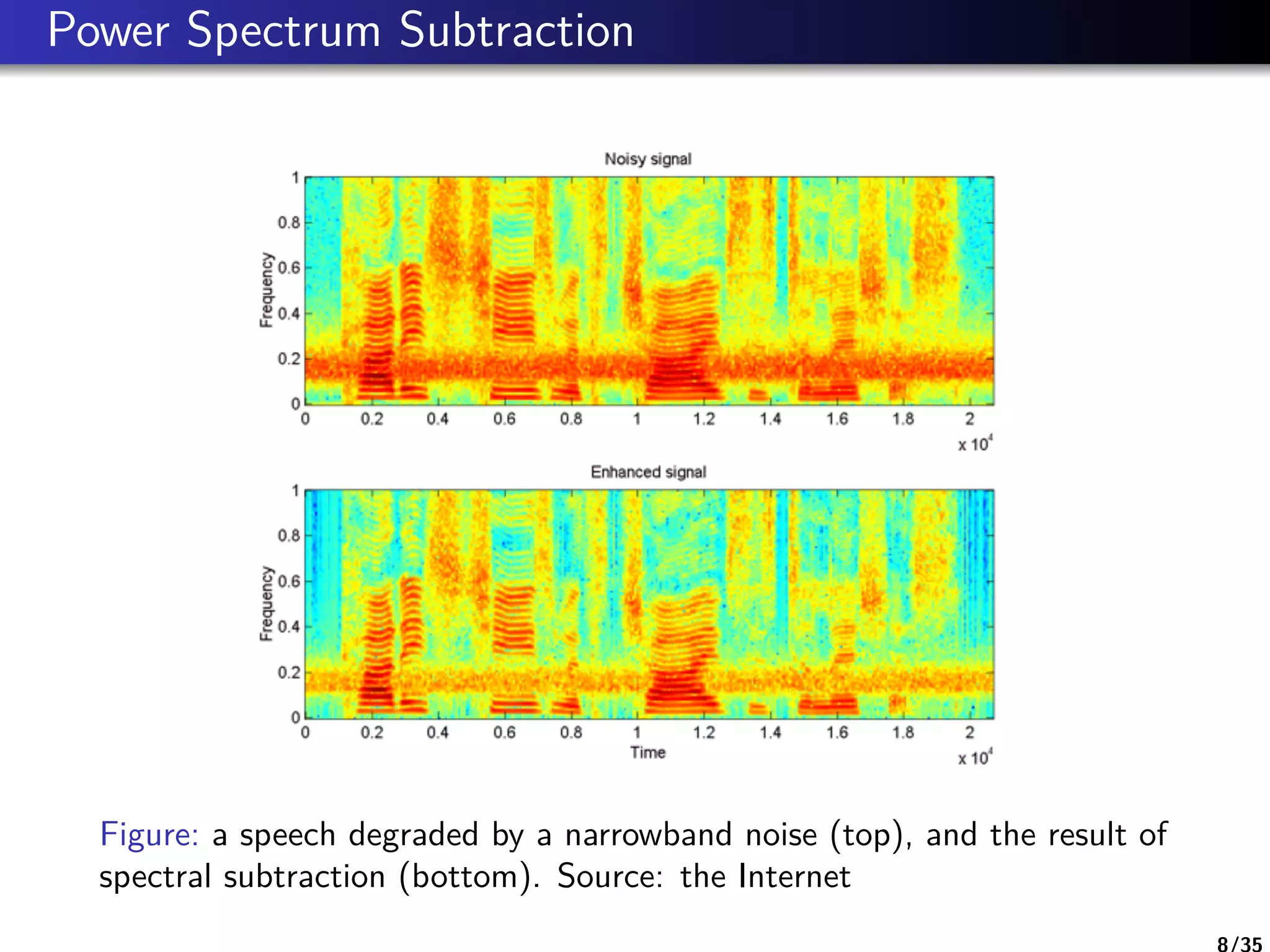
Power Spectrum Subtraction
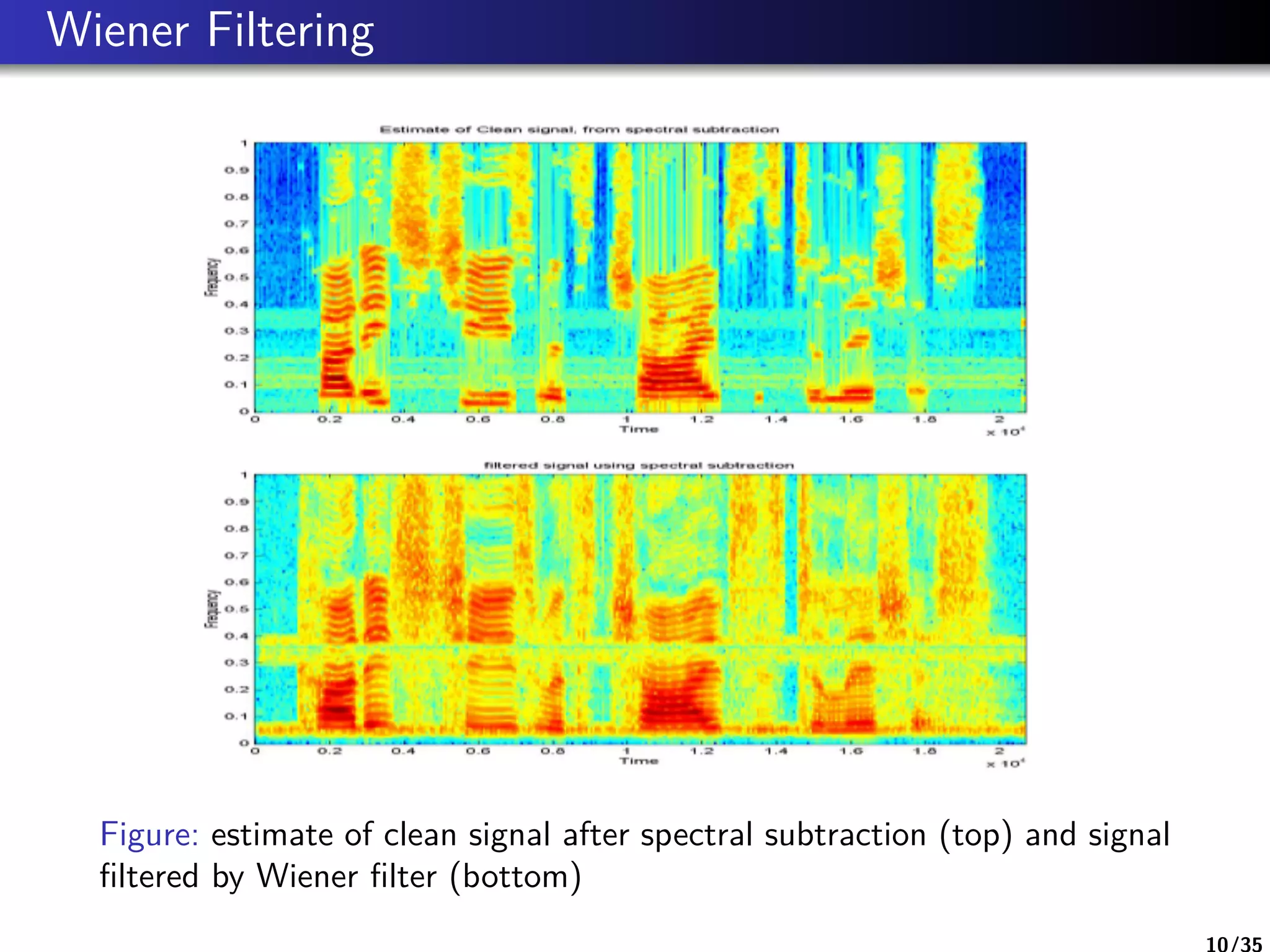
Wiener Filtering
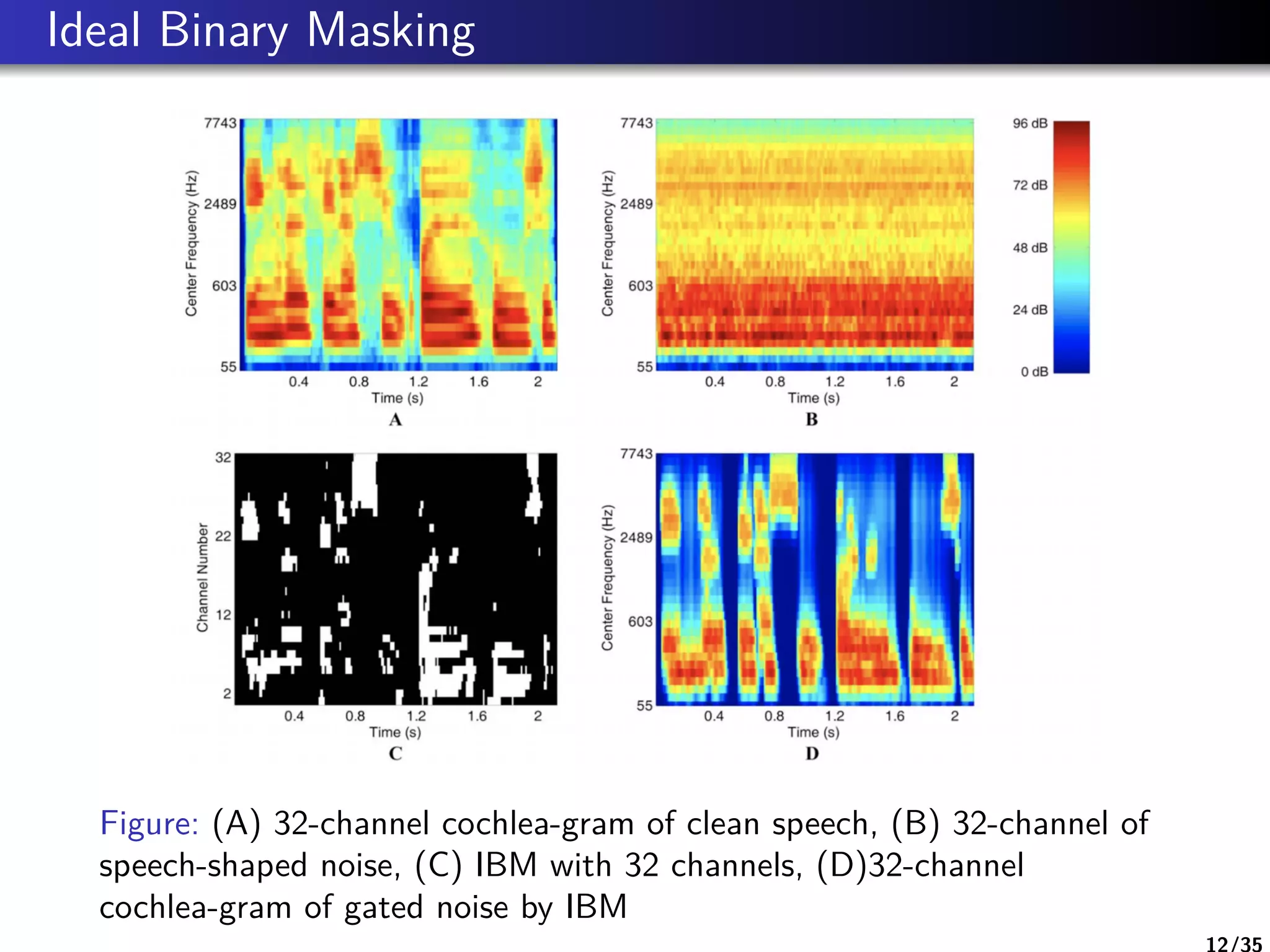
Ideal Binary Masking
Wiener Filtering
Minimize the error E |s(n) − ˆs(n)|2 , we obtain Wiener
filter’s gain H(f )
H(f ) =
E |S(f )|2
E [|S(f )|2] + E [|D(f )|2]
where |S(f )|2 is the power spectrum of clean speech, |D(f )|2
is the power spectrum of noise, s(n) is clean signal and ˆs(n) is
enhanced signal.
The mean squared error (MSE) criterion is not strongly
correlated with perception (Lim 1979)
Tuan Anh Dinh A literature review on improving speech intelligibility in noisy en](https://image.slidesharecdn.com/talk-181206184511/75/A-literature-review-on-improving-speech-intelligibility-in-noisy-environment-9-2048.jpg)






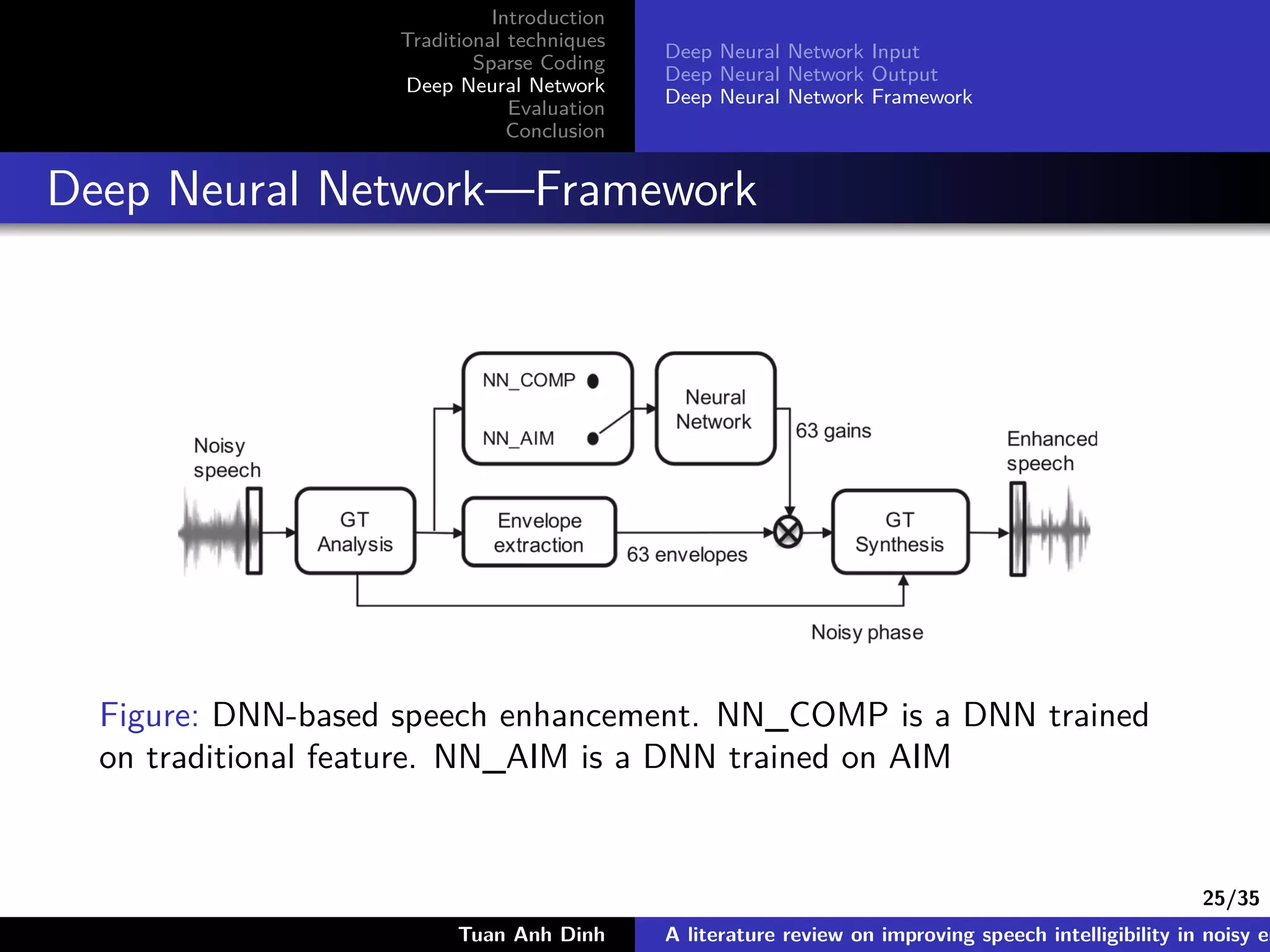

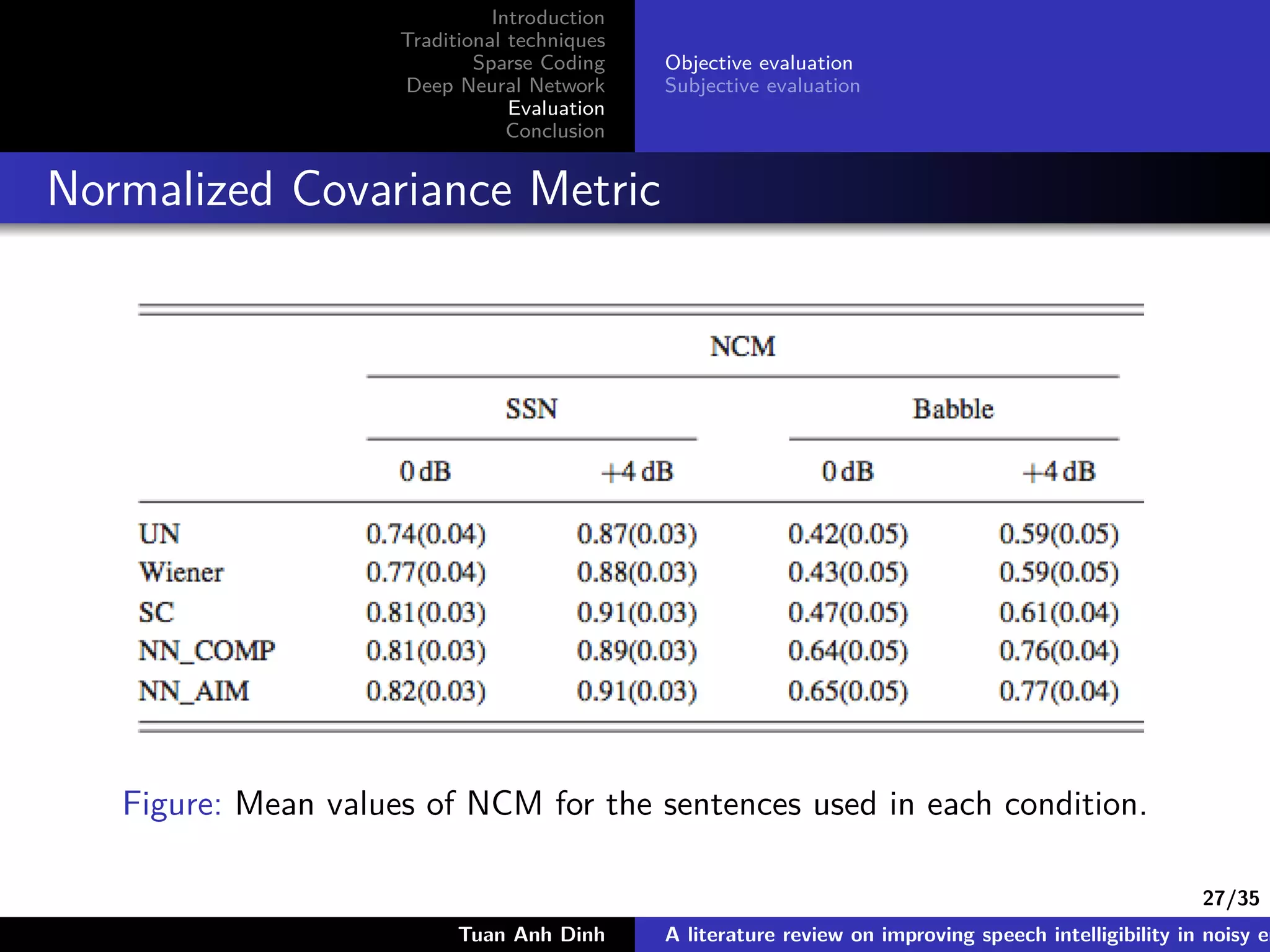
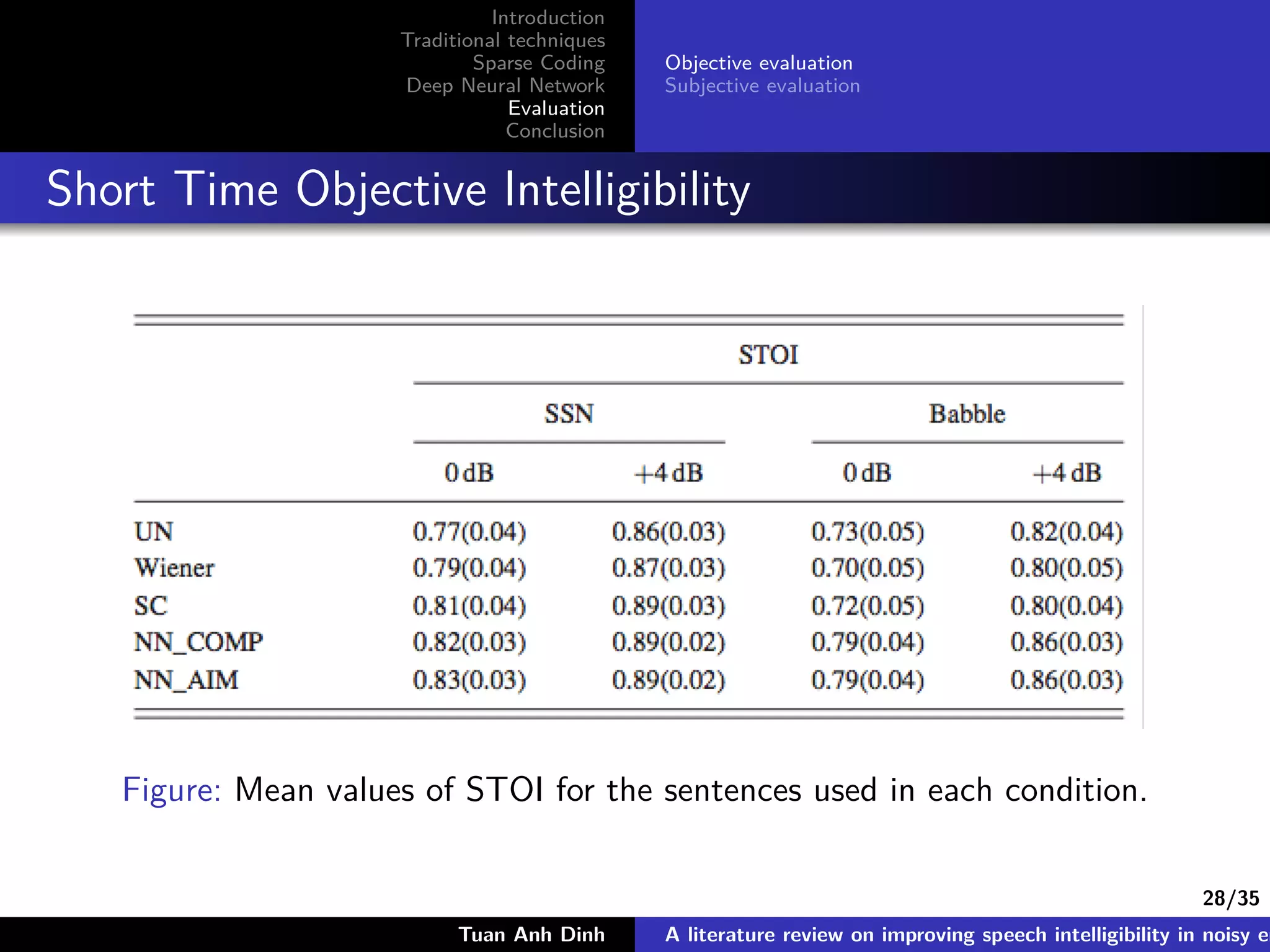



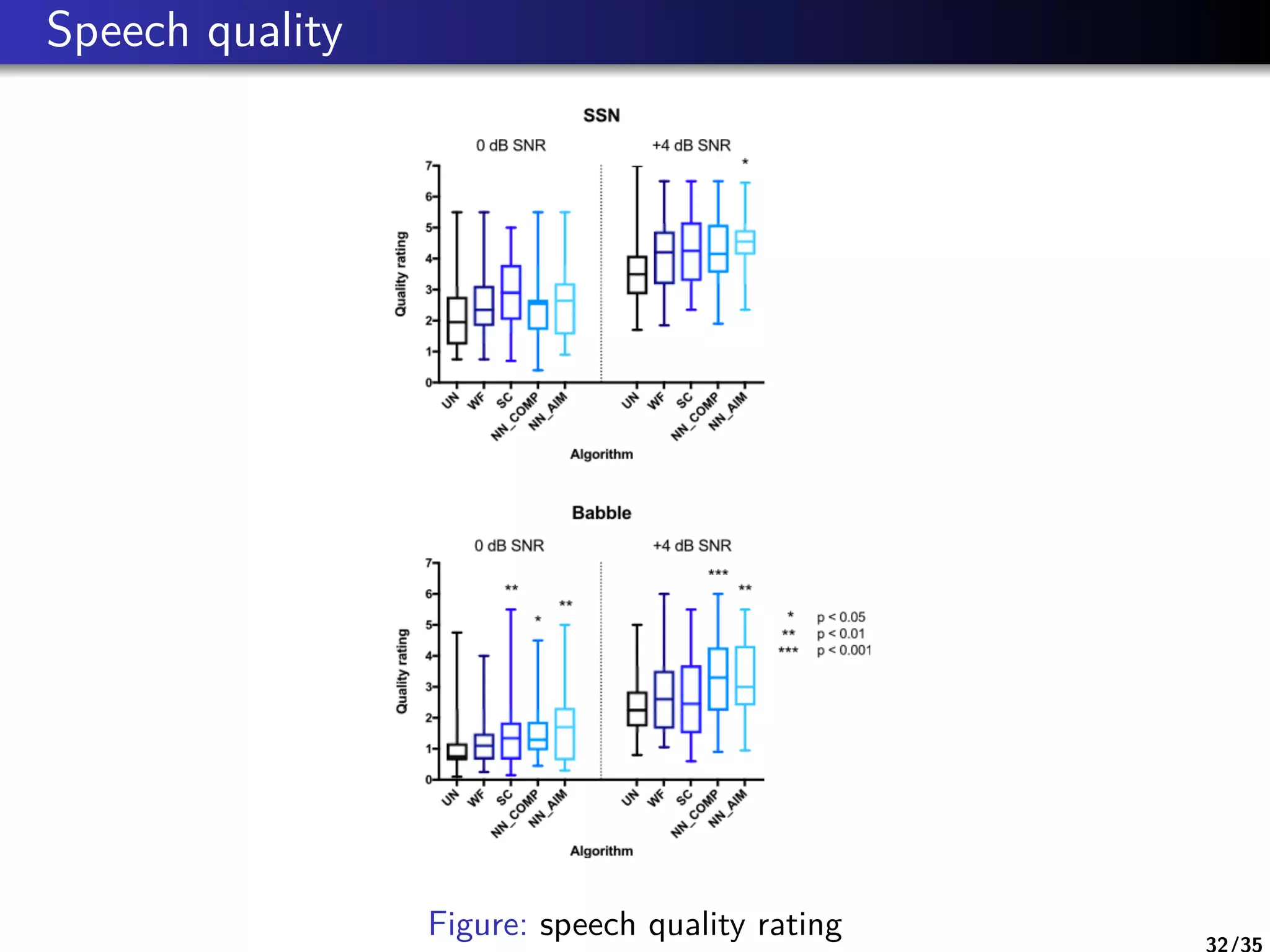
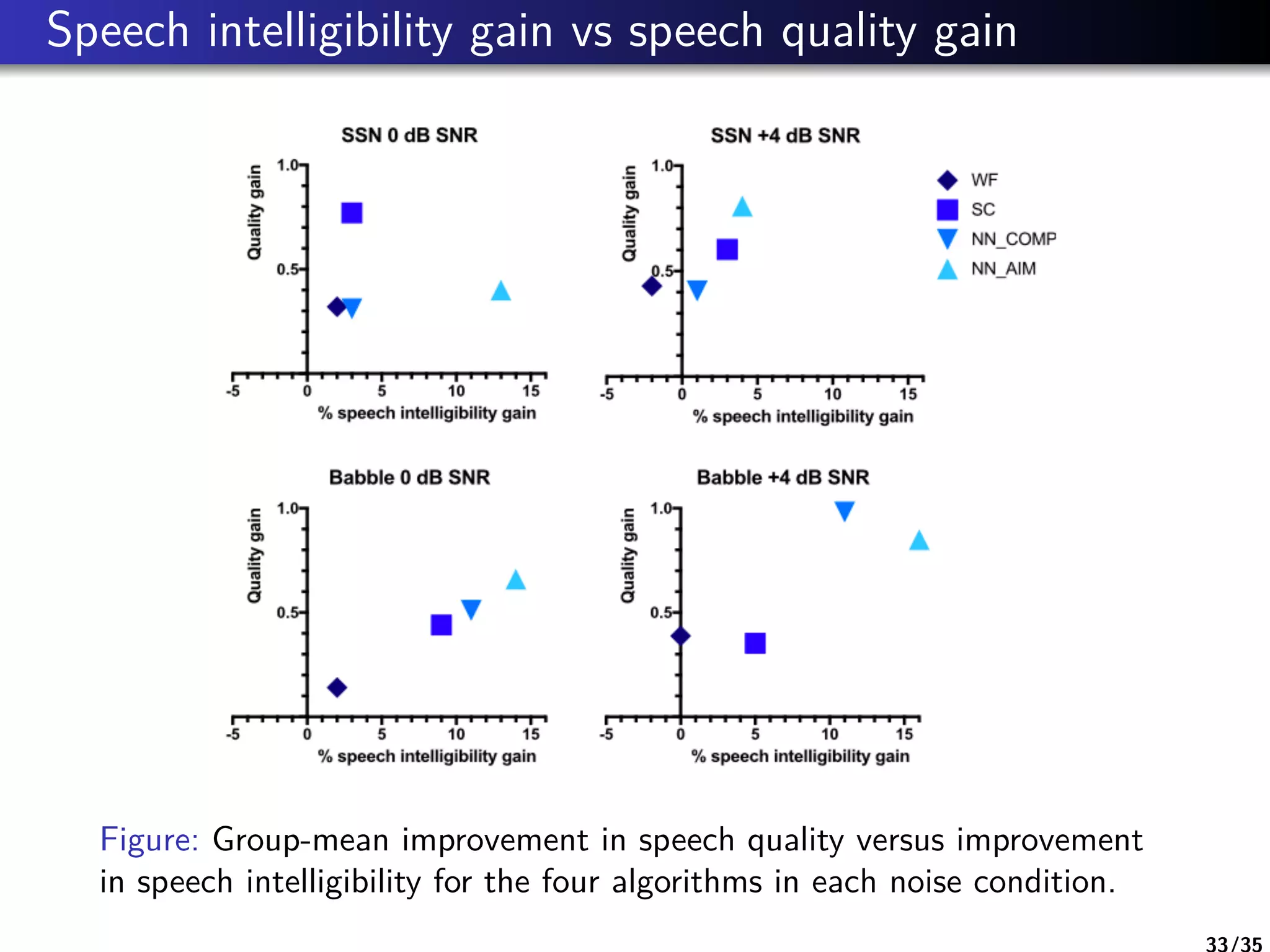
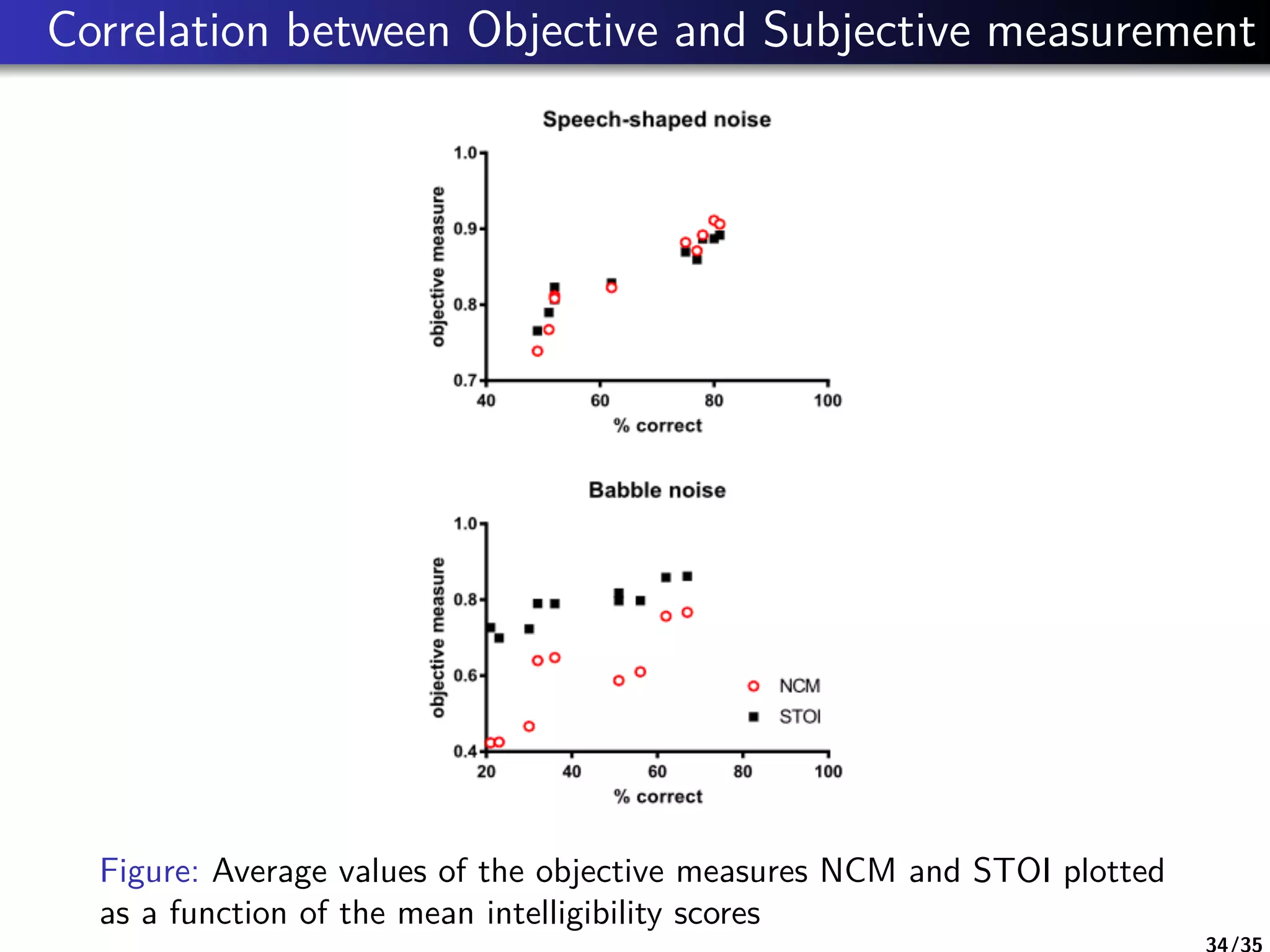


The document is a literature review on methods for improving speech intelligibility in noisy environments, discussing both traditional and machine learning techniques. It highlights approaches like power spectrum subtraction, Wiener filtering, ideal binary masking, and sparse coding, as well as deep neural networks (DNNs) for speech enhancement. The findings indicate that machine learning algorithms, particularly DNNs utilizing auditory features, generally yield better performance in enhancing speech intelligibility compared to traditional techniques.





![129966864160453838[1]](https://cdn.slidesharecdn.com/ss_thumbnails/1299668641604538381-130806105228-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)



























































