Downloaded 18 times




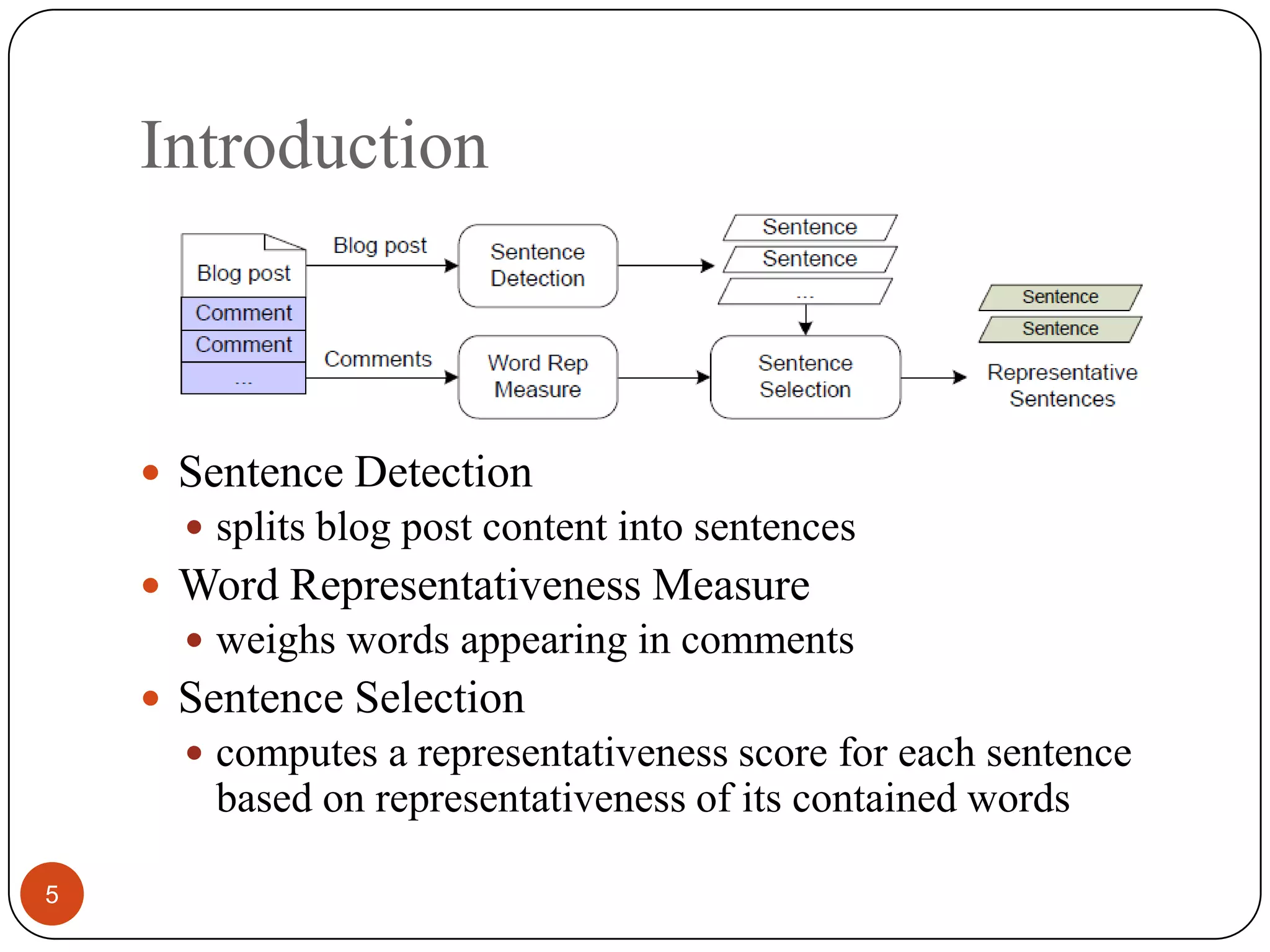











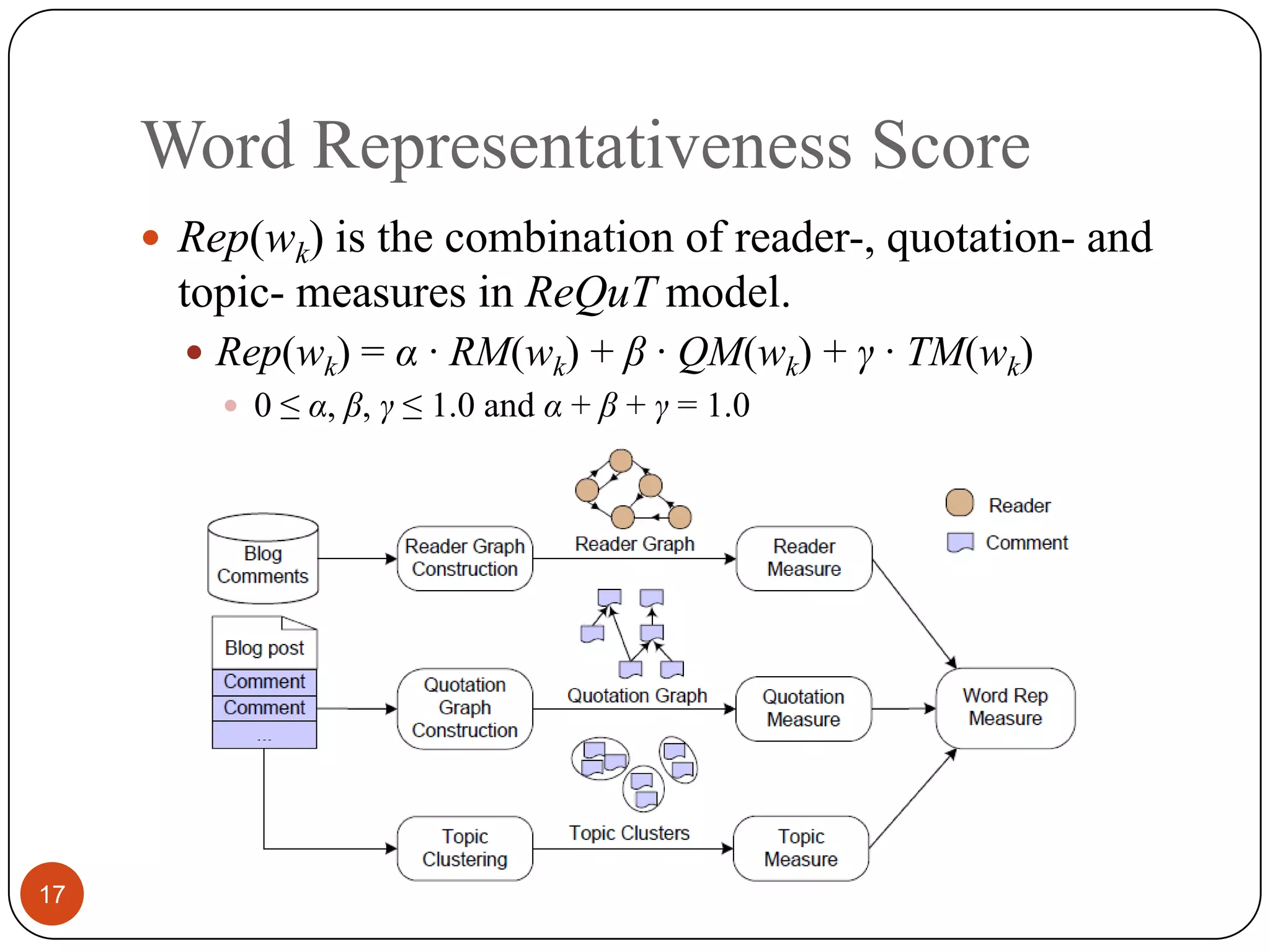








This paper proposes a comments-oriented blog post summarization approach called ReQuT that extracts representative sentences from blog posts using information from associated comments. ReQuT measures word representativeness based on three aspects: reader authority, quotation frequency, and topic importance. It then computes representativeness scores for sentences based on the representativeness of constituent words to select sentences for the summary. A user study found that reading associated comments does change readers' understanding of blog posts. Experimental results showed that ReQuT outperformed baseline methods in generating summaries.



























