
Recommended
Recommended
More Related Content
Featured
Featured (20)
Stealth startup AtScale lets top BI tools dip right into Hadoop data
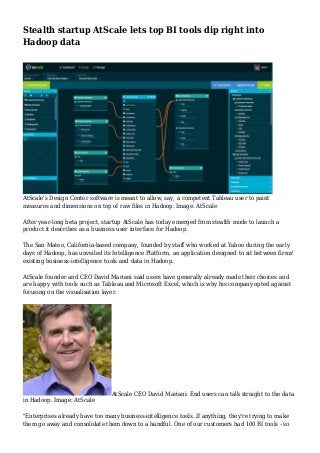
- 1. Stealth startup AtScale lets top BI tools dip right into Hadoop data AtScale's Design Center software is meant to allow, say, a competent Tableau user to paint measures and dimensions on top of raw files in Hadoop. Image: AtScale After year-long beta project, startup AtScale has today emerged from stealth mode to launch a product it describes as a business user interface for Hadoop. The San Mateo, California-based company, founded by staff who worked at Yahoo during the early days of Hadoop, has unveiled its Intelligence Platform, an application designed to sit between firms' existing business-intelligence tools and data in Hadoop. AtScale founder and CEO David Mariani said users have generally already made their choices and are happy with tools such as Tableau and Microsoft Excel, which is why his company opted against focusing on the visualisation layer. AtScale CEO David Mariani: End users can talk straight to the data in Hadoop. Image: AtScale "Enterprises already have too many business-intelligence tools. If anything, they're trying to make them go away and consolidate them down to a handful. One of our customers had 100 BI tools - so
- 2. we're not going to add another," he said. "But we are going to make those tools work and we're going to allow the data guys and IT to take the legacy data infrastructures that have been so complex and so hard to maintain and to scale, and replace them with Hadoop." According to AtScale, the application makes Hadoop appear to business users as a multi-dimensional OLAP cube, in which data is already classed into dimensions, measures and hierarchies to speed up queries. "To the end user it all looks and works just like it used to against their proprietary cubes, when in actuality they're talking straight to the data in Hadoop through AtScale," Mariani said. The subscription-based software is installed on a client or gateway node on a Hadoop cluster, rather than on the cluster itself and does not require either a separate cluster, dataset or set of servers to manage the cube. Part of the company's approach has been to avoid creating client software and drivers, because of the cost and complexity that imposes on enterprises. "The key thing here is that we are very much leveraging the Hadoop ecosystem, including all the various SQL-on-Hadoop engines - like Impala, Spark and Spark SQL, Hive on Tez, Presto and Drill," Mariani said. "We provide a cube interface - a dynamic cube, so not a physical entity - that users interact with using their visualisation tools. What our software does is talk to Hadoop through those SQL-o- -Hadoop engines and delivers really OLAP cube-like performance in the interface, which are the measures, dimensions and hierarchies and drill-downs and cross-tabs that users have come to expect. "The cube is purely dynamic. It's metadata that's defined on top of Hadoop. Once data lands in HDFS, it's queryable and actionable by the upscale platform. So it's a no-data-movement architecture, which is really different to what you're seeing in the marketplace." Because of that architecture, there are no extraction or load processes. Transformation is conducted inline at query time. "It's a true schema-on-read as opposed to a schema-on-load architecture. The cube definition itself contains the transformations. They're all centralised in metadata and hosted on the cluster - so you can think of it as that sort of semantic business layer on top of Hadoop. The transformations are injected at query time when users are interacting with the business-visualisation tools," Mariani said. The cube itself is built up in AtScale's Design Center, seen above, which is designed to enable, say, a competent Tableau user to paint measures and dimensions on top of raw files in Hadoop. "The technology is we talk through the Hive metastore, because that's how we understand what the definition of those files are. An experienced business user will then paint the measures, the dimensions, define the calculations as well as the hierarchies, and then that gets published out to the BI tools," he said.
- 3. "If you're connecting through Excel, we look like an [Microsoft SQL Server] Analysis Services cube, we look like MPX [Microsoft Project Exchange]. If you were to connect, for example, through Tableau, we look like a Hive server and your access in Tableau would be speaking SQL to us. So you can speak SQL or you can speak MPX to AtScale, and we're going to translate that on the fly into queries directly against Hadoop." During its two-year stealth mode period, AtScale has built a number of partnerships with Altiscale, Cloudera, Databricks, Hortonworks and MapR, as well as on the business-intelligence side with Microsoft, QlikTech, and Tableau. AtScale aims to offer Hadoop query times of one second or less through the use of real-time data aggregation. "We're actually computing and maintaining aggregates automatically for users, by examining those query patterns and being smart about when we reaggregate versus when we access data live on the cluster. By a combination of those aggregates and those SQL-on-Hadoop engines like Impala and Spark SQL, we're able to deliver a consistent one second or less query performance," Mariani said. "Why reaggregate, why resum something on the fly that's not changing? Why pass billions or even trillions of lines in a file when you've already done that once? What we do is blend the historical aggregates in with the live data, so we're not putting a load on the Hadoop cluster and doing things over and over again when they don't need to be." More on Hadoop and big data http://zdnet.com.feedsportal.com/c/35462/f/675847/s/4523f667/sc/28/l/0L0Szdnet0N0Carticle0Csteal th0Estartup0Eatscale0Elets0Etop0Ebi0Etools0Edip0Eright0Einto0Ehadoop0Edata0C0Tftag0FRSSb affb68/story01.htm