More Related Content
Similar to tradictional DR solution vs Active-active solution
Similar to tradictional DR solution vs Active-active solution (20)
tradictional DR solution vs Active-active solution
- 2. 2. 为什么不使用 PPRC:
A.SVC 实现的高可用方案比起传统的 PPRC 方式,能够减少甚至避免业务中断时间
B.SVC 实现的高可用方案比起传统的 PPRC 方式,大大简化了人手系统恢复的过程,也意味着大大减低人手误操作的可能和带来的风险
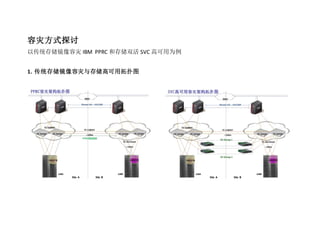
2.1 故障情景分析:
PPRC SVC 比较结果
编号 故障场景 业务影响 PPRC 业务恢复流程 备注 业务影响 SVC 业务恢复流程 备注
1
生产主机设备
发生故障,
业务中断,大约
10 分钟以内;通
过 PowerHA 由
siteB 的备用 AIX
主机自动接管
应用根据PowerHA配置模式
自动或手工回切资源组
业务中断,大约 10
分钟以 内; 通过
PowerHA 由 siteB
的备用 AIX 主机自
动接管
应用根据 PowerHA
配置模式自动或手
工回切资源组
一样
- 3. 2
生产存储设备
发生故障
存储 A 发生故
障
业务中断
2 小时-5 小时
16 个步骤:
1. 生产主机降级
2. 容灾主机升级
3. 停止 FlashCopy 卷更新
定时任务
4. 在容灾 端存储 上修改
lun mapping
5. 在容灾 端存储 上执行
failover
6. 停止 HACMP
7. 并重启主机
8. 删除 VM 上生产端存储
的设备
9. 删除两台 VIOS 上的生产
存储的设备 1. Redev 删
除虚拟设备 2.rmdev 删
除物理设备
10. 在两台 VIOS 上重
新发现容灾端存储的设
备,并修改 LUN 属性为
no_reserve
11. 在两台 VIOS 上使
用 mkvdev 命令重建虚
拟硬盘
12. 在 VM 上重新识别
容 灾 存 储 设 备 , 并
VIOS 重新认存储
B 硬盘的时候,
hdisk 序号可能与
原先的不一致,
需要人手查看存
储 B 中每个 LUN
ID,以确保存储 B
中的 LUN 正确映
射到每个虚拟机
上
业务无中断 / SVC 需要大概
数十秒的时间
自动检测并确
定生产存储的
故障,然后自
动切换到另一
存储
SVC 避免业
务中断,不
需要人为恢
复
- 4. importvg。
13. 启动 HACMP,并检
查其状态、文件系统和
数据库是否启动
14. 把相应的文件系统
mount 进来,启动数据
库
15. 数据库扫硬盘,做
数据完整性检验(耗时
取决于数据库的大小和
表之间的关联程度)
16. 启动应用
3
site 交换机设
备发生故障
site A 存储网络
发生故障,生产
主机访问不到
生产存储 A 和
容灾存储 B
业务中断 2 小时
-5 小时
14 个步骤:
1. 生产主机降级
2. 容灾主机升级
3. 停止 FlashCopy 卷更新
定时任务
4. 在容灾 端存储 上修改
lun mapping
5. 在容灾 端存储 上执行
failover
6. 停止HACMP并重启容灾
主机
7. 删除 VM 上生产端存储
的设备
8. 删除两台 VIOS 上的生产
VIOS 重新认存储
B 硬盘的时候,
hdisk 序号可能与
原先的不一致,
需要人手查看存
储 B 中每个 LUN
ID,以确保存储 B
中的 LUN 正确映
射到每个虚拟机
上
业务中断大约 1 小
时
3 个步骤:
步骤1,2同时进行,
并且无须人工干预
1. SVC自 动 切 换 到
使用site B SVC
节点和存储B,无
须人工干预。
2. 应 用 根 据
PowerHA 配 置 模
式自动关闭生产
端的应用和资源
组,再在容灾端
自动启动资源组
和应用,无须人
SVC 会有数十
秒自动检测并
确认生产存储
网络连接已经
断开
SVC 减少业
务中断,不
需要人为恢
复
- 5. 存储的设备 1. Redev 删
除虚拟设备 2.rmdev 删
除物理设备
9. 在两台 VIOS 上重新发现
容灾端存储的设备,并
修 改 LUN 属 性 为
no_reserve
10. 在 两 台 VIOS 上 使 用
mkvdev 命令重建虚拟硬
盘
11. 在 VM 上重新识别容灾
存储设备,并 importvg。
12. 把 相 应 的 文 件 系 统
mount 进容灾 AIX 主机,
启动数据库
13. 数据库扫硬盘,做数据
完整性检验(耗时取决
于数据库的大小和表之
间的关联程度)
14. 启动应用
工干预。
3. 重启数据库和
应用(耗时取决
于数据库的大
小和表之间的
关联程度)
4
整个生产站点
设备全部发生
故障(灾难)
业务中断 2 小时
-5 小时;siteA 的
业务由siteB 接管
14 个步骤:
1. 生产主机降级
2. 容灾主机升级
3. 停止 FlashCopy 卷更新
定时任务
4. 在容灾 端存储 上修改
业务中断大约 1 小
时-1.5 小时
3 个步骤:
步骤 1,2 同时进行,
并且无需人工干预:
1. SVC 自动切换到
使用 site B SVC
节点和存储 B
在 SVC 自动切
换前,SVC 需
要 1 分多钟确
认生产站点发
生存储,SVC
节点,存储网
SVC 减少业
务 中 断 时
间,不需要
人为恢复
- 6. lun mapping
5. 在容灾 端存储 上执行
failover
6. 停止HACMP并重启容灾
主机
7. 删除 VM 上生产端存储
的设备
8. 删除两台 VIOS 上的生产
存储的设备 1. Redev 删
除虚拟设备 2.rmdev 删
除物理设备
9. 在两台 VIOS 上重新发现
容灾端存储的设备,并
修 改 LUN 属 性 为
no_reserve
10. 在 两 台 VIOS 上 使 用
mkvdev 命令重建虚拟硬
盘
11. 在 VM 上重新识别容灾
存储设备,并 importvg。
12. 把 相 应 的 文 件 系 统
mount 进容灾 AIX 主机,
启动数据库
13. 数据库扫硬盘,做数据
完整性检验(耗时取决
于数据库的大小和表之
2. 应 用 根 据
PowerHA 配置模
式自动或手工回
切资源组。
3. 重启数据库和应
用(耗时取决于
数据库的大小和
表之间的关联程
度)
络均不可访问
- 7. 间的关联程度)
14. 启动应用
2.2 SVC 切换的监控:
SVC 有非常友好的用户界面,可以直观地看到目前 SVC 的状况:
e.g.
Volume01 已经成为一个 virtual disk 虚拟卷,其对应 copy0*,copy1 两个镜像卷,两个镜像卷分别来自两个本地生产存储和异地容灾存储,copy0* 的“*”
表示这个是来自与源卷,表示主机系统系统正在使用那台存储设备;详细关系如下图;假如应为生产存储故障,SVC 自动发生了存储切换,在这个界面可
以看到生产存储的卷被挂起处于 OFFLINE 状态。当然存储管理员也可以在存储监控页面查看甚至设置报警信息。
在管理界面下的 running task,可以查看到原来的 volume01 正在与 copy1 进行数据复制。
- 9. 3.为什么使用 2 对 4 个 SVC 设备:
3.1 保证 SVC 设备具有可用性:
编号 故障场景 业务影响 恢复方法
- 10. 1 单节点故障 业务无中断,受影响 IOG cache 变为 writethrough 模式 快速在线更换节点
2 不同 IOGroup 多节点故障 业务无中断,受影响 IOG cache 变为 writethrough 模式 快速在线更换节点
3 同一 IOG 双节点故障 业务中断 1-2 小时 1.后端存储快速退出 SVC(只针对 imagemode VDisk)
2.有可能的条件下,迁移 Vdisk 到其他 IOG
3.容灾切换
假如只使用 1 对 2 个 SVC 设备,则不具备场景 2 和 3 的故障保护能力。
3.2 系统性能考虑:
SVC 加入现有系统环境后,则主机访问存储的 IO 会经过 SVC,也就是 IO 流为“AIX 主机->SVC->存储”,我们需要保证 SVC 不会成为 IO 的瓶颈。
主机性能:
P750 每台 32 核 3.5GHz,线性 tpmC 值为 370 万,按照经典 OLTP 环境,
1tpmC 大约产生 30 个 IO,也 就是:
1tpmC =1 条交易/每分钟 =30 个 IO
故此处理一条交易过程中,每秒处理 30/60=0.5 个 IO, 即 0.5IOPS
则 370 万 tmpC 值的 POWER P750 理论上可以支撑 150 多万 IOPS,服务
器不多可能成为瓶颈;
存储性能:
存储设备 V7000,单台最大配置 240 块硬盘,假设硬盘几乎满配,
使用 224 个 15K FC 硬盘,使用性能估算工具按照经典 OLTP 环境 30%写
操作,70%读操作,DB2 块大小 8KB,2 台服务器在上面运行计算得,V7000
最大可以承受 64000 万 IOPS:
- 11. SVC 必须能够支撑 IOPS 大于 V7000 应用系统才能不成为整个系统的瓶颈 – 故此,SVC 需要能够支撑应用系统 IOPS 值得必须大于 64000IOPS。
SVC 性能:
SPC-1 测试值,可查看以下链接:
http://www.storageperformance.org/benchmark_results_files/SPC-1/IBM/A00113_IBM_SVC-6.2_Storwize-V7000/a00113_IBM_SVC-v6.2_Storwize-V7000_SPC-1_e
xecutive-summary.pdf
从 SPC-1 测试报告中说明,在 mirrorning 的环境,也就是本次项目使用的两端存储镜像实现数据复制的环境下,SVC 6.2 版本 8 个节点能够支持 52 万 IOPS;
由于 SVC 节点结构的特性,性能几乎线性扩展(从 SVC 5.2 版本 SPC-1 值, 4 个节点差不多 30 万,6 个节点 39 万可见,基本上是线性扩展的),故可以推
算 2 对 4 个 SVC 节点可支持吞吐量大于 26 万 IOPS;由于 SVC 镜像,故支持应用系统吞吐量为 13 万。
如果应用系统能够达到 13 万 IOPS,在一般 OLTP 系统上,写操作约占总 IO 的 30%,考虑存储层 RAID5 写惩罚 4 倍,假设系统总吞吐量为 X,则:
X*30%*4+X*0.7=13 –> X=6.8
则意味着这个双活系统可以支持生产应用系统每秒 6.8 万 IO 的吞吐量。