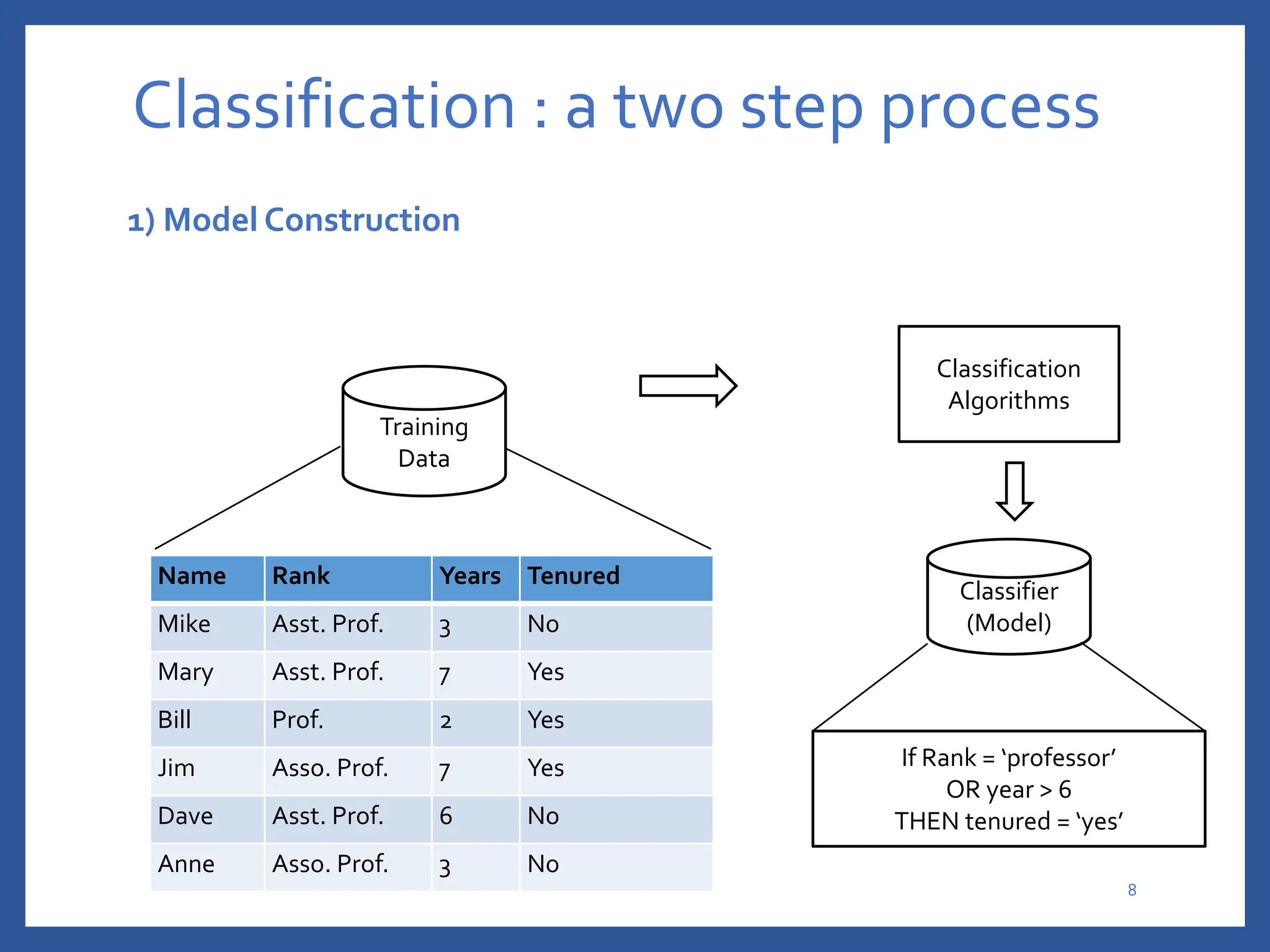
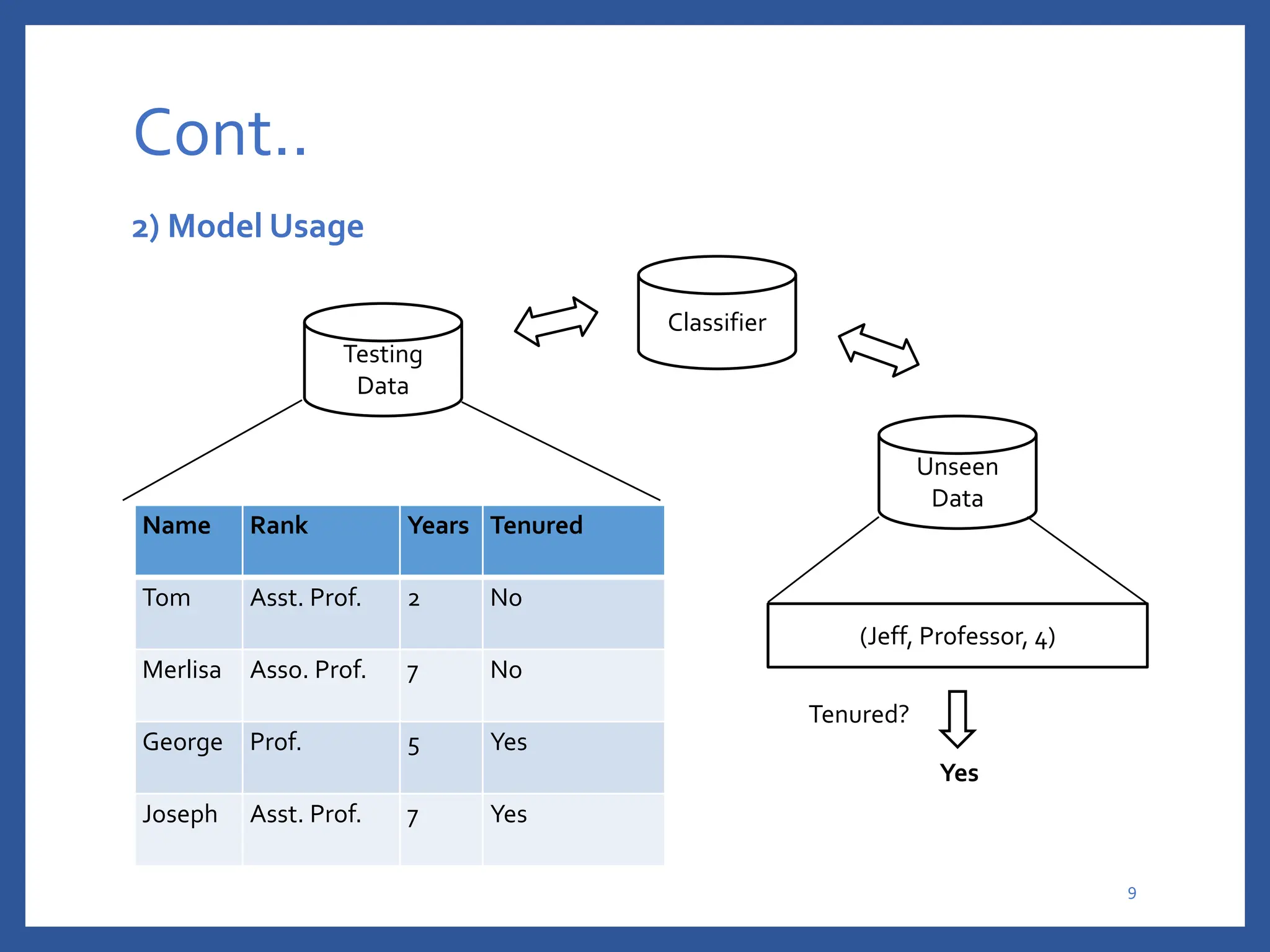
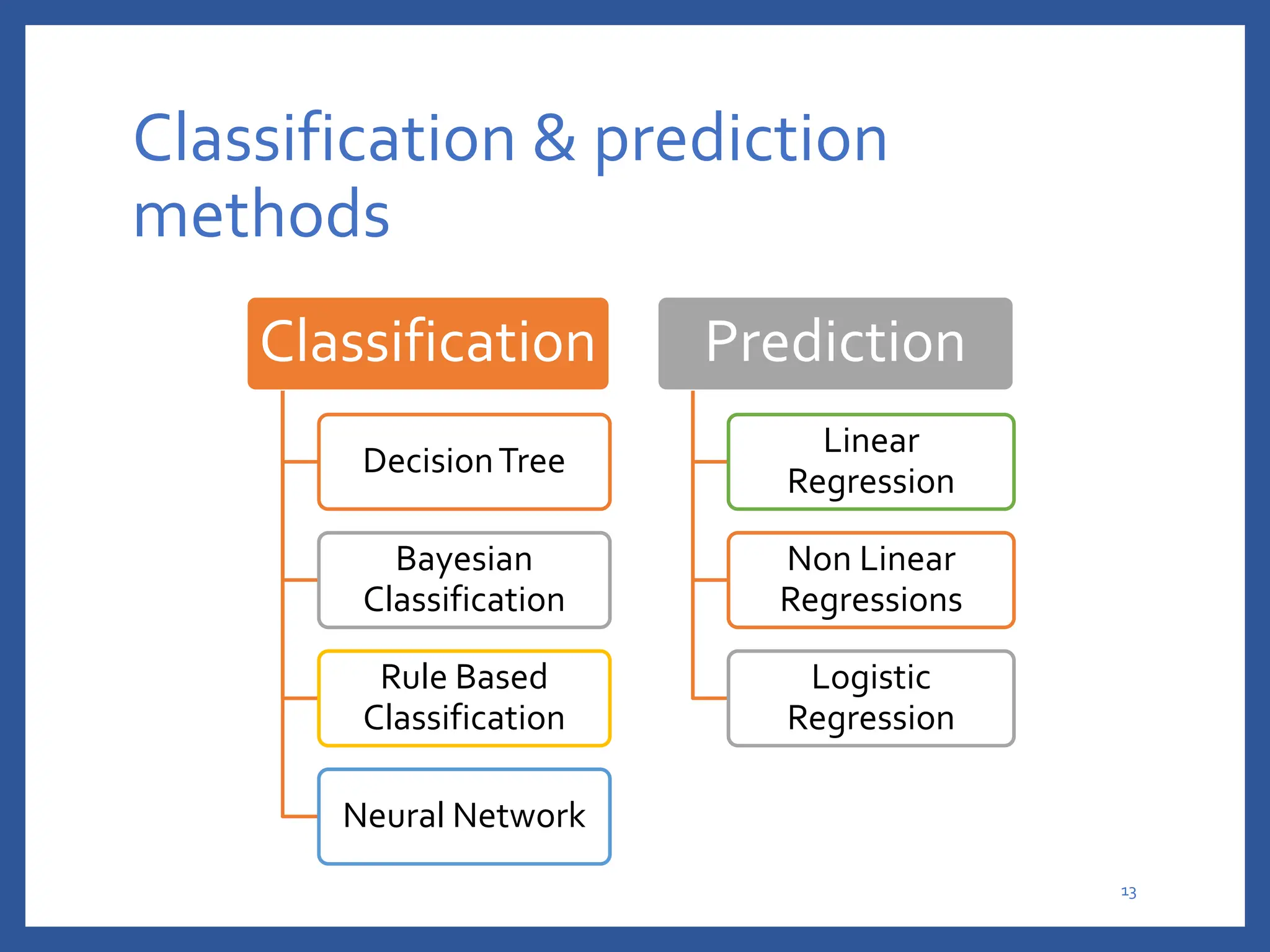
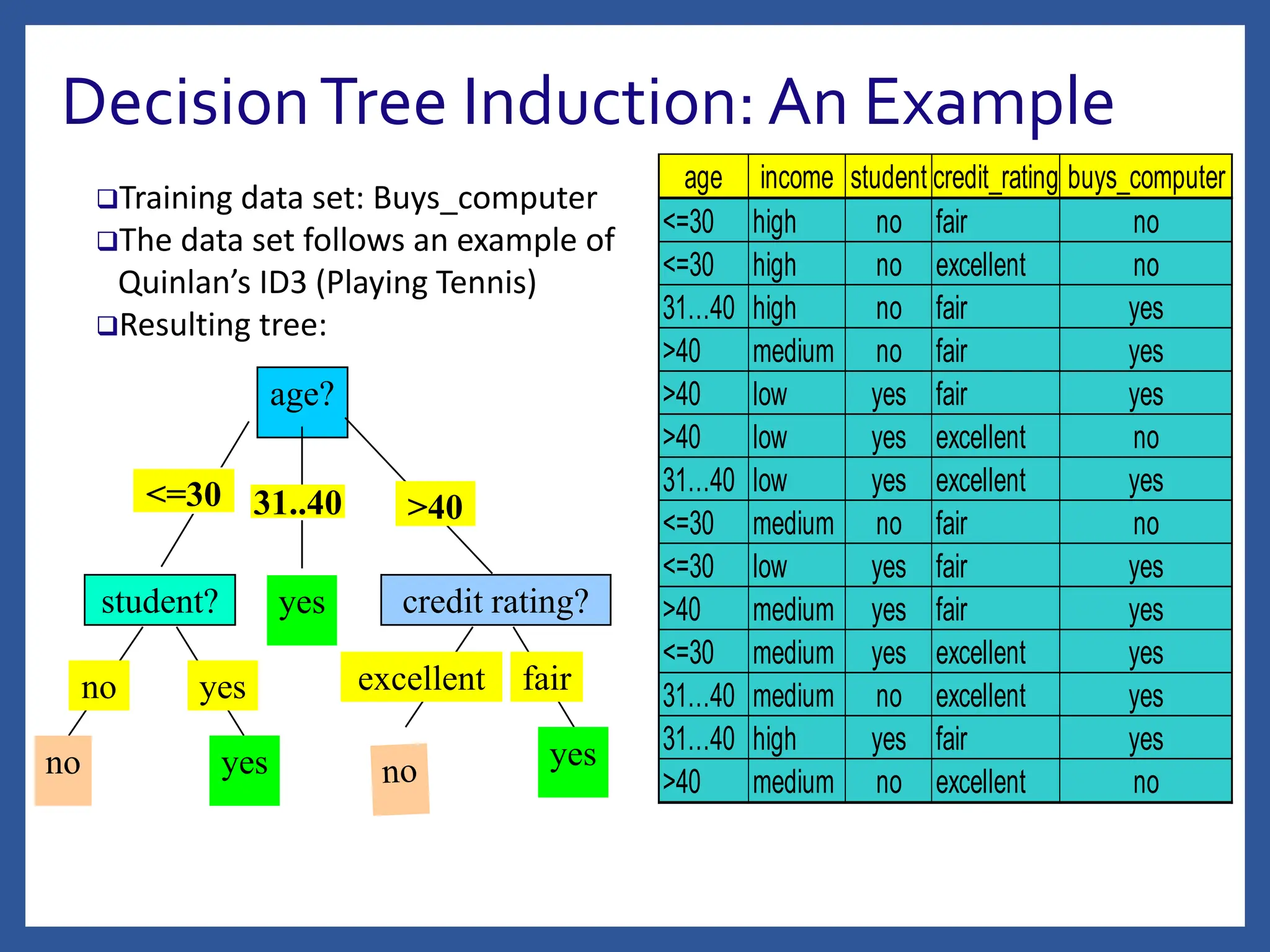
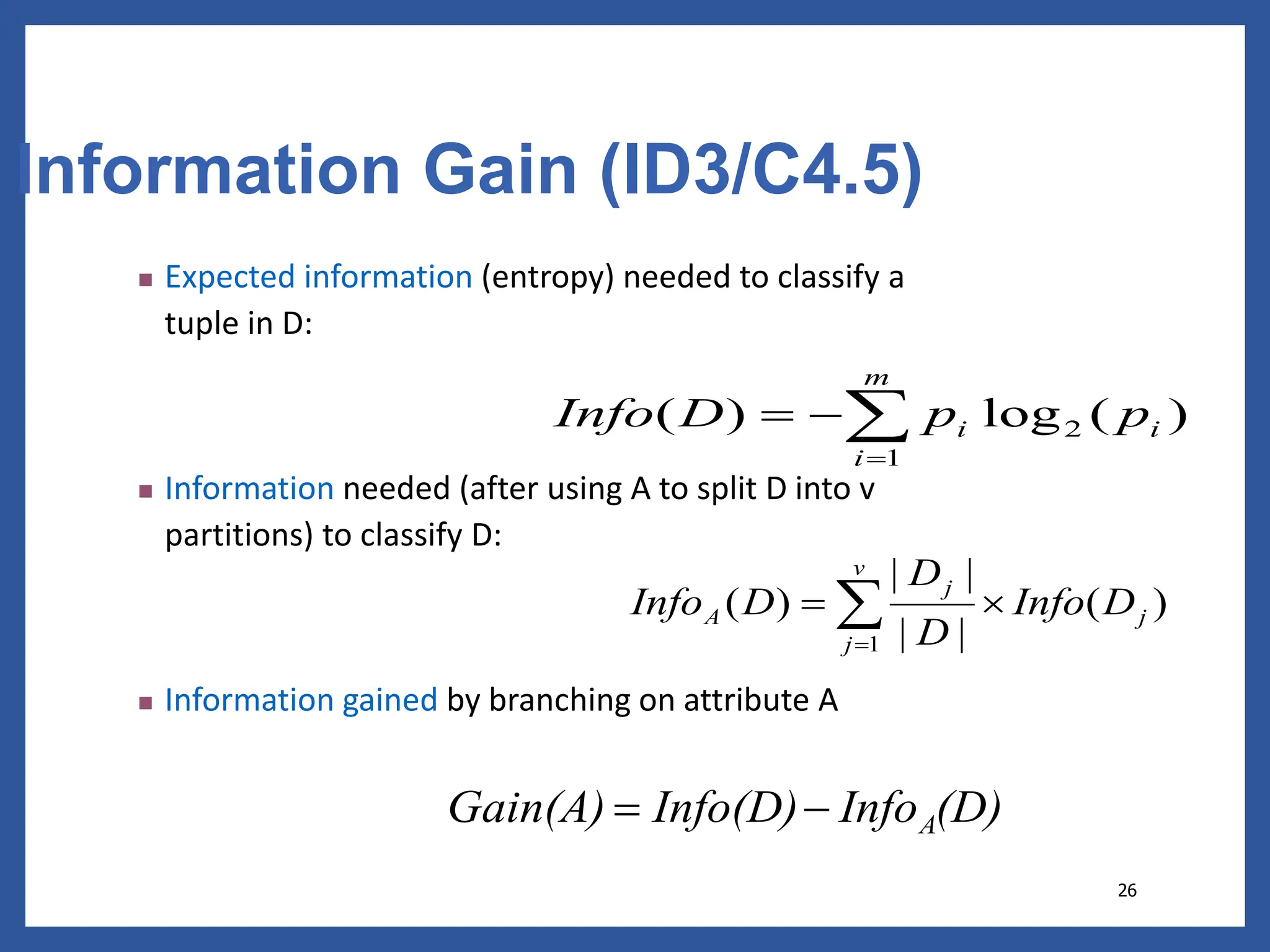
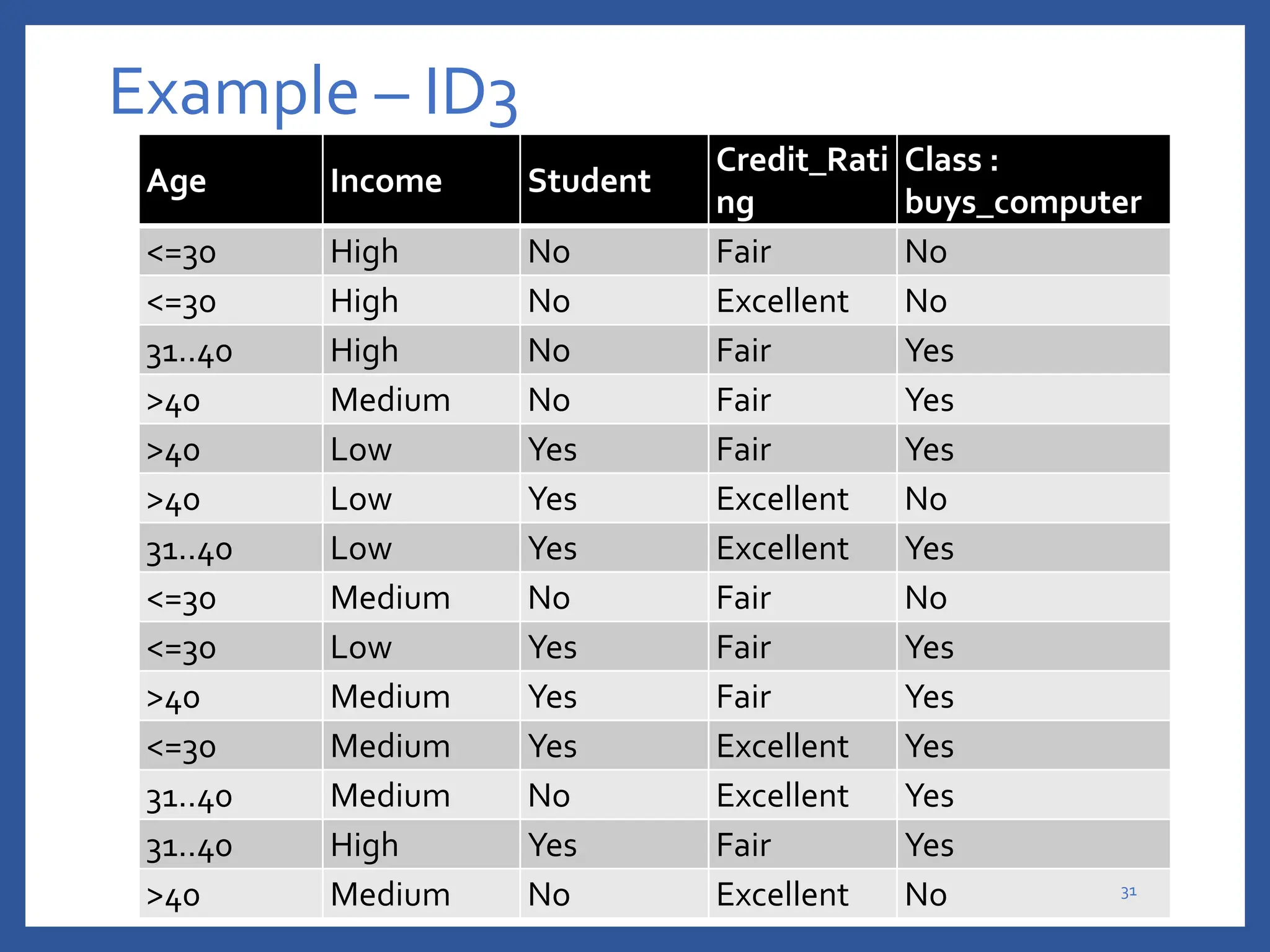
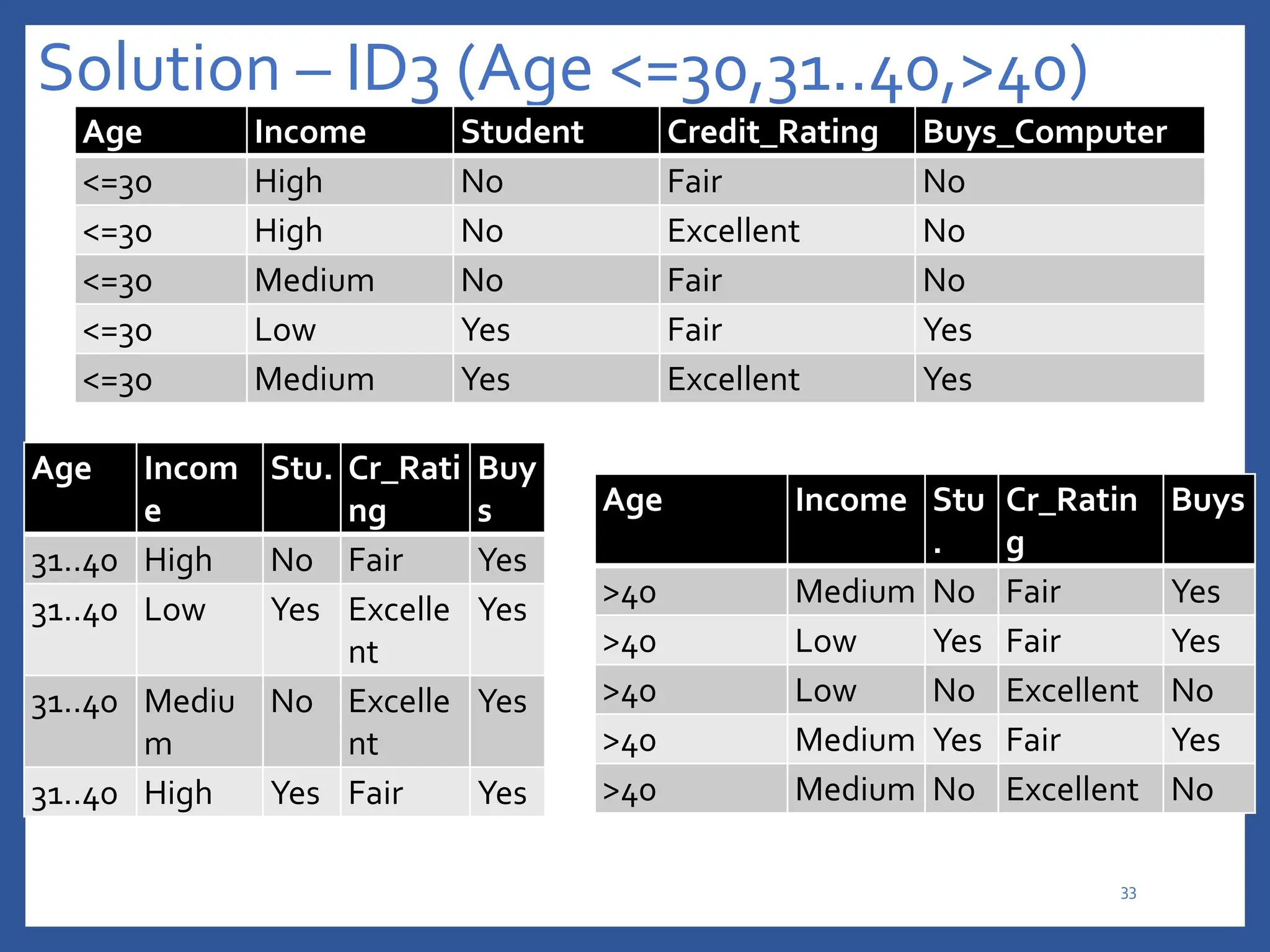
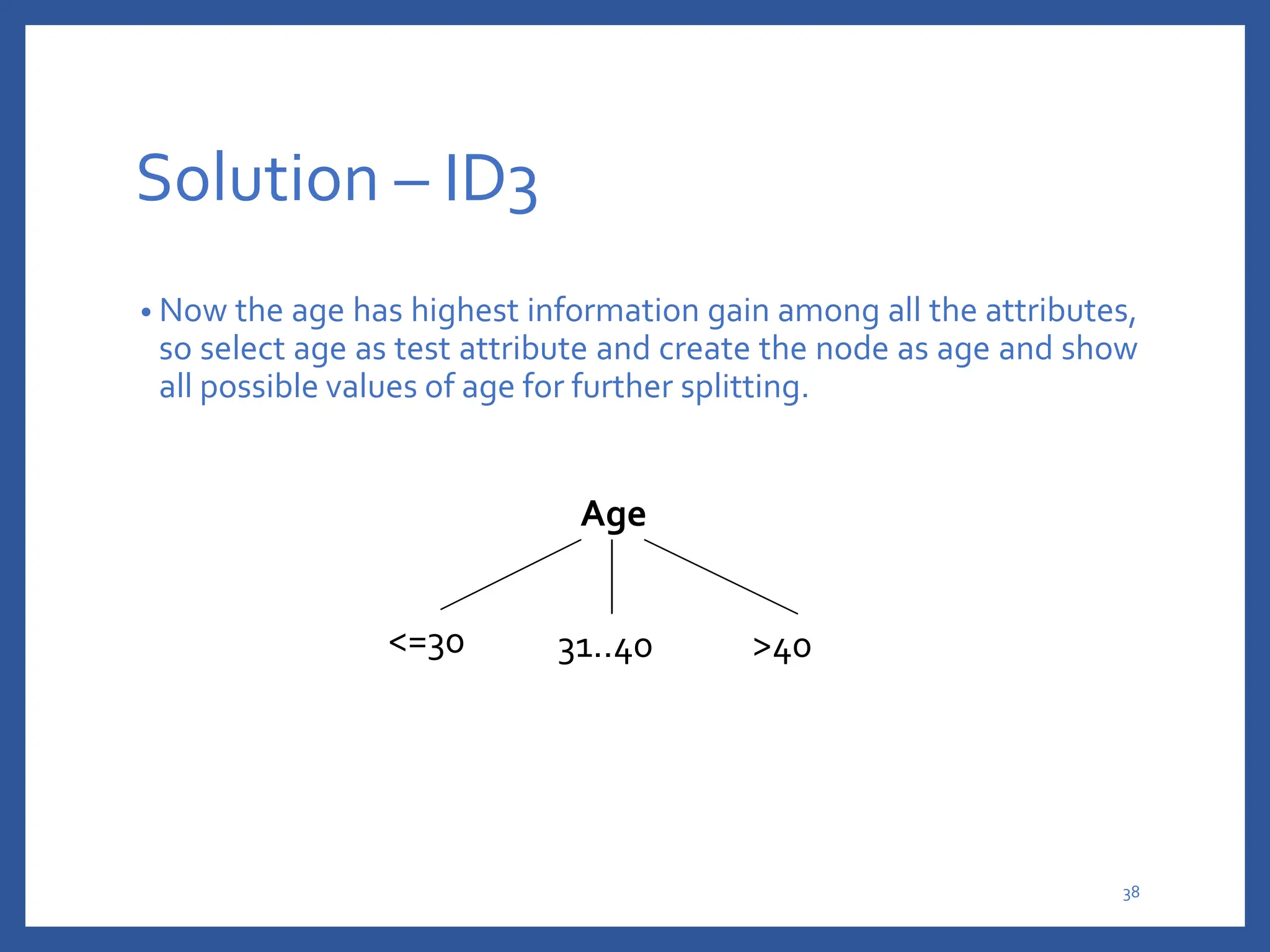
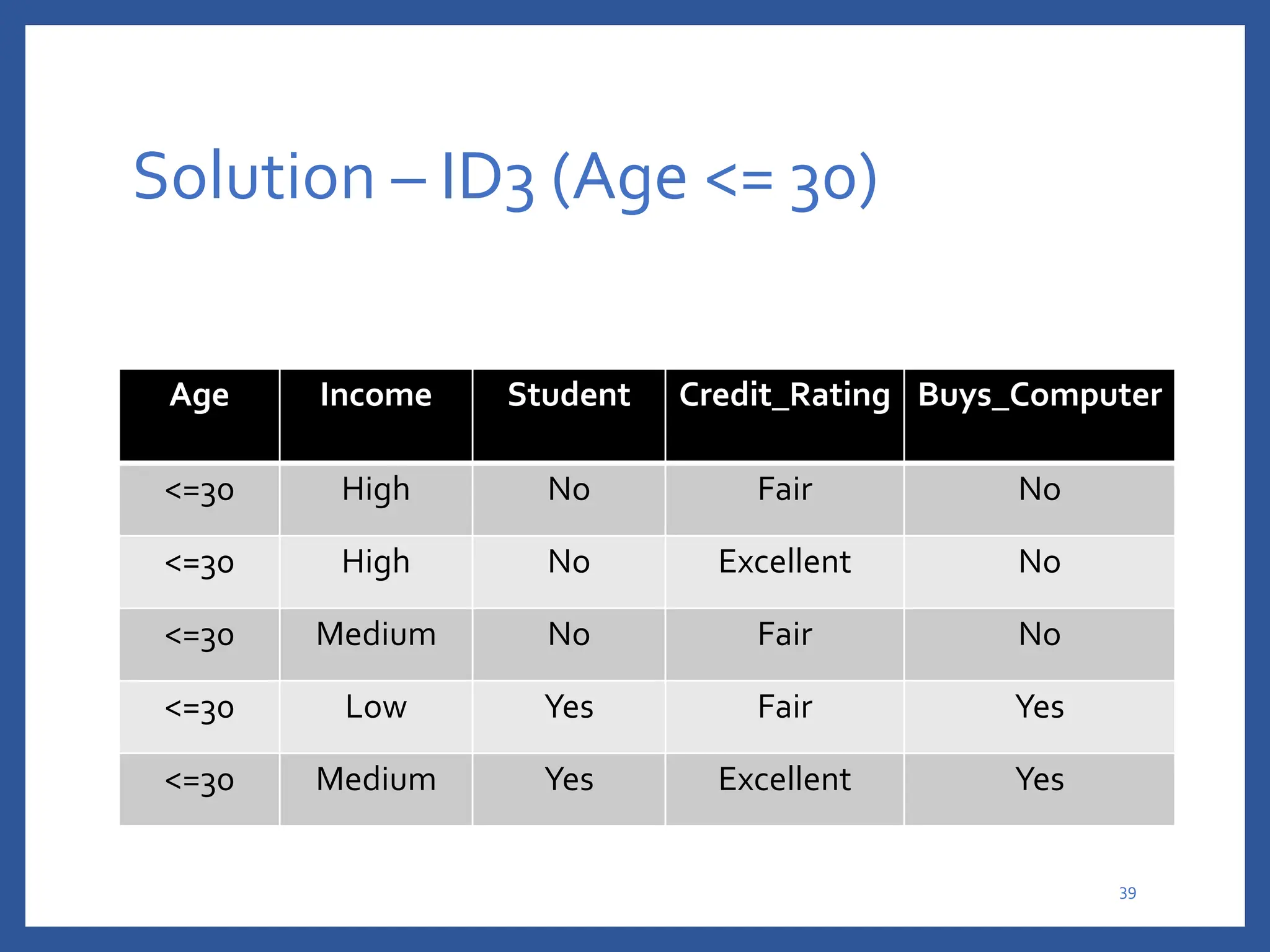
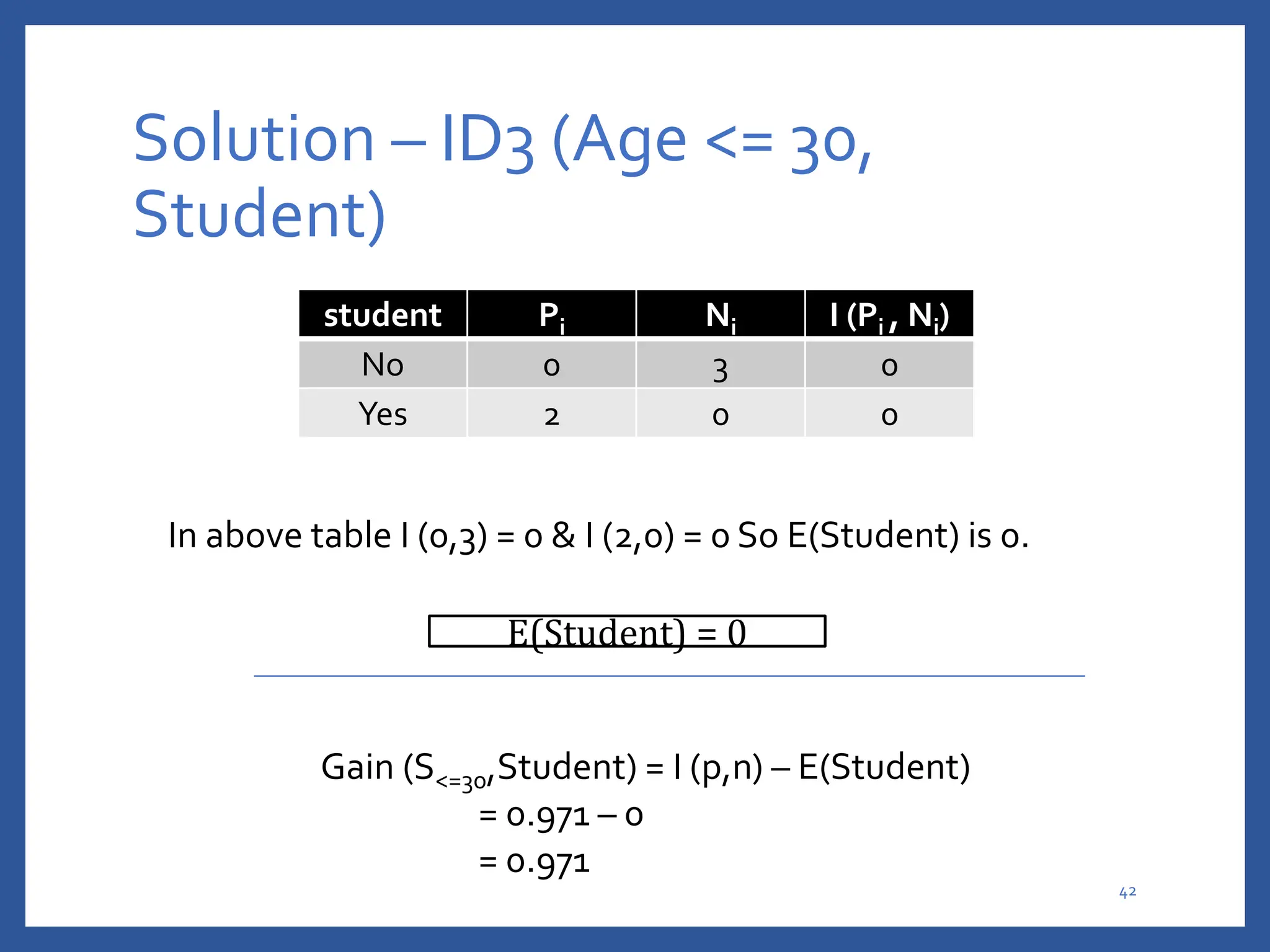
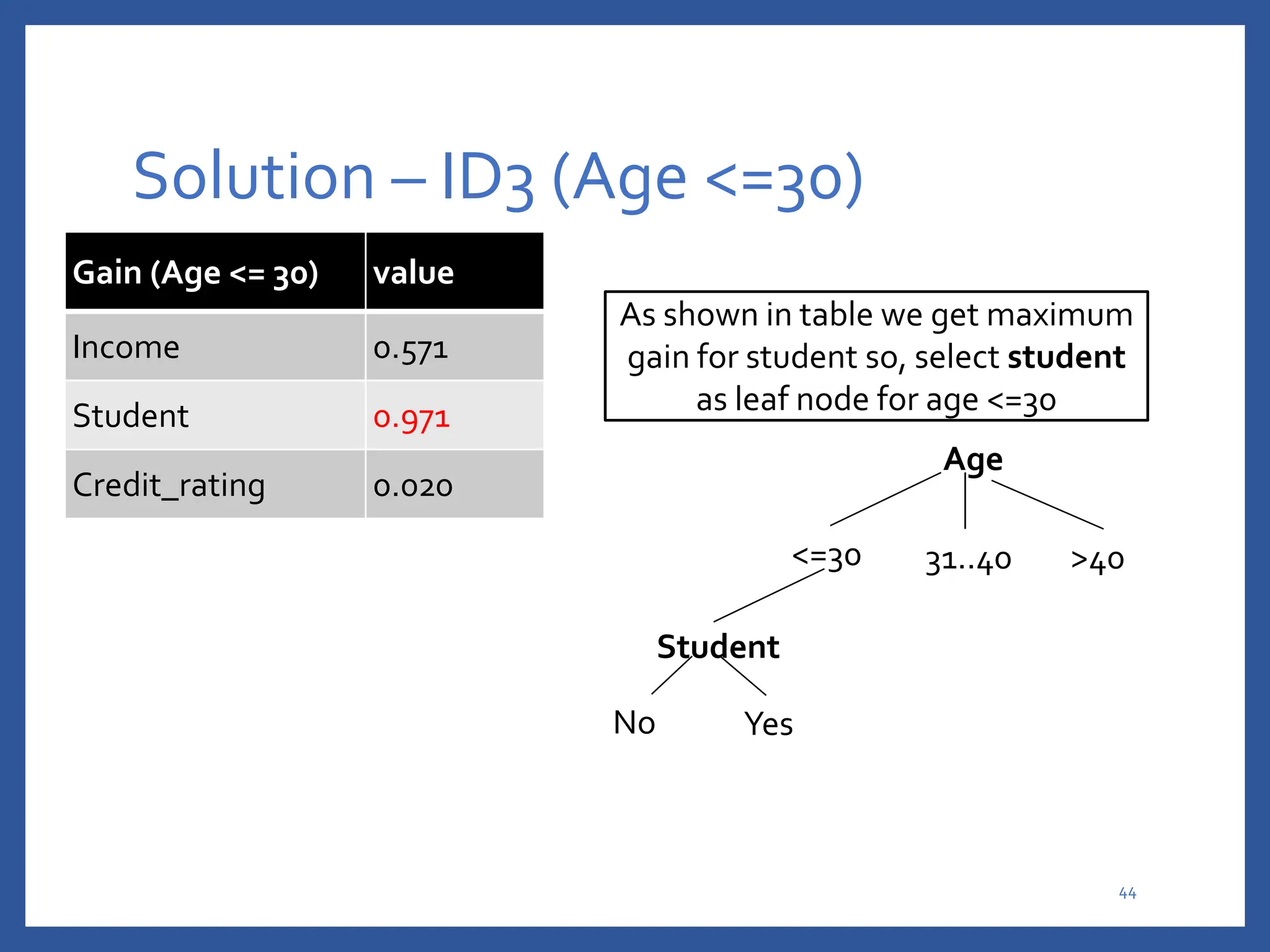
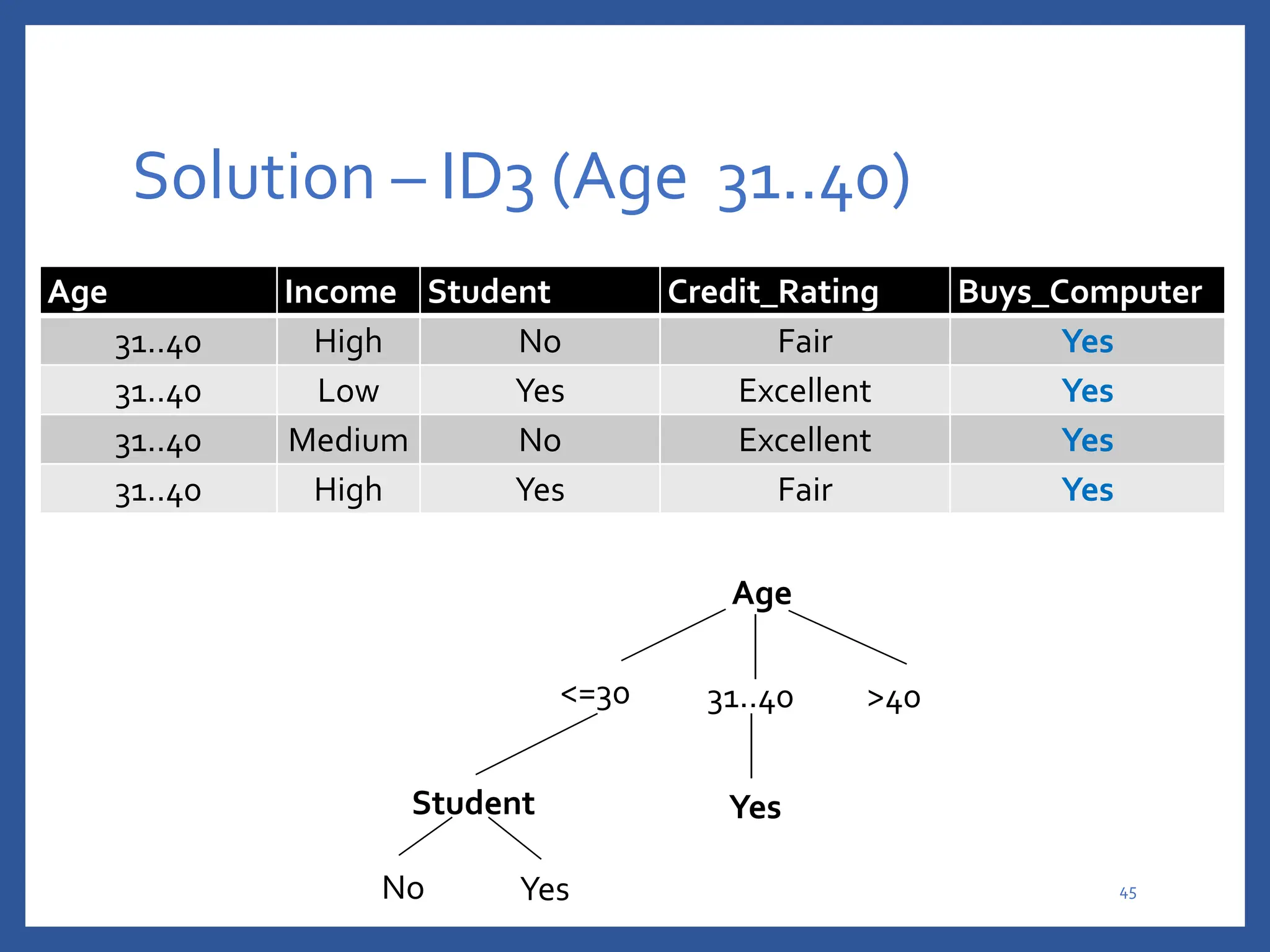
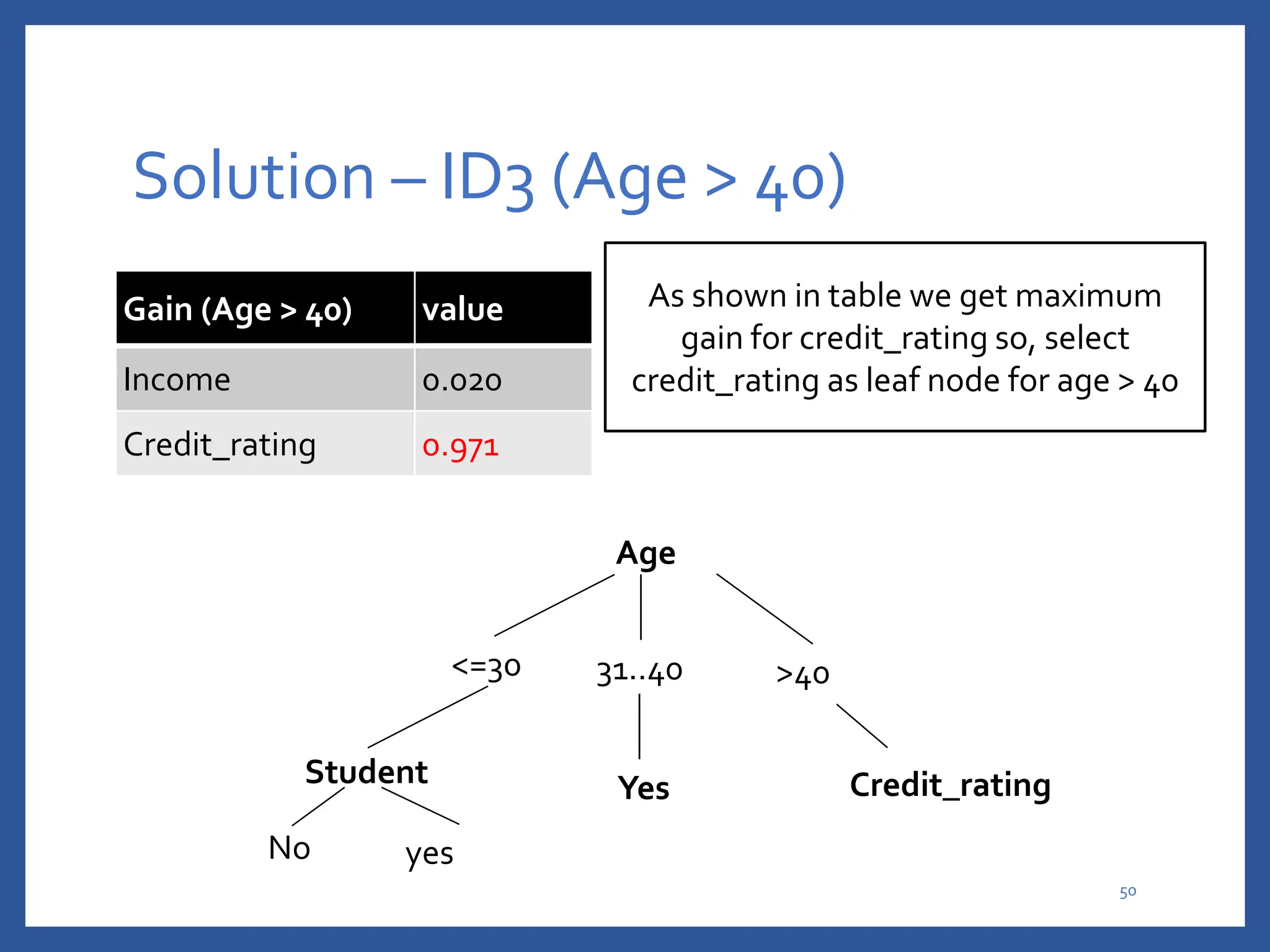
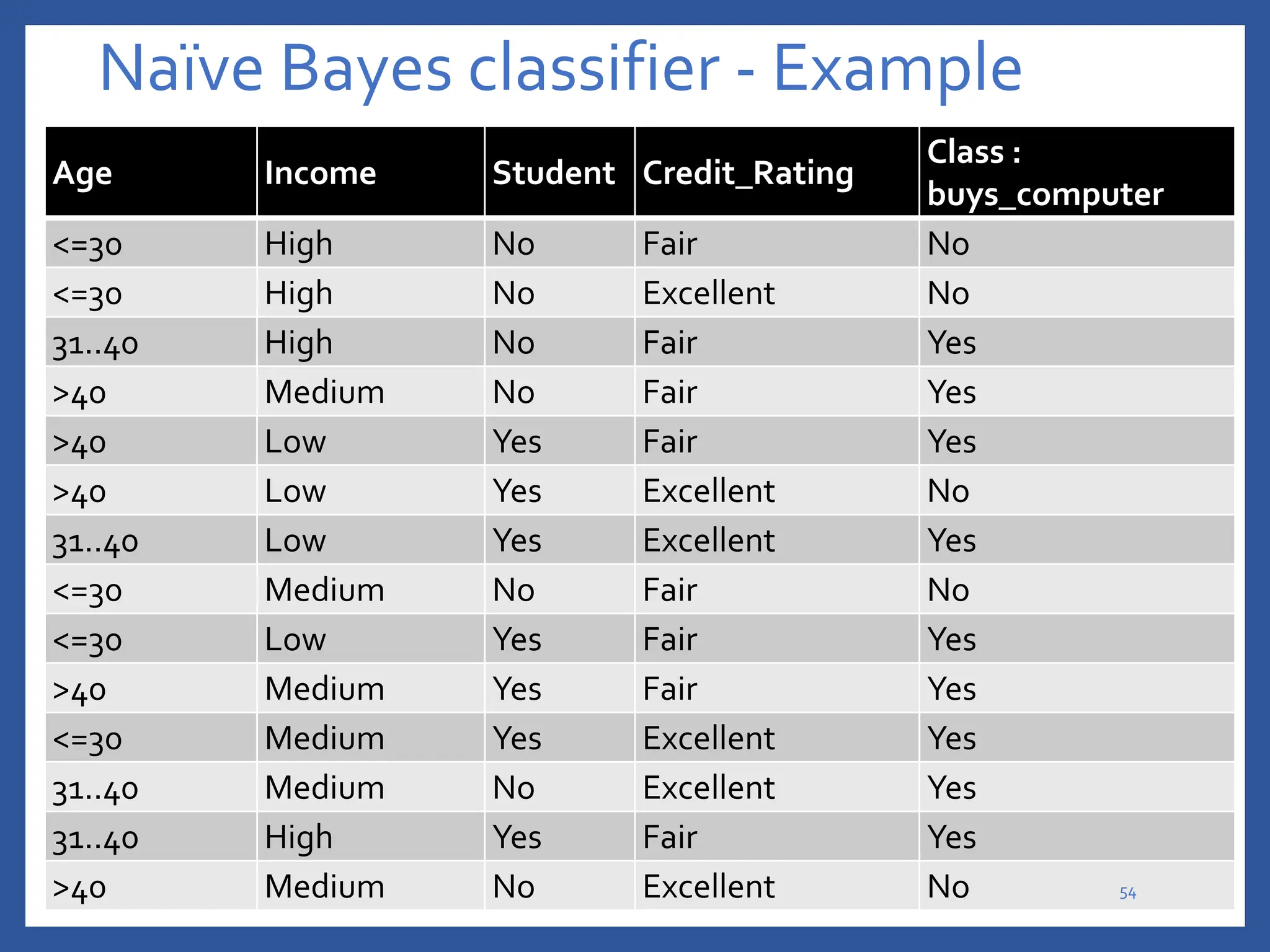
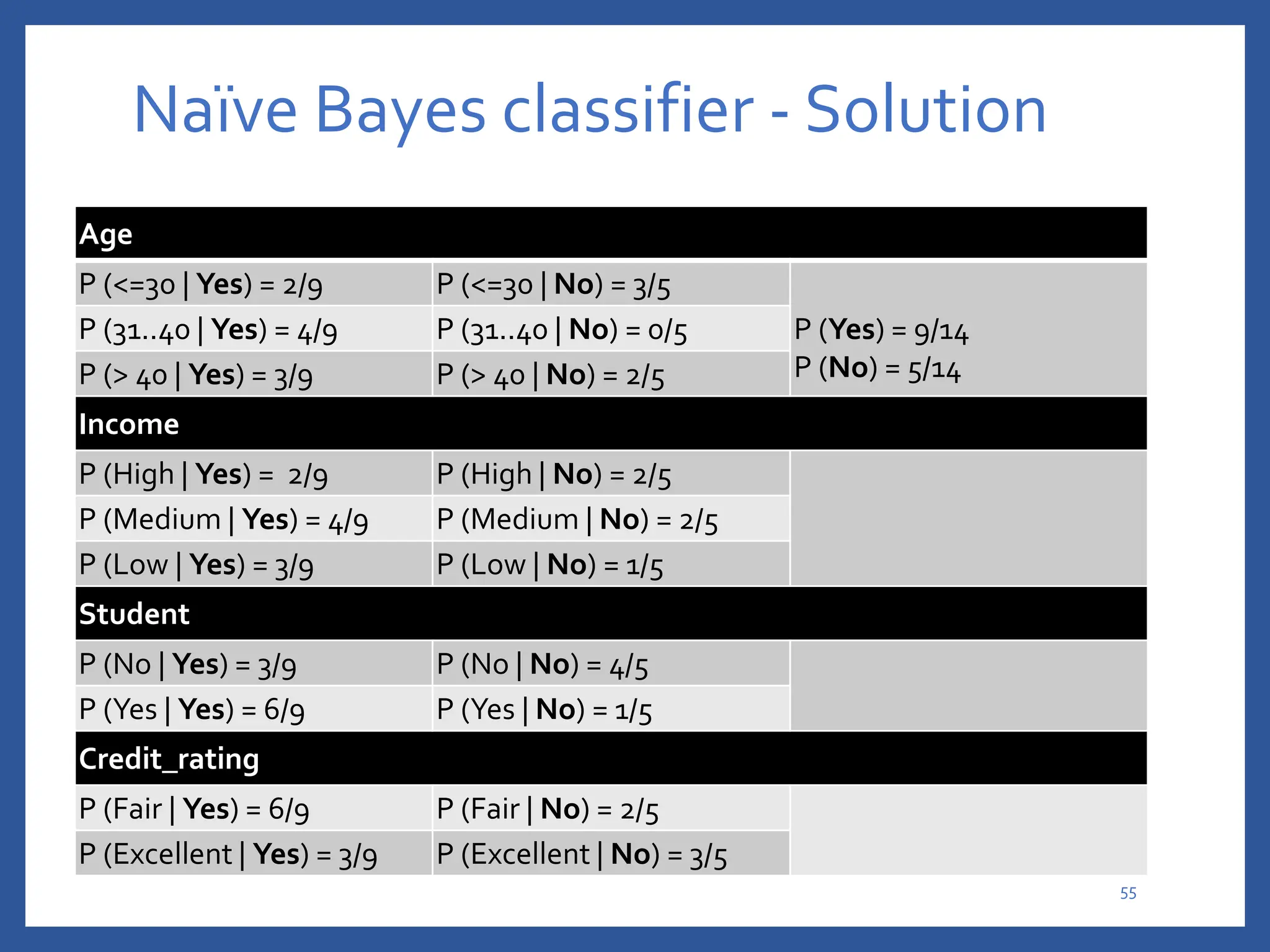
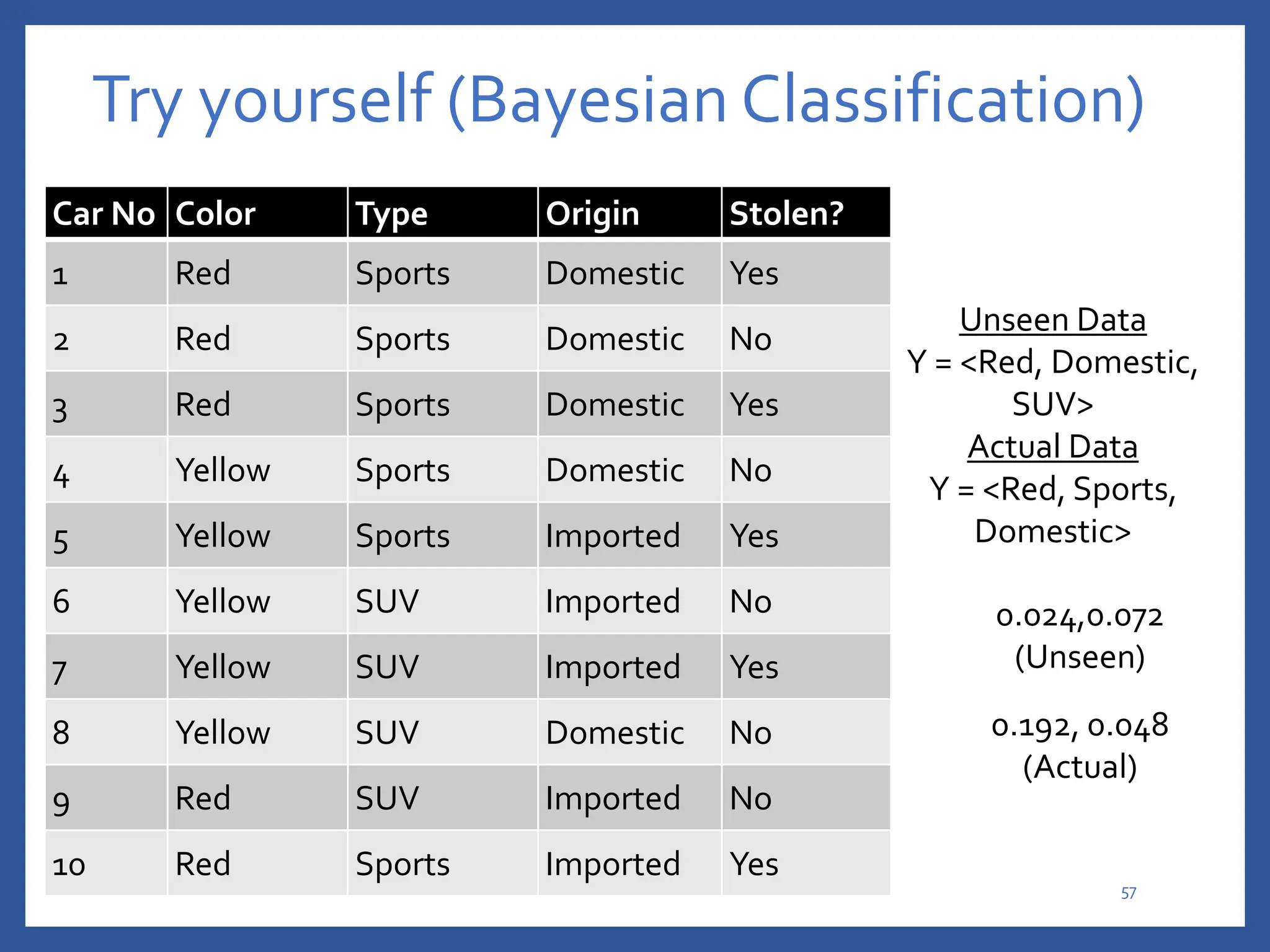
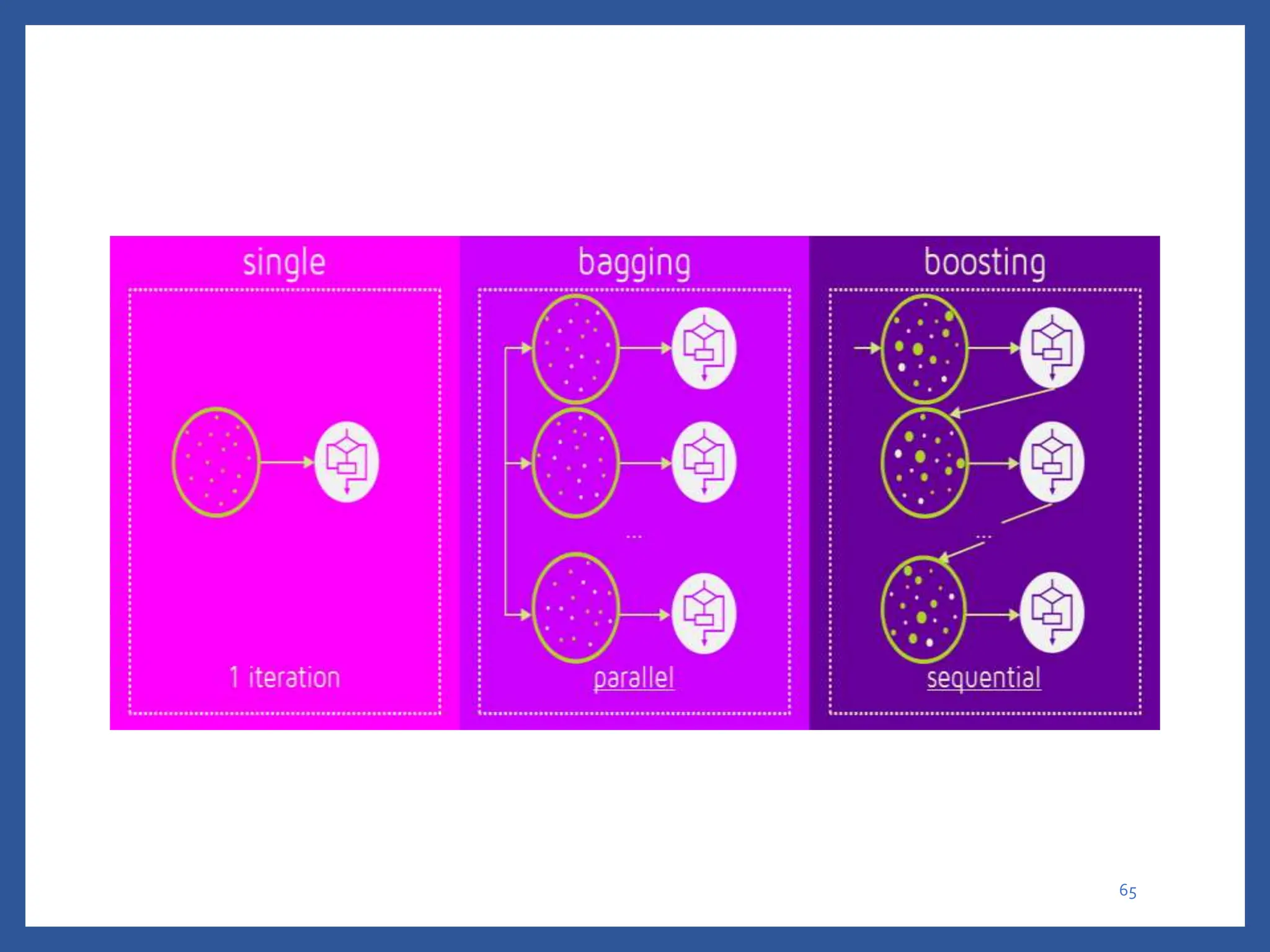
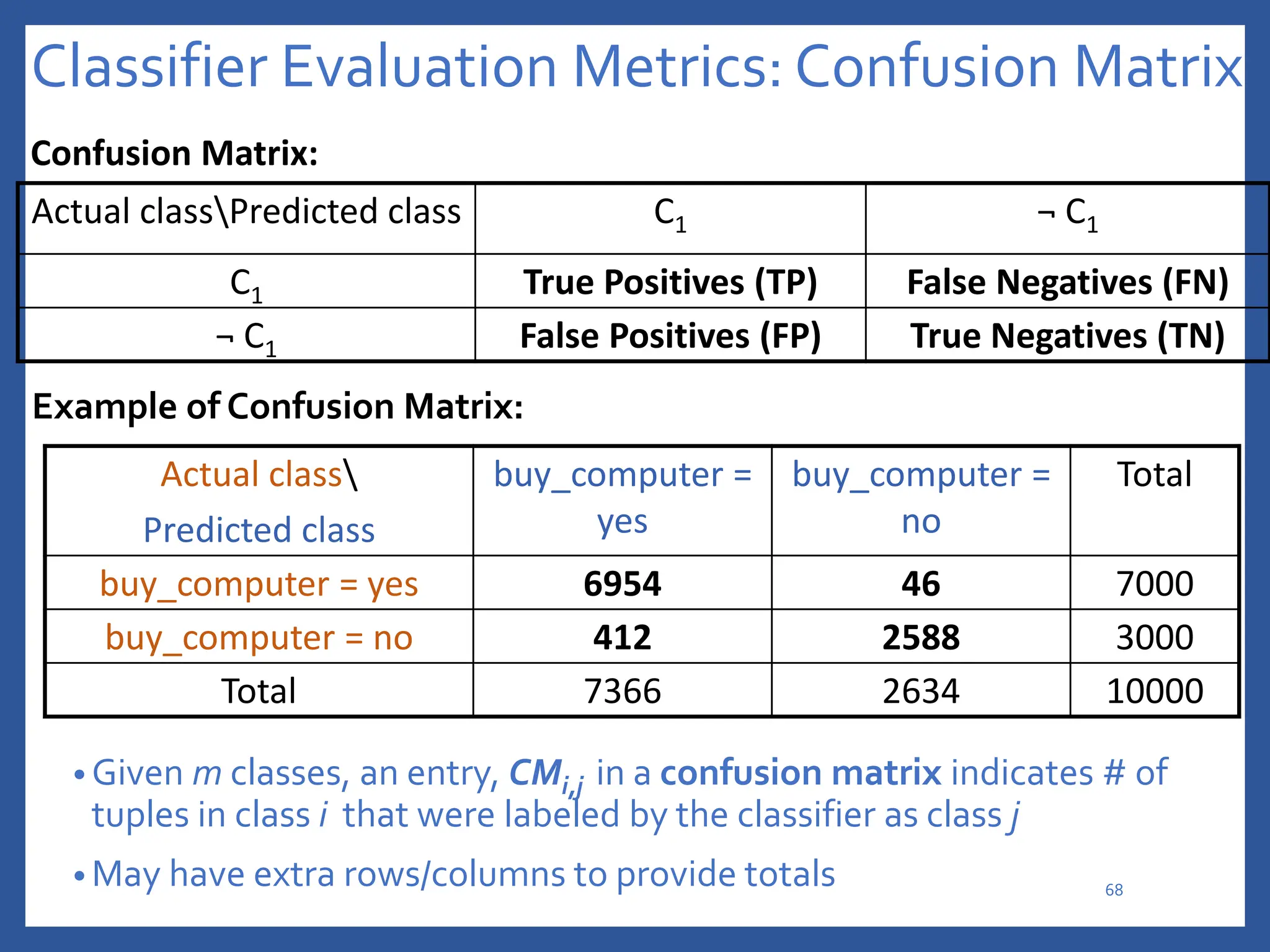
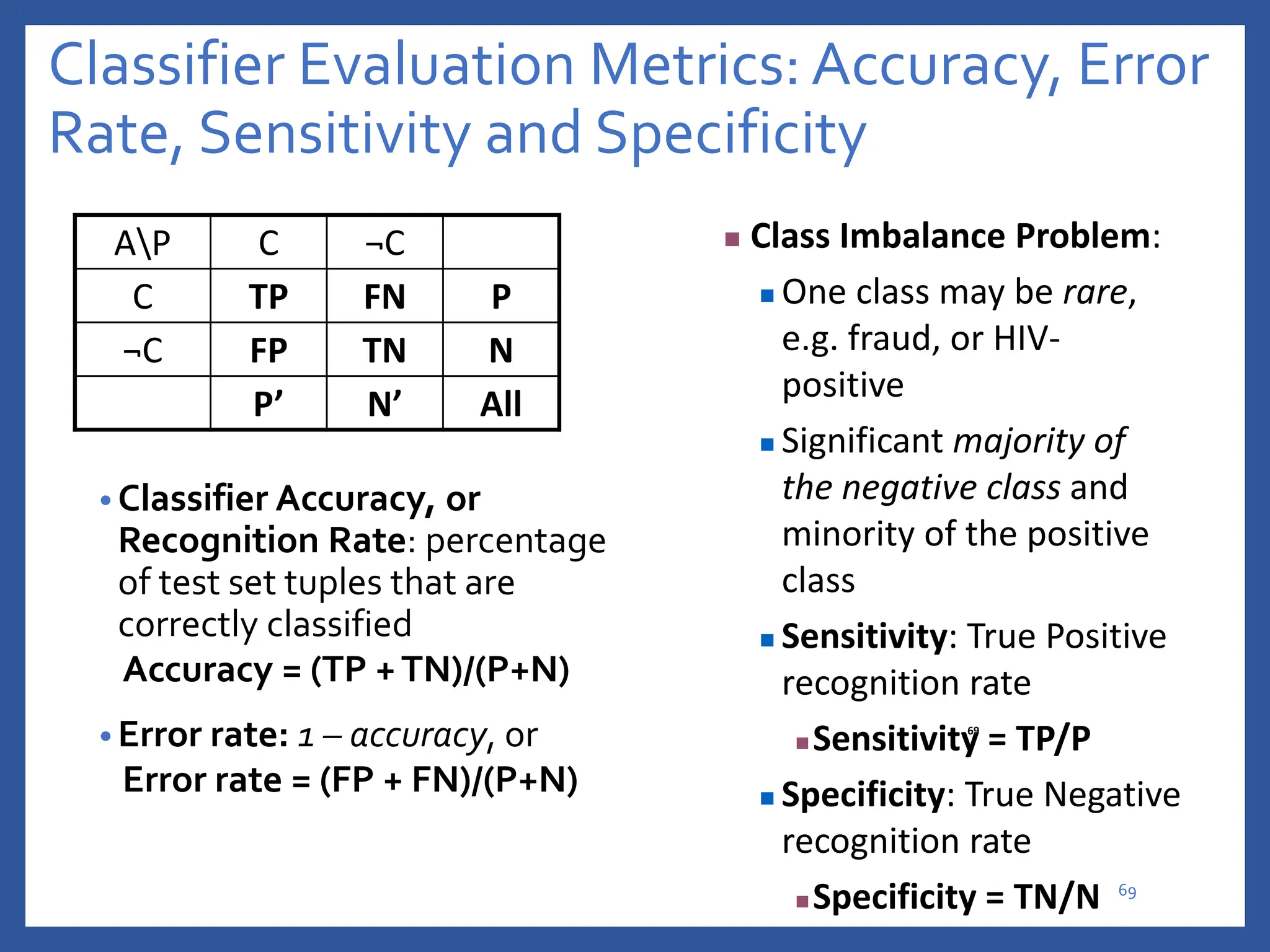
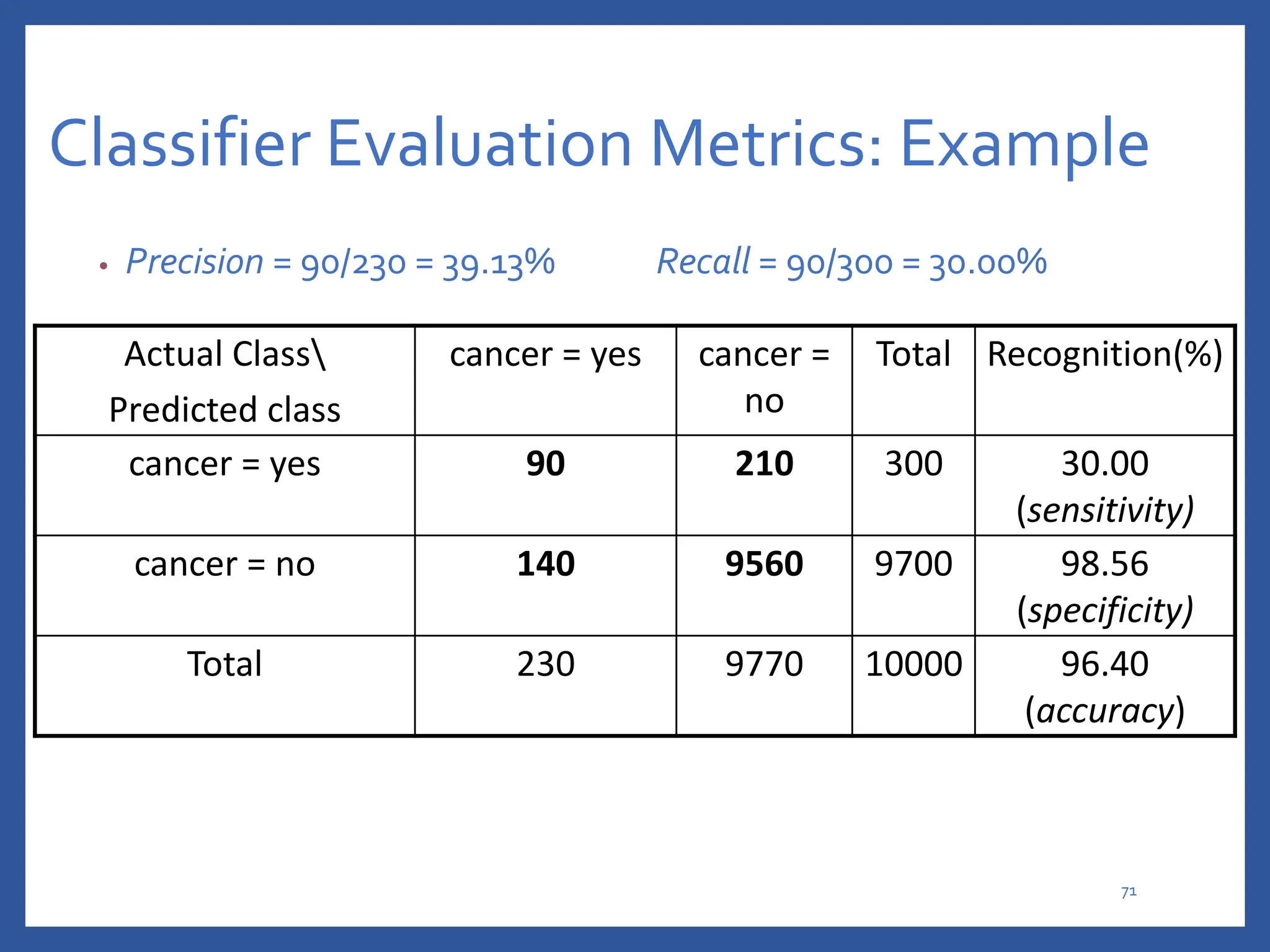
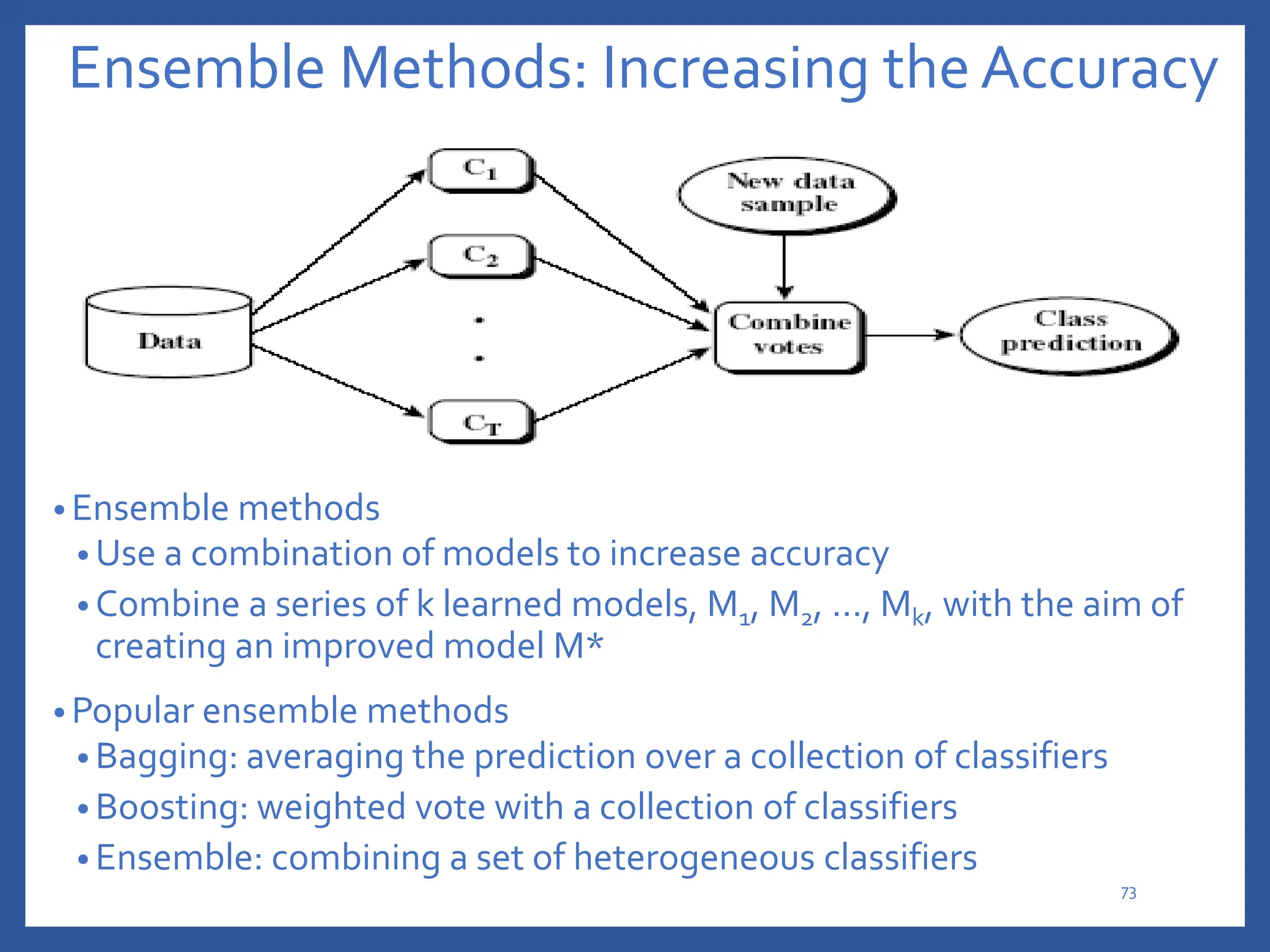
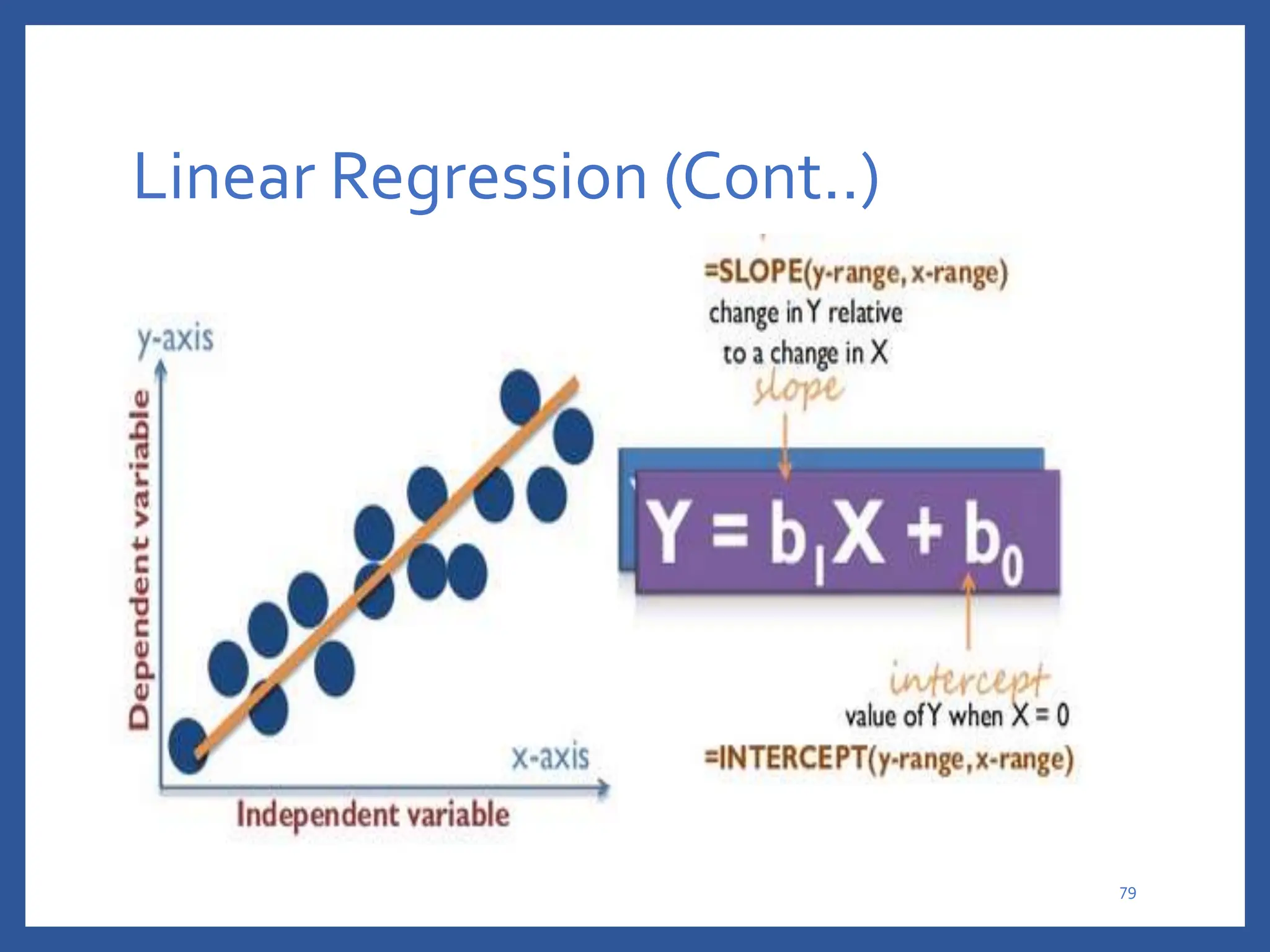
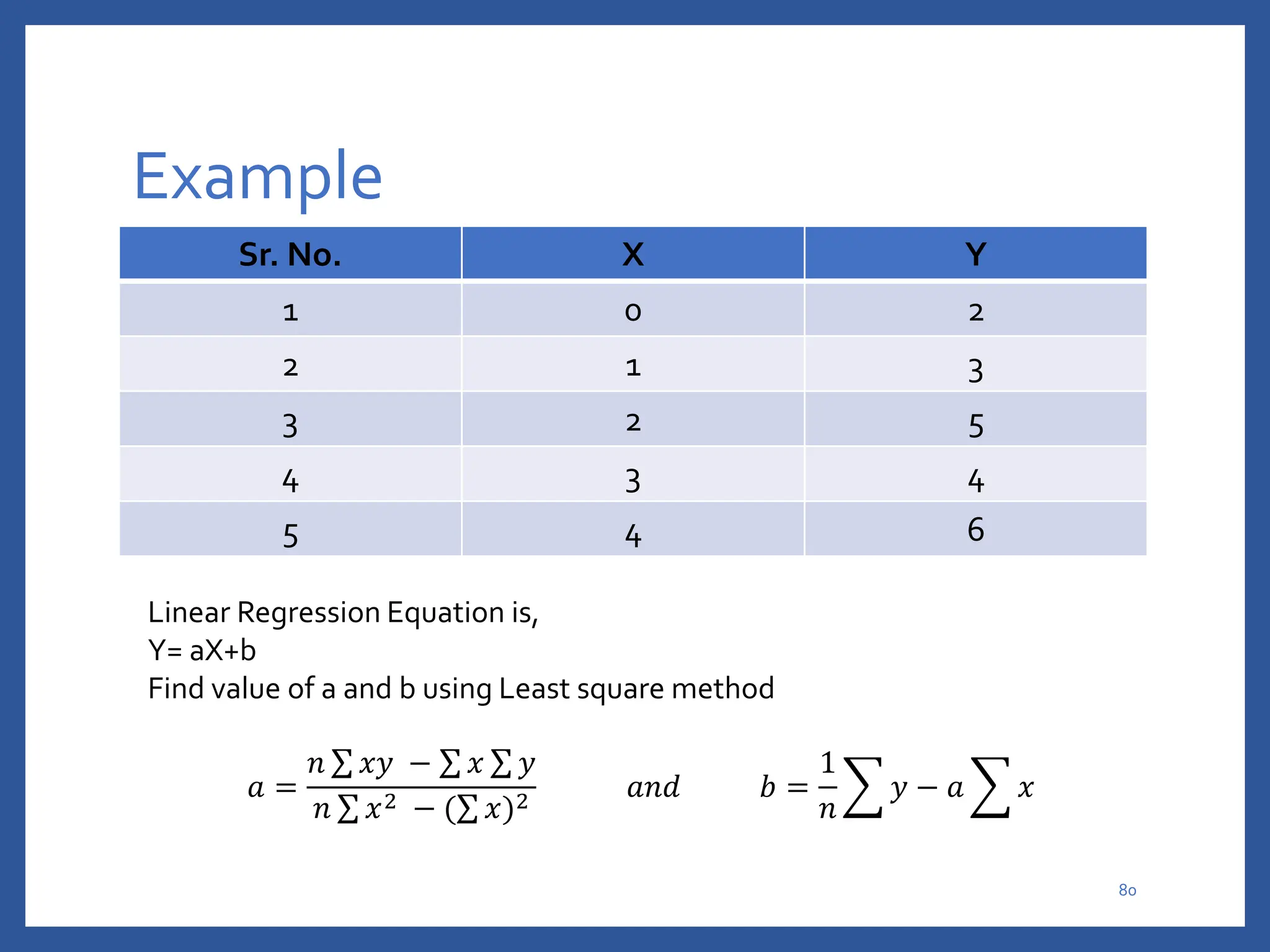
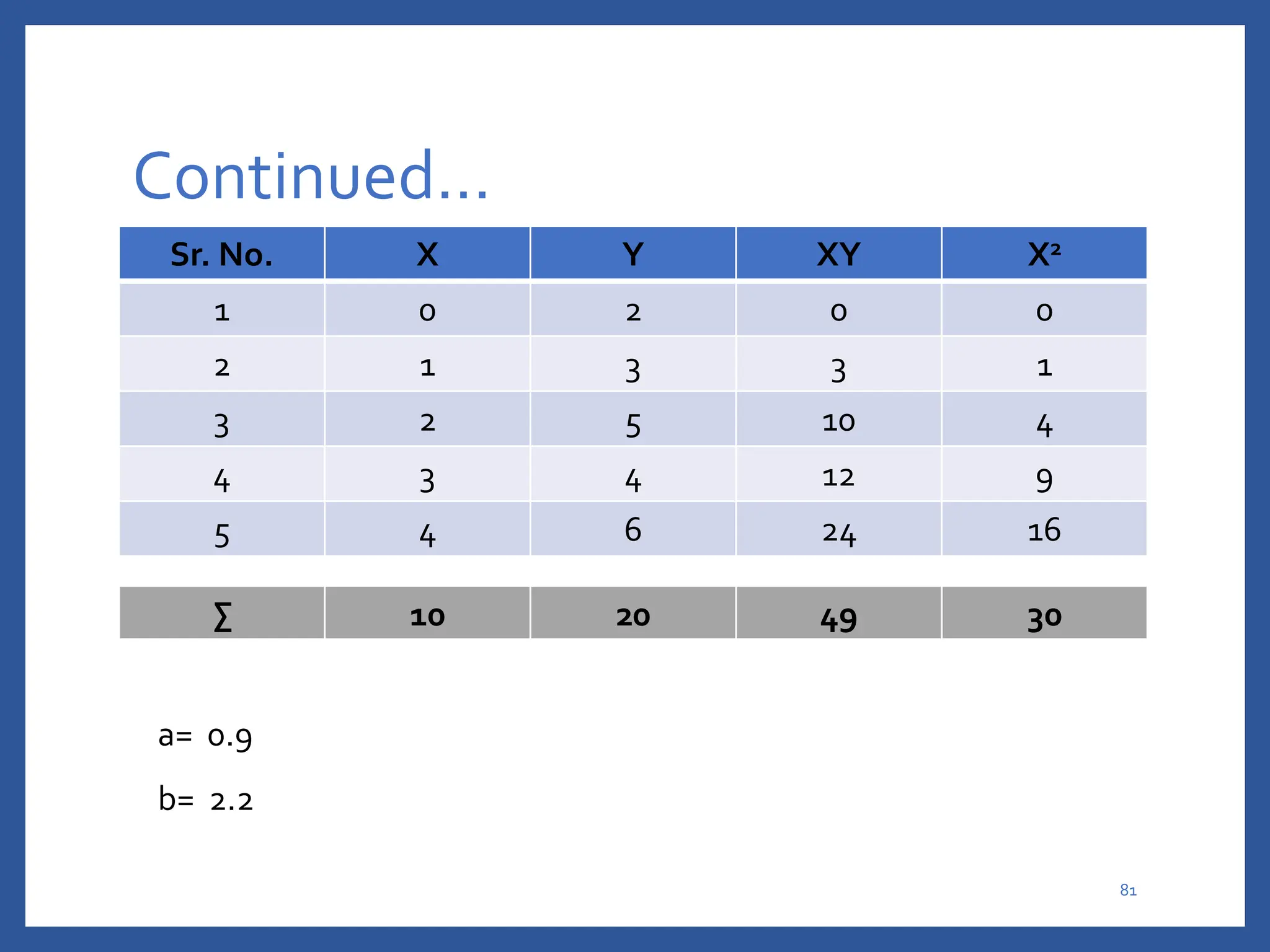
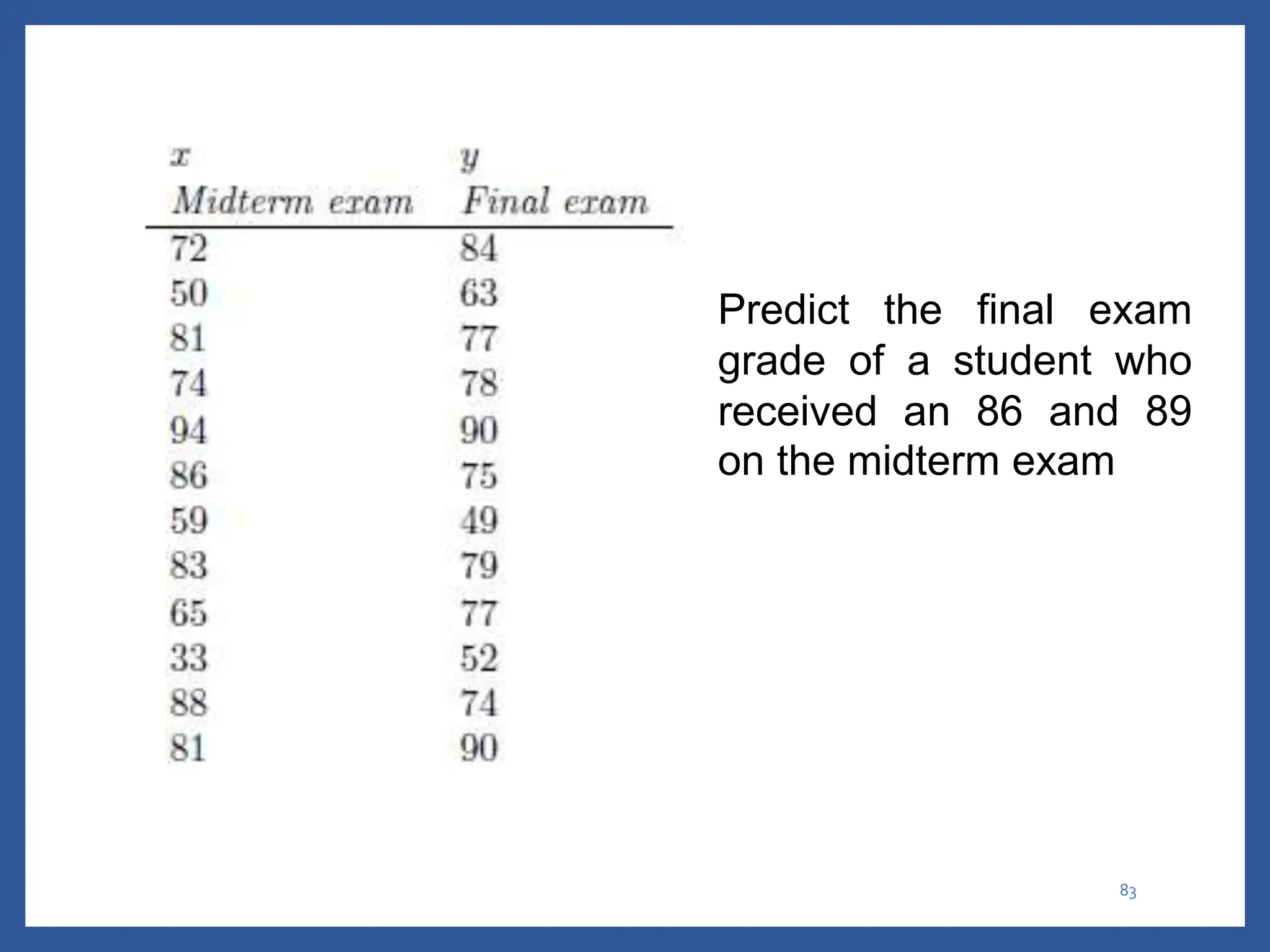
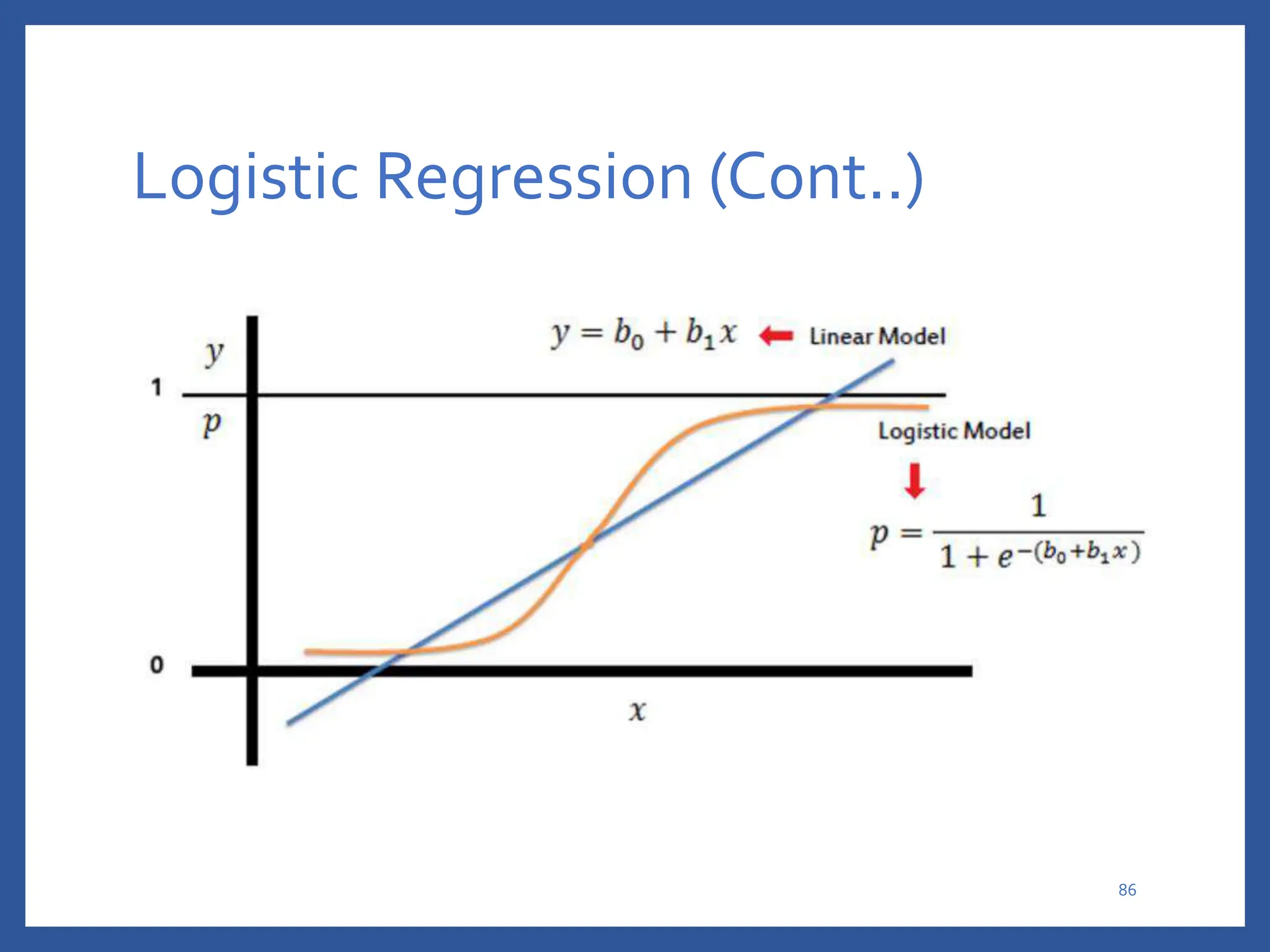
The document discusses classification in machine learning, distinguishing between supervised learning (where the model is trained on labeled data) and unsupervised learning (where no class labels are known). It describes various aspects of classification, including model construction, usage, and evaluation, focusing on algorithms like decision trees and metrics such as entropy, information gain, and the Gini index. The document emphasizes the importance of data preparation and the characteristics required for effective classification models.