Downloaded 16 times

![Introduction
Spanish-
English
Tamil-
French
Hopi-
Tewa
Marta: Ana, if I leave her here would you send her upstairs when you leave?
Zentella: I’ll tell you exactly when I have to leave, at ten o’clock. Y son las nueve y
cuarto. ("And it’s nine fifteen.")
Selvamani: Parce que n’importe quand quand j’enregistre ma voix ça l’aire d’un garçon.
([in French] "Because whenever I record my voice I sound like a guy.")
Alors, TSÉ, je me ferrai pas poigné ("So, you know, I’m not going to be had.")
[laughter]
Selvamani: ennatā, ennatā, enna romba ciritā? ([in Tamil] "What, what, what's so
funny?")
Speaker A: Tututqaykit qanaanawakna. ([in Hopi] "Schools were not wanted.")
Speaker B: Wédít’ókánk’egena’adi imbí akhonidi. ( [in Tewa] "They didn’t want a
school on their land.")
2](https://image.slidesharecdn.com/paclicharshjhamtani-141221001822-conversion-gate02/75/Word-level-language-identification-in-code-switched-texts-2-2048.jpg)












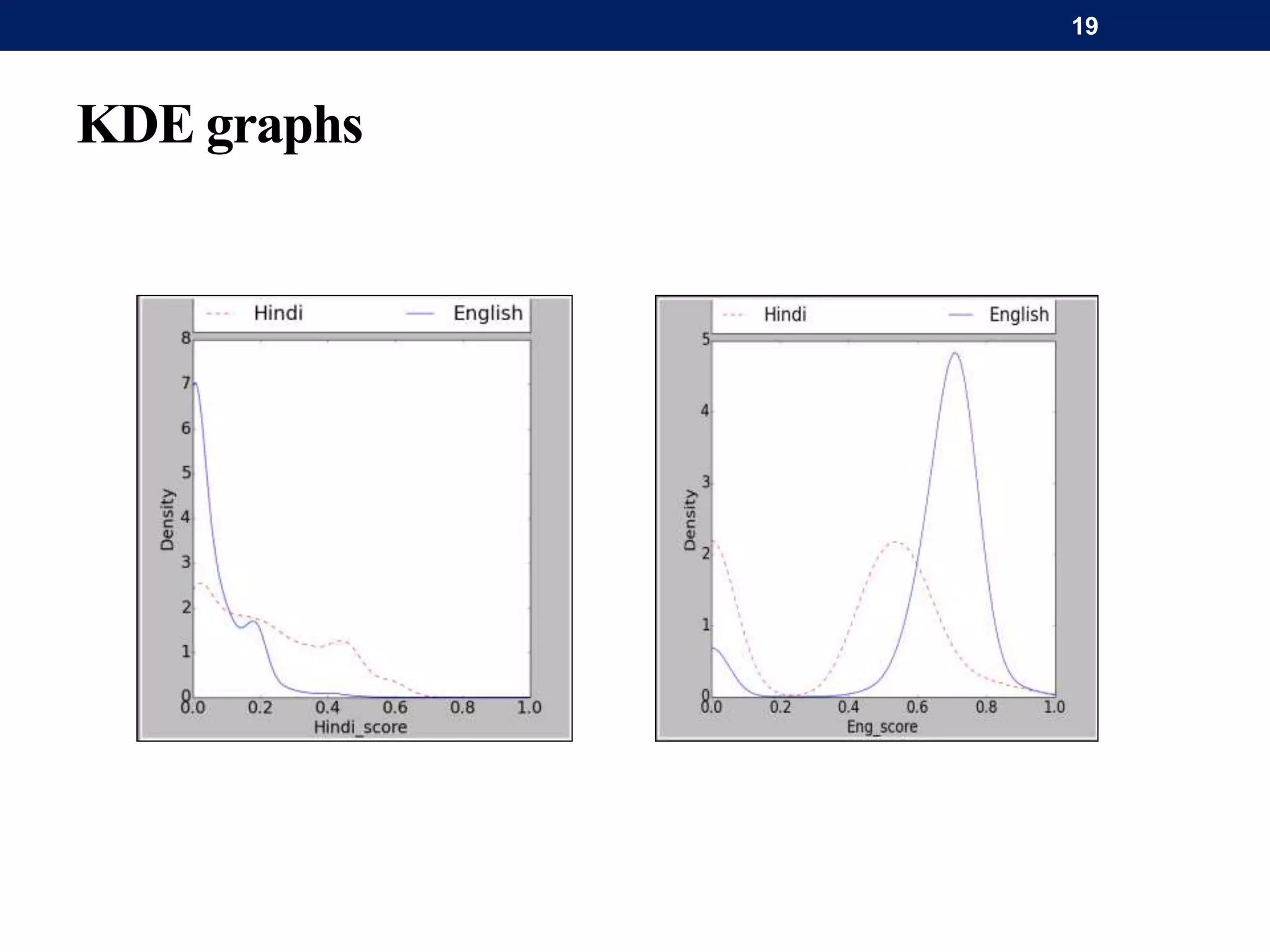
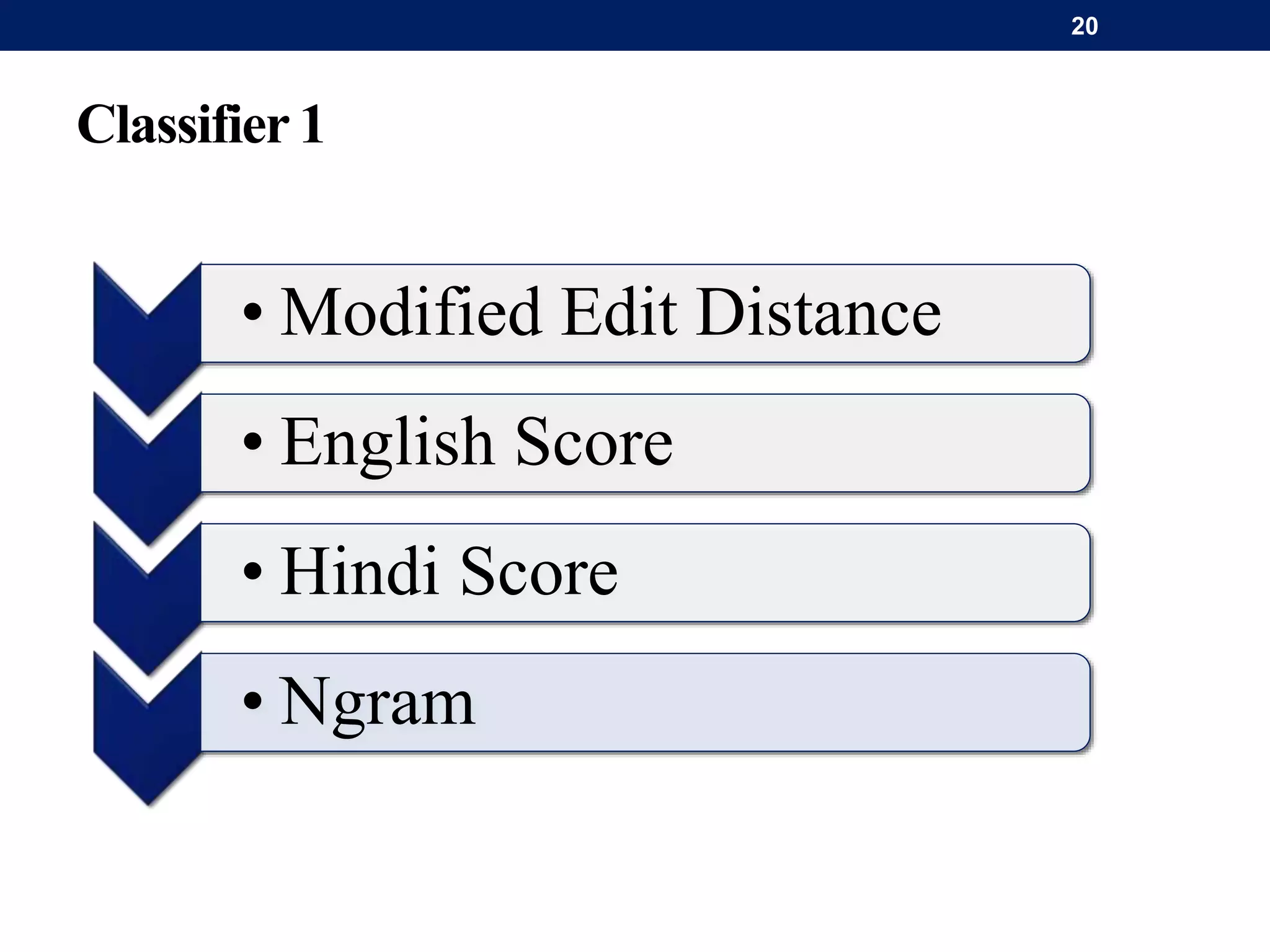

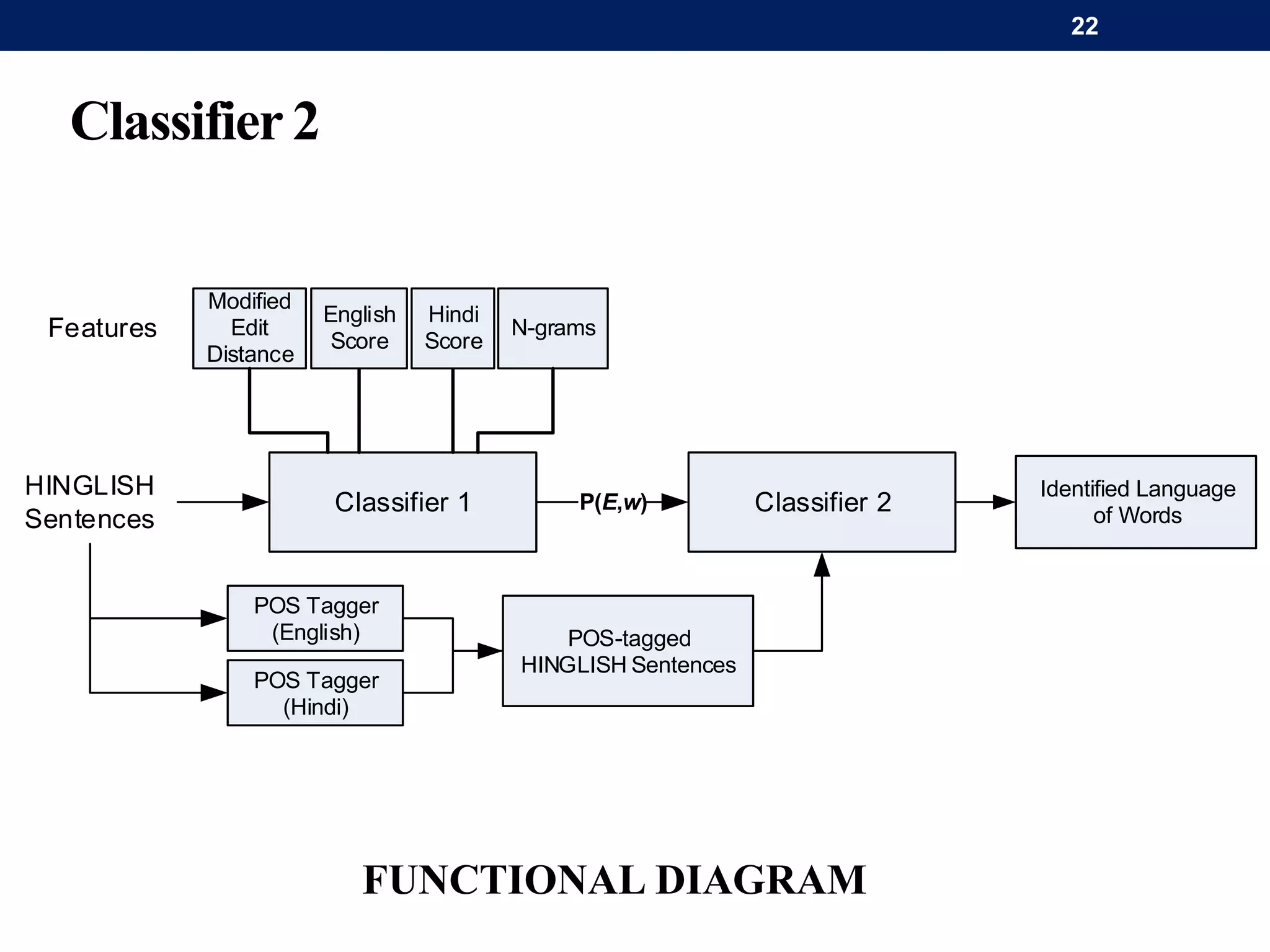




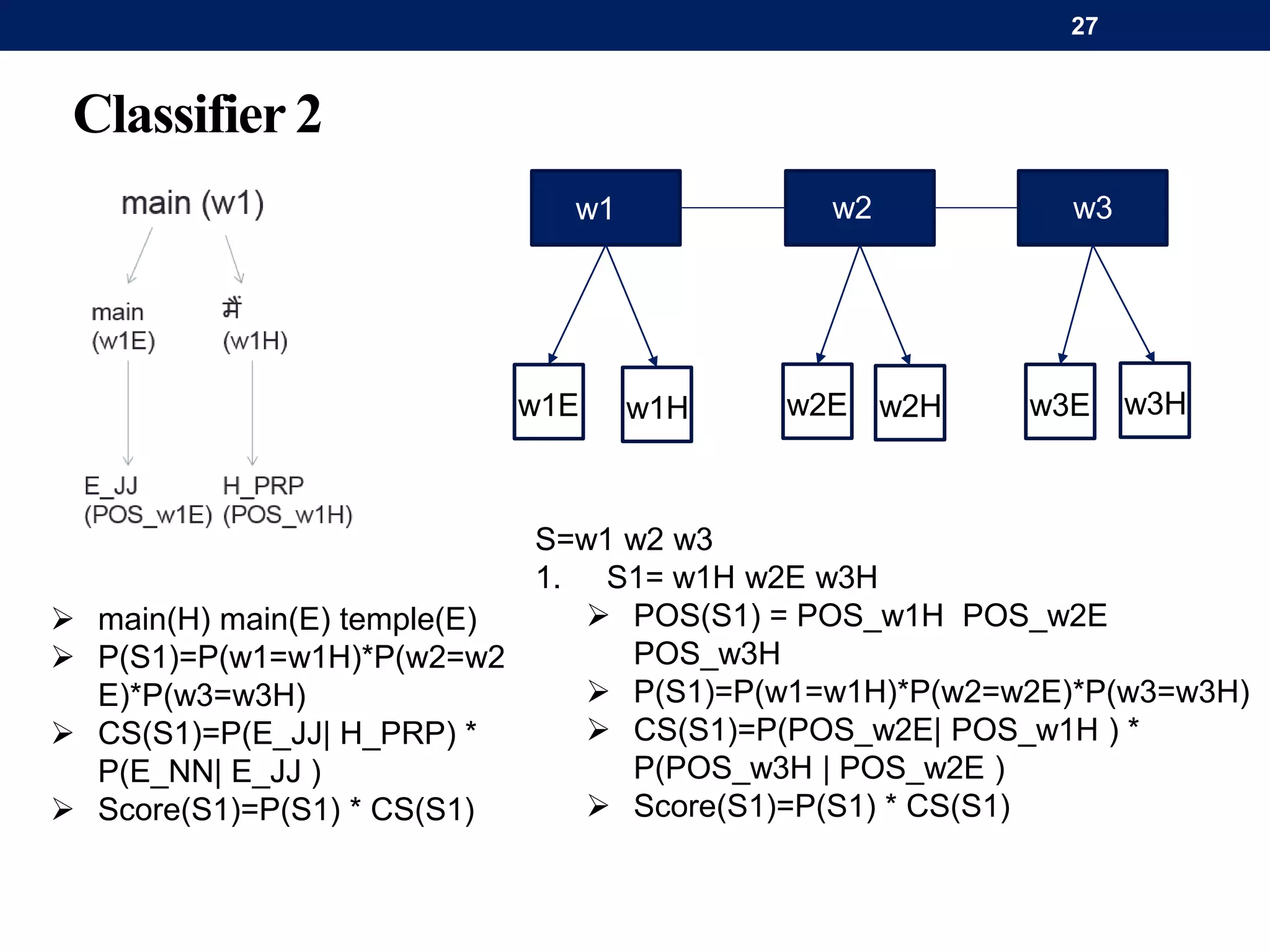

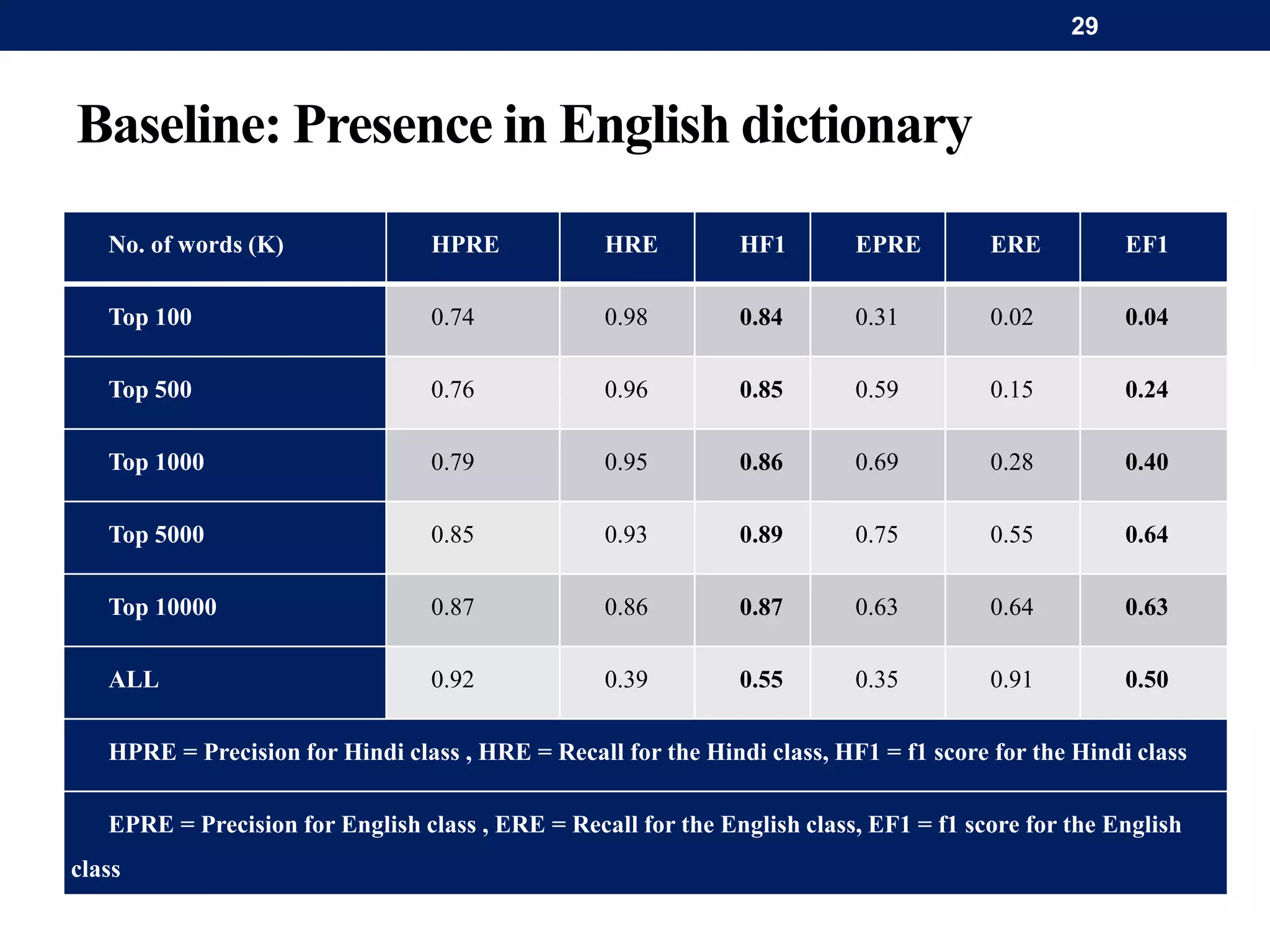
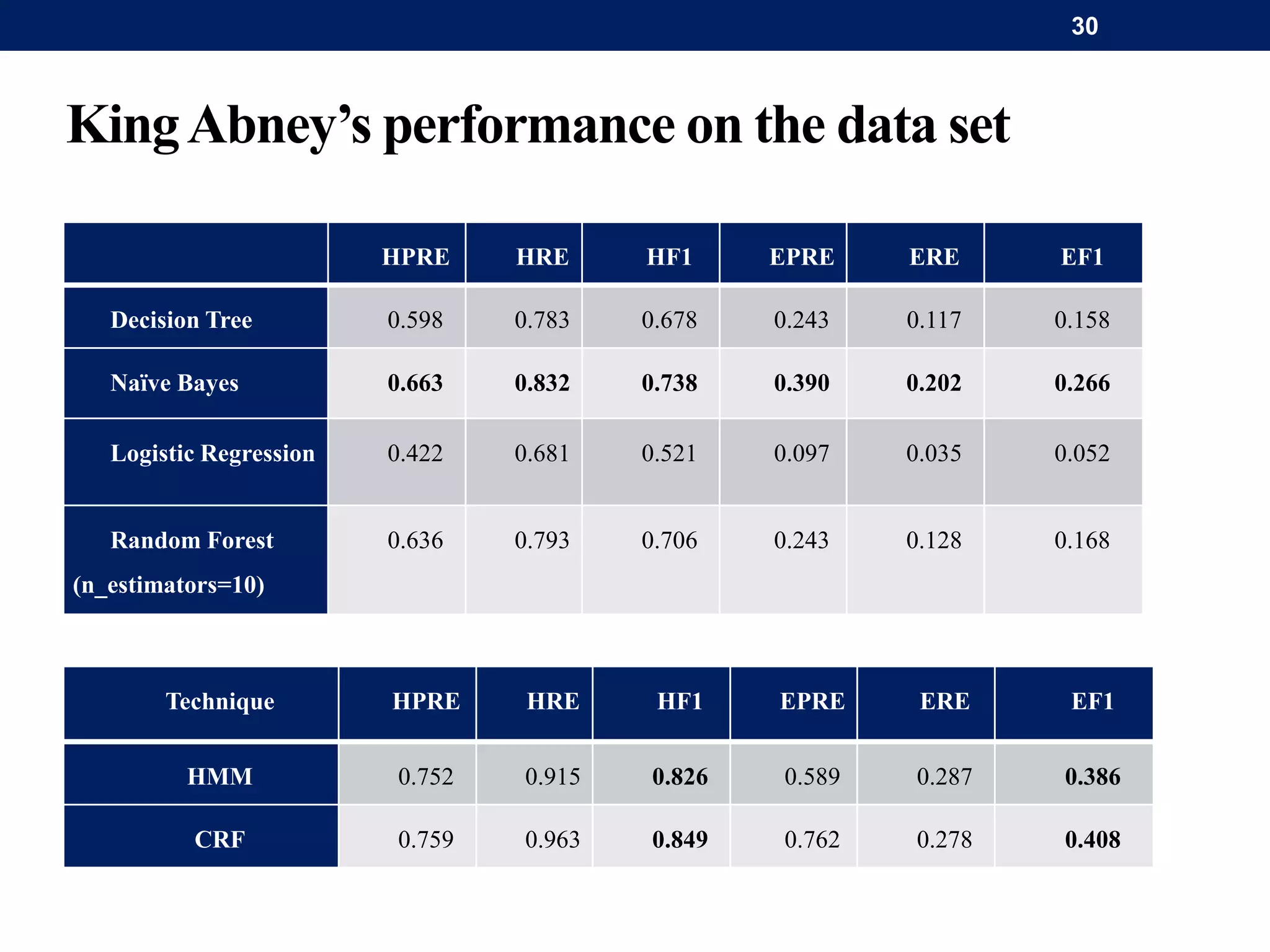
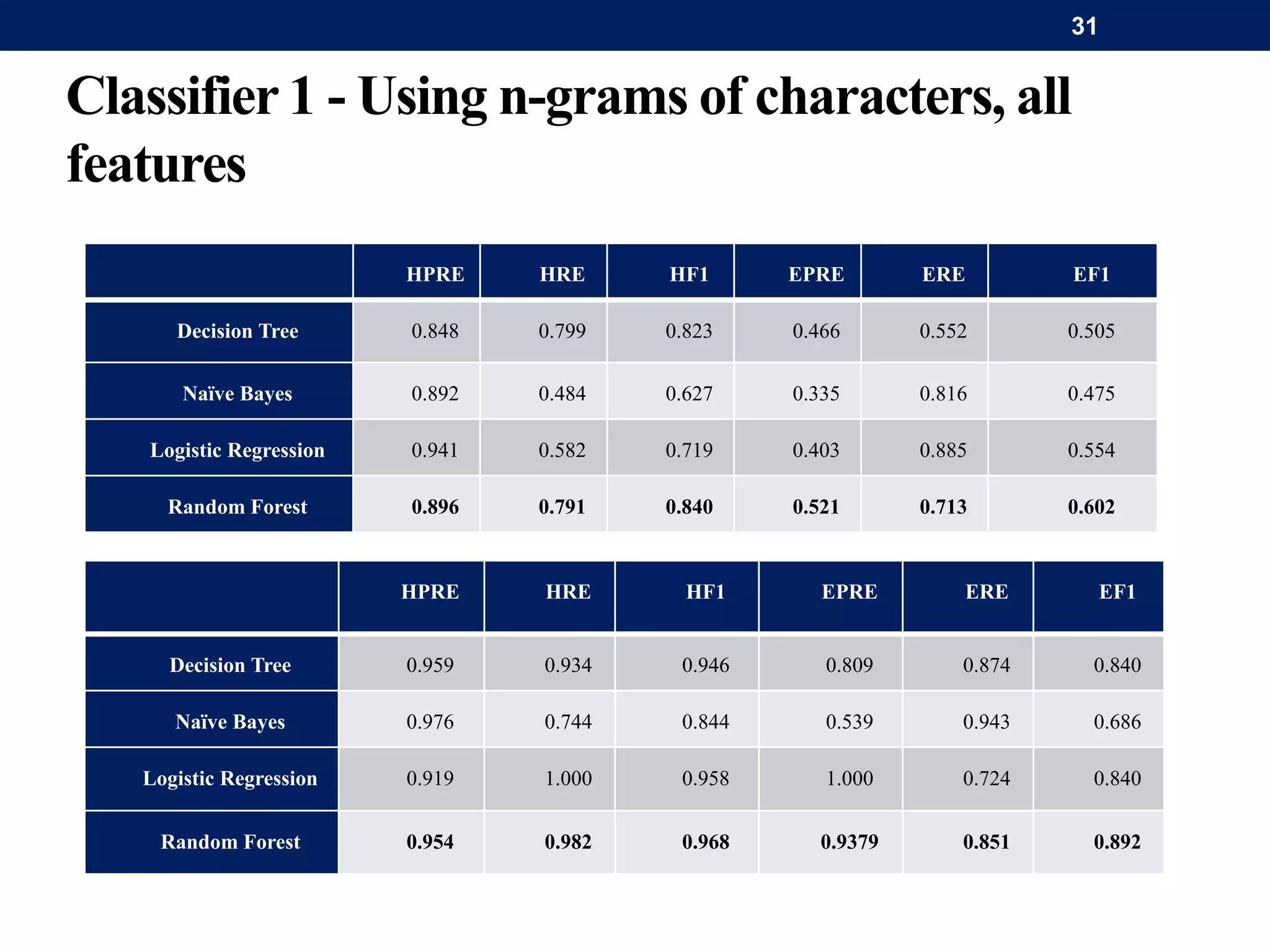
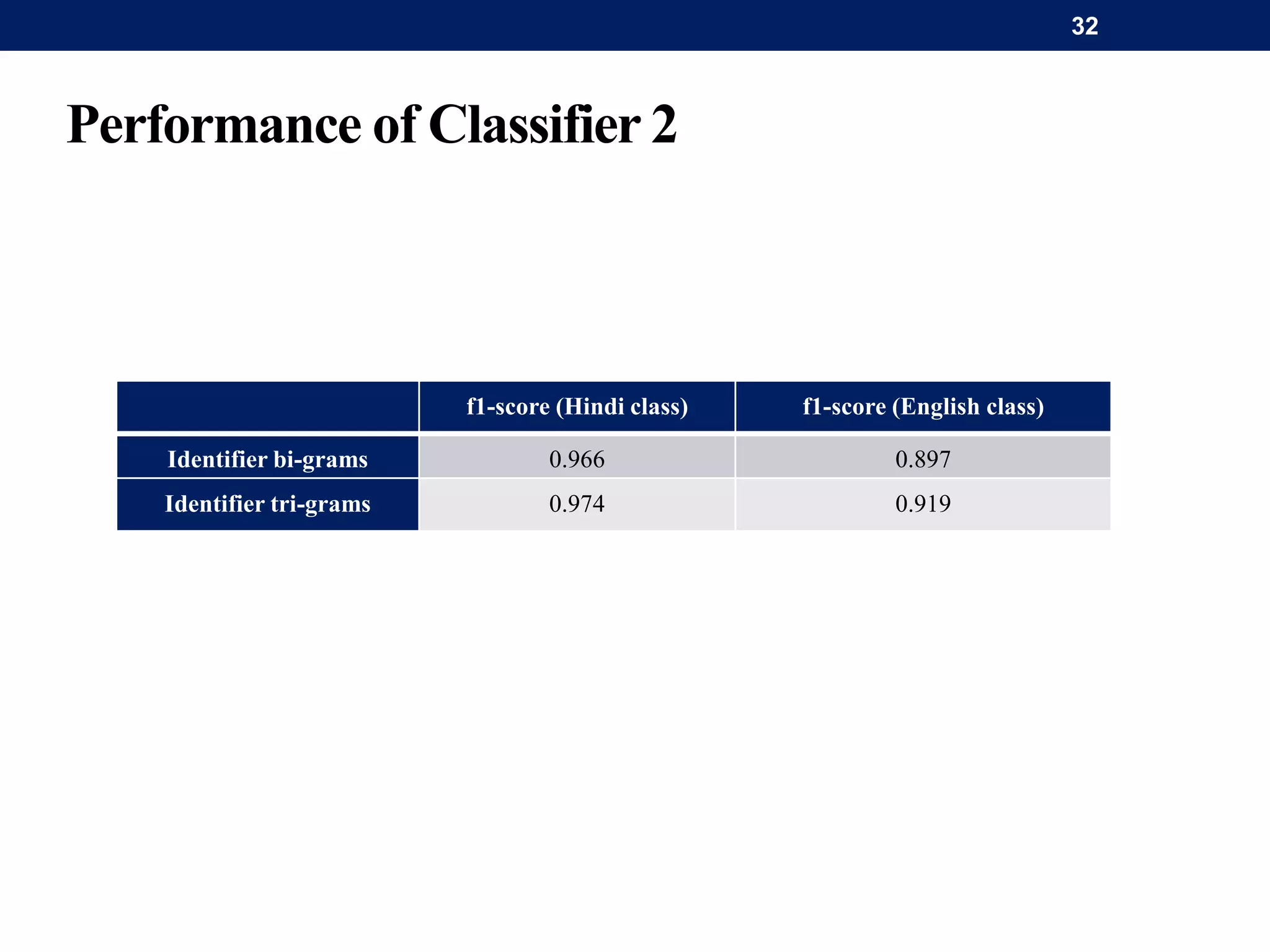

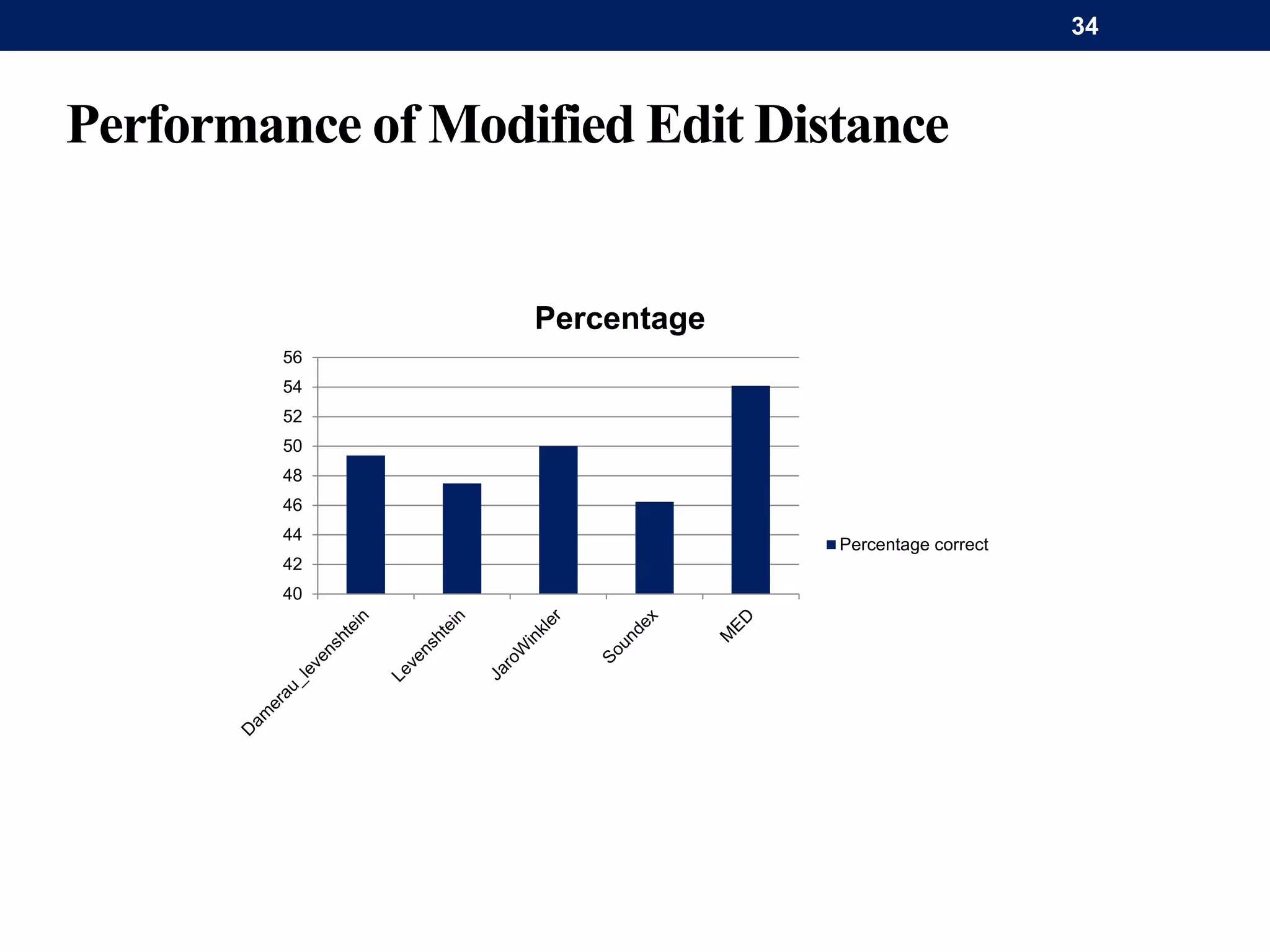
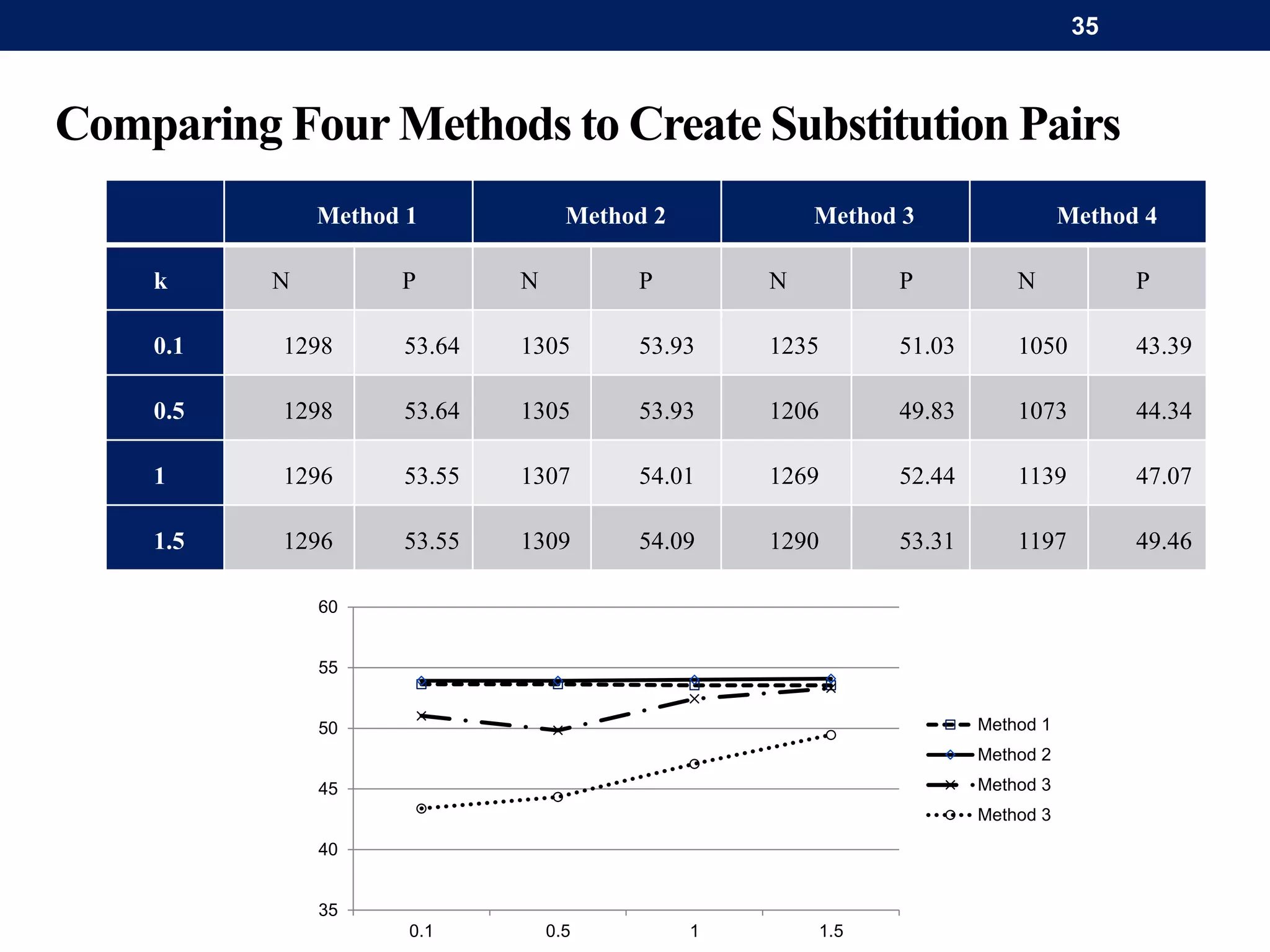


The document discusses a system for word-level language identification in bilingual code-switched texts, focusing on languages such as Hindi and English. It outlines the challenges of modeling such language due to inconsistent spelling and ambiguous word usage, while proposing classifiers that leverage n-grams, modified edit distance, and parts-of-speech tagging to improve accuracy. The study concludes that efficient techniques for identifying languages and authentic scripts are necessary for sentiment analysis and machine translation, with plans for future extensions to handle more complex language situations.

































































