삶
.
.
.
.
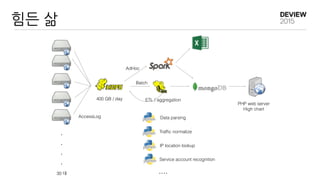
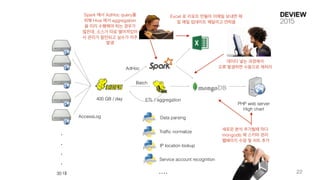
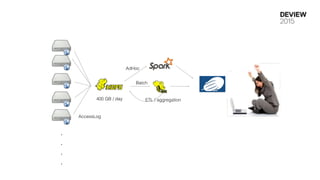
30 대
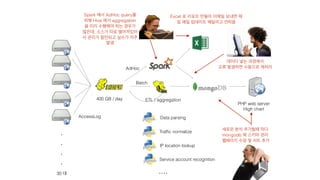
400 GB/ day ETL / aggregation
PHP web server
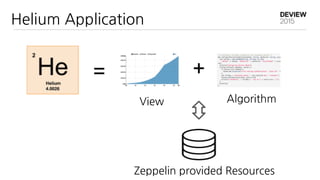
High chart
Data parsing
Traffic normalize
IP location lookup
Service account recognition
AccessLog
....
AdHoc
Batch
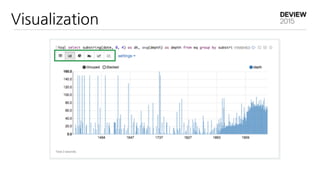
23.
.
.
.
.
30 대
400 GB/ day ETL / aggregation
PHP web server
High chart
Data parsing
Traffic normalize
IP location lookup
Service account recognition
AccessLog
....
AdHoc
Batch
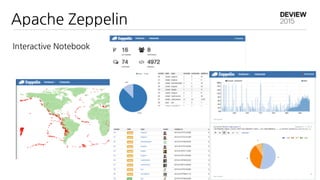
데이터 넣는 과정에서
오류 발생하면 수동으로 재처리
새로운 분석 추가될때 마다
mongodb 에 스키마 관리
웹페이지 수정 및 차트 추가
Spark 에서 AdHoc query를
위해 Hive 에서 aggregation
을 미리 수행해야 하는 경우가
많은데, 소스가 따로 떨어져있어
서 관리가 잘안되고 실수가 자주
발생
Excel 로 리포트 만들어 이메일 보내면 매
일 매일 업데이트 해달라고 연락옴


























![[121]네이버 효과툰 구현 이야기](https://cdn.slidesharecdn.com/ss_thumbnails/121-150914011346-lva1-app6891-thumbnail.jpg?width=640&height=640&fit=bounds)
![[211]대규모 시스템 시각화 현동석김광림](https://cdn.slidesharecdn.com/ss_thumbnails/211-161025004529-thumbnail.jpg?width=640&height=640&fit=bounds)
![[224]nsml 상상하는 모든 것이 이루어지는 클라우드 머신러닝 플랫폼](https://cdn.slidesharecdn.com/ss_thumbnails/224nsml-171017024133-thumbnail.jpg?width=640&height=640&fit=bounds)

![[233]멀티테넌트하둡클러스터 남경완](https://cdn.slidesharecdn.com/ss_thumbnails/233-161025011544-thumbnail.jpg?width=640&height=640&fit=bounds)
![[215]네이버콘텐츠통계서비스소개 김기영](https://cdn.slidesharecdn.com/ss_thumbnails/215-161025030904-thumbnail.jpg?width=640&height=640&fit=bounds)

![[236] 카카오의데이터파이프라인 윤도영](https://cdn.slidesharecdn.com/ss_thumbnails/236-161025031702-thumbnail.jpg?width=640&height=640&fit=bounds)
![[243]kaleido 노현걸](https://cdn.slidesharecdn.com/ss_thumbnails/243kaleido-161025011559-thumbnail.jpg?width=640&height=640&fit=bounds)
![[244] 분산 환경에서 스트림과 배치 처리 통합 모델](https://cdn.slidesharecdn.com/ss_thumbnails/244-150915025618-lva1-app6891-thumbnail.jpg?width=640&height=640&fit=bounds)
![[252] 증분 처리 플랫폼 cana 개발기](https://cdn.slidesharecdn.com/ss_thumbnails/225cana-150915052201-lva1-app6892-thumbnail.jpg?width=640&height=640&fit=bounds)
![[D2 COMMUNITY] Open Container Seoul Meetup - 마이크로 서비스 아키텍쳐와 Docker kubernetes](https://cdn.slidesharecdn.com/ss_thumbnails/dockerkubernetes-161207045638-thumbnail.jpg?width=640&height=640&fit=bounds)
![[231]운영체제 수준에서의 데이터베이스 성능 분석과 최적화](https://cdn.slidesharecdn.com/ss_thumbnails/231-171017003147-thumbnail.jpg?width=640&height=640&fit=bounds)

![[231]나는서버를썰터이니너는개발만하여라 양지욱](https://cdn.slidesharecdn.com/ss_thumbnails/231-161025004555-thumbnail.jpg?width=640&height=640&fit=bounds)
![[135] 오픈소스 데이터베이스, 은행 서비스에 첫발을 내밀다.](https://cdn.slidesharecdn.com/ss_thumbnails/35-171016061446-thumbnail.jpg?width=640&height=640&fit=bounds)




![[1A7]Ansible의이해와활용](https://cdn.slidesharecdn.com/ss_thumbnails/1a7ansible-140928232208-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)
![[NDC18] 만들고 붓고 부수고 - 〈야생의 땅: 듀랑고〉 서버 관리 배포 이야기](https://cdn.slidesharecdn.com/ss_thumbnails/ndc18-180429152609-thumbnail.jpg?width=640&height=640&fit=bounds)
![[OpenInfra Days Korea 2018] Day 2 - E5: Mesos to Kubernetes, Cloud Native 서비스...](https://cdn.slidesharecdn.com/ss_thumbnails/e60930openinfraday2018dennis-180705030830-thumbnail.jpg?width=640&height=640&fit=bounds)
![[NDC18] 야생의 땅 듀랑고의 데이터 엔지니어링 이야기: 로그 시스템 구축 경험 공유 (2부)](https://cdn.slidesharecdn.com/ss_thumbnails/ndc2018-2-180430180517-thumbnail.jpg?width=640&height=640&fit=bounds)




![[211] 네이버 검색과 데이터마이닝](https://cdn.slidesharecdn.com/ss_thumbnails/211-150915001301-lva1-app6891-thumbnail.jpg?width=640&height=640&fit=bounds)
![[212] large scale backend service develpment](https://cdn.slidesharecdn.com/ss_thumbnails/221largescalebackendservicedevelpment-150915001346-lva1-app6892-thumbnail.jpg?width=640&height=640&fit=bounds)
![[222]대화 시스템 서비스 동향 및 개발 방법](https://cdn.slidesharecdn.com/ss_thumbnails/222-150915011307-lva1-app6892-thumbnail.jpg?width=640&height=640&fit=bounds)
![[213] ethereum](https://cdn.slidesharecdn.com/ss_thumbnails/231ethereum-150915024025-lva1-app6891-thumbnail.jpg?width=640&height=640&fit=bounds)
![[264] large scale deep-learning_on_spark](https://cdn.slidesharecdn.com/ss_thumbnails/246large-scaledeeplearningonspark-150915055051-lva1-app6891-thumbnail.jpg?width=640&height=640&fit=bounds)
![[221] docker orchestration](https://cdn.slidesharecdn.com/ss_thumbnails/212dockerorchestration-150915010646-lva1-app6891-thumbnail.jpg?width=640&height=640&fit=bounds)
![[223] h base consistent secondary indexing](https://cdn.slidesharecdn.com/ss_thumbnails/232hbaseconsistentsecondaryindexing-150915010743-lva1-app6891-thumbnail.jpg?width=640&height=640&fit=bounds)
![[231] the simplicity of cluster apps with circuit](https://cdn.slidesharecdn.com/ss_thumbnails/213thesimplicityofclusterappswithcircuit-150915022150-lva1-app6892-thumbnail.jpg?width=640&height=640&fit=bounds)
![[232] 수퍼컴퓨팅과 데이터 어낼리틱스](https://cdn.slidesharecdn.com/ss_thumbnails/223-150915022242-lva1-app6891-thumbnail.jpg?width=640&height=640&fit=bounds)
![[234] 산업 현장을 위한 증강 현실 기기 daqri helmet 개발기](https://cdn.slidesharecdn.com/ss_thumbnails/243daqrihelmet-150915022636-lva1-app6891-thumbnail.jpg?width=640&height=640&fit=bounds)
![[224] 번역 모델 기반_질의_교정_시스템](https://cdn.slidesharecdn.com/ss_thumbnails/242-150915010843-lva1-app6892-thumbnail.jpg?width=640&height=640&fit=bounds)
![[263] s2graph large-scale-graph-database-with-hbase-2](https://cdn.slidesharecdn.com/ss_thumbnails/236s2graph-large-scale-graph-database-with-hbase-2-150915055019-lva1-app6892-thumbnail.jpg?width=640&height=640&fit=bounds)
![[243] turning data into value](https://cdn.slidesharecdn.com/ss_thumbnails/234turningdataintovalue-150915052705-lva1-app6891-thumbnail.jpg?width=640&height=640&fit=bounds)
![[253] apache ni fi](https://cdn.slidesharecdn.com/ss_thumbnails/235apachenifi-150915053924-lva1-app6892-thumbnail.jpg?width=640&height=640&fit=bounds)
![[242] wifi를 이용한 실내 장소 인식하기](https://cdn.slidesharecdn.com/ss_thumbnails/224wifi-150915025827-lva1-app6892-thumbnail.jpg?width=640&height=640&fit=bounds)
![[233] level 2 network programming using packet ngin rtos](https://cdn.slidesharecdn.com/ss_thumbnails/233level2networkprogrammingusingpacketnginrtos-150915022357-lva1-app6891-thumbnail.jpg?width=640&height=640&fit=bounds)
![[262] netflix 빅데이터 플랫폼](https://cdn.slidesharecdn.com/ss_thumbnails/226netflix-150915054913-lva1-app6892-thumbnail.jpg?width=640&height=640&fit=bounds)
![[245] presto 내부구조 파헤치기](https://cdn.slidesharecdn.com/ss_thumbnails/245presto-150915054242-lva1-app6891-thumbnail.jpg?width=640&height=640&fit=bounds)
![[241] Storm과 Elasticsearch를 활용한 로깅 플랫폼의 실시간 알람 시스템 구현](https://cdn.slidesharecdn.com/ss_thumbnails/83713-150915040003-lva1-app6892-thumbnail.jpg?width=640&height=640&fit=bounds)
![[251] implementing deep learning using cu dnn](https://cdn.slidesharecdn.com/ss_thumbnails/215implementingdeeplearningusingcudnn-150915052020-lva1-app6892-thumbnail.jpg?width=640&height=640&fit=bounds)


















![[AWSKRUG] 데이터 얼마까지 알아보셨어요?](https://cdn.slidesharecdn.com/ss_thumbnails/aa-190614060527-thumbnail.jpg?width=640&height=640&fit=bounds)

![[211] 인공지능이 인공지능 챗봇을 만든다](https://cdn.slidesharecdn.com/ss_thumbnails/211chatbot-181106094835-thumbnail.jpg?width=640&height=640&fit=bounds)
![[233] 대형 컨테이너 클러스터에서의 고가용성 Network Load Balancing: Maglev Hashing Scheduler i...](https://cdn.slidesharecdn.com/ss_thumbnails/233networkloadbalancing-181018151852-thumbnail.jpg?width=640&height=640&fit=bounds)
![[215] Druid로 쉽고 빠르게 데이터 분석하기](https://cdn.slidesharecdn.com/ss_thumbnails/215druid-181012071910-thumbnail.jpg?width=640&height=640&fit=bounds)
![[245]Papago Internals: 모델분석과 응용기술 개발](https://cdn.slidesharecdn.com/ss_thumbnails/245papagointernals1-181012045005-thumbnail.jpg?width=640&height=640&fit=bounds)
![[236] 스트림 저장소 최적화 이야기: 아파치 드루이드로부터 얻은 교훈](https://cdn.slidesharecdn.com/ss_thumbnails/236deview2018jihoonson-final-181012031726-thumbnail.jpg?width=640&height=640&fit=bounds)
![[235]Wikipedia-scale Q&A](https://cdn.slidesharecdn.com/ss_thumbnails/235deview2018julienperezwikipediaqa12oct2018-181012030613-thumbnail.jpg?width=640&height=640&fit=bounds)
![[244]로봇이 현실 세계에 대해 학습하도록 만들기](https://cdn.slidesharecdn.com/ss_thumbnails/244deview2018tomisilanderrobotsrealworldfinal11oct2018-181012024720-thumbnail.jpg?width=640&height=640&fit=bounds)
![[243] Deep Learning to help student’s Deep Learning](https://cdn.slidesharecdn.com/ss_thumbnails/243deeplearningtohelpstudentsdeeplearning-181012024530-thumbnail.jpg?width=640&height=640&fit=bounds)
![[234]Fast & Accurate Data Annotation Pipeline for AI applications](https://cdn.slidesharecdn.com/ss_thumbnails/234fastaccuratedataannotationpipelineforaiapplications1-181012024230-thumbnail.jpg?width=640&height=640&fit=bounds)
![Old version: [233]대형 컨테이너 클러스터에서의 고가용성 Network Load Balancing](https://cdn.slidesharecdn.com/ss_thumbnails/233largecontainerclusternetworkloadbalancing-181012024225-thumbnail.jpg?width=640&height=640&fit=bounds)
![[226]NAVER 광고 deep click prediction: 모델링부터 서빙까지](https://cdn.slidesharecdn.com/ss_thumbnails/226naveraddeepclickprediction-181012024116-thumbnail.jpg?width=640&height=640&fit=bounds)
![[225]NSML: 머신러닝 플랫폼 서비스하기 & 모델 튜닝 자동화하기](https://cdn.slidesharecdn.com/ss_thumbnails/225nsmlmachinelearningntuningautomize-181012023407-thumbnail.jpg?width=640&height=640&fit=bounds)
![[224]네이버 검색과 개인화](https://cdn.slidesharecdn.com/ss_thumbnails/224naversearchnpersonalizationfinal-181012022631-thumbnail.jpg?width=640&height=640&fit=bounds)
![[216]Search Reliability Engineering (부제: 지진에도 흔들리지 않는 네이버 검색시스템)](https://cdn.slidesharecdn.com/ss_thumbnails/216sresearchreliabilityengineering-181012022623-thumbnail.jpg?width=640&height=640&fit=bounds)
![[214] Ai Serving Platform: 하루 수 억 건의 인퍼런스를 처리하기 위한 고군분투기](https://cdn.slidesharecdn.com/ss_thumbnails/214aiservingplatforminference-181012022603-thumbnail.jpg?width=640&height=640&fit=bounds)
![[213] Fashion Visual Search](https://cdn.slidesharecdn.com/ss_thumbnails/213fashionvisualsearchreduced-181012022540-thumbnail.jpg?width=640&height=640&fit=bounds)
![[232] TensorRT를 활용한 딥러닝 Inference 최적화](https://cdn.slidesharecdn.com/ss_thumbnails/232dlinferenceoptimizationusingtensorrt1-181012014455-thumbnail.jpg?width=640&height=640&fit=bounds)
![[242]컴퓨터 비전을 이용한 실내 지도 자동 업데이트 방법: 딥러닝을 통한 POI 변화 탐지](https://cdn.slidesharecdn.com/ss_thumbnails/242pcdpublic-181012011734-thumbnail.jpg?width=640&height=640&fit=bounds)
![[212]C3, 데이터 처리에서 서빙까지 가능한 하둡 클러스터](https://cdn.slidesharecdn.com/ss_thumbnails/212c3-181012011644-thumbnail.jpg?width=640&height=640&fit=bounds)
![[223]기계독해 QA: 검색인가, NLP인가?](https://cdn.slidesharecdn.com/ss_thumbnails/2232018-181012010149-thumbnail.jpg?width=640&height=640&fit=bounds)