Download free for 30 days
Sign in
Upload
Language (EN)
Support
Business
Mobile
Social Media
Marketing
Technology
Art & Photos
Career
Design
Education
Presentations & Public Speaking
Government & Nonprofit
Healthcare
Internet
Law
Leadership & Management
Automotive
Engineering
Software
Recruiting & HR
Retail
Sales
Services
Science
Small Business & Entrepreneurship
Food
Environment
Economy & Finance
Data & Analytics
Investor Relations
Sports
Spiritual
News & Politics
Travel
Self Improvement
Real Estate
Entertainment & Humor
Health & Medicine
Devices & Hardware
Lifestyle
Change Language
Language
English
Español
Português
Français
Deutsche
Cancel
Save
EN
Uploaded by
cloretsblack
PDF, PPTX
8,343 views
機械学習によるリモートネットワークの異常検知
warning of remote network with machine learning
Technology
◦
Read more
20
Save
Share
Embed
Embed presentation
Download
Download as PDF, PPTX
1
/ 27
2
/ 27
3
/ 27
4
/ 27
5
/ 27
6
/ 27
7
/ 27
8
/ 27
9
/ 27
10
/ 27
11
/ 27
12
/ 27
13
/ 27
14
/ 27
15
/ 27
16
/ 27
17
/ 27
18
/ 27
19
/ 27
20
/ 27
21
/ 27
22
/ 27
23
/ 27
24
/ 27
25
/ 27
26
/ 27
27
/ 27
More Related Content
PDF
ネットワーク運用とIoT
by
cloretsblack
PDF
パケットキャプチャでインフラ主導のデバッグ環境を作る
by
cloretsblack
PDF
エンタープライズにおけるOpen flowユースケースを考える
by
cloretsblack
PDF
情シスのひみつ
by
cloretsblack
PDF
JTF2016 The strategy and Sun Tzu
by
irix_jp
PPTX
[事例紹介]スクラッチソフト「XFDを導入してみると」
by
義隆 川路
PPTX
要求開発を補完する現状分析
by
Atsushi Takayasu
PPTX
02.超初心者向けセキュリティ入門(IoT)
by
Study Group by SciencePark Corp.
ネットワーク運用とIoT
by
cloretsblack
パケットキャプチャでインフラ主導のデバッグ環境を作る
by
cloretsblack
エンタープライズにおけるOpen flowユースケースを考える
by
cloretsblack
情シスのひみつ
by
cloretsblack
JTF2016 The strategy and Sun Tzu
by
irix_jp
[事例紹介]スクラッチソフト「XFDを導入してみると」
by
義隆 川路
要求開発を補完する現状分析
by
Atsushi Takayasu
02.超初心者向けセキュリティ入門(IoT)
by
Study Group by SciencePark Corp.
What's hot
PPTX
01.超初心者向けセキュリティ入門
by
Study Group by SciencePark Corp.
PDF
Menoh-Rubyで始めるお手軽簡単なDNN推論アプリ
by
Preferred Networks
PPTX
20171013 Too
by
CloudNative Inc.
PPTX
20180724 Gartner tokyo 2018 shinji
by
CloudNative Inc.
PDF
止めないためのWEBインフラ入門
by
Sho Okada
PPTX
ハードコア デバッギング : サポート直伝!運用中 Windows アプリケーション バグバスター!!
by
TAKUYA OHTA
PPTX
20180727 第16回 セキュリティ共有勉強会(テーマ:身近なセキュリティ )
by
CloudNative Inc.
PPTX
20180112 ssmjp shinji
by
CloudNative Inc.
PPTX
CI/CD専用モニタと心理的安全性
by
Shinya Nakajima
PPTX
CrowdStrike Falconと効果的に楽に付き合っていくために
by
Eiji Hoshimoto
PDF
ハンズオン セッション 3: リカレント ニューラル ネットワーク入門
by
NVIDIA Japan
PDF
これから始める人の為のディープラーニング基礎講座
by
NVIDIA Japan
PDF
「DevSecOpsとは?」の一歩先 (CloudNative Days Tokyo 2021)
by
Masaya Tahara
PPTX
20101022 構成管理勉強会資料
by
Atsushi Takayasu
01.超初心者向けセキュリティ入門
by
Study Group by SciencePark Corp.
Menoh-Rubyで始めるお手軽簡単なDNN推論アプリ
by
Preferred Networks
20171013 Too
by
CloudNative Inc.
20180724 Gartner tokyo 2018 shinji
by
CloudNative Inc.
止めないためのWEBインフラ入門
by
Sho Okada
ハードコア デバッギング : サポート直伝!運用中 Windows アプリケーション バグバスター!!
by
TAKUYA OHTA
20180727 第16回 セキュリティ共有勉強会(テーマ:身近なセキュリティ )
by
CloudNative Inc.
20180112 ssmjp shinji
by
CloudNative Inc.
CI/CD専用モニタと心理的安全性
by
Shinya Nakajima
CrowdStrike Falconと効果的に楽に付き合っていくために
by
Eiji Hoshimoto
ハンズオン セッション 3: リカレント ニューラル ネットワーク入門
by
NVIDIA Japan
これから始める人の為のディープラーニング基礎講座
by
NVIDIA Japan
「DevSecOpsとは?」の一歩先 (CloudNative Days Tokyo 2021)
by
Masaya Tahara
20101022 構成管理勉強会資料
by
Atsushi Takayasu
Similar to 機械学習によるリモートネットワークの異常検知
PDF
R実践 機械学習による異常検知 01
by
akira_11
PDF
時系列分析による異常検知入門
by
Yohei Sato
PDF
異常検知 - 何を探すかよく分かっていないものを見つける方法
by
MapR Technologies Japan
PPTX
機械学習を用いた異常検知入門
by
michiaki ito
PDF
Deep Learning Lab 異常検知入門
by
Shohei Hido
PDF
FIT2012招待講演「異常検知技術のビジネス応用最前線」
by
Shohei Hido
PDF
R実践 機械学習による異常検知 02
by
akira_11
PPTX
Lt talk 2017_0912
by
Kenta Togashi
PDF
Elastic ML Introduction
by
Hiroshi Yoshioka
PDF
Tokyo r15 異常検知入門
by
Yohei Sato
R実践 機械学習による異常検知 01
by
akira_11
時系列分析による異常検知入門
by
Yohei Sato
異常検知 - 何を探すかよく分かっていないものを見つける方法
by
MapR Technologies Japan
機械学習を用いた異常検知入門
by
michiaki ito
Deep Learning Lab 異常検知入門
by
Shohei Hido
FIT2012招待講演「異常検知技術のビジネス応用最前線」
by
Shohei Hido
R実践 機械学習による異常検知 02
by
akira_11
Lt talk 2017_0912
by
Kenta Togashi
Elastic ML Introduction
by
Hiroshi Yoshioka
Tokyo r15 異常検知入門
by
Yohei Sato
More from cloretsblack
PDF
JTF2020に来てください。本物の経営者目線ってやつを見せてやりますよ
by
cloretsblack
PDF
父さんな、パケットキャプチャで食っていこうと思うんだ。
by
cloretsblack
PDF
Rancher2.0のコンテナ間通信を可視化してみた
by
cloretsblack
PDF
パケットキャプチャとIoT
by
cloretsblack
PDF
試してわかるSDN
by
cloretsblack
PDF
情シス戦線異状アリ!? 自作のパケットレコーダーで海外拠点のLANを自動監視してみた
by
cloretsblack
PDF
中国にOpenflowを入れてきた話
by
cloretsblack
PDF
「こんなこともあろうかと用意しておいたぞ」 カッコいいNFVの運用事例 TremaDay#8
by
cloretsblack
PPTX
SDNを導入してみて思った事
by
cloretsblack
JTF2020に来てください。本物の経営者目線ってやつを見せてやりますよ
by
cloretsblack
父さんな、パケットキャプチャで食っていこうと思うんだ。
by
cloretsblack
Rancher2.0のコンテナ間通信を可視化してみた
by
cloretsblack
パケットキャプチャとIoT
by
cloretsblack
試してわかるSDN
by
cloretsblack
情シス戦線異状アリ!? 自作のパケットレコーダーで海外拠点のLANを自動監視してみた
by
cloretsblack
中国にOpenflowを入れてきた話
by
cloretsblack
「こんなこともあろうかと用意しておいたぞ」 カッコいいNFVの運用事例 TremaDay#8
by
cloretsblack
SDNを導入してみて思った事
by
cloretsblack
機械学習によるリモートネットワークの異常検知
1.
機械学習によるリモートネットワークの 異常検知 @Clorets8lack
2.
最初にお知らせ 本日の資料は後ほど公開しますので、リラックスしてお 聞きください 安心してください 数式は出てきません
専門的な内容を期待していた方、すみません
3.
自己紹介 @Clorets8lack 某ユーザー企業の国際インフラ担当
トラブルシューティング専用パケットレコーダー 「Sonarman ソナーマン」を開発 株式会社デベルアップジャパンを設立し、経営、開発、 営業、ユーザーというマルチキャスト(複数役)を実践し つつ奮闘中 自称:意識高い系情シス
4.
今日お話すること 開発の背景 海外の実情に即した異常検知とは
機械学習について 実装について 導入結果 余談
5.
海外のネットワーク管理(ヘルプデスク含む) ってどんな仕事? 距離と時差に大きく制約される – 遅延、損失との戦い (インドでは600msを超えることも) –
なかなか現地に行けない – 現地業者のレベルが様々、横展開できない コスト削減圧力が高い – 現地の人件費が安いため、IT費用が相対的に大き く見える – 「この仕組みを入れると何人減らせるの?」 – 「そしてそれはいくらのコスト削減なの?」 とか言われる
6.
日本では考えられないトラブルの数々 偽物のケーブル スイッチングハブの代わりに使われる無線ルータ
頻発する回線障害(道路工事でケーブル切ったりとかしょっちゅう) 約束という概念が通用しない現地ベンダ 国策による通信のフィルタリング プロバイダのレベルも様々 不可避な災害や気象条件(洪水、地震、雷、静電気等)
7.
海外における運用上の問題 現地ベンダに任せきりになってしまう 現地スタッフは頼りにならない本社情シスには協力してく れない
直接PCを触れない情シスが、現地のために何が出来る か? 1.遠隔でのヘルプデスクサポート(日本品質) 2.現地ベンダの適切なコントロール(チェック機能の提供) 3.高度なトラブルシューティング(効率重視、悪即斬)
8.
[CM] Sonarman(ソナーマン)をつくりました (2ページだけお付き合いください) パケットキャプチャをローテーションしつつ、 継続収集する装置(備えあればうれしい) 障害の原因調査が楽になる –
発生時刻にさかのぼれる – 正常時と異常時の挙動を容易に比較できる 論理的な障害対応(闇雲なトライアンドエラーの排除) 「再現を待たなくていい」という利便性 遠隔サポート業務のコスト(時間)を大幅に削減する
9.
実物 この製品に機械学習による障害検知 機能を搭載した ● ファンレス小型筐体 ● Web UI ●
x64アーキテクチャの小型サーバ ● 別途、スイッチのポートミラーリング機能 が必須 ● 無償VM版を公開中 http://develup-japan.co.jp/wp/works/sonarman-free-edition/
10.
障害検知に必要な機能 パケットキャプチャは容量が大きすぎて扱いづらい – 巨大サイズは宿命 –
L7デバッグができることとのトレードオフ 一定サイズに細切れにされたキャプチャ毎に、どのよう な異常が検出されたのかを可視化する必要がある あと、通知もしてほしい でも、しょうもない警告がバンバン来るのは勘弁な
11.
ネットワークの異常検知とはどうあるべきか 国、地域、規模、業種、使用機材、生活態様等によって、 ネットワークの状態は様々に変化する 画一的な閾値やフィルタのようなものは設定しづらい
一方、エラーは容易に検出できるが本質的に解決すべ きでない事もある – PassMTUなどで発生する ICMP Host Unreachable – 公衆網上の損失など不可避な性質を持つ物 普段とは違う、異常事態を検知する事が出来ないか
12.
1.パケットキャプチャを統計的に解析する事により、エ ラーカウンタや異常を示す兆候を収集し、内部データ ベースに蓄積する 2.データに基づき、その環境における「普段の状態」を 定義する 3.「普段の状態」を明らかに逸脱した現象をとらえて警 告する 「普段」の定義
13.
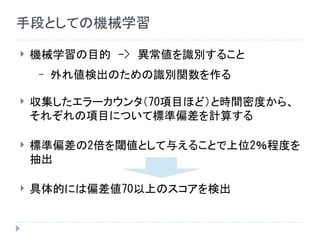
手段としての機械学習 機械学習の目的 -> 異常値を識別すること – 外れ値検出のための識別関数を作る
収集したエラーカウンタ(70項目ほど)と時間密度から、 それぞれの項目について標準偏差を計算する 標準偏差の2倍を閾値として与えることで上位2%程度を 抽出 具体的には偏差値70以上のスコアを検出
14.
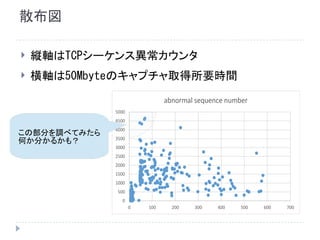
散布図 縦軸はTCPシーケンス異常カウンタ 横軸は50Mbyteのキャプチャ取得所要時間 0 500 1000 1500 2000 2500 3000 3500 4000 4500 5000 0
100 200 300 400 500 600 700 abnormal sequence number この部分を調べてみたら 何か分かるかも?
15.
データの性質 各データはパケットキャプチャから抽出した、独立したエ ラーカウンタであり、それぞれの値の相関は薄い(時間密 度のみ考慮) 相関が薄いため高次元の特徴抽出は必要ない
カウンタが少ない、または時間密度が低い場合は検出 不要 カウンタ別警告レベルの重みづけ自動化は今後の課題 – ゆくゆくは教師あり学習に放り込みたい
16.
結局やりたいこと is 何? 通常の範囲でバシバシ出るエ ラーは無視して、シャバそうな やつだけ教えて?
17.
実装の概要 偏差スコアの精度を高めるため、標本となるデータは過 去の同一時間帯、月末月初、曜日などを考慮して収集 機械学習だけでなく、一発レッドなエラーはフィルタとして 個別に実装
一発レッドな例 – Bittorrent (フラッディングによるポート枯渇) – SMTP レスポンスエラー (400番以上の頻発) – SMB I/Oタイムアウト (Disk故障の予兆) – DHCP NAK (IP Pool枯渇)
18.
エラーカウンタの実装 パケットキャプチャがあるので、L7まで元気よく読む Deep
Packet InspectionをCで実装 – libpcapを使用 – IPv6周りの実装が面倒(小並感) 省力化目的で一部 Wiresharkのフィルタを使う – TCPシーケンス異常系検出は便利 実網の運用経験を活かして警告パラメータを実装
19.
実際の導入について 海外での導入実績 – 海外拠点LANの監視 –
OpenFlowでスイッチのポートミラーリング機能を制御 – 海外3拠点に導入(従業員60名未満の拠点) 国内での導入実績 – 基幹系システムの夜間処理監視 – 時差のきつい地域からのサーバアクセス監視
20.
海外拠点での使用方法 LAN内のWindowsサーバでキャプチャ &
ローテーション VirtualBox上でSonarmanのVMを動かす – Windows上のキャプチャ格納ディレクトリをVMと共有 – VMからキャプチャファイルを参照しつつ機械学習 – 問題発生時にはVMから警告メールを飛ばす ミラーリング cap SonarmanVM 警告メール 異常
21.
見つけたもの 異常値には何らかの問題が介在している例が殆ど DNSエラー -> ルータに設定したDNSサーバの故障を検知
ARP重複 -> BYODのAndroid端末のdhcpd不具合、なぜか古いアドレ スを適切に開放できておらず、IPが被る TCPコネクション毎の累積転送量 -> 巨大ダウンロードの検出 TCP/UDP比率 -> ウイルス検出 TCP再送 -> 現地NASで再送多発、20-30%程度の通信容量ロス インタ フェースのネゴシエーション不良?(調査中) かなり良い精度で問題に到達できている (というかエラーをカウントしているから、ある意味当然)
22.
導入した感想 今まで見えなかった問題が可視化されるため結構仕 事が増えた 米国など日本との時差のきつい地域ではサポートレベ ルが向上した(外人特有のオーバーリアクションで超感謝される)
夜間処理エラーなどの原因も切り分けたので、他人の仕 事も増やしたw 困ったときの頼れる可視化ツール 面倒事が舞い込む恐怖の可視化ツールでもある。。
23.
[余談] 製品開発と営業活動の軌跡 自分が欲しいものを作る これ超便利だし絶対売れるよ(ソースは俺)
情シス(同業者)の人たち、あんまり興味無さそう。。 あ、あれ? ← New
24.
わかったこと 新しい気付き! 圧倒的感謝(笑)
25.
半年ほど(ユーザー情シスに)営業した感想 色々な情シス部門が存在する(ワタシ含め) – アウトソースの管理業務が多い –
バリバリキャプチャ読む人にはリーチしにくい 可視化にも意欲的でない? – 「可視化ツール入れたけど見てない」例多し 前からちょっと思ってたけど、ターゲット間違ってね? うわっ…私の戦略、ダメすぎ?
26.
今後どうすんの? やっぱり価値の分かる人と組まないとムリ 問題発見ツールとして提案活動とコラボすると強力 –
エンドユーザーへの提案実績はボチボチ出始めた 顧客の了解を取った上で、サポートツールとして導入し、 ソリューション営業のツールとしても使っていく 局所的なパケットから問題を検知する技術を考えていく
27.
ありがとうございました お気軽にコンタクトいただければ 嬉しく思います @Clorets8lack
Download








![[CM] Sonarman(ソナーマン)をつくりました
(2ページだけお付き合いください)
パケットキャプチャをローテーションしつつ、
継続収集する装置(備えあればうれしい)
障害の原因調査が楽になる
– 発生時刻にさかのぼれる
– 正常時と異常時の挙動を容易に比較できる
論理的な障害対応(闇雲なトライアンドエラーの排除)
「再現を待たなくていい」という利便性
遠隔サポート業務のコスト(時間)を大幅に削減する](https://image.slidesharecdn.com/random-160301154841/85/slide-8-320.jpg)












![[余談] 製品開発と営業活動の軌跡
自分が欲しいものを作る
これ超便利だし絶対売れるよ(ソースは俺)
情シス(同業者)の人たち、あんまり興味無さそう。。
あ、あれ? ← New](https://image.slidesharecdn.com/random-160301154841/85/slide-23-320.jpg)









![[事例紹介]スクラッチソフト「XFDを導入してみると」](https://cdn.slidesharecdn.com/ss_thumbnails/xfd-120729014834-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)


































