

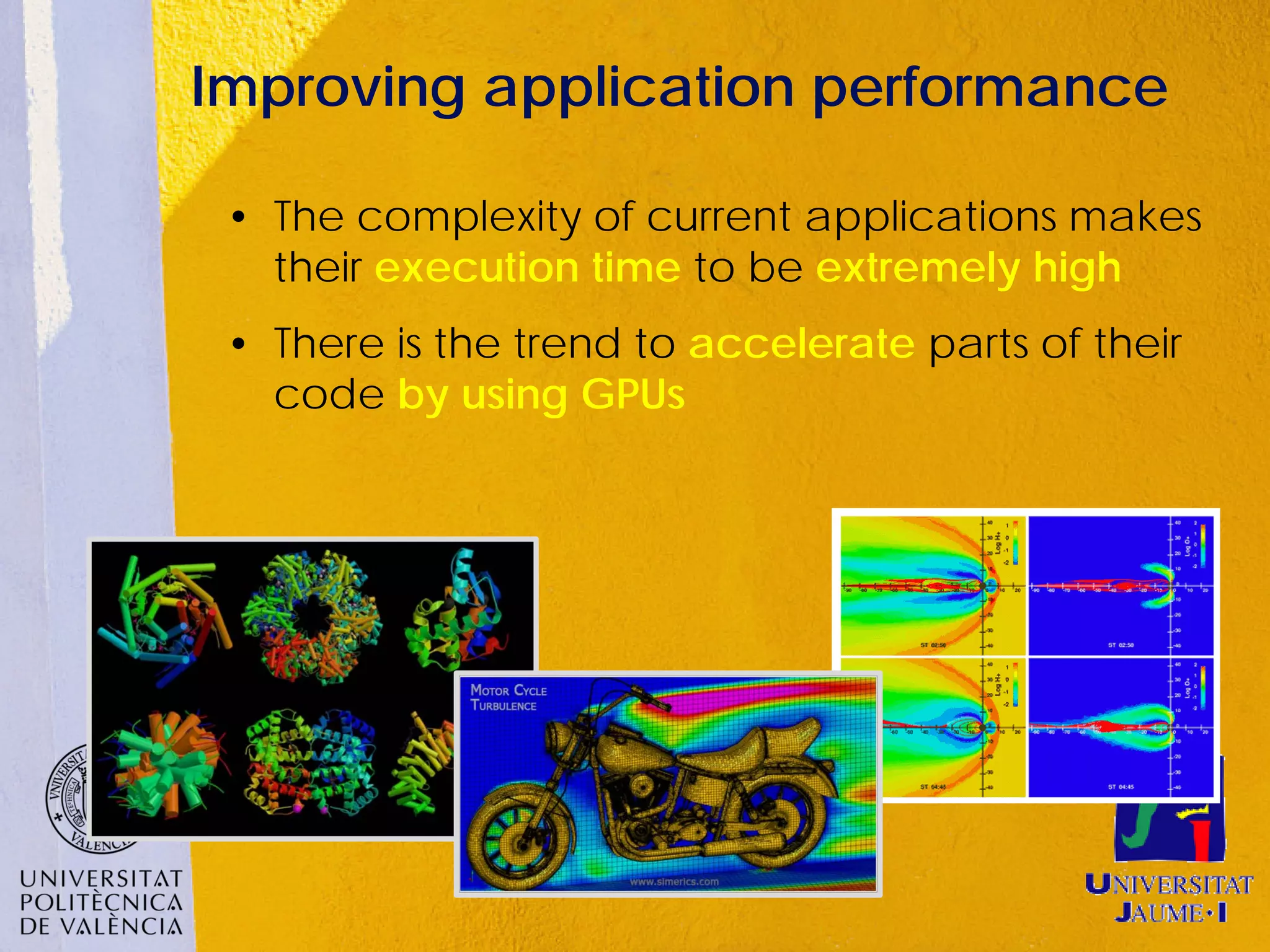



![Moderate level of data parallelism
Application presents a data parallelism
around [40%-80%]. This is the common case
Regarding GPU computing?
The GPUs in the system are used only for some parts of the
application, remaining idle the rest of the time](https://image.slidesharecdn.com/rcudapresentationibfeatures120704-120705112335-phpapp01/75/R-cuda-presentation_ib_features_120704-8-2048.jpg)







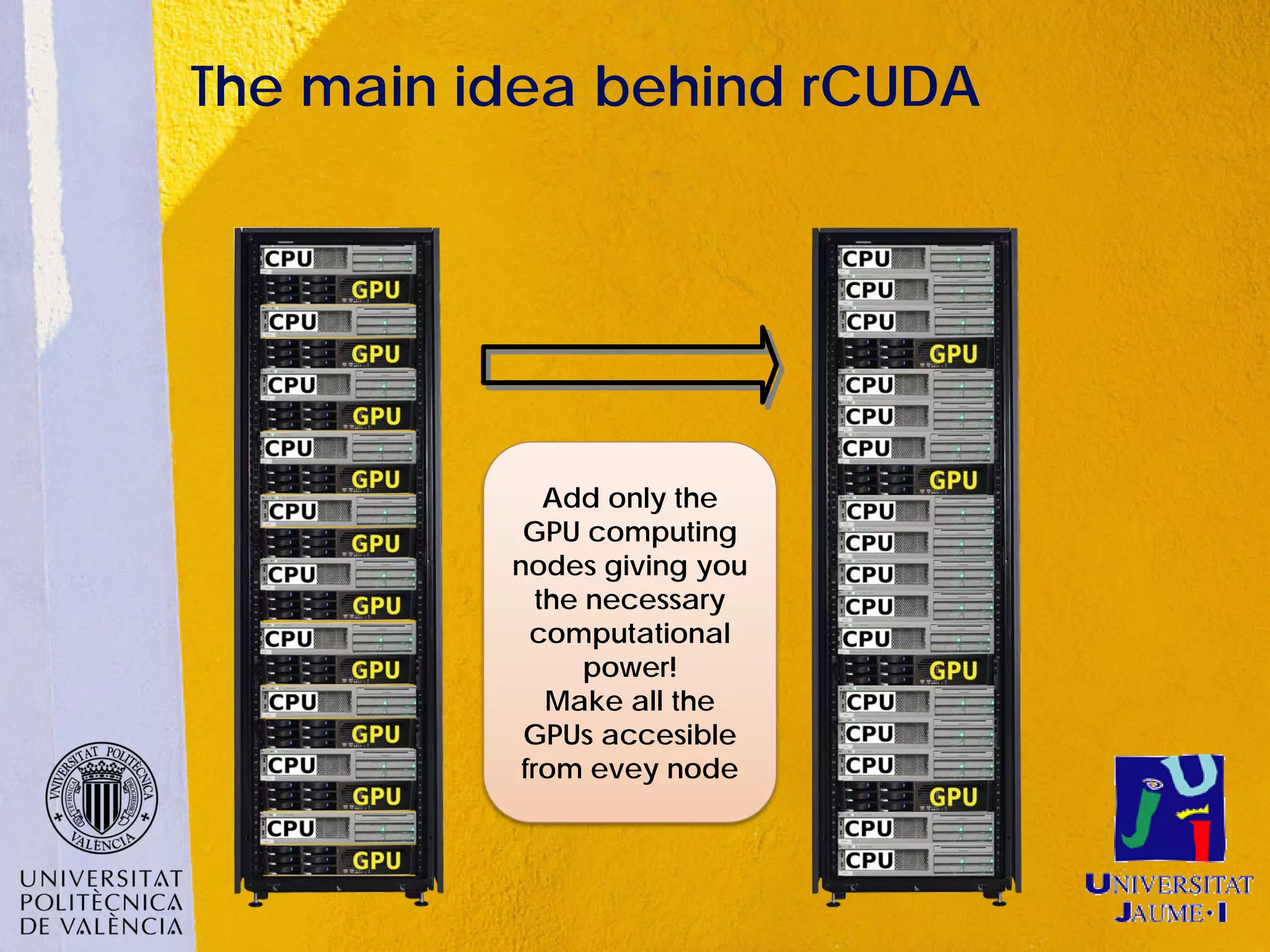


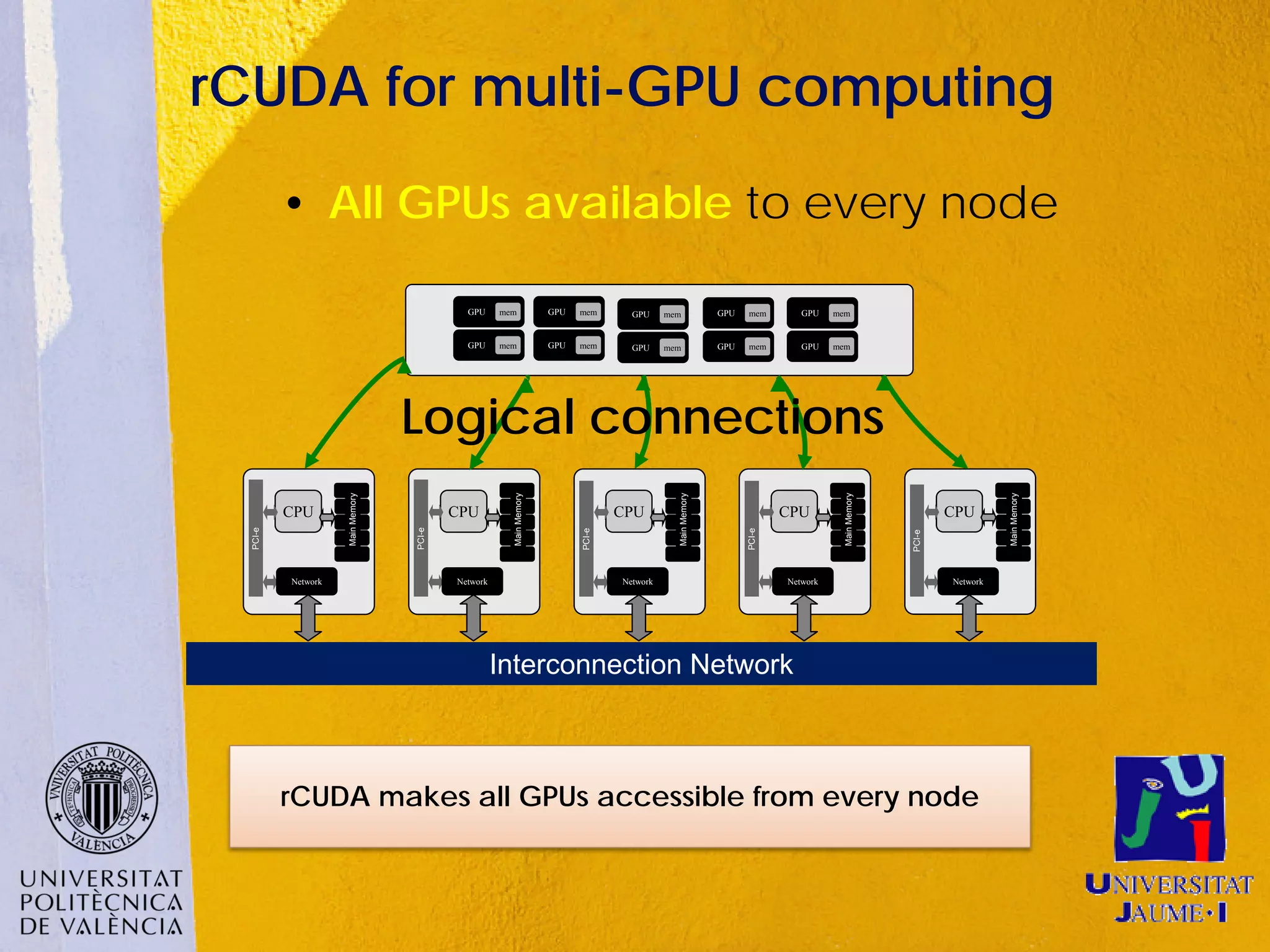
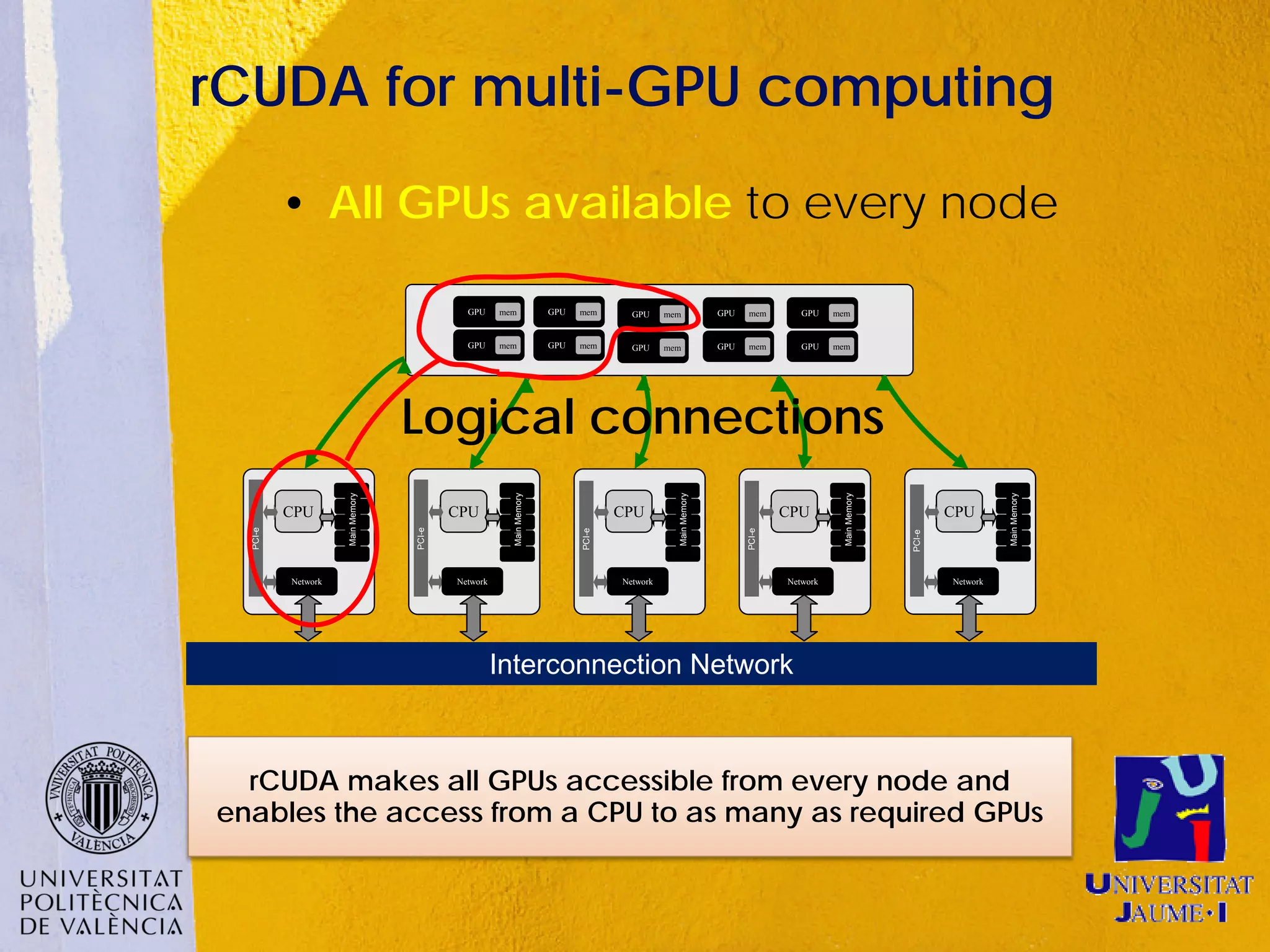


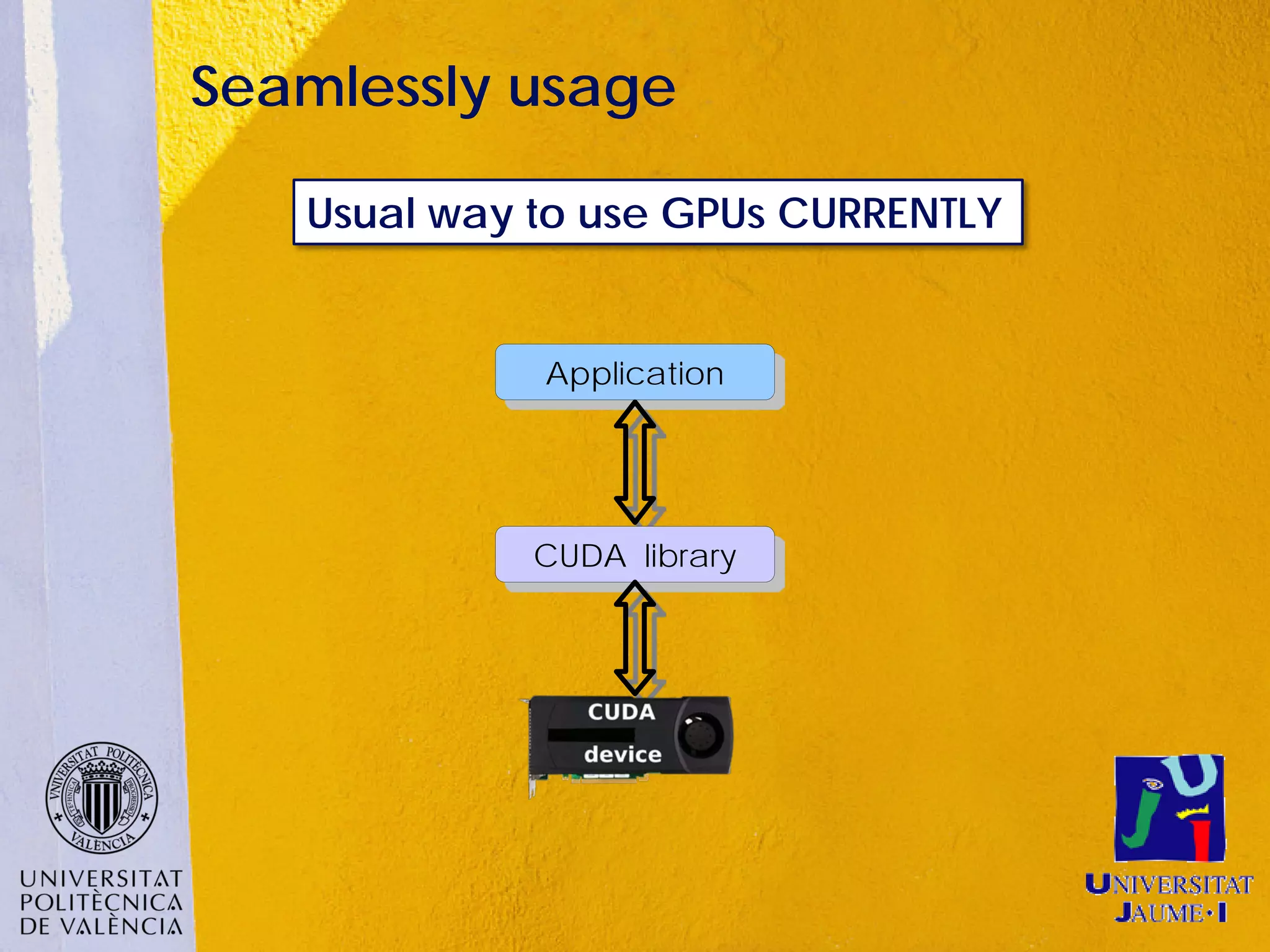
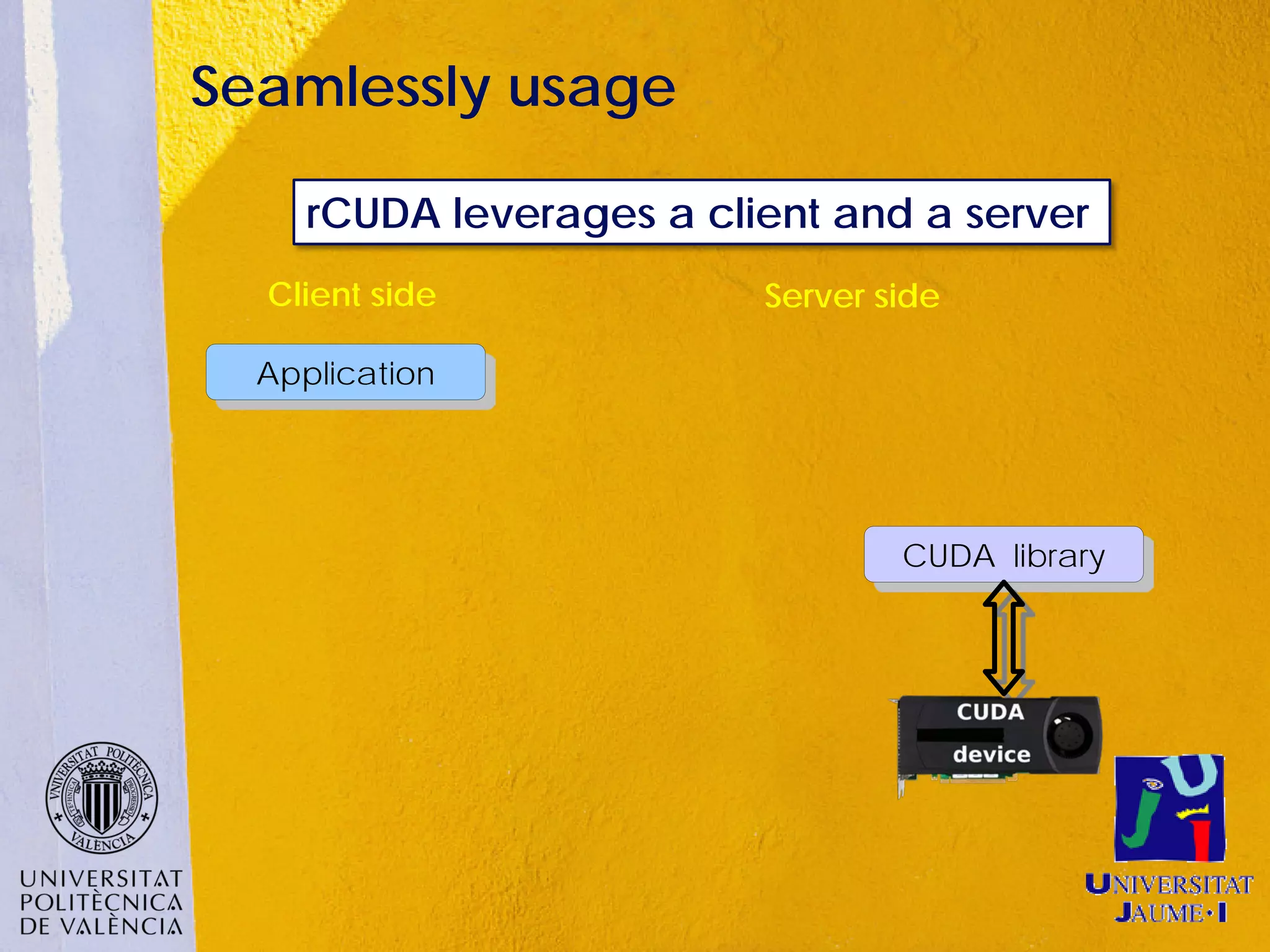
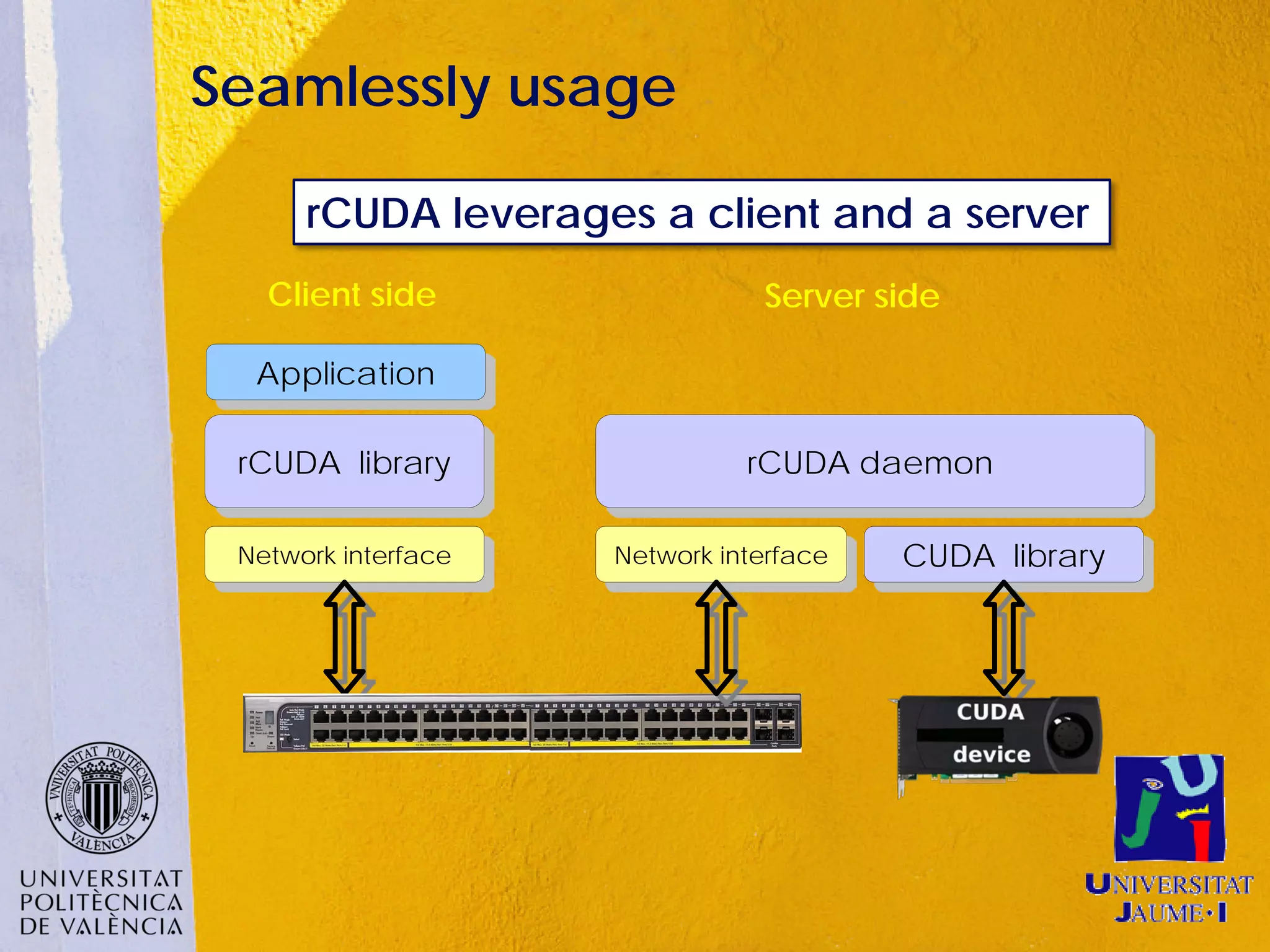
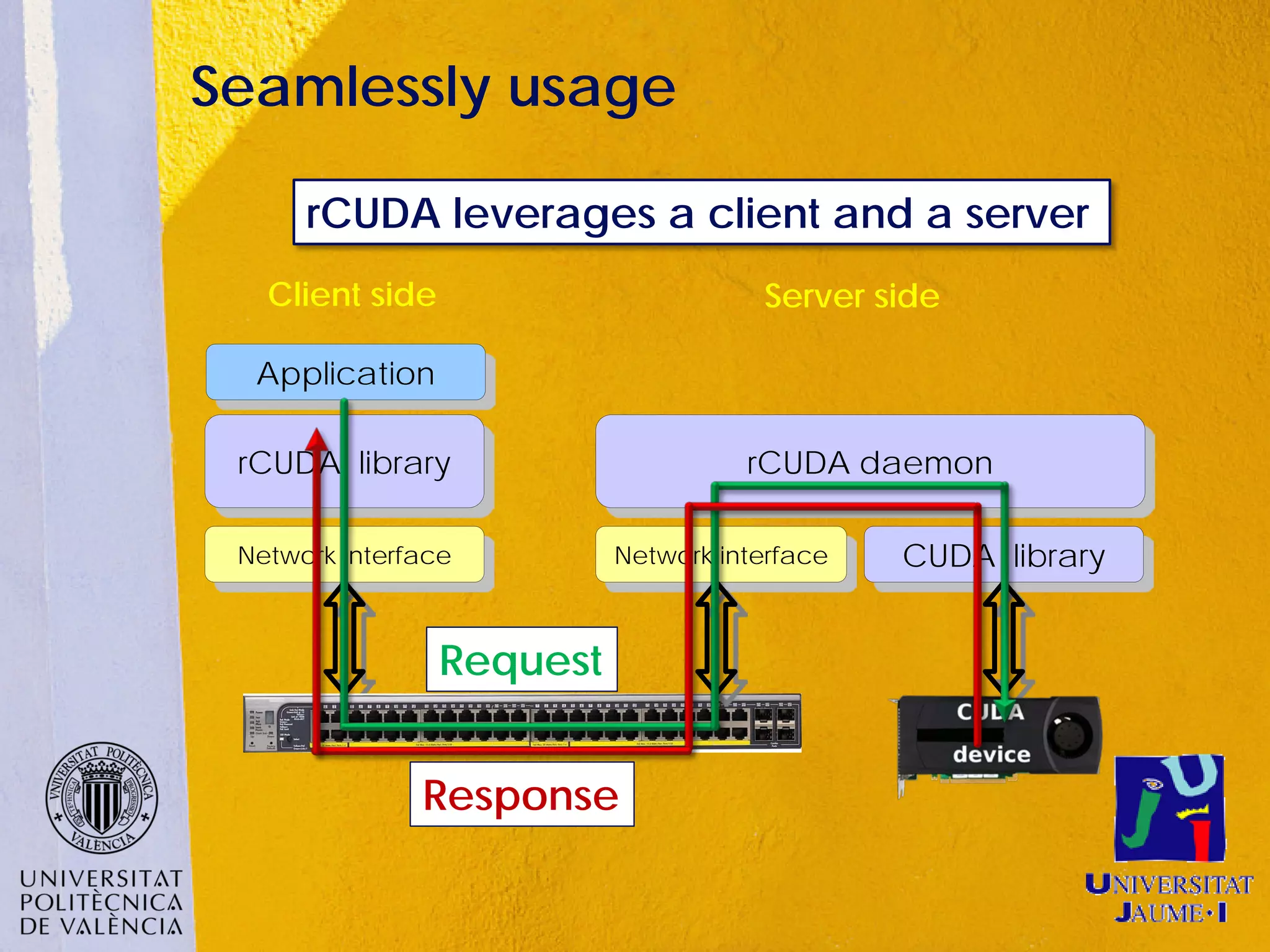



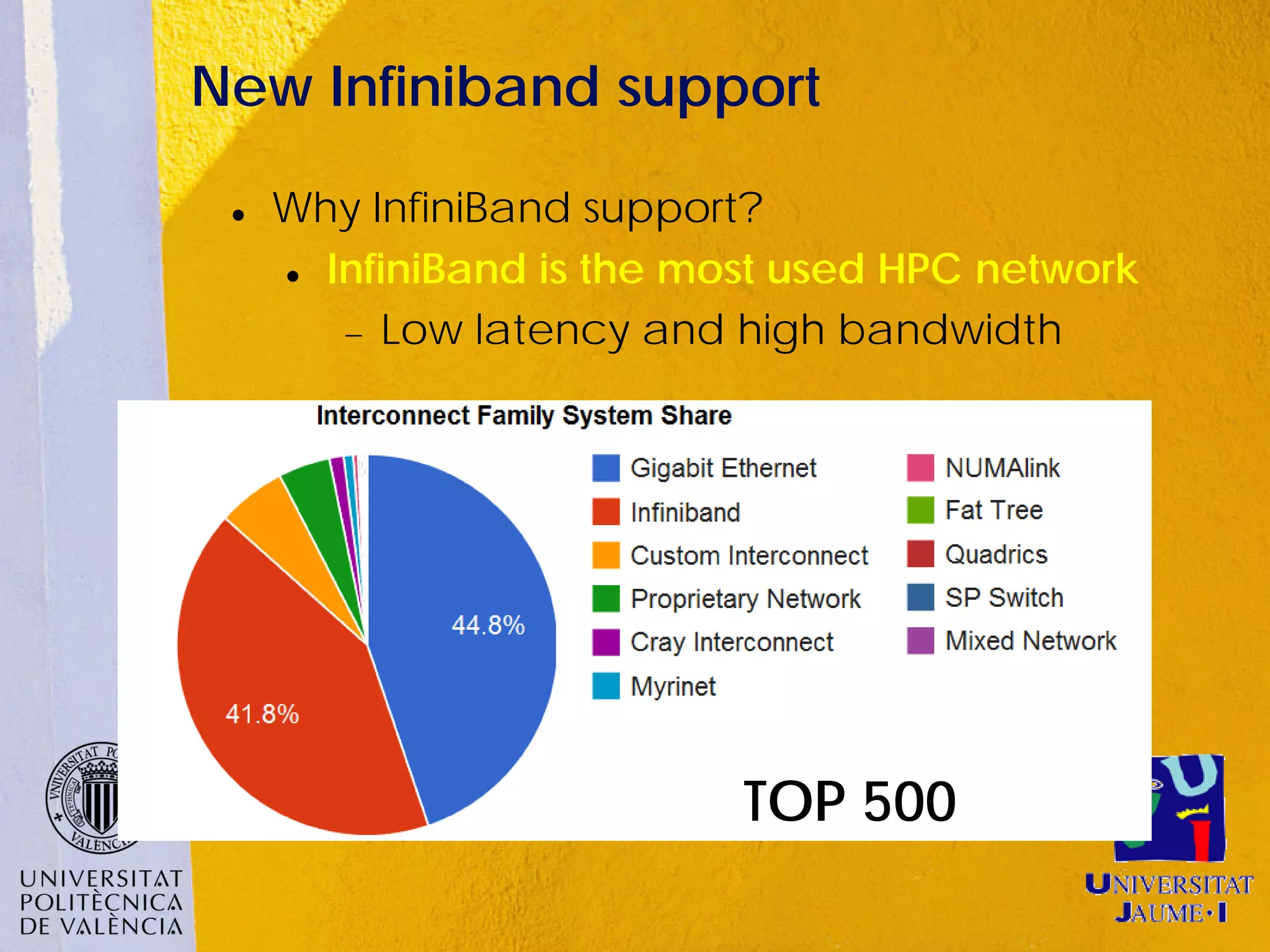

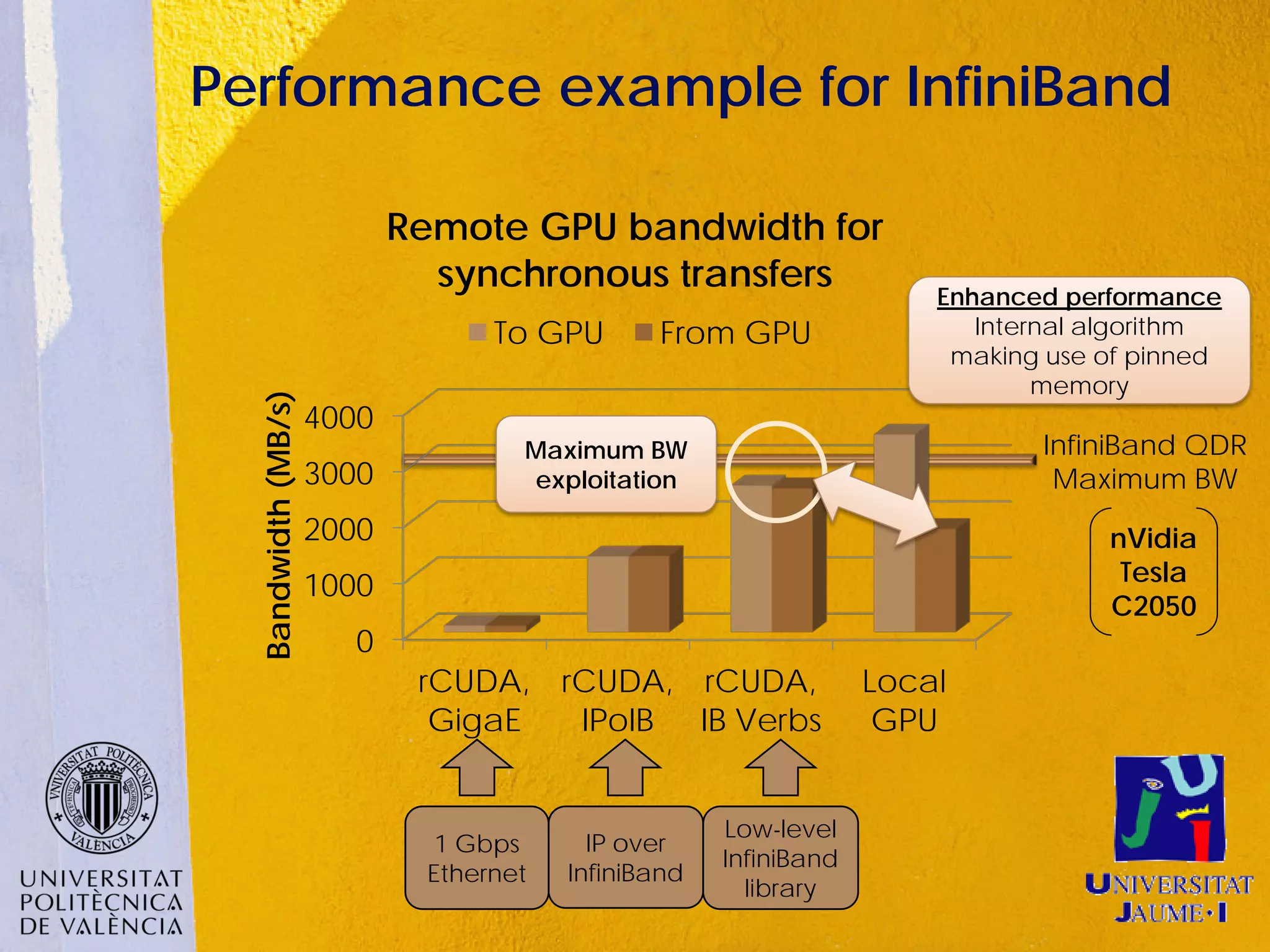
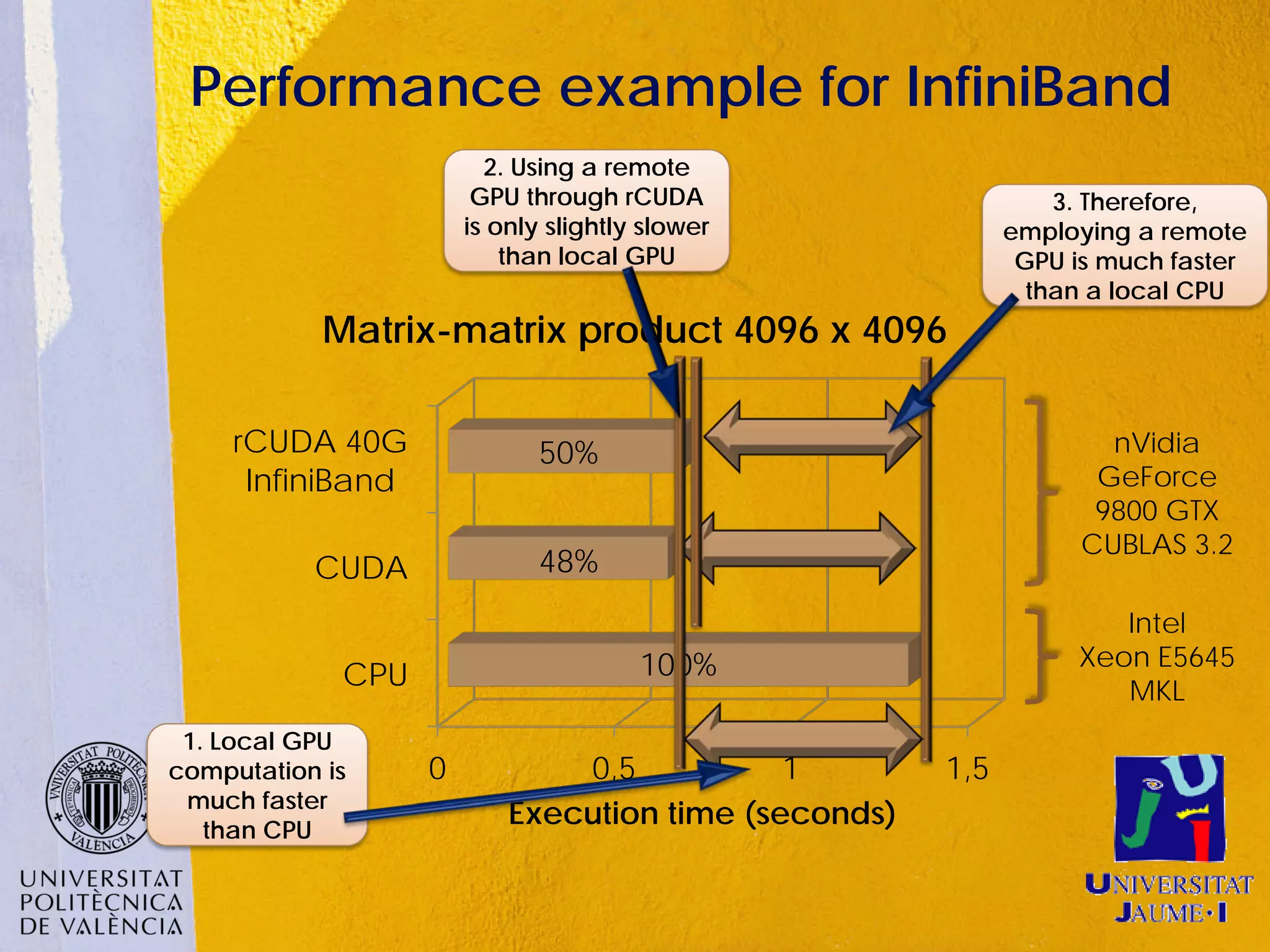
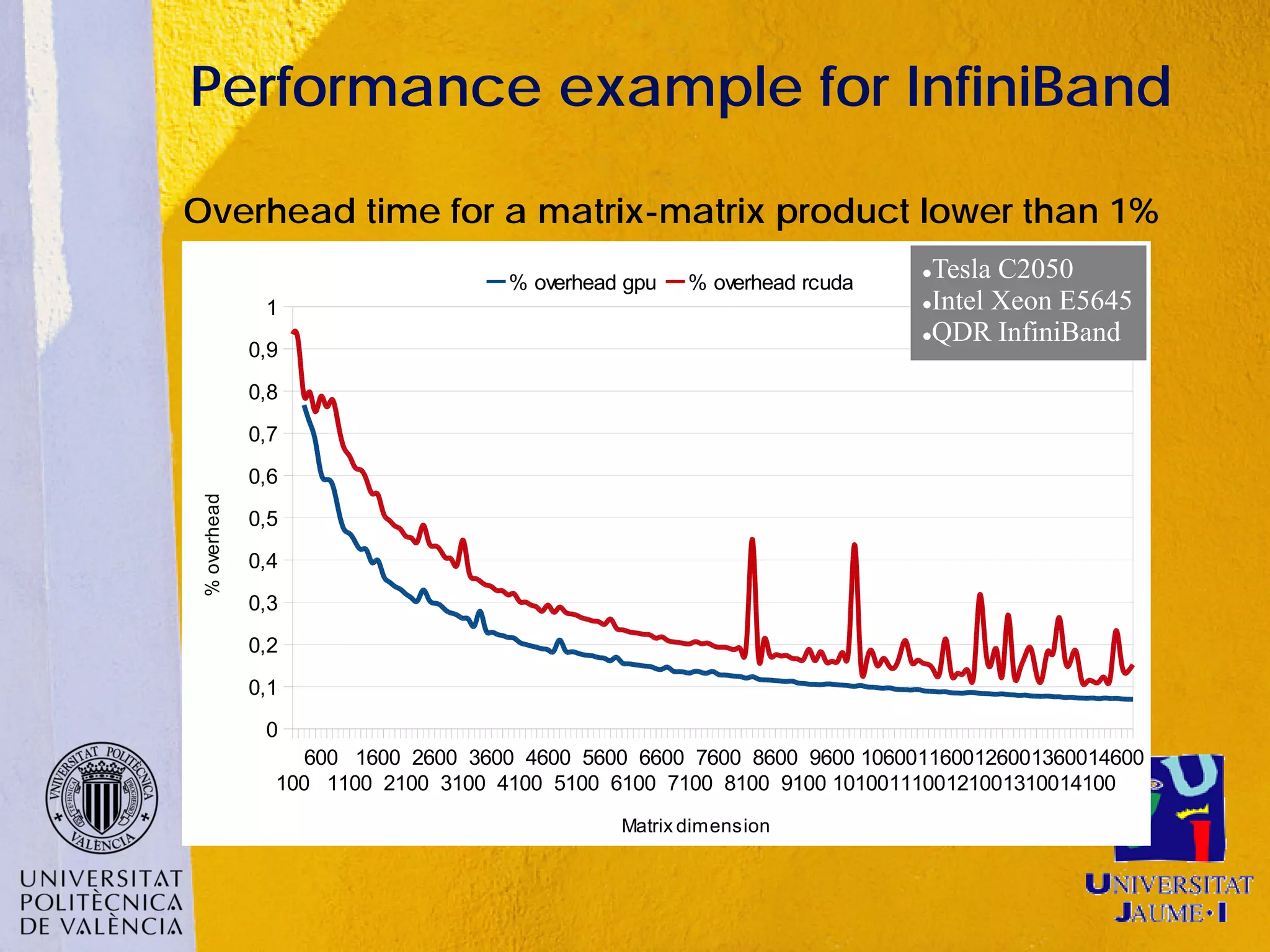
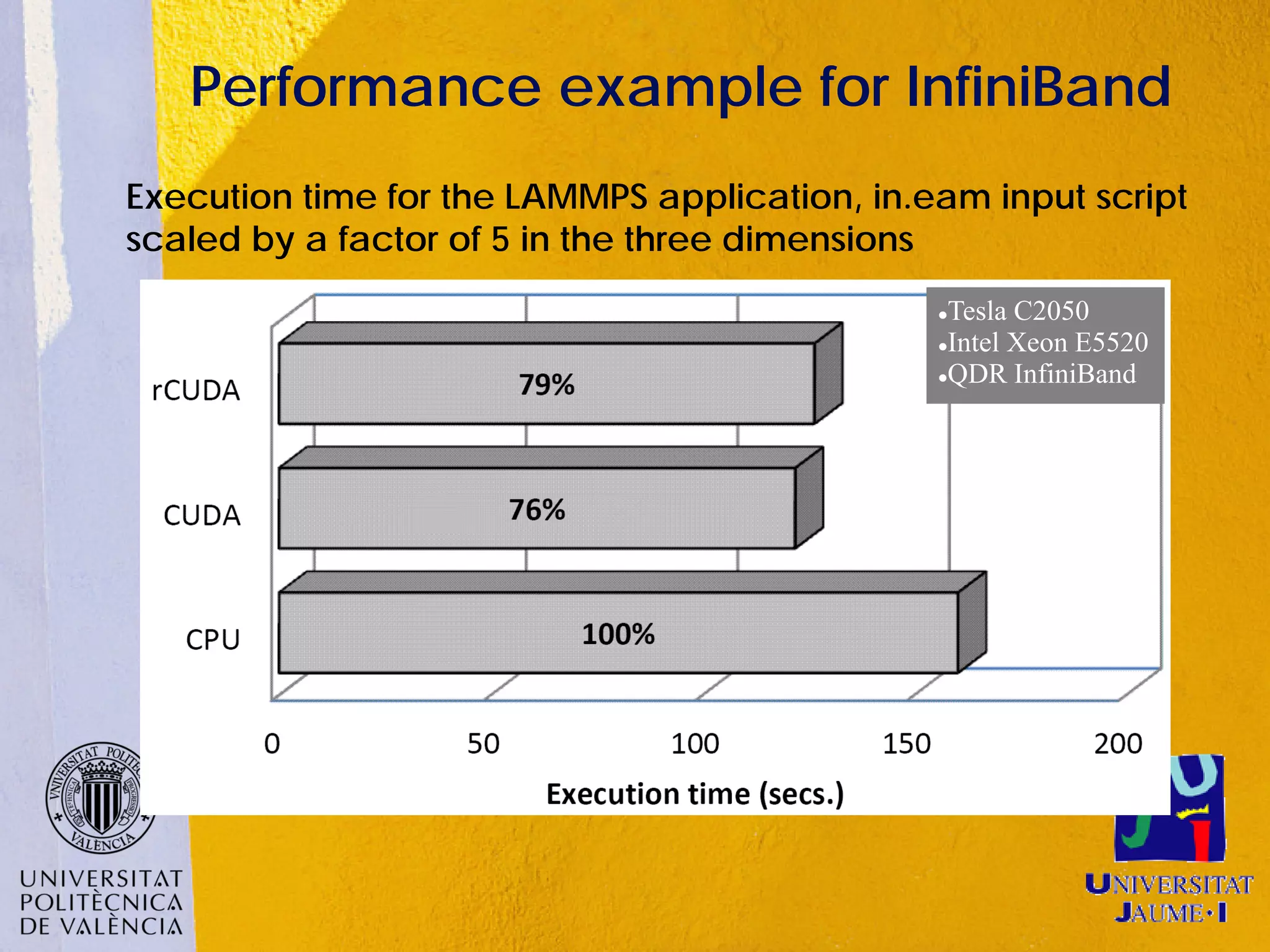


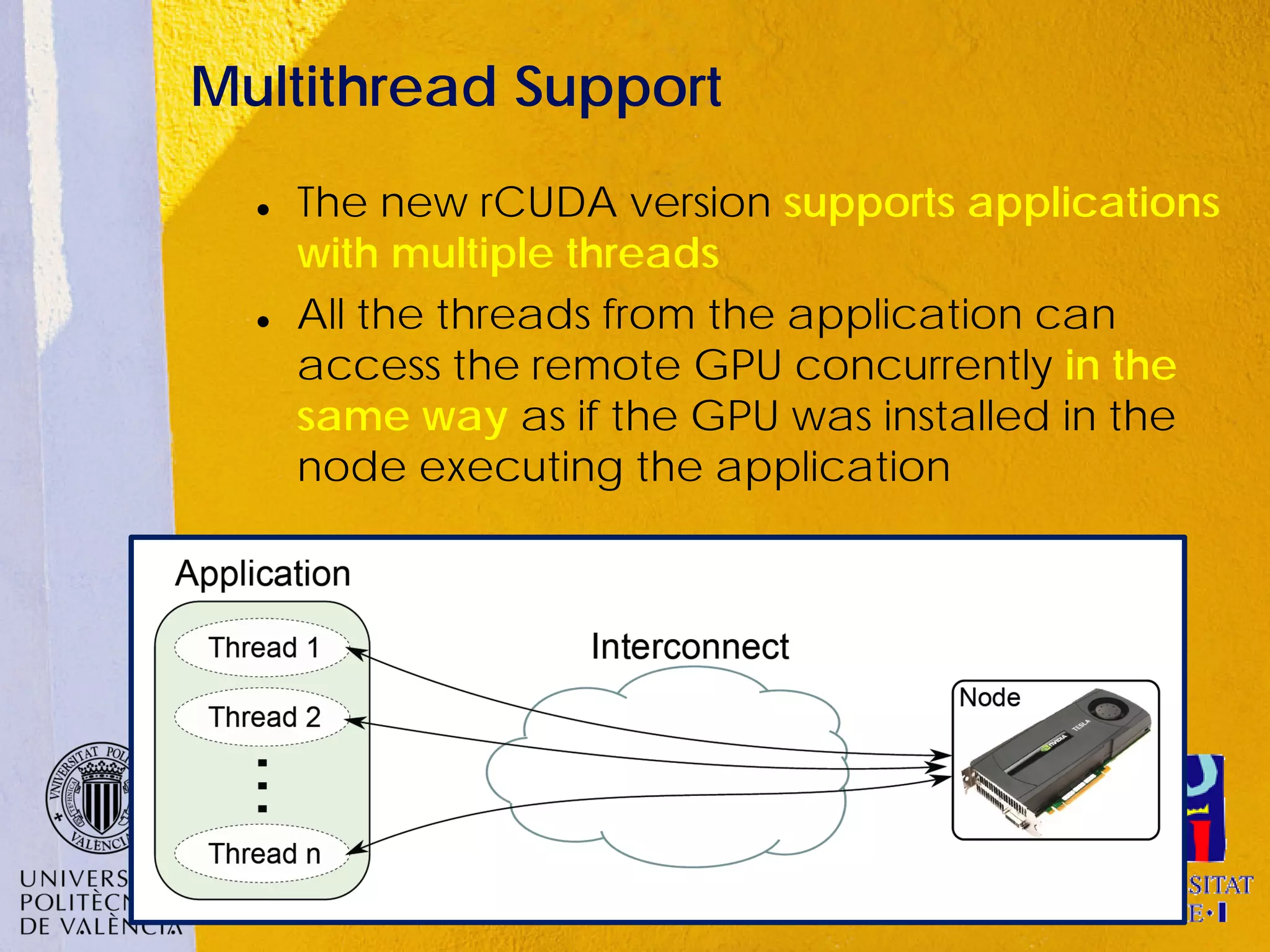
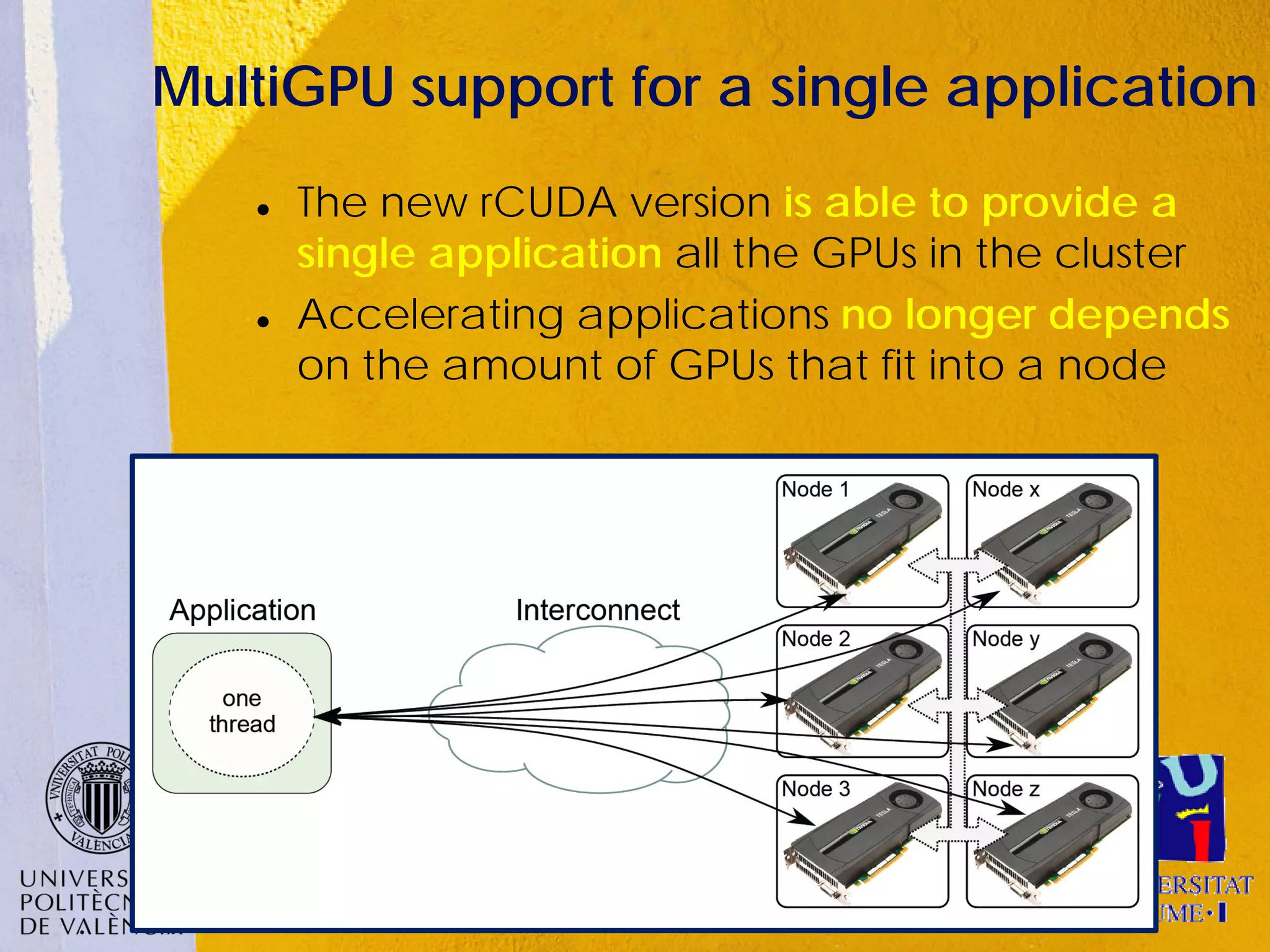
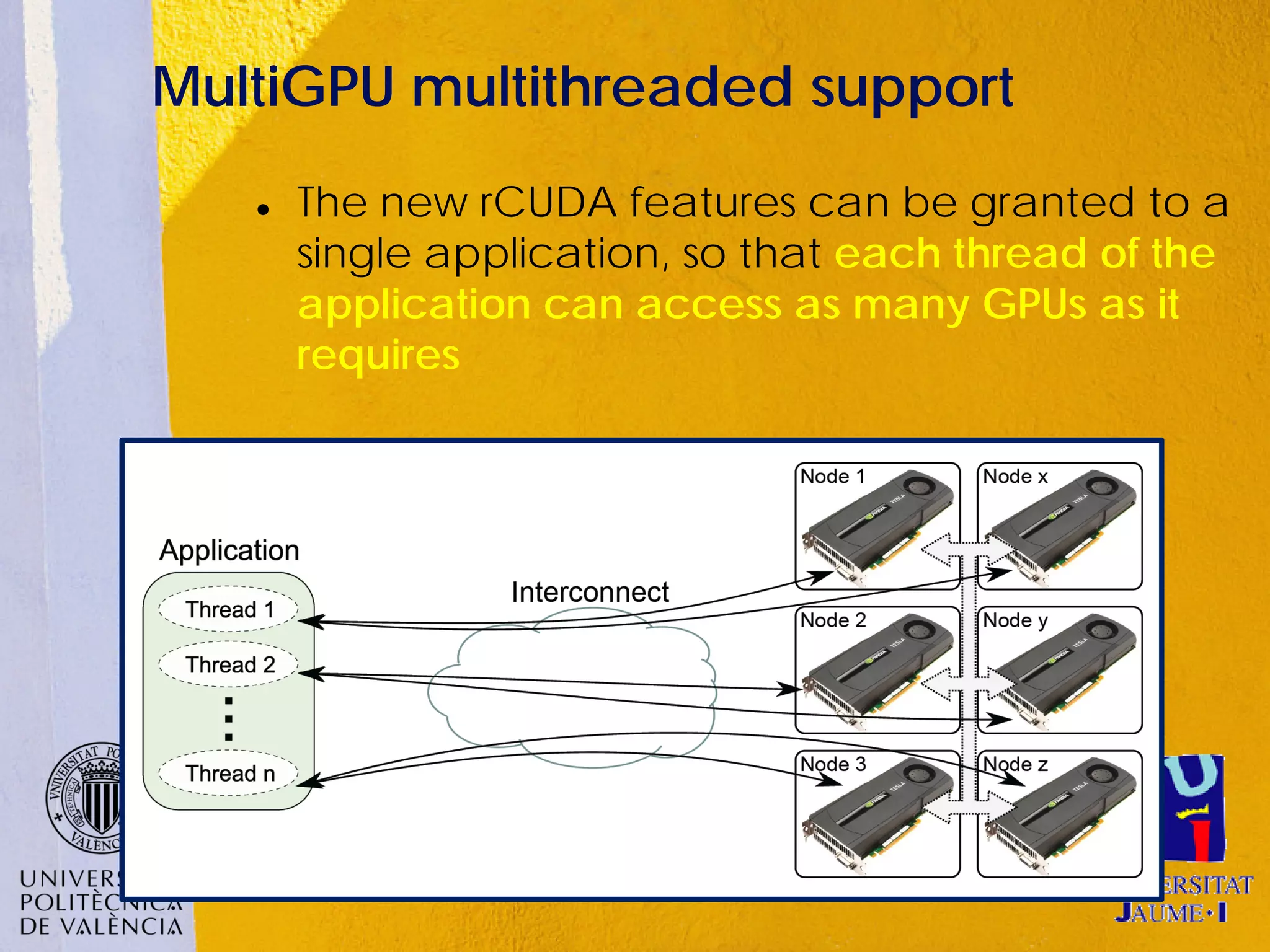



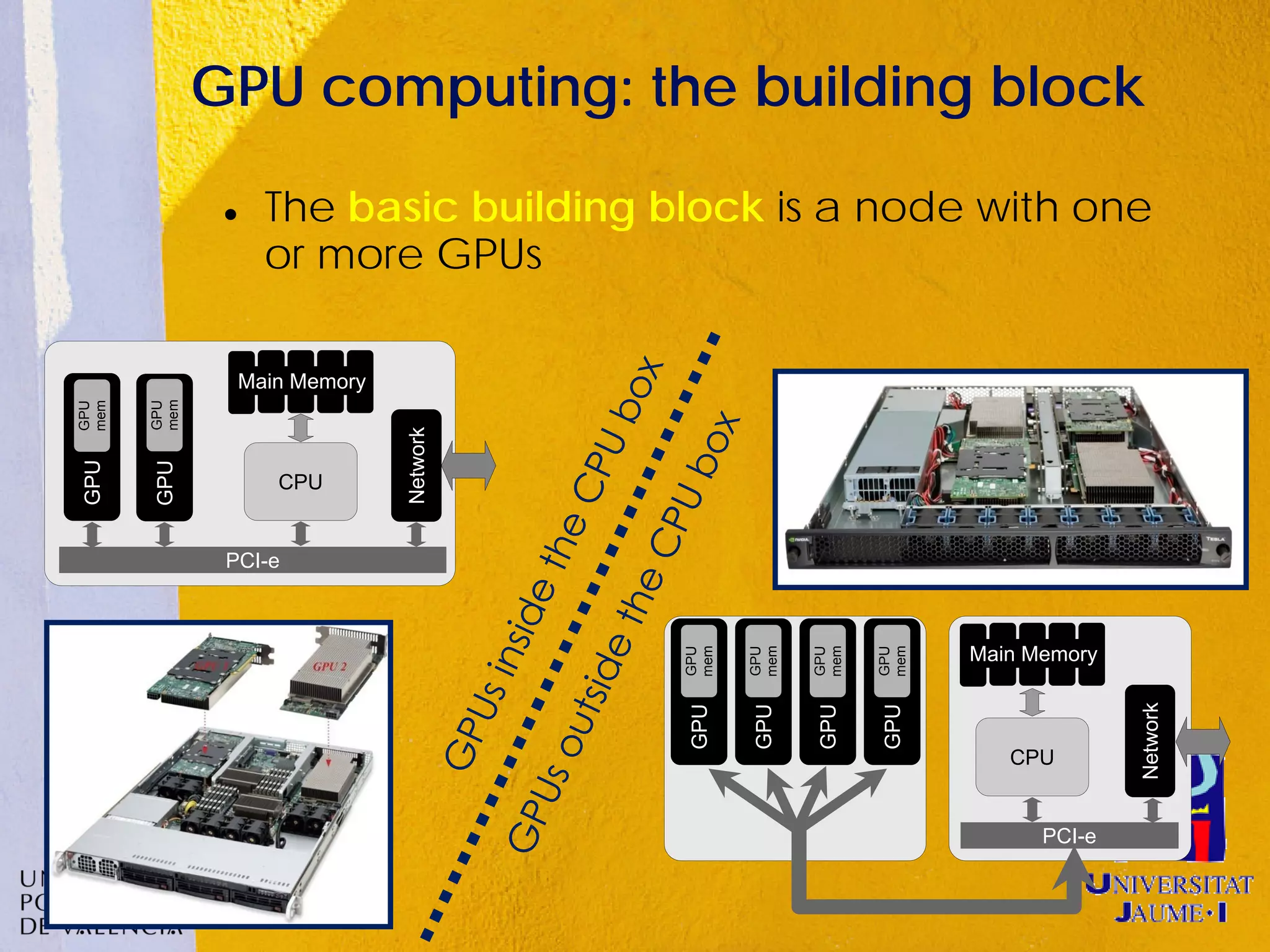
This document discusses sharing GPUs across a cluster using rCUDA. rCUDA allows nodes in a cluster to access GPUs remotely, improving GPU utilization and reducing costs by needing fewer total GPUs. It extends CUDA's capabilities by making all GPUs in the cluster accessible to applications running on any node. This "GPU as a service" approach can increase performance for multi-GPU applications by providing access to more GPUs than are locally present in a node.

























![[Harvard CS264] 05 - Advanced-level CUDA Programming](https://cdn.slidesharecdn.com/ss_thumbnails/cs264201105-cudaadvancedsharetmp-110222173227-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)








![[05][cuda 및 fermi 최적화 기술] hryu optimization](https://cdn.slidesharecdn.com/ss_thumbnails/05cudafermihryuoptimization-110106231451-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)



















![Vibe Coding vs. Spec-Driven Development [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/vibecodingvsspecdrivendevelopment-251209105622-43f455e7-thumbnail.jpg?width=640&height=640&fit=bounds)







