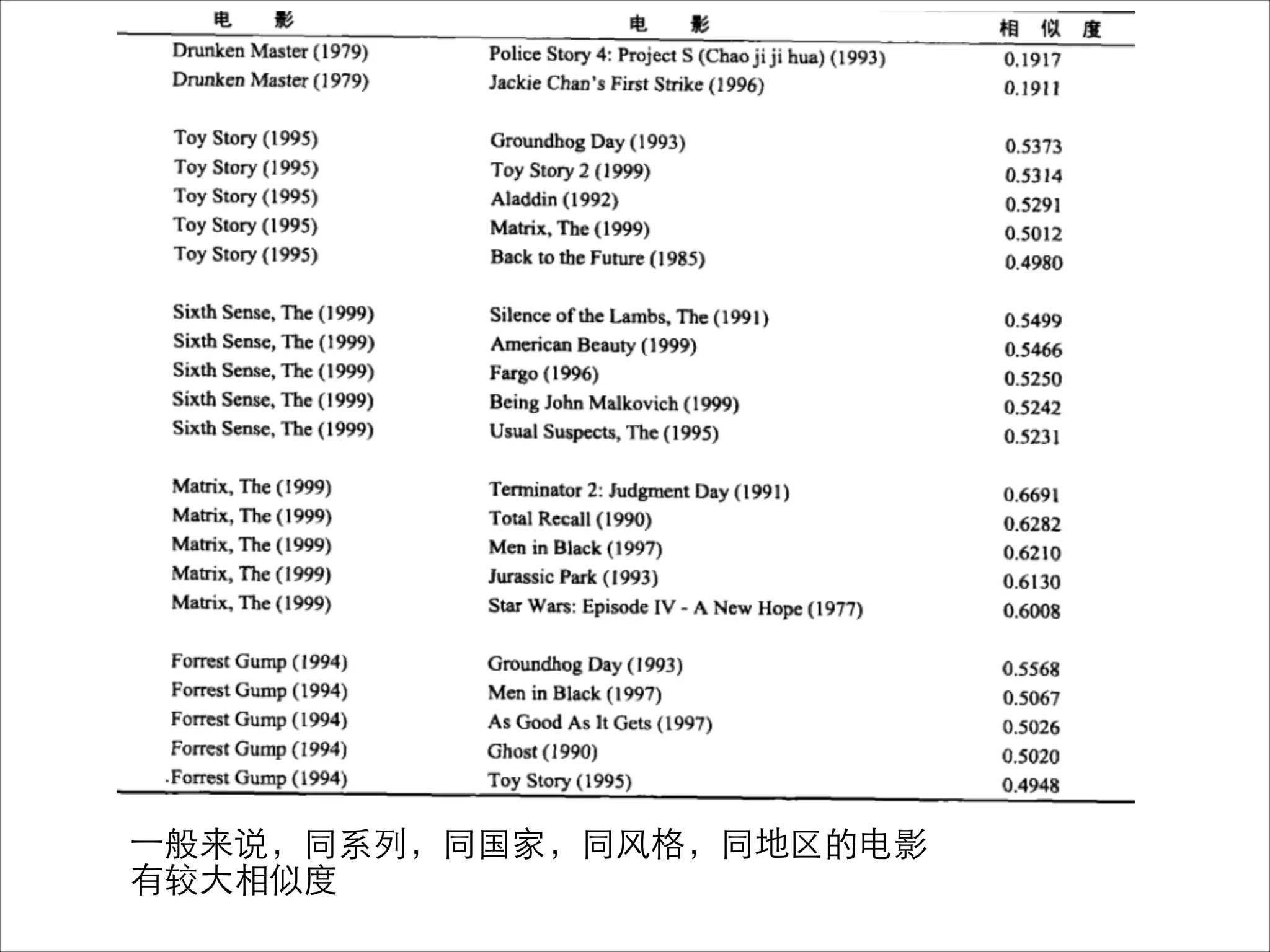
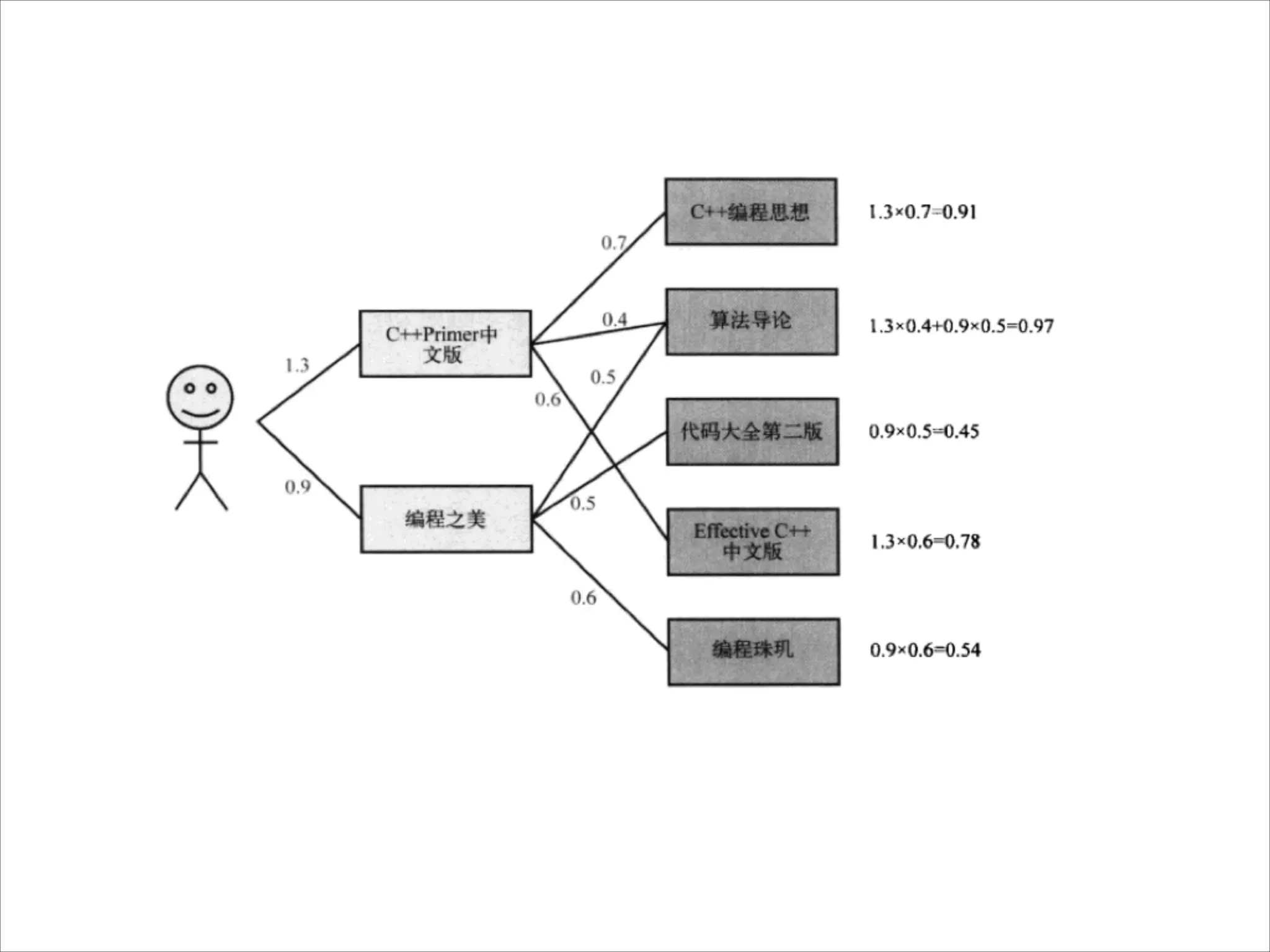
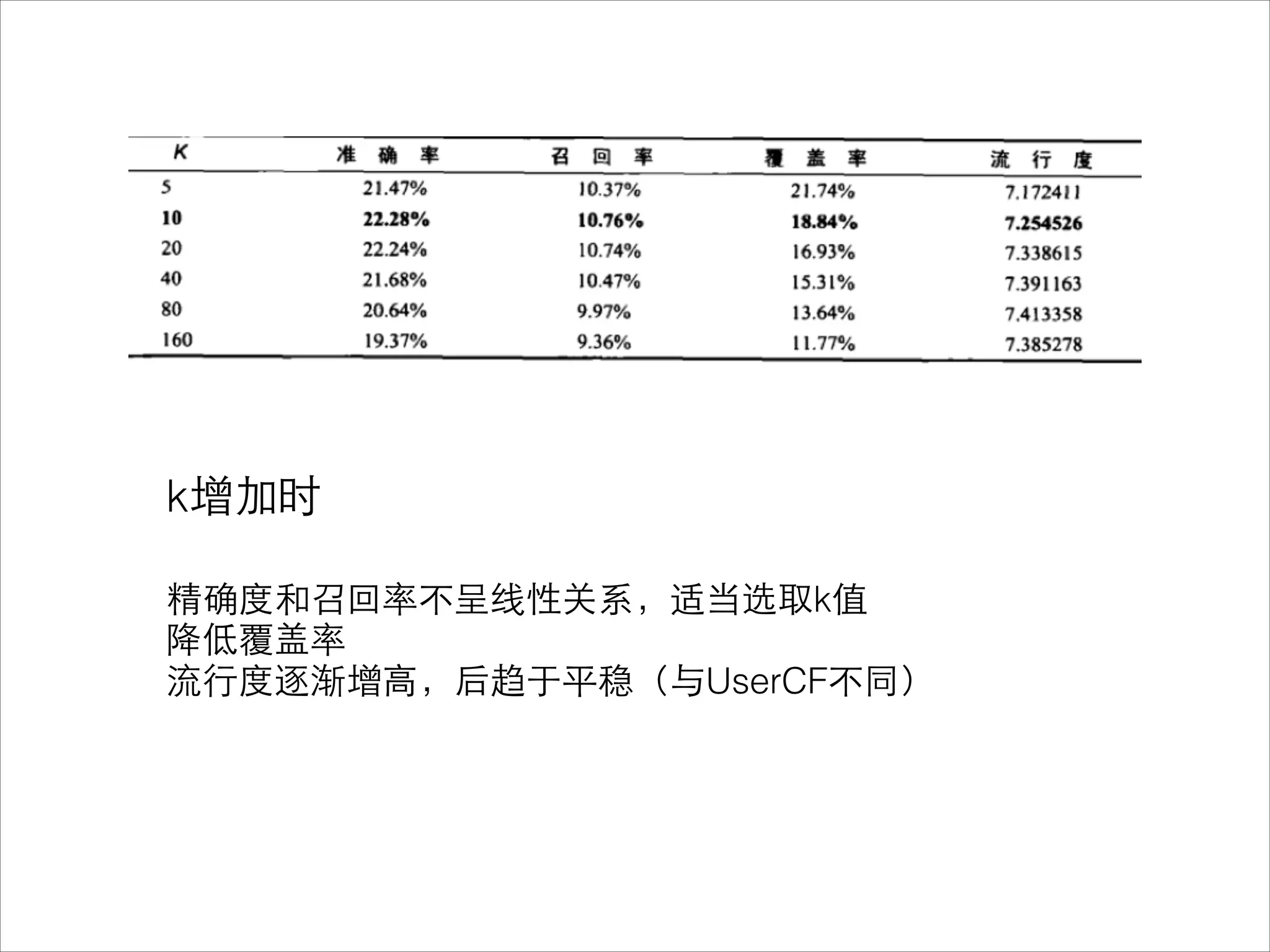
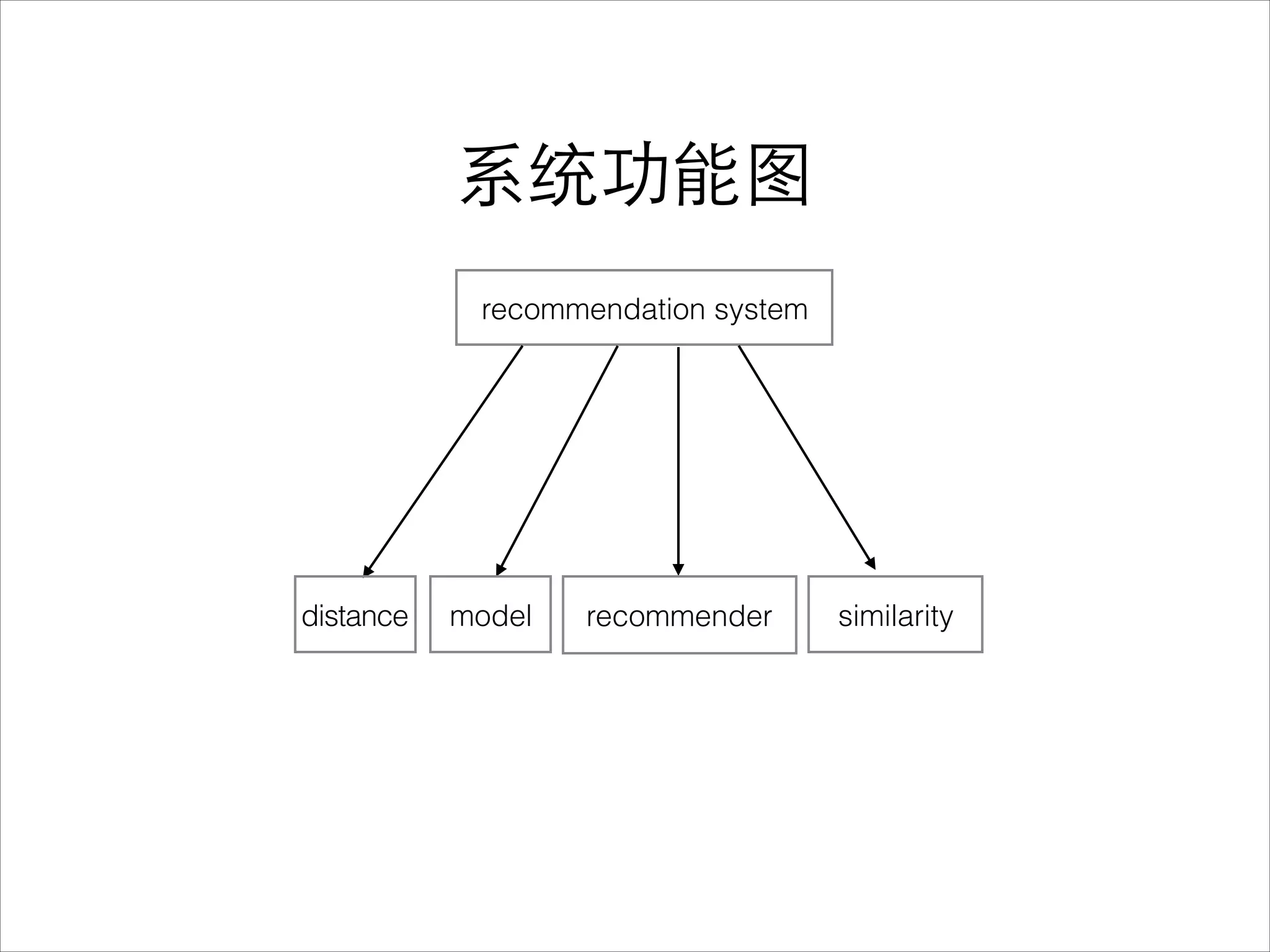
该文档介绍了个性化推荐系统的基本概念及其实现,聚焦于协同过滤算法的工作原理和应用。它探讨了推荐系统在解决信息超载问题中的潜力,以及用户和物品相似性的计算方法。文中还提到了不同的机器学习算法及其优缺点,并展示了实现推荐系统所需的技术构成。















![c[i][j]记录了同时喜欢物品i和物品j的⽤用户数](https://image.slidesharecdn.com/random-140712211006-phpapp02/75/slide-18-2048.jpg)