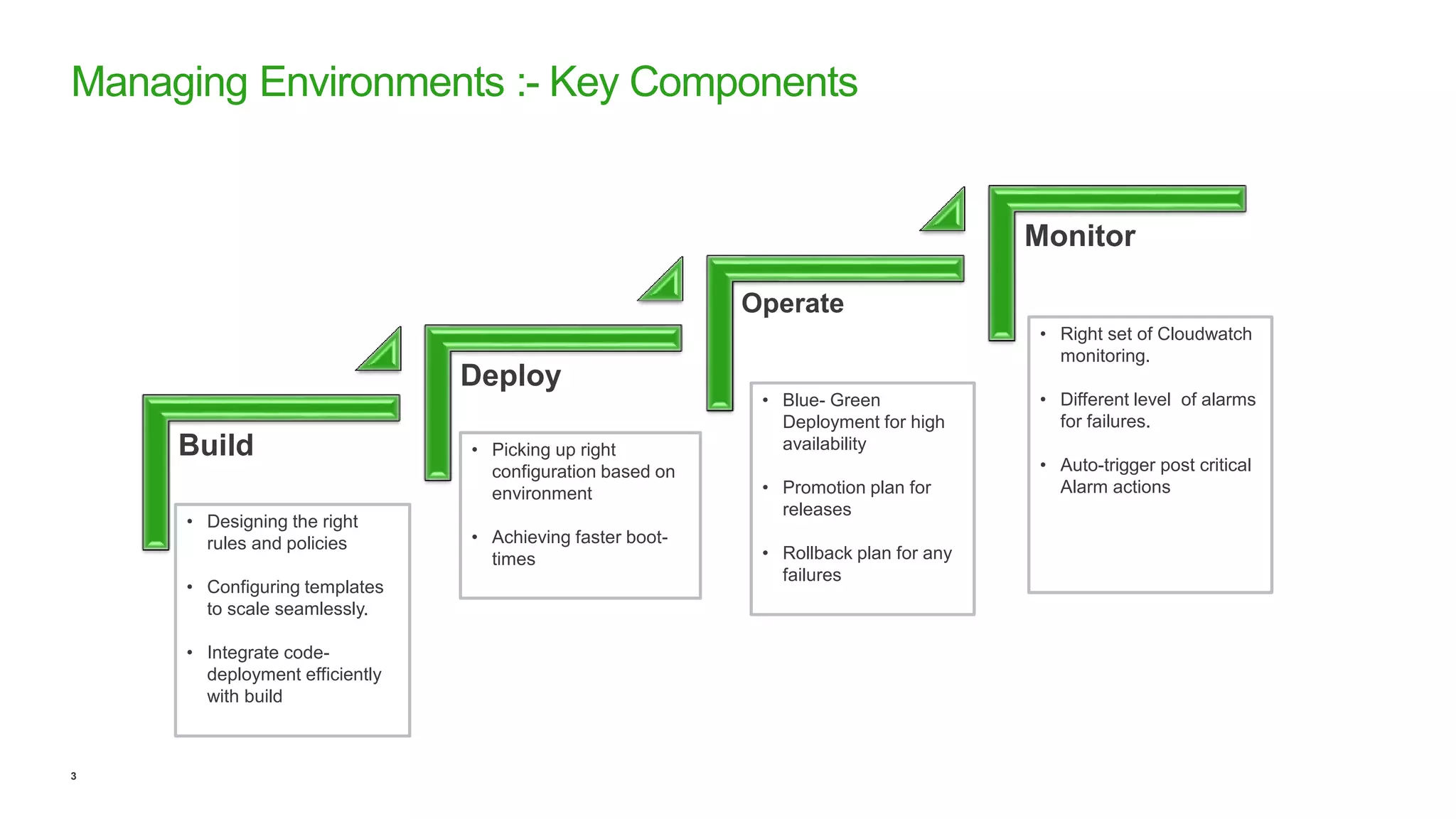
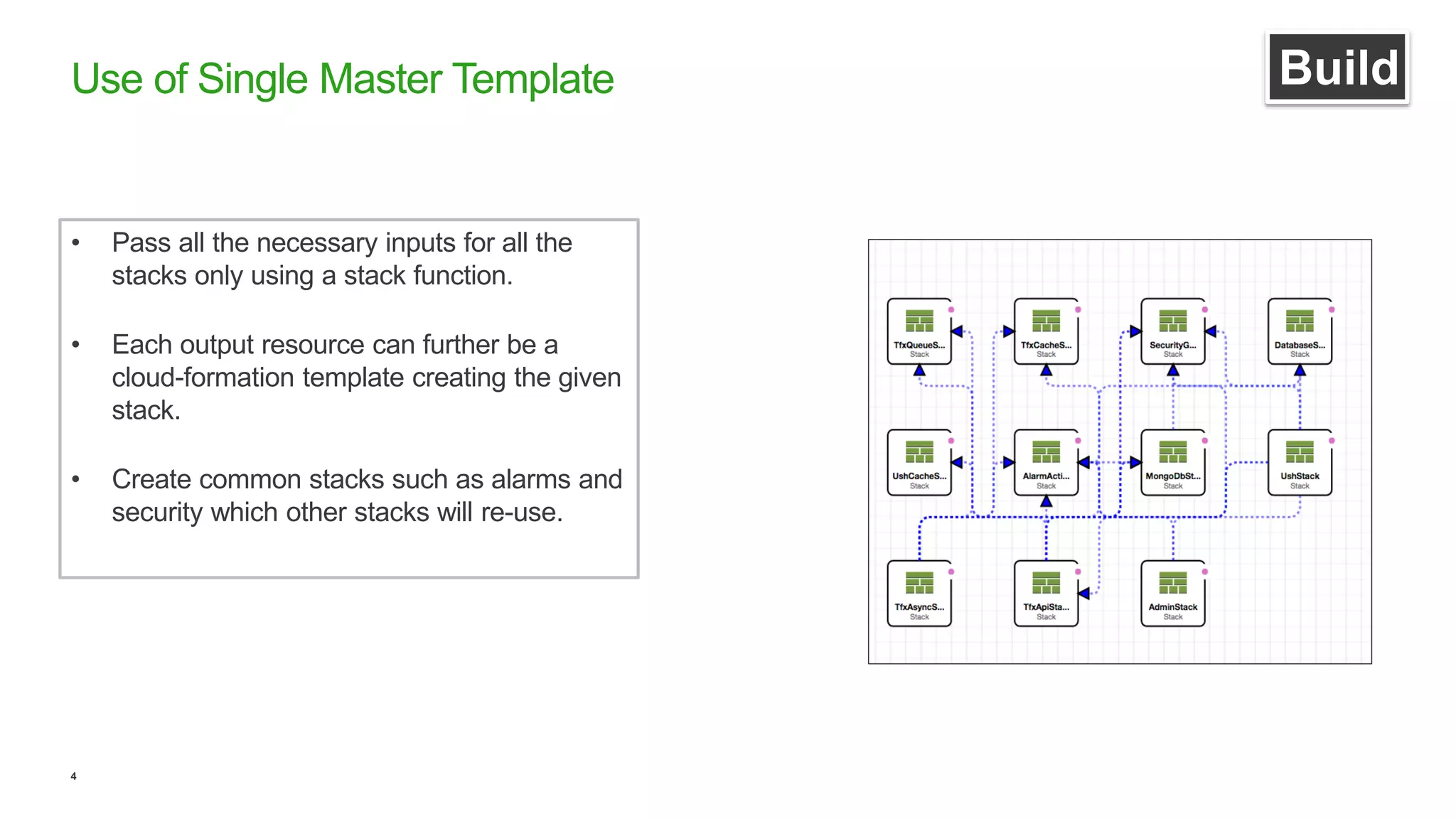
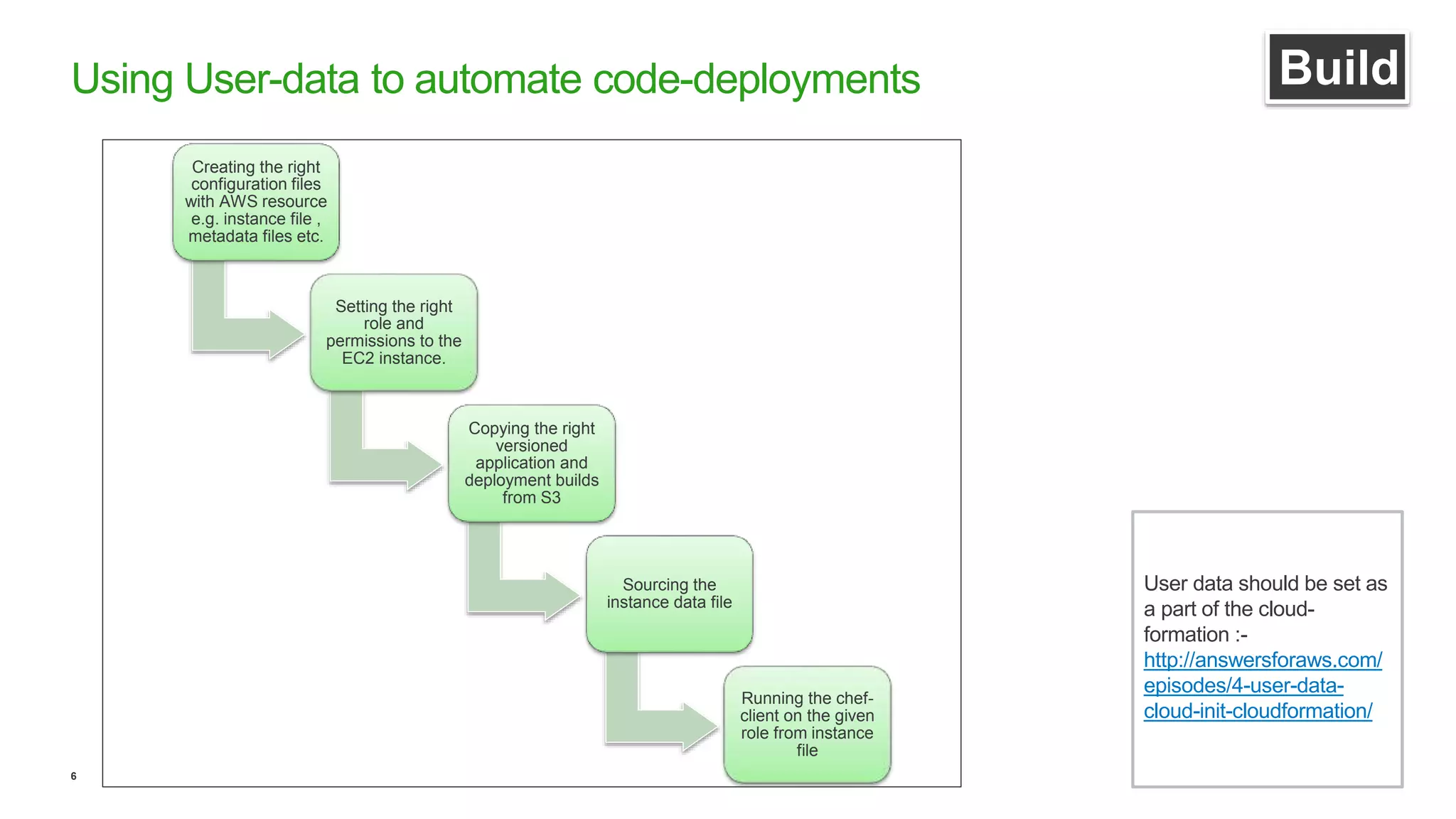
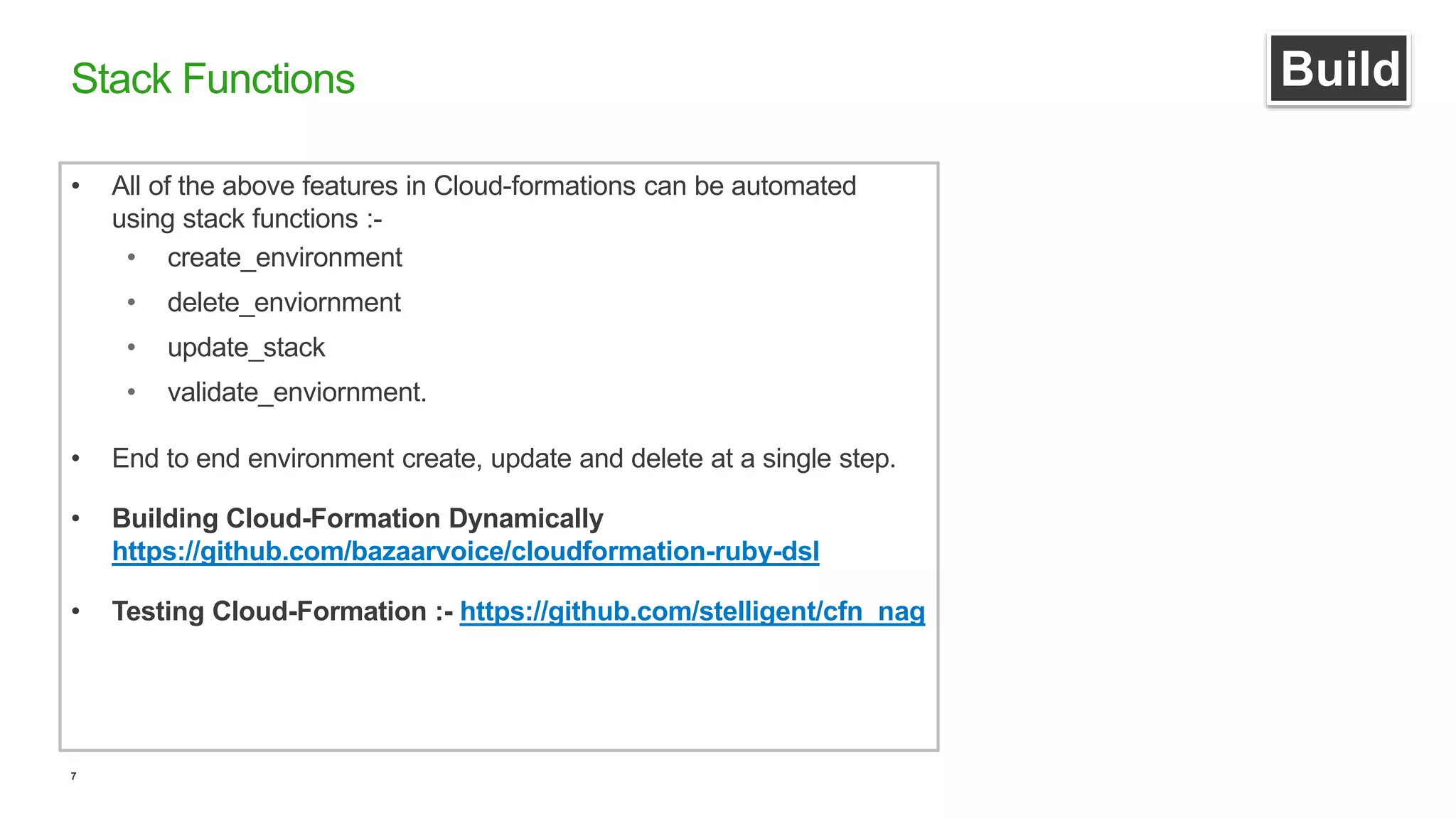
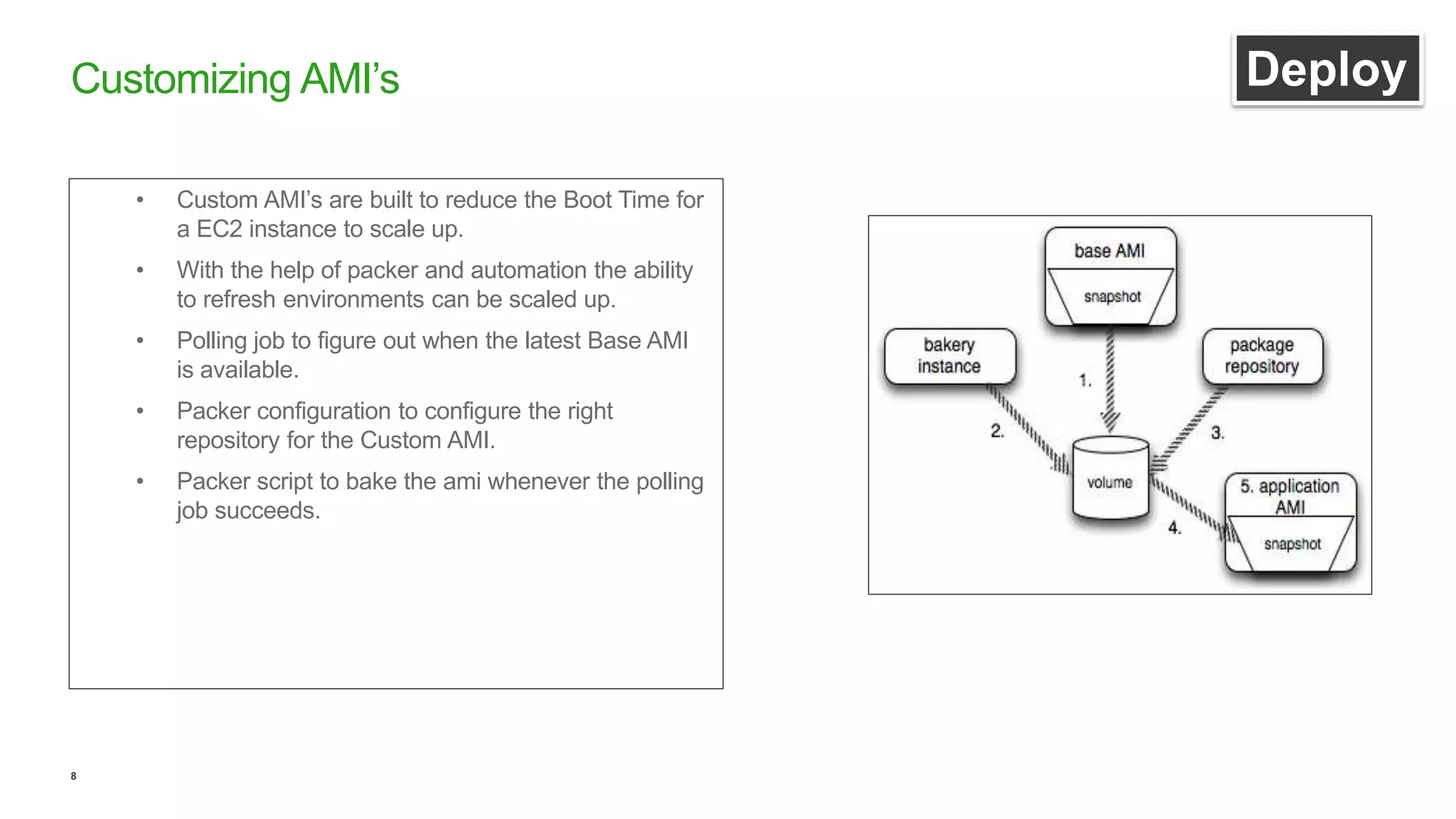
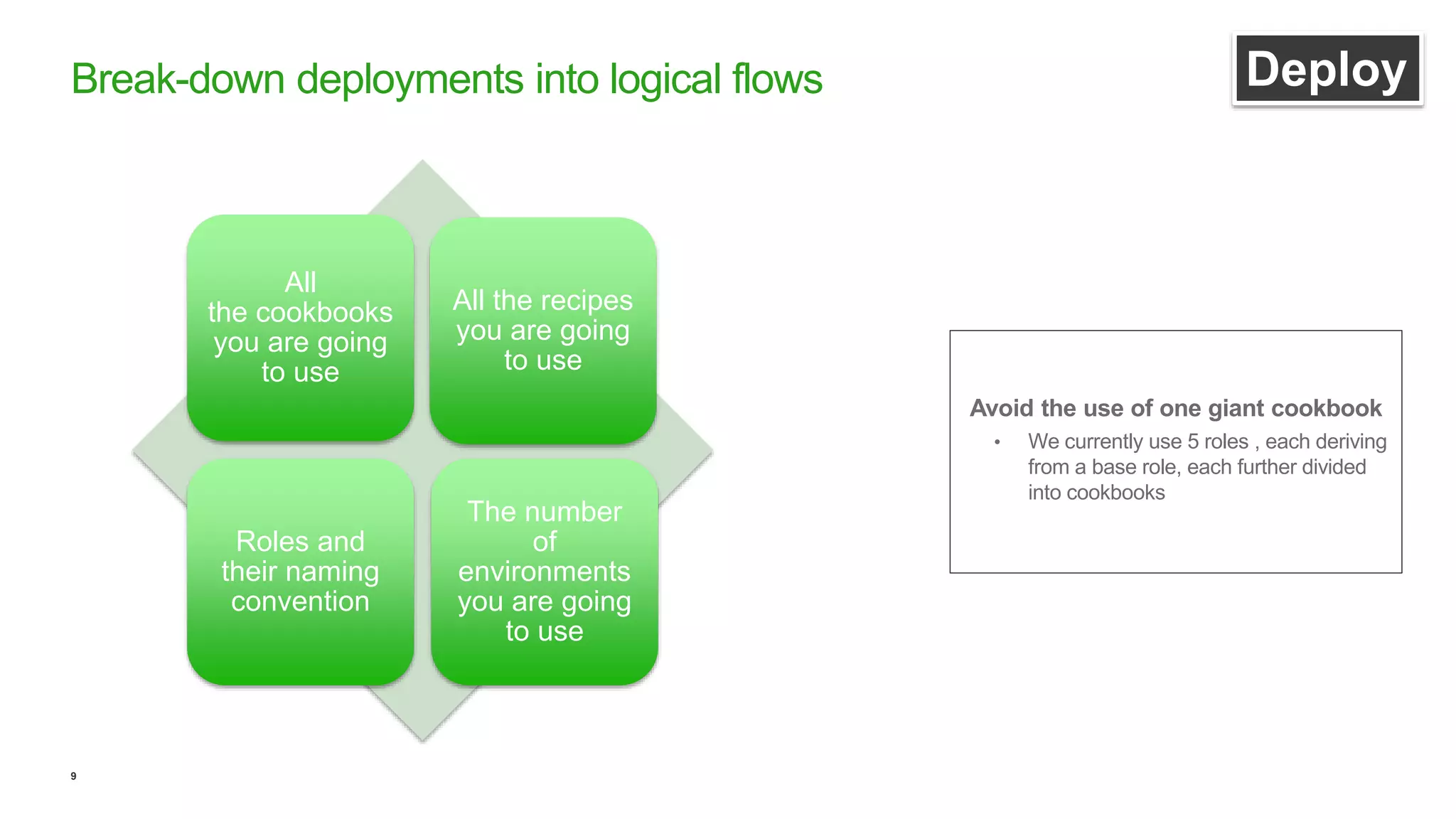
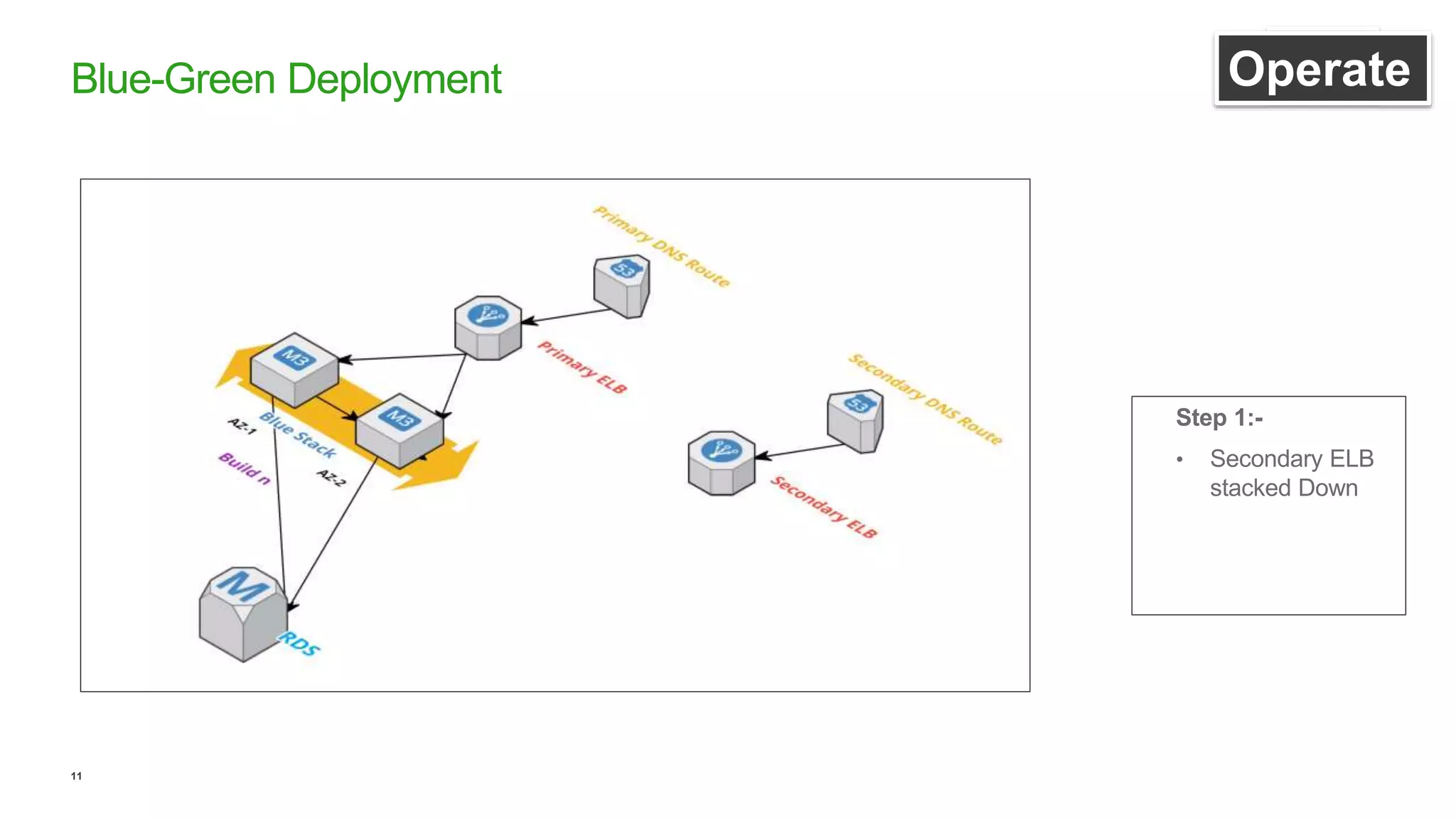
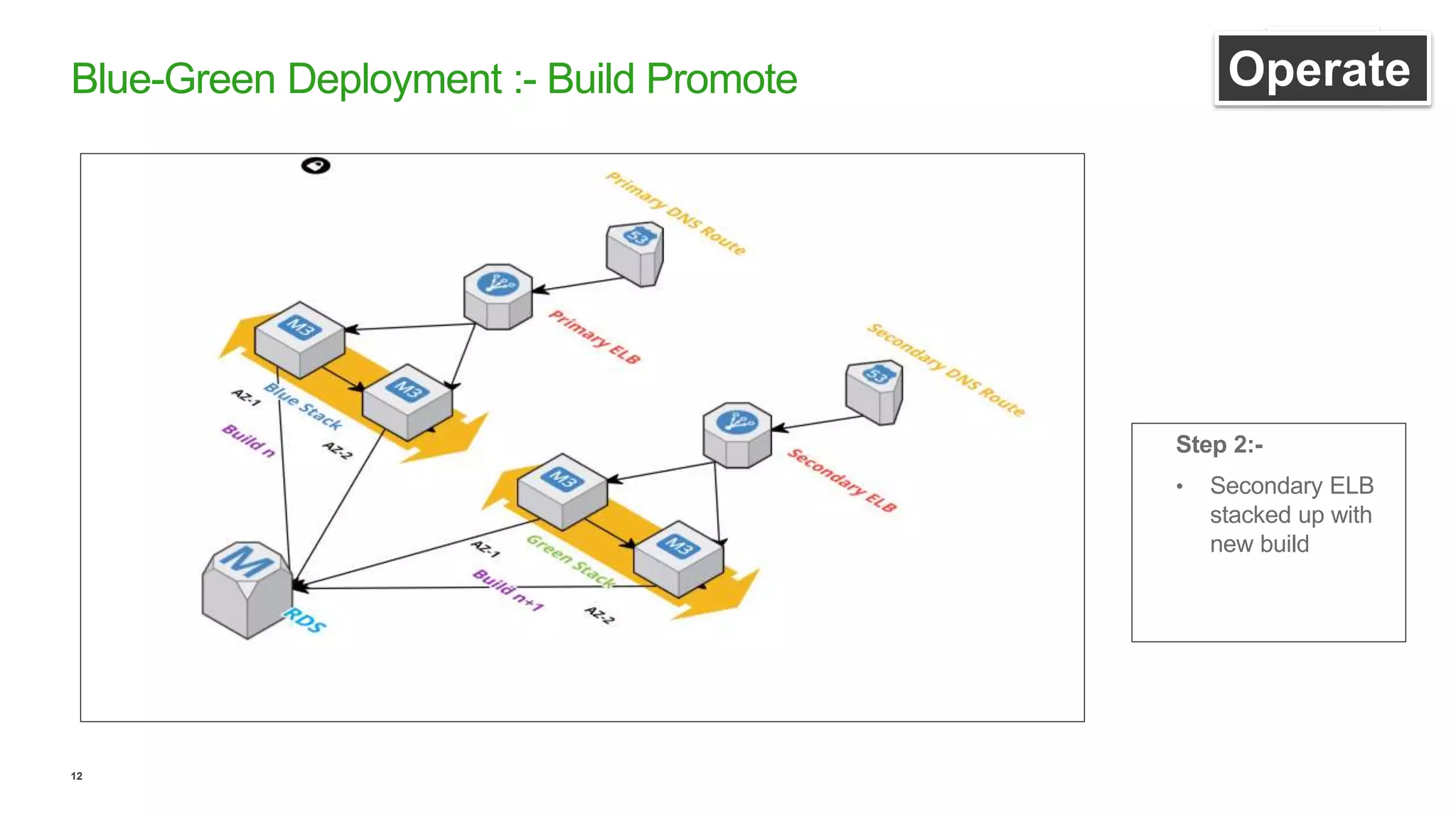
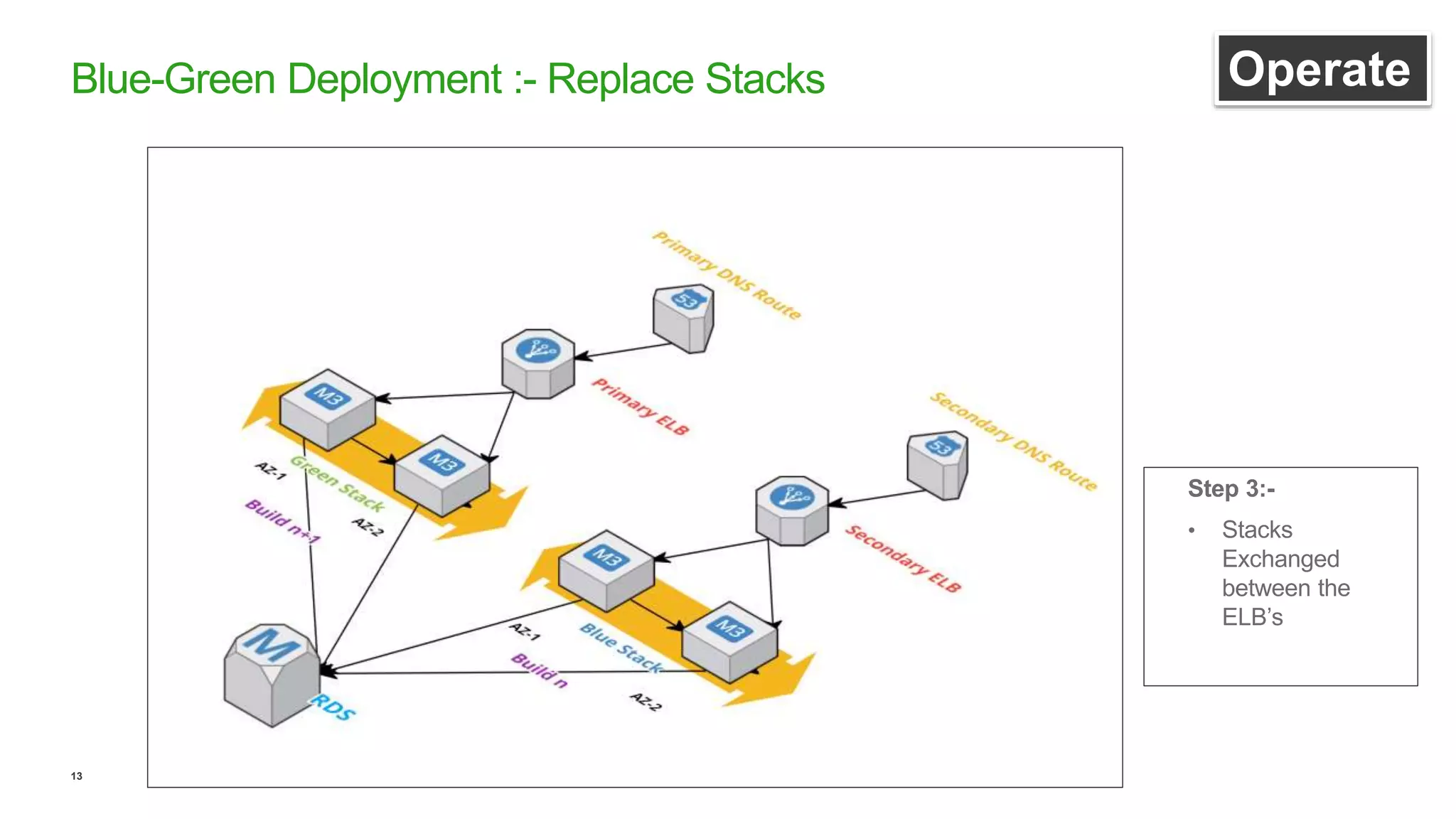
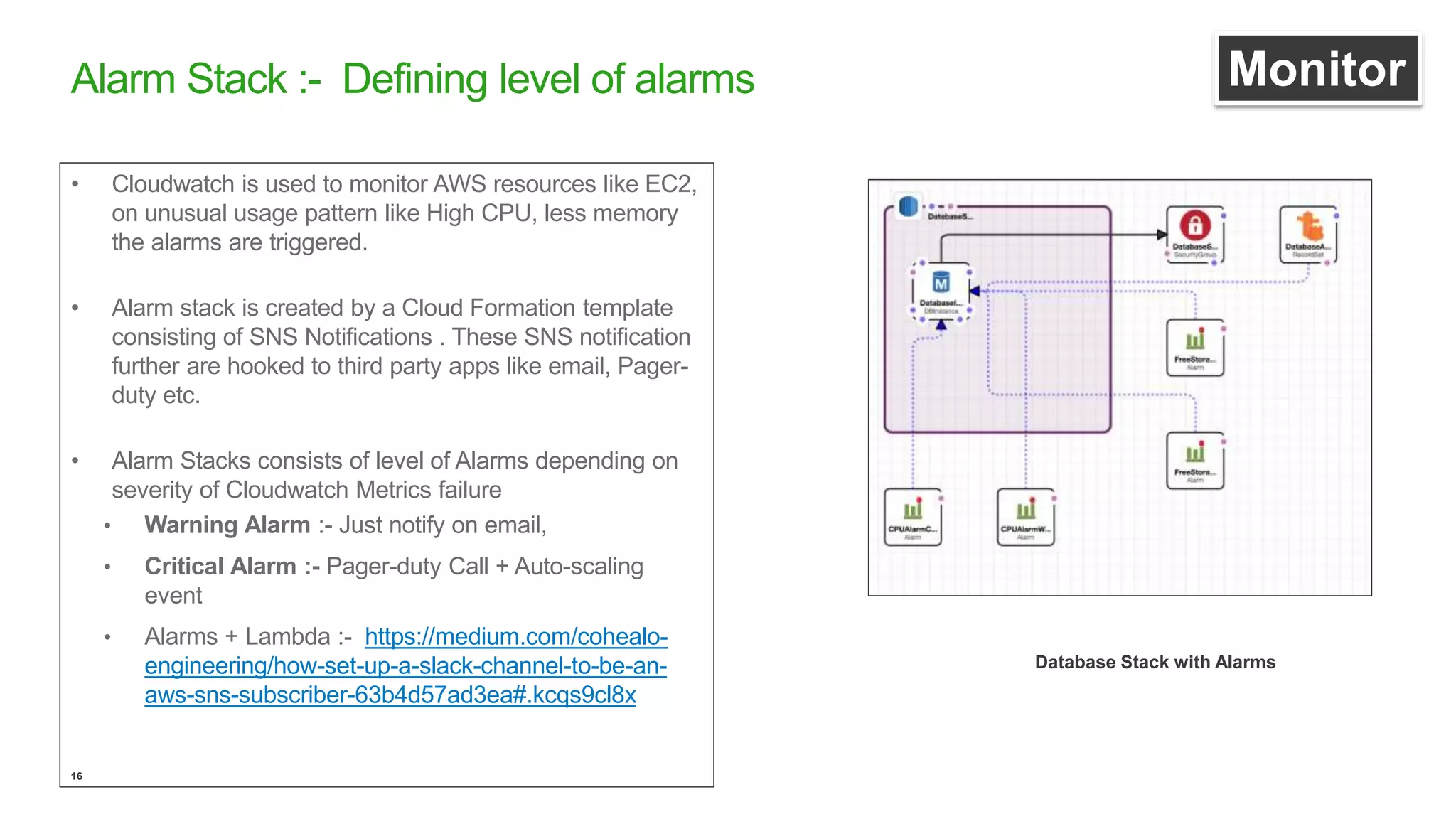
This document discusses efficient ways to manage environments in AWS using cloud formation templates. It covers key components like build, deploy, operate, and monitor. It provides guidance on using templates to configure environments, automating deployments with tools like Chef, implementing blue-green deployments, creating alarm stacks to monitor resources, and scaling infrastructure based on cloudwatch metrics. The overall aim is to achieve faster release cycles, predictability, and reliability when managing dynamic AWS infrastructure.














![[Jun AWS 201] Elastic Beanstalk for Startups](https://cdn.slidesharecdn.com/ss_thumbnails/aws201elasticbeanstalkforstartups-130708040156-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)







































































