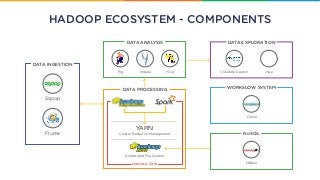
The Hadoop ecosystem is continuously growing to meet the needs of Big Data. This slideshare presentation will help you understand the role of each component of the Hadoop ecosystem.
The popularity ofHadoop has grown in the last few years, because
it meets the needs of many organizations for flexible data analysis
capabilities with an unmatched price-performance curve.
The Hadoop ecosystem is continuously growing to meet the needs
of Big Data. Let’s understand the role of each component of the
Hadoop ecosystem.
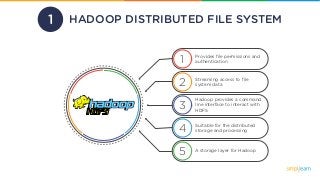
Provides file permissionsand
authentication1
Streaming access to file
system data2
Hadoop provides a command
line interface to interact with
HDFS
3
Suitable for the distributed
storage and processing4
A storage layer for Hadoop
5
HADOOP DISTRIBUTED FILE SYSTEM1
8.
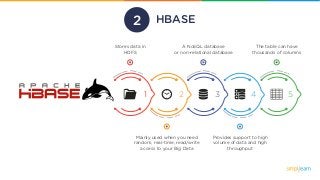
HBASE
Stores data in
HDFS
Mainlyused when you need
random, real-time, read/write
access to your Big Data
A NoSQL database
or non-relational database
Provides support to high
volume of data and high
throughput
The table can have
thousands of columns
1 2 3 4 5
2
9.
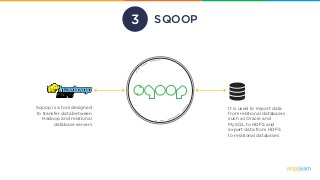
SQOOP
Sqoop is a tooldesigned
to transfer data between
Hadoop and relational
database servers
It is used to import data
from relational databases
such as Oracle and
MySQL to HDFS and
export data from HDFS
to relational databases
3
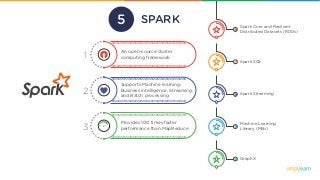
SPARK
1
An open-source cluster
computingframework
3
Provides 100 times faster
performance than MapReduce
2
Supports Machine learning,
Business intelligence, Streaming,
and Batch processing
Spark Core and Resilient
Distributed Datasets (RDDs)
Spark SQL
Spark Streaming
Machine Learning
Library (Mlib)
GraphX
5
12.
HADOOP MAPREDUCE
4
3
2
1Commonly used
Anextensive and mature
fault tolerance framework
The original Hadoop processing
engine which is primarily Java based
Based on the map and
reduce programming model
6
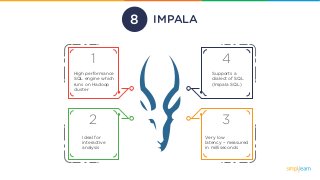
IMPALA
1
High performance
SQL enginewhich
runs on Hadoop
cluster
2
Ideal for
interactive
analysis
4
Supports a
dialect of SQL
(Impala SQL)
3
Very low
latency – measured
in milliseconds
8
CLOUDERA SEARCH
One ofCloudera's
near-real-time access
products
Users do not need SQL or
programming skills to use
Cloudera Search
A fully integrated data
processing platform
Enables non-technical users
to search and explore data
stored in or ingested into
Hadoop and HBase
10
17.
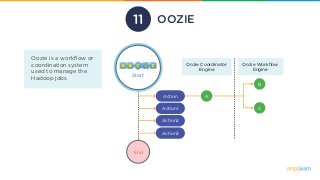
OOZIE
Oozie is aworkflow or
coordination system
used to manage the
Hadoop jobs
End
Action
Action1
Action2
Action3
A
B
C
Oozie Coordinator
Engine
Oozie Workflow
Engine
Start
11
18.
HUE
Hue is anopen source
Web interface for
analyzing data with
Hadoop
It provides SQL editors
for Hive, Impala, MySQL,
Oracle, PostgreSQL,
Spark SQL, and Solr SQL
12












































![[DSC Europe 25] Jean Del Rosario - How to Reduce GenAI Costs up to 73.45%.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/zjehcwqsiwjisav1znml-5-251217093201-eae4440a-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DSC Europe 25] Miodrag Pesovic & Vladislav Radonjic - Federated Data Archite...](https://cdn.slidesharecdn.com/ss_thumbnails/gsbe3y5it5uhndi4e08e-1-251212103249-f1008e0c-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DSC Europe 25] Ivan Peric - Intelligence Swarm Logic and Techno-Functional M...](https://cdn.slidesharecdn.com/ss_thumbnails/7my7c97fsduiccadgavw-2-251212103249-5a03f7c6-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DSC Europe 25] Djordje Hirs - Revolutionizing Telco Customer Experience with...](https://cdn.slidesharecdn.com/ss_thumbnails/zif75aur3qscnckv6tnc-djordje-hirs-cc-dsc2025-1-251219145617-679178aa-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Francisco Prado Moreno - Model Validation in the Age of AI: T...](https://cdn.slidesharecdn.com/ss_thumbnails/2igqvkir1yd2yzlhoylg-3-251215095918-6676c4e6-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Nikolay Burlutskiy - Best Practices for Building Enterprise M...](https://cdn.slidesharecdn.com/ss_thumbnails/uirvaiuvq8y1w8hzd9tx-7-251212103249-2619edb4-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Tatevik Maytesyan - How to actually use AI in marketing: gett...](https://cdn.slidesharecdn.com/ss_thumbnails/tjo626lsqdgfntbgl2mw-4-251216103155-e36cd239-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DSC Europe 25] Branko Urosevic -Rethinking Financial Talent: Integrating Cod...](https://cdn.slidesharecdn.com/ss_thumbnails/8jjrus8ttko6qj64f58f-3-251212103250-642c6374-thumbnail.jpg?width=640&height=640&fit=bounds)
