Download as PDF, PPTX














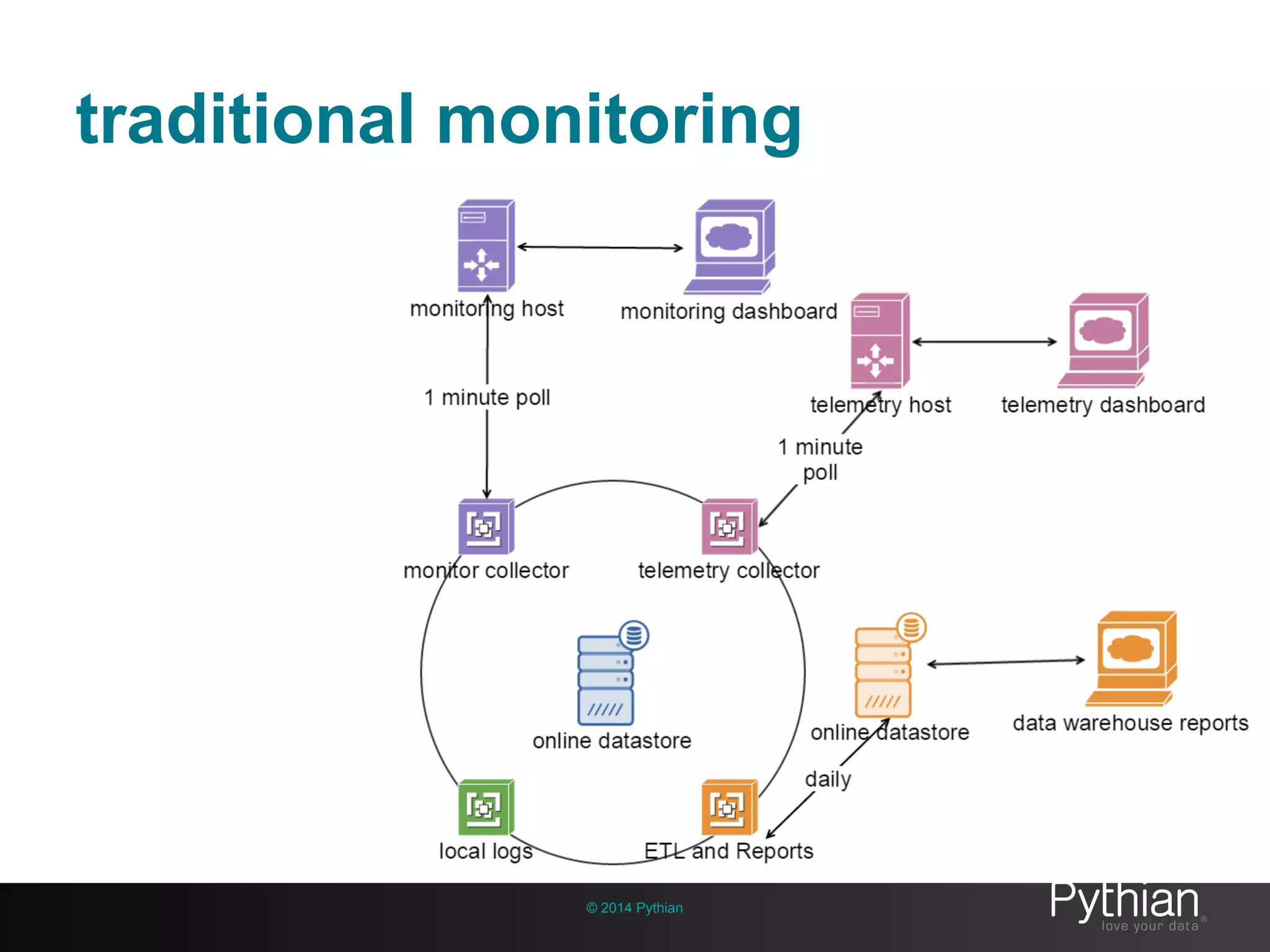
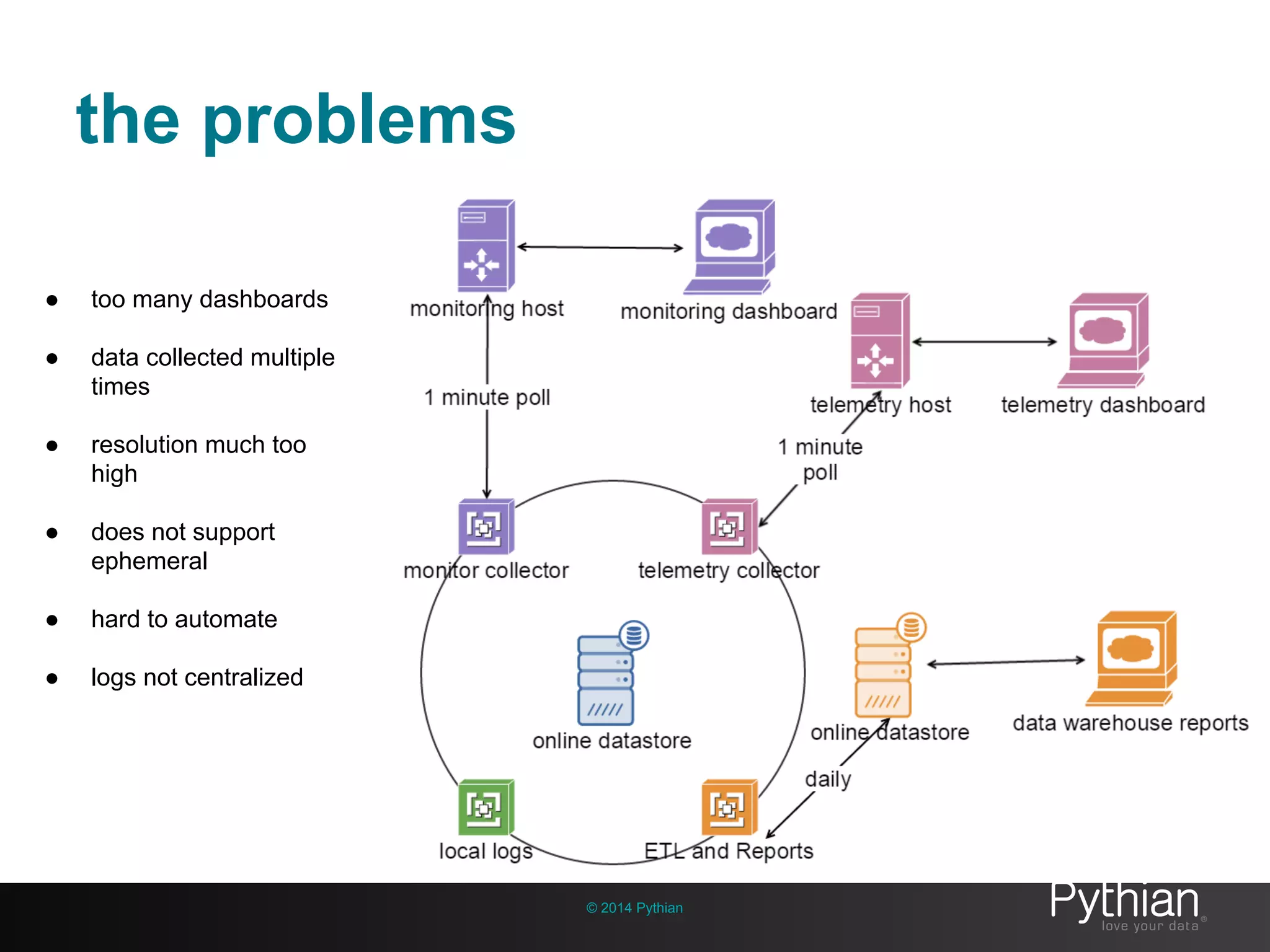
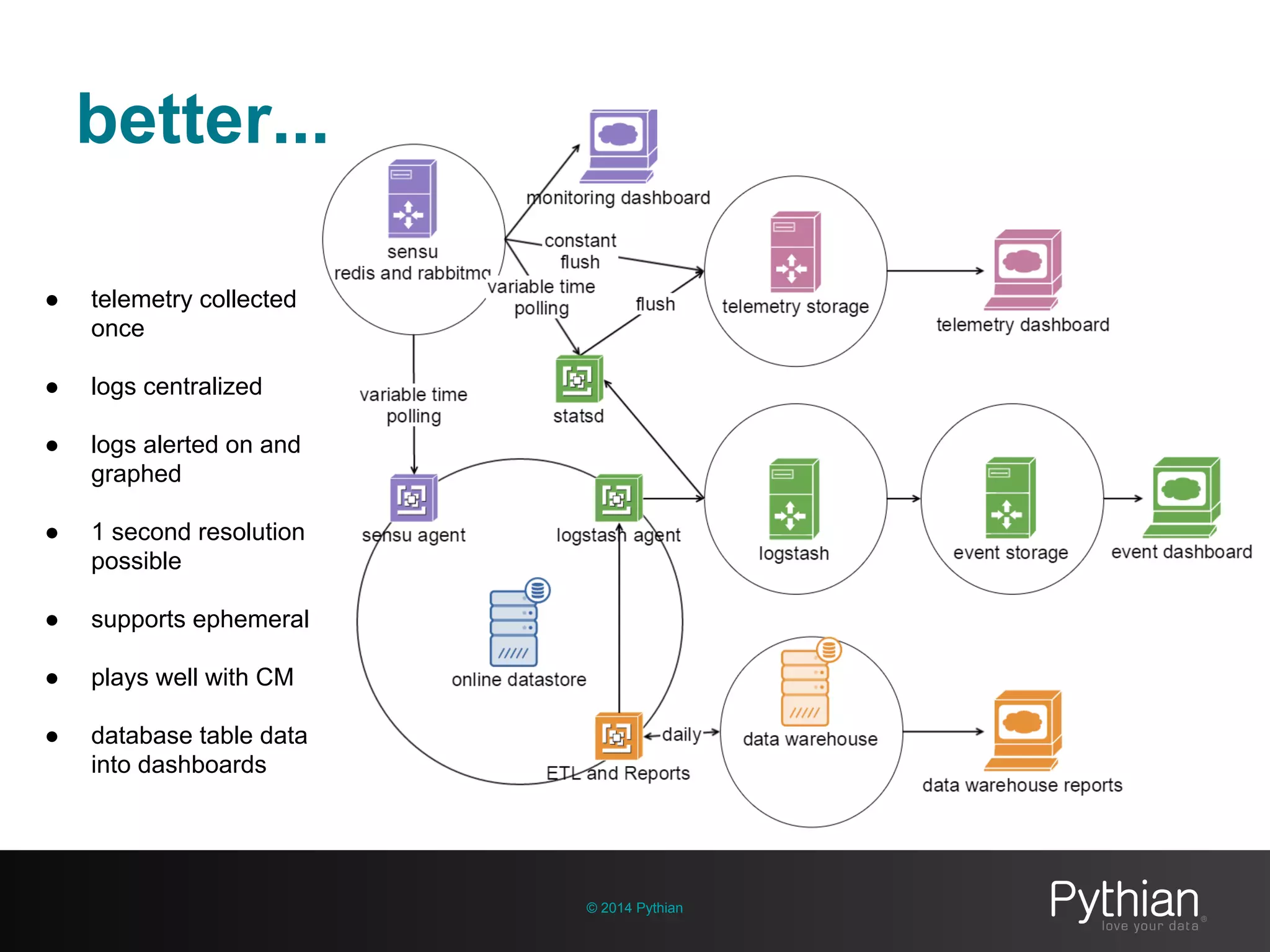





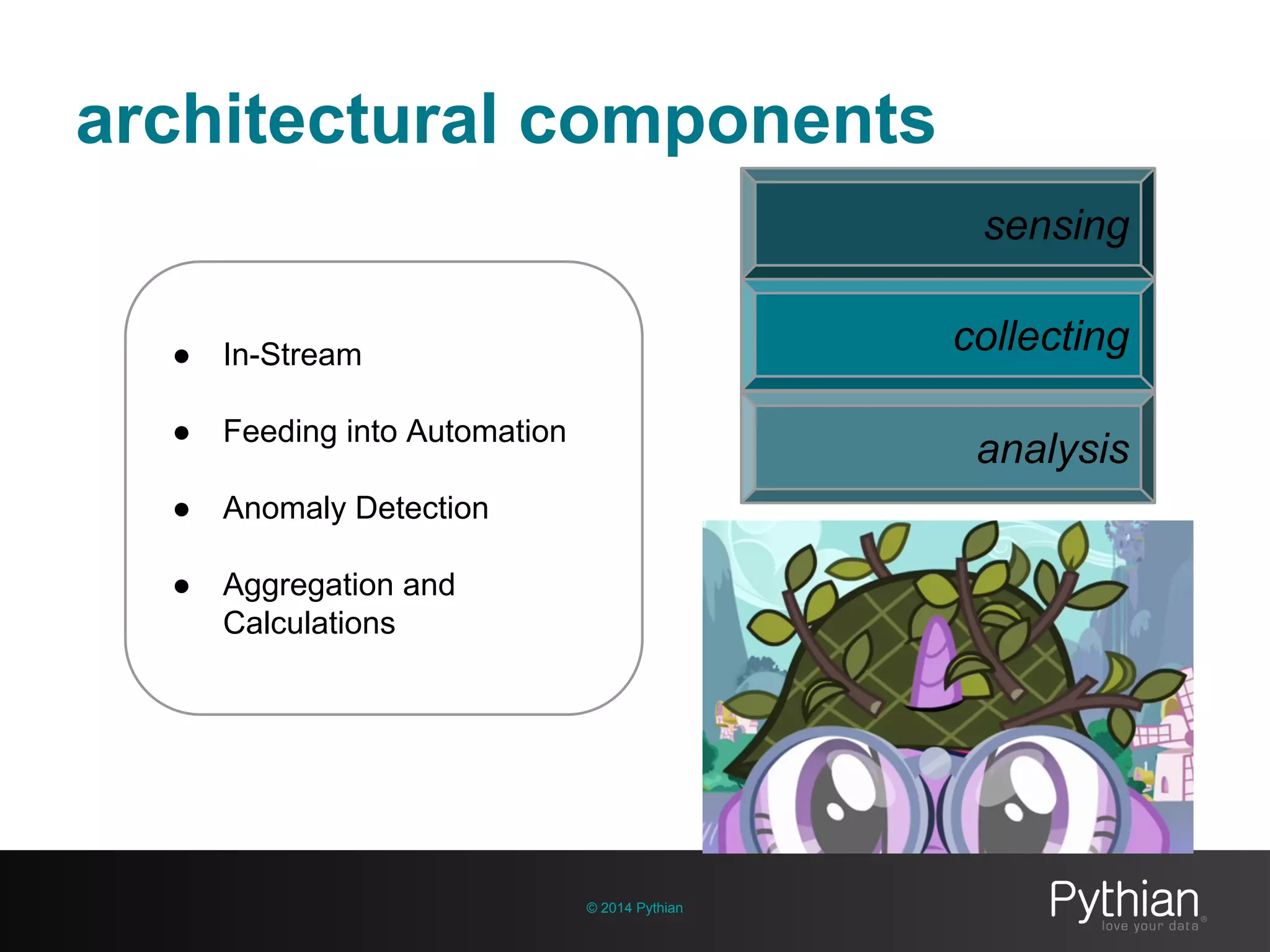
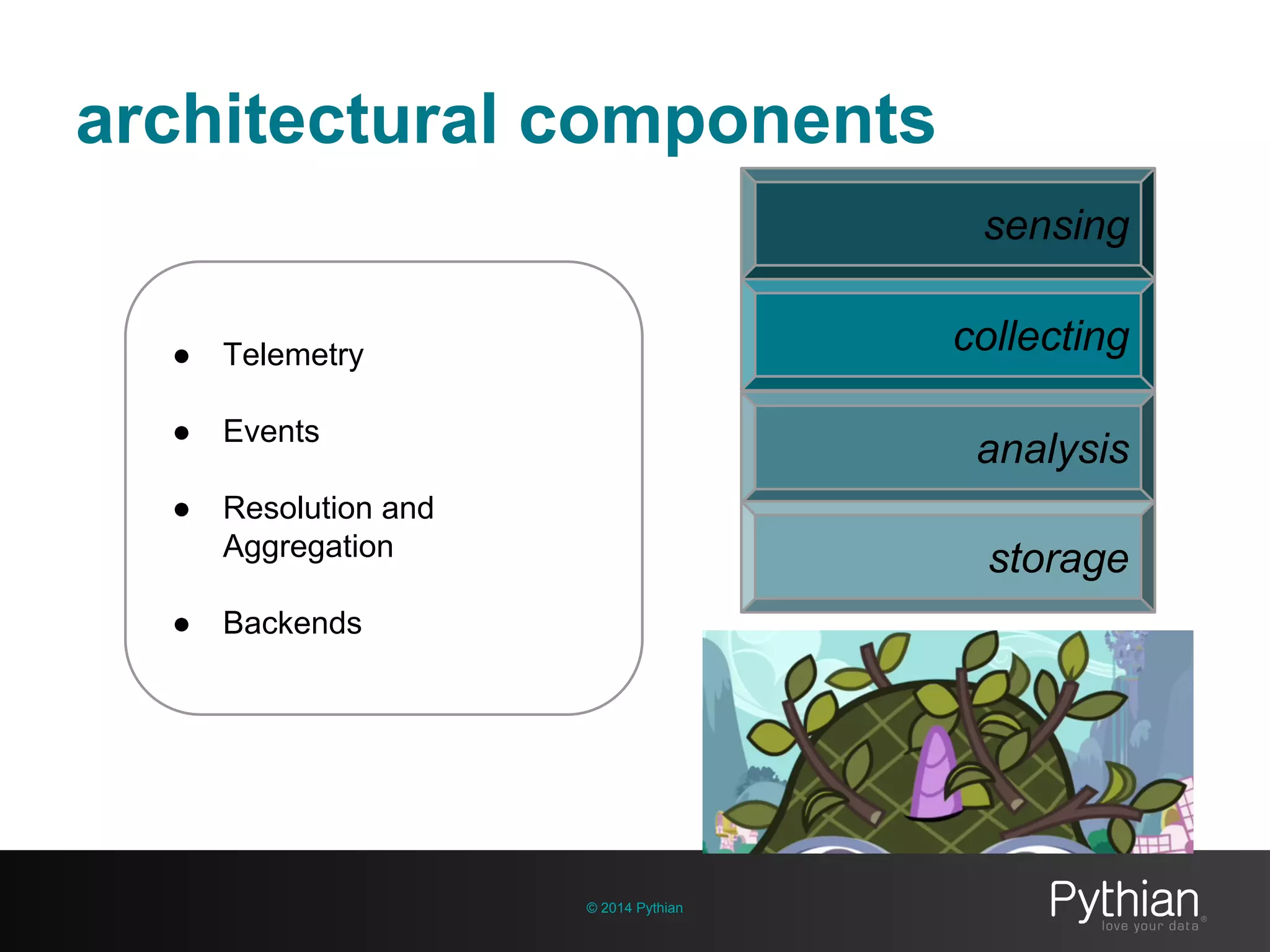

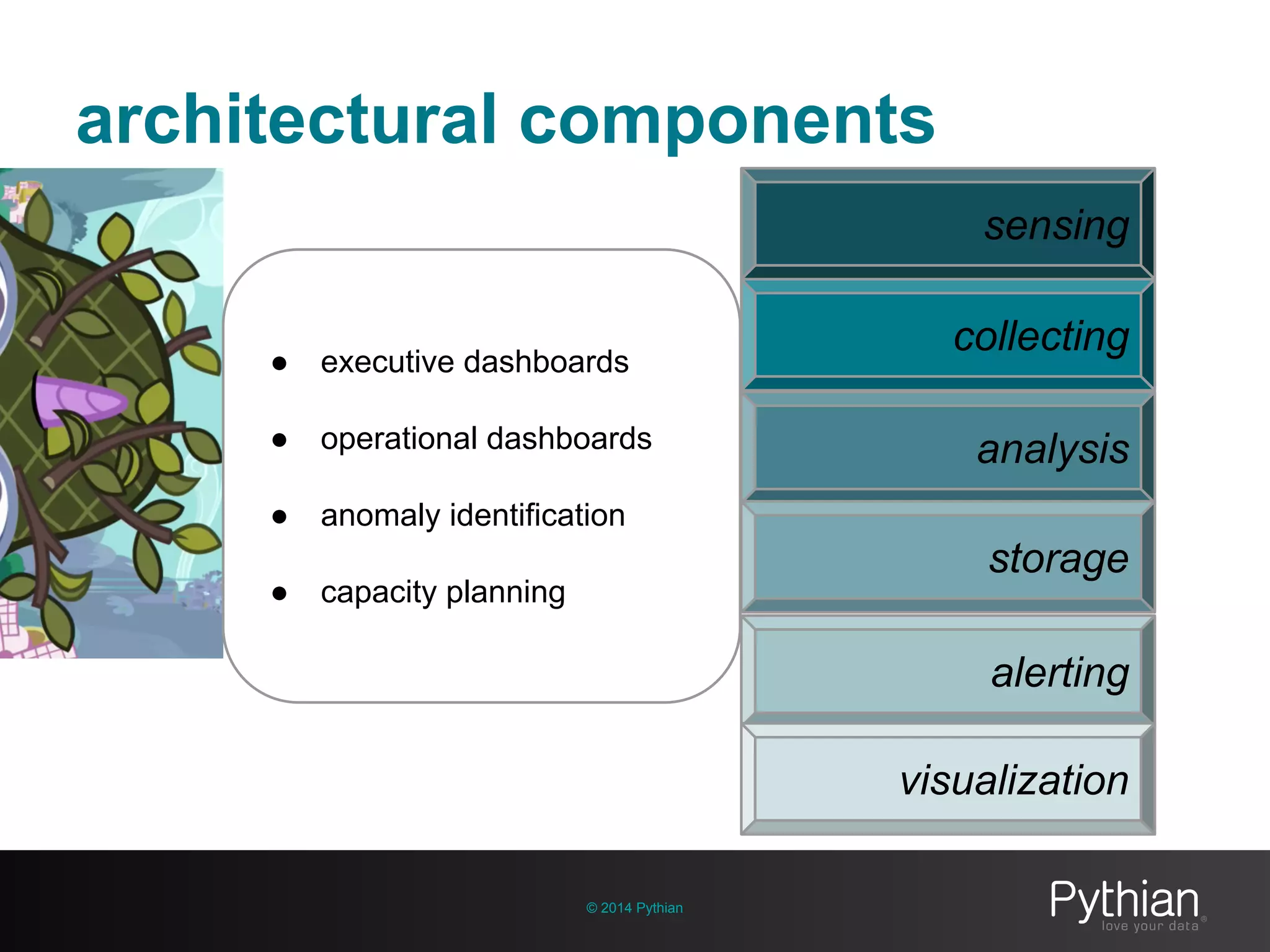






















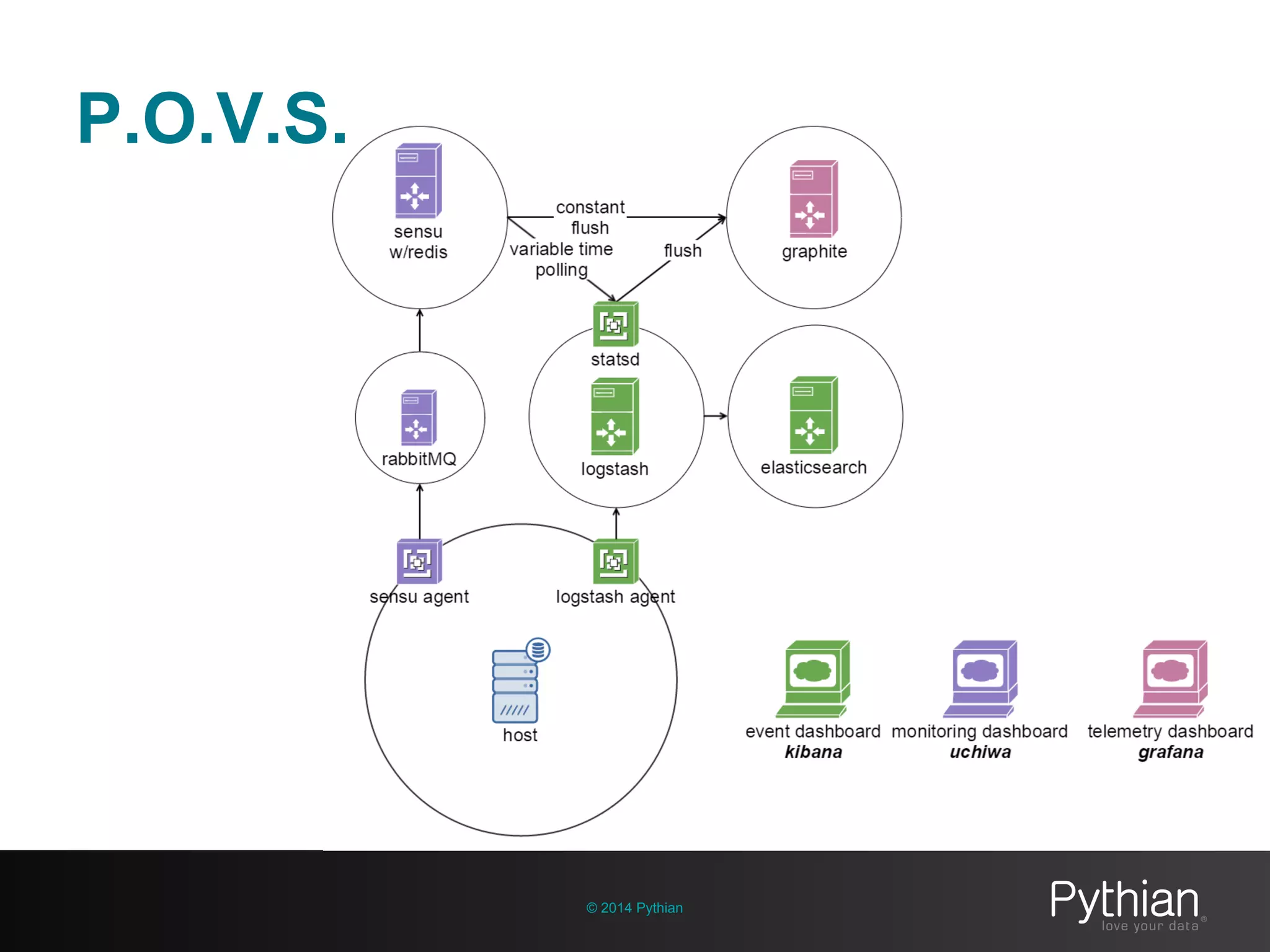




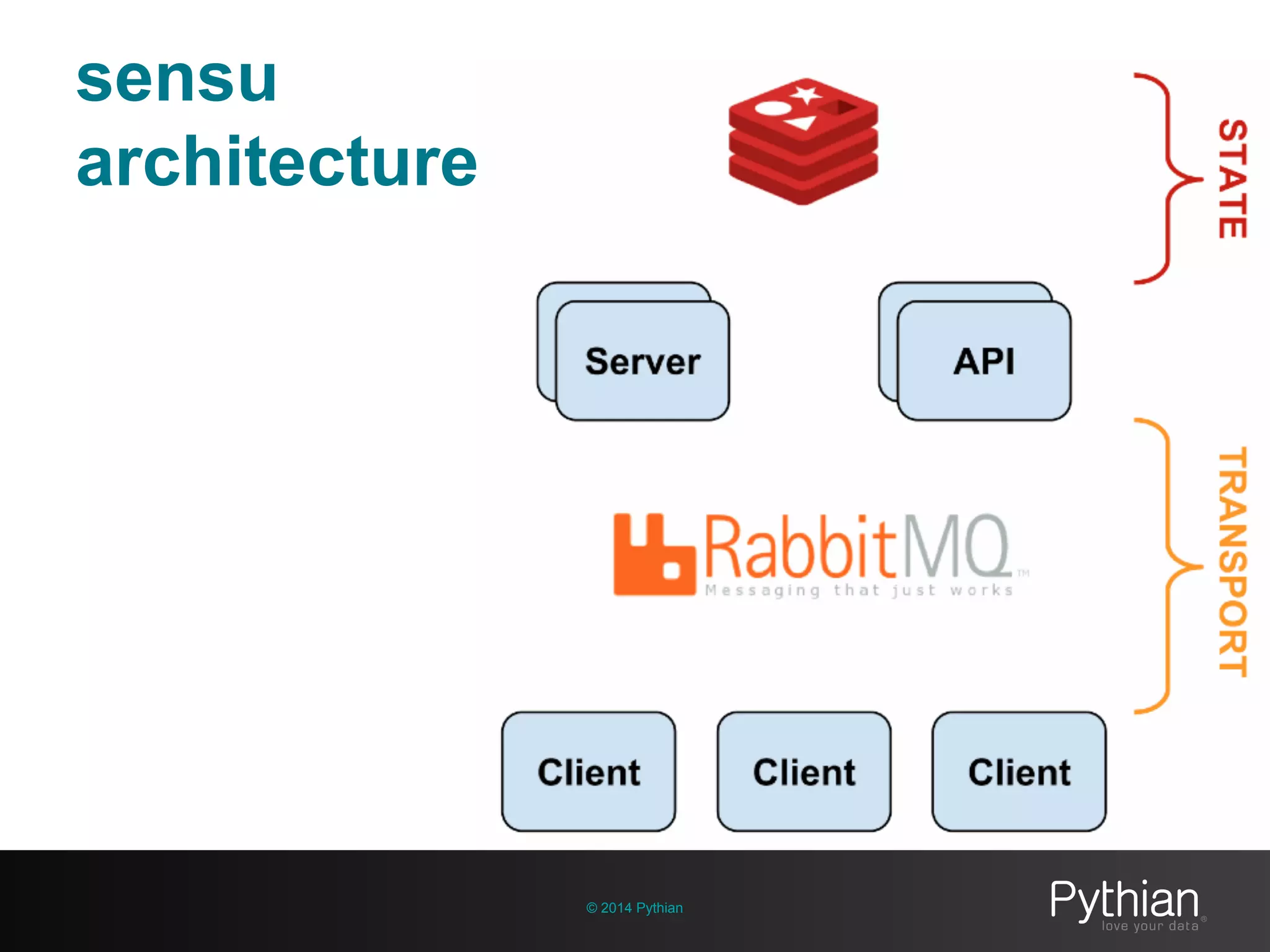







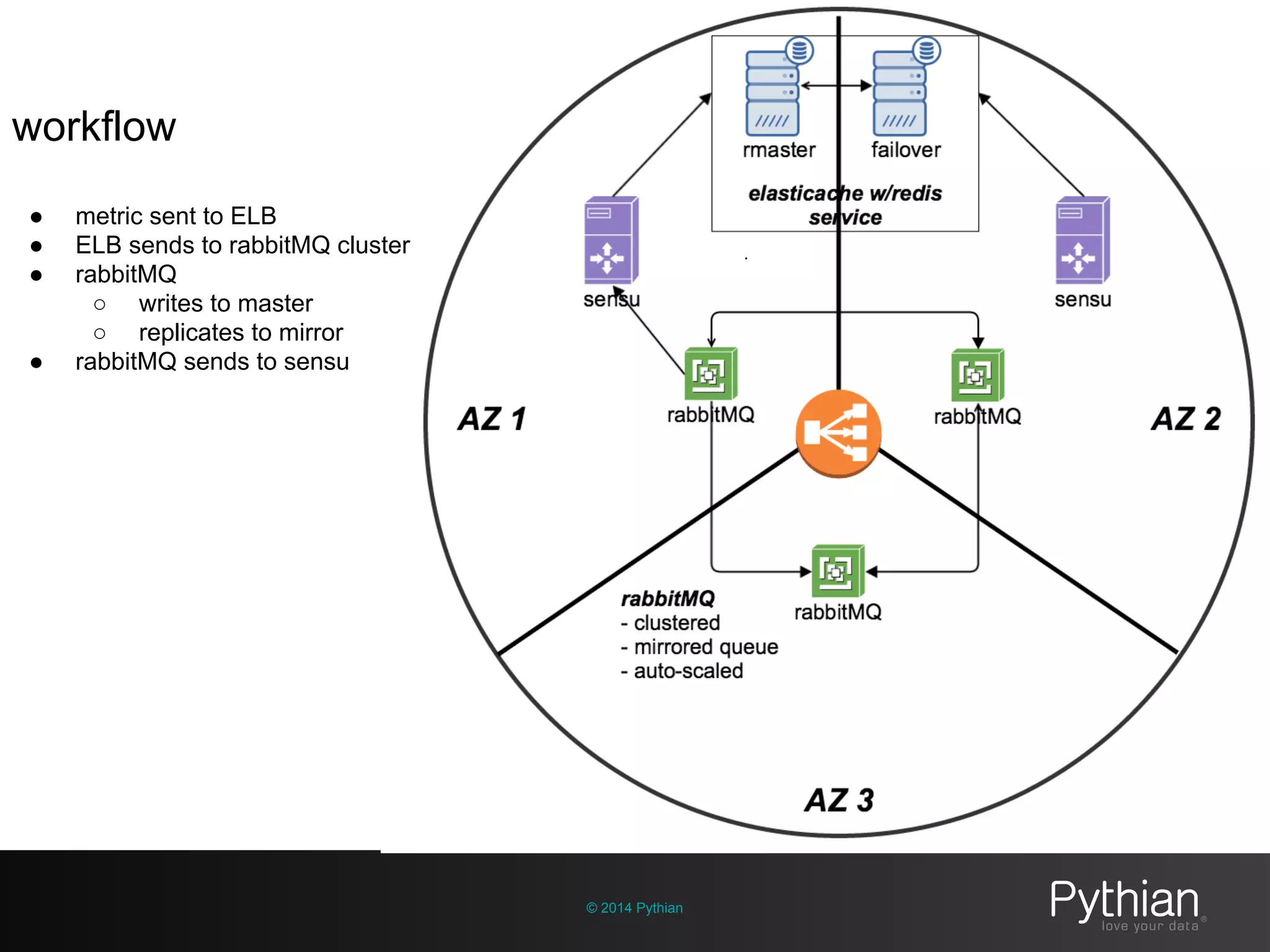

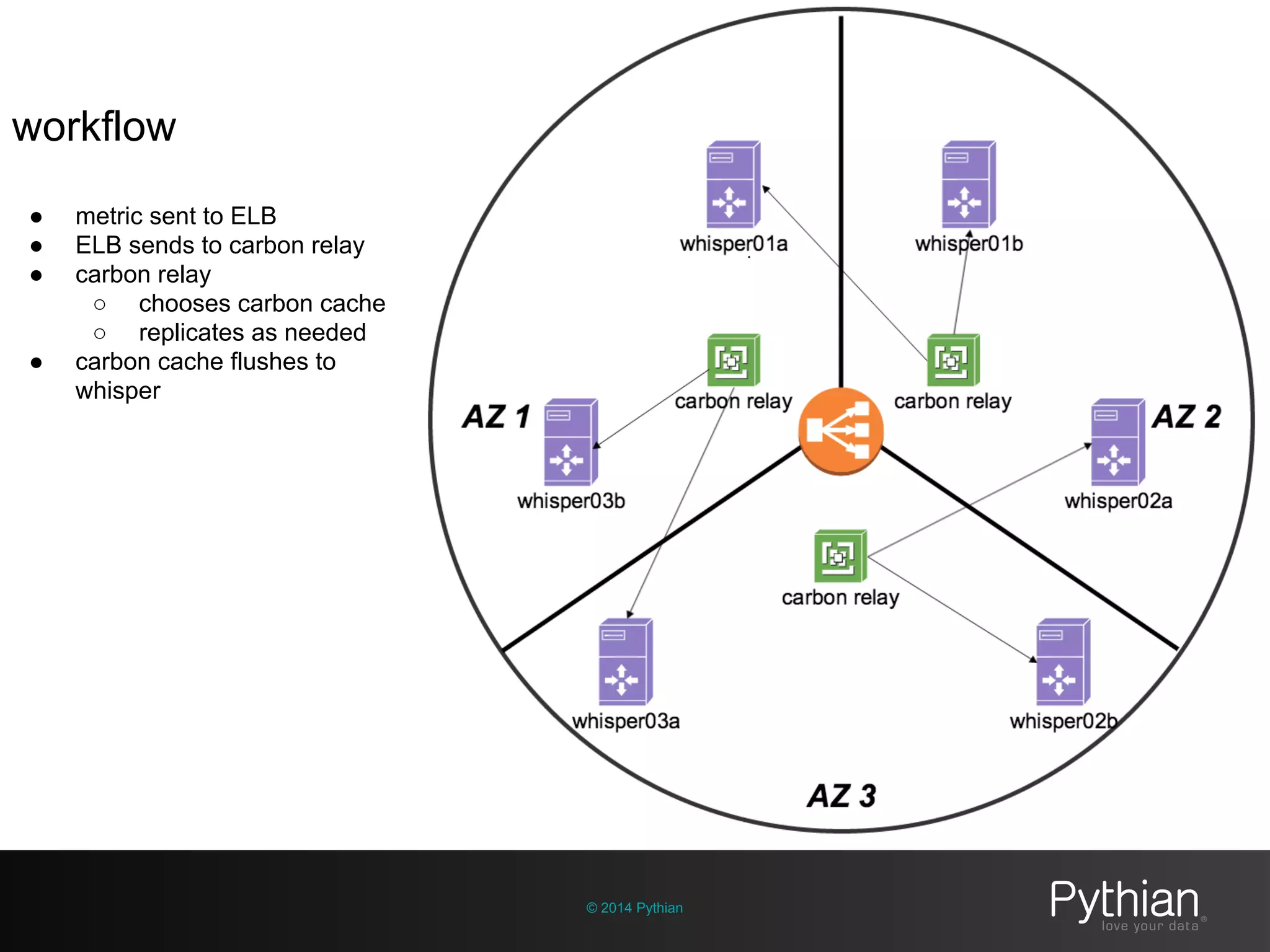

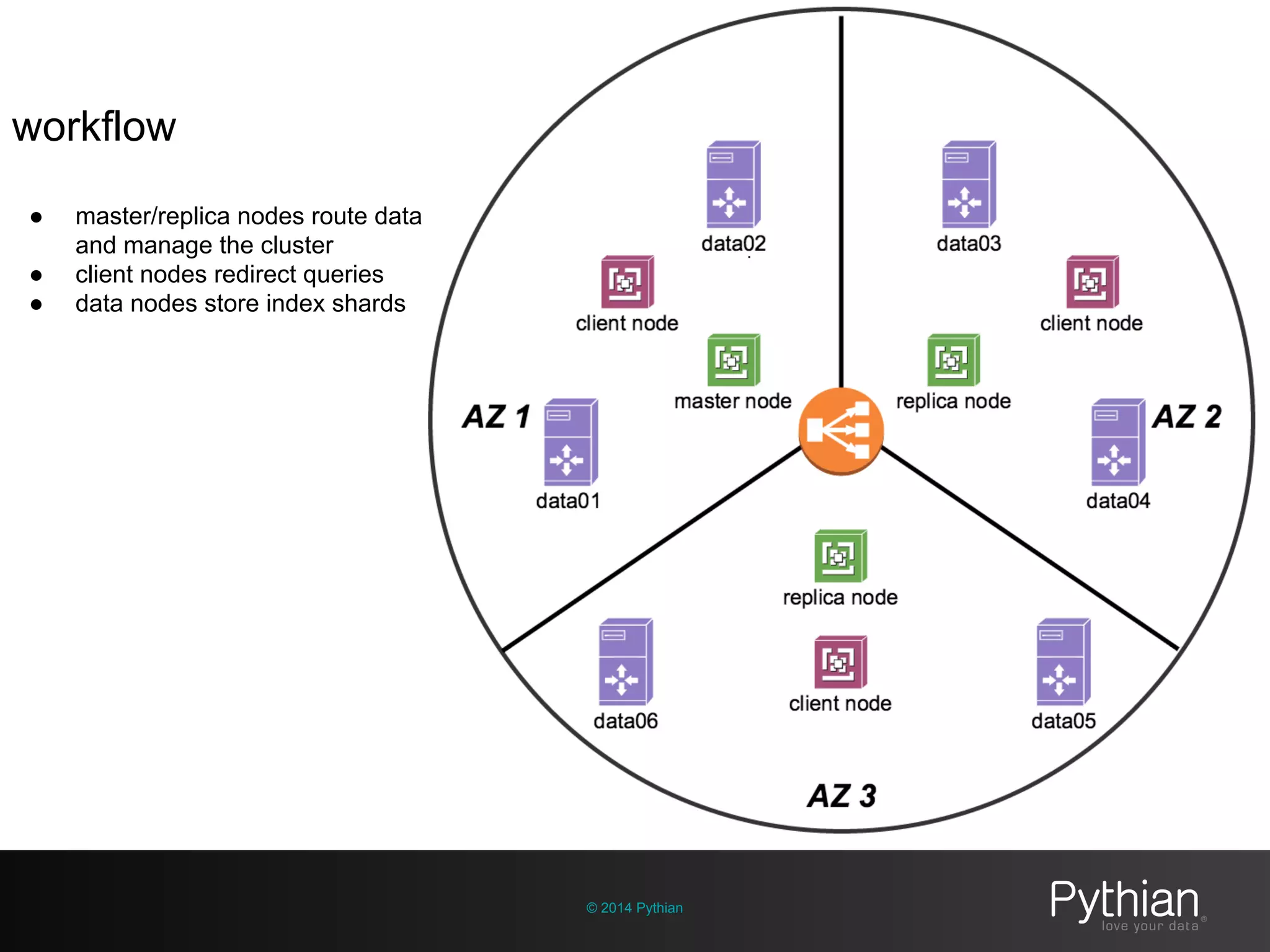




The document discusses operational visibility and observability principles crucial for modern IT environments, emphasizing the need for continuous improvement and stakeholder engagement. It outlines Pythian's approach to infrastructure management, detailing metrics for business velocity, availability, efficiency, and scalability while identifying current limitations in traditional monitoring methods. The focus is on integrating telemetry data, improving data storage, and employing machine learning for predictive analysis and anomaly detection.



































































![[BDD 2025 - Full-Stack Development] PHP in AI Age: The Laravel Way. (Rizqy Hi...](https://cdn.slidesharecdn.com/ss_thumbnails/fs-phpinaiagethelaravelway-251125012602-ef9d330e-thumbnail.jpg?width=640&height=640&fit=bounds)



![Support, Monitoring, Continuous Improvement & Scaling Agentic Automation [3/3]](https://cdn.slidesharecdn.com/ss_thumbnails/agenticcommunityseries-day3-cfd-251120170304-ddef8112-thumbnail.jpg?width=640&height=640&fit=bounds)

![[BDD 2025 - Full-Stack Development] The Modern Stack: Building Web & AI Appli...](https://cdn.slidesharecdn.com/ss_thumbnails/fs-themodernstackbuildingwebaiapplicationswithserverless-251124030844-388cf04f-thumbnail.jpg?width=640&height=640&fit=bounds)


