— 46 —
10.3Python第三方库
10.3.3 Jieba库
【例10-48】分析《淮南子原道训》文中出现频率最高的10个词语。
17 for word in excludes:
18 del (counts[word])
19 items = list(counts.items())
20 items.sort(key=lambda x: x[1], reverse=True)
21 for i in range(10):
22 word, count = items[i]
23 print('{:<10}{:>5}'.format(word, count))








![— 10 —
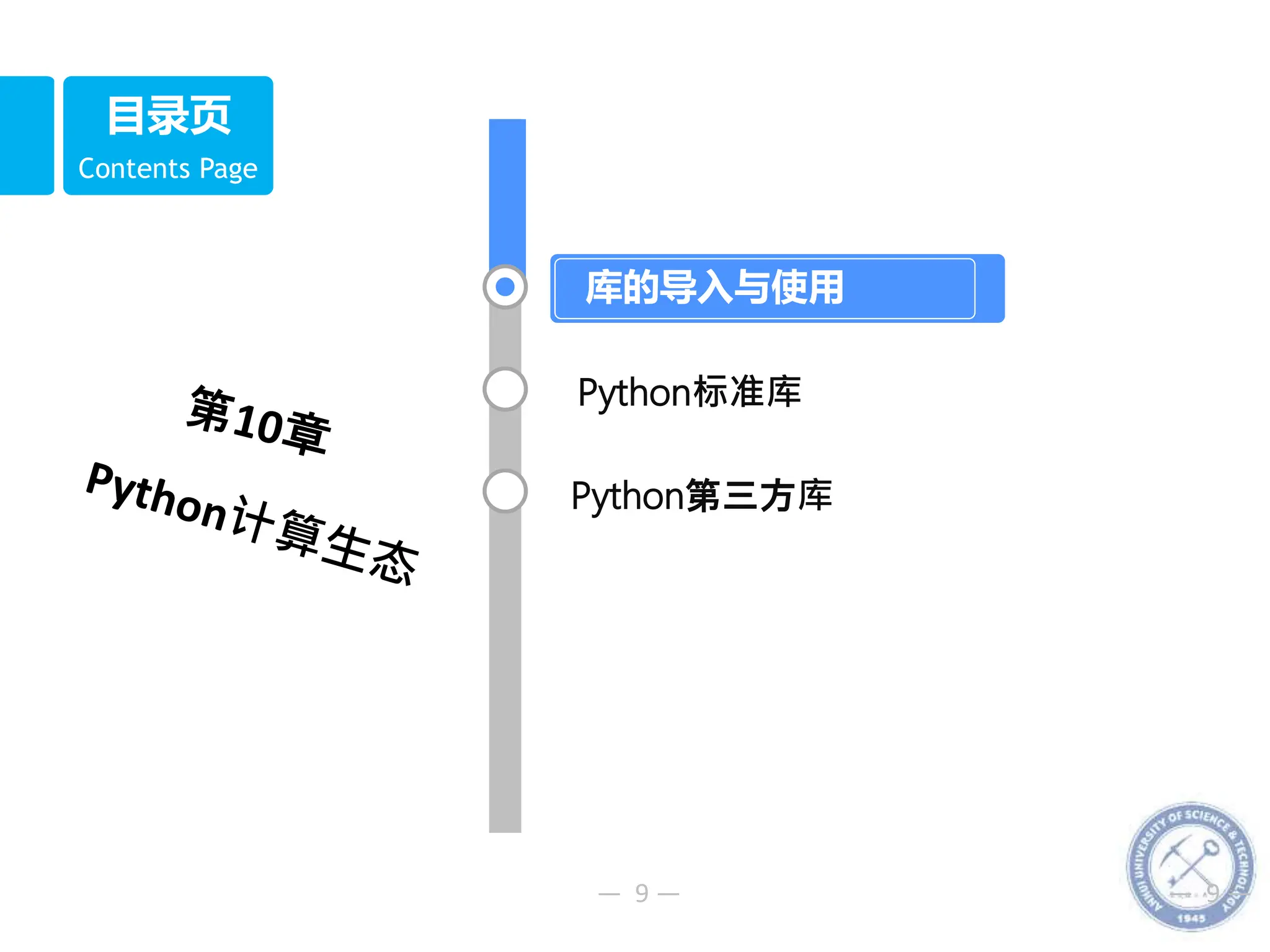
10.1库的导入与使用
模块导入的语法格式:
(1)导入模块:
import 模块名 [AS 标识符] #导入模块(或同时取别名)
(2)导入模块中所有项目(函数、类或变量):
from 模块名 import *
(3)导入模块中指定项目:
from 模块名 import 项目名 [AS 标识符]
(4)导入指定包模块中指定项目:
from 包名.模块名 import 项目名 [AS 标识符]](https://image.slidesharecdn.com/10python-231217052829-7e92c4f0/75/10-Python-pptx-10-2048.jpg)

![— 13 —
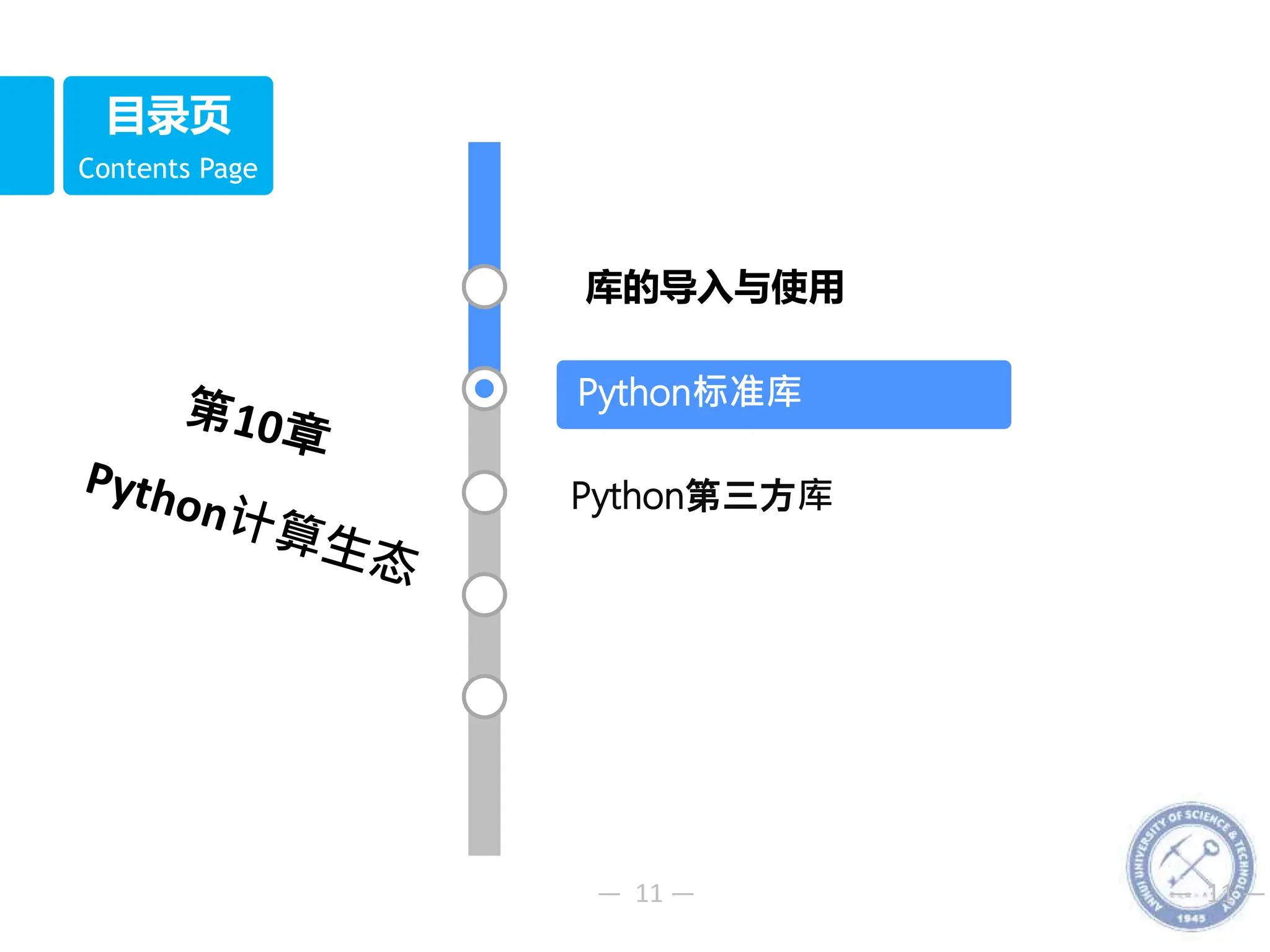
10.1库的导入与使用
10.2.1 random库
函数名 说明
seed(a=None) 初始化随机数种子,默认值为当前系统时间
random() 生成一个[0.0,1.0]之间的随机小数
randint(a,b) 生成一个[a,b]之间的整 数
getrandbits(k) 生成一个k比特长度的随机整数
randrange(start,stop[,step
])
生成一个[start,stop]之间以step为步数的随机整数
uniform(a,b) 生成[a,b]之间的随机小数
choice(seq) 从序列类型(例如列表)中随机返回一个元素
shuffle(seq) 将序列类型中元素随机排列,返回打乱后的序列
sample(pop,k) 从pop类型中随机选取k个元素,以列表类型返回](https://image.slidesharecdn.com/10python-231217052829-7e92c4f0/75/10-Python-pptx-13-2048.jpg)
![— 14 —
10.1库的导入与使用
例10-1
1 import random
2 print(random.randint(1,20))
# 产生 1 到 20 的一个整数型随机数
3 print(random.random()) # 产生 0 到 1 之间的随机浮点数
4 print(random.uniform(2.2,16.3))
# 产生 2.2 到 16.3 之间的随机浮点数
5 print(random.choice('sunday'))
# 从序列中随机选取一个元素
6 print(random.randrange(1,100,7))
# 生成从1到100的间隔为7的随机整数
7 list1=[8,'s',5.0,24,'moon'] # 将序列list1中的元素顺序打乱
8 random.shuffle(list1)
9 print(list1)](https://image.slidesharecdn.com/10python-231217052829-7e92c4f0/75/10-Python-pptx-14-2048.jpg)











![— 27 —
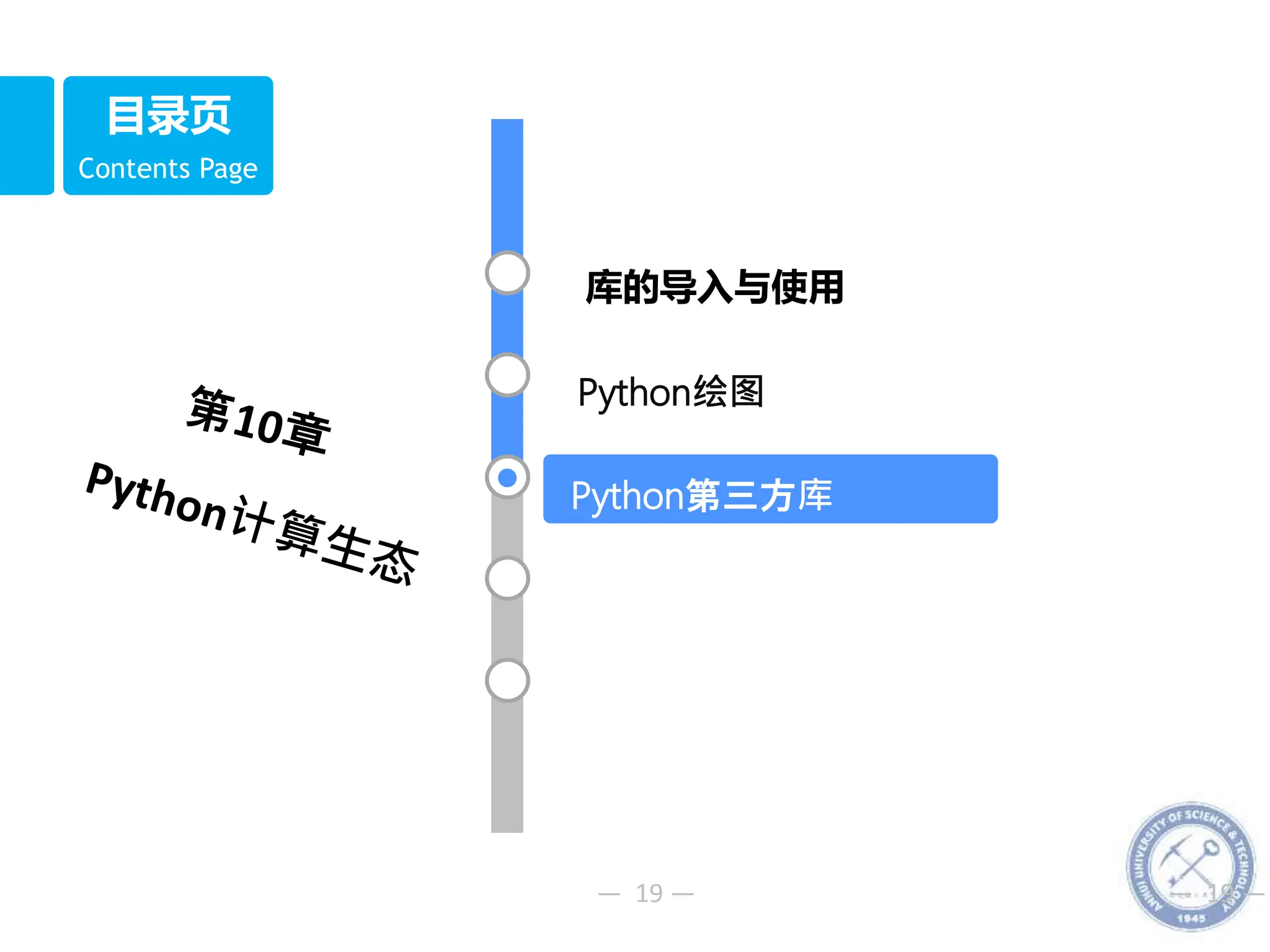
10.3 Python第三方库
1. 创建NumPy数组
10.3.1 NumPy库
1 import numpy as np
2 a=np.array([1,3,5])
3 print(a)
4 b=np.array([[1,2,3],[4,5,6]])
5 print(b)
6 c=np.array([[1,2], [3,4],[5,6]])
7 print(c)](https://image.slidesharecdn.com/10python-231217052829-7e92c4f0/75/10-Python-pptx-27-2048.jpg)


![— 30 —
10.3 Python第三方库
3. NumPy数组操作
10.3.1 NumPy库
【例10-24】数组切片操作。
程序代码:
1 import numpy as np
2 a = np.arange(10)
3 s = slice(1, 7, 2) # 从索引 2 开始到索引 7 停止,间
隔为2
4 print(a[s])
运行结果:
[1 3 5]](https://image.slidesharecdn.com/10python-231217052829-7e92c4f0/75/10-Python-pptx-30-2048.jpg)
![— 31 —
10.3 Python第三方库
4. NumPy字符串函数
10.3.1 NumPy库
【例10-34】字符串连接。
程序代码:
1 import numpy as np
2 print('连接两个字符串:')
3 print(np.char.add(['hello'], [' world']))
4 print(np.char.multiply('hello ', 3))
5 print(np.char.center('Hi', 20, fillchar='*'))](https://image.slidesharecdn.com/10python-231217052829-7e92c4f0/75/10-Python-pptx-31-2048.jpg)
![— 32 —
10.3 Python第三方库
5. Numpy数组运算
10.3.1 NumPy库
【例10-41】数组相乘。
程序代码:
1 import numpy as np
2 a = np.array([1,2,3])
3 b = np.array([10,20,30])
4 c = a * b
5 print(a*3)
6 print (c)
运行结果:
[3 6 9]
[10 40 90]](https://image.slidesharecdn.com/10python-231217052829-7e92c4f0/75/10-Python-pptx-32-2048.jpg)

![— 34 —
10.3 Python第三方库
10.3.2 Requests库
【例10-47】使用request便捷实现调用API,获取天气信息。
程序代码:
1 import requests
2 response =
requests.get('https://api.muxiaoguo.cn/api/tianqi?
city=%E9%A9%AC%E9%9E%8D%E5%B1%B1&type=1')
3 print(response.json()['data']['cityname'])
4 print(response.json()['data']['temp'])
5 print(response.json()['data']['weather'])
6 print(response.json()['data']['time'])
7 print(response.text)](https://image.slidesharecdn.com/10python-231217052829-7e92c4f0/75/10-Python-pptx-34-2048.jpg)







![— 42 —
10.3 Python第三方库
10.3.3 Jieba库
【例10-48】分析《淮南子原道训》文中出现频率最高的10个词语。
1 import jieba
2 fname="淮南子全文.txt"
3 fo=open(fname,encoding="utf-8")
4 txt=fo.read()
5 lb=jieba.lcut(txt)
6 counts={}
7 for word in lb:
8 if len(word)==1:
9 continue
10 else:
11 counts[word]=counts.get(word,0)+1](https://image.slidesharecdn.com/10python-231217052829-7e92c4f0/75/10-Python-pptx-42-2048.jpg)
![— 43 —
10.3 Python第三方库
10.3.3 Jieba库
【例10-48】分析《淮南子原道训》文中出现频率最高的10个词语。
12 items=list(counts.items())
13 items.sort(key=lambda x:x[1],reverse=True)
14 for i in range(10):
15 word,count=items[i]
16 print('{:<10}{:>5}'.format(word,count))](https://image.slidesharecdn.com/10python-231217052829-7e92c4f0/75/10-Python-pptx-43-2048.jpg)

![— 45 —
10.3 Python第三方库
10.3.3 Jieba库
【例10-48】分析《淮南子原道训》文中出现频率最高的10个词语。
7 excludes = {
8 '这样', '所以', '一样', '一定', '可以', '的话', '不会', '现在', '人
9 家', '什么', '不能', '那么', '如果', '他们', '自己', '我们', '反而',
10 '没有', '于是', '就是', '所以', '这样', '知道', '这时', '不是', '这是
11 ', '一个', '有时候'
12 }
13 for word in lb:
14 if len(word) == 1:
15 continue
16 counts[word] = counts.get(word, 0) + 1](https://image.slidesharecdn.com/10python-231217052829-7e92c4f0/75/10-Python-pptx-45-2048.jpg)
![— 46 —
10.3 Python第三方库
10.3.3 Jieba库
【例10-48】分析《淮南子原道训》文中出现频率最高的10个词语。
17 for word in excludes:
18 del (counts[word])
19 items = list(counts.items())
20 items.sort(key=lambda x: x[1], reverse=True)
21 for i in range(10):
22 word, count = items[i]
23 print('{:<10}{:>5}'.format(word, count))](https://image.slidesharecdn.com/10python-231217052829-7e92c4f0/75/10-Python-pptx-46-2048.jpg)

























