Download free for 30 days
Sign in
Upload
Language (EN)
Support
Business
Mobile
Social Media
Marketing
Technology
Art & Photos
Career
Design
Education
Presentations & Public Speaking
Government & Nonprofit
Healthcare
Internet
Law
Leadership & Management
Automotive
Engineering
Software
Recruiting & HR
Retail
Sales
Services
Science
Small Business & Entrepreneurship
Food
Environment
Economy & Finance
Data & Analytics
Investor Relations
Sports
Spiritual
News & Politics
Travel
Self Improvement
Real Estate
Entertainment & Humor
Health & Medicine
Devices & Hardware
Lifestyle
Change Language
Language
English
Español
Português
Français
Deutsche
Cancel
Save
EN
Uploaded by
Kazuhiro Ogura
PDF, PPTX
6,838 views
20131213 jawsugソフトウェアベンダーがAWSを活用して 急にSaaSをはじめた話
JAWSUG 東京 2013/12/13 ソフトウェアベンダーが AWSを活用して 急にSaaSをはじめた話
Technology
◦
Read more
21
Save
Share
Embed
Embed presentation
Download
Download as PDF, PPTX
1
/ 63
2
/ 63
3
/ 63
4
/ 63
5
/ 63
6
/ 63
7
/ 63
8
/ 63
9
/ 63
10
/ 63
11
/ 63
12
/ 63
13
/ 63
14
/ 63
15
/ 63
16
/ 63
17
/ 63
18
/ 63
19
/ 63
20
/ 63
21
/ 63
22
/ 63
23
/ 63
24
/ 63
25
/ 63
26
/ 63
27
/ 63
28
/ 63
29
/ 63
30
/ 63
31
/ 63
32
/ 63
33
/ 63
34
/ 63
35
/ 63
36
/ 63
37
/ 63
38
/ 63
39
/ 63
40
/ 63
41
/ 63
42
/ 63
43
/ 63
44
/ 63
45
/ 63
46
/ 63
47
/ 63
48
/ 63
49
/ 63
50
/ 63
51
/ 63
52
/ 63
53
/ 63
54
/ 63
55
/ 63
56
/ 63
57
/ 63
58
/ 63
59
/ 63
60
/ 63
61
/ 63
62
/ 63
63
/ 63
More Related Content
PDF
データ分析基盤、どう作る?システム設計のポイント、教えます - Developers.IO 2019 (20191101)
by
Yosuke Katsuki
PDF
AWSだけでSI/MSPする会社に入って
by
真吾 吉田
PPTX
AWSで作る分析基盤
by
Yu Otsubo
PPTX
[CWT2017]Infrastructure as Codeを活用したF.O.Xのクラウドビッグデータ環境の変化
by
Takahiro Moteki
PDF
20190723 PubSec local gov webinar
by
Amazon Web Services Japan
PDF
基調講演: 「パーペイシブ分析を目指して」#cwt2015
by
Cloudera Japan
PPTX
Clouderaが提供するエンタープライズ向け運用、データ管理ツールの使い方 #CW2017
by
Cloudera Japan
PPTX
kintone のレコード絞り込み置き換え事例の紹介
by
Ryo Mitoma
データ分析基盤、どう作る?システム設計のポイント、教えます - Developers.IO 2019 (20191101)
by
Yosuke Katsuki
AWSだけでSI/MSPする会社に入って
by
真吾 吉田
AWSで作る分析基盤
by
Yu Otsubo
[CWT2017]Infrastructure as Codeを活用したF.O.Xのクラウドビッグデータ環境の変化
by
Takahiro Moteki
20190723 PubSec local gov webinar
by
Amazon Web Services Japan
基調講演: 「パーペイシブ分析を目指して」#cwt2015
by
Cloudera Japan
Clouderaが提供するエンタープライズ向け運用、データ管理ツールの使い方 #CW2017
by
Cloudera Japan
kintone のレコード絞り込み置き換え事例の紹介
by
Ryo Mitoma
What's hot
PDF
AWS WAF Security Automation
by
Hayato Kiriyama
PDF
クラウド上でHadoopを構築できる Cloudera Director 2.0 の紹介 #dogenzakalt
by
Cloudera Japan
PDF
先行事例から学ぶ IoT / ビッグデータの始め方
by
Cloudera Japan
PDF
SmartNewsのニュース配信を支えるサーバ技術 / Kazhiro Sera @ SmartNews,Inc. #jjug_ccc
by
SmartNews, Inc.
PDF
[CTO Night & Day 2019] AWS Database Overview -データベースの選択指針- #ctonight
by
Amazon Web Services Japan
PDF
データ分析基盤構築のポイントと関連クラスメソッドサービスの紹介
by
Yosuke Katsuki
PDF
2018/9/11 SAP on AWS お客様事例セミナー@東京(BeeX資料1/2)
by
BeeX.inc
PDF
AWS re:Invent 2017 Security re:Cap Key Messages
by
Hayato Kiriyama
PDF
Spring で実現する SmartNews のニュース配信基盤
by
SmartNews, Inc.
PDF
Serverless analytics on aws
by
Amazon Web Services Japan
PDF
AWS White Belt Guide 目指せ黒帯!今から始める方への学び方ガイド
by
Trainocate Japan, Ltd.
PPTX
AWS社員による怒涛のLTチャレンジ! AWS IoT EduKitで遊ぼうぜ!
by
Amazon Web Services Japan
PPTX
[簡易提案書]Azure overview 2017_sep_v0.9
by
Toshihiko Sawaki
PDF
「これ危ない設定じゃないでしょうか」とヒアリングするための仕組み @AWS Summit Tokyo 2018
by
cyberagent
PDF
AWS IoTの勘所
by
Tsuyoshi Seino
PPTX
Machine Learning for Digital Advertising
by
Amazon Web Services Japan
PDF
GDC2018 Amazon Overview
by
Amazon Web Services Japan
PDF
20180306 AWS Black Belt Online Seminar 働き方改革を実現するAWSのエンドユーザーコンピューティングサービス
by
Amazon Web Services Japan
PDF
Cloudera in the Cloud #CWT2017
by
Cloudera Japan
PDF
デジタル化への第一歩 「エンタープライズデータレイク構築事例のご紹介」
by
BeeX.inc
AWS WAF Security Automation
by
Hayato Kiriyama
クラウド上でHadoopを構築できる Cloudera Director 2.0 の紹介 #dogenzakalt
by
Cloudera Japan
先行事例から学ぶ IoT / ビッグデータの始め方
by
Cloudera Japan
SmartNewsのニュース配信を支えるサーバ技術 / Kazhiro Sera @ SmartNews,Inc. #jjug_ccc
by
SmartNews, Inc.
[CTO Night & Day 2019] AWS Database Overview -データベースの選択指針- #ctonight
by
Amazon Web Services Japan
データ分析基盤構築のポイントと関連クラスメソッドサービスの紹介
by
Yosuke Katsuki
2018/9/11 SAP on AWS お客様事例セミナー@東京(BeeX資料1/2)
by
BeeX.inc
AWS re:Invent 2017 Security re:Cap Key Messages
by
Hayato Kiriyama
Spring で実現する SmartNews のニュース配信基盤
by
SmartNews, Inc.
Serverless analytics on aws
by
Amazon Web Services Japan
AWS White Belt Guide 目指せ黒帯!今から始める方への学び方ガイド
by
Trainocate Japan, Ltd.
AWS社員による怒涛のLTチャレンジ! AWS IoT EduKitで遊ぼうぜ!
by
Amazon Web Services Japan
[簡易提案書]Azure overview 2017_sep_v0.9
by
Toshihiko Sawaki
「これ危ない設定じゃないでしょうか」とヒアリングするための仕組み @AWS Summit Tokyo 2018
by
cyberagent
AWS IoTの勘所
by
Tsuyoshi Seino
Machine Learning for Digital Advertising
by
Amazon Web Services Japan
GDC2018 Amazon Overview
by
Amazon Web Services Japan
20180306 AWS Black Belt Online Seminar 働き方改革を実現するAWSのエンドユーザーコンピューティングサービス
by
Amazon Web Services Japan
Cloudera in the Cloud #CWT2017
by
Cloudera Japan
デジタル化への第一歩 「エンタープライズデータレイク構築事例のご紹介」
by
BeeX.inc
Similar to 20131213 jawsugソフトウェアベンダーがAWSを活用して 急にSaaSをはじめた話
PDF
2011-04-21 クラウド勉強会
by
Koichiro Doi
PDF
20120303 jaws summit-meister-03_s3
by
Amazon Web Services Japan
PDF
20120319 aws meister-reloaded-s3
by
Amazon Web Services Japan
PDF
20120319 aws meister-reloaded-s3
by
Amazon Web Services Japan
PDF
2013 デブサミ 「SIの未来ってどうなのよ?」
by
Serverworks Co.,Ltd.
PDF
スタートアップだからこそ使うAWS(第5回JAWS-UG Nagoya)
by
Tomotsune Murata
PDF
Amazon Web Services 最新事例集
by
SORACOM, INC
PDF
Aws seminar-tokyo dan-jp-final-publish
by
awsadovantageseminar
PDF
Aws dan jp-final-publish
by
awsadvantageseminar
PDF
JAWS DAYS 2015
by
陽平 山口
PDF
「はじめてのAmazon Web Services」 JAWS-UG 長崎第1回勉強会
by
Yasuhiro Horiuchi
PDF
[AWS Summit 2012] クラウドデザインパターン#1 CDP概要編
by
Amazon Web Services Japan
PDF
クラウド開発に役立つ OSS あれこれ
by
Masataka MIZUNO
PPTX
インフラ系自主トレするならAWS
by
Yasuhiro Araki, Ph.D
PPTX
NoSQL on AWSで作る最新ソーシャルゲームアーキテクチャ
by
Yasuhiro Matsuo
PDF
スタートアップがAWSを使うべき3つの理由
by
Serverworks Co.,Ltd.
PDF
20120323 cloudpacknight
by
Yasuhiro Horiuchi
PDF
20120528 aws meister-reloaded-awssd-kforjava-public
by
Amazon Web Services Japan
PDF
AWS meets Android - "AWS SDK for Android"で開発を楽にしよう!
by
SORACOM, INC
PDF
業務アプリをクラウド化する5つのステップ ~Amazon Web Services活用の勘所~
by
SORACOM, INC
2011-04-21 クラウド勉強会
by
Koichiro Doi
20120303 jaws summit-meister-03_s3
by
Amazon Web Services Japan
20120319 aws meister-reloaded-s3
by
Amazon Web Services Japan
20120319 aws meister-reloaded-s3
by
Amazon Web Services Japan
2013 デブサミ 「SIの未来ってどうなのよ?」
by
Serverworks Co.,Ltd.
スタートアップだからこそ使うAWS(第5回JAWS-UG Nagoya)
by
Tomotsune Murata
Amazon Web Services 最新事例集
by
SORACOM, INC
Aws seminar-tokyo dan-jp-final-publish
by
awsadovantageseminar
Aws dan jp-final-publish
by
awsadvantageseminar
JAWS DAYS 2015
by
陽平 山口
「はじめてのAmazon Web Services」 JAWS-UG 長崎第1回勉強会
by
Yasuhiro Horiuchi
[AWS Summit 2012] クラウドデザインパターン#1 CDP概要編
by
Amazon Web Services Japan
クラウド開発に役立つ OSS あれこれ
by
Masataka MIZUNO
インフラ系自主トレするならAWS
by
Yasuhiro Araki, Ph.D
NoSQL on AWSで作る最新ソーシャルゲームアーキテクチャ
by
Yasuhiro Matsuo
スタートアップがAWSを使うべき3つの理由
by
Serverworks Co.,Ltd.
20120323 cloudpacknight
by
Yasuhiro Horiuchi
20120528 aws meister-reloaded-awssd-kforjava-public
by
Amazon Web Services Japan
AWS meets Android - "AWS SDK for Android"で開発を楽にしよう!
by
SORACOM, INC
業務アプリをクラウド化する5つのステップ ~Amazon Web Services活用の勘所~
by
SORACOM, INC
20131213 jawsugソフトウェアベンダーがAWSを活用して 急にSaaSをはじめた話
1.
ソフトウェアベンダーが AWSを活用して 急にSaaSをはじめた話 小椋 一宏/Kazuhiro Ogura CTO of
HDE, Inc. @goura fb.me/rgoura
4.
なぜSaaSを はじめたのか
5.
はじめたかったから
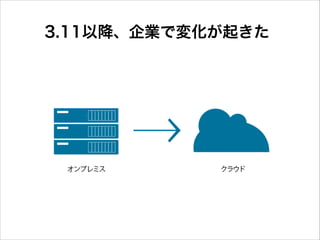
6.
3.11以降、企業で変化が起きた
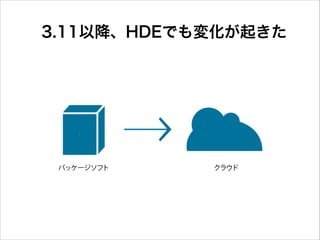
8.
3.11以降、HDEでも変化が起きた
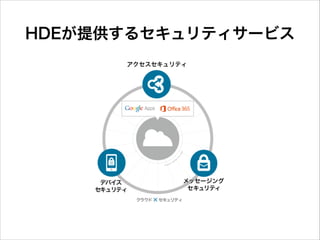
9.
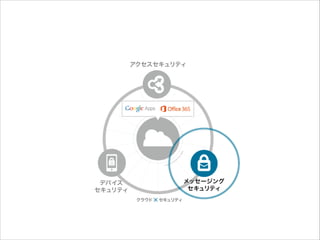
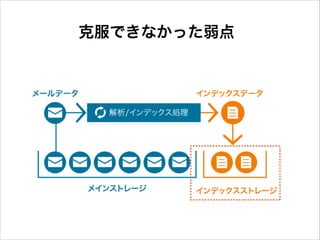
HDEが提供するセキュリティサービス
12.
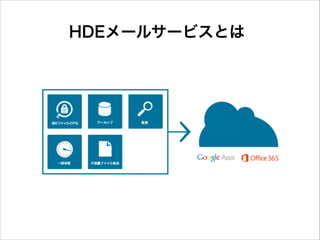
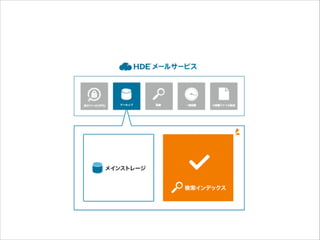
HDEメールサービスとは
13.
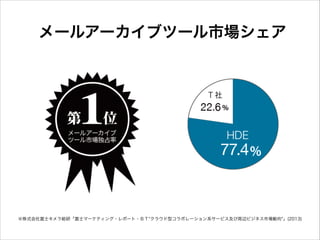
メールアーカイブツール市場シェア ※株式会社富士キメラ総研「富士マーケティング・レポート・BT"クラウド型コラボレーション系サービス及び周辺ビジネス市場動向"」(2013)
14.
約 550社 40万ユーザー
15.
処理通数:約3.0億通/月 保管通数:約1.0億通/月
16.
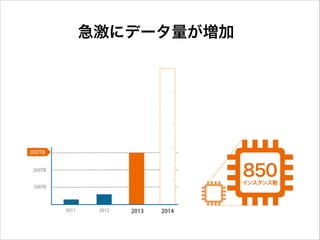
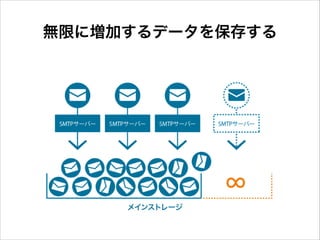
急激にデータ量が増加
17.
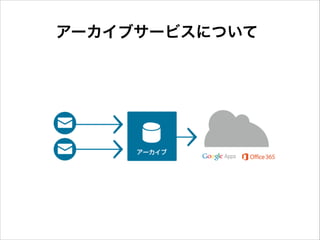
アーカイブサービスについて
18.
アーカイブ主要コンポーネント
19.
ストレージについて
20.
メインストレージには 何を使うか?
21.
要件 ・無限に増加するデータの安全な保管 ・現実的なパフォーマンスで検索可能にする (検索インデックスの作成) ・目標稼働率 99.99%
22.
S3の採用 • • • • • • オブジェクト数上限:なし ストレージ総容量制限:なし オブジェクト容量制限: 5TBまで 可用性: 99.99% 三つ以上のデータセンターに分散 GBあたり単価:
$0.10/GB
23.
使いたかったから
24.
無限に増加するデータを保存する
25.
S3の課題: I/O性能 HTTPベースのAPI:単体でのアクセスは遅い
26.
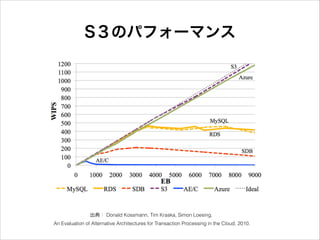
課題解決: I/O性能
27.
S3のパフォーマンス 出典: Donald Kossmann,
Tim Kraska, Simon Loesing. An Evaluation of Alternative Architectures for Transaction Processing in the Cloud, 2010.
28.
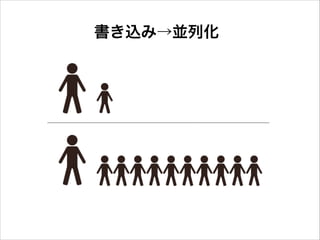
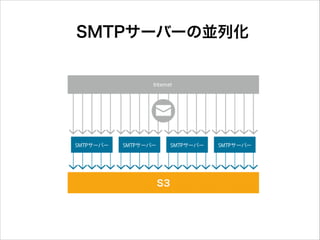
書き込み→並列化
29.
SMTPサーバーの並列化
30.
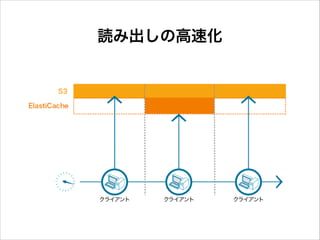
課題解決: I/O性能
31.
読み出しの高速化
32.
課題解決: I/O性能
33.
S3でメインストレージを構築
34.
検索インデックスについて
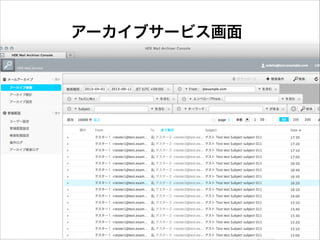
35.
アーカイブサービス画面
36.
全文検索エンジン ゼロから開発
37.
作りたかったから
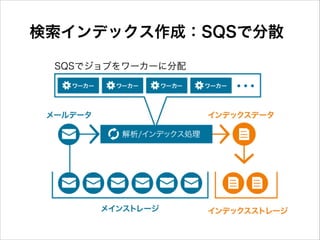
38.
検索インデックス作成:SQSで分散 SQSでジョブをワーカーに分配
39.
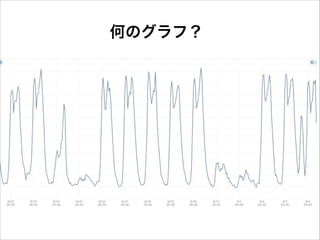
何のグラフ?
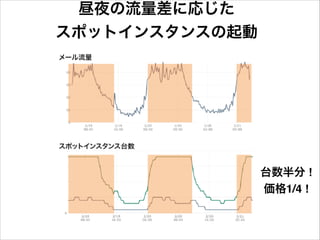
40.
昼夜の流量差に応じた スポットインスタンスの起動 台数半分 ! 価格1/4 !
41.
めでたしめでたし のようだが……
42.
克服できなかった弱点
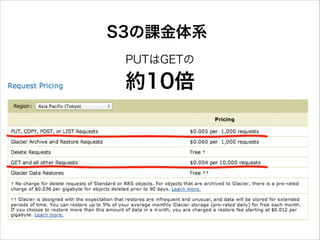
43.
S3の課金体系 PUTはGETの 約10倍
44.
インデックス処理にかかる金額 • 当社の検索方式はN-gram風 • 全文検索インデックス処理では、メール1通につき 3000∼5000キーの更新が発生する ! •
そのままS3に書き込んでしまうと、、
45.
S3だとパケ死する
46.
しょうがないので MongoDB
47.
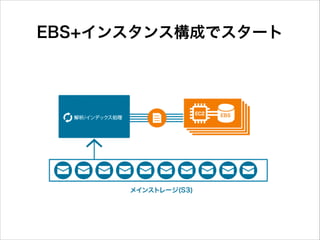
EBS+インスタンス構成でスタート
48.
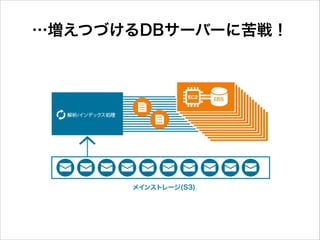
…増えつづけるDBサーバーに苦戦!
49.
S3を使えなかった理由は 更新・書き込みが多いから ! ならば ! 更新が終わったら S3に移せばいいかも
50.
そうだ ついでに圧縮して 料金を節約しよう
51.
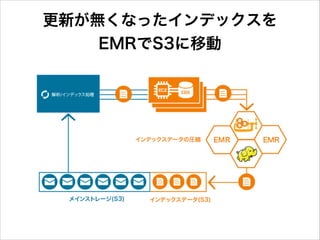
更新が無くなったインデックスを EMRでS3に移動
52.
EMR
53.
使いたかったから
54.
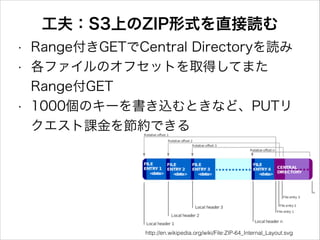
工夫:S3上のZIP形式を直接読む • • • Range付きGETでCentral Directoryを読み 各ファイルのオフセットを取得してまた Range付GET 1000個のキーを書き込むときなど、PUTリ クエスト課金を節約できる http://en.wikipedia.org/wiki/File:ZIP-64_Internal_Layout.svg
56.
ここまでのまとめ • S3 +
SQS でたいていのことはできる • 書き込み→並列化 • 読み込み→キャッシュで弱点克服 • 細かいデータをたくさん書く用途は、 従来型のシステムとのハイブリッド型 も選択肢の一つ
57.
Glacier登場 2012/8 Glacierの発表 ! • ストレージコストはS3のおよそ1/8 •
100TB貯めても12万円/月 • 読み出しにはお金がかかる→バックアップ用 • 削除にはお金がかからない
58.
使いたかったので 使いどころを必死で考えた
59.
Glacierの活用
60.
ここまでのまとめ • Glacierは、取り出さない目算が高いデー タを格納するのに有効 • AWSを基盤にすることで、AWSの競争力 を武器にできる
61.
話は以上です ありがとうございました さいごに
62.
ジョブシェアで人材募集中です! https://job-share.net/jobs/3084
63.
ありがとうございました! 小椋 一宏/Kazuhiro Ogura CTO of
HDE, Inc. twitter.com/goura fb.me/rgoura
Download










































![[CWT2017]Infrastructure as Codeを活用したF.O.Xのクラウドビッグデータ環境の変化](https://cdn.slidesharecdn.com/ss_thumbnails/dlcwt2017infrastructureascodef-171108044056-thumbnail.jpg?width=640&height=640&fit=bounds)








![[CTO Night & Day 2019] AWS Database Overview -データベースの選択指針- #ctonight](https://cdn.slidesharecdn.com/ss_thumbnails/ctond2019morningsessiondb-191027185856-thumbnail.jpg?width=640&height=640&fit=bounds)







![[簡易提案書]Azure overview 2017_sep_v0.9](https://cdn.slidesharecdn.com/ss_thumbnails/azureoverview2017sepv0-170904135653-thumbnail.jpg?width=640&height=640&fit=bounds)


















![[AWS Summit 2012] クラウドデザインパターン#1 CDP概要編](https://cdn.slidesharecdn.com/ss_thumbnails/aws-summit-cdp-01-121001104449-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)







