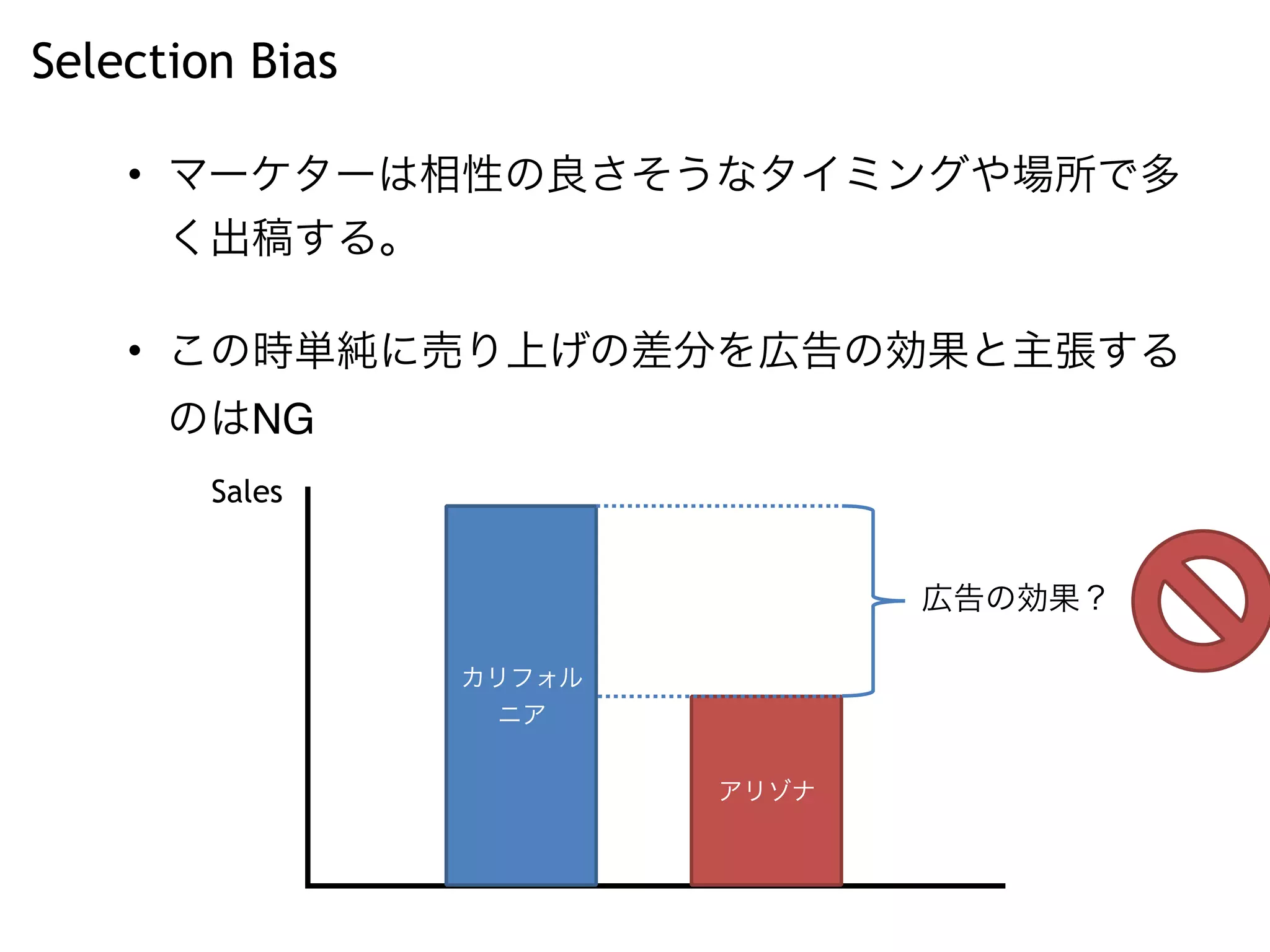
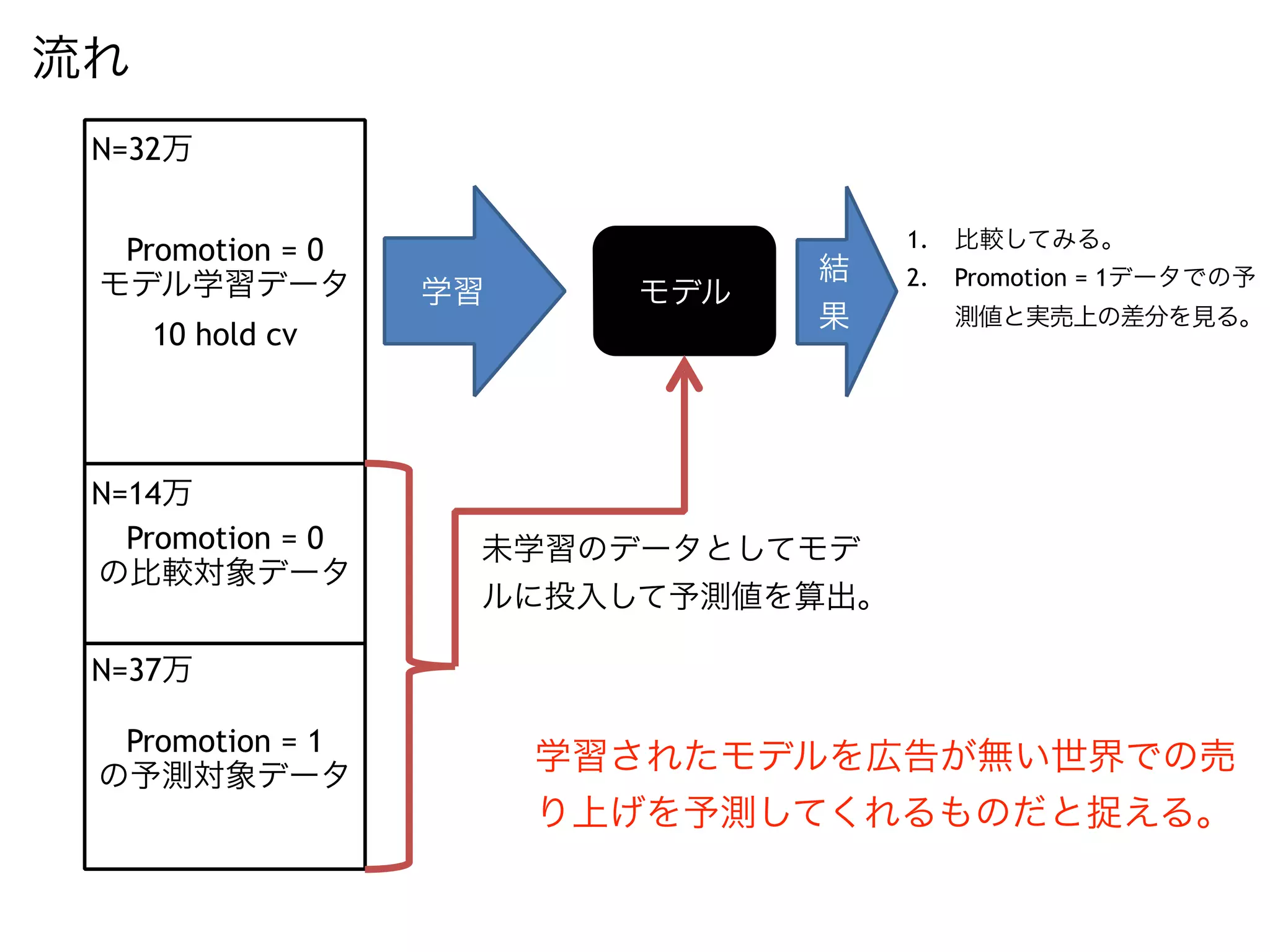
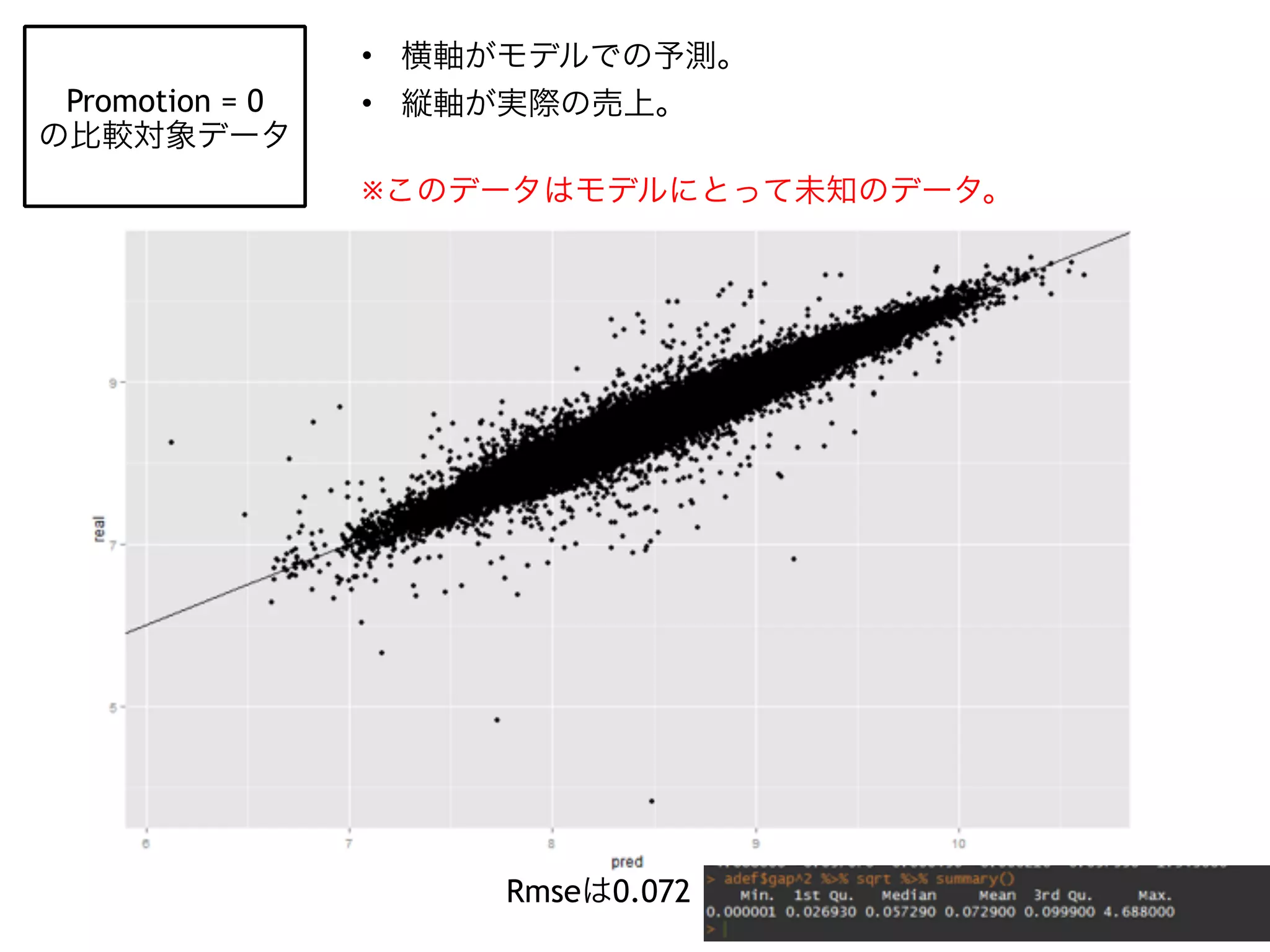
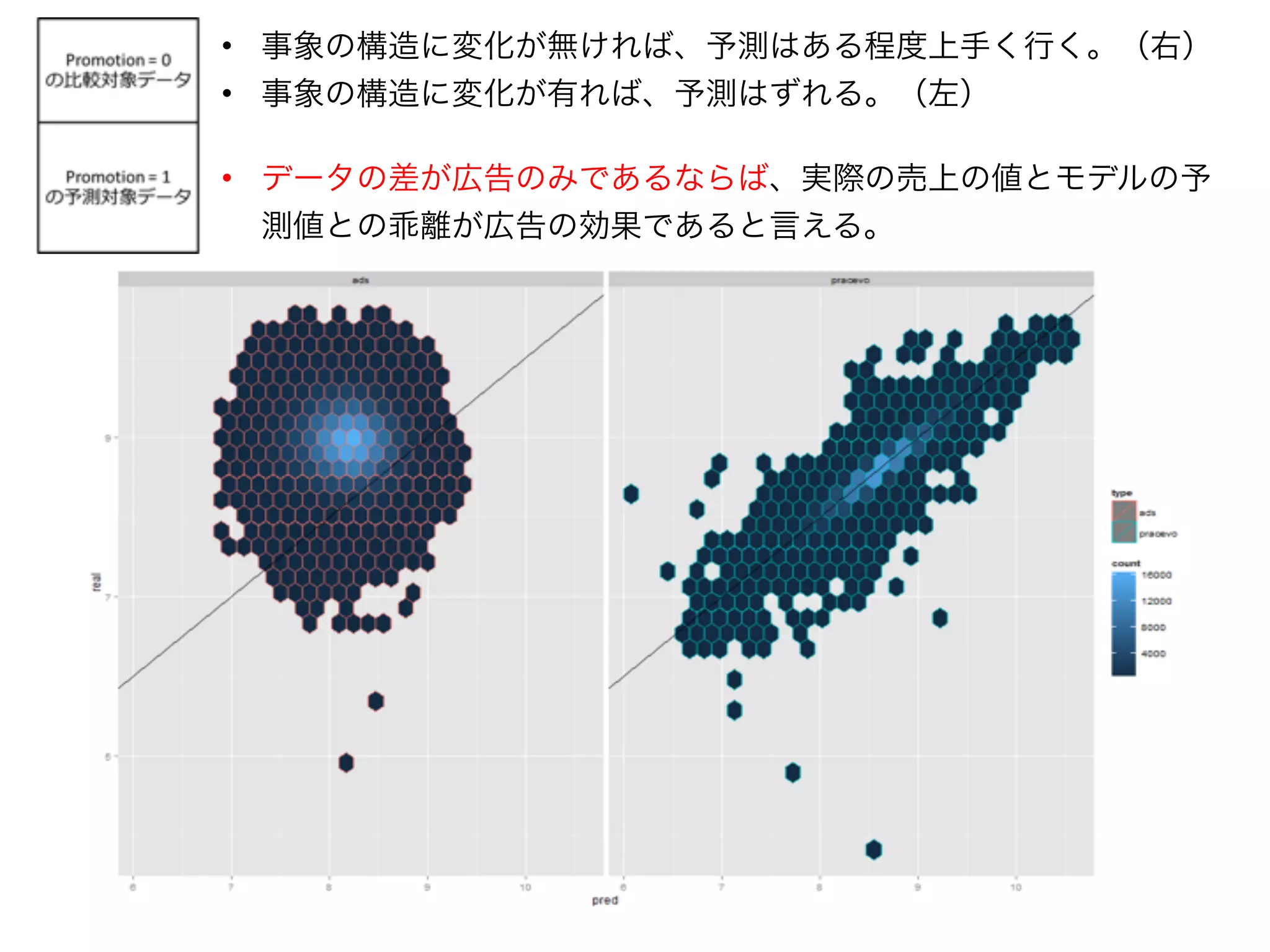
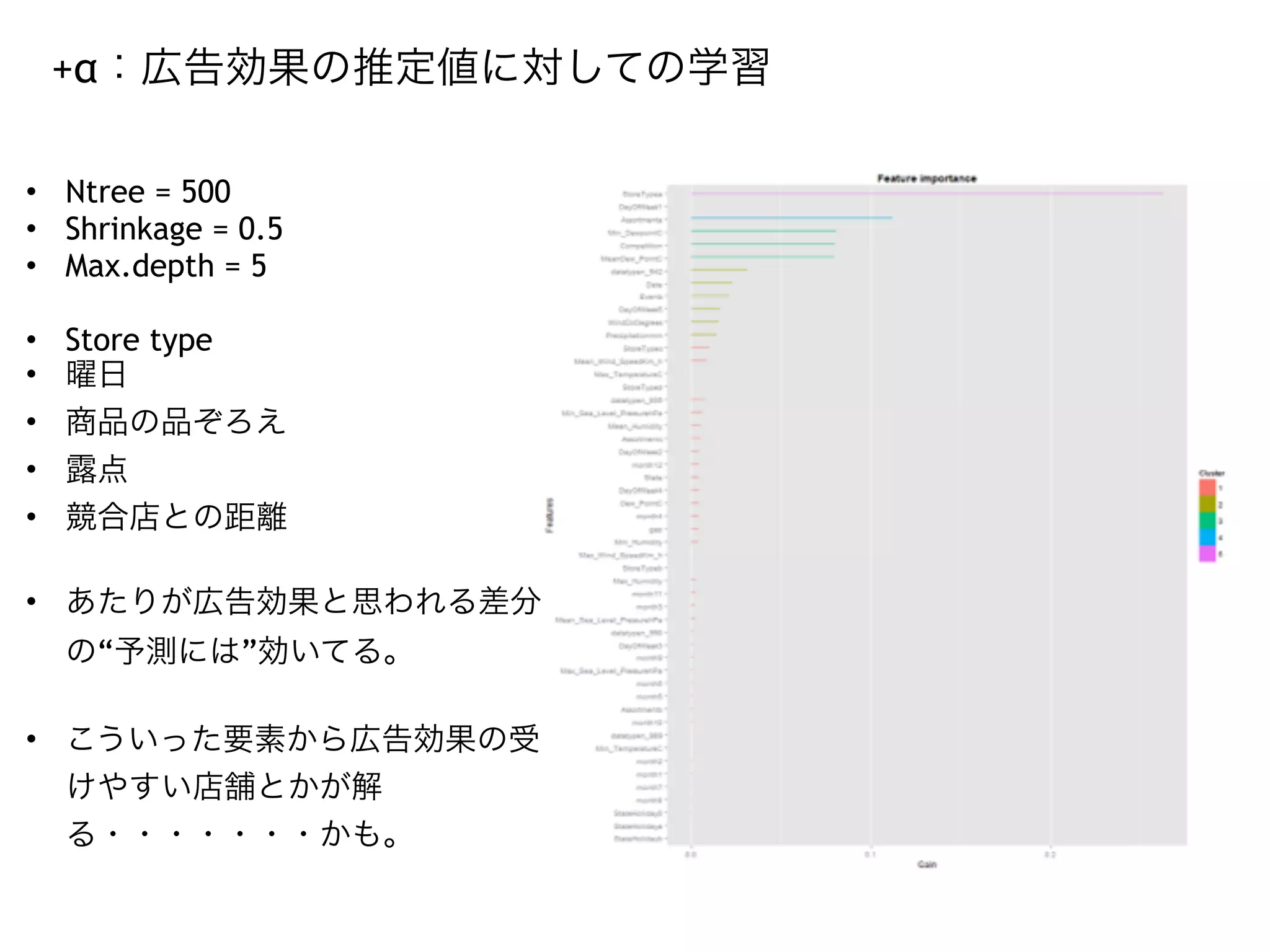
This is the slides where I used for Japan.R I tried to estimate the effect of advertisement by Hal Varian's approach that he described in his paper.