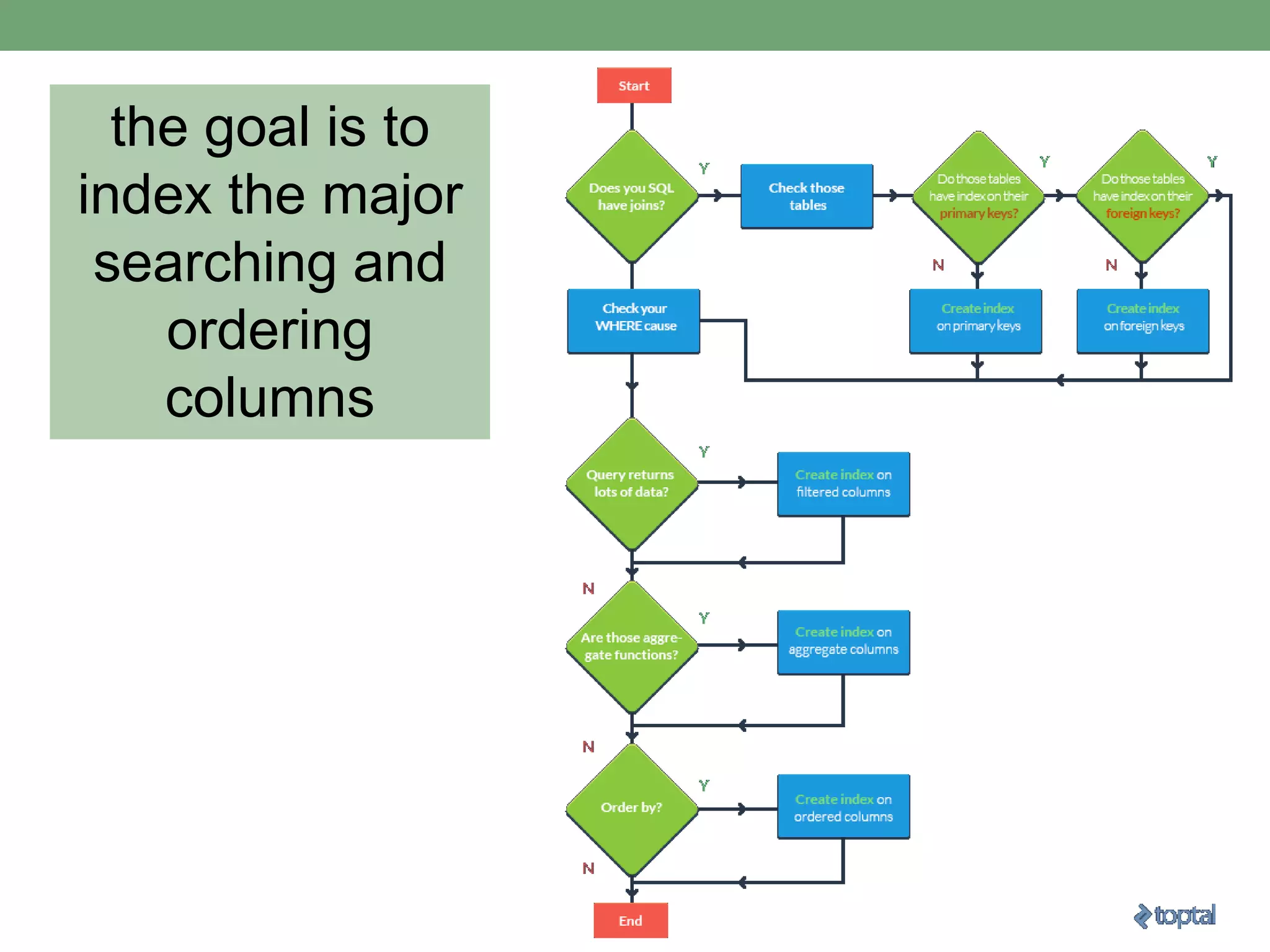
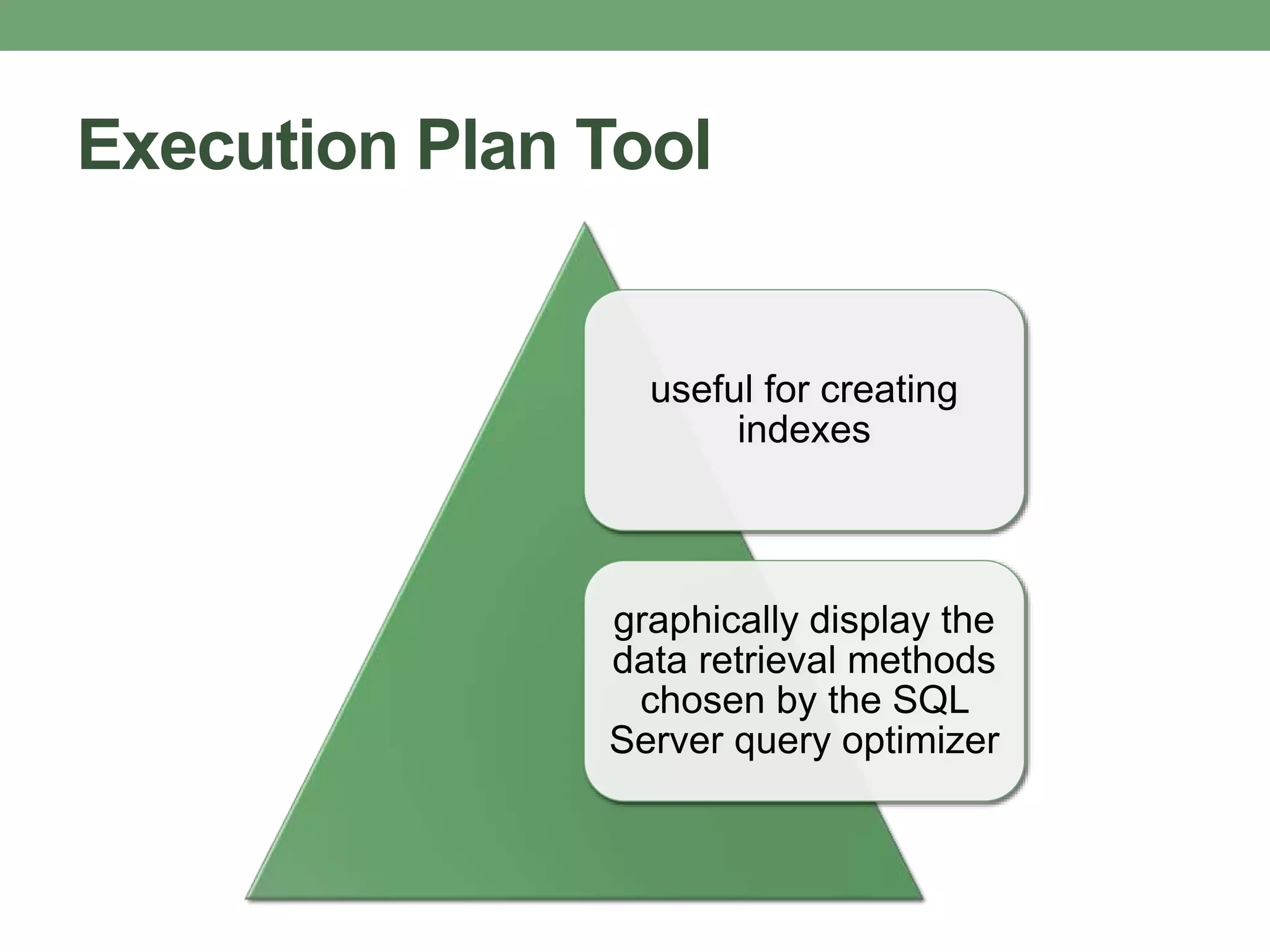
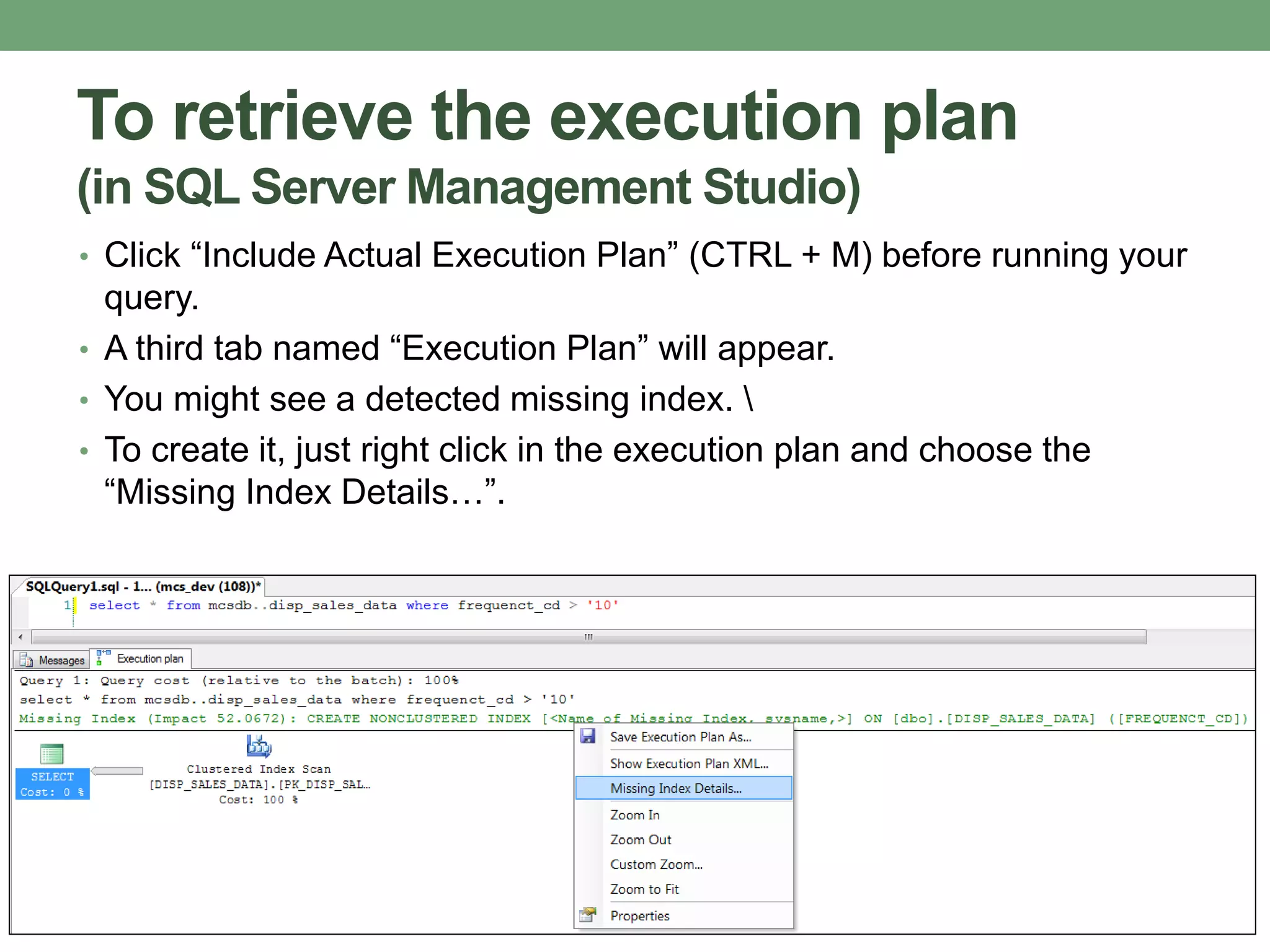
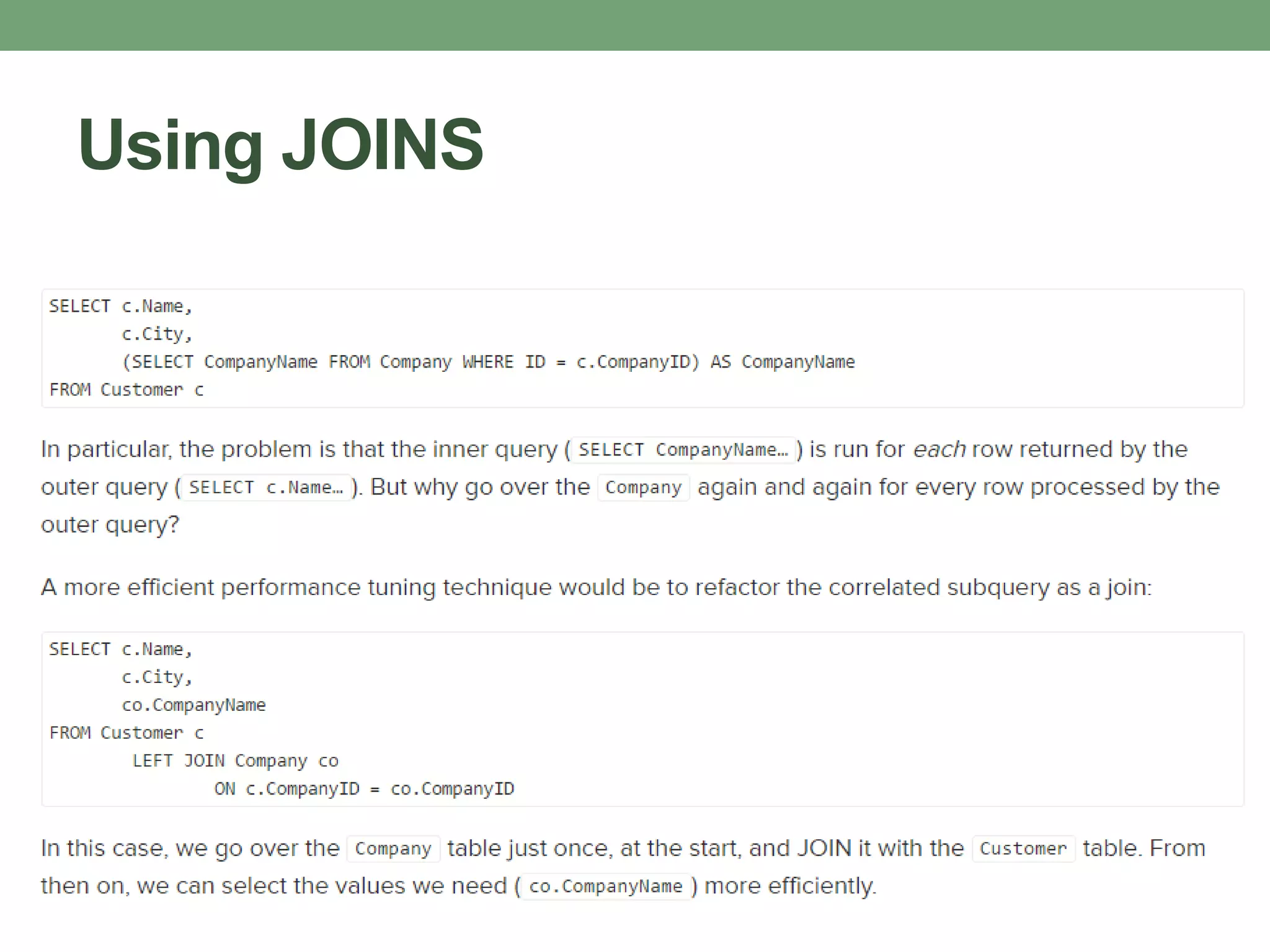
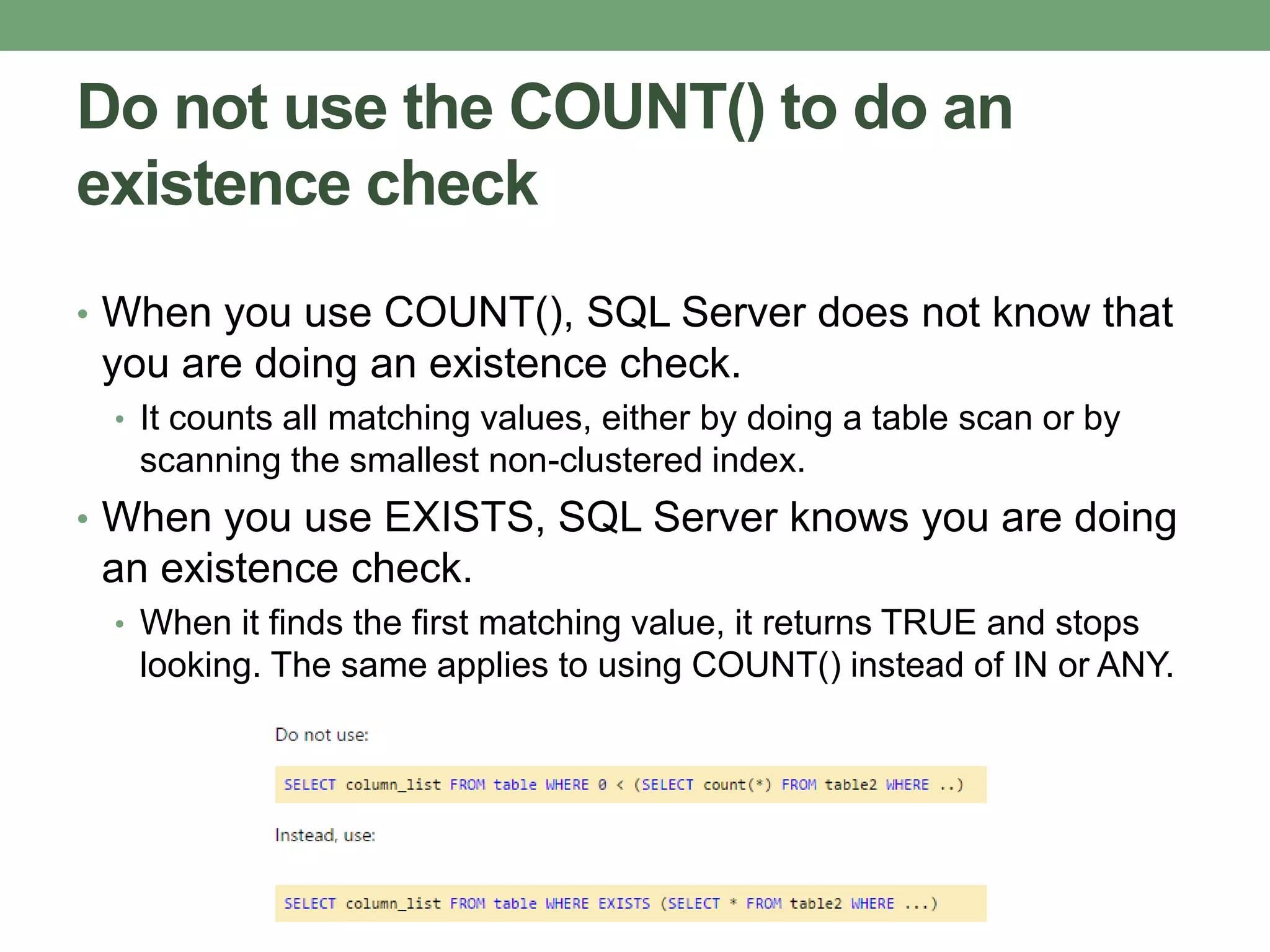
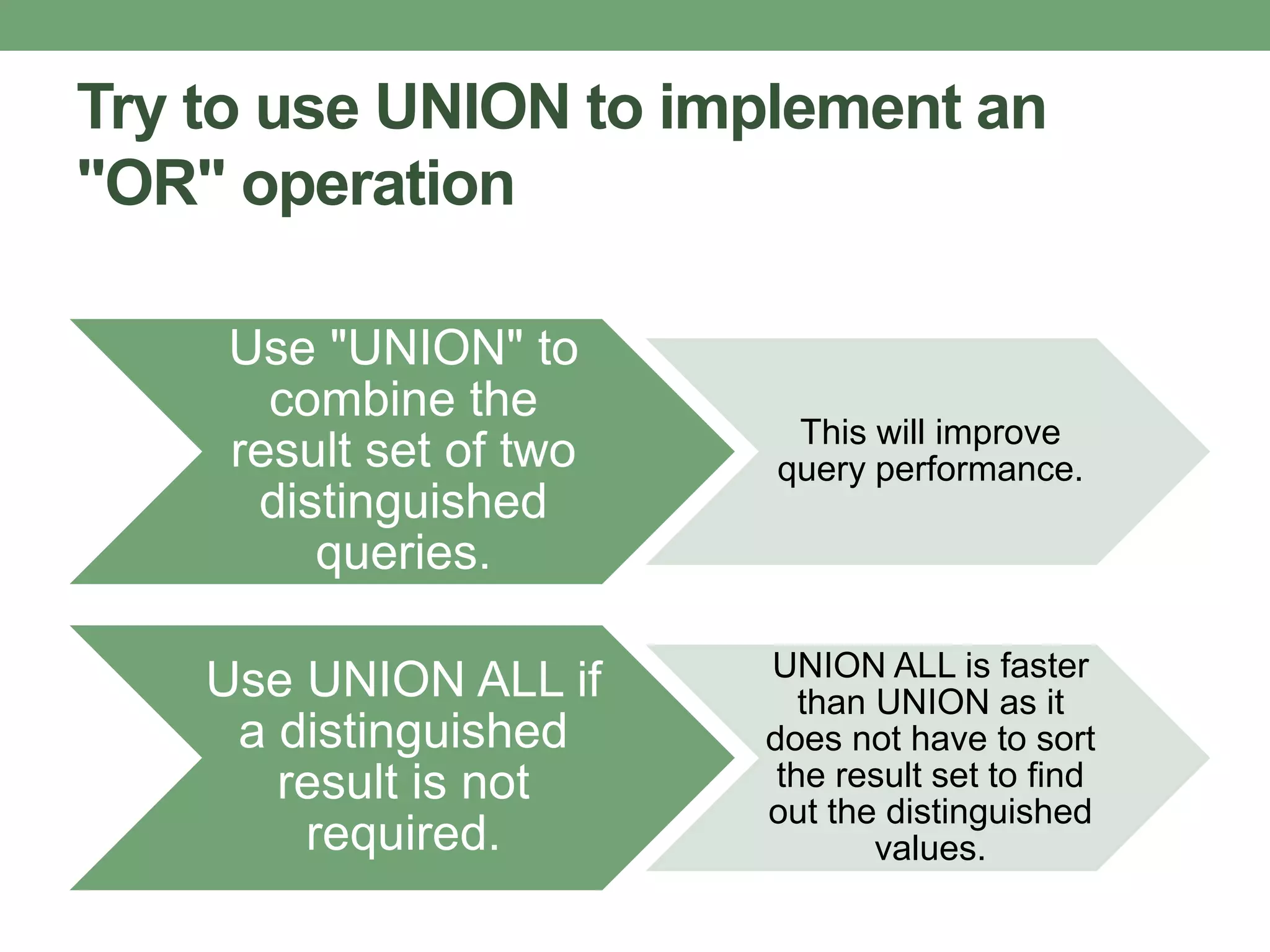
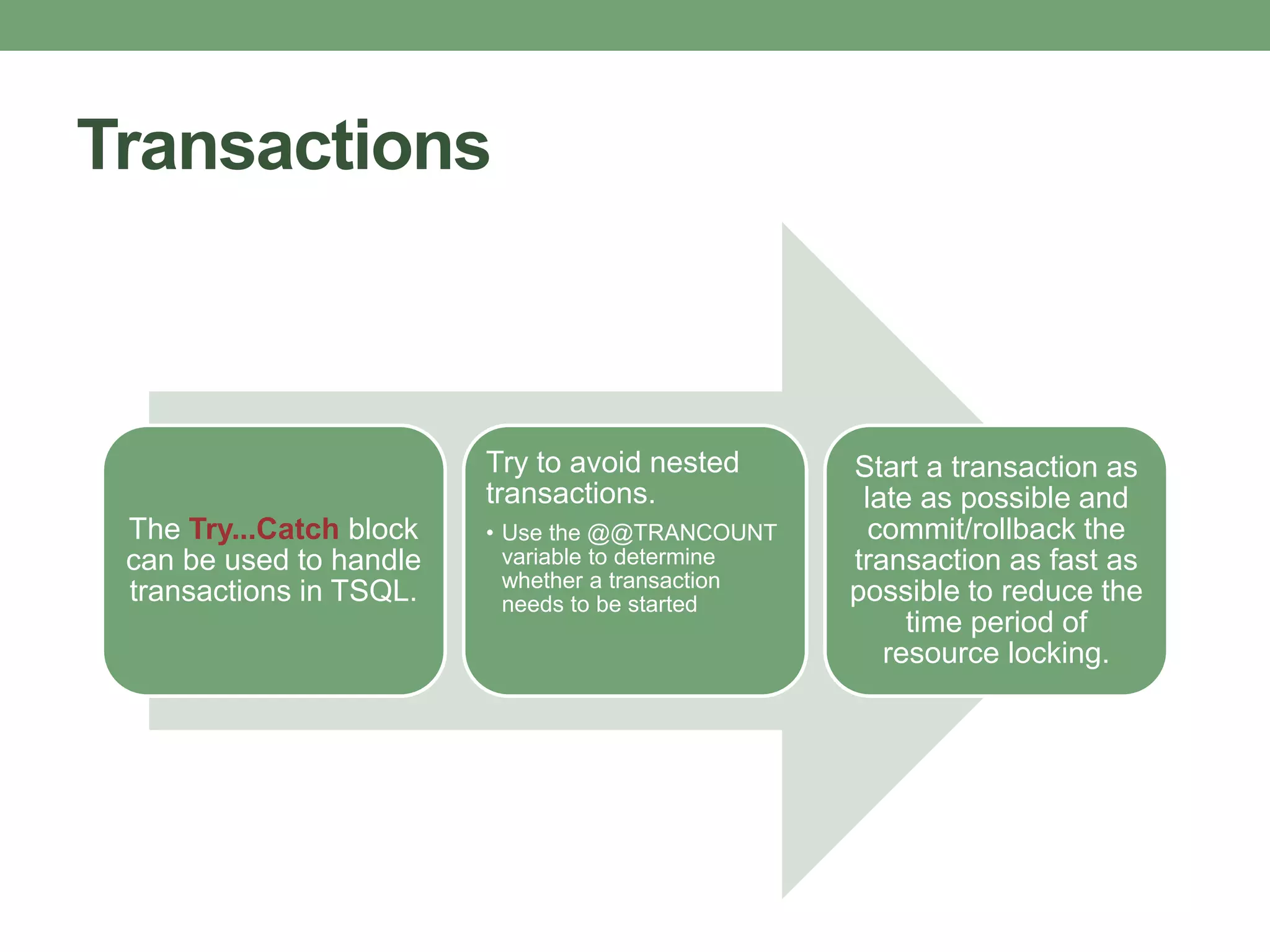
This document provides guidance on optimizing database performance through techniques like indexing, query tuning, avoiding unnecessary operations, and following best practices for objects like stored procedures, triggers, views and transactions. It emphasizes strategies like indexing frequently accessed columns, avoiding correlated subqueries and unnecessary joins, tuning queries to select only required columns, and keeping transactions and locks as short as possible.