並列分散処理基盤のいま ~45分で学ぶHadoop/Spark/Kafka/ストレージレイヤSW入門~ (Open Source Conference 2021 Online/Hokkaido 発表資料) 2021年6月26日 NTTデータ 技術革新統括本部 システム技術本部 デジタル技術部 インテグレーション技術担当 吉田 貴哉










![© 2021 NTT DATA Corporation 33
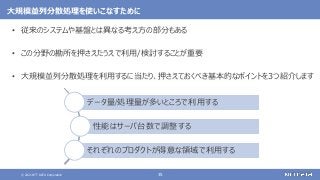
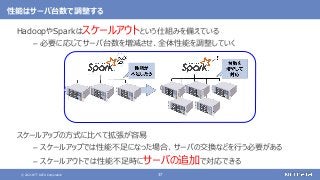
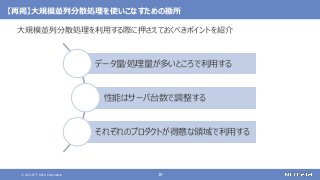
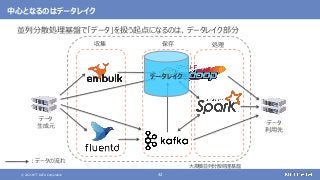
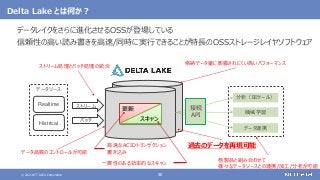
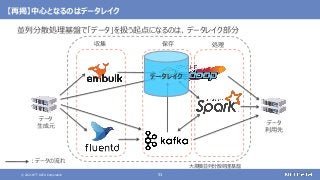
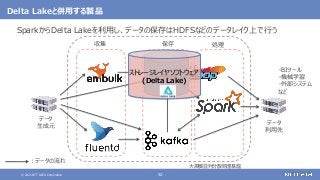
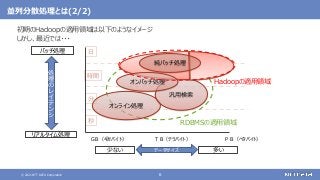
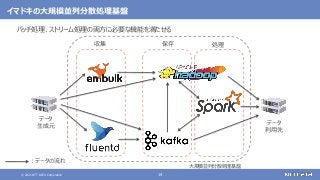
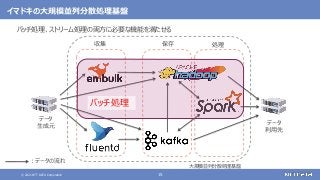
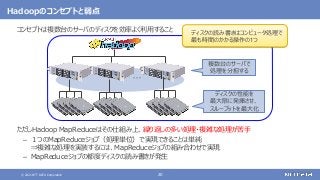
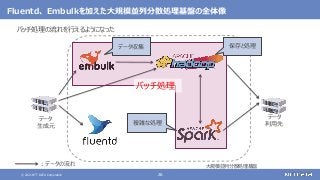
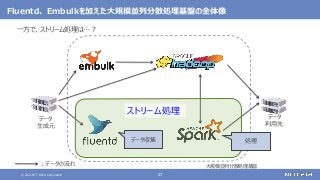
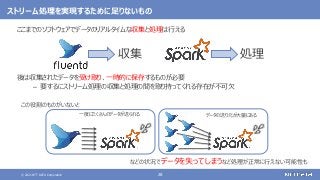
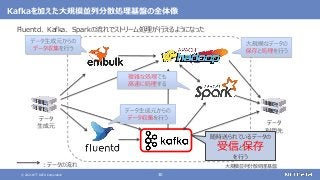
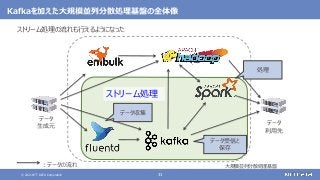
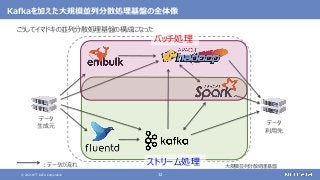
登場した各ソフトウェアの役割のまとめ
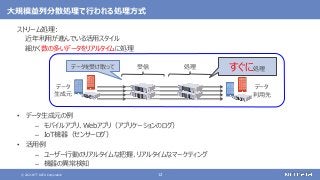
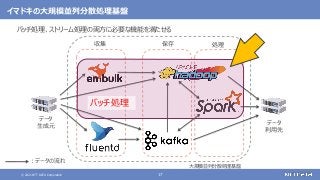
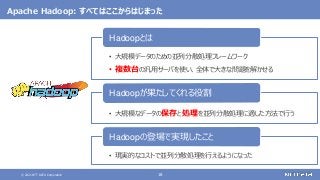
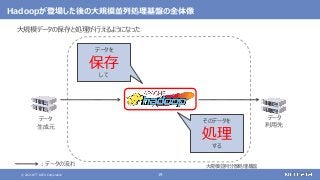
大規模なデータの保存と処理(バッチ処理)を行う
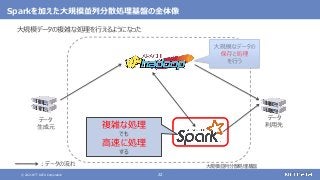
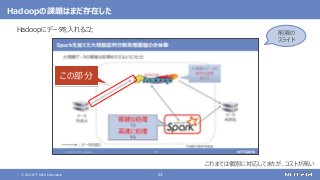
大規模なデータの複雑な処理も高速に行う
[繰り返しの多い処理、機械学習、SQLによる記述、グラフ処理]
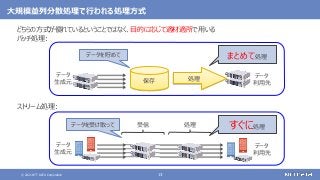
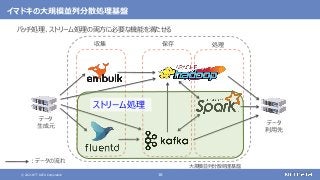
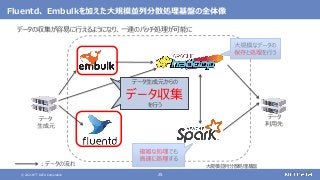
さまざまなデータソースからデータを収集する
随時送られてくるデータの受信と保存を行う
ストリーム処理も可能](https://image.slidesharecdn.com/distributeddataprocessingsystemhadoopsparkkafkastoragelayersoftwareosc2021onlinehokkaidonttdata-210709110433/85/45-Hadoop-Spark-Kafka-SW-Open-Source-Conference-2021-Online-Hokkaido-33-320.jpg?cb=1625829010)