Download as PDF, PPTX































![Don’t believe me?
• In MapStatus.scala
def apply(loc: BlockManagerId, uncompressedSizes:
Array[Long]): MapStatus = {
if (uncompressedSizes.length > 2000) {
HighlyCompressedMapStatus(loc,
uncompressedSizes)
} else {
new CompressedMapStatus(loc, uncompressedSizes)
}
}](https://image.slidesharecdn.com/top5mistakesv4160218171402-160218190042/75/Top-5-Mistakes-to-Avoid-When-Writing-Apache-Spark-Applications-36-2048.jpg)





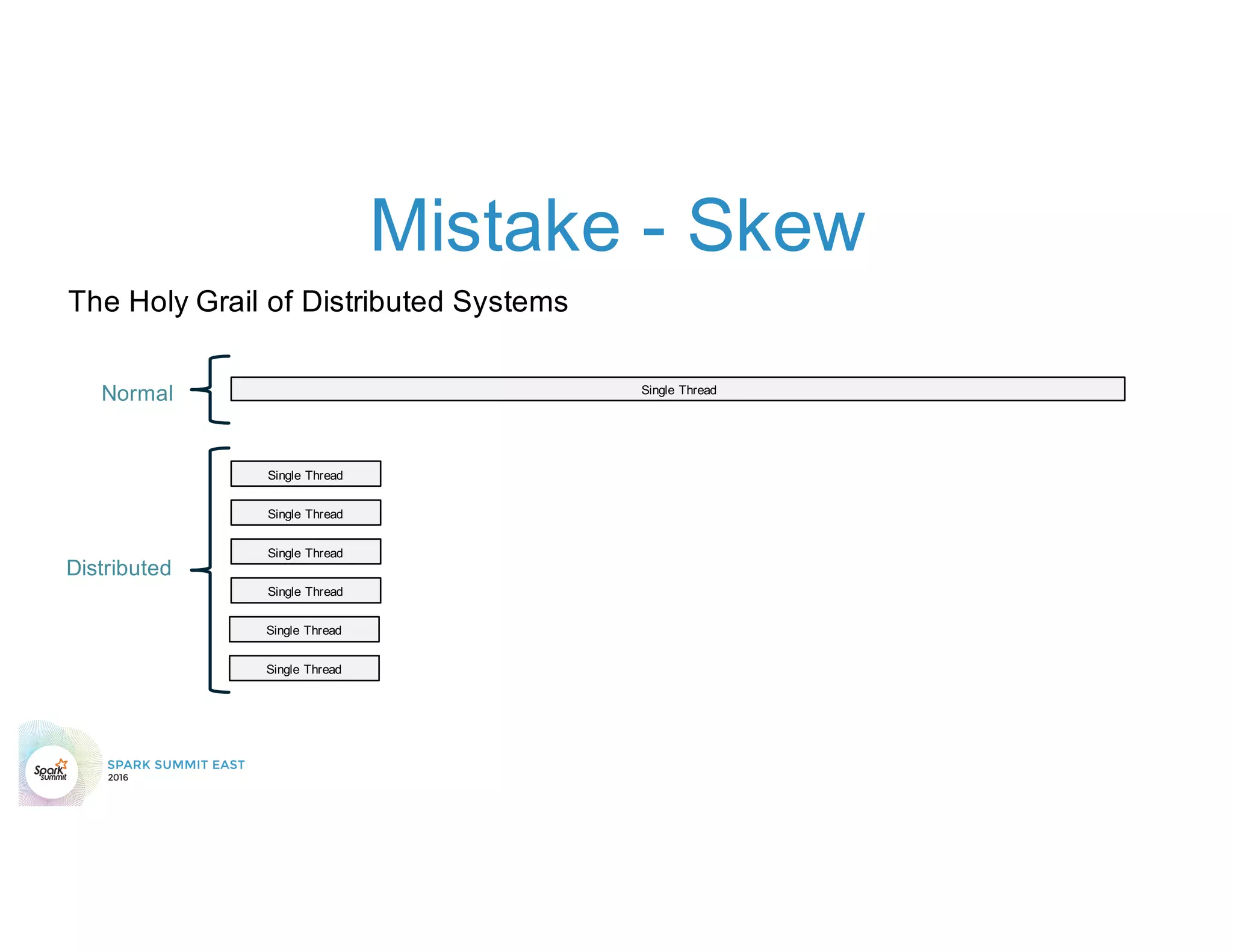



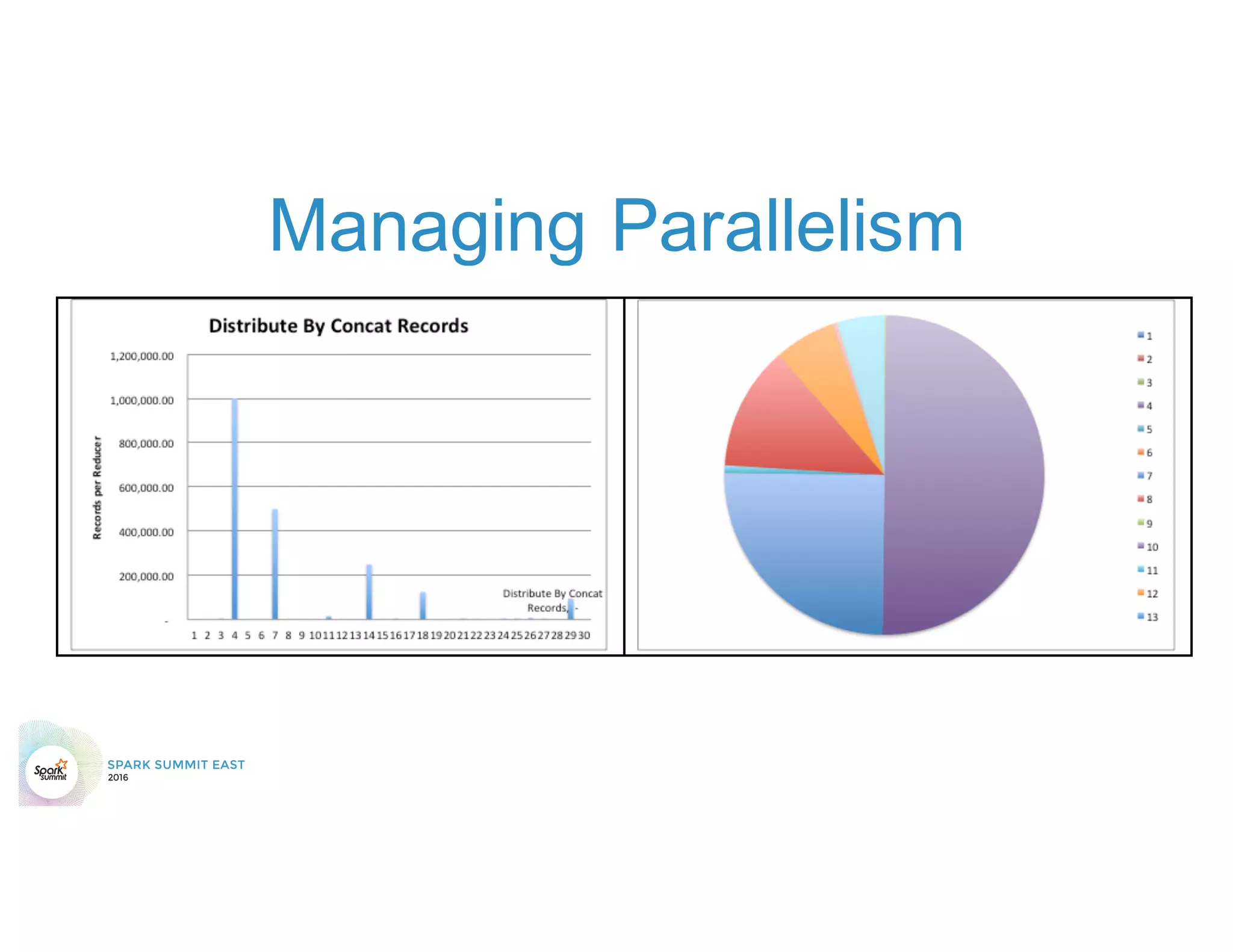


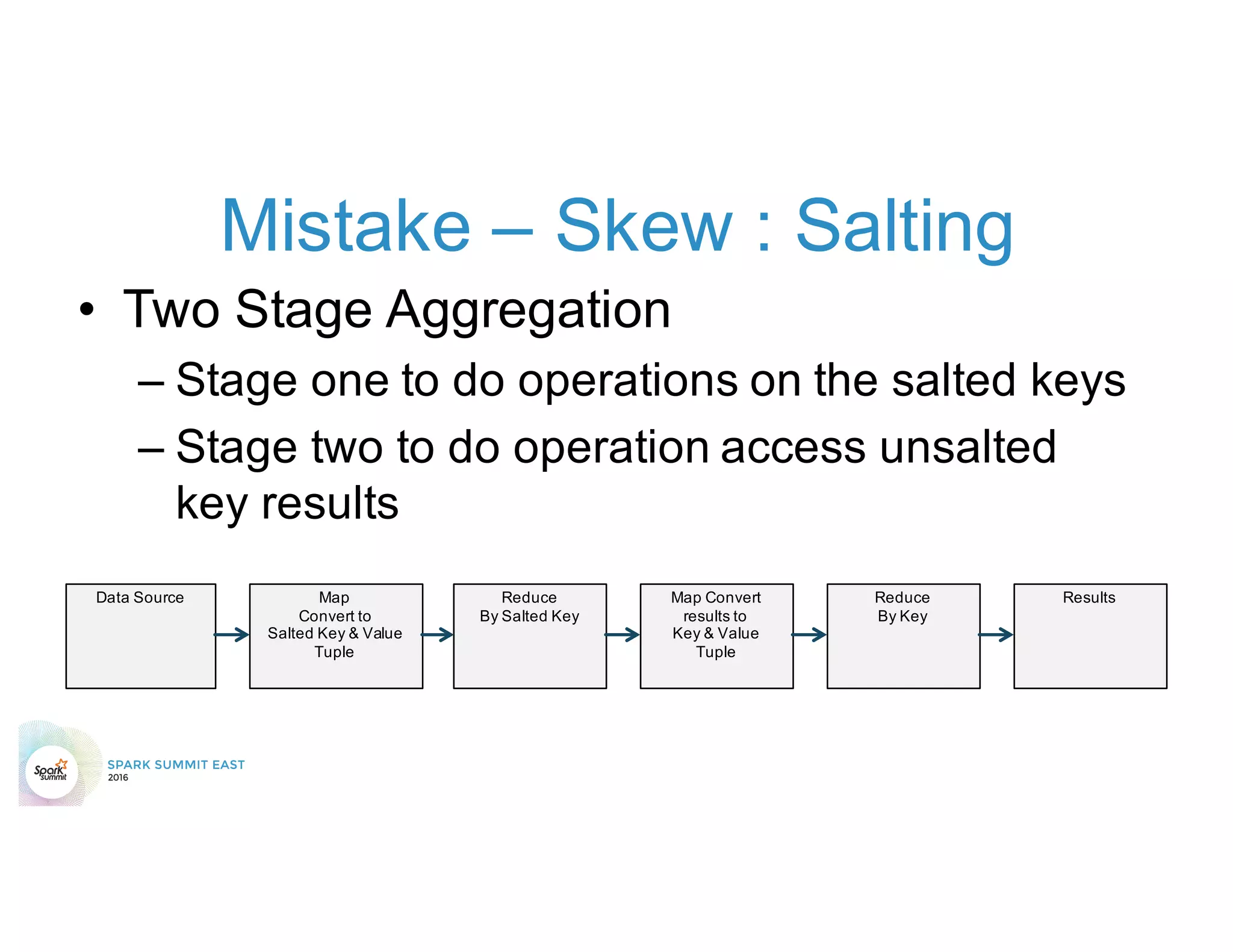
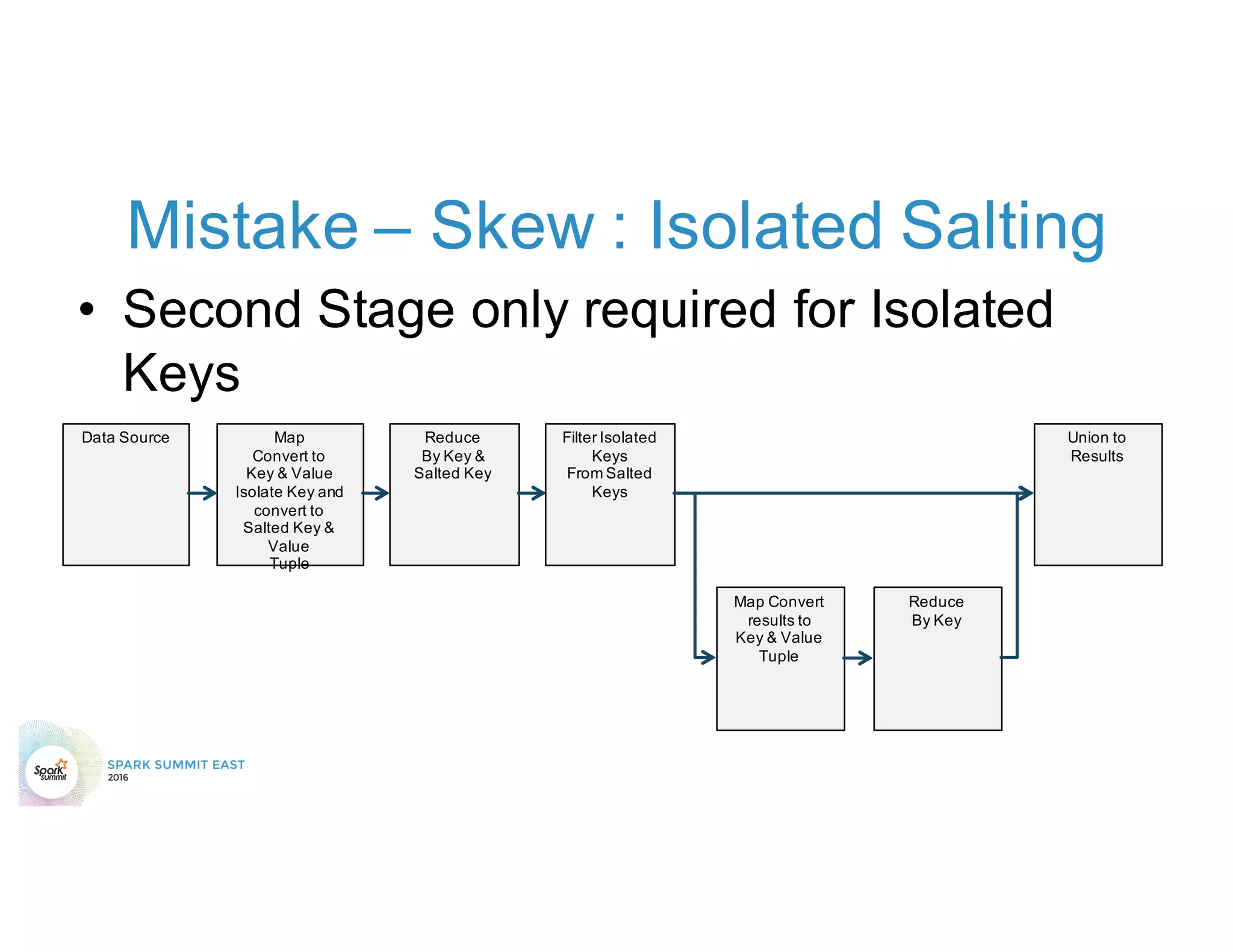
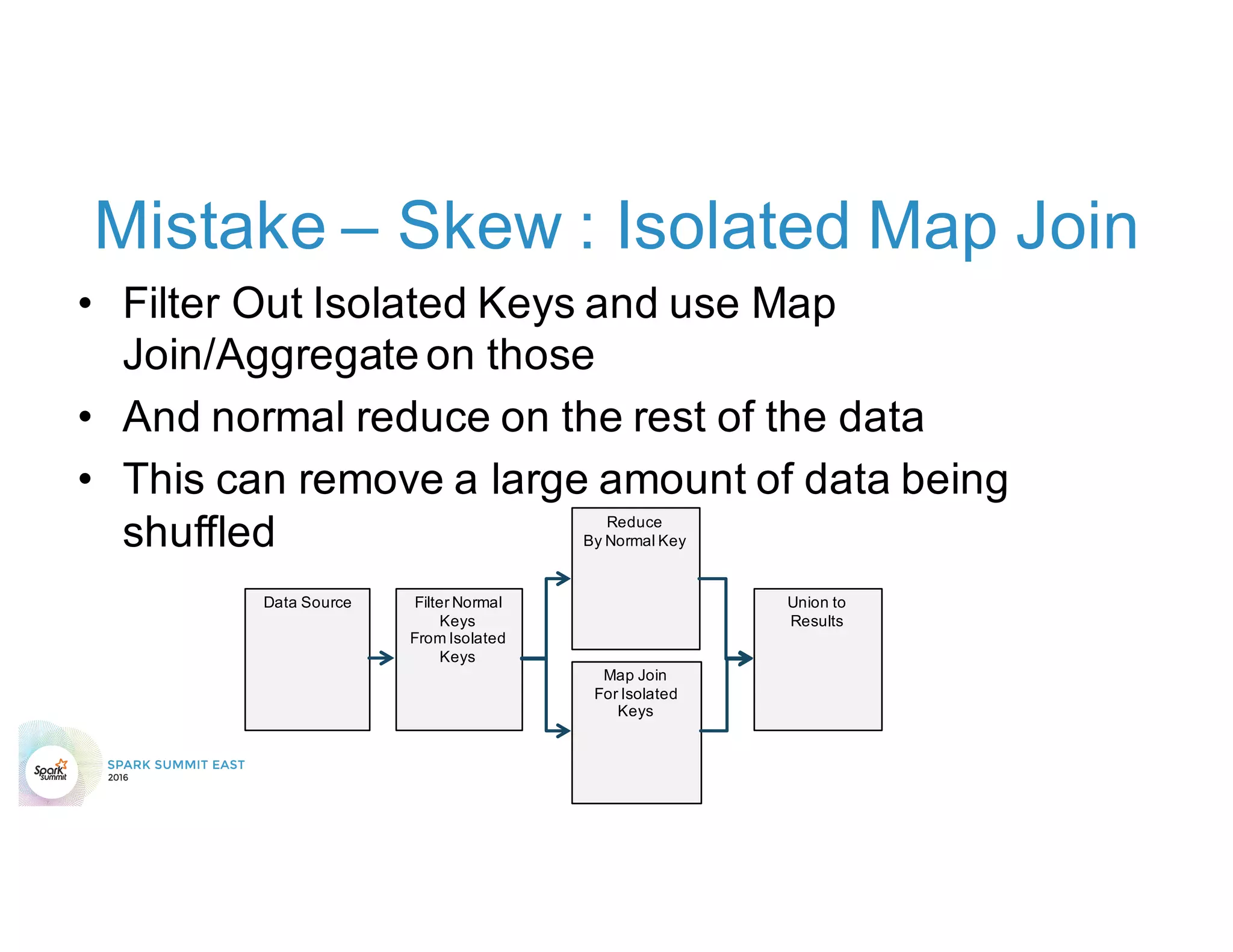
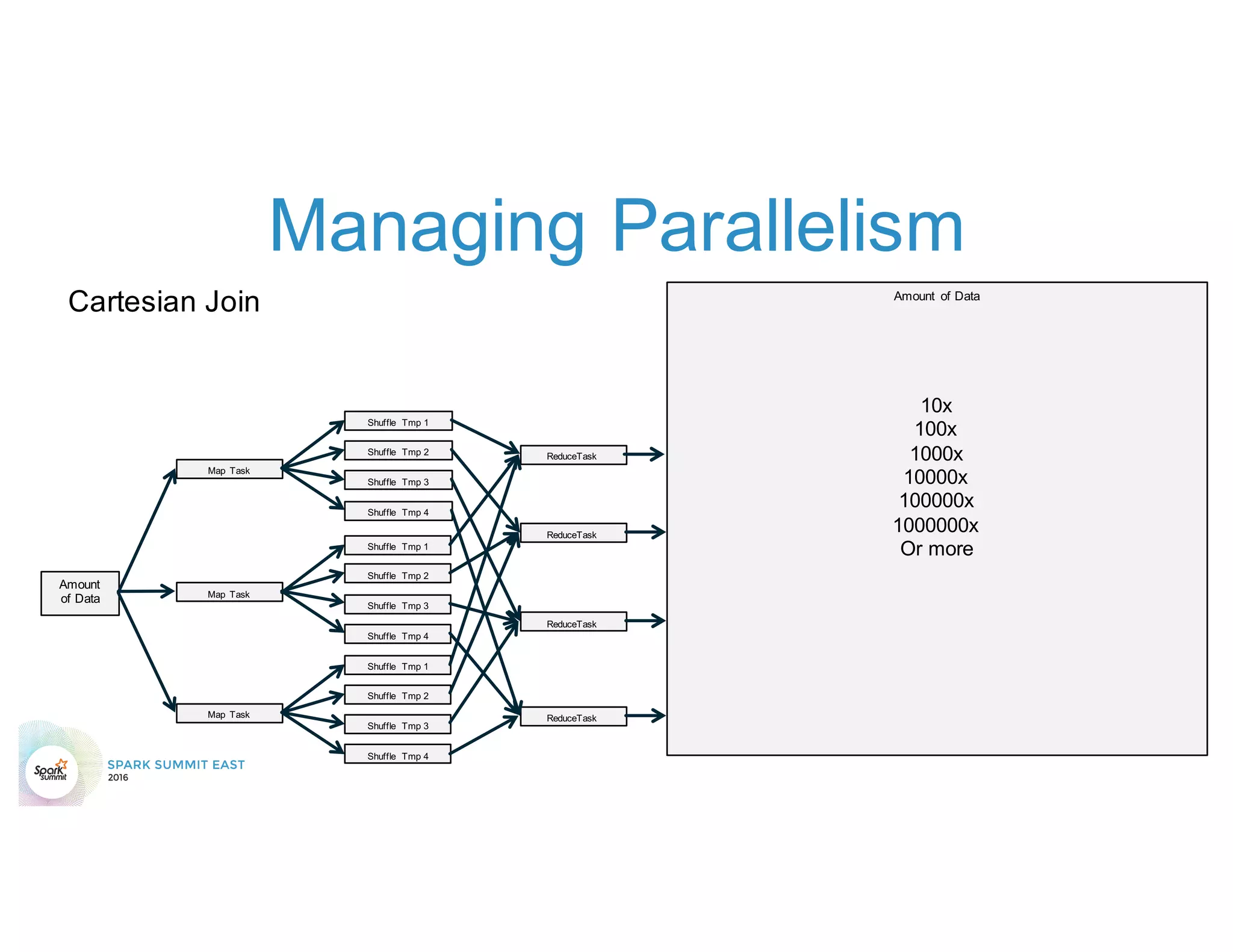






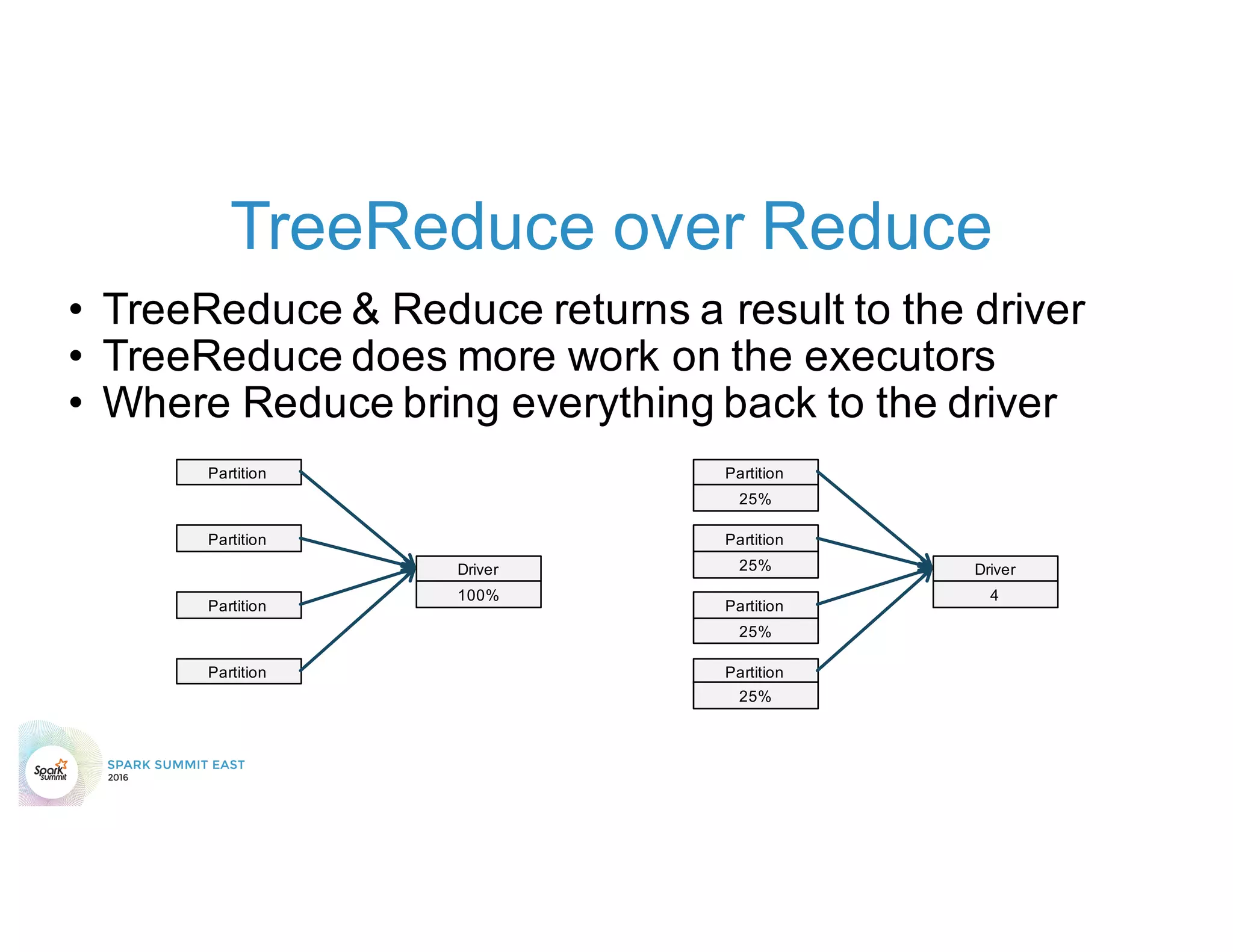











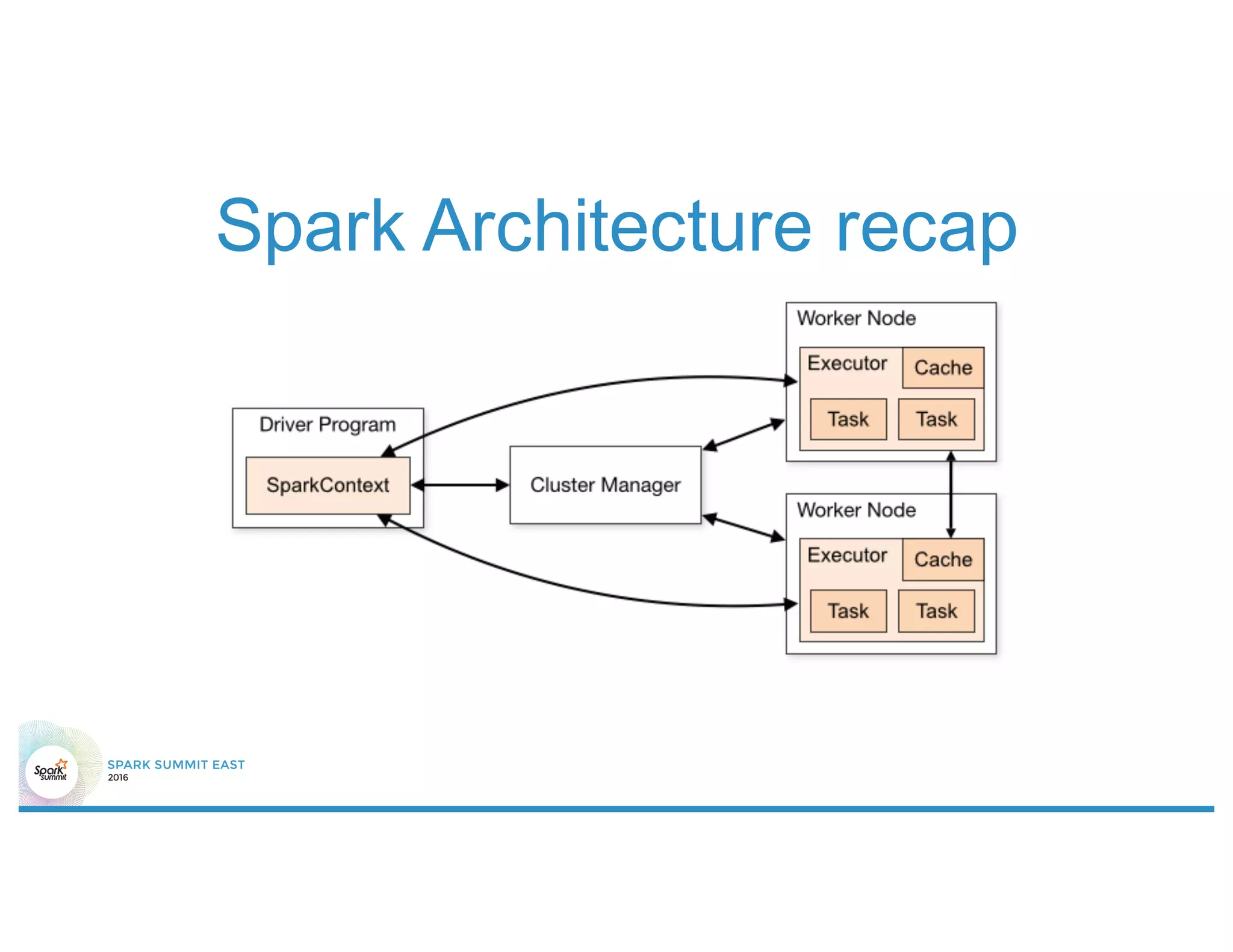
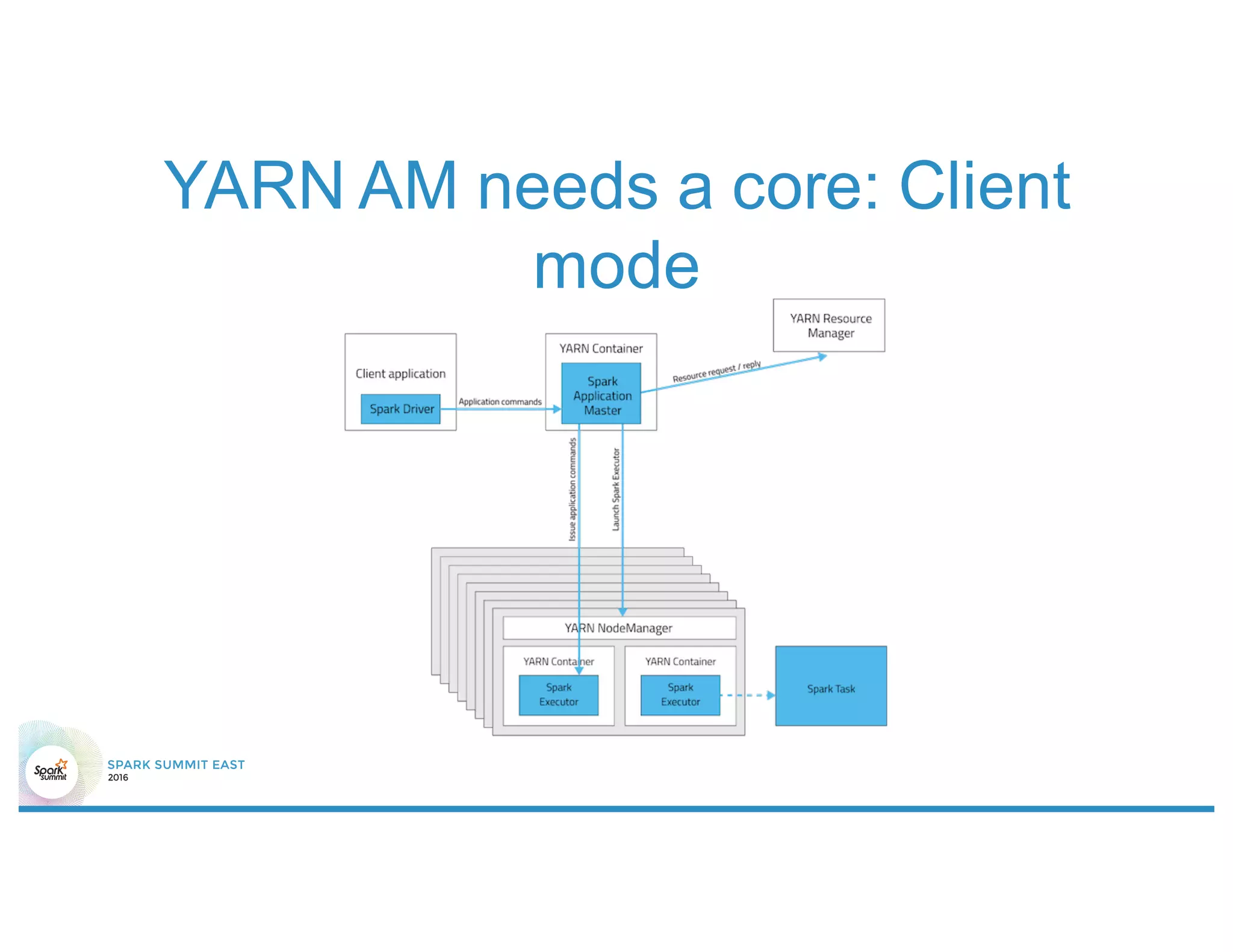
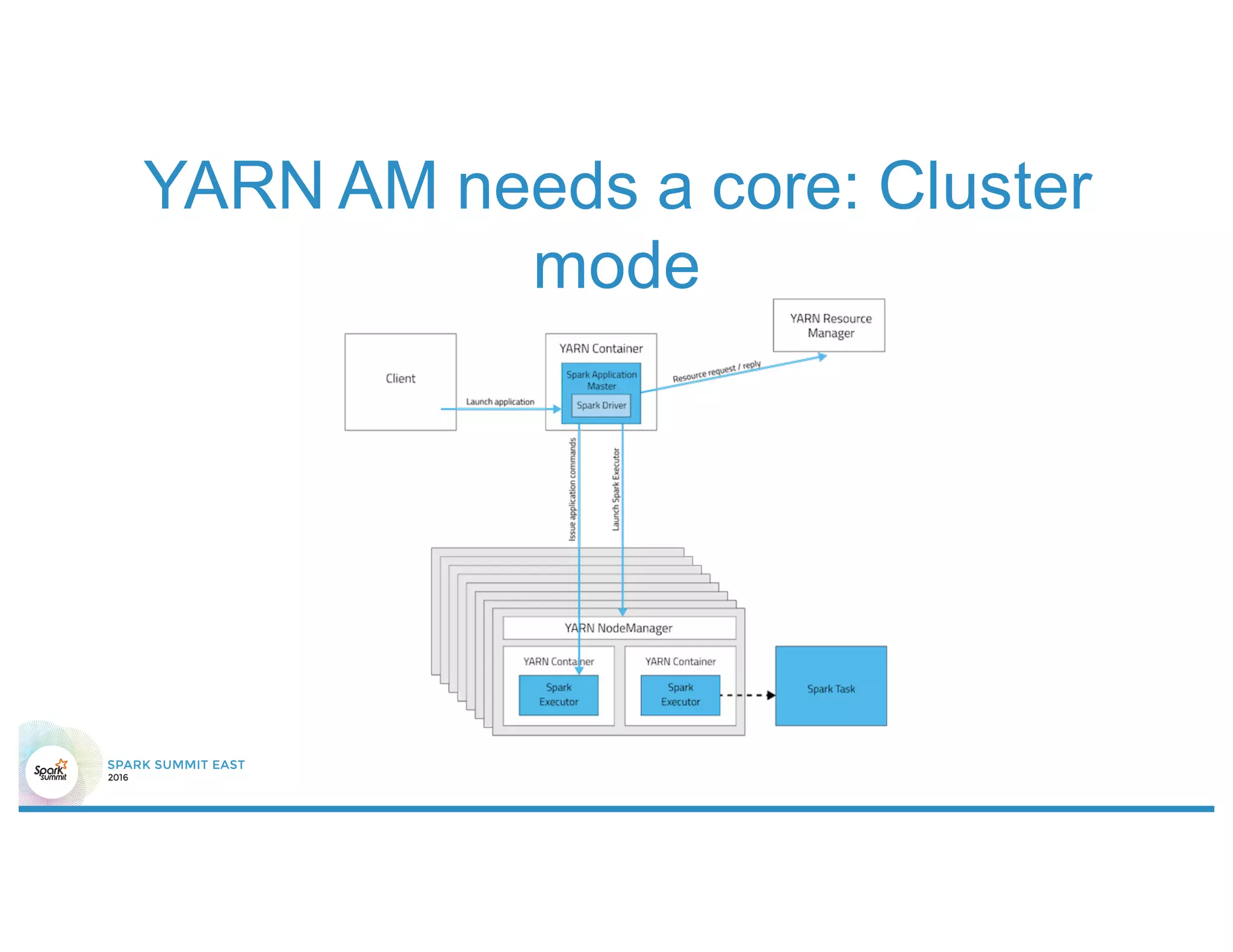
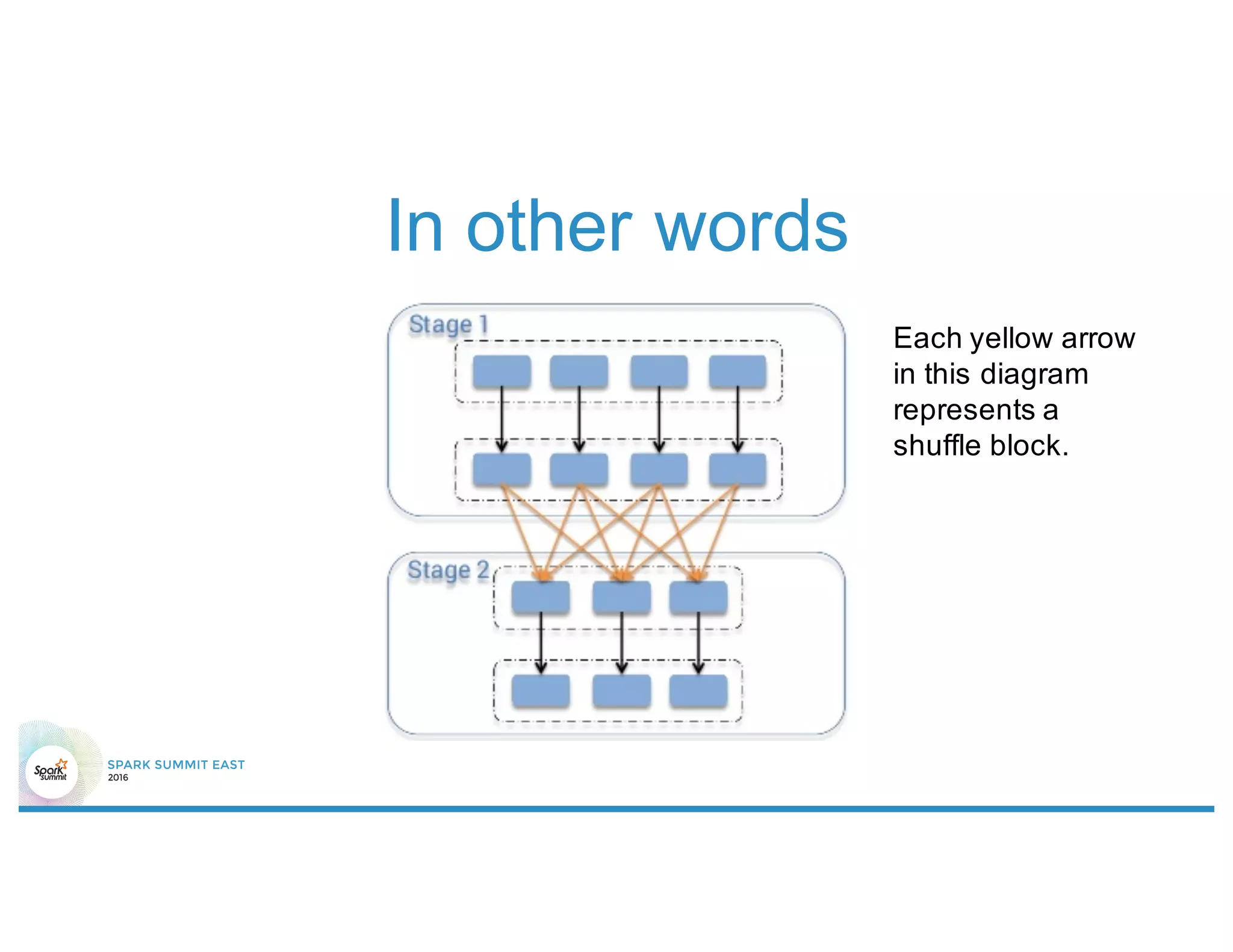
The document discusses 5 common mistakes people make when writing Spark applications: 1) Not properly sizing executors for memory and cores. 2) Having shuffle blocks larger than 2GB which can cause jobs to fail. 3) Not addressing data skew which can cause joins and shuffles to be very slow. 4) Not properly managing the DAG to minimize shuffles and stages. 5) Classpath conflicts from mismatched dependencies causing errors.























































































