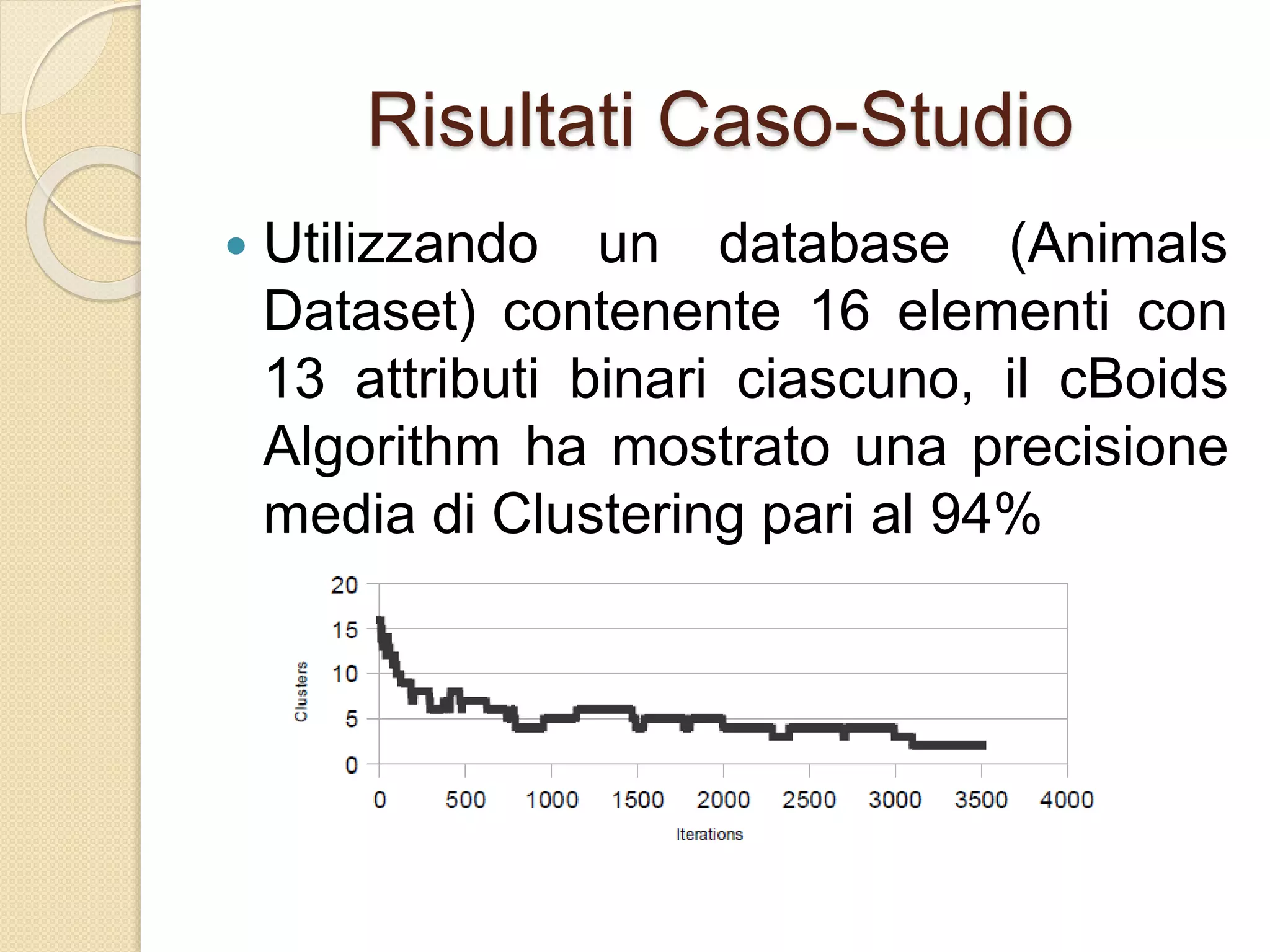
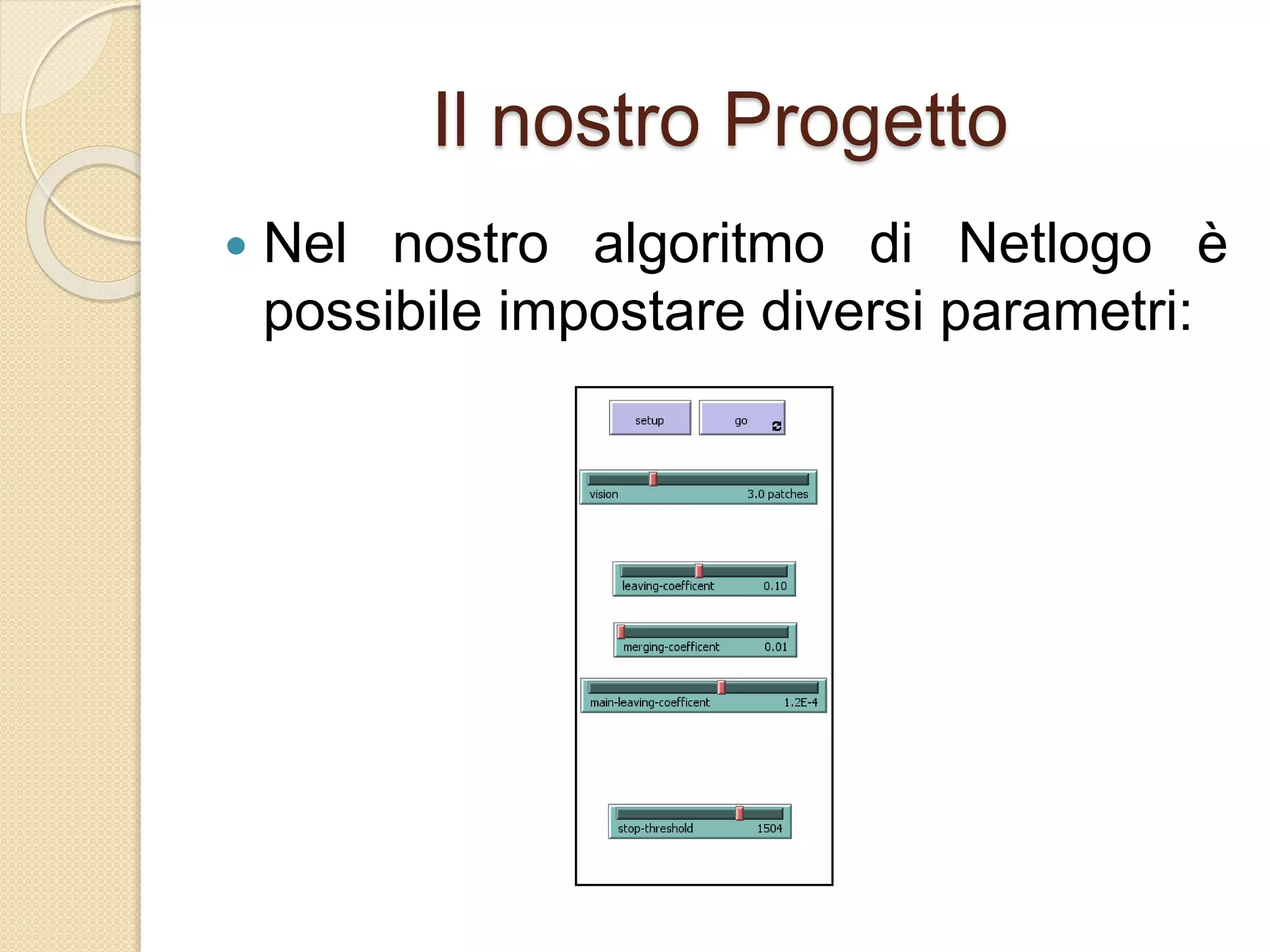
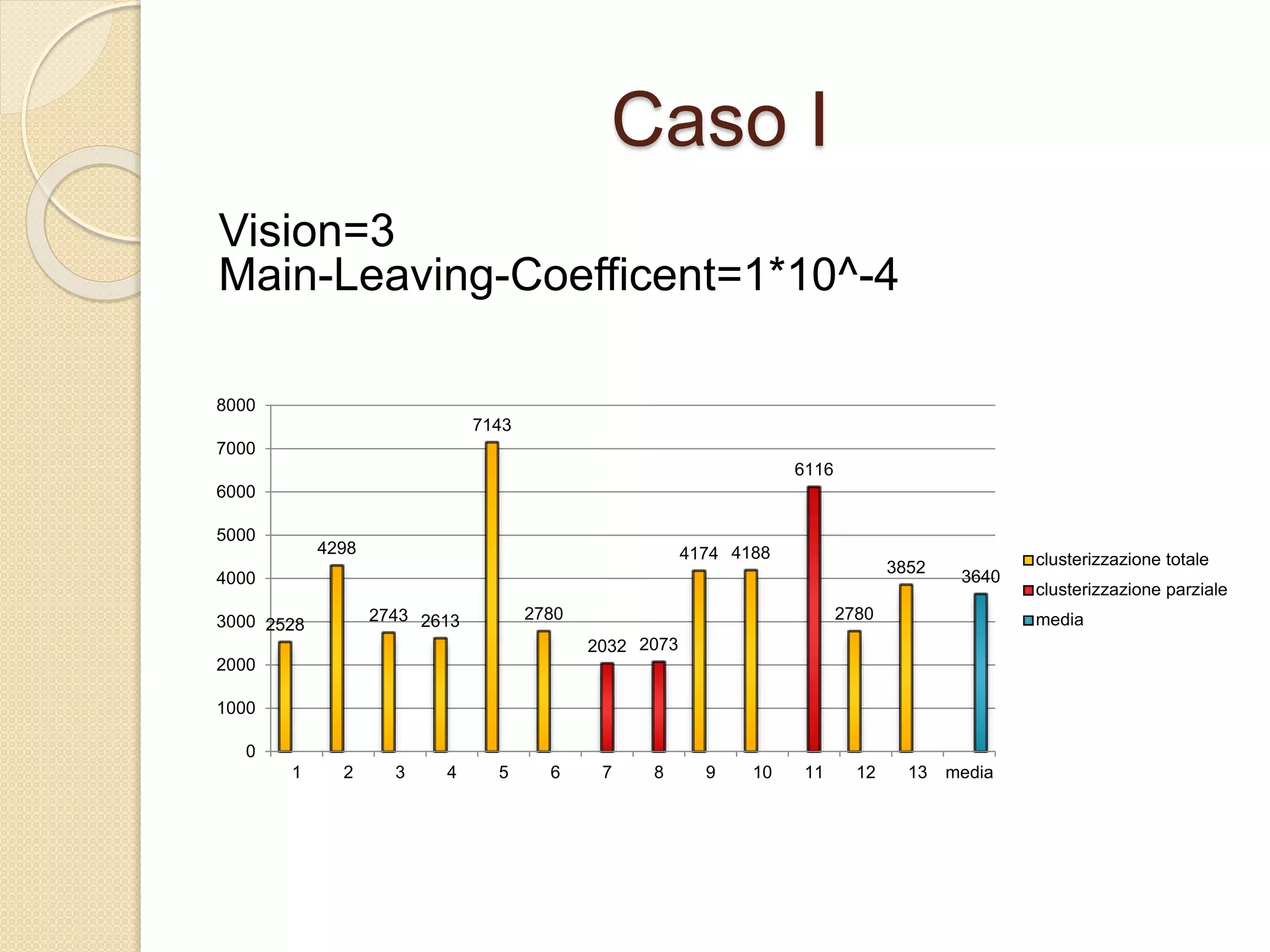
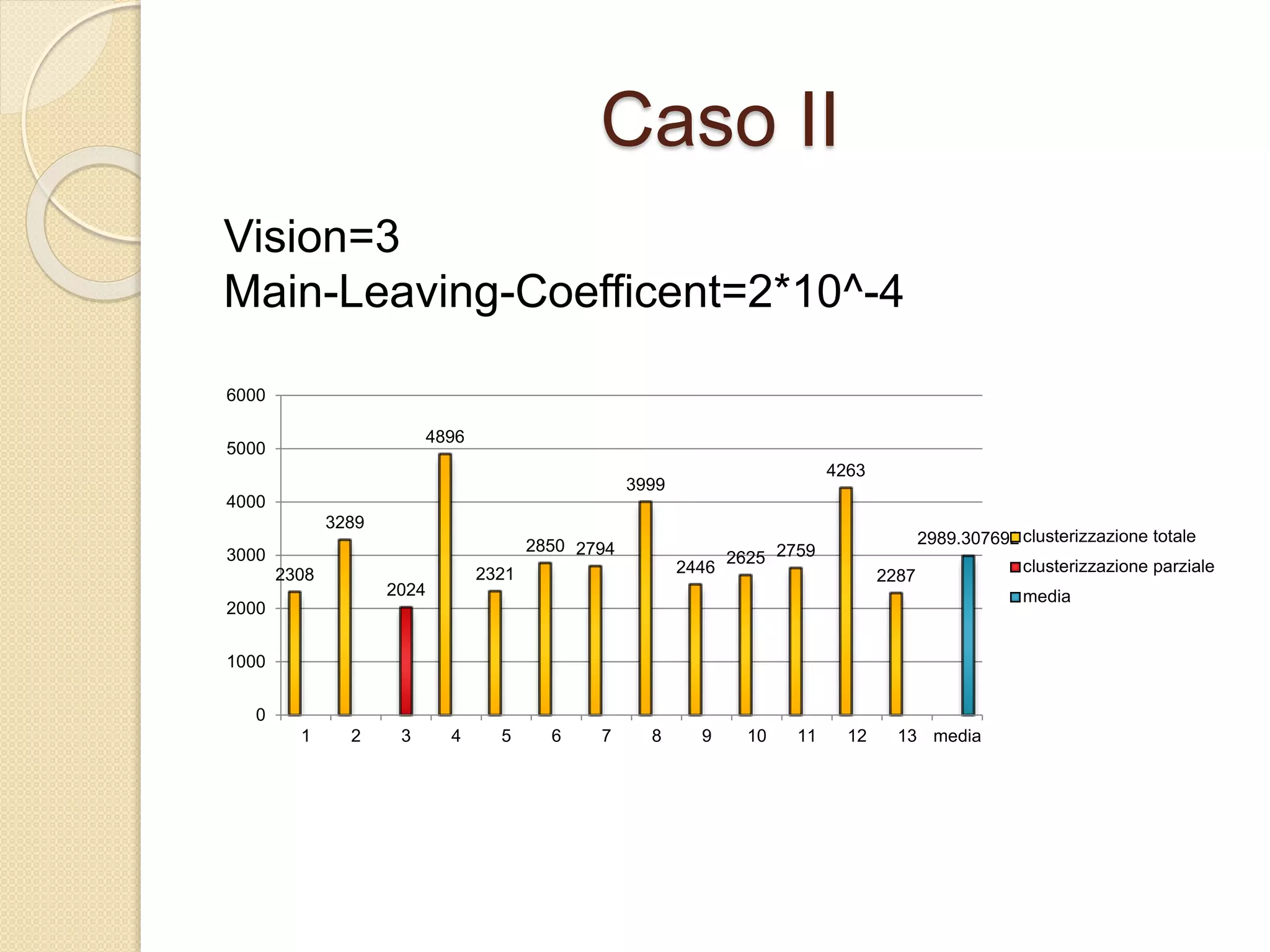
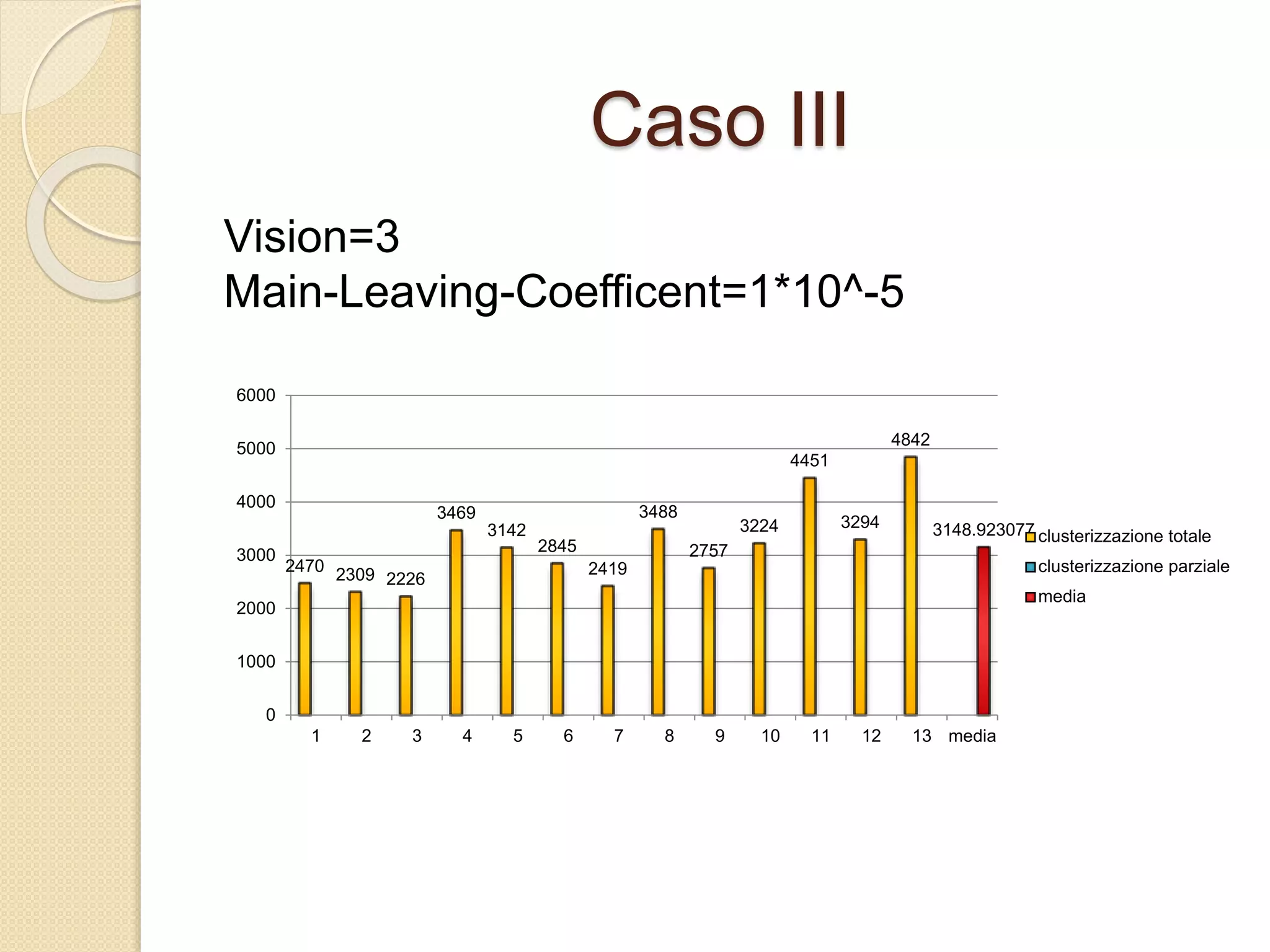
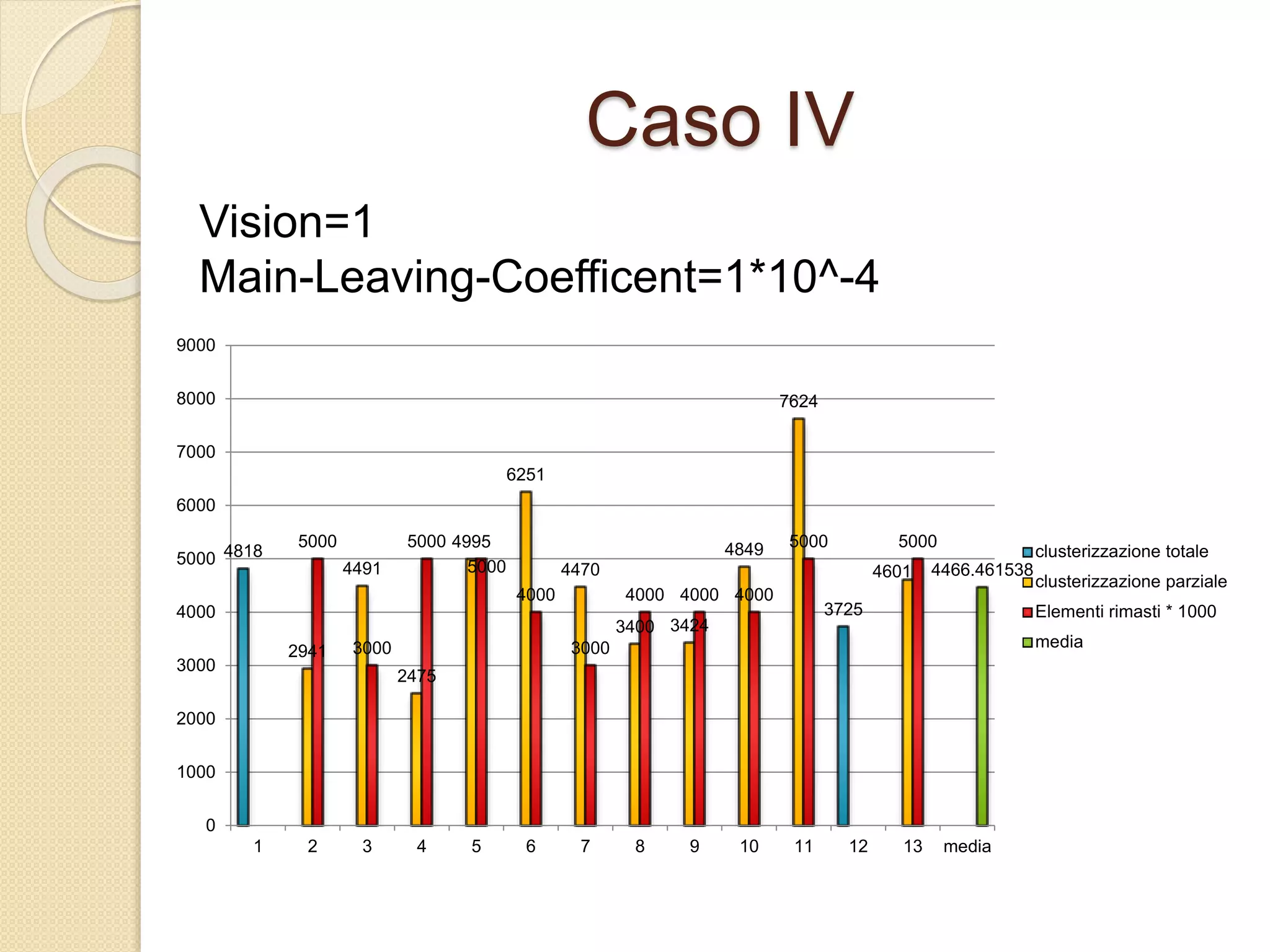
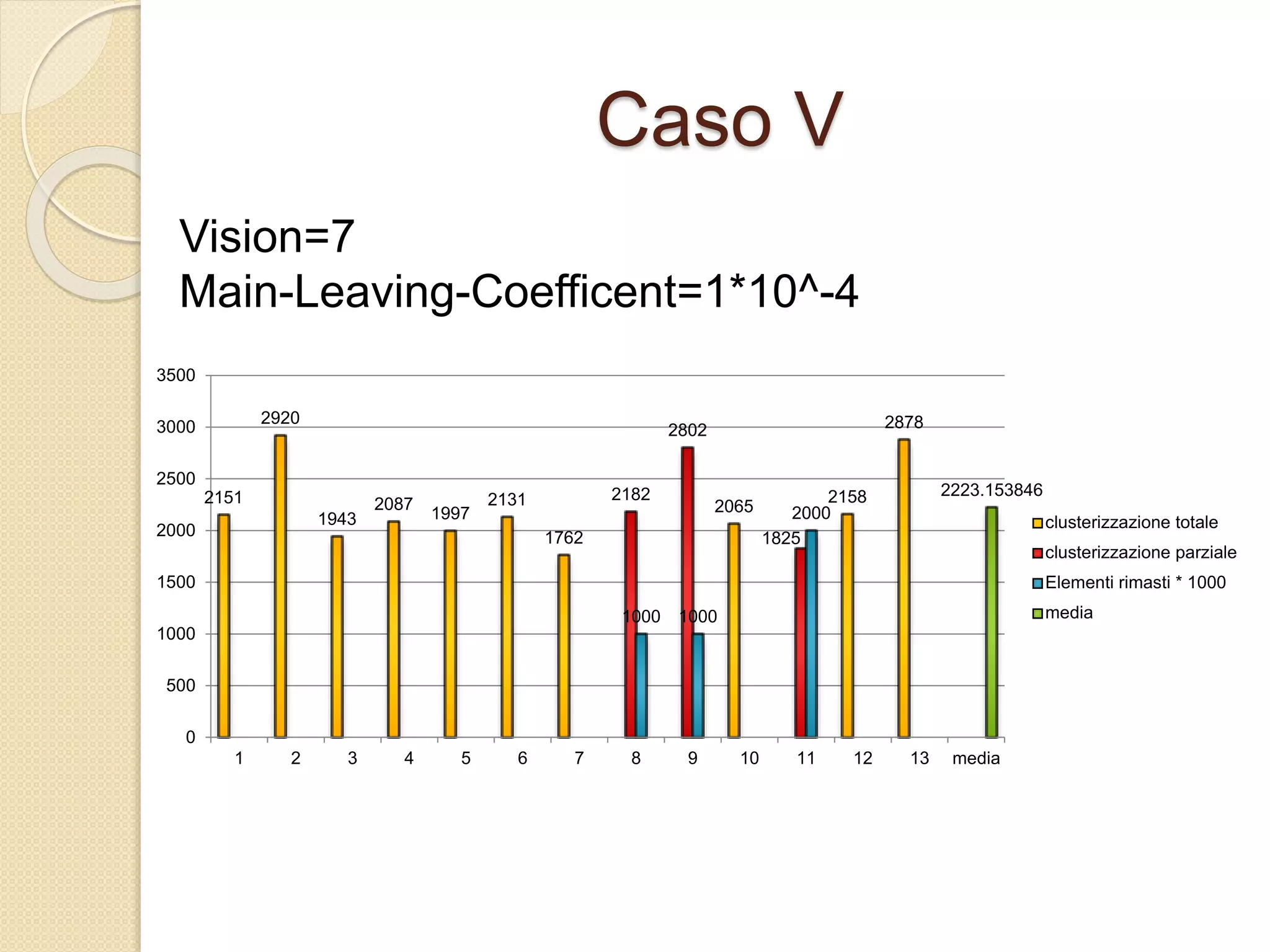
Il documento descrive lo sviluppo del CBoids Algorithm, un algoritmo per il clustering che si basa sui principi dello swarm intelligence, e introduce regole di fusione e scissione oltre a quelle di separazione, allineamento e coesione. Sperimentazioni con un dataset di animali hanno mostrato che l'algoritmo ha raggiunto una precisione media di clustering del 94%. Il progetto include una simulazione in NetLogo e suggerisce ulteriori sviluppi come l'adattamento alle dimensioni dei centroidi e test su altri database.