1. Econometrie, prof. Aniela Danciu pag. 1/8 15-Oct.-2011
Regresia liniara unifactoriala
Liniara, adica legatura intre x si y, y depinde de un singur factor, x.
Aplicatie:
Se cunosc datele referitoare la distanta parcursa de un autovehicul din momentul franarii si pana la
oprire si respectiv viteza autovehiculului in momentul franarii.
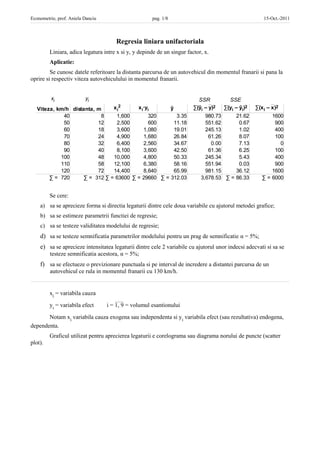
xi yi SSR SSE
Viteza, km/h distanta, m x i2 x i∙yi ŷ ∑(ŷi – y)2 ∑(yi – ŷi)2 ∑(x i – x)2
40 8 1,600 320 3.35 980.73 21.62 1600
50 12 2,500 600 11.18 551.62 0.67 900
60 18 3,600 1,080 19.01 245.13 1.02 400
70 24 4,900 1,680 26.84 61.26 8.07 100
80 32 6,400 2,560 34.67 0.00 7.13 0
90 40 8,100 3,600 42.50 61.36 6.25 100
100 48 10,000 4,800 50.33 245.34 5.43 400
110 58 12,100 6,380 58.16 551.94 0.03 900
120 72 14,400 8,640 65.99 981.15 36.12 1600
∑ = 720 ∑ = 312 ∑ = 63600 ∑ = 29660 ∑ = 312.03 3,678.53 ∑ = 86.33 ∑ = 6000
Se cere:
a) sa se aprecieze forma si directia legaturii dintre cele doua variabile cu ajutorul metodei grafice;
b) sa se estimeze parametrii functiei de regresie;
c) sa se testeze validitatea modelului de regresie;
d) sa se testeze semnificatia parametrilor modelului pentru un prag de semnificatie α = 5%;
e) sa se aprecieze intensitatea legaturii dintre cele 2 variabile cu ajutorul unor indecsi adecvati si sa se
testeze semnificatia acestora, α = 5%;
f) sa se efectueze o previzionare punctuala si pe interval de incredere a distantei parcursa de un
autovehicul ce rula in momentul franarii cu 130 km/h.
xi = variabila cauza
yi = variabila efect i = 1, 9 = volumul esantionului
Notam xi variabila cauza exogena sau independenta si yi variabila efect (sau rezultativa) endogena,
dependenta.
Graficul utilizat pentru aprecierea legaturii e corelograma sau diagrama norului de puncte (scatter
plot).
2. Econometrie, prof. Aniela Danciu pag. 2/8 15-Oct.-2011
80
70
60
50
40
y
distanta, m
30
1 cm OX = 20km/h
1 cm OY = 10 m
20
10
0
≈
30 40 50 60 70 80 90 100 110 120 130
x
N-am respectat scara pe acest interval
Unim primul cu ultimul punct. De pe grafic se observa ca intre cele 2 variabile exista o legatura
directa. Ecuatia este:
{ yy=abx
=abx
ŷ = valori ajustate (teoretice), rezulta din model; ε = eroarea
functii (ecuatii) de regresie liniara unifactoriala.
b.) estimarea parametrului a si b ai functiei de regresie se face cu ajutorul celor mai mici patrate
(MCMMP):
„Suma patratelor abaterilor valorilor reale yi de la valorile ajustate ŷi este minima” sau suma
patratelor erorilor este minima.
n n
2 2
∑ y i− yi =minim=∑ yi −a−bx i =minim
i=1 i=1
adica cand derivatele in raport cu a si b se anuleaza (conf. teoriei lui Fermat)
df
{ {
n n
==> n⋅ab⋅∑ x i =∑ yi <==
da
=0 ∑ xi=720
n
i=1
n
i=1
n
∑ y i=312
a⋅∑ xi b⋅∑ x =∑ xi⋅y i 2
i <==
df
=0
∑ x2 =63600
i
i=1 i=1 i=1 db ∑ 2 2
xi ⋅yi =29660
{9a720b=312
720a 63600b=29660 ==> {a=−27,97
b=0,783 ==> ŷ = -27,97 + 0,783∙x
a s.n. termen liber, b s.n. coeficient de regresie si ne arata directia legaturii dintre y si x.
– daca b > 0 avem o legatura directa intre y si x (creste x, creste y)
– daca b < 0 avem o legatura indirecta intre x si x (creste x, scade y)
– daca b = 0 nu exista legatura intre y si x (creste x, y = contant)
3. Econometrie, prof. Aniela Danciu pag. 3/8 15-Oct.-2011
b = 0,783 > 0; la o crestere cu 1 km/h a vitezei (o crestere cu o unitate de masura a lui x) distanta
parcursa va creste cu 0,783 m (y va creste cu b unitati de masura).
c.) Testarea validitatii modelului de regresie
La nivelul esantionului modelul de regresie are forma:
y = – 27,97 + 0,783x + ε
a b
La nivelul colectivitatii generale din care a fost extras esantionul modelul de regresie are forma:
y = α + βx + u
Testarea validitatii modelului se face cu testul F (Fischer – Snedecor), respectiv cu ajutorul tabelului
ANOVA (analiza de variatie)
Testarea validitatii
1. Se stabilesc ipotezele nula (H0) si alternativa (H1)
H0 = „modelul nu este valid” (nu exista deosebiri esentiale intre imprastierea valorilor lui y datorate
factorului x si imprastierea valorilor lui y datorate erorii)
H1 = „modelul este valid” (imprastierea valorilor lui y datorate factorului x difera semnificativ de
imprastierea valorilor lui y datorate erorii)
2. Se stabileste testul statistic ce va fi utilizat si se calculeaza valorile testului pe baza datelor din
esantion.
s2
x
F= 2 Unde s2x = dispersia valorilor lui y datorate factorului x
su
n k – numarul factorilor de influenta din model (numarul de
2
∑ y i − 2
SSR i=1
y variabile cauza); k =1 – depinde de un singur factor.
s x= =
k 1 SSR = sum of squares of regression (suma patratelor datorate
factorului = varianta factoriala)
n
SSE
∑ yi− yi 2
2
su = = i= 1 = dispersia erorilor k = numarul variabilelor cauza
n−k −1 9−1−1
SSE = sum of squares of errors – suma
patratelor erorilor – varianţa reziduala
∑ y i − i 2=SSR=3678,53
y ∑ yi − y i 2=SSE=86,33
==> s2x = 3678,53 s2u = 86,33 / 7 = 12,33 ==> F = 3678,53 / 12,33 = 298,33
3. se stabileste regiunea critica si se formuleaza concluzii (daca se respinge sau se accepta ipoteza
alternativa)
Regiunea critica, Rc, reprezinta acele valori ale testului statistic pentru care ipoteza nula se respinge.
Rc e astfel aleasa (construita) incat probabilitatea ca valoarea testului sa se gaseasca in regiunea
critica, desi ipoteza nula e falsa, sa fie foarte mica, adica sa fie egala cu un α numit prag de
semnificatie foarte mic (de ex. α = 0,01; 0,05)
α = P (resping H0 / desi H0 e adevarata); P – probabilitatea
(1 – α)∙100 reprezinta probabilitatea cu care garantam rezultatele.
Daca: Rc : Fcalc ≥ Fαjkj n – k – 1 ==> respingem H0 si acceptam H1
df2 = ajkj; df1 = n – k – 1; Fαjkj n – k – 1 = F tabelat sau F critic
Fcalc = 298,33; Fα = 0,05 = valoarea erorii; k = 1 (un singur factor); n–k–1=7
4. Econometrie, prof. Aniela Danciu pag. 4/8 15-Oct.-2011
Rc: 298,3 ≥ F0,05;1;7 F0,05;1;7 = 5,58 (se ia din
n–k–1
k tabel) ==>
1 2 3 4 5 6 7
se respinge ipoteza H0 si se accepta H1 conform
1 5,58
careia modelul este valid.
2
3
4
5
6
7
Tabelul ANOVA (furnizat de excel pentru testarea validitatii modelului, 6 coloane si 3 randuri)
Sursa variatiei SS (sum of squares) df MS (mean of F Significance F
squares) (prag de semnificatie)
Regression SSR = 3678,53 K=1 s2x = 3678,53 s2
x
Se compara cu
(variatia datorata 2 =298,33
pragul de
factorului x) s u semnificatie α dat
2 in problema.
Reziduals (variatia SSE = 86,33 n–k–1=7 s u = 12,33
datorata erorii) sig F ≤ α – model
Se compara cu F valid
Total (variatia SST = SSR + n–1=8 s2u = SST / n-1 = tabelat sig F > α – model
totala) SSE = 3764,86 (suma celor doua) invalid
471,1
(varianta totala)
df – numitoare de dispersii MS – media patratelor sau dispersii corectate
MS = SS / df
La examen tabelul va fi completat si vor trebui interpretate rezultatele.
d.) Testarea semnificatiei parametrilor modelului
La nivelul esantionului modelul de regresie are forma:
yi = - 29,97 + 0,783 xi + εi (a = -29,97; b = 0,783)
La nivelul colectiei generale modelul de regresie are forma:
yi = α + β xi + ui
Testarea semnificatiei parametrului β
1. H0: β = 0 (β nu e semnificativ statistic)
H1: β ≠ 0 ( β e semnificativ statistic) = test bilateral (pentru ca e diferit de zero si nu mai mare sau
mai mic)
2. se alege testul statistic
b−0
Z=
daca n ≥ 30 se aleg testul Z aferent repartitiei normale sau functiei Gauss Laplace sp
b−0
t=
daca n < 30 atunci se utilizeaza testul t aferent repartitiei Student sb
cum n = 9 ==> n < 30 ==> avem esantion de volum redus si pentru testare utilizam testul t
5. Econometrie, prof. Aniela Danciu pag. 5/8 15-Oct.-2011
b−0 b 0,783 s2 12,33
9
t= = = =17,79 2
s= u
= =0,002 ∑ xi
sb sb 0,002 b n
6000 720
∑ xi−
x 2
x i=1 =
= =80 km/ h
i=1
9 9
Se stabileste regiunea critica si se formuleaza concluziile
Regiunea critica Rc: tcalc < – tα/2; n-k-1 (ramura cu –); pentru ca e test bilateral se imparte α la 2
sau
tcalc > tα/2; n-k-1 (ramura cu +) tα/2; n-k-1 = t tabelat sau t critic = 2,998; tcalc = 17,79 (A)
0,05/2 7
n-k- α 0,025
1
1 | ==> testul este adevarat, ne gasim in regiunea critica ==> se respinge H 0 si se
| accepta H1 ==> parametrul β e semnificativ statistic (pt α = 5%).
2
| Deoarece parametrul β e semnificativ statistic putem determina intervalul de
3 | incredere pentru acesta.
4 |
| lower (in excel) upper pt 5%
5 | b – tα/2; n-k-1 ∙ sb ≤ β ≤ b + tα/2; n-k-1 ∙ sb
6 | 0,783 2,998 0,044
| 0,11 0,794
7 – – 2,998 0,772
La nivelul esantionului β = 0,783, la nivelul colectivitatii generale β se situeaza intre
0,772 si 0,794 pentru α = 5%.
Daca modelul este valid obligatoriu si parametrul β e semnificativ statistic.
Testarea semnificatiei parametrului α.
H0: α = 0 (α nu e semnificativ statistic)
H1: α ≠ 0 (α este semnificativ statistic) ==> test bilateral
pentru ca n = 9 < 30, utilizam testul t
a−0 a −27,97
t= = = =−15,62
sa sa 3,2 sa se ia din ANOVA
[ ] [ ]
2 2 1 x2
1 802
sa =su n =12,33⋅ =3,20
n 9 6000
∑ x i − 2
x
i=1
Rc, regiunea critica:
-15,62 - 2,998 (A)devarat ==> ne gasim in regiunea critica ==> se respinge ipoteza
tcalc < – tα/2; n-k-1 nula si se accepta ipoteza alternativa conform careia α e semnificativ
statistic.
tcalc > tα/2; n-k-1
Pentru ca parametrul α este semnificativ statistic putem determina
intervalul de incredere pentru acesta:
a – tα/2; n-k-1 ∙ sa ≤ α ≤ a + tα/2; n-k-1 ∙ sa unde a = -27,97 sa = 1,79
tα/2; n-k-1 = 2,998
==> –33,33 ≤ α ≤ -22,61
La nivelul colectivitatii generale parametrul α [ -33,33; -22,61] pentru un prag de semnificatie de 5%
6. Econometrie, prof. Aniela Danciu pag. 6/8 15-Oct.-2011
Observatie: cand lower si upper au celasi semn pentru un parametru, respectivul parametru este
semnificativ statistic.
Tabelul din excel (tab. 3) pe baza caruia testam semnificatia parametrilor modelului:
Coefficient Standard Testul statistic P value (prag de Lower 5% Upper 5%
error semnificatie)
Intercept a = -27,97 sa = 1,79 a -33,33 -22,61
(termenul liber) t a= =
sa
−15,62
x variable b = 0,783 sb = 0,044 a 0,772 0,794
(variabila x, viteza) t b= =
sb
17,79
Pentru ca b >0 coeficient Se compara cu Interval de
t=
==> legatura standard error pragul de incredere; daca
directa se compara cu tcrit semnificatie dat in upper si lower au
problema (5%) acelasi semn sunt
sau cu -tcrit
semnificative.
Daca P value ≤ α ==> parametrul e semnificativ statistic, in caz contrar nu este.
e.) Intensitatea legaturii dintre doua sau mai multe variabile se poate aprecia cu ajutorul urmatorilor
indicatori:
(1) Raportul de corelatie R (multiple R) se poate utiliza pentru toate tipurile de legaturi si ne arata doar
intensitatea legaturii nu si directia ei. Directia se deduce doar din semnul lui b.
R [0, 1]
Daca R = 0 nu exista legatura intre variabile;
Daca R → 1, legatura este foarte puternica intre variabile.
R=
SSR
SST
=
3678,53
3764,86
=0,988 SSR si SST se iau din ANOVA
2 SSR
R= =0,97
SST = R square = grad de determinatie, [0, 1] si ne arata cat la suta din variatia lui
y se datoreaza factorului x; in cazul nostru 97% din variatie (a lui y) se datoreaza lui x.
Testarea raportului de corelatie la nvelul colectivitatii generale
1. Ipoteza nula, H0: raportul de corelatie la nivelul colectivitatii generale nu e semnificativa statistic
H1: raportul de corelatie la nivelul colectivitatii generale e semnificativa statistic.
2. Se stabileste testul statistic
pentru testarea semnificatiei raportului de corelatie se utilizeaza testul Fischer (testul F)
R 2 n−k −1 0,97 7
F= 2⋅ = ⋅ =226,33
1−R k 1−0,97 1
3. se stabileste regiunea critica si se formuleaza concluziile
pentru testul F:
Fcalc ≥ Fα, k, n-k-1 Fα, k, n-k-1 = Ftabelat = 5,58; Fcalc = 226,33
==> Adevarat, ne gasim in regiunea critica, se respinge H 0 si se accepta H1 ==> raportul de corelatie
e semnificativ statistic.
Observatie: daca modelul este valid atunci si parametrul β e semnificativ statistic si raportul de
7. Econometrie, prof. Aniela Danciu pag. 7/8 15-Oct.-2011
corelatie e semnificativ statistic.
(2) coeficientul de corelatie propus de Pearson notat cu r ce se poate utiliza doar in cazul in care vem
legatura liniara intre variabile si pe baza lui putem deduce atat intensitatea legaturii cat si directia ei
n
n ∑ x i yi −∑ x i ∑ y i
i=1 9⋅29660−720⋅312
r= = =0,988
[n ∑ x − ∑ x ]⋅[ n ∑ y − ∑ y ] [9⋅63600−720 ]⋅[ 9⋅14584−312 ]
2 2 2 2
2 2
i i i i
r [-1, 1]
daca:
r > 0 ==> legatura directa intre y si x
r < 0 ==> legatura inversa intre y si x
r = 0 ==> nu exista legatura intre y si x
r → ± 1 ==> legatura foarte puternica intre y si x
cum r = 0,998 ==> intre y si x exista o legatura directa si foarte puternica
Observatie: daca | r | = R ==> legatura liniara a fost foarte bine aleasa.
Deoarece in cazul nostru r = R = 0,988 ==> legatura dintre y si x e o legatura liniara.
f.) Previzionarea punctuala reprezinta valoarea previzionata obtinuta prin inlocuirea valorii date in
ecuatia de regresie (reprezinta previziune la nivelul esantionului)
xn+p = 130 km/h
ŷn+p = -27,97 + 0,783∙xn+p = 73,82 m (previzionare punctuala)
Previzionarea pe baza intervalului de incredere.
ŷn+p – tα/2; n-k-1∙ sŷn+p ≤ ŷn+p ≤ ŷn+p+ tα/2; n-k-1∙ sŷn+p ŷn+p= 73,82; tα/2; n-k-1= 2,998
60,81 86,82
[ ] [ ]
2 2
1 x −
x 1 130−80
s2 n p=su 1 n np
y 2
=12,33 1 =18,827 s2u = 12,33, se ia din ANOVA
n 9 6000
∑ xi−
x 2
i= 1
Tabelul 1 din excel se refera la intensitatea legaturii dintre variabile:
Multiple R, (R) = 0,988
R Square, (R2) = 0,97 [0, 1]
Adjusted R Square (R2) = grad de determinatie ajustat = R Square impartit la gradele de libertate
corespunzatoare.
SSE
2 SSE n−k −1 SSE⋅n−1
R =1− =1− =1−
SST SST SST⋅n−k −1
n−1
Standard error = abaterea standard a erorilor = s u
2
su = su se ia din ANOVA
daca su = 0 nu ar exista eroare, toate punctele s-ar gasi pe o dreapta de regresie ==> valorile reale
sunt egale cu valorile ajustate.