Downloaded 54 times






![14
$ ps -ef | grep /usr/lib/impala/sbin
impala 5161 1 0 19:27 ? 00:00:00 /usr/lib/impala/sbin/statestored -log_dir=/var/log/impala...
impala 5618 1 11 19:27 ? 00:00:05 /usr/lib/impala/sbin/catalogd -log_dir=/var/log/impala ...
impala 5664 1 14 19:27 ? 00:00:06 /usr/lib/impala/sbin/impalad -log_dir=/var/log/impala ...
$ file ./impalad
./impalad: ELF 64-bit LSB executable, x86-64, version 1 (SYSV), dynamically linked (uses shared libs)
$ ps -Lfp `pgrep impala` | wc -l
245
$ sudo pmap `pgrep impalad`
5664: /usr/lib/impala/sbin/impalad -log_dir=/var/log/impala
0000000000400000 36200K r-x-- /usr/lib/impala/sbin-retail/impalad
000000000275a000 1332K rw--- /usr/lib/impala/sbin-retail/impalad
00000000028a7000 328K rw--- [ anon ]
000000000404f000 81548K rw--- [ anon ]
...
0000003f9f000000 1576K r-x-- /lib64/libc-2.12.so
0000003f9f400000 92K r-x-- /lib64/libpthread-2.12.so
...
00007f6bb76cc000 44K r--s- /usr/java/jdk1.7.0_67-cloudera/jre/lib/charsets.jar
00007f6bb76d7000 40K r--s- /usr/java/jdk1.7.0_67-cloudera/jre/lib/resources.jar
...
00007f6bd3188000 156K rw--- [ anon ]
00007f6bd31af000 11712K r-x-- /usr/java/jdk1.7.0_67-cloudera/jre/lib/amd64/server/libjvm.so
00007f6bd3d1f000 2044K ----- /usr/java/jdk1.7.0_67-cloudera/jre/lib/amd64/server/libjvm.so
00007f6bd3f1e000 788K rw--- /usr/java/jdk1.7.0_67-cloudera/jre/lib/amd64/server/libjvm.so
impalad (process layout)
Impala uses
both C++ and
Java under the
hood!](https://image.slidesharecdn.com/apacheimpalainternalswithtanelpoder-170720183843/85/Apache-Impala-Internals-with-Tanel-Poder-14-320.jpg?cb=1500577241)


![17
• Minimize branches & complexity in tight loops
• Oracle 12c In-Memory Option example
• Not instruction codegen. Jumptable to previously compiled special purpose functions
It’s all about CPU-efficiency
generate pcodes
3 opcodes
0: new order 0 opcode 646 cost 2
1: new order 1 opcode 646 cost 2
2: new order 2 opcode 646 cost 2
PCODE
------
version: PCODE1.0, flags: 0x0 size: 280, numbvs: 2
expeal: 0xcc16440
consts: 0x1b proj-pcode: 0x0
[0x7f114c13d658] [== constant] Filt0xffffffffffffffff BV1 = Col0, 0x3fbfaf2280(len=2)
[0x7f114c13d688] [branch if ] if (BV1 == 0) goto 0x7f114c13d708
[0x7f114c13d6a8] [>= and <= ] Filt0x1 BV2 = Col2, 0x3fbfaf1fc8(len=2), 0x3fbfaf1e30(len=3)
[0x7f114c13d6e8] [and ] BV1 = BV1 & BV2
[0x7f114c13d708] [end]
More info on CPU-efficiency topics:
http://blog.tanelpoder.com/2015/08/09/ram-is-the-new-disk-and-how-to-measure-its-performance-part-1/](https://image.slidesharecdn.com/apacheimpalainternalswithtanelpoder-170720183843/85/Apache-Impala-Internals-with-Tanel-Poder-17-320.jpg?cb=1500577241)



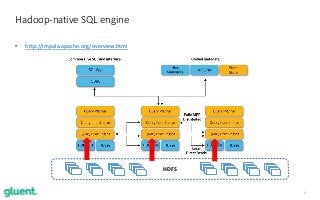
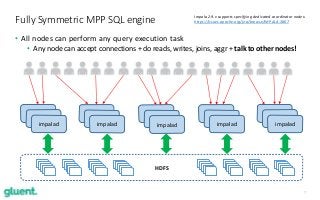
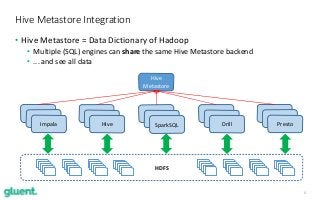
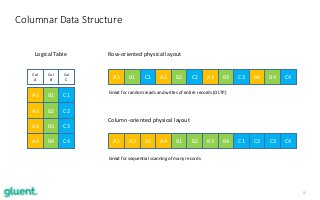
Apache Impala (incubating) is an open source distributed SQL engine, designed to run at scale on top of Hadoop, while giving short response times for interactive queries over petabytes of data. In this 1-hour technical session, Tanel will guide you through a sample of Impala's key features such as parallel processing, columnar data format access, block skipping (storage indexes), distributed aggregations and joins, Bloom filters and standard monitoring tools. Because of Tanel's long-time background in the Oracle Database world, he will compare Impala's built-in features to the typical Oracle database counterparts. This session will show you the power of Apache Impala in the modern world and give you an understanding of which workloads it is designed to work with the best.















































