Download free for 30 days
Sign in
Upload
Language (EN)
Support
Business
Mobile
Social Media
Marketing
Technology
Art & Photos
Career
Design
Education
Presentations & Public Speaking
Government & Nonprofit
Healthcare
Internet
Law
Leadership & Management
Automotive
Engineering
Software
Recruiting & HR
Retail
Sales
Services
Science
Small Business & Entrepreneurship
Food
Environment
Economy & Finance
Data & Analytics
Investor Relations
Sports
Spiritual
News & Politics
Travel
Self Improvement
Real Estate
Entertainment & Humor
Health & Medicine
Devices & Hardware
Lifestyle
Change Language
Language
English
Español
Português
Français
Deutsche
Cancel
Save
EN
Uploaded by
Syota Yano
165 views
20190628 cognitive serviceshandson
2019/06/28 KIS オープンセミナー Cognitive Servicesのハンズオンの資料です。 ※新入社員を対象とした初めて触る人向けの内容です。
Technology
◦
Read more
0
Save
Share
Embed
Embed presentation
1
/ 159
2
/ 159
3
/ 159
4
/ 159
5
/ 159
6
/ 159
7
/ 159
8
/ 159
9
/ 159
10
/ 159
11
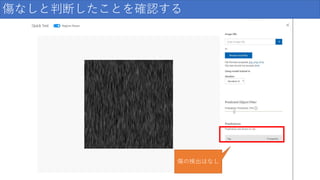
/ 159
12
/ 159
13
/ 159
14
/ 159
15
/ 159
16
/ 159
17
/ 159
18
/ 159
19
/ 159
20
/ 159
21
/ 159
22
/ 159
23
/ 159
24
/ 159
25
/ 159
26
/ 159
27
/ 159
28
/ 159
29
/ 159
30
/ 159
31
/ 159
32
/ 159
33
/ 159
34
/ 159
35
/ 159
36
/ 159
37
/ 159
38
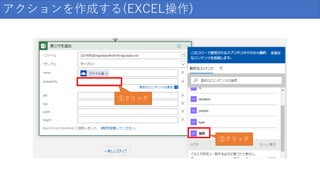
/ 159
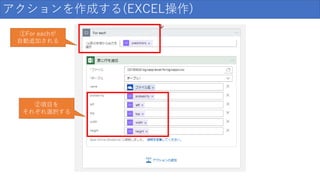
39
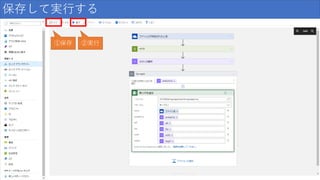
/ 159
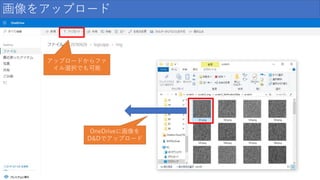
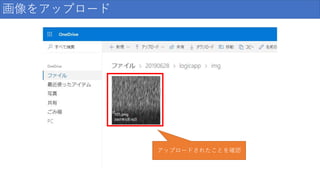
40
/ 159
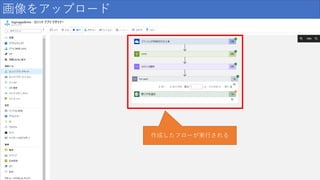
41
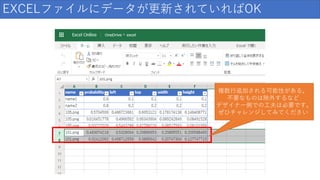
/ 159
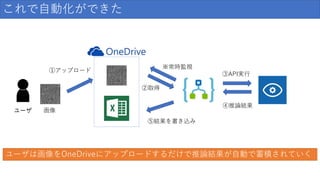
42
/ 159
43
/ 159
44
/ 159
45
/ 159
46
/ 159
47
/ 159
48
/ 159
49
/ 159
50
/ 159
51
/ 159
52
/ 159
53
/ 159
54
/ 159
55
/ 159
56
/ 159
57
/ 159
58
/ 159
59
/ 159
60
/ 159
61
/ 159
62
/ 159
63
/ 159
64
/ 159
65
/ 159
66
/ 159
67
/ 159
68
/ 159
69
/ 159
70
/ 159
71
/ 159
72
/ 159
73
/ 159
74
/ 159
75
/ 159
76
/ 159
77
/ 159
78
/ 159
79
/ 159
80
/ 159
81
/ 159
82
/ 159
83
/ 159
84
/ 159
85
/ 159
86
/ 159
87
/ 159
88
/ 159
89
/ 159
90
/ 159
91
/ 159
92
/ 159
93
/ 159
94
/ 159
95
/ 159
96
/ 159
97
/ 159
98
/ 159
99
/ 159
100
/ 159
101
/ 159
102
/ 159
103
/ 159
104
/ 159
105
/ 159
106
/ 159
107
/ 159
108
/ 159
109
/ 159
110
/ 159
111
/ 159
112
/ 159
113
/ 159
114
/ 159
115
/ 159
116
/ 159
117
/ 159
118
/ 159
119
/ 159
120
/ 159
121
/ 159
122
/ 159
123
/ 159
124
/ 159
125
/ 159
126
/ 159
127
/ 159
128
/ 159
129
/ 159
130
/ 159
131
/ 159
132
/ 159
133
/ 159
134
/ 159
135
/ 159
136
/ 159
137
/ 159
138
/ 159
139
/ 159
140
/ 159
141
/ 159
142
/ 159
143
/ 159
144
/ 159
145
/ 159
146
/ 159
147
/ 159
148
/ 159
149
/ 159
150
/ 159
151
/ 159
152
/ 159
153
/ 159
154
/ 159
155
/ 159
156
/ 159
157
/ 159
158
/ 159
159
/ 159
More Related Content
PDF
Inside of 聖徳玉子 by O2
by
mganeko
PDF
JAZUG女子部 第2回勉強会 ハンズオン
by
Kana SUZUKI
PDF
Custom Vision APIの下準備
by
Keiji Kamebuchi
PDF
Custom Visionを活用するためのTips
by
Yoshitaka Seo
PPTX
20190319 KIS Open Seminar LT
by
Syota Yano
PDF
Custom visionのすゝめ
by
ru pic
PPTX
使ってみよう!Cognitive Services Container_20190122
by
Ayako Omori
PDF
Build 2017 更新情報 Cognitive Services 編
by
Atsushi Yokohama (BEACHSIDE)
Inside of 聖徳玉子 by O2
by
mganeko
JAZUG女子部 第2回勉強会 ハンズオン
by
Kana SUZUKI
Custom Vision APIの下準備
by
Keiji Kamebuchi
Custom Visionを活用するためのTips
by
Yoshitaka Seo
20190319 KIS Open Seminar LT
by
Syota Yano
Custom visionのすゝめ
by
ru pic
使ってみよう!Cognitive Services Container_20190122
by
Ayako Omori
Build 2017 更新情報 Cognitive Services 編
by
Atsushi Yokohama (BEACHSIDE)
Similar to 20190628 cognitive serviceshandson
PDF
DEV-020_Bot Framework & Cognitive Services ~自動応答ソリューション開発に挑戦~
by
decode2016
PDF
DBP-014_機械学習の実践ノウハウ提供します! ~AI で広がる夢を現実にする方法~
by
decode2016
PDF
Cognitve Services × Azure Kinect DK
by
ru pic
PPTX
ITコーディネーター沖縄: Microsoft 画像認識ツールハンズオン
by
Daiyu Hatakeyama
PDF
使ってみよう!”人工知能パーツ” Microsoft Cognitive Services_20180216
by
Ayako Omori
PPTX
Aiをアプリに取り込む!
by
史也 久米
PPTX
Azure Custom Vision
by
Jingun Jung
PDF
【de:code 2020】 ハンズオンで学ぶ AI ~ Bot Framework Composer + QnA Maker / Custom Visi...
by
日本マイクロソフト株式会社
PPTX
Azure Antenna AI 概要
by
Miho Yamamoto
PDF
Container x AI
by
Tsukasa Kato
PDF
20180627 - DEEP LEARNING LAB / Cognitive Services 最新情報 30 分でズバリ!
by
Takashi Okawa
PDF
Cognitive Services 最新情報 @Build 2018 を一気にチェックする50分!
by
Takashi Okawa
PDF
Azure 入門 (と言いながらちょまどの好きな Azure サービス紹介)
by
Madoka Chiyoda
PDF
ホームセンターにある画像をVision apiで分析してみた話
by
Wasaburo Miyata
PDF
Azure Cognitive Services の Vision カテゴリーまとめ(2020/3)
by
Atsushi Yokohama (BEACHSIDE)
PDF
無料の「IBM Cloud ライトアカウント」を用いた画像判定アプリハンズオン資料
by
Kohei Nishikawa
PDF
マイクロソフトの AI プラットフォーム & Cognitive Services 概要 ~ Ignite 2020 Recap
by
Ayako Omori
PDF
機械学習 (AI/ML) 勉強会 #1 基本編
by
Fujio Kojima
DEV-020_Bot Framework & Cognitive Services ~自動応答ソリューション開発に挑戦~
by
decode2016
DBP-014_機械学習の実践ノウハウ提供します! ~AI で広がる夢を現実にする方法~
by
decode2016
Cognitve Services × Azure Kinect DK
by
ru pic
ITコーディネーター沖縄: Microsoft 画像認識ツールハンズオン
by
Daiyu Hatakeyama
使ってみよう!”人工知能パーツ” Microsoft Cognitive Services_20180216
by
Ayako Omori
Aiをアプリに取り込む!
by
史也 久米
Azure Custom Vision
by
Jingun Jung
【de:code 2020】 ハンズオンで学ぶ AI ~ Bot Framework Composer + QnA Maker / Custom Visi...
by
日本マイクロソフト株式会社
Azure Antenna AI 概要
by
Miho Yamamoto
Container x AI
by
Tsukasa Kato
20180627 - DEEP LEARNING LAB / Cognitive Services 最新情報 30 分でズバリ!
by
Takashi Okawa
Cognitive Services 最新情報 @Build 2018 を一気にチェックする50分!
by
Takashi Okawa
Azure 入門 (と言いながらちょまどの好きな Azure サービス紹介)
by
Madoka Chiyoda
ホームセンターにある画像をVision apiで分析してみた話
by
Wasaburo Miyata
Azure Cognitive Services の Vision カテゴリーまとめ(2020/3)
by
Atsushi Yokohama (BEACHSIDE)
無料の「IBM Cloud ライトアカウント」を用いた画像判定アプリハンズオン資料
by
Kohei Nishikawa
マイクロソフトの AI プラットフォーム & Cognitive Services 概要 ~ Ignite 2020 Recap
by
Ayako Omori
機械学習 (AI/ML) 勉強会 #1 基本編
by
Fujio Kojima
20190628 cognitive serviceshandson
1.
Cognitive Services ハンズオン 2019/06/28 KISオープンセミナー 矢野
翔大
2.
•CustomVision • 画像分類 • 食べ物画像の分類 •
物体検出 • 傷の検出 •【おまけ1】Custom Vision + Logic Apps •【おまけ2】 • Custom Visionでアナログメータ読み取りの紹介 • MSLearnの紹介 アジェンダ
3.
難しいことはよくわかんないけど 私でもAI作れるじゃん 本日のゴール
4.
Custom Visionで画像分類 まずは食べ物の画像を分類してみましょう
5.
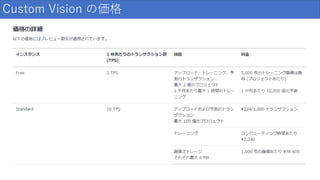
Custom Vision の価格
6.
操作をミスったら 高額課金が発生するポイントが2か所あるので そこだけ注意が必要です 注意点・・・
7.
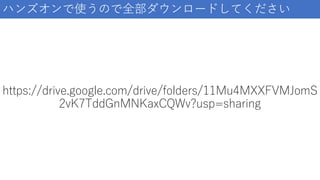
https://drive.google.com/drive/folders/11Mu4MXXFVMJomS 2vK7TddGnMNKaxCQWv?usp=sharing ハンズオンで使うので全部ダウンロードしてください
8.
Azureポータルへアクセス https://azure.microsoft.com/ja-jp/features/azure-portal/ クリック
9.
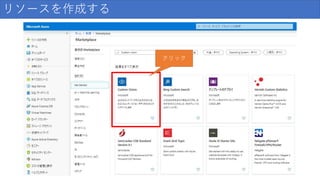
リソースを作成する ②検索
10.
リソースを作成する クリック
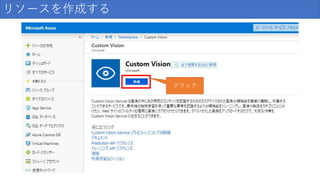
11.
リソースを作成する クリック
12.
必要な項目を入力する 項目 値 名前 適当に サブスクリプション
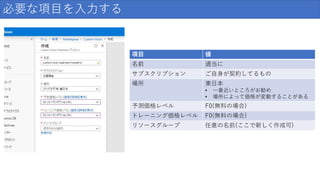
ご自身が契約してるもの 場所 東日本 • 一番近いところがお勧め • 場所によって価格が変動することがある 予測価格レベル F0(無料の場合) トレーニング価格レベル F0(無料の場合) リソースグループ 任意の名前(ここで新しく作成可)
13.
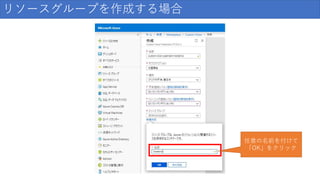
リソースグループを作成する場合 任意の名前を付けて 「OK」をクリック
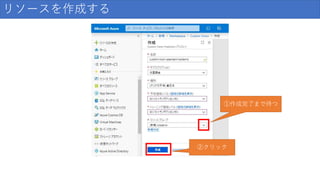
14.
リソースを作成する ②クリック ①作成完了まで待つ
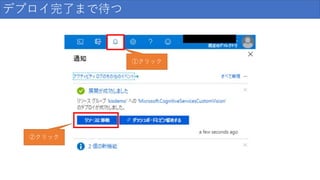
15.
デプロイ完了まで待つ ①クリック ②クリック
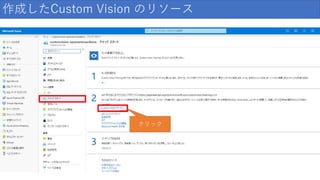
16.
作成したCustom Vision のリソース クリック
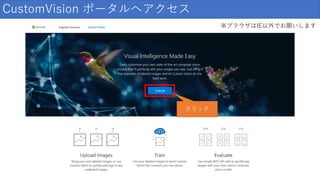
17.
CustomVision ポータルへアクセス クリック ※ブラウザはIE以外でお願いします
18.
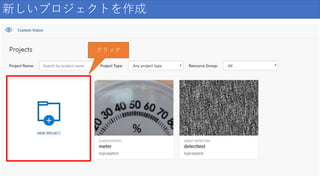
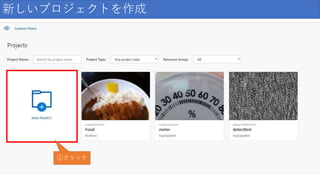
新しいプロジェクトを作成 クリック
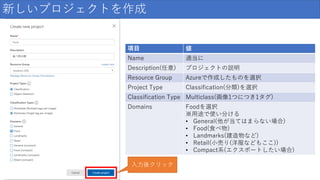
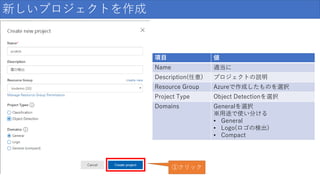
19.
新しいプロジェクトを作成 項目 値 Name 適当に Description(任意)
プロジェクトの説明 Resource Group Azureで作成したものを選択 Project Type Classification(分類)を選択 Classification Type Multiclass(画像1つにつき1タグ) Domains Foodを選択 ※用途で使い分ける • General(他が当てはまらない場合) • Food(食べ物) • Landmarks(建造物など) • Retail(小売り(洋服などもここ)) • Compact系(エクスポートしたい場合) 入力後クリック
20.
今回使用する画像セット https://www.vision.ee.ethz.ch/datasets_extra/food-101/ スイスのチューリッヒ工科大学の コンピュータビジョン研究チームが公開しているものです。 クラス分けのタグ情報が付加された食べ物の画像です。 約5GBの一括ダウンロードです。容量に注意してください。 今回はこの中から一部を抽出して使用します。
21.
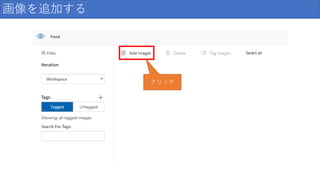
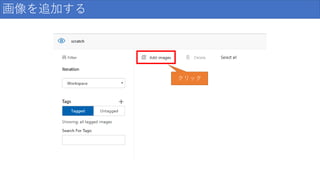
画像を追加する クリック
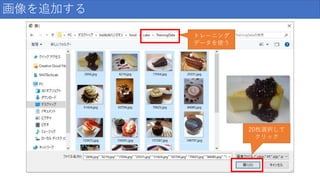
22.
画像を追加する トレーニング データを使う 20枚選択して クリック
23.
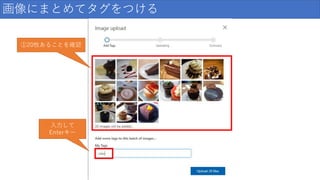
画像にまとめてタグをつける ①20枚あることを確認 入力して Enterキー
24.
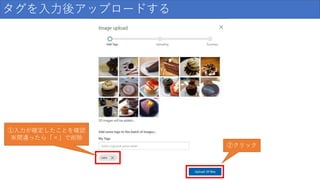
タグを入力後アップロードする ②クリック ①入力が確定したことを確認 ※間違ったら「×」で削除
25.
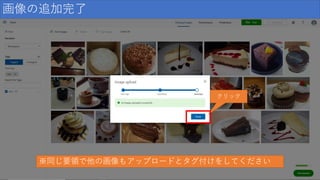
画像の追加完了 クリック ※同じ要領で他の画像もアップロードとタグ付けをしてください
26.
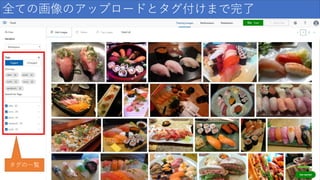
全ての画像のアップロードとタグ付けまで完了 タグの一覧
27.
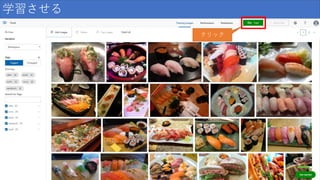
学習させる クリック
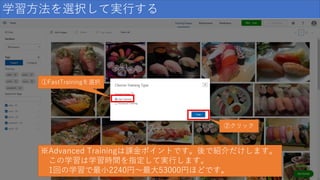
28.
学習方法を選択して実行する ②クリック ※Advanced Trainingは課金ポイントです。後で紹介だけします。 この学習は学習時間を指定して実行します。 1回の学習で最小2240円~最大53000円ほどです。 ①FastTrainingを選択
29.
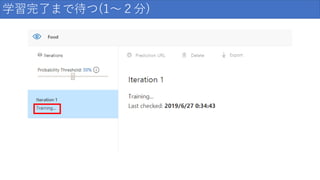
学習完了まで待つ(1~2分)
30.
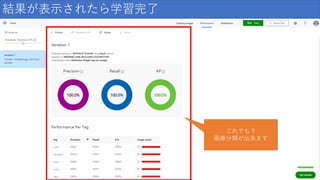
結果が表示されたら学習完了 これでもう 画像分類が出来ます
31.
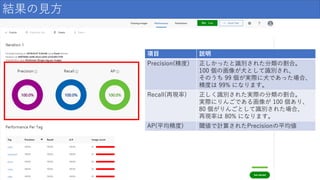
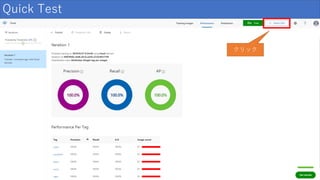
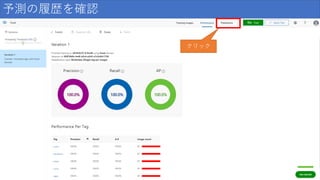
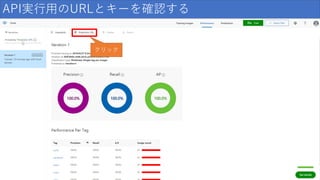
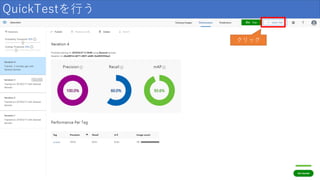
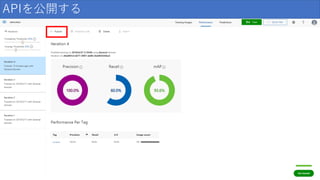
結果の見方 項目 説明 Precision(精度) 正しかったと識別された分類の割合。 100
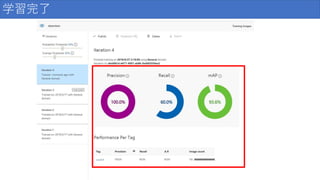
個の画像が犬として識別され、 そのうち 99 個が実際に犬であった場合、 精度は 99% になります。 Recall(再現率) 正しく識別された実際の分類の割合。 実際にりんごである画像が 100 個あり、 80 個がりんごとして識別された場合、 再現率は 80% になります。 AP(平均精度) 閾値で計算されたPrecisionの平均値
32.
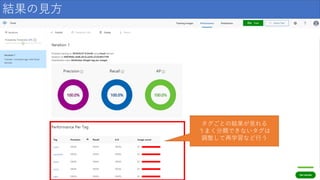
結果の見方 タグごとの結果が見れる うまく分類できないタグは 調整して再学習など行う
33.
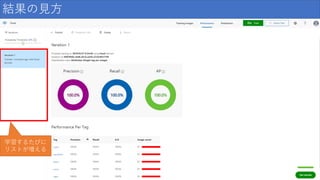
結果の見方 学習するたびに リストが増える
34.
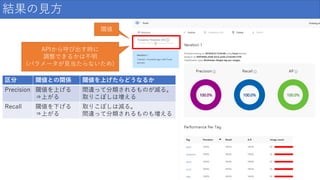
結果の見方 閾値 区分 閾値との関係 閾値を上げたらどうなるか Precision
閾値を上げる ⇒上がる 間違って分類されるものが減る。 取りこぼしは増える Recall 閾値を下げる ⇒上がる 取りこぼしは減る。 間違って分類されるものも増える APIから呼び出す時に 調整できるかは不明 (パラメータが見当たらないため)
35.
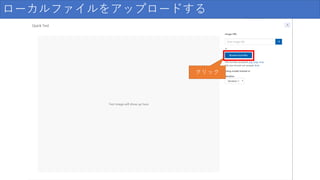
Quick Test クリック
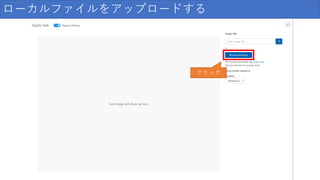
36.
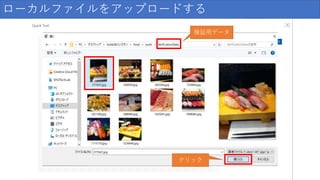
ローカルファイルをアップロードする クリック
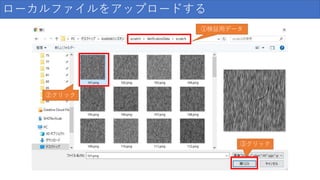
37.
ローカルファイルをアップロードする 検証用データ クリック
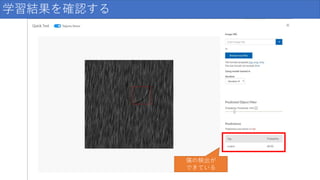
38.
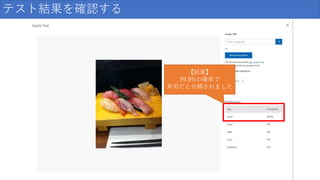
テスト結果を確認する 【結果】 99.9%の確率で 寿司だと分類されました
39.
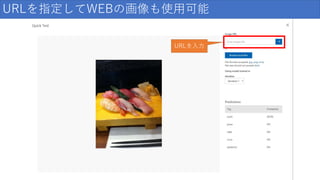
URLを指定してWEBの画像も使用可能 URLを入力
40.
予測の履歴を確認 クリック
41.
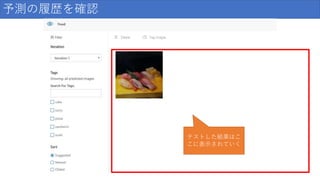
予測の履歴を確認 テストした結果はこ こに表示されていく
42.
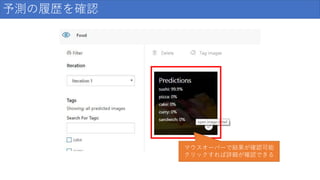
予測の履歴を確認 マウスオーバーで結果が確認可能 クリックすれば詳細が確認できる
43.
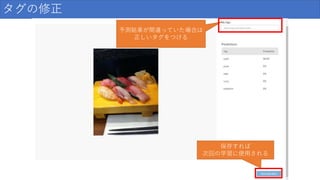
タグの修正 予測結果が間違っていた場合は 正しいタグをつける 保存すれば 次回の学習に使用される
44.
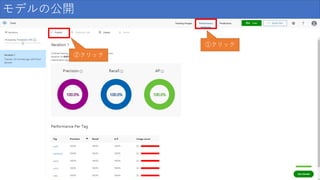
モデルの公開 ①クリック ②クリック
45.
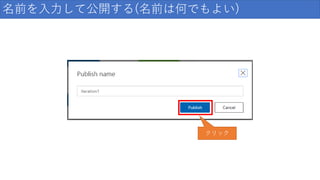
名前を入力して公開する(名前は何でもよい) クリック
46.
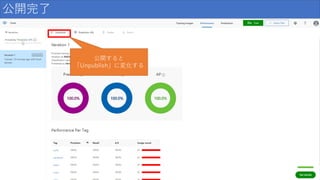
公開完了 公開すると 「Unpublish」に変化する
47.
API実行用のURLとキーを確認する クリック
48.
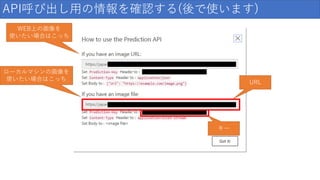
API呼び出し用の情報を確認する(後で使います) キー URL WEB上の画像を 使いたい場合はこっち ローカルマシンの画像を 使いたい場合はこっち
49.
Foodの中のHTMLをテキストエディタで開く テキストエディタで開く
50.
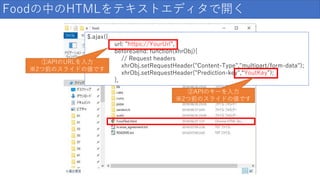
Foodの中のHTMLをテキストエディタで開く $.ajax({ url: "https://YourUrl", beforeSend: function(xhrObj){ //
Request headers xhrObj.setRequestHeader("Content-Type","multipart/form-data"); xhrObj.setRequestHeader("Prediction-key",“YoutKey"); }, ①APIのURLを入力 ※2つ前のスライドの値です ②APIのキーを入力 ※2つ前のスライドの値です
51.
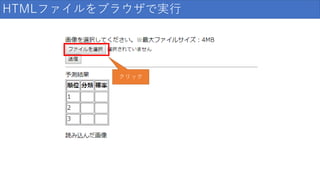
HTMLファイルをブラウザで実行 クリック
52.
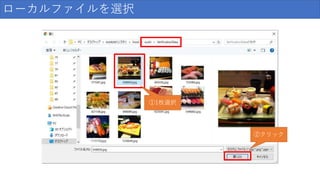
ローカルファイルを選択 ②クリック ①1枚選択
53.
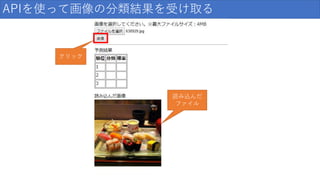
APIを使って画像の分類結果を受け取る 読み込んだ ファイル クリック
54.
これでもうAPIさえたたけば画像分類できますね 結果が表示される
55.
補足 ソースの解説
56.
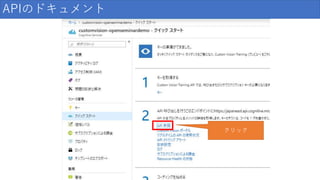
APIのドキュメント クリック
57.
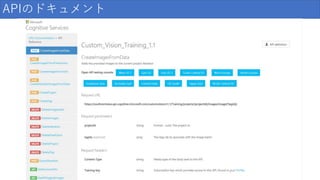
APIのドキュメント
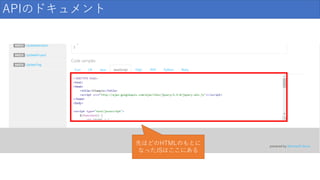
58.
APIのドキュメント 先ほどのHTMLのもとに なったJSはここにある
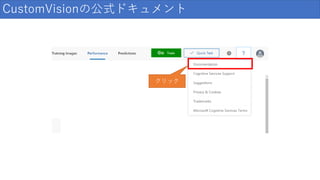
59.
CustomVisionの公式ドキュメント クリック
60.
CustomVisionの公式ドキュメント
61.
以上が画像分類です
62.
Custom Visionで物体検出 今度は少し業務よりのものとして製品の傷の検出を試します
63.
http://resources.mpi-inf.mpg.de/conferences/dagm/2007/prizes.html 使用する画像セット ドイツのシンポジウムで開催されたコンペ用のデータセットです。 工業用部品の表面の欠陥を検出するという目標で、 ・基本画像1000枚 ・人工的につけられた欠陥を含む150枚 の画像が含まれています。
64.
①クリック 新しいプロジェクトを作成
65.
新しいプロジェクトを作成 項目 値 Name 適当に Description(任意)
プロジェクトの説明 Resource Group Azureで作成したものを選択 Project Type Object Detectionを選択 Domains Generalを選択 ※用途で使い分ける • General • Logo(ロゴの検出) • Compact ①クリック
66.
画像を追加する クリック
67.
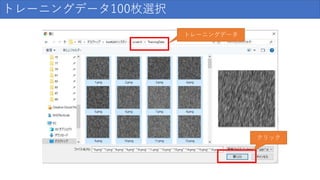
トレーニングデータ100枚選択 トレーニングデータ クリック
68.
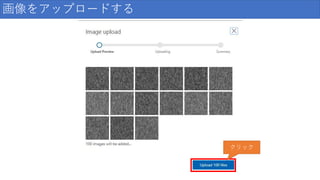
画像をアップロードする クリック
69.
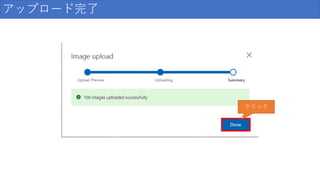
アップロード完了 クリック
70.
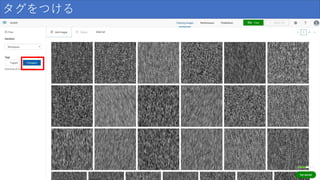
タグをつける
71.
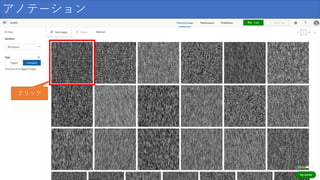
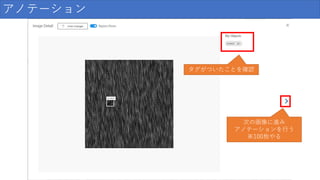
アノテーション クリック
72.
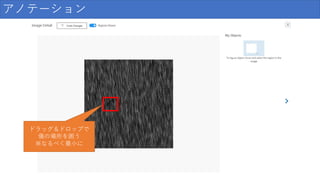
アノテーション ドラッグ&ドロップで 傷の場所を囲う ※なるべく最小に
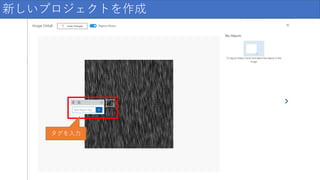
73.
新しいプロジェクトを作成 タグを入力
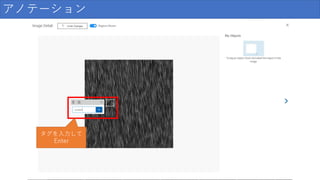
74.
アノテーション タグを入力して Enter
75.
アノテーション タグがついたことを確認 次の画像に進み アノテーションを行う ※100枚やる
76.
アノテーション完了 100枚あることを確認
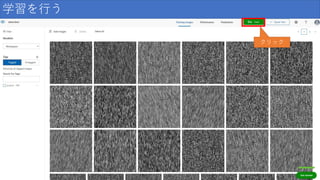
77.
学習を行う クリック
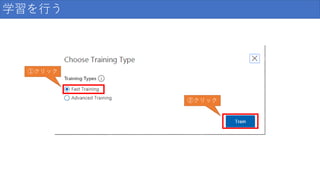
78.
学習を行う ①クリック ②クリック
79.
学習完了
80.
QuickTestを行う クリック
81.
ローカルファイルをアップロードする クリック
82.
ローカルファイルをアップロードする ③クリック ②クリック ①検証用データ
83.
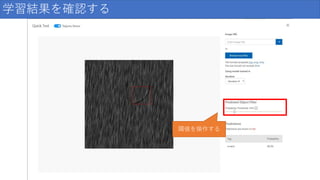
学習結果を確認する 傷の検出が できている
84.
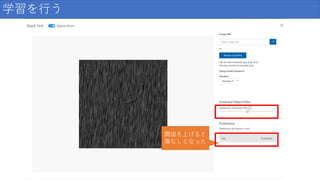
学習結果を確認する 閾値を操作する
85.
学習を行う 閾値を上げると 傷なしとなった
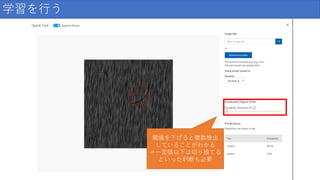
86.
学習を行う 閾値を下げると複数検出 していることがわかる ⇒一定値以下は切り捨てる といった判断も必要
87.
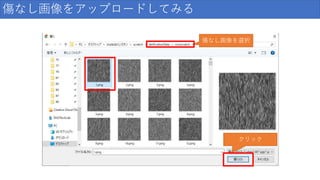
傷なし画像をアップロードしてみる 傷なし画像を選択 クリック
88.
傷なしと判断したことを確認する 傷の検出はなし
89.
APIを公開する
90.
APIを公開する クリック
91.
公開完了 クリック
92.
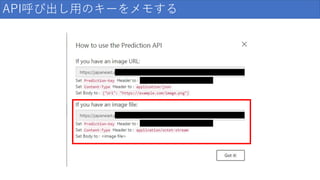
API呼び出し用のキーをメモする
93.
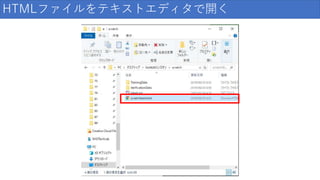
HTMLファイルをテキストエディタで開く
94.
APIキーに置き換えて保存する $.ajax({ url: "https://YourUrl", beforeSend: function(xhrObj){ //
Request headers xhrObj.setRequestHeader("Content-Type","multipart/form-data"); xhrObj.setRequestHeader("Prediction-key",“YourKey"); }, type: "POST", data: $("input[name='ufile']").prop("files")[0], processData: false, contentType: false })
95.
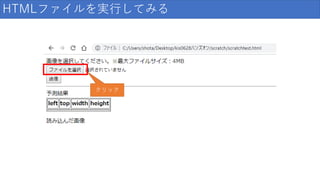
HTMLファイルを実行してみる クリック
96.
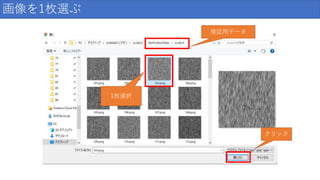
画像を1枚選ぶ 検証用データ クリック 1枚選択
97.
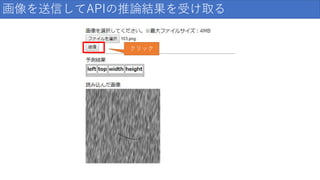
画像を送信してAPIの推論結果を受け取る クリック
98.
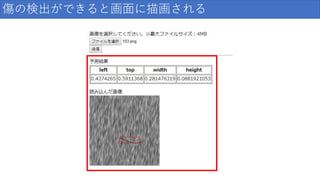
傷の検出ができると画面に描画される
99.
補足 ソースの解説
100.
以上が物体検出です
101.
難しいことは知らなくても AIは作れる
102.
【おまけ1】 Custom Vision +
Logic Apps CustomVisionを使ったノンコーディングのアプリ開発 ※万が一早く進みすぎて時間が余ったらやります
103.
【注意】 数十円程度の課金が 発生します
104.
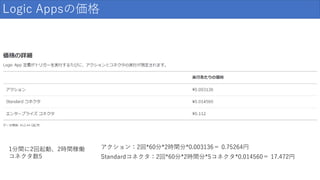
1分間に2回起動、2時間稼働 コネクタ数5 アクション:2回*60分*2時間分*0.003136= 0.75264円 Standardコネクタ:2回*60分*2時間分*5コネクタ*0.014560= 17.472円 Logic
Appsの価格
105.
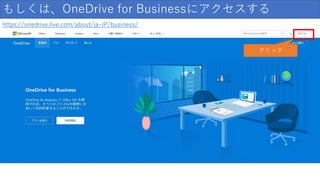
OneDriveにアクセスする https://onedrive.live.com/about/ja-jp/ クリック
106.
もしくは、OneDrive for Businessにアクセスする https://onedrive.live.com/about/ja-JP/business/ クリック
107.
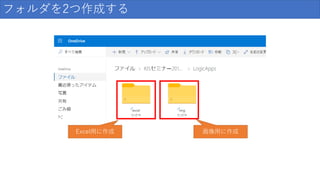
フォルダを2つ作成する Excel用に作成 画像用に作成
108.
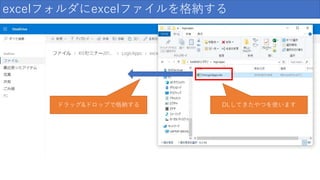
excelフォルダにexcelファイルを格納する ドラッグ&ドロップで格納する DLしてきたやつを使います
109.
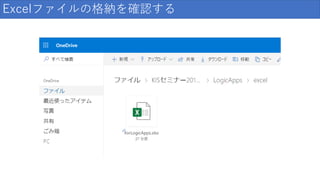
Excelファイルの格納を確認する
110.
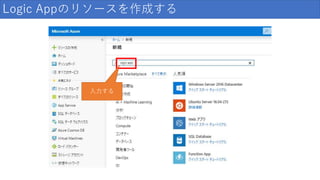
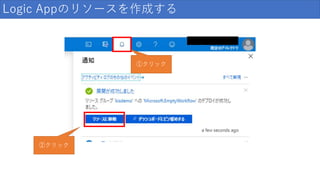
Logic Appのリソースを作成する 入力する
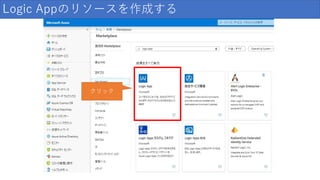
111.
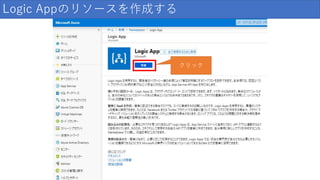
クリック Logic Appのリソースを作成する
112.
Logic Appのリソースを作成する クリック
113.
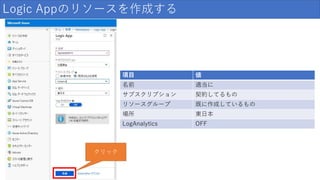
Logic Appのリソースを作成する 項目 値 名前
適当に サブスクリプション 契約してるもの リソースグループ 既に作成しているもの 場所 東日本 LogAnalytics OFF クリック
114.
Logic Appのリソースを作成する ①クリック ②クリック
115.
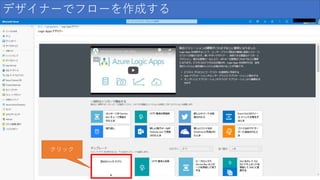
デザイナーでフローを作成する クリック
116.
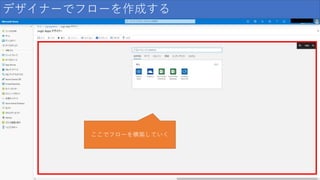
デザイナーでフローを作成する ここでフローを構築していく
117.
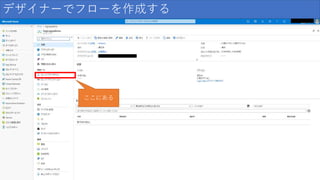
デザイナーでフローを作成する ここにある
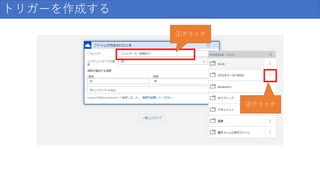
118.
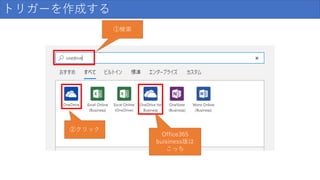
トリガーを作成する ①検索 ②クリック Office365 buisiness版は こっち
119.
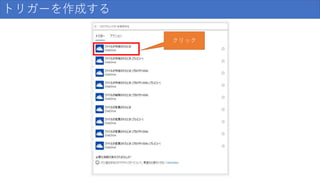
トリガーを作成する クリック
120.
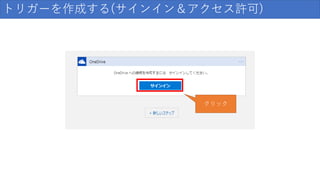
トリガーを作成する(サインイン&アクセス許可) クリック
121.
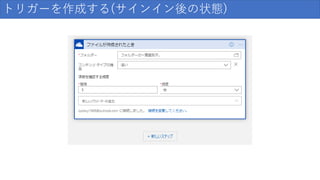
トリガーを作成する(サインイン後の状態)
122.
トリガーを作成する ①クリック ②クリック
123.
トリガーを作成する 画像フォルダを選択
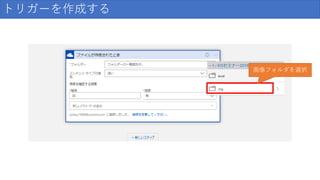
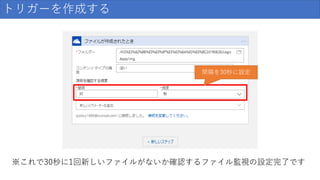
124.
トリガーを作成する 間隔を30秒に設定 ※これで30秒に1回新しいファイルがないか確認するファイル監視の設定完了です
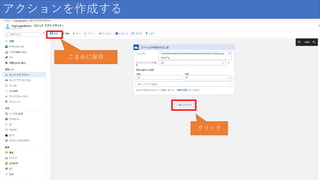
125.
アクションを作成する クリック こまめに保存
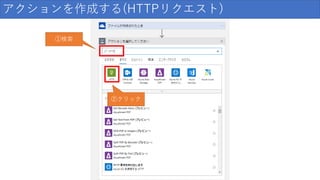
126.
アクションを作成する(HTTPリクエスト) ①検索 ②クリック
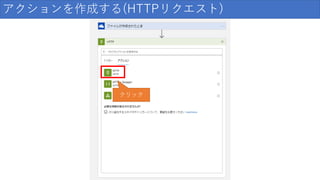
127.
アクションを作成する(HTTPリクエスト) クリック
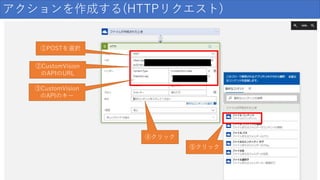
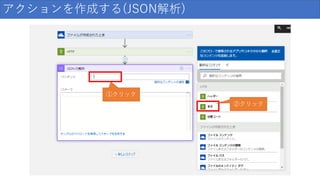
128.
アクションを作成する(HTTPリクエスト) ①POSTを選択 ②CustomVision のAPIのURL ③CustomVision のAPIのキー ④クリック ⑤クリック
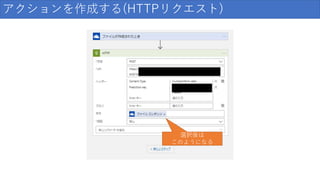
129.
アクションを作成する(HTTPリクエスト) 選択後は このようになる
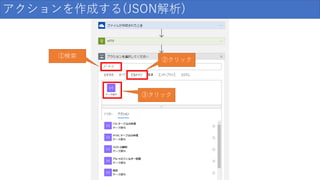
130.
アクションを作成する(JSON解析) ①検索 ②クリック ③クリック
131.
アクションを作成する(JSON解析) クリック
132.
アクションを作成する(JSON解析) ①クリック ②クリック
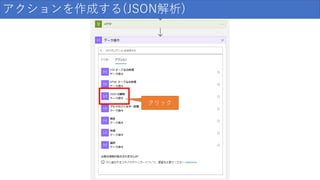
133.
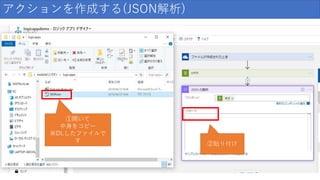
アクションを作成する(JSON解析) ①開いて 中身をコピー ※DLしたファイルで す ②貼り付け
134.
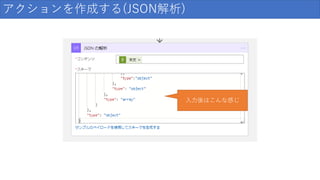
アクションを作成する(JSON解析) 入力後はこんな感じ
135.
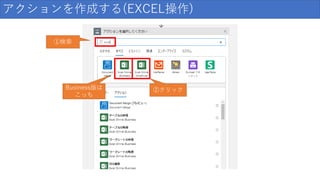
アクションを作成する(EXCEL操作) ①検索 ②クリックBusiness版は こっち
136.
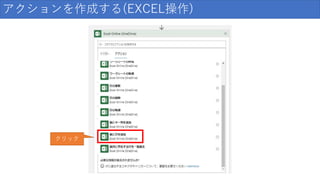
アクションを作成する(EXCEL操作) クリック
137.
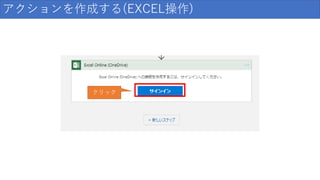
アクションを作成する(EXCEL操作) クリック
138.
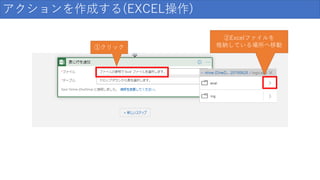
アクションを作成する(EXCEL操作) ①クリック ②Excelファイルを 格納している場所へ移動
139.
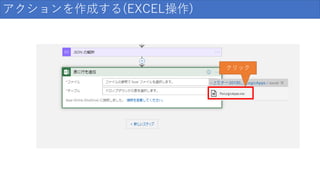
アクションを作成する(EXCEL操作) クリック
140.
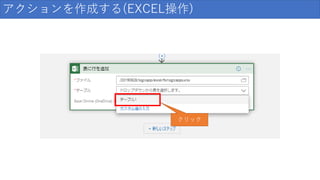
アクションを作成する(EXCEL操作) クリック
141.
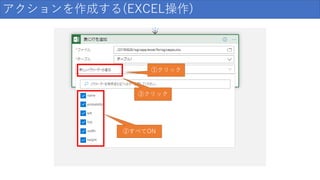
アクションを作成する(EXCEL操作) ①クリック ②すべてON ③クリック
142.
アクションを作成する(EXCEL操作) ①クリック ②クリック
143.
アクションを作成する(EXCEL操作) ①For eachが 自動追加される ②項目を それぞれ選択する
144.
保存して実行する ①保存 ②実行
145.
OneDriveに画像を D&Dでアップロード 画像をアップロード アップロードからファ イル選択でも可能
146.
画像をアップロード アップロードされたことを確認
147.
画像をアップロード 作成したフローが実行される
148.
EXCELファイルにデータが更新されていればOK 複数行追加される可能性がある。 不要なものは除外するなど デザイナー側での工夫は必要です。 ぜひチャレンジしてみてください
149.
これで自動化ができた ユーザユーザ ①アップロード ②取得 ※常時監視 ③API実行 ④推論結果 ⑤結果を書き込み ユーザは画像をOneDriveにアップロードするだけで推論結果が自動で蓄積されていく 画像
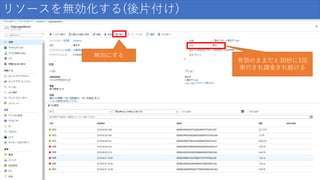
150.
リソースを無効化する(後片付け) 無効にする 有効のままだと30秒に1回 実行され課金され続ける
151.
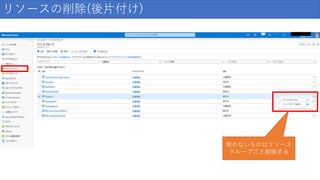
リソースの削除(後片付け) 使わないものはリソース グループごと削除する
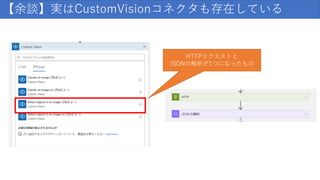
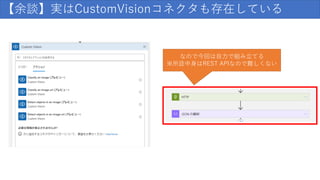
152.
【余談】実はCustomVisionコネクタも存在している HTTPリクエストと JSONの解析が1つになったもの
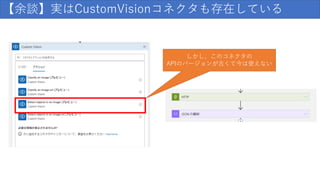
153.
【余談】実はCustomVisionコネクタも存在している しかし、このコネクタの APIのバージョンが古くて今は使えない
154.
【余談】実はCustomVisionコネクタも存在している なので今回は自力で組み立てる ※所詮中身はREST APIなので難しくない
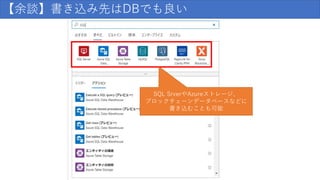
155.
【余談】書き込み先はDBでも良い SQL SrverやAzureストレージ、 ブロックチェーンデータベースなどに 書き込むことも可能
156.
【おまけ2】
157.
Custom Visionでアナログメータの読み取り https://qiita.com/t-sho/items/5e6cbb3fbb547d946bed 当初はこれをハンズオンでやる予定でしたが、 1時間くらい学習(待ち時間)が発生するのと、 無料枠を使いきるので紹介だけしておきます ※アノテーションがめんどくさいだけで 1日~2日あればできます。 アナログの湿度計を使って 1目盛り単位で画像を撮って学習させてます ※1目盛り当たり20枚の教師データ使用 (50目盛り分で1500枚) 99.8%の確率で 「湿度32%」だと推論
158.
Azureの無料の公式学習サイト https://docs.microsoft.com/ja-jp/learn/ Azureの使い方がハンズ オン形式で学べます
159.
Cognitive Services ハンズオン -おわり- お疲れさまでした











![APIキーに置き換えて保存する
$.ajax({
url: "https://YourUrl",
beforeSend: function(xhrObj){
// Request headers
xhrObj.setRequestHeader("Content-Type","multipart/form-data");
xhrObj.setRequestHeader("Prediction-key",“YourKey");
},
type: "POST",
data: $("input[name='ufile']").prop("files")[0],
processData: false,
contentType: false
})](https://image.slidesharecdn.com/20190628cognitiveserviceshandson-190701020407/85/20190628-cognitive-serviceshandson-94-320.jpg)